
8
Advanced Queuing Topics
Chapter 7 focused on queuing and scheduling concepts and how they operate. This chapter discusses more advanced scenarios involving overprovisioning and guaranteed rates that are used in large-scale queues to differentiate shaping rates. This chapter touches on the debate about the optimal size of the queues and different memory allocation techniques. Finally, the chapter details the famous (or infamous) Random Early Discard (RED) concept.
8.1 Hierarchical Scheduling
The techniques in Chapter 7 described single-level port scheduling. But modern QOS scenarios and implementations need to support multiple levels of scheduling and shaping. A situation when this is common is a subscriber scenario that provisions end users. Consider the topology in Figure 8.1.
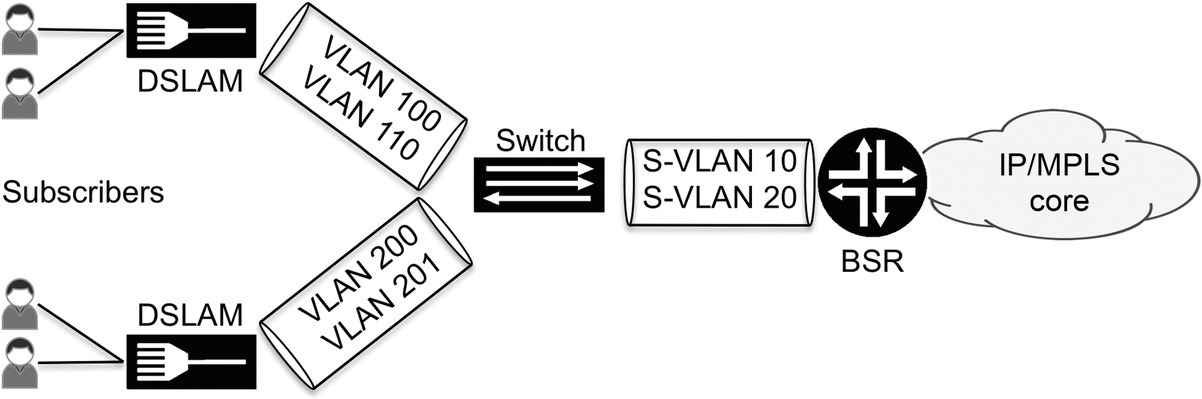
Figure 8.1 Aggregated hierarchical rate provisioning model
The Broadband Service Router (BSR) in Figure 8.1 has a 10-Gbps Gigabit Ethernet link to the switch. The two connections between this switch and the two DSLAM switches are both Gigabit Ethernet links. The subscribers have traffic contracts with different services and rates. To be able to have a functional traffic provisioning model, rates to and from the subscribers need to accommodate service and contracts. Traffic from the subscribers must be shaped to align with the service contract, and traffic to the subscribers must be shaped according to the supported model. To meet these conditions, a hierarchical shaping model must be created on the BSR router link to and from the aggregation switch. At the port level, traffic to the switch is first shaped to 1 Gbps on the two SVLANs, SVLAN 10 and SVLAN 20 in Figure 8.1. The next layer of shaping occurs on the VLANs that exist within each SVLAN. For example, some users might have 12 Mbps contracts, while others have 24 Mbps. In Figure 8.1, these VLANs are 100 and 110 on the upper DSLAM switch and 200 and 201 on the lower DSLAM.
The next level of scheduling is the ability to provide a differentiated model to classify different types of traffic, for example, VOIP, IPTV, and best-effort (BE) Internet traffic, by scheduling each into a different queue. Figure 8.2 shows the hierarchical scheduling and shaping model for this scenario.

Figure 8.2 Hierarchical scheduling model
Figure 8.2 shows two levels of aggregated shaping and scheduling. Routers that support hierarchical scheduling and shaping face issues not only with back pressure in levels from the port that carries SVLAN and VLAN toward the subscribers, but also, by the nature of the service, they need to support a large amount of traffic and they need to be able to scale.
QOS scheduling on a large scale, with a large number of units and schedulers, has to be able to propagate important traffic. Consider a case in which you have 1000 subscribers on an interface, with one logical interface (i.e., one unit) per subscriber. In the case of congestion, the scheduling algorithm establishes that each unit is visited in turn in case they have packets in their queues. This mechanism can result in variable delay, depending on how many users have packets in their queues. Variable delay is not desirable for users who have triple-play services with, for example, VOIP. The scheduling must be able to propagate information about the priority of the queues before all the subscriber queues are visited in order. Figure 8.3 shows how all user queues with high-priority VOIP traffic are scheduled before each individual user is visited.

Figure 8.3 Propagation of priority queues
A second scenario for aggregated hierarchical rate and scheduling models involves overprovisioning. A common scenario is to balance oversubscription against guaranteed bandwidth for the users. This concept is most often referred to as Peak Information Rate (PIR) versus Committed Information Rate (CIR). The sum of all the CIRs on an interface cannot exceed the interface rate or the shaped rate, but the PIR is allowed to exceed these rates. If all the bandwidth is not used, subscribers and shaped VLANs are allowed to reuse that bandwidth, as illustrated by Figure 8.4.

Figure 8.4 The PIR/CIR model
Consider a service provider who sells a real-time service such as IPTV Video on Demand (VOD) and who also sells BE Internet. The IPTV bandwidth is about 6 Mbps per user. The Internet service is committed to be about 4 Mbps. The result is a CIR of 10 Mbps per subscriber. When no other users are transmitting, the PIR is allowed to be 20 Mbps. This bandwidth can be achieved if no other users are using their CIR portion of the bandwidth. So this overprovisioning model has a PIR of 2 : 1. Traditionally, the CIR is always lower than the PIR. Using hierarchical scheduling and rates, one possible service can be to shape Internet service for users to a certain value. The charge for Internet access is a fixed price each month. For subscribers who also have IPTV service, the allowed VOD rate could be much higher than the contract because sending a movie over the VOD service results in direct payment to the operator. Therefore, the VOD rate is scheduled and shaped in a hierarchical fashion, separate from the subscriber Internet rate contract.
8.2 Queue Lengths and Buffer Size
One debate that comes and goes concerns the optimal size of the queue. It is sometimes called the small versus big size buffer debate. This debate can be viewed from a macro level or from a micro level.
First, let us consider the macro debate, which centers on the question of how to design congestion avoidance in the big picture. On one side of this debate are the supporters of big buffers. The designers who favor this approach argue that in packet-based networks on which QOS is implemented using per-hop behavior (PHB), routers and switches make all the decisions on their own, with no awareness of the end-to-end situation. Hence, here an end-to-end QOS policy is simply not doable. Traffic destinations change as the network grows or shrinks on daily basis. Thus, the rerouting that occurs as the network continually changes size invalidates any attempt to predesign paths, with the result that any traffic modeling easily breaks down. In this design, end-to-end RTT estimates are hard to predict, so it is a good idea for all resources to be available. The solution is to go ahead and add memory to expand the capability of storing traffic inside a router. One benefit of this is that big buffers can temporarily absorb traffic when traffic patterns or traffic paths change. The idea is that a combination of well-designed QOS policy and tuned bandwidth and queue length works only if the traffic patterns and paths are somewhat static and easy to predict. In the macro situation, rather than having an end-to-end QOS policy, the QOS policy can be adapted to define specific traffic classes and to align with the capabilities of the routers. If one router can support a queue length of hundreds of milliseconds, while another router in the traffic path can support up to seconds of traffic buffering, the QOS policy can be tailored to each router’s capabilities. In this way, the policies can be based on each router’s functions and capabilities, because traffic and other conditions can vary widely from router to router and day by day, making end-to-end policies ineffective or impossible. Figure 8.5 illustrates the main argument for defining QOS policies on each individual router.

Figure 8.5 Every router stands on its own regarding QOS
The opposing view is that end-to-end QOS policy is the only way for QOS to be effective, and hence buffers must be tuned to be a part of an estimated end-to-end delay budget. This means that for the possible congestion paths in the network, prioritizing the expected traffic is not enough. It is also necessary to tune the buffers to be able to carry the traffic and at the same time be within the end-to-end delay figures. The estimation of what a fair share of the path and bandwidth is needs to take into account both the steady-state situation and predicted failure scenarios along the traffic paths and must also anticipate possible congestion points. The rule to be followed with this approach is to control the rate of traffic entering the network. The amount of traffic that needs to be protected cannot be greater than what the network can carry. To achieve this service, the convergence and backup paths need to be calculated. A common way to control the paths is to use RSVP LSP signaling, implementing object constraints regarding bandwidth and ERO objects to control the end-to-end delay and bandwidth, because LSPs allow complete control over the path that the traffic takes (see Figure 8.6).
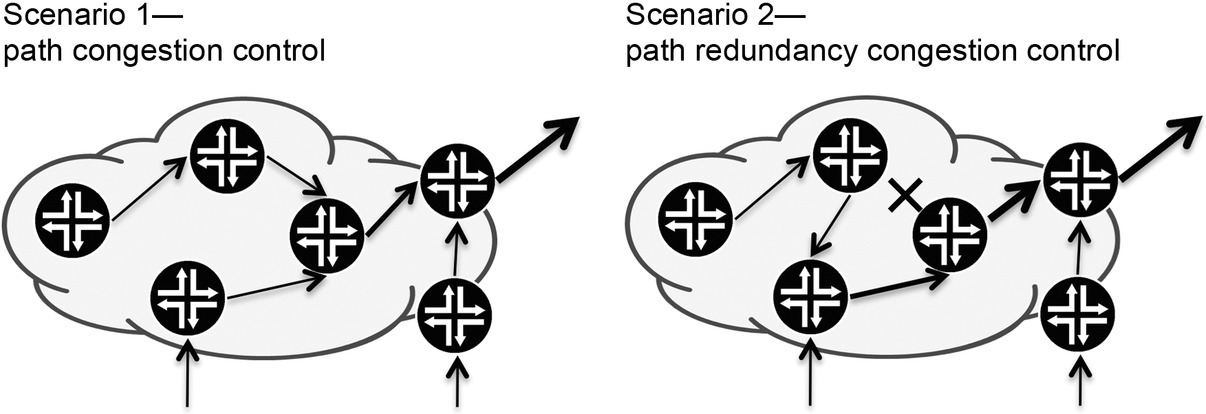
Figure 8.6 End-to-end QOS policy for certain traffic classes
When considering these two approaches, the reality is probably that good queue length tuning needs to use a little of both alternatives. Real-time applications obviously need to have reliable control of traffic paths, which means that the number of congestion points need to be minimal and the end-to-end delay, in milliseconds, needs to be predictable. For these applications, designers generally think that buffers should be small and paths should be well designed. Also, in the case of a network path outage, equivalent convergence backup paths should be included in the design.
Here is a concrete example of balancing the queue length and buffer size. A transit router has four 10-Gigabit Ethernet (10GE) links. (A 10GE link is 10 000 Mbps.) Transforming this to bytes gives 1000/8 or 1250 Mbps. Transforming this to milliseconds gives 1250 × 1000 or 1250 kB. This means that 1 ms of traffic is 1250 kB. If the router supports 100 ms of traffic buffering, the buffer allocated to the 10GE interface is 100 × 1250 kB or 125 000 000 bytes of memory.
Under steady conditions, the estimate is that a router has one duplex path for transit voice traffic and the volume for one direction is 500 Mbps. If a reroute event occurs, one more duplex path of voice traffic transits the router. In the case of congestion, the core link may suddenly find itself carrying 1000 Mbps of voice traffic or 125 kB/ms. This traffic volume can be handled well by a router capable of buffering 100 ms of traffic on the 10GE interface.
In the first design approach, in which each router handles QOS on its own, the calculation for QOS ends here. The second design approach demands that buffers be adapted to the end-to-end RTT and that backup paths be well controlled, for example, by link-protection schemes. If a reroute scenario demands bandwidth and ERO cannot be achieved, the routing and forwarding tables cannot deliver the traffic. The result is that RSVP would resignal the ingress and egress points of the LSP to achieve the ERO requirements.
One possible design compromise is to use RSVP LSP paths for loss-sensitive traffic to control the buffer length and paths, effectively establishing a predictable delay and handling the bulk of the BE traffic with the available buffer space on each router in the network.
Now, let us consider the micro view, which considers the best behavior for the majority of applications and protocols regarding buffer tuning. Most designers agree that delay-sensitive and loss-sensitive traffic favors a design with smaller buffer lengths. The big difference between the micro and macro views is probably the dimensioning of the queue size for the TCP BE traffic. That is, should we use short queues so that bad news can be relayed quickly? The result would be earlier retransmissions or even the avoidance of too much congestion from transmitting hosts. In theory, retransmissions within a session are limited to a few packets because the queue should not be very full. The whole purpose of using smaller queue sizes is to avoid a “bigger mess” caused by delays in delivering bad news. With small queues, the delay is relatively low and jitter is not much of an issue, but the volume of packet retransmissions is higher. Web applications that are short lived are more sensitive to delay because response time must be quicker since there is not much CWND buildup and not many bytes of traffic are transferred. On the other hand, should the queue be big to be able to smooth out bursts, but at the cost of increased delay or even a huge jitter? Having large queues would avoid retransmissions and allow smoother traffic delivery, and they ignore the delay factor because no delay occurs if the sessions exist just to transfer a file.
You can never have enough buffers to smooth the bursty traffic of all possible BE users in today’s Internet or large enterprise networks. Consider TCP-based traffic that is elastic with regard to its congestion and receiving windows. The memory necessary to be able to buffer all user streams is equal to all possible active TCP sessions, and the sessions of traffic must be multiplied by the maximum size of each session’s TCP window. In most situations, providing this amount of memory is unrealistic.
8.3 Dynamically Sized versus Fixed-Size Queue Buffers
As we have discussed earlier, other queues can be configured to use bandwidth that is not being used by higher- priority or active queues. This means, for example, that when saturation and packet drops are expected with a BE queue, the queue can receive better service if no assured-forwarding or expedited-forwarding packets need the allocated bandwidth and scheduling time. BE service is normally not rate-limit or policed to conform to a specific rate, so if a BE queue gets more scheduling time because other queues have nothing to remove, this is simply the nature of BE traffic and oversubscription.
But the question arises about whether you should share buffers also. That is, should you allow the queue size memory quota to be reused if it is not needed by other queues? The advantages with this, of course, are being able to absorb a greater burst of packets and to reuse the memory space. Designers who favor this approach are supporters of having routers with large queuing buffers establishing their own QOS policy.
The term most commonly used to describe this method is memory allocation dynamic (MAD). While the logic of implementing MAD seems fairly simple, it is actually relatively complex because the queue length status must be taken into consideration when scheduling turns allocate bandwidth based on the deficit counter and credit state. An additional algorithm is required to reallocate buffers for the queues currently not transmitting to add entries to those queues.
Figure 8.7 illustrates how MAD operates. Queue zero (Q0) contains no entries, while Q1 and Q2 are approaching a trail-drop situation because these buffers are close to overflowing. The extra scheduling (bandwidth) cycles and buffer space help the queues when they are highly saturated.

Figure 8.7 Dynamic buffer allocation example
It is worth noting that some designers do not like being able to share both buffer space and bandwidth, because the delay obviously cannot be predicted. The most common design is to allocate a queue for a BE traffic type class, thereby offering the ability to get more buffering space in case of need, but to have a more traditional static buffer length for expedited-forwarding traffic class as a way to keep the delay values below a strict margin.
8.4 RED
Throughout this book, we have highlighted the applicability of RED and weighted RED (WRED) for TCP flows and as a way to differentiate between different traffic types inside a queue. Let us now dive into the concepts behind RED and its variations. Queuing and scheduling handle bandwidth and buffering once congestion exists. Once packets are in the queue, they are either transmitted after spending some time in the queue or are aged out and dropped because the queue has no scheduling cycles. But what about dropping a packet before it enters a queue or dropping a packet in the queue before it gets aged out? What congestion avoidance tools are available? There are two main traffic congestion avoidance tools, policers, which have been described earlier in Chapter 6, and RED.
As described earlier, policing can be “hard” (i.e., packets are dropped if traffic exceeds a certain rate) or “soft” (packets are remarked if traffic exceeds a certain rate). Hard policing can ensure that delay-sensitive traffic entering at the edge of the network does not exceed the rate supported across the core. It can also be used to rate-limit BE traffic that is being transmitted into the network maliciously, for example, during an ICMP attack. And policing can be used with RED. So what is this RED?
RED is a tool that provides the ability to discard packets before a queue becomes full. That is, RED can drop packets in the queue before the congestion becomes excessive, before packets are aged because the queue is overflowing, and hence before traffic stalls. Floyd and Jacobson [1] first proposed RED in 1993 in their paper Random Early Detection Gateways for Congestion Avoidance. The idea behind RED is to provide feedback as quickly as possible to responsive flows and sessions, which in reality means TCP-based sessions. The thinking behind RED is to flirt with a TCP congestion avoidance mechanism that kicks in when duplicate ACKs are received, acting by decreasing the congestion window (CWND). The packet drops are not session related; rather, they are distributed more fairly across all sessions. Of course, when a session has more packets in the buffer, it has a greater chance of being exposed to drops than lower-volume sessions.
Let’s first examine the default queue behavior, tail drop. A queue has a specific length, which can be translated into how many packets it can accommodate. When a packet arrives to be put into the queue, it is either dropped if the queue is full or stored in the queue. This behavior is somewhat analogous to a prefix-limiting policy that can be applied to any routing protocol, in which new routes are accepted until a limit is reached, and then no new routes are accepted.
In Figure 8.8, the vertical axis represents a drop probability, and the horizontal axis represents the queue fill level, and both parameters can range from 0 to 100%. As illustrated here, the drop probability is always 0% unless the queue is full, in which case the probability jumps straight to 100%, meaning that once the queue is full, all packets are dropped. This standard tail-drop behavior makes sense: why drop a packet if the queue has room to store it?

Figure 8.8 Tail-drop behavior
RED allows the standard tail-drop behavior to be changed so that a packet can be dropped even if the queue is not full (see Figure 8.9). It sounds somewhat bizarre that the queue can store the packet but that the incoming packet can still be dropped.

Figure 8.9 RED drops
Two scenarios can justify this behavior. The first, present with TCP sessions, is a phenomenon called the TCP synchronization issue, in which massive traffic loss triggers the TCP back-off mechanism. As a result, sessions enter the initial state of TCP slow start, and they all start to ramp up their congestion windows simultaneously. The second scenario occurs when different types of traffic share the same queue and differentiating between the traffic types is necessary.
8.5 Using RED with TCP Sessions
As discussed earlier, TCP protocols have the concept of rate optimization windows, such as congestion windows and receiving windows, which can be translated into the volume of traffic that can be transmitted or received before the sender has to wait to receive an acknowledgment. Once an acknowledgment is received, data equal to the window size accepted on the receiver’s and the sender’s congestion windows, minus the still unacknowledged data, can be transmitted. The details of the TCP session’s behavior are detailed in Chapter 4.
But let us recap briefly: the source and destination always try to have the biggest window size possible to improve the efficiency of the communication. The session starts with a conservative window size and progressively tries to increase it. However, if traffic is lost, the size of the sender’s and receiver’s congestion windows is reduced, and traffic whose receipt was not acknowledged is retransmitted. The window size reduction is controlled by the TCP back-off mechanism, and the reduction is proportional to the amount of the loss, with a bigger loss leading to a more aggressive reduction in the window size. A severe traffic loss with timeouts causes the window size to revert to its original value and triggers a TCP slow-start stage (Figure 8.10).

Figure 8.10 TCP congestion mechanism
The question is, how can RED usage improve this behavior? First, let us identify the problem clearly: massive traffic loss leads to a drastic reduction in window size. When is traffic loss massive? When the queue is full.
All active TCP sessions simultaneously implement their TCP back-off algorithms, lowering their congestion window sizes and reducing the volume of offered traffic, thus mitigating the congestion. Because all the sessions then start to increase their congestion window sizes roughly in unison, a congestion point is again reached, and all the sessions again implement the back-off algorithm, thus entering a loop situation between both states. This symptom is most often referred as TCP synchronization.
In this situation, RED can be used to start discarding traffic in a progressive manner before the queue becomes full. Assume that as the queue reaches a fill level close to 100%, a drop probability of X% is defined. This translates into “The queue is close to getting full, so out of 100 packets, drop X.” Thus, before reaching the stage in which the queue is full and massive amounts of traffic start to be dropped, we start to discard some packets. This process provides time to allow the TCP sessions to adjust their congestion window sizes instead of reverting to their initial congestion window sizes to the slow-start stage value.
That’s the theory. But does RED work? There has been a debate about how useful RED has been in modern networks. The original idea design by Floyd and Jacobson [1] focused on long-lived TCP sessions. For example, a typical file transfer, such as an FTP session, reacts by lowering the congestion window size when it receives three or more duplicate ACKs. Users are rarely aware of the event unless the session enters the slow-start phase or stalls. But the explosion of HTTP has surfaced questions about how RED can affect short-lived sessions. A web session often just resends packets after a timeout to avoid having the end user think that there were service problems or having them just click more on the web page.
It is worth discussing some basics at this point. First, for RED to be effective and keep the congestion window within acceptable limits, sessions must be long lasting. That is, they need to be active long enough to build up a true congestion window. By simply dropping sessions with limited congestion windows in response to HTTP continuation packets, RED probably cannot be effective with regard to tweaking the TCP congestion mechanism. Sessions must have a fair number of packets in the buffer. The more packets a specific session has in the buffer when the congestion is large, the greater the chance that the session experiences drops. Second, modern TCP stacks are actually very tolerant to drops. Features such as selective acknowledgment (SACK), fast retransmit, and fast recovery allow a session to recover very quickly from a few drops by triggering retransmission and rapidly building up the congestion window again.
The trend now is toward long-lasting sessions, which are used commonly for downloading streamed media, “webcasting,” and point-to-point (P2P) file sharing. At the same time, current TCP stacks can take some beating for a short period without significantly slowing down other sessions. To ramp down sessions, either many sessions must be competing, thus preventing any buildup of congestion windows, or the RED profiles must be very aggressive and kick in relatively early before congestion builds up in the queue. If the “sessions” were UDP based, RED would not be effective at all except possibly to shape the traffic volume, which is likely outside the original RED design. If RED profiles just provide alternate profiles for handling how long such packets can stay in the buffer, RED can be used for UDP traffic by applying several tail-drop lengths. But again, this use does not follow the original definition of RED.
8.6 Differentiating Traffic inside a Queue with WRED
When different types of traffic share the same queue, it is sometimes necessary to differentiate between them, as discussed in Chapters 2 and 3. Here, one method used frequently is WRED. WRED is no different than applying different RED profiles for each code point (see Figure 8.11).

Figure 8.11 Multiple RED drop levels in the same queue
To provide a concrete scenario, suppose in-contract and out-of-contract traffic are queued together. While queuing out-of-contract traffic can be acceptable (depending on the service agreement), what is not acceptable is for out-of-contract traffic to have access to queuing resources at the expense of dropping in-contract traffic. Avoiding improper resource allocation can be done by applying an aggressive RED profile to out-of-contract traffic, which ensures that while the queue fill level is low, both in-contract and out-of-contract traffic have access to the same resources. However, when the queue fill level increases beyond a certain point, queuing resources are reserved for in-contract traffic and out-of-contract traffic is dropped. Figure 8.12 illustrates this design for an architecture that drops packets from the head of the queue.

Figure 8.12 Aggressive RED drop levels for out-of-contract traffic
In effect, this design creates two queues in the same physical queue. In this example, packets that match profile 1, which are marked with a dark color, are likely to be dropped by RED when they enter the queue, and they are all dropped when queue buffer utilization exceeds 50%. Packets matching profile 2, which are shown as white, have a roller-coaster ride until the queue is 50% full, at which point RED starts to drop white packets as well.
The classification of out-of-contract packets can be based on a multifield (MF) classifier or can be set as part of a behavior aggregate (BA). For example, the service of a BE service queue is lower than that for best-effort (LBE). If ingress traffic exceeds a certain rate, the classification changes the code point from BE to LBE, effectively applying a more aggressive RED profile. Typically, in-contract and out-of-contract traffic share the same queue, because using a different queue for each may cause packet-reordering issues at the destination. Even if RED design mostly focuses on TCP, which has mechanism to handle possible packet reordering, having the two types of traffic use different queues can cause unwanted volumes of retransmissions and unwanted amounts of delay, jitter, and buffering on the destination node.
An alternative design for having multiple traffic profiles in the same queue is to move traffic to another queue when the rate exceeds a certain traffic volume. The most common scenario for this design is the one discussed earlier, in which badly behaved BE traffic is classified as LBE. This design, of course, has both benefits and limitations. The benefits are that less complex RED profiles are needed for the queue and that the buffer for BE in-contract traffic can use the entire length of the buffer. The limitations are that more queues are needed and thus the available buffer space is shared with more queues and that traffic can be severely reordered and jitter increased compare with having the traffic in the same physical buffer, resulting in more retransmissions. Current end-user TCP stacks can reorder packets into the proper order without much impact on resources, but this is not possible for UDP packets. So, applying RED profiles to UDP is a poor design.
8.7 Head versus Tail RED
While the specifics of the RED operation depends on the platform and the vendor, there are two general types that are worth describing: head and tail RED. The difference between them is where the RED operation happens, at the head of the queue or at the tail. As with most things, there are upsides and downsides to both implementations. Before discussing this, it is important to note that head and tail RED have nothing to do with queue tail drops or packet aging (queue head drops) described in earlier chapters. RED drops occur independently of any queue drops because either the buffer is full or packets are about to be aged out.
With head RED, all packets are queued, and when a packet reaches the head of the queue, a decision is made about whether to drop it. The downside is that packets dropped by head RED are placed in the queue and travel through it and are dropped only when they reach the head of the queue.
Tail RED exhibits the opposite behavior. The packet is inspected at the tail of the queue, where the decision to drop it is made. Packets marked by tail RED are never queued. The implementation of the RED algorithm for both head and tail RED is not very different. Both monitor the queue depth, and both decide whether to drop packets and at what rate to drop them. The difference between the two is how they behave.
Head-based RED is good for using high-speed links efficiently because RED is applied to packets in the queue. Utilization of the link and its buffer are thereby maximized, and short bursts can be handled easily without the possibility of dropping packets. On low-speed links, head-based RED has drawbacks because packets that are selected to be dropped are in the way of packets that are not being dropped. This head-of-line blocking situation means that packets not selected to be dropped must stay in the queue longer, a situation that might affect the available queue depth and might result in unintended packets being dropped. To avoid this situation, the RED profiles in the same queue need to be considerably different to effect more aggressive behavior (see Figure 8.13).

Figure 8.13 Head-based RED
On the other hand, tail-based RED monitors the queue depth and calculates the average queue length of the stream inbound to the queue. Tail-based RED is good for low-speed links because it avoids the head-of-line blocking situation. However, packet dropping can be too aggressive, with the result that the link and buffer might not be fully utilized. To avoid RED being too aggressive, profiles must be configured to allow something of a burst before starting to drop packets (see Figure 8.14).

Figure 8.14 Tail-based RED
One more academic reason also favors head-based RED over tail-based RED: in congestion scenarios, the destination is made aware of the problem sooner, following the maxim that bad news should travel fast. Consider the scenario in Figure 8.15.

Figure 8.15 Bad news should travel fast
In Figure 8.15, assume congestion is occurring and packets need to be dropped. Head RED operates at the queue head, so it drops P1, immediately making the destination aware of the congestion because P1 never arrives. Tail RED operates at the queue’s tail, so when congestion occurs, it stops packet P5 from being placed in the queue and drops it. So the destination receives P1, P2, P3, and P4, and only when P5 is missed is the destination made aware of congestion. Assuming a queue length of 200 ms as in this example, the difference is that the destination is made aware of congestion 200 ms sooner with head RED. For modern TCP-based traffic with more intelligent retransmission features, this problem is more academic in nature. The receiver triggers, for example, SACK feedback in the ACK messages to inform the sender about the missing segment. This makes TCP implementations less sensitive to segment reordering.
8.8 Segmented and Interpolated RED Profiles
A RED profile consists of a list of pairs, where each pair consists of a queue fill level and the associated drop probability. On an X–Y axis, each pair is represented by a single point. Segmented and interpolated RED are two different methods for connecting the dots (see Figure 8.16). However, both share the same basic principle of operation: first, calculate an average queue length, and then generate a drop probability factor.

Figure 8.16 Interpolated and segmented RED profiles
Segmented RED profiles assume that the drop probability remains unchanged from the fill level at which it was defined, right up to the fill level at which a different drop probability is specified. The result is a stepped behavior.
The design of interpolated RED profiles is based on exponential weight to dynamically create a drop probability curve. Because implementations of RED are, like most things with QOS, vendor specific, different configurations are needed to arrive at the same drop probability X based on the average queue length Y.
One implementation example creates the drop probability based on the input of a minimum and a maximum threshold. Once the maximum threshold is reached, the tail-drop rate is defined by a probability weight. Thus, the drop curve is generated based on the average queue length (see Figure 8.17).

Figure 8.17 Interpolated RED drop curve example 1
A variation of this implementation is to replace the weight with averages that are computed as percentages of discards or drops compared with average queue lengths (see Figure 8.18).

Figure 8.18 Interpolated RED drop curve example 2
What is the best approach? Well, it is all about being able to generate a configuration that performs with predicted behavior while at same time being flexible enough to change in case new demands arise.
Extrapolating this theoretical exercise to real life, it is the case that most implementations have restrictions. Even if you have an interpolated design with generated exponential length and drop values, there are limitations on the ranges of measured points. For example, there is always a limit on the number of status ranges of elements or dots, 8, 16, 32, or 64, depending on the vendor implementation and hardware capabilities. Also, there are always rounding and averages involved in the delta status used to generate the discards as compared with the queue length ratio.
In a nutshell, there are limited proofs to show any differences between segmented and interpolate implementations. In the end, what is more important is to be able to configure several profiles that apply to different traffic control scenarios and that can be implemented on several queues or on the same queue.
8.9 Conclusion
So, does RED work in today’s networks? The original version of RED was designed with an eye on long-lasting TCP sessions, for example, file transfers. By dropping packets randomly, RED would provide hosts with the opportunity to lower the CWND when they received duplicate ACKs. With the explosion of web surfing, there has been an increase in the number of short-lived sessions. RED is not very efficient for these short web transactions, because a web session often just resends packets after a timeout as congestion mechanism. But also, as discussed in Chapter 4, with the recent file sharing and downloading of streamed media, long-lasting sessions have returned to some extent. So is RED useful now? The answer is probably yes, but a weak yes.
The value of using RED profiles for TCP flows is questionable in environments that use the latest TCP implementations, in which the TCP stacks are able to take a considerable beating, as described in Chapter 4. Features such as SACK, which in each ACK message can provide pointers to specific lost segments, help TCP sessions maintain a high rate of delivery, thus greatly reducing the need for massive amounts of retransmission if a single segment arrives out of order. The result is that any RED drop levels need to be aggressive to slow down a single host; that is, dropping one segment is not enough.
Because RED is not aware of sessions, it cannot punish individual “bad guys” that ramp up the CWND and rate and that take bandwidth from others. The whole design idea behind RED is that many packets need to be in the queue belonging to certain sessions, thereby increasing the chance of dropping packets for these bandwidth-greedy sessions.
However, RED is still a very powerful tool for differentiating between different traffic types inside the queue itself, for example, if packets have different DSCP markings.
Reference
- [1] Floyd, S. and Jacobson, V. (1993) Random Early Detection Gateways for Congestion Avoidance. Berkeley, CA: Lawrence Berkeley Laboratory, University of California.
Further Reading
- Borden, M. and Firoiu, V. (2000) A Study of Active Queue Management for Congestion Control, IEEE Infocom 2000, Tel Aviv-Yafo, Israel.
- Croll, A. and Packman, E. (2000) Managing Bandwidth: Deploy QOS in Enterprise Networks. Upper Saddle River, NJ: Prentice Hall.
- Goralski, W. (2010) JUNOS Internet Software Configuration Guide: “Class of Service Configuration Guide,” Release 10.1, Published 2010. www.juniper.net (accessed August 18, 2015).
- Heinanen, J., Baker, F., Weiss, W. and Wroclawski, J. (1999) RFC 2597, Assured Forwarding PHB Group, June 1999. https://tools.ietf.org/html/rfc2597 (accessed August 18, 2015).
- Jacobson, V., Nichols, K. and Poduri, K. (1999) RFC 2598, An Expedited Forwarding PHB, June 1999. https://tools.ietf.org/html/rfc2598 (accessed August 18, 2015).
- Nichols, K., Blake, S., Baker, F. and Black, D. (1998) RFC 2474, Definition of the Differentiated Services Field, December 1998. https://tools.ietf.org/html/rfc2474 (accessed August 18, 2015).
- Postel, J. (1981) RFC 793, Transmission Control Protocol—DARPA Internet Protocol Specification, September 1981. https://tools.ietf.org/rfc/rfc793.txt (accessed August 18, 2015).
- Semeria, C. (2002) Supporting Differentiated Service Classes: Active Queue Memory Management, White Paper. Sunnyvale, CA: Juniper Networks, Inc.
- Stevens, R. (1994) TCP Illustrated, Vol. 1: The Protocols. Upper Saddle River, NJ: Addison-Wesley.
- Zang, H. (1998) Models and Algorithms for Hierarchical Resource Management. Pittsburgh, PA: School of Computer Science, Carnegie Mellon University.