
Chapter 7
Communication and Synchronization Utilities
7.1 Introduction
In Chapter 6 we discussed that the Availability Management Framework (AMF) [48] assigns the component service instances (CSIs) to a group of components in different high availability (HA) states to protect the CSI according to the redundancy model. AMF is like the conductor of the orchestra who indicates to the different instruments when they need to enter, take lead, quiet down, but it does not tell how the musician can achieve any of these. Similarly the components receiving the assignments need to figure out what they need to do to fulfill these HA state assignments: Whether they need to save their state, pick up some state information, suspend or resume a service, and so on.
The components in the active and standby roles—the different HA states—on behalf of a CSI need to synchronize the state of the service associated with this CSI so that if the need arises the standby can take over the service provisioning as seamlessly as possible. This requires that the user of the service should not become aware that another component—most likely on another node in the cluster—took over the role of providing the service.
In summary this means that to achieve high Service Availability (SA) there is a general need for utilities that decouple the service provider from the service access point that the service user would bind to as well as for those that allow the replication of any necessary service state information within the cluster so that the service is perceived as continuous.
Some of the Application Interface Specification (AIS) services defined by the SA Forum address exactly these needs. They play an essential role for applications to improve their availability. Applications do not need to use all of these services at the same time but rather they use a subset of these utility services to solve their specific needs in achieving their availability goals.
In this chapter we present the three most frequently used utility services. Our emphasis is on what they do, what problems they solve, and how applications can use them to solve their particular availability requirements rather than discussing how they are implemented in the middleware.
One of the simplest communication method that decouples senders from receivers is known as the publish/subscribe messaging pattern [83], which is at the basis of the SA Forum Event service (EVT) [43]. It provides application processes with the ability to publish events on some event channels that in turn can be collected by other application processes subscribing for these channels.
Thus the EVT enables a multipoint-to-multipoint communication in which publishers and subscribers are independent and not aware of each other. The delivery guarantees of the EVT are described as best effort, which definitely leaves room for improvement in the context of SA.
To fill this room the SA Forum also specified the Message service (MSG) [44] which provides delivery guarantees. It enables a message transfer between processes in a multipoint-to-point manner using a priority based message queue serving for its opener as an input queue. Message queues are cluster-wide entities which are accessed using logical names that are location agnostic in the sense that a sender of a message does not have any idea where a receiver is located and conversely the receiver has no sense of where the sender is located unless the sender provides this information. The sender and the receiver are also decoupled that messages are sent to the queue and not to a given process. Anyone opening the message queue becomes the receiver.
Additionally the MSG allows the grouping of Message queues together to form a message queue group, which is addressed the same way as an individual message queue. Thus, message queue groups permit multipoint-to-multipoint communication. Each message queue group distributes the messages sent to the group according to one of the four distribution policies defined in the MSG.
As opposed to these message-based services the SA Forum designed the Checkpoint service (CKPT) [42] for storage-based exchange of information. It allows an active instance of an application to record its critical state data in memory, which then can be accessed by its standby counterpart either periodically or as part of a failover or switchover when the standby transitions to become the active instance.
To protect against data loss, the checkpoint data is typically replicated on several nodes in the cluster. This replication is performed by the CKPT without any involvement of the application.
In this schema application processes are also not aware of each other in the sense that they do not know the identity or the location of their counterpart processes and they may not be aware of the location of the checkpoint replicas either.
In the rest of the chapter we take a detailed look at the features of these three services.
7.2 Event Service
7.2.1 Background: Event Service Issues, Controversies, and Problems
Highly available applications need to communicate amongst their distributed sub-parts as well as with other applications.
One of the forms of such communication is referred to as the publish/subscribe messaging pattern [83], which enables multiple processes—the publishers—to communicate to several other processes—the subscribers—without necessarily knowing where these processes are located. This provides an abstraction much needed in fault tolerant systems to cater a flexible design of application messaging.
It is quite possible that senders and recipients of messages reporting different events in the system are not known from day one when the application design actually starts. It is like the TV channels of the old days, which were established based on the band used for the transmission. A broadcaster would take ownership of such a channel for a particular region where then it could recruit subscriber interested to watch its broadcast.
Indeed, the most common usage issue with recipients is that additional ones can arrive dynamically later in the application design or production life-cycle. A common example is an application that provides Simple Network Management Protocol (SNMP) [53] traps. The application designer builds a SNMP trap generator process which receives the events directly from the various distributed sub-parts of the application, converts them to the proper format, and emits them as SNMP traps. At the time of the design it may not be known who, what manager applications will be the receivers of these traps. The most predictable receiver of course is the system administrator itself.
In this respect, the opposite may also be true that new applications are added to and old ones removed from the system all of which generate SNMP traps and the system administrator or a manager application would be interested to receive all or a particular subset of these traps.
So the question is how to set up the communication between the applications generating these traps and the managers interested in different subsets of the generated traps, all under the circumstances that both of these parties change dynamically over time. Most importantly neither lists are known in advance, that is, at the time the applications (manager and managed) are written.
Furthermore on the managed applications side, they report different issues such as the state of operation, alarm conditions, the temperature they collect from the underlying hardware or just a heartbeat indicating that they are ‘alive.’ On the other side, not all manager applications are interested in or can deal with all these reports. An availability manager is interested in the heartbeat and the operational state, while the temperature figures may be irrelevant. An alarm is irrelevant in a different way as it may indicate a situation when human intervention is necessary. Hence the system administrator needs to receive all the alarms from all applications and possible other information too, but definitely does not want to see any heartbeats.
Thus, it is necessary that subscribers can tailor their subscription to their interest.
The SA Forum EVT was designed with these requirements in mind.
7.2.2 Overview of the SA Forum Event Service
To address the issues described in the previous section the SA Forum EVT provides a cluster-wide publish/subscribe messaging utility that enables processes within a cluster to communicate without the need for knowing each other's identity or locations.
Processes that send messages are known as publishers while processes that receive messages are the subscribers. They exchange messages—referred as events—over logical message buses called event channels as shown in Figure 7.1. Channels are typically created by publishers; however the EVT also allows subscribers to create event channels.
Figure 7.1 Entities of the event service.
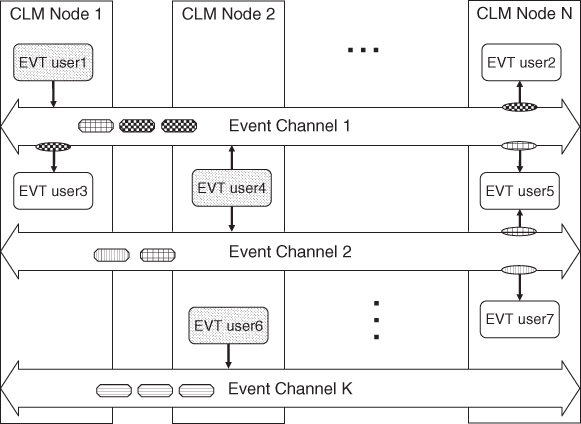
Once an event channel has become available a process may publish events on it. Each event has an associated pattern, a kind of label that indicates, for example, the contents of the message and therefore helps in categorizing the event. A process that intends to scoop messages from the channel must subscribe on to the event channel using a subscription filter. After this, the subscriber receives an event when its pattern matches the filter of the subscription based on a set of pre-ordained rules.
Each event is normally delivered to all the subscribers whose filters it matches and it is delivered at most once. Due to congestion or failure however events may get lost. So events are also prioritized by the publisher. In case of congestion events of lower priority are dropped before those of higher priority. The events of higher priority are delivered first and in order with respect to a given priority and a given publisher.
In addition to these traditional features, the EVT also supports delayed retrieval of events. That is, if there is a need an event can be retained on a channel for a given period—a retention time—specified at publication and be retrieved by processes subscribing to the channel after the fact of the publication.
With all these features, the SA Forum EVT enables application designers to design applications without needing to know the message end-points from the very start. They can build a future-proof application messaging infrastructure based on ‘well-known’ event channels which has a pre-defined pattern and filter syntax.
Considering our SNMP example we could define an event channel called ‘SNMPtrap,’ which then would be a cluster-wide entity, meaning that any application running in the cluster can publish events on this channel. Events would represent SNMP traps. Whenever an application generating traps is added to the system it needs to open this channel and whenever it generates a trap, it needs to publish an event containing the trap. It needs to associate this event with the pattern from the agreed upon set that identifies the type of the trap it is publishing. For example, ‘amop’ may indicate the trap for the operational state, ‘amh’ for the heartbeat, ‘temp’ for the temperature, and ‘alarm’ for the alarms.
On the other hand, the manager applications interested in receiving traps need to subscribe to the ‘SNMPtrap’ event channel with filters matching the event patterns of their interest. Since the availability manager is interested in the operational state and heartbeats it could set up a prefix filter for patterns starting with ‘am.’ The administrator would set its filter to match exactly the pattern ‘alarm’ in its subscription.
From the moment of their subscriptions both the availability manager and the administrator will start to receive events matching their respective filter. But before that the EVT will also deliver any matching event which is being retained in the event channel.
7.2.3 Event Service Architecture and Model
The EVT offers a multipoint-to-multipoint communication mechanism: One or more publishers communicate asynchronously with one or more subscribers by means of events over a cluster-wide event channel.
7.2.3.1 Event
An event is a unit of communication used by the EVT. It carries a piece of information that may be interesting for other processes in the system. It can be an SNMP trap as we discussed in our example, an advertisement of some services, or a status update. It can be any piece of information. The most important characteristic of this piece of information is that the processes interested in it are not known to the process, which has the information. It is a ‘to whom it may concern’ type of announcement where the concerned party needs to do the sorting.
The announcer helps the sorting by adding some labels called the patterns to the information. The purpose of these patterns is to categorize the information so that the interested parties can use filters and receive only the events that are relevant to them. In addition to the patterns the announcer—or the publisher in EVT terminology also assigns a priority and a retention time as well as indicates its own name. The EVT also adds an event id and the publication time to each event shown in italic in Figure 7.2.
Figure 7.2 The event structure.

The priority and the retention time indicate for the EVT the delivery features of the event. That is, the EVT delivers the events of higher priority before events of lower priority and appropriately when it runs low on resources it will drop events of lower priority first.
The retention time indicates how long the service will keep the event in the channel and deliver it to any new subscriber with a filter, which matches the event's patterns. This implies some persistency for events that are published with nonzero retention time. Indeed in some EVT implementations events may survive even a cluster reboot, but this is not a requirement posed by the specification.
The portion of the event that holds these common attributes characterizing an event is called the event header. While the information portion of the event is referred as the event data.
The EVT does not mandate any structure or format for the data portion. Of course to be able to interpret the event one needs to understand the data format, encoding, and so on. It is outside of the scope of the EVT how the communicating parties establish the common ground. Even for the patterns and their filters only the mechanics are defined in the service; the actual pattern values associated with different event categories are also outside of scope and need to be established by other means. There are no well-known patterns, for example, for SNMP traps.
7.2.3.2 Event Channels
One may think of an event channel as a cluster-wide communication bus that not only delivers messages—well, events—but also stores them. Cluster-wide as it can be accessed from anywhere within the cluster using a unique identifier, the name of the event channel.
An event channel can be created by any EVT user by simply opening it. The service checks if a channel with the given name already exists. If it does not and the opening request allows the creation, EVT creates a new channel with the provided name. If an event channel already exists with the given name, the user is added to the existing channel in the role indicated in the open request even if the creation flag is set in the request. In any other case the service returns an error.
A user can be associated with a channel in the publisher, the subscriber, or both roles. So the same channel may be used for both uni- and bi-directional communication between these two groups of processes. In general neither set of users are known to the other.
A user may open a channel as a publisher and start publishing events on it right away without waiting for any user to attach itself to the channel as a subscriber. In fact using the service application programming interface (API) the publisher does not know and cannot find out whether there are any subscribers at given moment.
As far as the open operation is concerned the subscribers are in a position similar to the publishers'. That is, a subscriber may create an event channel just like any publisher. However after the opening the channel it will not automatically receive the events. It first needs to set up its subscriptions. Each subscription is associated with a set of filters and only events matching these filters are delivered through the given subscription. Each subscription can be viewed as an individual delivery queue for the given subscriber where events are stored for the subscriber until the subscriber collects them.
A user who opened an event channel in the subscriber role may subscribe to this channel any number of times with the same or different sets of filters. The event channel will deliver the events per subscription and not per user. So if two subscriptions of the same user process define overlapping sets of filters, then events matching the intersection will be delivered twice to the process. This is useful when there is a need to modify a subscription as existing subscription cannot be modified. Instead users need to subscribe with the new set of filters and then remove the old obsolete set.
Whenever an event arrives that matches the filters of a given subscription, the EVT calls back the user owning that subscription identifying the subscription and the size of the data. It is the responsibility of the user to collect the event itself. It can collect separately the even header info and the data portion. In any case, once the EVT notified a subscriber about an event, the event is stored for this subscriber as long as the memory allocated for the event was not de-allocated by the subscriber explicitly.
This means that a slow subscriber may pile up a significant backlog and cause the EVT to run out of resources.
Whenever a channel looses an event for a given subscriber it generates a special ‘lost event’ event and delivers this at the highest priority. Such an event may indicate that more than one event were lost.
Since the service may run out of resources at different phases of the delivery it may not even be able to tell whether the lost event would match a particular subscription, so it may happen that it would deliver a lost event to a subscriber who would not receive the event if it was matched properly with its filters.
Based on these considerations we can say that the EVT provides a best effort delivery. When it delivers events it delivers them at most once per subscription and only complete events are delivered. Events are delivered according to their priority: Higher priority events are delivered prior to lower priority events.
An event channel exists in the cluster until it is explicitly deleted by ‘unlinking’ it. However the EVT performs the actual deletion only if there is no user process in the cluster that has the event channel open. If there is, the deletion is postponed until the last user closes the channel. At that point, however, the channel is deleted together with any retained event regardless of their retention time.
In contrast, all users closing the event channel does not imply the deletion of the channel. It remains available in the cluster for potential further use.
7.2.3.3 Event Filtering
When a process publishes an event on a channel it specifies a list of patterns for this event. On the other hand when a process subscribes to the same event channel it specifies a list of filters. Based on these the EVT performs a matching procedure: It pairs up the two lists and looks at the patterns and filters as pairs. The first pattern of an event needs to match the first filter of a subscription, the second pattern the second filter, and so on until all patterns are matched up with all filters. An event is delivered to a subscriber only if all patterns associated with the event match all the filters associated with the subscription.
There are four filter options:
- Prefix match: — an event passes such a filter as long as the pattern starts with the same ordered set of characters as indicated in the filter;
- Suffix match: — an event passes such a filter as long as the pattern ends with the same ordered set of characters as indicated in the filter;
- Exact match: — an event passes such a filter if the pattern has the same ordered set of characters as the filter;
- All match: — any event passes such a filter.
This relatively simple matching technique allows for the design of rather elaborate filtering system for subscribers. The key issue is, however, that the communicating parties need to agree in advance on the conventions in the pattern interpretation and therefore the filter setting. All of which is beyond the scope of the specification.
The patterns and the filters act as addresses and masks that guide the delivery of multicast packages on the Internet, but in contrast to the Internet the EVT does not require location specific addresses. In fact it is completely location agnostic.
7.2.3.4 Conceptual EVT Architecture
From all these considerations we see unfolding a conceptual architecture shown in Figure 7.3.
Figure 7.3 Subscriptions to an event channel.
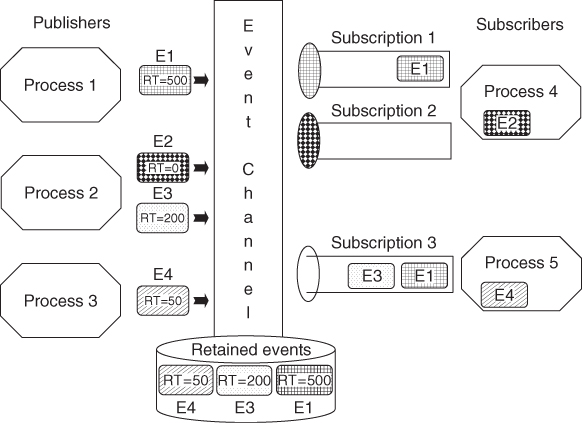
Each event channel implies a highly available storage area where the EVT stores the events published on the channel for the period of their retention time.
When a user subscribes to an event channel the EVT associates a delivery queue with the subscription. This is where the EVT places a copy of each event on the channel event that matches the filters of the subscription and being retained. At the same time the service also informs the owner of the subscription—the user process—about the delivery. Subsequently each time an event is published on the channel the EVT checks if it matches the subscription and if so delivers it.
The event copies remain in the delivery queue until the user collects them or the subscription is cancelled.
When a publisher publishes an event typically it is stored first locally on the publisher's node so that the publisher can free any memory allocated for the event. With that the publishing is completed and successful. Subsequently the EVT transports the event to the main storage area and to the delivery queues of the subscribers whose filters it matches.
When a user unsubscribes from a channel the EVT removes the delivery queue associated with the subscription. When one user unlinks and all other openers close the event channel it is also removed together with its storage area.
7.2.4 User Perspective
The most important aspects of the EVT that users need to be aware are:
- establishing the conventions for an event channel;
- life-cycle management of the channel; and
- event handling and the associated memory management.
7.2.4.1 Event Channel Name and Pattern Convention
To access an event channel the user process needs to know the channel's name as it is used in the API call to open a channel. The method by which the name is established and communicated among the parties involved is not discussed in the EVT specification. Users are left to their imagination to find a suitable mechanism.
The situation is similar with the pattern conventions: Publishers need to use patterns that the subscribers are aware of so that they can install appropriate filters. Otherwise they can only use the filters that let through all events. These may be used to discover the patterns used on a channel; however, the bigger challenge is to interpret the event data.
The publishers and subscribers need to use the same conventions with respect to the event data so that they interpret it the same way at both ends. The EVT offers no solution for this either therefore it requires some planning at the application design and development time.
All these also mean that unless some well-known names, patterns, and formats are established for the service the event channels will be used within the scope of a given application.
An application may use other AIS services to communicate at least partially the needed information. In particular, the SA Forum Naming service [46] was defined for providing a directory type of service. One may also rely on the functionality of the SA Forum Information Model Management service (IMM) [38] by defining application configuration information provided at deployment time.
7.2.4.2 Life-Cycle Management of the Event Channel
Event channels are managed completely and exclusively by the user applications. We have seen in the conceptual architecture that the EVT associates certain resources with each event channel and it relies on the users that they use these resources efficiently.
To avoid accidental creation of event channels just by attempting to open them, it is important that only processes that are responsible for the creation of the channel set the creation flag in the open call. Also it is essential that once an application does not need a channel it unlinks the channel to let the EVT free its resources.
A service implementation also needs to be prepared to handle failure cases of the application managing the channel life-cycle.
7.2.4.3 Event Handling
When it comes to event handling memory management is the most important issue that user applications need to take care of.
To publish an event a process allocates the data structure associated with the event header using the provided event allocation function. This header part can only be manipulated using the appropriate API calls. This portion can also be reused by the process as many times as needed since the memory remains allocated until the user calls the API to free the previous allocation.
At publication in addition to the header the user also needs to provide the data buffer and its size. This portion is handled completely by the user.
When the user has finished constructing both parts, it can publish the event at which time the EVT creates a copy of the entire event; it takes complete charge of the event content so that the user can free any or all memory allocations associated with it or reuse any part of it to construct a new event. The publication is confirmed by the service issuing an event id associated with the event. This id may be used subsequently to clear the event's retention time, which also removes the event from the event channel (i.e., from its main storage area, but the event remains in any delivery queue until consumption).
Symmetrically when an event is delivered the EVT allocates some memory for the event header and informs the user of the data size of the event. For this latter portion the user needs to allocate an appropriate buffer and pass it in the call at the time it wants to retrieve the event data. For the header portion again the user needs to free the allocation using the provided API after it has collected all the needed information.
Since the subscriber can obtain the event id from the event header, it can also clear the event's retention time and therefore delete the event from the event channel.
7.2.5 Administrative and Management Aspects
At the time of writing, the specification defines no configuration or administrative operations for the EVT itself or its event channels. The service also generates no notifications or alarms.
However the EVT reflects the presence of event channels in the system as runtime objects in the information model. These objects expose a set of read-only run-time attributes that can be accessed via the SA Forum IMM if desired. This provides some statistics about the use of the channel such as the number of openers, the number of retained and lost events, and so on.
7.2.6 Service Interactions
7.2.6.1 Interactions with CLM
The SA Forum EVT provides its services only to users within the cluster for which it needs to be up to date about the cluster membership. This requires that the service implementation tracks the membership information through the SA Forum Cluster Membership service (CLM) [37]. Whenever CLM reports that a node left the cluster the EVT stops serving user processes on that node. This implies some housekeeping on EVT's side as with the node leaving the cluster all the subscriptions of processes residing on that node needs to be cancelled and the related resources freed including any associations between these processes and any event channel they opened.
However any event channel created will remain in the system as long as it is not unlinked.
Note that the EVT is not allowed to loose event channels as a consequence of nodes leaving the cluster. It may however loose events that were not secured yet for safe keeping.
7.2.6.2 Interactions with IMM
The only interaction between EVT and IMM is related to the event channels that the EVT exposes as runtime objects in the information model. For this the service needs to use the Object Implementer (OI) API of IMM. Accordingly it registers with IMM as the implementer for the class representing event channels (SaEvtChannel) and provides the necessary callback functions.
Whenever a new channel is created by a user the EVT creates an object of this class using the IMM OI-API. The name and the creation time are set at creation. All other attributes are non-cached meaning that the EVT does not update them unless someone attempts to read their values. If this happens IMM calls back EVT using the callback function EVT provided at registration as an OI and ask for the requested attributes.
7.2.7 Open Issues and Recommendations
The EVT is one of the services that were defined in the early stage of the specifications. It was also among the first ones implemented in the different middleware implementations. As a result it is mature and from the standardization perspective there are no open issues.
The SA Forum EVT is a very good fit when asynchronous communication is needed amongst processes that could reside in various nodes of the cluster. It is particularly suited for (multi)point-to-multipoint communication when the set of senders and the receivers not known in advance or dynamically changes over time.
Its biggest drawback is that it does not provide the delivery guaranties that applications may require in the HA environment. It should not be used in applications where reliable message delivery is absolutely essential. In particular it is not suitable for notifications and alarms for which the SA Forum Notification service (NTF) should be used instead. In the next section we will also look at the SA Forum MSG, which was designed for reliable communication.
The concept of retention time associated with an event goes beyond the basic publish/subscribe paradigm. It enables the communication between processes that need not exist at the same time which is quite powerful and can be used to preserve state even between incarnations. The possibility of clearing of the retention time allows one to remove the event from the channel as soon as it has been taken care of or become obsolete, which eliminates the guessing at the publisher side.
Users may experience some ambiguity regarding the possible preservation of events and the implied persistency of channels over cluster reboots. It may come as a surprise for an application that after a cluster reboot it will find events in an event channel from before the reboot. Considering that these events may convey state information, they may also save faulty states that might have been contributing to the cluster reboot on the first place. So the possibility to control the behavior is desirable, but in the current situation at least applications need to be aware that event preservation may occur.
7.3 Message Service
7.3.1 Need for Reliability and Load Distribution
Maintaining SA requires cooperation and coordination amongst applications within a cluster as well as within the various distributed subparts of an application, which in turn requires a reliable messaging service that can be used to communicate important events in a timely fashion.
Considering the redundancy used to achieve fault tolerance it is easy to see that it is useful if this communication does not require the knowledge of the exact location of the end-points. In a highly available environment the end-points may change dynamically as the active and standby instances of an application change roles due to failovers and switchovers. This dynamism calls for providing an abstraction between message senders and receivers that allows for the senders to send messages without knowing the exact identity and location of message receivers.
Although the EVT provides the decoupling of publishers and subscribers it does not guarantee reliable communication which is essential for many HA applications.
Load distribution to avoid overloads is another important requirement in highly available systems. We would like to share the load amongst multiple processes that may even be located on different nodes of the cluster. For example, the traffic served by a web-server may experience wild swings during the course of a day. During peak hours we may want to be able to deploy two, three times as many instances to serve the traffic as we would need when the traffic is low. In this case there are two issues: One is that we would like to distribute the traffic load at any given moment of the day among all the server instances. Secondly we would like to be able to increase and decrease the number of instances sharing the load as the traffic changes. All this we want to be able to pull off without any support or even awareness of the users accessing our web-server.
So there is a need to be able to submit requests or jobs to a service access point, which then could distribute them somehow magically among all the processes that are capable of processing those jobs without overloading any of them. The clients submitting these jobs should not be involved and even aware of any aspect of this distribution.
The SA Forum has defined the magic bullet to address these in the form of the MSG specification. It describes a reliable messaging service which enables multipoint-to-point as well as multipoint-to-multipoint communication. It also supports load-sharing amongst multiple processes within a cluster.
7.3.2 Overview of the SA Forum Message Service
The SA Forum MSG specification defines a reliable buffered message passing facility that has all the features expected from a true carrier class messaging service. It includes capabilities that can be leveraged to build applications that provide continuous availability under the most demanding conditions.
The main concept defined in the MSG is the message queue, which is a cluster-wide entity with a unique name as shown in Figure 7.4. One may think of it as an input queue of a process, but instead of addressing the process itself this input or message queue is used as the destination point of the messages. This approach makes the process using the input queue interchangeable.
Figure 7.4 Message queues with single receiver and multiple sender processes.
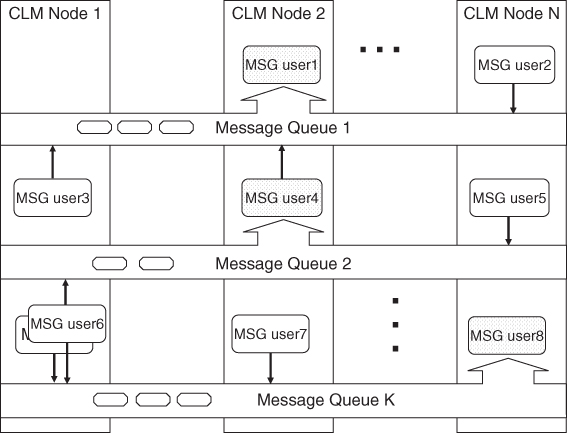
A process which needs such a queue opens a message queue and can start receiving messages sent to the queue. The MSG message queue can be opened by at most one process at a time as usual for input queues. However when the first process closes the message queue another process on the same or from a different node may open it and continue processing the messages. Meanwhile the message queue acts as a buffer for the messages sent to the queue.
There is no restriction on who may send messages to a given message queue therefore a single message queue allows for a multipoint-to-point communication.
A process sending messages to a message queue is unaware of the process receiving it. The latter may change any time, for example, due to a failover, and the sender of the messages will have no idea that the original receiver process has been replaced with another one possibly on a different node of the cluster. This abstraction provides a location agnostic communication with seamless handling of failovers and switchovers which is a necessity in HA systems.
For example, we can associate a message queue with an Internet protocol (IP) address and send all requests addressed to this address to the messages queue. The process of the application serving the requests associated with the address such as a web-server then can sit on any of the nodes of the cluster, it will receive the requests even if one node fails and a new process is assigned the task on another node. The new process just needs to open the same message queue.
The MSG preserves all the messages sent to the queue that have not been consumed yet. It does so as long as the queue exists even when the queue is not open by any process. That is, the life-cycle of an application process that has opened a message queue is not tied to the life-cycle of the message queue itself.
The MSG implementation may store the message queues on the disk and therefore its contents may survive a cluster reboot, however this is not a requirement imposed by the specification not even for persistent queues as we discuss later. The implementation choice depends on the targeted communication performance as such feature may hamper performance and within the suite of AIS services the MSG is intended for high-performance communication.
To address the need of load distribution the MSG offers the concept of message queue groups. It is a set of message queues, which can be addressed by the same unique name in the cluster and has an associated distribution policy. With message queue groups the MSG enables multipoint-to-multipoint communication.
From the perspective of a sender a message queue group is very much like an individual message queue, but each message is delivered to one selected message queue in the group (unicast) or to all the queues in the group (multicast).
Considering the web-server application this means that if we associate the IP address with a message queue group instead of a particular message queue then we can install several application processes each serving one message queue of those grouped together in the message queue group. The MSG will take care of the distribution of the requests incoming to the message queue group. It will apply the distribution policy selected for the queue group and deliver the messages to the message queues of the group accordingly.
7.3.3 Message Service Architecture and Model
7.3.3.1 Message
A unit of information carried by the MSG is called a message. As in case of events, messages may carry any type of information in their data portion while the specification defines the message header, which is called the message meta-data pictured in Figure 7.5.
Figure 7.5 The message data structure.

A standard set of message attributes and a fixed size implementation-specific portion comprise this meta-data. The standard attributes describe the type, the version, the priority, the sender name and its length, and the data size. The implementation-specific portion is handled by the service implementation exclusively.
The message data is an opaque for the MSG array of bytes.
The specification defines the data structure only for the standard attributes portion of the message meta-data, which is used at both ends of the communication. This provides for some negotiation between the senders and the receiver with respect to the interpretation of the message data content. However again, the specification only provides the tools (i.e., the type and version fields) the actual interpretation of these fields and any negotiation procedure are outside of the scope of the MSG specification.
7.3.3.2 Message Queue
A message queue is a buffer to store the messages. It is divided into separate data areas of different priorities as shown in Figure 7.6. A message queue is identified by a unique name in the cluster and it is global—cluster-wide—entity.
Figure 7.6 The message queue and message queue group.
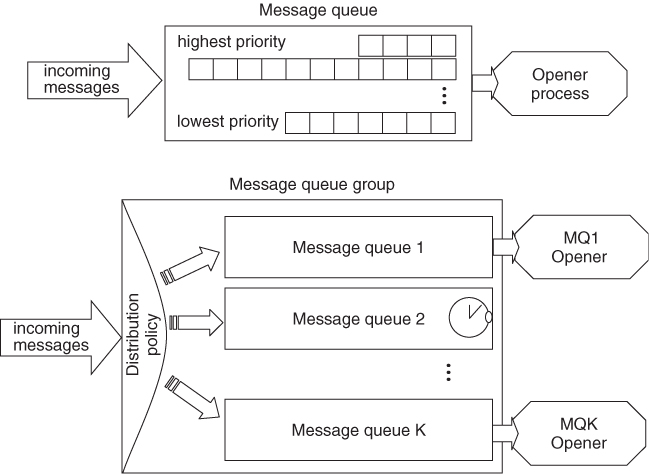
Message queues are dynamically created using the MSG API. Once a message queue has been created any process can send messages to the queue. To receive messages sent to the queue a process needs to open it.
The process that has opened a message queue successfully becomes the sole receiver of the messages arriving to the queue until this relation is terminated by the process failing or closing the queue.
The MSG delivers the message to the destination message queue and from that moment on the opener process of this queue may collect the message. Depending on the selected option the MSG may call back the opener process whenever a new message arrives to queue.
When the opener process collects the messages the MSG returns the messages of higher priority before those of lower priority. Therefore this delivery mechanism may reorder the messages of the same sender. Each message of the queue delivered at most once after which it is deleted from the queue.
Messages that have not been collected yet do not expire from the message queue.
Closing the message queue does not delete the queue or its contents. It terminates the ‘receiver’ relation established by the opener process, which then allows another process to attach itself to the same message queue. This allows for a graceful switchover between processes handling the messages of a queue. For example, when the standby instance takes over the servicing of incoming requests it can just continue with the next message available in the queue.
However when a new process opens the message queue it has the option of flushing its content. Since a MSG implementation may preserve the contents of message queues over cluster reboot, a process may make sure that no faulty information is preserved from the previous run by flushing it first.
Messages are also deleted when the queue ceases. A message queue may be persistent or nonpersistent. For nonpersistent queues the closure also starts a timer—the retention timer. If no other process opens the queue before its expiration then the queue is deleted from the cluster by the MSG. Persistent message queues need to be deleted explicitly by an API user.
7.3.3.3 Message Queue Groups
The MSG offers load distribution among message queues. To apply a distribution policy among a set of message queues they need to be grouped into a message queue group as shown in Figure 7.6.
Senders send messages to a message queue group exactly the same way as to a message queue—that is, by indicating the name of the message queue group. From the sender's perspective it is a single global entity addressed by a name. The sender does not need to be aware whether it uses a name of a queue or a queue group.1
A message queue group is created empty—no queue associated with it. They are added subsequently. The same message queue can be inserted into any number of message queue groups. It will remain the member of a message queue group as long as it exists, the message queue group exits, or it is explicitly removed from the group. When a message queue ceases to exist it is removed from all message queue groups where it was a member.
The deletion of the message queue group has no impact on the existence of the message queues themselves. It only disassociates them, meaning that they stop participating the distribution scheme defined for the message queue group.
The specification defines three unicast and one multicast distribution policies for message queue groups:
- Unicast policies:
- Equal load distribution: Each message sent to the queue group is delivered to one message queue within the group which is selected in a round-robin fashion. This policy is mandatory and should be supported by any MSG implementation.
- Local equal load distribution: The MSG delivers each message to a single queue according to round-robin selection, but priority is given to queues that are opened by processes on the same node as the sender process. That is, queues which are opened by processes on other nodes are taken into account only if there is no queue with a local opener.
- Local best queue: Again preference is given to message queues opened locally and among them to those that have the largest space available.
- Multicast policy:
- Broadcast: The message is delivered to all member message queues that have enough space to hold the entire message (i.e., to preserve message integrity).
In case of the unicast policies if the selected message queue cannot receive the message (e.g., it is full) a MSG implementation may choose between delivering an error to the sender or selecting another queue from the group by applying the same policy. In case of multicast the sender receives an error only if the message could not be delivered to any message queue.
There is no restriction on who can manage a message queue group. Any MSG API user may do so and these manipulations have immediate effect on the group. Processes interested in the changes of the membership of a particular queue group can track the queue group and be notified at any change.
7.3.4 User Perspective
With respect to the MSG an API user need to resolve similar issues as with respect to the EVT. Namely, the naming and other conventions associated with message queues; the life-cycle handling of message queues and groups; and the handling of messages.
In addition the management of the message queue group membership also rests in the hands of API users since the MSG also does not expose any administrative operations or configuration objects in the system information model.
7.3.4.1 Naming and Other Conventions
Sender processes need to know about message queues and message queue groups they need to send their messages. The MSG offers no discovery option.
They also need to be in agreement with the receiver processes about the format, the encoding and the interpretation of the data portion of the messages. The MSG facilitates this task by including in the meta-data portion of a message the type and version fields to characterize the message content, but the specification does not define the usage of these attributes. So their values and the interpretation are again completely open for applications. This is an advantage and a disadvantage at the same time as applications may establish any conventions without any restriction, and they must establish their conventions before being able to use these facilities.
7.3.4.2 Message Queue Management
The MSG also puts the control of the life-cycle of message queues in the hand of the API users.
When a process attempts to open a message queue, the MSG checks whether the queue exists.
If there is no message queue in the cluster by the name indicated in the call then the MSG creates a new queue using the creation attributes of the call and the process opening the queue becomes its sole opener.
If the creation attributes are not provided or there is already a message queue by the same name but its attributes differ from those provided, the opening operation fails.
Otherwise if the queue exists and no other process has it open then the operation is successful and the opener process can start receiving messages sent to the queue for as long as it has the queue open.
If the opener process fails or closes the message queue, it becomes available for other processes to open it, but only one at a time. The MSG enforces this exclusivity therefore no special conflict resolution or coordination is needed on the application's side.
The new opener has the option of flushing or preserving the queue's current content. It can also indicate whether it wants to be called back whenever messages arrive or it will collect the messages at its own pace.
In contrast to event channels, a message sender cannot create a message queue. In fact senders do not need to open the message queue to which they want to send messages. Of course this means that they cannot send messages until a receiver becomes available in the cluster and creates the message queue.
Senders also cannot detect the existence of the message queue in any other way than trying to send messages to it.
Among the creation attributes, the user process indicates whether the message queue is persistent or not and provides a retention time for the later case. The persistency of the message queue indicates who can delete it. Once closed nonpersistent queues remain in the system for the period of the retention time after which the service deletes the queue. Or a user may unlink the queue any time to delete it as soon as it has no opener. Persistent queues can only be removed by explicitly unlinking them.
Unlinking of the queue is not coupled with the opener/receiver role. Any process may delete a message queue using the API. This may happen while another process has the queue opened. In this case the deletion will proceed at the moment the process having the message queue open closes it.
The MSG allows for a very precise management of the service resources. At the creation of the message queue the creator indicates to the service the requested size of each priority area in bytes. In addition the API provides users with functions to check the status of message queues and to set the thresholds for the different priority areas.
There are two watermarks associated with respect to each priority area. The high-water mark indicates the capacity at which the priority area reaches the critical state and may not be able to accept any more messages. The low-water mark indicates that there is enough capacity available in the priority area so that its state can return to noncritical again.
The API function allows the user to set the high- and low-water marks for each priority queue separately.
Whenever the high-water mark is reached for all priority areas of a message queue the MSG generates a state change notification indicating the critical status of the queue. It also generates a notification clearing this condition when at least in one priority area the usage drops below the low-water mark.
To control and calculate the usage is the reason why the API exposes even such detail as the size of the implementation-specific portion of the meta-data.
7.3.4.3 Message Queue Group Management
With respect to message queue groups the specification defines no dedicated role aspects or restrictions. Any process may manage the life-cycle and the membership of a message queue group whether it has any relation to the queues in the group or not.
Anyone or even different processes can configure and reconfigure a message queue group any time during the existence of a message queue group. These changes determine the load-distribution among the processes associated with the message queues and take effect immediately.
When the message queue group is created it is empty. Message queues are inserted subsequently.
While the membership of a queue group can be modified its distribution policy cannot be changed. This may be an issue on the long run because if the initially selected policy needs to be changed, there is no easy way to make the change without the notice of the sender processes.
Processes may track the membership changes. Using the track API a user may find out not only the current members of the message queue group and the subsequent changes, but also the distribution policy associated with the queue.
Tracking can only be started on existing message queue groups, but since anyone may create a message queue group, this is hardly an issue. As a result a want-to-be-sender process is in a better position when it comes to message queue groups. It may create the group and start tracking it so it can send its message as soon as a queue is added to the group.
The MSG provides a callback at the deletion of the message queue group.
7.3.4.4 Message Handling
The guarantees of the message delivery depend on the option chosen by the sender at sending each message. There are four options to choose from:
A sender may decide to send a message asynchronously.
In this case it may or may not ask for any delivery confirmation. Such a call will not wait for the service delivering the message to the message queue. It will return as soon as the MSG ‘collects’ the message from the sender and if the sender asked for it the MSG will provide delivery confirmation once the message has been placed into the message queue.
A sender may send a message synchronously.
In this case, the call returns only when the message has been delivered to the destination message queue. If it is full, it does not exist, or the message cannot be delivered by any other reasons, the call returns with an error. This call provides the same delivery guarantee as the asynchronous version with delivery confirmation. In neither case is it guaranteed, however, that a process will receive the message.
So alternatively a sender may send its message synchronously and request a reply from the receiver all within the same call. In this case the MSG will deliver the message to the destination queue and expect a reply from the process collecting the message from the queue. The MSG delivers this reply at the return of the initiating call.
To ensure that any of the synchronous calls do not block forever the sender needs to provide a timeout.
On the receiving end the MSG calls back the process which has the message queue open provided it has asked for such notification at the opening of the queue. The callback however is not a prerequisite and the opener process may collect the messages any time from the queue. The MSG keeps messages in the queue until a process—the current opener—successfully retrieves them. If there is no message in the queue the get operation blocks for a period chosen by the retriever.
Message handling also involves some similar memory handling issues that were discussed in Section 7.2.4.3 in relation to event handling. Users need to pay attention to these to make sure that the service resources are used efficiently.
7.3.5 Administrative and Management Aspects
The MSG does not expose any administrative operations or configuration options through the IMM. The management of all MSG entities is done via the service user API, so management applications may use this if they need to manage message queue groups or delete message queues. They can use the track API for monitoring these entities.
The MSG does expose runtime objects via the IMM. Through these the status of message queue groups, message queues, and their priority areas can be obtained. For message queues and their priority areas the status information includes among others the allocated and used buffer size, the number of messages in the different queues. For message queue groups it lists the member queues.
The MSG also generates state change notifications via the NTF that management applications or the administrator may want to monitor. However they typically would not be able to act on these notifications as it is the process that has the message queue open, which should retrieve the messages from the queue to free up resources when the queue is in a critical capacity state so even the user applications may want to subscribe for these notifications.
7.3.6 Service Interaction
7.3.6.1 Interactions with CLM
The SA Forum MSG provides its services only to users within the cluster and an MSG implementation determines the cluster membership using the CLM track API [37].
If CLM reports that a node left the cluster the MSG stops serving user processes on that node. If any process on that node has a message queue opened that queue implicitly becomes closed and any other process from within the cluster may reopen it.
By the same note, processes residing on the node that left the cluster will not be able to send messages to any of the message queues or queue groups.
With respect to the message queues and queue groups, the MSG has the responsibility to maintain them in spite of failures. Note, however, that the specification allows the MSG to loose messages from a message queue when it is implemented as node local resource.
7.3.6.2 Interactions with NTF
The MSG generates no alarms, but it generates state change notifications that a MSG implementation shall propagate using the SA Forum NTF.
The MSG specification defines two states for a priority area based on the utilization of its buffer capacity. A priority area enters the critical capacity state when the used space of its buffer exceeds the high-water mark set for it. When all its priority areas are in critical capacity state the message queue is in critical capacity state and the MSG generates the state change notification for the message queue.
When all message queues of a message queue group are in the critical capacity state the message queue group also enters the critical capacity state and the service generates also a state change notification for the entire message queue group.
As soon as in one of the priority areas of any of the message queues of the queue group there is enough space—that is, its used area drops below the low-water mark set for that priority area the state of the message queue to which the priority area belongs and of the entire message queue group returns to noncritical. The MSG again generates a notification about this state change for both the message queue and the message queue group.
To free enough space in a priority area so that its usage drops below the low-water mark, the process which has the message queue open needs to retrieve enough messages from the queue. This means that a process which opens a message queue may also want to subscribe with the NTF to receive the notifications whenever the message queue reaches critical capacity state.
When a message queue is created the high- and low-water marks are equal to the size of the priority area. That is, the critical capacity notification is generated when the queue has already run out of space. To receive the notifications while there is still some capacity available in the queue the opener process needs set the threshold values for the different priority areas as it is most appropriate for itself.
7.3.6.3 Interactions with IMM
Since the MSG does not expose administrative operations or configuration objects, the only interaction between MSG and IMM is to reflect its different entities as runtime objects in the information model. Accordingly, a MSG implementation needs to register with IMM as the OI for these classes and use the OI-API to create, delete, and modify the objects.
Most of the attributes of the MSG object classes are cached, which means that it is the service implementation's responsibility to update these attributes in the information model. For IMM to be able to obtain from MSG the values of noncached runtime attributes, the service implementation needs to provide the callback functions at the initialization with IMM.
7.3.7 Open Issues and Recommendations
The SA Forum MSG specification is also one of the first AIS services defined as the cluster being a distributed system the need for reliable, location independent communication service that can be used between cluster entities is obvious. We can make a step further, the need is for service interaction rather than the interaction between the service provider entities as the latter may fail at any time and be replaced by other providers momentarily, but this should not reset the service interaction.
The SA Forum MSG addresses these needs and provides a rich set of APIs that application developers can use to build highly available applications. It provides synchronous as well as asynchronous APIs for sending messages thus accommodating a variety of programming styles and providing different delivery guarantees.
One of the key differentiator of the SA Forum MSG is the decoupling of the life-cycles of the message queue and the process that created and opened it. This provides an isolation that enables the survival of messages in the queue that has not been consumed yet and that can be consumed by another receiver thus effectively continuing the service interaction.
Since these features typically hamper performance it would have been nice if the specification also considered options that target high performance and low latency cases. This way, users could use the same programming paradigm for all their communication needs.
The MSG also addresses the load distribution among service provider entities. It allows for grouping of message queues together in to message queue groups and defining a distribution policy—one of the four policies defined by the specification—which then will be applied by the MSG implementation to distribute messages among the queues of the group. The configuration of the message queue group can be changed dynamically at runtime by adding and removing message queues and therefore adding or removing processing capacity according to the actual needs. These changes also can be tracked by interested entities.
A somewhat controversial point of the MSG specification is the statement that it permits the loss of messages if the message queue is implemented as a node local resource. Unfortunately an application cannot determine whether this is the case or not, and it also contradicts to the intention of the MSG providing reliable communication facilities as well as message queues being cluster-wide entities.
As a result if an application targets any MSG implementation it may decide to prepare for the worst, which hampers significantly performance while in most cases this is completely unnecessary. MSG implementations typically do provide the reliable communication facilities as intended by the specification as this is the main distinction between the MSG and traditional communication facilities and also from the EVT.
Using the MSG an active components and its standby may reliably exchange their state information so that they stay in sync with each other and the standby can take over the service provisioning whenever the active fails.
Alternatively the two parties can receive the same message simultaneously and, for example, the active may react by providing the service, while the standby only uses the message to update its state, so it can take over the service provisioning on a short notice.
So the question is whether with MSG we have the perfect solution for the communication and state synchronization needs to provide SA.
7.4 Checkpoint Service
7.4.1 Background: Why Checkpoints
Applications that need to be highly available are often state-full. In other words the active instance of such an application often has state information, which is critical for service continuity and needs to be shared with the standby in order to enable the standby instance to take over the active's responsibilities within a bounded time-frame. In Chapter 6 we presented the stopwatch service as an example for which the elapsed time is such a state information that enables another process to resume the service in case of the failure of the first process.
There are different possibilities to propagate this information. The first option is that the process which actively provides the stopwatch service regularly sends updates to its standby process about the elapsed time it has measured.
In general when a message-based state synchronization is used, the active instance packages, marshals, and transmits to the standby the data that describes its state. The standby instance receives, unmarshals, and seeds its data structures to mirror the state of the active. To keep the standby in sync with the active subsequently only the changes need to be sent as updates.
Such message-based synchronization can be implemented using either the EVT or the MSG presented in the previous sections. It provides a fast update of the standby instance's state, but this scheme may require complicated application logic to keep the state information consistent between the active and the standby instances. The standby may need to receive all messages in correct order. In addition if the standby fails the new instance needs to receive from the active instance all the state information again creating an overhead that may hamper the performance of the regular workload.
A storage-based synchronization scheme could eliminate these issues therefore the SA Forum defined the CKPT.
Since the writing to the checkpoint is performed normally by the active while serving its clients the operation needs to be efficient. Some applications may have performance constraints that can be fulfilled only by local write to memory, which is volatile.
Considering our stopwatch example or any other case it is essential in that if the active instance fails due to a node crash, the state information, for example, the record of the elapsed time survives this node crash. So another expectation towards the CKPT is that it ensures that checkpoints survive node failures. This typically involves multiple replicas of the data on different nodes.
This creates the third expectation that the CKPT maintains all the replicas of a checkpoint without the involvement of the applications.
Depending on the number of replicas this operation can be rather heavy therefore we would also like to be able to tune the update operations so that one can achieve an optimal trade off between reliability and performance.
In our example the elapsed time can be recorded as a single string or an integer, but applications may have elaborated data structures describing their state. It is vital that not the entire data content needs to be exchanged at each update or at each read operations, but that the changes can be done incrementally for both write and read operations.
The SA Forum CKPT addresses all these requirements and therefore enables applications to keep their standby instances current with the state of the active instances.
Let us see in more details what features and options the CKPT offers to its users.
7.4.2 Overview of the SA Forum Checkpoint Service
In the CKPT the SA Forum provided a set of APIs that allow application processes to record some data incrementally that can be accessed by the same or other processes. As a result these data records—if storing in them some state information—can be used to protect an application against failures by using the data to restore the state before the failure.
For example, for an application that processes voice or video calls it is important that the information about ongoing calls that the active instance is handling—the state information for this application—is replicated in the standby instance so that it is ready to step in to replace the active at any point in time. For this purpose the application can use the CKPT: The active instance would create a data structure—a checkpoint—using the service API to store all the information needed about the ongoing calls and update it as some of the calls complete and new ones are initiated. The standby can access this checkpoint also using the CKPT API regardless of its location. That is, checkpoints are global entities as reflected in Figure 7.7.
Figure 7.7 Checkpoint are cluster-wide entities maintained as a set of replicas located on different nodes.
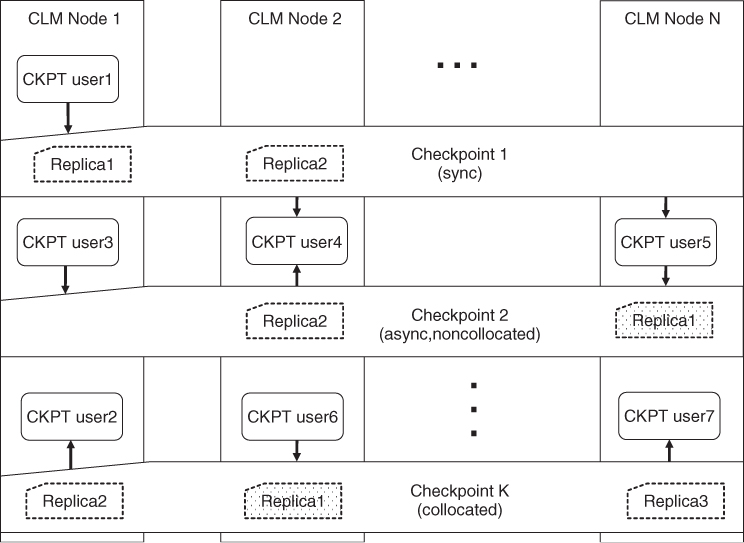
If and when the active instance fails the standby is told by the availability manager—for example, the SA Forum AMF—to assume the active state. Since the standby already has or can obtain from the checkpoint an accurate record of the state of the ongoing calls it has a detailed knowledge to assume the active state seamlessly.
For performance reasons the specification requires that checkpoints are stored in the main memory rather than on disk. That is, this data is not persisted. Nevertheless the CKPT implementation will make all possible precautions against data loss. This means that the service implementation maintains multiple copies or replicas for each checkpoint in the system on different nodes so that a node failure causes no data loss.
Accordingly, checkpoints do not survive cluster restart or reboot, not even the restart of the CKPT itself. The CKPT is not suitable for data that needs to be kept through these global operations.
The CKPT synchronizes the checkpoint replicas without any user assistance. The user may create a checkpoint with either synchronous or asynchronous synchronization mode. In case of synchronous updates the write operations initiated on the checkpoint return only when all the replicas have been updated and the caller is blocked for the entire operation.
In case of asynchronous updates the write operation returns as soon as one replica—the primary or active replica—has been updated. Thus, the process that initiated the write operation gets back the control and can continue with its job while the CKPT takes care of the update of all other replicas of the written checkpoint.
This way the application may achieve a better performance at the expense that a given moment in time the replicas may not be identical, which imposes some risk as the active replica may be lost due to a node failure, for example, before the service had the chance to propagate the update to other replicas. Applications need to consider this risk.
The performance of asynchronous updates can be further improved by using collocated checkpoints.
Normally it is the CKPT implementation, which decides on the number and location of the replicas. In case of a collocated checkpoint this decision is given to the application, which can choose when and where to create checkpoint replicas and which one of them is the active at any given moment in time.
Similarly to the nonpersistent message queues of the MSG checkpoints also have retention time as well as close and unlink operations. When the checkpoint has been closed by all users the CKPT keeps the checkpoint for the period of the retention time. Once this expires the CKPT automatically deletes the checkpoint with all its replicas. A user may also ask the deletion of the checkpoint explicitly with the unlink operation in which case as soon as all users close the checkpoint it is deleted by the service. That is, no coordination is needed on the application side.
While the Event and the MSGs of the SA Forum can be used for the communication between processes of the same application and different applications, the CKPT is primarily intended to be used those of the same application. It is a cluster-wide equivalence of processes communicating through shared memory. It is geared toward the needs of state synchronization between active and standby instances of the same application.
7.4.3 Checkpoint Service Model
7.4.3.1 Checkpoint
A checkpoint is a cluster-wide entity managed by the CKPT. It has a unique name in the cluster, which is used by the different processes to access the checkpoint from anywhere within the cluster. Processes store data in a checkpoint, which in turn can be read by same or other processes as necessary. The same or different processes may have the same checkpoint open many times simultaneously.
For performance reasons checkpoints are stored in memory therefore to protect against node failures the CKPT typically maintains multiple copies of the checkpoint data on different nodes of the cluster. These copies are called replicas of the checkpoint and at most one of them may exist on each node.
Each checkpoint is characterized by a set of attributes specifying the checkpoint's name, size, creation flags, retention duration, and the maximum size and number of sections it may contain Figure 7.8.
Figure 7.8 Checkpoint organization.
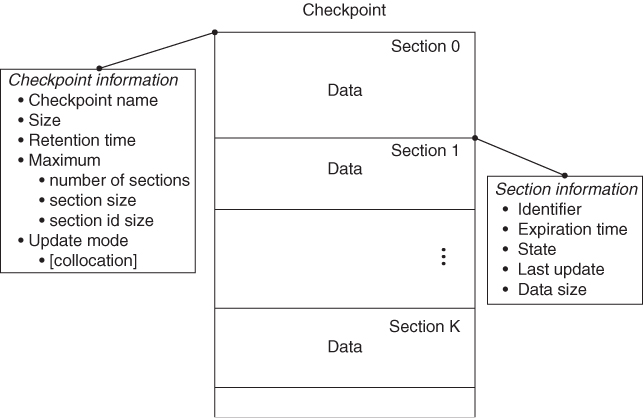
The creation flags indicate whether the replicas are updated synchronously or asynchronously and in the later case whether atomicity is guaranteed and/or if the checkpoint is collocated, that is, the user controls the replica creation.
The atomicity guarantee means that when an update operation returns successfully it is guaranteed that the active replica contains all the changes proposed by the operation. If it fails then no change is made to the active replica.
The CKPT maintains the status of each checkpoint. Whenever any of the maximums defined for the checkpoint is reached it becomes ‘exhausted’ otherwise it is ‘available.’
The user data is stored in a checkpoint in sections discussed next.
7.4.3.2 Section
Each checkpoint has one or more sections up to a maximum number defined at creation Figure 7.8.
A section contains raw data without any particular structure as far as the service is concerned. Again any structuring, interpretation, encoding, and so on, are all concerns of the application using the CKPT.
Each checkpoint is created with at least one section. Additional sections can be created and deleted by users as needed up to their defined maximum number.
Each section is identified by a section id which could be user defined or generated by the CKPT. If the checkpoint is created with a maximum of one section then this section is called the default section and has a predefined id.
Each section also has an expiration time. This is an absolute time specifying the moment the CKPT should remove the section automatically. It is like the expiration date on meat products, which must be cleared from the selves ‘automatically’ when the date is reached. Unlike with meat products, the section expiration time can be updated if needed—for example, each time the data in the section is updated—or even set to the ‘end of time’ value to never expire like in the case of the default section.
Sections also have a state. In most cases it is valid, but if the checkpoint is asynchronous with weak writes (i.e., the atomicity of updates is not guaranteed) then it may happen that a write operation returns with an error while the sections to be updated are only partially written and therefore those that have been changed become corrupt.
Finally the CKPT also keeps track of the last update of each section.
After creation sections can be updated individually by overwriting the section or as part of a write operation performed on the checkpoint that updates multiple sections identified by their ids.
Since sections are dynamically created and deleted throughout the checkpoint's life time one may discover them by iterating through them.
7.4.3.3 Replicas
As we mentioned already to protect against data loss the CKPT maintains multiple replicas of each checkpoint on different nodes in the cluster as shown in Figure 7.7. On a given node there is always at most one replica of a given checkpoint.
Replicas may be managed by the CKPT implementation completely (i.e., without any user participation) in which case the service determines the number of replicas maintained in the cluster and their location. The user has no control over them. This may not be an issue when all replicas need to be in synch all the time and therefore the checkpoint is created in the synchronous update mode. Synchronous update guarantees that write operations return only when all replicas were successfully updated or the operation failed and therefore none of them has changed. To maintain consistency and atomicity the CKPT implementation would need to use special protocols known from the database technology (e.g., two-phase commit protocol [84]), which require significant time.
Alternatively to improve performance, a checkpoint can be created with asynchronous updates. In this case there is the notion of the active replica, a particular replica on which the write operations are performed. A write operation returns as soon as it has updated the active replica or the operation failed. The CKPT implementation updates the remaining replicas asynchronously from the write operation while the process that updated the replica can carry on with its task.
This means that even read operations need to target the active replica it is the only one which is guaranteed to be up-to-date. So the replicas are there really for the protection of the checkpoint data and not, for example, to provide local access. Other replicas may lag behind as the service implementation propagates the changes to all of them.
For an asynchronous checkpoint the CKPT still manages the number of replicas, their location, and also the selection of the active replica. This option suites the case when multiple processes write to the checkpoint simultaneously from different nodes, so there is no favored location for the active replica or the replicas in general. For example, in a service group using the N-way-active redundancy model all active components of a CSI may need to update the same checkpoint.
When there is a particular process or component which does the updates of the checkpoint the update operation can be optimized by making sure that the active replica and this updater process or component are hosted by the same node and therefore the update is a local operation.
To achieve this, the CKPT has the notion of collocated checkpoints. For example, components protecting a CSI according to the N-way redundancy model may take advantage of this update mode as it is always the active component which writes the checkpoint and the standbys read it. Even though the read operation is remote in this case because the standbys do not provide the service like the active does the delay is less likely to impact service performance.
The replicas of a collocated checkpoint are managed by the users of the checkpoint. Whenever a user opens such a checkpoint the service implementation makes sure that there is a local replica of the checkpoint on the node this opener is running. It is also the users who decide which of these replicas is the current active. If there is no active replica at a given moment the checkpoint cannot be read or updated.
In case of collocated checkpoints, it is also the users' responsibility to create enough replicas so that there is enough protection against data loss. They may want to ensure also that there are not too many replicas to hamper performance by the extra replica update operations.
Note however that for collocated checkpoints the opening and closing operations are not symmetric. While the service ensures a local replica for each open the opposite is not true for closure, that is, the service is not required to remove the replica if there is no other local opener. In general, the specification does not define how long replicas exist in the system and it is left to the discretion of the service implementation.
7.4.4 User Perspective
To access and interpret the checkpoint data application processes also need to agree on the name of the checkpoint and the data organization and interpretation. Since checkpoints are typically used among processes or components of the same application these conventions are less of a concern that they were for the EVT and MSG.
In case of the CKPT the different life-cycle management and data access are the main focus of the user applications. Depending on the update mode selected at the checkpoint creation time the user application may need to manage the life-cycle of the sections and the checkpoint itself and in addition it may have the responsibility of managing the replicas as well.
7.4.4.1 Checkpoint Creation and Opening
After initializing the CKPT to be able to use a checkpoint a user process needs to open it.
At opening a checkpoint the service implementation checks first if a checkpoint by the given name exists already or it needs to be created. If it does not exist the creation attributes indicate the checkpoint's features such as the update mode, the different size limits, and the retention time. To successfully create the checkpoint the user also needs to permit the creation by setting a flag, which protects against accidental creation. If this is not set then the user can open only an existing checkpoint for reading, writing, or both. If the creation flag is set and the checkpoint exists then the creation attributes are compared with the features of the existing checkpoint and the call succeeds only if they are the same. All these checks allow seamless creation and opening of checkpoints without particular synchronization among the user processes accessing the checkpoint potentially simultaneously while preventing accidental creations or duplications.
Note that a checkpoint can be opened using a synchronous call, which blocks the caller for the time of the operation, or through an asynchronous, nonblocking call. These are not to be confused with the update mode of the replicas, which depend on the setting of the creation flags within the creation attributes.
A user can check these attributes of an existing checkpoint by getting the status of the checkpoint. This will also include the current number of sections and the memory used to store checkpoint data.
7.4.4.2 Write Access
After opening the checkpoint the user will be able to perform on it only the operations that were indicated in the open flags of the open call, which is the standard way for databases. Comparing to databases, however, the CKPT does not provide concurrency control such as exclusive access to the checkpoint or its portion. As mentioned earlier, many users may open a checkpoint simultaneously and they are able to read or write it simultaneously. If concurrent access is an issue the users need to resolve it among themselves by other means, for example, by using another AIS service: the Lock service [45].
The reason why the CKPT does not provide concurrency control is the consequence of its intended use: It was designed for efficient checkpointing of some entity's state related to a job it is performing so that another entity, a standby, can stay in sync and take over the job in case the first fails. That is, the assumption is that there is only one entity (e.g., process, component) writing its state and one or more others reading this information. Even if there is more than one entity that writes the same checkpoint, they are assumed to write to different sections.
Under these assumptions concurrency control would add an unnecessary overhead and slow down a CKPT implementation. We mention these assumptions as they limit the CKPT's applicability.
7.4.4.3 Section Management
Users who opened a checkpoint for writing can create new sections in the checkpoint and fill these sections with data. Each of these sections has an expiration time—an absolute time—when the data contained in them becomes obsolete. The nice feature of the CKPT is that it does the clean up for its users based on the expiration time. When the expiration time is reached for a section the CKPT automatically deletes the section from the checkpoint. Based on this feature a user may come up with different strategies: It may create a section and overwrite it as necessary, or add a new section each time with the new data ‘a la EVT.’ All depends on the needs of the given application.
Existing sections can be written individually or simultaneously respectively using the overwrite or the write operations. In both cases the section(s) to be written is identified by the section id given at the section creation. The overwrite operation as its name indicates overwrites the selected section completely and the new data size becomes the size of the section. The write operation on the other hand writes portions of different sections starting from the given offset. Many section and multiple portions of the same section can be written with a single write operation.
If the checkpoint is updated synchronously when either of the write operations return successfully all replicas have been updated with the new data.
If it is a checkpoint with asynchronous update then only the active replica was updated and the CKPT will propagate the change to the other replicas in due course. This however implies some risk as if the active replica gets lost to a failure or the node leaves the cluster before this happens then the changes will be lost. It is also not necessary that all changes are propagated to all replicas at the same time. Service implementations are free to use any suitable update protocol.
Further risk is introduced by the weak update mode of asynchronous checkpoints. This means that when any of the write operations return with an error, some of the changes might have been applied to some sections and therefore corrupt their data. From a service implementation perspective this means that when updating such a checkpoint the data can be changed directly in the active replica. There is no promise of the ‘all or nothing’ atomicity and therefore the operation can be faster at the price of a greater risk.
7.4.4.4 Replica Management
With respect to the asynchronous checkpoints we also need to mention the collocated option as in this case the user application has to take the responsibility of managing the replicas.
First of all replicas are created only due to user actions: When a user process opens a checkpoint on a node that does not host a replica for it, the service will create a new replica locally. This means that to protect the checkpoint data adequately the users need to open the checkpoint from different nodes so that the replication occurs.
Considering that in a cluster the user processes may not be in control of their location this seems to be an odd requirement toward applications considering the goal of the SA Forum.
In reality this checkpoint option assumes that the user processes are part of components managed by AMF that form a protection group. In this case, AMF will make sure that these components are running on different nodes and therefore they only need to coordinate their management of the checkpoint replicas with the assignments they receive from AMF for the associated with the checkpoint CSI. So the checkpoint collocation mechanism actually makes sure that mechanism replicating a checkpoint and the processes accessing this checkpoint and its replicas are not controlled by different tunes of different managers, but they are synchronized under a single manager, which is AMF.
7.4.4.5 Access for Read
To read a checkpoint a process needs to open it with the read flag set. In this case the creation attributes and flags do not need to be set.
Once a process has successfully opened a checkpoint for read, it may collect any stored information any time provided it is aware of the checkpoint structure. The process needs to know at least the section ids so that it can indicate in the read request the sections it wants to read, they need to be named explicitly.
The process may or may not provide buffer space for the actual data. In the latter case the CKPT will make the memory allocations that the process will need to free once it processed the collected data.
If the process is not aware the actual contents of the checkpoint it can use the checkpoint status get and the section iteration API to collect the information needed to formulate a valid read call.
For the interpretation of the checkpoint data again user processes need to follow some conventions; however as we have mentioned, since these are assumed to be processes of the same application the issue should not be critical.
The concurrent access may also require considerations at read access. Since a user may read a checkpoint while another user is writing it. As the CKPT is not required to provide concurrency control, the data obtained by the reader may be inconsistent, that is, partially written at the time of the read. Service implementations, however, may provide stronger guarantees.
As opposed to the EVT and the MSG, the CKPT does not provide any API through which it would inform its user processes that opened a particular checkpoint for reading that the checkpoint has changed. This is probably the greatest issue with the CKPT specification available at the time of writing.
The reader processes may use different strategies to keep up to date with the changes. This may range from reading the checkpoint at given intervals to relying on the service assignments performed by AMF or using the CKPT with EVT or MSG in tandem and communicate the fact of the updates through them.
7.4.4.6 Removal of Checkpoints
Application processes indicate to the CKPT that they stopped using the checkpoint by closing it. This does not remove the checkpoint from the system as other processes may have the same checkpoint open. Furthermore, even if there is no other opener at a given moment the checkpoint remains in the system for the retention time. This allows a second dimension of user processes to exchange data using checkpoint. That is, a subsequent incarnation of a component may read the stored state of a previous incarnation and therefore become capable of continuing some task from where its predecessor left of.
To remove a checkpoint a user process needs to unlink it. This deletes the checkpoint and all its replicas immediately if there is no other opener in the cluster. If there is, the service maintains the checkpoint until no opener remains. During this existing openers can use the checkpoint without any change, while new open requests of a checkpoint with the same name will create a new checkpoint.
7.4.5 Administrative and Management Aspects
The CKPT maintains an information model as part of the system information model. This reflects the checkpoints and their replicas existing at any given moment in the system. Both checkpoints and their replicas are represented by runtime objects created and deleted by the service as these entities are created and destroyed dynamically in the system.
For a checkpoint the representing object contains the creation attributes and creation flags discussed in Section 7.4.3.1 and related statistics such as the total number of openers, and the readers and writers among them; the number of replicas and the number of sections and how many of them are corrupted.
For each replica the only attributes reflected in the model are the replica name and whether it is the active one. An object representing a replica is a child of the object representing the associated checkpoint. From this information one cannot deduce the location of a replica and, for example, an administrator may accidentally lock two cluster nodes simultaneously that host the only replicas for a checkpoint.
Since each CLM node may host only one replica for a given checkpoint the replica object can be interpreted as an association object between a checkpoint and a CLM node. With this interpretation and the rules presented in Chapter 4 the replica Relative Distinguished Name (RDN) would need to be the Distinguished Name (DN) of the hosting CLM node, which combined with the checkpoint's DN creates the replica's DN. As a result the information model can reflect not only the number of checkpoint replicas existing in the system, but also their location. This usage has been discussed by the Technical Workgroup of the SA Forum and accepted for a future—at the time of the writing—release of the Checkpoint specification.
The CKPT specification defines no administrative operations or configuration objects. But a service implementation should generate notifications related to the checkpoint status discussed in the next section.
7.4.6 Service Interaction
7.4.6.1 Interactions with CLM
In an SA Forum system the CKPT is only provided to user processes residing on CLM member nodes therefore the service implementation needs to track the membership information using the CLM API [37]. Whenever the CLM reports that a node left the cluster, the CKPT implementation needs to stop serving user processes on that node. It must also consider any lost checkpoint replica that was stored on that node, which means that it may need to restore the missing replica on a node within the cluster.
The service implementation is responsible for the replication of noncollocated checkpoints; therefore for them this loss automatically triggers the replication process.
In case of collocated checkpoints it is the user's responsibility to restore the redundancy if needed. If the process with whom the replica was collocated was managed by AMF then AMF will apply the required recovery actions, which should trigger this restoration if the components coordinate their assignment with the checkpoint access properly.
Since the CKPT exposes the checkpoints and their replicas through the information model it may need to adjust the picture to the CLM changes.
If more than one node leaves suddenly the cluster it is also possible that the CKPT loses all the replicas for some of the checkpoints. This is acceptable according to the CKPT specification, but considered a rare event and therefore the higher performance achieved by storing replicas in memory outweighs the risk of data loss.
7.4.6.2 Interactions with NTF
Even though it might be significant for some the loss of all replicas for some checkpoints the CKPT specification at the time of writing defines no alarms for such a case. It only specifies state change notifications that a CKPT implementation shall generate for a checkpoint when the resources usage exceeds the level defined for the checkpoint at its creation. To propagate these notification CKPT implementations shall use the SA Forum NTF [39].
The CKPT generates the checkpoint section resources exhausted notification in two cases:
- If the maximum number of sections defined for the checkpoint has been reached; or
- If the maximum checkpoint size has been reached, that is, the total amount of data stored in the different sections is equal to the maximum size defined at creation.
Notice that neither of these indicates error conditions as the checkpoint can be still updated by overwriting the existing contents. So if a checkpoint is permanently in this state that may just mean a very efficient use of the service resource.
The reason to worry comes only when a write access fails with the SA_AIS_ERR_NO_RESOURCES error code.
As soon as both resources show availability again the service generates the checkpoint section resources available notification.
7.4.6.3 Interactions with IMM
As discussed the CKPT exposes in the information model the checkpoints and their replicas as runtime objects. That is, an implementation needs to register with IMM as the OI for the classes of these objects (SaCkptCheckpoint and SaCkptReplica) and use the IMM OI-API. Since the service offers no administrative operations the only callback it needs to provide is related to the non-cached attributes of the SaCkptCheckpoint class. Since these are not cached they are updated on user request, which IMM receives at its Object Manager API and forwards to the service implementation.
As checkpoints and their replicas are dynamically created and removed from the system the CKPT implementation reflects them in the information model. IMM and the information model is the only window the CKPT provides for its internal behavior that management applications can rely on across service implementations.
7.4.7 Open Issues
The main issue with the current CKPT specification is that it does not provide a push or callback mechanism for reader processes that a checkpoint has been updated. Interested parties need to pull the information or use other mechanism, other services to propagate the information.
The issue has been discussed in the Technical Workgroup of the SA Forum and a tracking interface was proposed to resolve the issue. It follows the track API defined in the programming model (Chapter 11) and existing in other services like CLM or AMF.
This solution facilitates the implementation of the so-called hot standby without the use of additional services as the standby component gets the notifications and can obtain in a timely manner any change the active component makes available through the checkpoint.
A second issue that may qualify as open is whether the CKPT should generate an alarm when all replicas of a checkpoint are lost. The reason the specification does not require this is that alarms are intended to be delivered to the system administration for resolution but this is not possible as the CKPT exposes no administrative operations or configuration options as discussed in Section 7.4.5.
Nevertheless the reason behind the loss could be an administrative action performed on the cluster membership, for example, locking all nodes that hold replicas for a given checkpoint. Since the objects representing the replicas in the information model do not reflect their location this is quite possible. Using a naming schema suggested in Section 7.4.3.3 provides a solution, but it also implies that when nodes leave the cluster the objects representing the checkpoint replicas must be removed and recreated as the service restores them, which might generate extra load toward IMM.
Some consider that replicas should not be reflected in the information model at all as their dynamism creates to much load on IMM already.
There were also considerations to provide options for API users and/or system administration to configure the replication aspects of the service. For example, to allow a user process creating a checkpoint also to identify the CLM nodes it desires to host the replicas even in case of noncollocated checkpoints.
Practice shall show whether these issues are indeed important and need to be addressed. At the moment the real demand only supports the introduction of the track API.
7.4.8 Recommendation
As we discussed in Section 7.4.4 the concept of collocated checkpoints is suited for the use of the CKPT by components of applications managed by AMF. However the processes of the component interacting with the CKPT need to act almost like proxies between the AMF and the CKPT to achieve the desired behavior.
It may seem that this option is putting a lot of responsibility on the user application it requires very little extra compared to just using the CKPT with its built in mechanisms: The application only needs to manage the active replica selection according to AMF's orchestration of the HA active state and coordinate the access to the checkpoint with the assignments. These measures provide automatically the protection level appropriate for the redundancy model and the performance optimization for the write access. In all other cases applications may consider the use the built in mechanisms of the CKPT.
Since the CKPT provides data replication and stores the replicas in memory. It may be looked at as a high performance alternative for databases for more transient application data which is incomplete or irrelevant at cold start such as application or cluster restart, but which improves performance at runtime. In particularly data that supports the service recovery aspects of an application. To allow recovery after cold start the relevant information needs to be stored persistently on a disk and it is usually referred as backing up the application data and it is typically a demanding operation.
Checkpoints are viable alternatives that are much less demanding and that can be used in combination with, for example, logging to provide the needed protection between two backups. The backup and the log together provide protection for the case of cold restarts while the checkpoints allow for quick failovers and switchovers.
Compared to real databases the CKPT does not provide concurrency control, so if this is necessary the Lock service or other mutex mechanism can be used.
7.5 Conclusion
7.5.1 Common Issue: Entity Names
Before concluding this chapter we need to mention a reoccurring issue that we did not discuss at the particular services as it exists for all of them. It is the issue already mentioned in Chapter 4 at the discussion of the naming of runtime objects.
The problem is that all three services of this chapter reflect their service entities in the information model as runtime objects. The DN of these objects is given to the service implementation by the user application, which may be written at the time when the actual information model of the system is not known. Since it is a DN which is given, it implies the DNs of all the ancestor objects for the runtime object to be created.
In other words the name of an event channel, a message queue, a message queue group, or a checkpoint determines where the runtime object representing the entity is inserted into the information model. This implies that at naming of these entities one needs to take into consideration of the persistency and the life-cycle of all the parent objects.
As a result it might be tempting to put these objects directly at the root, but not desirable to do so. Instead one option is to insert these objects under the object representing the appropriate service itself. Alternatively a process which is part of an AMF component can find out using the AMF API about the component name and as a result the application's name (since it is part of the component name). In addition such a process can find out about the CSI names assigned to the component, which are most likely associated with the use of these service entities.
7.5.2 Conclusion
In this chapter we presented the three most often used utility services of the AIS defined by the SA Forum. They allow different ways of communication between application processes among others for the purpose of synchronizing their states when collaborating in the provisioning and protection of some services. That is, at providing SA, which is the aspect we are most interested in this book.
These services are the EVT, the MSG, and the CKPT. All three services offer solutions that decouple the communicating parties that need to share some information. For the purpose of this communication the parties synchronize through the respective service entities, the names of which are the minimum required shared knowledge among the involved parties.
Beyond this information the presented services require no or minimal synchronization from the user application even with respect to the life cycle of these service entities. It is actually an application choice whether this life-cycle synchronization is expected or not. That is, both parties the senders or the information owners and the receivers—the information user may create the service entity through which the information exchange is conducted.
Most importantly these service entities are cluster-wide and therefore location transparent allowing for failure recoveries transparent for the application service users and application service providers alike.
The SA Forum EVT provides a publish/subscribe based communication mechanism that can be used among multiple anonymous processes of the cluster. Publishers and subscribers may join and leave ‘the club’—represented by an event channel—as they please. Publishers do not know about the receivers of their communication. On the other hand receivers have enough knowledge about the expected communication so that they can subscribe to them even if they do not know the exact identity of the publishers. Event channels have some ‘memory’ as they can retain events if needed for potential late comer subscribers, but overall the service provides best effort delivery.
The SA Forum MSG provides a communication mechanism, which can be tuned for greater performance or more reliability. The basic service entity is the message queue, which is an input queue for a set of processes collaborating in the protection of the service represented or requested through the messages delivered by the queue. Any number of anonymous senders may send messages to the queue processed by a single receiver at a time. In case of the failure of this receiver the message queue acts as a buffer until the new receiver takes up the message processing task.
When message queues are combined into message queue groups the MSG also provides a load distribution mechanism among multiple message processors.
If not for the creation of message queues, the message senders may not be aware whether they send their messages to an individual message queue or message queue group. The method of communication is somewhat alike to data streaming where if part of the data is missing the whole stream may need to be retransmitted.
Finally the SA Forum CKPT provides a cluster-wide equivalence to shared memory based communication. The service entity representing this ‘shared memory’ is the checkpoint which is accessible from anywhere in the cluster for processes needing to write or read part or the entire data. It conveniently holds the complete picture of the information to share at any moment in time like series of snapshot that follow one another without the need to keep the history of changes.
Since checkpoints are stored in memory the service allows for fast dissemination of any information and it is the reader's choice whether it reads the entire checkpoint or just the relevant or updated parts of it.
The CKPT offers options particularly tailored for applications managed by the AMF so that the data replication performed by the CKPT is in complete synchronization with the redundancy of service provider entities under AMF control.
As none of these services impose a format on the units of communications used with their service entities (i.e., events, messages, and sections) application designers have a lot of freedom in defining the layout that is most suitable for their application. But this also imposes the limitation as for successful communication the sender and the receiver need to be in an agreement about the interpretation of these data structures.
Therefore the scope within which this agreement exists determines the scope within which the services can be used. As a result without further standardization of at least the negotiation mechanisms all three services discussed are most suitable for intra-application communication. In combination with existing standards (e.g., higher level communication protocols, other AIS services) however they can be extended beyond the application limits and suddenly the MSG can be used as a load balancer front end for web services or the EVT can be used as the carrier of alarms and notifications as defined by NTF.
1 Since the RDN attribute type is different for message queues and message queue groups the DN indicates which is the case.