
Chapter 7
Developing for the Cloud
EXAM AZ-303 OBJECTIVES COVERED IN THIS CHAPTER:
- Implement Management and Security Solutions
- Manage security for applications
- Implement Solutions for Apps
- Implement an application infrastructure
EXAM AZ-304 OBJECTIVES COVERED IN THIS CHAPTER:
- Design Identity and Security
- Design authentication
- Design security for applications
- Design Business Continuity
- Design for high availability
- Design Infrastructure
- Design an application architecture
- Design a compute solution
- Design Data Storage
- Design a solution for databases
At the start of Chapter 5, I told you to take for granted that you have an application. That application could be a simple snippet of code or a complicated enterprise system that uses inheritance, interfaces, and third-party functional libraries. No matter how well you designed, implemented, and configured the security, networking, compute, and data stores, if your code is bad, the other components don't matter so much. Well, from a security perspective, that's not 100% true, because security always matters, but I think you get what I am trying to say here. In short, there are coding patterns that you can follow that will increase the probability of success in the cloud. This chapter shares some of those patterns and provides some coding examples. It also covers IDEs, source code repositories, and more about coding for security.
Don't expect many, if any, questions about coding on the exam. This chapter is present more for making you the best Azure Solutions Architect Expert than it is for helping you prepare for the exam. As Ian Stewart once said, “There are 10 kinds of people in the world: those who understand binary numerals and those who don't.” In this chapter, you will learn some coding patterns and tools for creating and managing source code.
Architectural Styles, Principles, and Patterns
In this section, you will find information about the following topics:
- Architectural styles
- Design principles
- Cloud design patterns
Patterns have been called out in a few chapters in various phases of IT solution design and configuration.
- Architectural styles such as multitiered applications
- Enterprise data warehouse (EDW) designs such as snowflake and star schemas
- Design principles such as partitioning
There are design patterns that should be implemented into your code when running in the cloud. This chapter provides guidelines and suggestions for implementing all the best-practice styles, principles, and patterns into the solutions that you plan on moving or creating on the Azure platform.
Architectural Styles
The most common or traditional architecture style is called multitiered (aka n-tier), which is illustrated in Figure 7.1. In this design, you will see the existence of a client that connects to a web server, which is one of the tiers. The web server then can make connections to an application server and/or a database server.
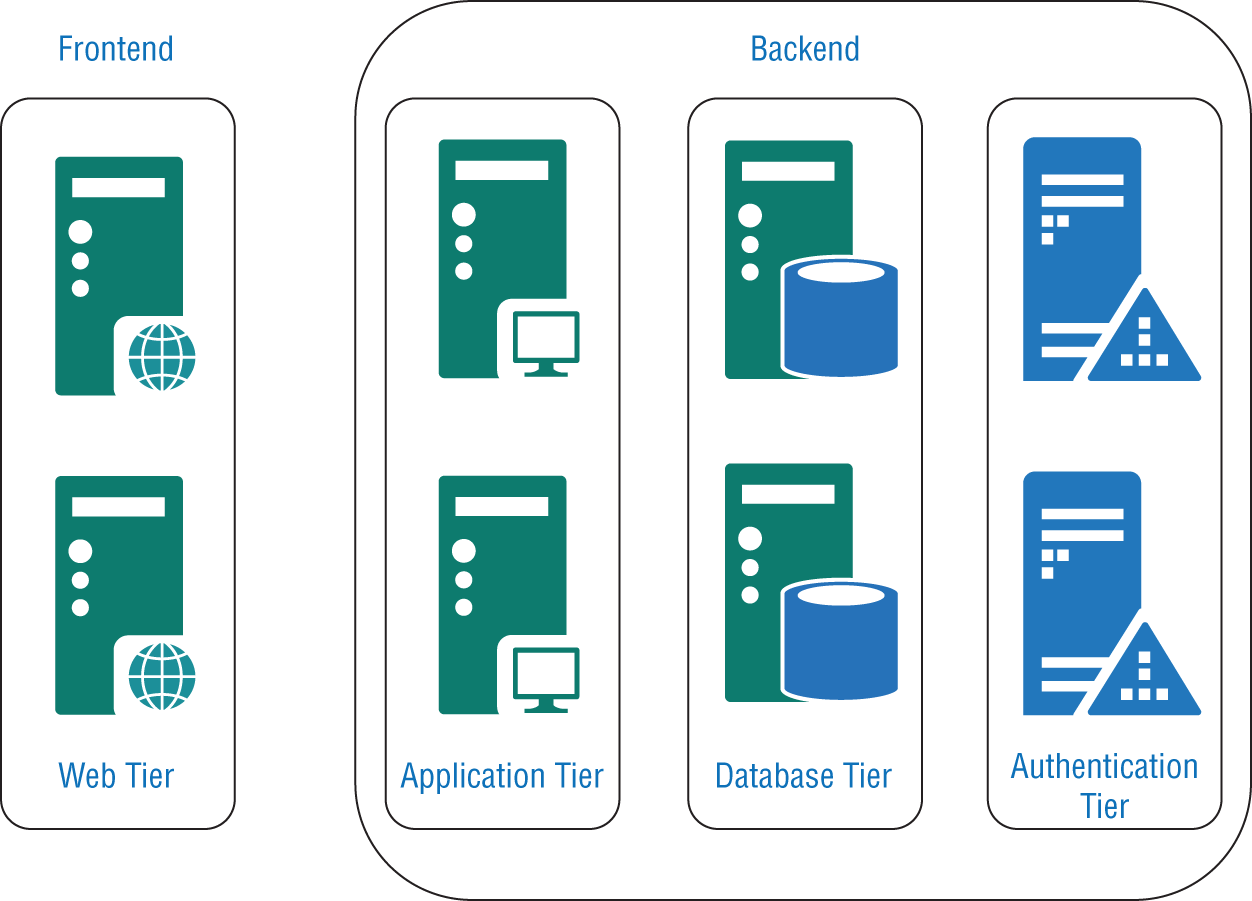
FIGURE 7.1 A multitiered architecture
Table 7.1 lists some of the other common architectural styles.
TABLE 7.1 Azure Architecture Styles
| Architectural Style | Description | Azure Product |
|---|---|---|
| Multitiered (n-tier) | A division of application roles by physical machines | Azure Virtual Machines |
| Big Data | Unstructured data collection and analysis | Azure Cosmos DB Azure Synapse Analytics Data Lake Analytics |
| Microservices | A division of business logic by service exposed via an API | Service Fabric Azure Kubernetes Service (AKS) |
| Web-queue-worker | Decoupling of IT solutions using a messaging queue | Service Bus Azure Storage Queue |
| Event-driven | Producers create data; consumers receive and process it | Event Hub Event Grid |
| Big Compute | Data analysis that requires great amounts of memory or CPU | Azure Batch (aka HPC) Azure Virtual Machines |
| Workflow management | Automate business processes with your current IT applications | Logic Apps |
| Serverless computing | An event-triggered compute model without the need to provision machines | Azure Functions |
| Web applications | Applications that are accessible via the internet that work with the HTTP and HTTPS protocol | Azure App Service |
The following is a list of figures in the book that can provide more context about these styles:
Multitiered (n-tier): Figures 4-19 and 4-57
Big Data: Figure 5-8
Microservices: Figures 4-58 and 4-60
Web-queue-worker: Figure 6-24
Event-driven: Figures 4-4, 6-20, and 6-30
Big Compute: Figures 4-48 to 4-52
There are many more architectural styles not mentioned here. The ones provided here are the most common. As the concept of a hybrid model is not an unfamiliar term for you, using bits and pieces of each style to build the one you require is by all means a valid approach. Keep in mind that these styles are best-practice recommendations. If you choose to take your own path, great, but recognize that it comes at a risk. Following best-practice recommendations is the path that leads you toward success.
Design Principles
When designing your solution on the Azure platform or in any data center, there are some guiding principles to align with during this design phase. They are provided in the following list and discussed afterward in more detail:
- Redundancy, resiliency, and reliance
- Self and automatic healing
- Scaling and decoupling
- Use SaaS, PaaS, and IaaS, in that order
- Design for change
The list is ordered based on the relevance and impact they have on running workloads successfully on the Azure platform.
Redundancy, Resiliency, and Reliance
These three concepts shouldn't be new to you now. Take a moment to go over them in your head and then see whether what you have learned so far matches the descriptions that follow:
- Redundancy Redundancy has to do with having multiple copies of your system configurations, source code, and data in many places. This is important in the case of mid- to long-term outages and, in some cases, helpful in recovery in the case of permanent data loss. To implement redundancies in Azure, concepts such as Availability Zones, fault and update domains, failover database instances and ZRS and GRS storage options should all be considered.
- Resiliency Resiliency has to do with the next section that discusses recovering from transient issues automatically. How well does your application respond and recover from failures? One pattern discussed later, the Retry pattern, will wait for a few seconds if an error is received when attempting to execute code and then try it again. That is a much more resilient experience than simply throwing an exception stating, “Something unexpected happened; please try again later.”
- Reliance The experiences users, customers, employees, or clients have with the application determine how much they can rely on the system. If they lose faith in it, meaning they don't know if the system will be working or not when they need it, you have failed in making the system resilient because it is not reliable. Reliance is the outcome of a system that is resilient and redundant.
Self and Automatic Healing
The components used in the cloud are commoditized. Their lifespan may not be what you would expect from a trademarked brand of computer components. When a commoditized memory module, for example, fails, it is simply replaced instead of trying to find out why it failed and fixing it. Simply replacing it is much faster than performing root-cause analysis and fixing it, and the latter really isn't possible at cloud speed anyway. When there is a failure of a hardware component, there will be a disruption. How large of a disruption is dependent on how heavily your application depends on the component that failed. Regardless, you need to place code into your applications to manage these kinds of short disruptions. Making sure that your transactions are ACID compliant (atomic, consistent, isolated, and durable) will help your application respond better in these situations.
If your software fails for some reason, make sure to catch the exception. This results in a handled exception and provides an interface for responding and retrying the execution. If you do not catch exceptions and one happens (an unhandled exception), it has the likelihood of crashing the process. When a process such as
W3WP.exe
crashes, it is possible that it will not be respawned automatically. It may require a reboot or manual restart to get all the bits realigned. There are platform features on Azure that monitor the health of the operating system and sometimes the application itself. When the OS or application appears to be unhealthy, the platform monitor may trigger a reimage of the VM on which your application is (or was) running. Simply, your application must be able to handle sudden stoppages in the execution of your transactions. It will happen, and if you don't manage it, your application will not be reliant!
Scaling and Decoupling
One of the primary features in the cloud and on Azure is the ability to provision and scale on demand. You can use large amounts of compute when required and then deallocate the computer when the demand diminishes. Your application needs to be able to work in that scenario, for example, if your web application requires state to be maintained throughout an operation. When a customer is placing an order online, then the process is usually fulfilled across numerous pages and numerous steps. Do any of these steps store some of the information on the server? If yes, then you need to make sure requests are sent back to the same server each time if you have multiple servers running. This can be achieved by a context called client affinity or sticky sessions. Those simply make sure that once a session is started on a specific server, all additional requests route to the same server for that session. There are scenarios in which your scaling is automated and will scale in or out the number of instances your workload is consuming. However, there is some built-in intelligence that waits some time before reimaging and returning the VM to the pool. Long-running tasks, like a WebJob, a batch job, or a background job, might get shut down in midprocess. You need to code for that by perhaps having some startup logic in the background job to check that everything is OK before proceeding with normal operations. The logic is application-specific. Making sure everything is OK could be as simple as having a processing status column on a row in a database and checking that status at startup. If the status shows “in process” for a long period, the code likely failed, and the data needs reprocessing.
The next topic discussed in this section covers decoupling and has a lot to do with the messaging services discussed in Chapter 6. It also has to do with removing long-running or resource-intensive jobs like a WebJob, batch job, or another background job to an offline service. For example, the multitiered (n-tiered) architecture style is a tightly coupled process. In that scenario, the client would wait for the request to the web server to flow through the application server and to the database server and then back before proceeding further. One of the problems with that architecture is that a successful response is dependent on the availability of all three of those tiers. If you could somehow decouple that flow by implementing the web-queue-worker model, then a request from a client wouldn't be dependent on the availability and resiliency of many systems. Your application would appear more reliant.
Use SaaS, PaaS, and IaaS, in That Order
You would likely agree that the fewer tasks you are directly responsible for, the higher probability of being successful in the areas where your responsibilities increase. In other words, if you can focus your efforts more directly on what you feel is the most important and be successful at those few things, then overall you will be more successful. If you can offload the management of your network infrastructure, the configuration, and the maintenance of your computer hardware, as well as the administration of the operating system, then by all means do that. If all you need is the product, then take that one too. The point is, if you can run your workload on PaaS, choose that one over IaaS. There is less to worry about. In reality, if you are like me, you can always find things to worry about. Even if you have only two tasks, not having to worry about network, hardware, and operating system administration is great. Then you can worry about just the important aspects of your work.
Design for Change
Things change, and sometimes they change fast. Can you recall any mention of the cloud five or ten years ago? Think about where we were then and what we have now. Designing for change is focused on, but not limited to, factors such as decoupling, asynchronous models, and microservice/serverless concepts. In short, the more you can isolate a specific piece of logic from the whole, the easier it is to change. Recall the discussion about NoSQL databases like Azure Cosmos DB and how quickly you can get a container to store data into it. Contrast that with a relational database where the tables and columns have an applied meaning, and the changes would likely have greater impact. When compared to a nonrelational data source, making a change to a relational model is possible, but it would take much longer and require much more application knowledge.
Cloud Design Patterns
From a coding perspective, there are many patterns that are worthy of a book on their own. Therefore, only five patterns will be discussed in detail. These five have the most impact when running your workloads on Azure:
- Retry
- Gatekeeper
- Throttling
- Sharding
- Circuit Breaker
Some additional coding patterns worthy of honorable mention are Health Endpoint Monitoring, Bulkhead, Valet Key, and Command and Query Responsibility Segregation (CQRS). If any of those trigger any interest, search for information online. There is a plethora of information available.
Retry
The Retry pattern is probably the most important one to implement. You can implement the pattern in all code running on all kinds of platforms, but it is of additional importance when the code is running in the cloud. This is because of the higher probability of transient faults. Historically, there have been patterns that recommend catching exceptions using a code snippet like the following:
try{ …}catch (Exception ex){…}
The interesting fact about this pattern is that in many cases there is no coded logic added inside the
catch
expression to perform any kind of recovery activity. I cannot explain this behavior; however, I review a lot of code, and this is the scenario I see often. The more sophisticated applications do at least log the
ex.Message
that is included in the
Exception
and maybe provide it back to the client that triggered the transaction, but nothing more. When running in the cloud, transient faults may happen more often when compared to running on-premise, trademarked hardware. Here, you should now implement some code within the
catch
expression to retry the transactions that triggered the exception. You need to define a retry policy that describes the scenario in which a retry should happen and the actions to take on retry.
The
Exception
defined in the previous code snippet is considered a catchall exception; however, there are numerous kinds of exceptions. This is not the place to cover all the possible exceptions. One that can be called out is an
HttpRequestException
. This kind of exception is one that could be successful if you were to try it again after waiting a few seconds. Some pseudocode that defines how a retry would look is shown here:
catch (HttpRequestException ex){writeLog($"This exception happened {ex.Message}")if currentRetryCount < allowedRetryCount && IsTransient(ex)await Task.Delay(5000)theMethodWhichFailed()}
The retry policy applied in the previous code snippet requires that:
- The exception be logged
- The retry happen only a specific number of times
- The retry validate the exception to confirm it may be transient
- The retry wait for five seconds and then recall the method again
The example provided here was one that would occur when using the
System.Net.Http.HttpClient
class. When you use Azure product-specific SDKs for communicating with, for example, AAD, Azure Storage, or Cosmos DB, the SDKs typically have built-in retry capabilities. For a list of products that have built-in retry capabilities, take a look at https://docs.microsoft.com/en-us/azure/architecture/best-practices/retry-service-specific
Gatekeeper
It makes a lot of sense to name things that perform the action it actually performs. The Gatekeeper pattern does exactly as the name implies, like an orchestrator orchestrates and like a programmer inherits attributes from a parent class. A gatekeeper monitors an entry point to some service and makes sure that only those who should have access to it actually do. The location of the gatekeeper is in front of the resource that it protects so that unauthorized entities attempting to access it can be denied access before they are inside or close to being inside. (If it had been up to me, I would have named this Bouncer, which seems a bit cooler, but I guess Gatekeeper is acceptable.)
There are many Azure resources that have a global endpoint that in the given scenario is already too close to the protected resource for comfort. The measurement of “too close” depends greatly on the sensitivity and criticality of the data and application. However, let's assume doing authentication on a service that runs in full trust mode is, for you, too much of a risk. You may know that when you have a process (like
W3WP.exe
) running on an operating system, it runs within the context of an identity. Some identities have full access, while other custom identities may have restricted access only to the specific resources required to do a job. In reality, the latter is hard to do, but the most common scenario is somewhere in between with a tendency to provide too much privilege. Therefore, if for some reason the entry point at your front door is compromised, then full access to the house is a relative certainty. It's interesting that I used “front door” there because there is an Azure product named Azure Front Door that can be used to protect endpoints from an architectural perspective. You may be thinking, well, what about service endpoints, NSGs, and IP restrictions? You can achieve the Gatekeeper pattern by using Azure Firewall, a service endpoint, and some other Azure products. As illustrated in Figure 7.2, any Azure product or feature that can act as a firewall is an option for implementing this pattern.

FIGURE 7.2 Gatekeeper design pattern
IP restrictions and NSGs (default Azure VM configurations) are typically configured on the resource themselves, which negates the purpose of the pattern. The purpose is to keep the tier that exposes a public endpoint separate from the tier that runs the sensitive or mission-critical processing.
Throttling
There is an HTTPS status code that exists just for this scenario; it's a status code of 429 and means Too Many Requests. This is usually handled by some custom code or third-party application that is monitoring the number of requests to a website for a specific period of time. What throttling does is limit the number of requests or amount of compute resources for a given time period. In Internet Information Services (IIS), it is possible to restrict the amount of consumed CPU for a given time frame. When the threshold is breached, any requests going to that specific process are not processed and instead return an error. This kind of setting can also be useful in a distributed denial-of-service (DDoS) scenario (intentional or not) where a large number of requests are coming from a specific IP address. The feature is called Dynamic IP Restrictions (DIPR), and it counts the number of concurrent connections or the number of total connection in a given time frame from the same IP address. When that restriction is breached, DIPR no longer allows access from that IP address for a configurable amount of time. Throttling is an important pattern that needs some attention, not only preventing it when it happens to your system but also preventing your system from inadvertently doing it to another system.
Sharding
Sharding was covered in many data storage scenarios in Chapter 5. The concept of sharding is the division of large sets of data into smaller, logically structured subsets. Review Figure 5.14 and Figure 5.15, which demonstrate examples of horizontal and vertical sharding. Horizontal sharding may break the data into rows depending on the alphabetical order of the row key. If you know there is an actual division of load across data starting and ending with A–K, L–P, and Q–Z, then it would make sense to configure three horizontal shards to improve performance and stability. On the other hand, if you see no pattern of such data access but instead notice there are three or four columns on each row that are retrieved much more frequently than the others, you can consider a vertical shard and separate the data structure into data columns that are accessed frequently versus a shard with columns that are not accessed as often.
Circuit Breaker
I was trimming my hedges once with an electric trimmer, and somehow the cord got between the blades and the leaves and—boom—it got cut, and the electricity shut off. To get the electricity flowing again, I had to switch the circuit back on. Had the circuit breaker not reacted, there would have been electricity flowing out the end of the electric cord causing damage but effectively doing nothing. When the circuit broke, it automatically caused the stoppage of electricity flow, which happened in less than a second. The Circuit Breaker pattern from a cloud design pattern operates in the same context. When one of the remote resources or services is not available, then the flow of all communications to them stop. You might be thinking that this is the same as the Retry pattern, and you are right—almost. The difference here is that you are certain that the resource or service your application is remotely connecting to is unavailable, and you have no idea when it will be back online. In this scenario, it doesn't make as much sense to retry. In the trimmer scenario, I knew something happened, and I knew trying to use the trimmer wouldn't work, so it was worthless to try. The outage took some time to resolve as I traversed down into the basement and found the switch needing administration. It took about 10 minutes; imagine how many exceptions your application would throw if your IT processes 100 or more transactions per second. Also, imagine how those using the application would feel getting the exceptions over and over again. They would think your system is unreliable. You could make the application more resilient by implementing the Circuit Breaker pattern.
A method for implementing a circuit breaker is to monitor the state of the dependent resources or services. For example, perhaps you look at the Closed, Open, and Half-Open states. If the state is Closed, the dependent resources are functional, just like if an electric circuit is closed, it is all flowing as expected, and there are no breaks in the connectivity. If there is a break, then the state changes to Open and requests that the dependent resource stop. In that scenario, you should have code that displays a temporary out-of-service page or routes and stores the transaction details to a temporary location for offline processing when the service comes back online. Half-Open is the state in which the exception has stopped occurring and the resource is likely back online, but it's in the early stages, so you throttle the number of requests you are passing through. After a given threshold based on a configured time frame is breached, the state is set back to Closed and you are back in business.
Antipatterns
When you are coding and designing your application, keep in mind the antipatterns, listed here:
- Superfluous Fetching
- Not Caching
- Synchronous I/O
- Monolithic Persistence
- Improperly Instantiating Objects
The first one, Superfluous Fetching, has to do with a concept called projection. This means you need to have only the columns that perform your task in the
SELECT
clause. You will need a very tight
WHERE
clause, as well. You do not want to retrieve any more data from a data store than is absolutely necessary. The same goes for caching. Don't store more data in a cache than the application needs to run because data loaded into the cache consumes memory. RAM has a cost in the cloud, sometimes a variable one. By all means, cache when you can. Give caching some close analysis and load only the data that is often retrieved from a data source into cache. This not only reduces load on your data store but also decreases the latency of your application since it doesn't have to perform unnecessary queries on the database to retrieve the same data over and over again.
When you are using a library in your programming and there exists asynchronous methods, by all means use them. When you use synchronous methods for performing I/O tasks such as accessing content on a hard disk or performing a task where the thread needs to pause for a response from some service on another server as the thread waits, that thread remains blocked until a response is returned from the I/O task. You must understand that the number of threads a process can generate is finite, and you should take actions where you can to reduce the number of them. Some latency happens when the process needs to create a new thread. When you use asynchronous methods that employ the
async/await
keywords, which make I/O calls, then the thread is not stuck waiting on the response. It is instead reallocated to the thread pool for other tasks to use. Once the I/O function is complete, the thread is pulled from the pool and is used to complete the action. Use asynchronous coding patterns when possible.
Monolithic Persistence has to do with having all your data stored on the same data store regardless of whether the data is related. When possible, you should separate online transactional processing (OLTP) data stores from data stores that contain logging, telemetry, or historical data used for reporting purposes. The reason for this is that OLTP data stores need to be responsive. They could be impacted if a large annual sales report is run against the same data store that orders are placed into. Separating them would likely have a positive impact on performance.
When you make a connection to a database or to a REST API, part of that process is to instantiate a connection object. Running your application on-premise, where you likely have almost unrestricted outbound connections, the most common pattern creates the connection within a
using
statement, like the following:
using (var httpClient = new HttpClient()){…}
This pattern follows a guideline for scoping the use of the
httpClient
object. As soon as the code execution leaves the closing bracket, the
httpClient
is marked for garbage collection. The negative aspect of this is that for every invocation of this code block, an object needs to be instantiated and a new connection made. That implementation is improper and will not scale in the cloud, from a performance perspective, but mostly from a connection perspective. Remember from Chapter 3 there was a discussion about SNAT ports. Recognize that there are rather stringent limitations on the number that you can have concurrently open. The previous pattern where the
httpClient
was instantiated has a high probability of using many SNAT ports under high load. The alternative and recommended best practice creates a static instance in your class and instantiates it in the constructor.
public class CsharpGuitarHttpClientController : ApiController{private static readonly HttpClient httpClient;static CsharpGuitarHttpClientController(){httpClient = new HttpClient();}public async Task<Product> GetTheCoolestGuitarEver(string id){…}}
When you do this, the same connection object is used for all outbound connections to the same server. The pattern is the same when you are making connections to an Azure SQL database, an Azure Cosmos DB, or any system that requires the instantiation of a connection object.
An Introduction to Coding for the Cloud
Throughout the book there have been references to Chapter 7 as the place where you will see how to actually implement some of the concepts. In this section, you will see those examples or get some tips on how to proceed with them. The following examples will be provided:
- Triggering a background job
- Connecting to regional/global database instances
- Working with the Azure Queue Storage SDK
- Using Forms Authentication, certificates, Windows Authentication, MFA, Open Standards, managed identities, and service principle authentication
- Reading encrypted data from a database
Triggering a Background Job
A background job is a snippet of code that typically require high CPU, high memory, or long-running activities. Really, code snippets do anything that takes too long to trigger the background job and then wait for a response in real time. There are two primary ways in which a background job can be triggered: by an event or by a schedule. In the context of a WebJob, for example, an event trigger calls its exposed REST API. As you may recall, WebJobs are background job processors that run in the Azure App Service (PaaS) context. Assume you have an Azure App Service named csharpguitar that has the following endpoint:
csharpguitar.azurewebsites.net
A WebJob can be triggered using a similar endpoint. That endpoint would be similar to the following:
https://csharpguitar.scm.azurewebsites.net/api/triggeredwebjobs/<webjobName>/run
These can be called from a browser manually or from another application that uses the
HttpClient
class. The other option is the use a scheduler like a CRON job that will trigger the execution of a batch job or a WebJob at certain intervals.
Connecting to Regional/Global Database Instances
In Chapter 5 you learned about the global replication capabilities of the Azure Cosmos DB. The question was, how can you make code intelligent enough to connect to the read-only instances closest to the location of the client? A class in the Azure Cosmos DB SDK named
ConnectionPolicy
exposes a property called
PreferredLocations
. Preferred locations are used when creating the client that is used to make the connection to the database. Code within the SDK itself chooses the most optimal location. That is very cool. The snippet of code that achieves this is provided here:
ConnectionPolicy connectionPolicy = new ConnectionPolicy();connectionPolicy.PreferredLocations.Add(LocationNames.SouthCentralUS); connectionPolicy.PreferredLocations.Add(LocationNames.NorthEurope);DocumentClient docClient =new DocumentClient(accountEndPoint, accountKey, connectionPolicy);
Working with the Azure Queue Storage SDK
Some principles that are important to know about Azure Queue Storage are related to these three methods:
PeekMessage()
,
GetMessage()
, and
DeleteMessage()
. These methods, as well as the client code required to utilize them, are downloadable as a NuGet package from here:
www.nuget.org/packages/Microsoft.Azure.Storage.Queue
Installation instructions for Visual Studio are also available at that URL.
The
PeekMessage()
method is called with the following code snippet. Please note that there is code required before and after this snippet to make it work. For example, you must instantiate the storage account, instantiate the storage client, and identify the storage queue. This example/pseudocode is useful only for the explanation of the following implementation concept.
CloudQueueMessage peekedMessage = queue.PeekMessage();
Here is a snippet of code that calls the
GetMessage()
method and its asynchronous alternative
GetMessageAsync()
:
CloudQueueMessage message = queue.GetMessage();CloudQueueMessage retrievedMessage = await queue.GetMessageAsync();
The difference between the
PeekMessage()
and
GetMessage()
methods is that the
GetMessage()
method, when called, blocks the thread and waits until a message arrives in the queue before returning. The thread will be hung in a waiting state, which may not be a huge issue since there wouldn't be any messages to process if the method call had to wait. Nonetheless, it is always good practice to release and not block threads in most, if not all, scenarios.
The benefit that
PeekMessage()
provides is that, when called, it tells you if there is a message in the queue waiting to be processed without blocking the thread or waiting on a message to arrive. Therefore, it is not necessary to call
GetMessage()
unless
PeekMessage()
returns with a status stating there is a message available for processing.
PeekMessage()
does not set any locks on the message and does not modify it in any way.
You may also consider calling the
GetMessageAsync()
method that would release the thread, but it would wait via
await
until there is a message in the queue ready for processing. Which process to use is up to the application requirements. One thing to note about using asynchronous methods is that all methods that include the
await
keyword must be asynchronous themselves (all the way up). It is not recommended to ever call
Result()
or
Wait()
in the async classes. This can cause serious blocking and hangs.
After one of the get message methods is called from your application, you need to call
DeleteMessage()
so that the queue knows the message has been processed. Notice that there is also an asynchronous version of this method and that it doesn't return a value; it will, however, return a catchable exception if the deletion fails.
queue.DeleteMessage(retrievedMessage);await queue.DeleteMessageAsync(retrievedMessage);
If there is an exception in your code and the message is not processed, then at some point the message would become unlocked and available for processing once again. The only way in which the queue knows that the message has been successfully processed is by you calling the
DeleteMessage()
method from your code after the processing is complete. You should seriously consider placing your code within a
try{} … catch{}
block and in the
catch
expression perform some code to attempt a reprocess, place the message into a poison queue, log it for sure, and decide what you want to do with it later. It is possible that the message is malformed and would fail over and over again, so simply reprocessing the message isn't the most optimal unless you have good logic in your
catch
expressions and handle them appropriately.
Forms, Certificate, Windows, MFA, Open Standard, Managed Identities, and Service Principle Authentication
There are numerous methods for implementing authentication into your application. Some have been covered in detail; others have not. We will briefly cover several types, starting with Forms Authentication.
Forms Authentication
Forms Authentication is implemented into an ASP.NET application starting with the installation of the IIS module. Then, its configuration is installed into the
web.config
file using syntax similar to the following snippet:
<configuration><system.web><authentication mode="Forms"/></system.web></configuration>
Figure 7.3 shows that the IIS module for Forms Authentication is installed but not yet enabled.
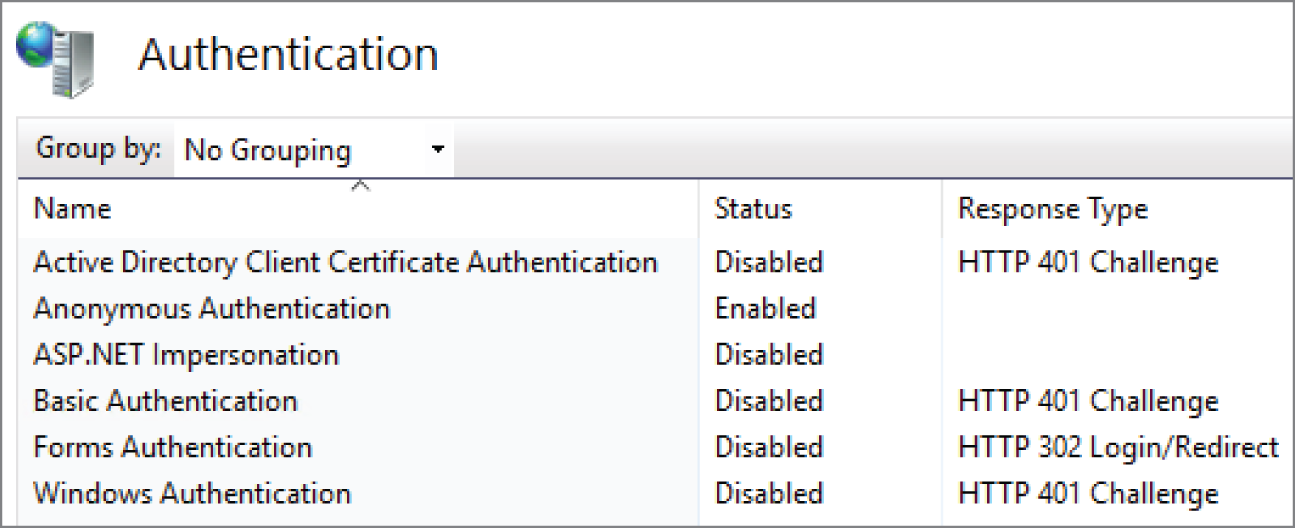
FIGURE 7.3 IIS authentication providers
Enabling the IIS module and the
web.config
file results in the authentication provider being enabled. The scope of this configuration is for the website running within and underneath the directory structure in direct relation to the location of the physical
web.config
file.
The reason for the note about where the configuration is applied in relation to the location of the
web.config
file is that this authentication provider can be enabled on the web server, but it's not used unless you enabled it specifically on a website. In addition to configuring
web.config
, you must also have an Authentication (AuthN), in which your custom user identity database stores the credentials. Any group associations that define whether the user has access to specific resources within the application once authenticated, would utilize Authorization (AuthZ) to confirm the access. The code required to perform the AuthN and AuthZ procedure must be written by a developer working in the application itself. This is not an “out-of-the-box” authentication solution. It is, however, a solid, sophisticated, and valid approach for implementing security into an internet application.
Certificate Authentication
A certificate is a file that contains an encrypted key or token that is created and administered by a certificate authority (CA). Recall from Chapter 5, which covered cryptography, that you encrypted a column on an Azure SQL database in EXERCISE 5.3. Certificate authentication falls into the same category and is related to cryptography. Something to call out here specifically has to do with public and private keys. Here are the fundamental concepts:
- A private key is used to encrypt data.
- The private key decrypts data encrypted by the public key.
Based on those definitions of public and private keys, it may be obvious that the private key is the one that needs the greatest protection. Making it possible to encrypt data using a key wouldn't cause any harm; however, the ability to decrypt that data and use it is something that needs greater control. Let's not go much deeper into this as it was mentioned before; this area of technology is career worthy and book worthy, but not essential for the exam. Some knowledge here is helpful. Certificate authentication has dependencies on public and private keys because those keys must be validated against the certificate to consider the certificate authentication successful. Look at Figure 7.3. You will see an authentication provider is installed as well. Figure 7.4 illustrates the process of this authentication (recall also from Figure 2.28 that a certificate was called out as a means for validating an identity using MFA).
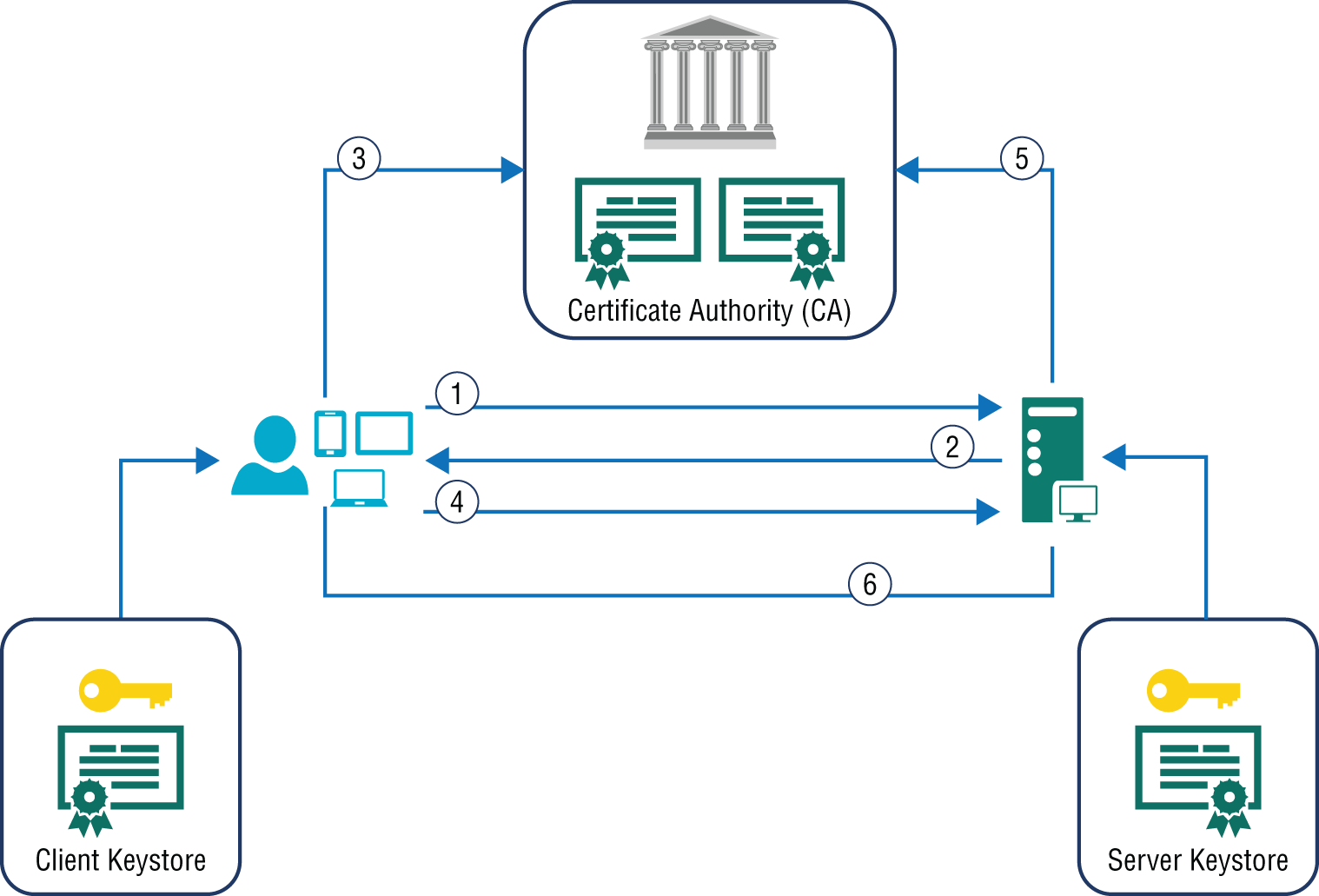
FIGURE 7.4 Client certificate authentication flow
An interesting point regarding the previous figure is that it isn't always just the server side that is concerned about the identity of the client/user making the connection. You should also be aware and confident that you are connecting to the server that you really intend to. It is easy to scrape a web page from a bank that includes the user ID and password textbox. You enter them on my page, and I store them when you click the submit button and then redirect you to the real bank site so you can reenter them and access. Having this client-server certificate validation is helpful for both parties, not just the server side. The process of client certification is as follows:
- The client requests a protected resource.
- The server returns a server certificate.
- The client validates the certificate with the CA.
- The client sends a client certificate.
- The server validates the certificate with the CA.
- The server grants or denies access based on the validation.
Notice that the client makes a request to the resource before sending the certificate. This makes sense because you wouldn't want to send a certificate with each request unless it is required to do so. This would increase the data transmission with each request. However, there is a feature called
uploadReadAheadSize
that defines how much of the data body content can be sent along with the certificate from the client in step 4. This improves performance as the data transmission can be optimized by utilizing all the available transmission buffer.
Windows Authentication
Both NTLM and Kerberos were introduced in Chapter 2 when discussing Azure Active Directory Domain Services. Both of those security protocols, NTLM and Kerberos, are included when you enable Windows Authentication for an intranet website. The key point here is that Windows Authentication is used with intranets and not the internet because intranets typically require an Active Directory (AD) and some additional infrastructure to implement. As you can see in Figure 7.3, there is an authentication provider named Windows Authentication aka Integrated Windows Authentication (IWA). If you want to enable IWA, you need to disable Anonymous Authentication to protect your website. Recall from the previous section where you learned that the initial request from the client to the server is an anonymous one. This is because the client doesn't yet know which security protocol the server requires for access to the requested resource. Therefore, if anonymous authentication is enabled, IIS uses that one as the default; once authentication is granted, it doesn't proceed to check for other enabled authentication providers.
Integrated Windows Authentication does support NTLM but mostly uses Kerberos, which is the default as it is more secure. You can see this in the advanced settings for IWA in the IIS Management console, as shown in Figure 7.5.
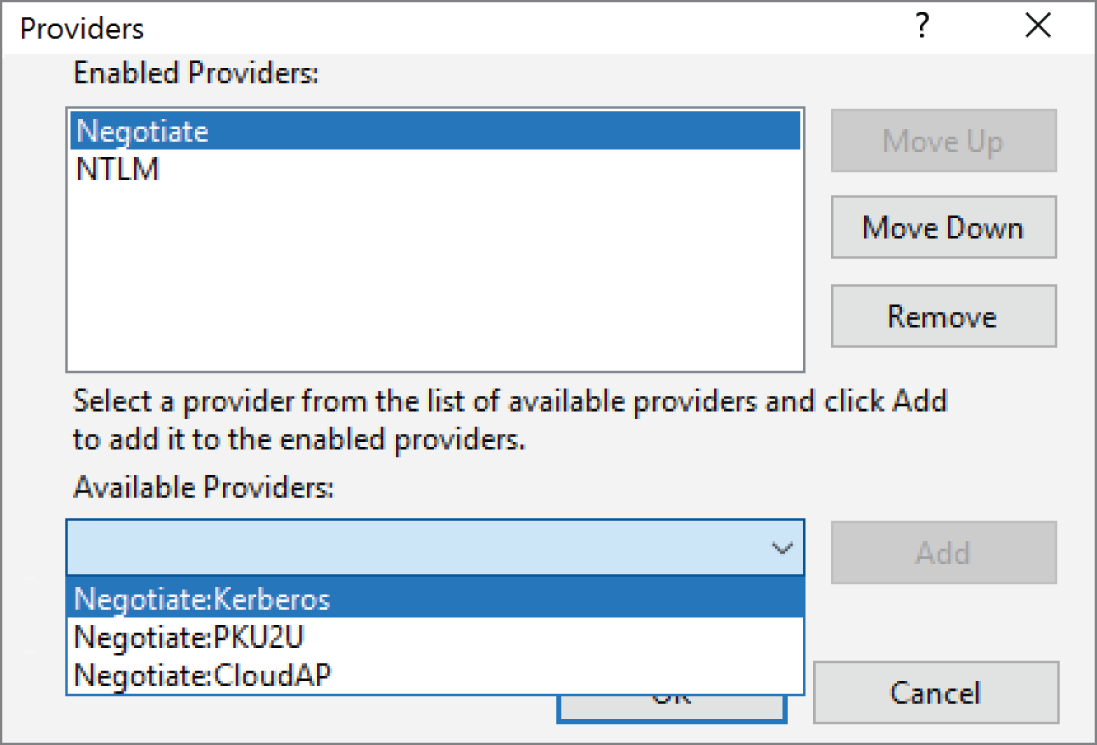
FIGURE 7.5 Kerberos and NTLM settings in IIS for IWA
IWA provides a single sign-on (SSO) solution. When an employee successfully logs into their Windows workstation, they receive a Kerberos token. This token is cached and can again be used when accessing a website without having to log in again. In most cases, the browser that is used to access the intranet site has the code necessary to check whether the website is an intranet and then look and use the Kerberos token automatically. If you are coding a custom client application that is not web-based or doesn't use a browser, then you would need to code this logic into your app manually.
Multifactor Authentication
There isn't much more to add about multifactor authentication (MFA) that hasn't already been covered in Chapter 2 (see Figure 2.28). In summary, MFA is an added level of security that takes place after someone successfully provides a user ID and password, which is something they know. The second layer is based on something they have, such as a certificate, a fingerprint, or a code sent to a mobile device in your possession. These days, you need to strongly consider MFA as a default because the user ID and password security solution has many vulnerabilities and should no longer be solely depended on.
Open Standards
Protocols like OAuth and OpenID are used mostly for delegated authentication of internet-based applications. If you have a Google, Apple, Microsoft, or Facebook account and have clicked a button similar to those shown in Figure 7.6, then you have been authenticated using an open standard authentication protocol.

FIGURE 7.6 Open standard authentication protocols
This protocol delegates the authentication to an identity provider instead of your application using one that is owned and operated by yourself or your company. Figure 7.7 illustrates how authentication works with OAuth, for example.
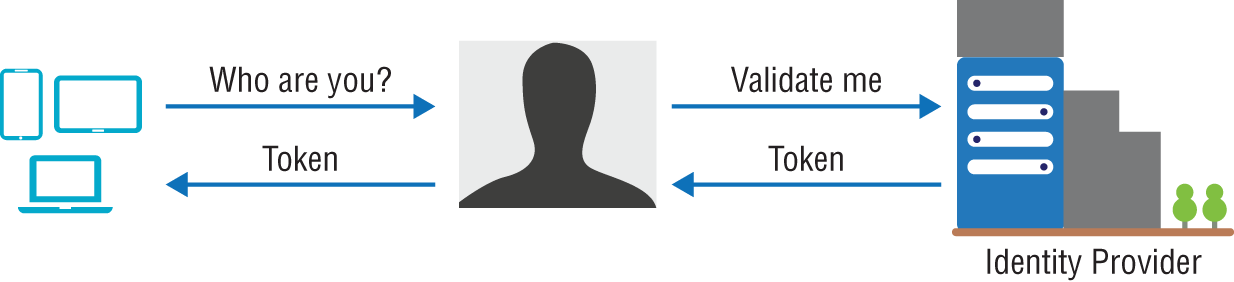
FIGURE 7.7 OAuth authentication process
In this example, you try to access some application that is protected by an identity provider, as shown in Figure 7.6. You select the one that you will use, which triggers a routing of the request to the selected identity provider. If the credentials are not cached locally already, then you are prompted to enter those necessary for the selected provider. If the credentials are cached on your machine already, then they get used. If the credentials are valid, then the identity provider returns a token that must then be validated by the application code to which you want access. In some respects, this is like Forms Authentication without the need to store user credentials in your own data store. You will, however, need to have logic to enforce authorization access, using groups, claims, and permissions.
Managed Identities
Managed Identities (MI) are in many ways a service principle. The difference is that they can be used only with Azure resources. Chapter 2 includes a section about managed identities, so take a look at that. In a majority of cases, credentials usually identify a human individual. Some scenarios let you give an application an identity and grant the application access to the application instead of granting access to individuals. A scenario in which MI is used is to access Azure Key Vault where a connection string or token is stored to access some other resource such as a database or an Event Hub partition. Using Managed Identity can prevent credential leaking since the developer and/or administrator of the application never sees the credentials of the resource that are stored in the Azure Key Vault.
Service Principal Authentication
A service principal is an identity that is used to access a resource but isn't linked to any living being. It is simply an account with a user ID and password that applications can use to make sure whatever is accessing it is allowed to. In the service principal scenario, someone has created the account and will need to manage it. For example, someone must be made responsible for resetting the password and performing other tasks. Doing that may cause some disruption if you are unaware of all the applications using it. You need to notify them all and give them the new password and the date and time, and it will change so they can update the connected systems. In summary, using a service principle requires some management, which is why the abstracted layer around the service principal is called a managed identity. All the creation and administration tasks of the service principal identity are managed for you. The approach to use depends on your needs.
Reading Encrypted Data from a Database
Encrypting your data at rest is something you should really consider. If your data source's integrity is compromised or stolen, the impact can be greatly reduced by simply encrypting the sensitive data. I confess to not being the best hacker in the world, but compromising a data source from the outside is extremely difficult. The reality is that many malicious activities happen by exploiting the trust or greed of an individual who has access to the resources you want. Most of the time the user ID and password are enough to get copies of the database onto a thumb drive and out it goes. But if the data is encrypted, like you did in EXERCISE 5.3, and no single person has access to the data source credentials and the encryption key, then the probability of a breach is greatly reduced.
In EXERCISE 2.9 you created an Azure Key Vault and generated a key, likely named
DAR
if you completed the exercises. If you take a look at your Azure Key Vault key now in the Azure Portal, it should resemble that shown in Figure 7.8.

FIGURE 7.8 An Azure Key Vault key
You will not be able to call the Key Identifier shown in Figure 7.8 because you do not have permission. Permission can be granted to a managed identity, which would make sure no individual or developer had direct access to the key. Instead, only the application would. If you are the administrator, for example, and you were the one who created the key, then you could access it using Azure CLI with the following command:
az keyvault key show --id https://<name>.vault.azure.net/keys/DAR/69 … 0bb9
Executing that would result in the encryption key being returned and stored to a variable named
n
. The key is accessible via C# code using syntax like the following. The GitHub link at the end of the next paragraph allows you to view the entire class.
var publicKey = Convert.ToBase64String(key.Key.N);
You used that key in EXERCISE 5.3 to encrypt the
MODEL
column on the
MODELS
table contained in an Azure SQL database. Take a look at Figure 5.30 if you forgot what that data looked like. In EXERCISE 5.8, you added an unencrypted Event Hub connection string to an Azure Key Vault secret, but later you learned how you could encrypt and store the connection string using some C# code. Take a look at it again if desired.
github.com/benperk/ASA/tree/master/Chapter05/DataEncryption
To use the code in that example to store and retrieve the encrypted data, you would need to perform the following:
- Create the connection to the database using either ADO.NET or Entity Framework.
- On
INSERT, get the Azure Key Vault key using the managed identity credentials. Call theEncryptText()method, which encrypts the data. Write the data to the database. - On
SELECT, get the Azure Key Vault key using the Managed Identity credentials. Call theDecryptText()method that decrypts the data. Display the data to the authenticated client.
If you completed EXERCISE 5.3, then you would only need to decrypt the data on selection because the data was encrypted when it was inserted by the configurations you made in that exercise. Another good use for this scenario is when you implemented Forms Authentication and need to store passwords in a database. For sure you would want to encrypt this column. However, you wouldn't want to send the plain-text password from the client to the server; even if TLS is enabled, it would still feel unsecure by doing that. Instead, you can make sure the passwords are encrypted using the Azure Key Vault key before it leaves the client and store it encrypted. Then, instead of comparing the plain-text password, encrypt the password on the client, and compare the encrypted value with the encrypted value on the database.
IDEs and Source Code Repositories
With all the programming languages and technologies that can be deployed on the Azure platform, you might have some questions about the most commonly used integrated development environments (IDEs) and source code repositories. The most common IDE by far is Visual Studio followed by Visual Studio Code, which is rapidly growing in popularity. Visual Studio is typically used for larger enterprises because it comes with a lot of debugging and testing capabilities. C# is the most common programming language, but C++ and Visual Basic are also popular. Visual Studio Code is used for many open source and cross-platform languages such as JavaScript, Python, and .NET Core. It is free but does lack some of the more sophisticated features found in full Visual Studio versions such as the Professional and Enterprise versions. Figure 7.9 shows the IDE for Visual Studio Community 2019. IntelliJ and NetBeans are two of the common IDEs used for developing Java-based applications.

FIGURE 7.9 The Visual Studio Community IDE
Backing up your data has been covered in much detail, and the reasons to do so are very clear. Now think about backing up the source code that analyzes, creates, or manipulates that data. If you lose the code, then all you have is a big data set but nothing to do with it or learn from it. Therefore, having a backup of your code is important. Additionally, having a change log so you can see who made changes and incorporating the ability to roll back to a previous version in case of bugs or regressions are helpful features. Some years ago, a Microsoft product named Visual Source Safe (VSS) provided these kinds of capabilities. These days the Microsoft tool for such a purpose is the Repository feature within the Azure DevOps portfolio, which used to be called Team Foundation Services (TFS), aka VSTS. There will be more on this in Chapter 8. There are many other source code repositories; a popular one is GitHub, which Microsoft recently purchased. Others like Bitbucket or a local Git repository are tightly integrated with Azure and can be used to implement deployment concepts like continuous integration/continuous deployment (CI/CD) deployment flows.
Implementing Security
You received 99% of what you need to know for the security portion of the Azure Solutions Architect Expert exam in Chapter 2. This section is more targeted toward the application itself. The content in this chapter is good to know if your goal is to become a great Azure Solutions Architect Expert. In this section, you will implement and configure Managed Identity into an Azure App Service to give your Azure App Service an identity and use that identity in creating and configuring an Azure Key Vault key secret and provide access to other Azure resources. The code that will use that identity to get a database connection string from an Azure Key Vault secret and an encryption key to encrypt and decrypt can be viewed here:
github.com/benperk/ASA/tree/master/Chapter07/DataEncryption
That code will not be discussed in detail because coding isn't part of the exam. But note that this is the code that will be used in the next chapter. In Chapter 8, this application is used as you learn how to deploy to the Azure platform.
In addition to Managed Identity and Azure Key Vault access policies, you will configure EasyAuth. EasyAuth (introduced in Chapter 2) is a quick and easy way to implement Authentication (AuthN) using Azure Active Directory within the context of Azure App Service or Azure Function.
Let's get started. In Exercise 7.1 you will enable Managed Identity in the Azure App Service you created in EXERCISE 3.8 and then grant the identity access to an Azure Key Vault secret. (You created an Azure Key Vault in EXERCISE 2.9.)
That wasn't so hard, was it? Just a few clicks in the portal, and you have enabled Managed Identity for an Azure App Service. The procedure for many other Azure products is of the same complexity. Behind the scenes, the configuration creates two environment variables,
MSI_ENDPOINT
and
MSI_SECRET
. You can review them in the SCM/KUDU console linked to the Azure App Service, accessible using a URL similar to the following:
https://<appName>.
scm.azurewebsites.net/Env.cshtml
The values are used by the platform to get an authentication token on behalf of the principle.
If you were to deploy the updated GitHub code with the required packages, after completing the previous exercise, then when you access the ASP.NET Core application, the following will take place:
- A token for the application principle is retrieved.
- An Azure Key Vault client is created and authenticated.
- A database connection string is retrieved from an Azure Key Vault secret.
- An Azure Key Vault key is retrieved and used to encrypt a guitar brand.
- A connection is made to a database, and the encrypted value is inserted into the database, as shown in Figure 7.12.
- The inserted row is then retrieved, decrypted, and displayed on the web page.

FIGURE 7.12 An encrypted data element on a database table
At the moment, the web page is open and accessible to anyone who comes across the page or discovers the endpoint. To prevent this, implement EasyAuth to make sure only authenticated users associated with an Azure Active Directory tenant can view the page. See Exercise 7.2.
That's easy and is why it's named EasyAuth. When you now access the Azure App Service, based on the Allow Anonymous Requests setting in the configuration, the client will have access to the main page. You need to make code changes to protect the content of your application, such as implementing Authorization (AuthZ). If you take a look at the source code provided earlier, specifically the
index.cshtml
file, you will notice an
if.. else..
statement that checks to see that an authentication token exists and is not null. If the token doesn't exist, then you see the links to log in with AAD. Clicking that captures the credentials, authenticates, and then dumps out some of the details about the token. You need to check whether the client is authenticated and has a valid token in each one of your web pages that needs restricted access. Additionally, and most importantly, you also need to build your own authorization logic into the application. EasyAuth doesn't provide that feature. When all is configured correctly, your client is authenticated, and the screen shown in Figure 7.14 is rendered in the browser.

FIGURE 7.14 EasyAuth Azure Active Directory successful login
Security is an important aspect when it comes to IT and creating applications. There are many components in an IT solution, each of which should be reviewed from a security perspective. In addition to the hardware and infrastructure components, the code and the entry point into the code require professional skill, expertise, and experience in the security area. In all cases, consult a security expert when you have doubts about the integrity of your IT footprint.
Summary
You will not find many questions on the exam about the contents of this chapter. In any case, knowing architectural styles and coding patterns that are optimal for the cloud will only make you a better architect. You gained some knowledge of the IDEs used for developing and testing applications and the importance of protecting and tracking your application source code. There were some examples about different types of authentication, such as Forms, IWA, and OAuth. In addition, you learned about encryption, enabling EasyAuth, and configuring Managed Identity on an Azure App Service.
Exam Essentials
- Know what lift and shift means. This term has to do with moving an application that is running in an on-premise data center and moving it to the cloud without making any changes. Having read this chapter, you will recognize there are some cloud-only issues you may face and some optimal patterns and styles to follow that will improve the chances of being successful in the cloud. They include Retry and creating a reusable static connection object.
- Understand authentication protocols. There are numerous methods for protecting your application by checking for credentials: Forms Authentication, certificate authentication, Windows Authentication (Kerberos), and OAuth. These are protocols that protect the application entry point, which then allow the client to execute the code. You need to implement some logic to authenticate and authorize access to the application and to the features running within it.
- Understand encryption. This area has to do with the concept of cryptography. The examples provided in this book focused on the encryption of data on a given column in an Azure SQL database table. This is an example of encrypting your data at rest. The data is encrypted when inserted, the data is selected from the database encrypted, and then the client can use an encryption key to decrypt and view the value. This kind of operation can add latency, so implement it only on very sensitive data.
Key Terms
| authentication (AuthN) | continuous integration/continuous deployment (CI/CD) |
| authorization (AuthZ) | integrated development environments (IDE) |
| Azure Front Door | Integrated Windows Authentication (IWA) |
| certificate authority (CA) | Team Foundation Services (TFS) |
| Command and Query Responsibility Segregation (CQRS) |
Review Questions
- Which of the following cloud concepts would you expect to occur more in the cloud than on-premise? (Select all that apply.)
- Auto healing
- Datacenter outage
- Transient outages
- Data loss
- If your application running on an Azure App Service or Azure Function is receiving a
SocketExceptionor experiencing SNAT port exhaustion, which coding pattern would you implement?- Gatekeeper
- Sharding
- Create private static connection objects
- Use asynchronous methods
- What coding pattern would you use to recover from transient issue?
- Retry
- Gatekeeper
- Circuit breaker
- Throttling
- Which of the following are user authentication mechanisms you can use to protect your internet-based application? (Select all that apply.)
- Forms authentication
- Certificate authentication
- Windows authentication
- Service principle
- Which of the following is not a valid IDE for building applications that run on Azure?
- Visual Studio Community
- IntelliJ
- Visual Studio Code
- Visio Studio
- Which of the following is true concerning Managed Identity (MI)? (Select all that apply.)
- Can be used to access Azure Key Vault
- Cannot be used with an ASP.NET Core application
- Represents the identity of an Azure product
- Managed Identity is enabled by default on all supported Azure products
- Which of the following authority providers does EasyAuth support? (Select all that apply.)
- Microsoft
- GitHub
- Which product would you choose to implement a Big Data solution? (Select all that apply.)
- Data Lake Analytics
- Azure Cosmos DB
- Event Grid
- Azure Kubernetes Service (AKS)
- Which product would you choose to implement a decoupled IT solution? (Select all that apply.)
- Service Bus
- Azure Cosmos DB
- Azure Batch
- Azure Storage Queue
- Which product would you choose to implement a big compute solution? (Select all that apply.)
- Service Fabric
- Azure Virtual Machines
- Azure Batch (aka HPC)
- Azure Functions