
Chapter 8
Services Needed for System Management
8.1 Introduction
System management is the cornerstone of maintaining high service availability (SA). It allows the configuration and reconfiguration of the system, monitoring its operation and it is essential for fault management. We have seen that the Availability Management Framework (AMF) [48] is the first line of defense when an error is detected. It uses redundancy and deploys recovery and repair actions to recover the system's services in the shortest possible time. However this may not be enough to prevent future problems. As we discussed in Chapters 1 and 6 an error is only the detected manifestation of a fault, recovering from and repairing the error may not repair its root-cause—the underlying fault.
To prevent future problems we need to go further and analyze the situation to find this root-cause of the detected error or errors, which requires more information from the system. Therefore systems built for SA systematically collect data that may reveal any information about any faults in the system.
Within the SA Forum Application Interface Specification (AIS) two services provide such capabilities. These are the Log service (LOG) [40] and the Notification service (NTF) [39].
The LOG provides applications with an interface to record any data that they consider important among others for fault management. Applications may create new or open existing log streams each of which is associated with one or more log files where the data inserted by the application is preserved for some period of time according to the policy defined for the log stream. The contents of these files may then be harvested periodically for offline analysis of the system or particular applications. Most importantly neither the LOG nor the other SA Forum specifications define the contents or the format of the log files. They are tailored as needed. The formatting information for each log stream is available for potential readers as a separate file, which needs to be collected together with the log files.
The LOG is suitable for collecting large amount of data from the system typically used in offline analysis.
For cases when a prompt reaction may be necessary to the events occurring in the system the AIS includes the NTF.
The NTF defines different categories of notifications, their contents, and format each indicating some kind of incident. Management entities in the system subscribe to the category and class of notifications they are capable of handling. Applications as well as system services generate the notifications whenever a significant event occurs and provide the contents as required via the NTF interface.
Most of the notifications are intended for the consumption of management entities within the system. We will see such an example with the Software Management Framework (SMF) [49], which is such a management entity and correlates an ongoing software upgrade with the errors reported within the system.
However not all situations can be handled within the system. Notifications that report situations where external intervention or administrative attention is required comprise the categories of alarms and security alarms. From an operator's perspective in telecommunication systems an alarm signals a situation requiring human attention or even intervention and therefore such an alarm often results in turning on an alarm sound signal and/or dispatching a call, an SMS to the person on duty in addition to logging it in the system logs and reflecting it on the management interface.
So the system administrator when receiving an alarm needs to act on it. This is the point when the third AIS service, the Information Model Management service (IMM) [38] comes into the picture. As mentioned several times in this book it stores the information model for the different services and combines them into a consistent system information model. The information model reflects the state of the system and it also acts as a management interface. Accordingly the IMM exposes an object management (OM) interface through which the managed objects of the information model can be manipulated. The administrator can create, delete, and modify configuration objects and issue administrative operations on both runtime and configuration object as appropriate. The OM-API, application programming interface is often referred to as the northbound or management interface of a system.
As discussed at the introduction of the system information model and at each of the services the objects of the information model reflect entities or logical concepts meaningful only for the service or application for which they have been defined. Therefore the manipulations carried out by the administrator on the managed object needs to be delivered to the service in charge of the object. In IMM terms this service or application is the object implementer (OI) deploying the managed object in the system and for this interaction the specification defines the OI-API.
Each time an object is manipulated via the OM-API, IMM delivers the actions to the OI associated with the object via the OI-API and returns any received outcome to the manager via the OM-API. IMM only acts as a mediator; the whole transaction is opaque for IMM.
In this chapter we will take a closer look at each of these AIS services starting with the LOG then moving onto the NTF and finally concluding with the IMM.
8.2 Log Service
8.2.1 Background: Data, Data, and More Data
As we pointed out in the introduction the main purpose of the LOG is to collect data from the system that can be used for root-cause analysis to diagnose problems that occurred during operation so that similar situations can be prevented in the future. Probably the most difficult question to answer in this respect is what information is useful for this purpose and what would be superfluous.
To answer this question we need to look at who is the user of the collected information. The users of the data collected by the LOG are the system or network administrators or tools at their level. In any case they have a general overview of the system, but may not be aware of the specifics of each particular application running in the system.
The information required by this audience is different from the software developer, for example, who has an intimate knowledge of the application details. The Log specification distinguishes this application specific low level information as trace data. While it can provide beneficial information for a more generic audience the amount of such information generated in a system would be so enormous that its collection on a continuous basis would create too much overhead in the system.
Instead the information collected through logging needs to be suitable for system level trouble shooting by personnel or tools possessing some high-level overview of the system.
Even with such higher level information volume remains the main challenge of logging. This can be tackled from two main directions: the organization of the data so it can be efficiently collected, stored, and retrieved when necessary; and the efficient purging of data when it becomes obsolete. In addition it is beneficial if the service provides filtering capabilities so that the amount of collected data can be adjusted to the particular circumstances, system requirements, and application needs, if it can take off the burden of record formatting from the applications, so they do not need to be aware if the output format changes due to requirement or locality changes.
All these issues are addressed by the SA Forum LOG with which we begin our exploration of the AIS management infrastructure services.
8.2.2 Overview of the SA Forum Solution
The SA Forum LOG offers its users cluster-wide logical entities called log streams that represent a flow of records, which is stored persistently as shown in Figure 8.1. Any number of users may open the same log stream simultaneously and insert log records into this flow. The log stream delivers these records to an associated file where the record is saved according to a format also associated with the log stream. The user writing to a log stream does not need to be aware of the format associated with the stream. It only needs to be aware of the pieces of information that it needs to provide in the API call for each write operation. Based on the provided data and the formatting associated with the stream the LOG saves the record in a file linked at the time of the saving operation with the log stream.
Figure 8.1 The overall view of the Log service.
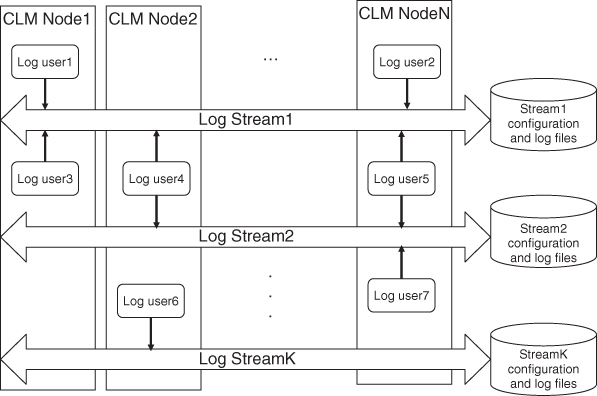
Since more than one API users may write to the same log stream simultaneously the LOG also serializes these records before saving them in the destination file. The specification does not stipulate how this serialization occurs and therefore different implementations of the LOG may use different strategies. For example, the specification does not require the ordering of the records according to the time stamp provided in the API call. One implementation may use this time stamp, while the other may not.
For each log stream the file formatting information and other properties are contained in a separate configuration file. The formatting information is essential for anyone wanting to read the log file as this defines the different fields, their length, and format within each saved record. The specification defines the different format tokens and their use.
In addition the configuration file also explains the maximum size of the log files generated and policy used by the LOG when this maximum size is reached. There are three strategies that may be defined:
- If the halt option was defined the LOG stops saving further records for the given log streams and records are lost until more space becomes available. To prevent the loss of records a threshold is defined for such a log stream and the LOG generates an alarm when this threshold is reached. It generates a second alarm if the file size still reaches its maximum.
- The wrap option instructs the LOG to continue saving the log records in the same log file even when it reaches full capacity by overwriting the oldest records existing in the file—that is, wrapping around. Hence doing so also may cause the loss of some information, although in this case from the log file itself, it has been proposed to add a similar threshold attribute to this type of log streams as well and generate an alarm whenever the threshold is reached.
- The third, the rotate option is a special case of the wrap option. The difference is that rather than wrapping around in a single file it uses a set of files. Whenever the maximum file size is reached a new file is created until the maximum number of files is reached. At this point the oldest file is replaced by the LOG. Setting the maximum number of files to the maximum possible value results in continuous creation of new files as they fill up, which may in turn result in running out of system resources.
Whenever the LOG creates a new log file it indicates the creation time in the file name. When the file is full and the LOG closes it, it is renamed by appending also the closing time.
The question is how log streams come to existence. The specification defines two classes of log streams: those that are configured by an administrator and those created by an application at runtime using the LOG API. Configured log streams exist from the moment they are added to the configuration up until they are removed from it. On the other hand application-created runtime log streams exist as long as there is at least one LOG user in the cluster who uses them. When the last user closes a stream (or stops using it due to the failure of the opener process, or the node leaving the cluster, etc.) the LOG closes the files associated with the log stream and removes the stream.
There are three configured log streams mandatory to implement by a LOG implementation. They are well-known—their name is defined by the LOG specification. These are the alarm log stream recording alarms and security alarms; the notification log stream recording all other categories of notifications; and the system log stream that can be used by applications and services alike to record situations that affect their service or the system.
As one may conclude the first two well-known streams are used for notifications carried by the SA Forum NTF, which will be discussed in Section 8.3. The reason to distinguish these two streams is that the LOG also allows the filtering of log records; however it cannot be applied to the alarm and notification log streams. The specification mandates that all alarms and notifications need to be logged in the system.
As we pointed out in the Section 8.2.1 one of the issues that the LOG needs to deal with is the amount of data generated in the system. Of course the code written for the applications and system components cannot be changed just because one would like to have more or less information generated. With a significant number of such software in the system it also becomes unimaginable of configuring each one of them separately.
Instead the LOG offers the possibility to define the level of severity at which logging should be performed.
Whenever a user writes a log record to a log stream it provides the severity level associated with the record. This information is then used by the LOG to filter out records that are below the currently set severity level. In addition the LOG also informs log writers not to produce records below this set level.
8.2.3 The LOG Information Model
The information model defined for the LOG is rather simple and specifies two similar object classes: One for configuration log streams and a second for runtime log streams.
Configuration log streams1 are created—just like any other configuration object of any other AIS service—by system administrators using the IMM object management API. These log streams exists as long as the configuration object exists. Users may open these log streams by referring to their names, that is, to the distinguished name (DN) of the configuration object representing the log stream.
All the characteristics of the associated log streams are determined by the attribute values of the configuration object including the name of the log file, its path, maximum size, the policy applicable when the file is full as well as the record format.
Most of these attributes are also writable, which means that if an attribute value, which configures in some way the log file associated with the log stream, changes then the LOG needs to close the current log file and create a new one, which satisfies the configuration defined by the new set of attribute values.
Attribute changes that do not define the log file features are applied immediately. For example, changing the severity level changes the filtering policy for the log stream across the cluster. The LOG applies this change right away.
Since these logs streams can exists in the system as log as the LOG implementation is present in the system the suggestion is to create the representing configuration objects as child objects to the configuration object representing the LOG itself.
Log streams can also be created by applications using the LOG API. These log streams are represented in the LOG information model as objects of the runtime log stream class. The configuration attributes for such log streams are provided by the creator process at creation time and therefore they remain in effect for the entire period of existence of the log stream.
The only attribute that can be manipulated and—being a runtime attribute—only through administrative operations is the severity level.
The name of the log stream provided by the creator is used by the LOG as the DN of the runtime object it creates to represent the log stream in the LOG information model. This means that the log stream name needs to be valid with respect to the actual system information model. More precisely the parent object to the log stream object needs to exist otherwise the LOG cannot insert the log stream object into the model and the creation operation fails.
Since the LOG API users generally do not need to be aware of the system information model this constraint may require some considerations from application designers who wish to use the LOG API in such a manner particularly if the application needs to be portable between systems.
There are a few potential parent objects that an application may know about without any knowledge of the current system information model:
- The well-known objects representing the different AIS services and in particular the one representing the LOG itself. As we mentioned the suggestion is to use it as the parent object of the configuration log stream objects.
- The system root is a special well-known object; however, one would quickly realize that this option is the least favored by operators and system administrators as it flattens—some would even say pollutes—the information model.
- In case of applications managed by the AMF a process
- can obtain the name of the AMF component it belongs to using the AMF API;
- learns about component service instances names as CSIs are assigned to the component the process belongs to.
In the later cases the IMM may not allow the removal of the AMF component or CSI unless the runtime log stream object is removed first. So their ancestors may be more suitable.
A runtime log stream exists as long as there is at least one opener associated with it in the cluster. When the last opener closes the stream the LOG closes the files associated with the stream and deletes the log stream. Accordingly it also removes from the information model the runtime object representing the now closed log stream. If there are several writers to the stream it may be difficult to achieve this in sync with the manipulation of the AMF objects.
There is no way to find out about closed runtime log streams from the information model, therefore the LOG also generates notifications in association with runtime log streams. It generates one at the creation of such a log stream and one at the deletion. Both notification types include the information necessary for collecting data from the log files.
8.2.4 User Perspective
The API defined for the LOG is simple and straightforward. The same way as for other AIS services, processes that wish to use the LOG need to link its library and initialize the API. At initialization three callbacks may be provided among which the most interesting is the one associated with the severity level. If this callback is provided at initialization the LOG is able to call back the process whenever the severity level is changed for any of the log streams opened by the process. Thus, the process can operate more efficiently by not generating log records that would be discarded by the LOG anyway.
Before the user process can start to write log records to a log stream it needs to open the stream. If the stream already exists in the system—it is a configuration log stream or it has been already created—then the new opener is added to the list of openers for the particular stream maintained by the LOG. This list has particular significance for runtime log streams as they exists as long as there is at least one opener process associated with the stream. When the last process closes the log stream it ceases to exist, the LOG closes the associated log files and removes the representing runtime object.
If the log stream does not yet exist, when a user process tries to open it the LOG creates the stream provided that the opener process has provided all the attributes necessary for configuring the log stream.
A special case is when two processes both assuming that they are the first openers—and therefore the creators of the log stream—and provide the configuration attributes for the log stream. To resolve the potential conflict the LOG creates the log stream based on the attributes of the request it receives first. If the second opener-creator defined the same attributes than there is no conflict as it would have created the same log stream. If however any of the attributes are different, the operation fails and the second user will receive an error that the log stream already exists. It can open the stream successfully only after removing the attributes associated with the log stream creation. (Well, it could also try to match the attributes of the existing log stream; however, that requires more efforts, for example, the use of the IMM OM-API to read the runtime object.)
Once the log stream has been opened by a process it can write log records to the stream. For the write operation the user needs to provide the log header, the time stamp, and the record data as an opaque buffer.
If the record is intended for the alarm or the notification log stream then the specially defined notification log header is used, however applications typically do not use these streams. For all other cases the generic log header is used, which includes the severity level, which is used at filtering as we have seen.
The user may provide an actual value for the time stamp or ask the LOG to provide it by setting its value to unknown.
A user process may invoke both the opening and the writing operations in a blocking or in an asynchronous nonblocking manner. The latter case requires that the process provides the appropriate callbacks at initialization.
After the initialization of the LOG the same process may open as many log streams as required; however implementations may limit the total number of log stream in the system.
8.2.5 Administrative and Management Aspects
The LOG offers different management capabilities depending on the type of the log stream.
As we already discussed in Section 8.2.3 administrators can create, delete, and reconfigure configuration log streams:
- Creating a configuration log stream means that the associated files are created and user processes may open the stream and write to it from anywhere in the cluster.
- Deleting a log stream means that the LOG will close all the files associated with the log stream and the configuration object is removed from the information model. Users who had the log stream open will receive an error next time they attempt to write to the stream.
- Modifying the configuration of such a stream most often results in the LOG closing the current log file and creating a new according to the new configuration. The exception is the modification of the severity level, which changes the filtering policy for the log stream.
Note that configuration log streams of applications will be first defined in the third release of the specification. Until that only the well-known log streams exist as configuration log streams and the LOG creates them. That is to say an administrator cannot create or delete any of these well-known streams; however, their reconfiguration is still possible except for the filtering of the alarm and notification streams, which are also prohibited by the service.
For runtime log streams a single administrative operation is available that changes the filtering criteria for the stream. It is equivalent to setting the severity level of a configuration log stream. The administrator has no other direct control over runtime log streams.
8.2.6 Service Interaction
8.2.6.1 Interaction with CLM
The LOG uses the membership information provided by the Cluster Membership service (CLM) [37] to determine the scope of the cluster. It provides the LOG API only on nodes that are members of the CLM cluster.
The reason behind this limitation is that log streams are cluster-wide objects accessible simultaneously from any node of the cluster. When a node is not member of the cluster it and its processes have no access to cluster resources such as the log streams. This implies that circumstances and events that need to be logged while a node is not a member need to be logged by other means, for example, most operating systems provide some local logging facilities. Any integration with such facilities is beyond the scope of the LOG specification and is implementation specific.
This also means that a LOG implementation is required to finalize all associations with processes residing on a node that drops out of the membership and any initialization of the service should fail as long as the node remains outside of the cluster. To obtain the cluster membership information the LOG needs to be a client of the CLM and track the membership changes.
8.2.6.2 Interaction with IMM
The IMM [38] maintains the information model of all AIS services including the LOG. It also provides the administrative interface toward it.
At system start up the LOG obtains the set of configuration log streams it needs to implement from IMM, which loads them as part of the complete system information model. A LOG implementation also registers with IMM as the OI for the LOG information model portion of the system model. It does so in all available roles.
From this moment on IMM will deliver to the LOG the information model changes initiated on configuration log streams and also the administrative commands issued on runtime log streams.
As the OI, the LOG implementation uses the IMM OI-API to create, update, and delete objects representing the runtime log streams existing within the cluster. It also updates any runtime attributes of configuration log streams as appropriate.
The IMM OM-API is the interface through which an administrator can observe and also to some extent control the behavior of the LOG in the system.
8.2.6.3 Interaction with NTF
According to the upcoming release, the LOG generates two types of alarms and three types of notifications and uses the NTF API to do so.
The two alarms announce situations when information may be lost either because it cannot be logged or it is about to be overwritten.
In particular the capacity alarm is generated when the threshold set for a log stream has been reached and again when the maximum capacity is reached. Depending on the policy set for the log stream at the reach of maximum capacity the logging cannot continue (halt) or it will result in overwriting of earlier records (wrap and rotate). The administrator needs to figure out which is the correct course of actions—preferable after the first alarm. In case of halt policy, the only option is really to collect the data from the log file, so that logging can continue. In case of wrap and rotate overwriting earlier records may well be the intention in which case no action is necessary. Otherwise again the data needs to be collected to avoid any loss.
The second alarm indicates that the LOG is not able to create a new log file as it is required by the configuration for the log stream. This may occur due to misconfiguration, but also due to running out of resources in the system. However, the alarm is generated only if the LOG is unable to communicate the error by other means. For example, if the error can be returned via the service API in response to the creation attempt of a runtime log stream, the alarm will not be generated.
Whatever the reason of the file creation alarm, it signals that the LOG is not able to save log records as required and they are being lost. The administrator needs to find out the actual reason to remedy the situation.
As the LOG will reattempt the operation that triggered the alarm it will detect that the problem has been corrected and clear the alarm automatically.
The notifications the LOG generates provide to the interested parties the information necessary to collect the data so that they do not need to monitor the LOG information model.
The LOG generates notifications at the creation and deletion of runtime log streams to warn the administrator or anyone interested and subscribing to these notifications that collecting the logged data may be due.
The LOG also generates notifications that a configuration log stream has been reconfigured and therefore the access to the logged information might have changed.
Besides the LOG using the NTF to produce alarms and notifications the NTF may also use the LOG. As we pointed out at the discussion of the well-known log streams, two of them are intended for alarms and notifications respectively. It is not specified who writes these streams and there are several possibilities: The first approach is that the NTF writes both streams. This is the intention and it is most efficient; however, the NTF specification does not require it. Since it is the LOG specification, which requires these streams a second approach is that the LOG also writes them. For this it needs to become also a subscriber to the NTF as discussed in Section 8.3.3.1. Again this is not spelled out in the specification, so an implementation may not do so. In this case finally, a dedicated application may subscribe to NTF and write to the log streams by that bridging the two services.
8.2.6.4 Interaction with AIS Services
It is recommended that all AIS service implementations log their actions and that their use for this the SA Forum LOG. In these relations the LOG is a provider for the other services.
8.2.7 Open Issues and Recommendations
After the release of the third version of the specification there will be only few open issues with respect to the Log specification. Probably the least clear from the specifications is the relation of the Log and the NTFs. This is primarily due to the NTF reader API discussed later in this chapter in Section 8.3.3.3 and the Log requirement of providing the well-known alarm and notification log streams. They seem to overlap.
Indeed it is possible for the NTF to use the LOG to persist the notifications with the purpose of reading them back whenever someone asks for it. Whether it should use the pre-defined alarm and notification log streams is another issue. The problem with using these well-known streams to support the NTF reader API is that they are reconfigurable by an administrator including their logging format. This means that the new format may or may not satisfy the requirements of the NTF also that its ‘reader module’ would need to adjust to the new format again and again. This is an unnecessary complication for the NTF implementation as it could create its own runtime log stream for which the format is locked in exactly the way it is needed for optimal use.
By the same logic we can define a rule of thumb when to use runtime log stream as opposed to configuration log streams.
When the log files are consumed by external users it is beneficial to use configuration log streams as their output format can be readily adjusted as required over time. Having the same type of adjustment of a runtime stream would be rather cumbersome as the stream needs to be recreated with the new attributes, which could require significant coordination if many users use the stream, not to mention that the new format would need to be configured somehow anyway. This was actually the rational why configuration log streams were introduced for applications as well.
On the other hand, when the logs are consumed by tools and applications optimized for a particular formatting the use of runtime log streams can preserve the format provided at the creation of the log stream for its entire existence.
Now returning back to the relation between LOG and NTF: All these consideration about the reader API do not prevent an NTF implementation to write the alarm and notification streams provided by Log. It is the intention. However, since it is not mandated yet another approach to resolve this relation is that the LOG or a dedicated application subscribes to alarms and notifications and writes them to the well-known log streams as appropriate. The critical issue here is to make sure that there is no duplication of the recordings. This is actually an issue in general for these well-known streams as the specification does not indicate the expected writes to the different streams. Hence an application designer or implementer reading the specification may be compelled to write the notifications the application generates by the application itself to the appropriate streams, which results in duplication if the middleware does so already.
The point is that applications producing alarms and notifications typically do not need to worry about them being logged. The middleware is expected to take care of it.
In summary we can say that the LOG provides a standard way to record situations, circumstances, and events that may be useful for—primarily—offline analysis of the system behavior whether this data is generated by system components or by applications. It is capable of collecting great amount of data organized into different streams of information while releasing the data producers from the burden of formatting and organization of these records.
The collected information is very beneficial in fault management; however, in high availability and SA systems there is a need for faster reaction to certain situations. The LOG is not intended to trigger these reactions; it is intended to provide the context to events that require thorough analysis.
The service addressing the need of reactiveness is the NTF that we will discuss next.
8.3 Notification Service
8.3.1 Background: Issues, Controversies, and Problems
We have seen that the AMF will try to repair components by restarting them and if that is unsuccessful then escalating it to the next fault zone, then potentially to the next, and so on. Obviously if the cause of the problem is a corruption of the file containing the executable code or a malfunctioning hardware, a simple restart at any level will not solve the issue. The administrator needs to get involved and fix the problem; therefore AMF needs a way to alert the administrator.
The same is true for other services. When a problem is beyond their self-healing capabilities they need to inform the administrator that the problem they are facing is persistent and their remedies failed. Of course we could define for each service an interface for this purpose, but if each of the services defined their own interface with their own methods of communicating the problem the combined system management would become quickly a nightmare for the system administrators.
Instead we would like to have a common communication channel and method through which the system entities (including applications) can signal an emergency situation that external intervention is needed.
In addition this channel may also be used to provide those external ‘forces’—or for that matter anyone else who may be interested—with regular updates about significant events and circumstances to provide some context to any potentially upcoming emergency situations.
At the same time it is also important that different listeners of this ‘emergency broadcast channel’ are not overwhelmed with data they cannot digest anyway. We would like them to receive only the information relevant to them and that they receive all of that information so they can make sound decisions should an emergency situation occur.
This means that the ‘broadcasted’ data needs to be organized such that anyone can read it easily as well as it can be classified efficiently so that the filtering and correlation of different pieces are both possible. Correlation may become necessary at a later point when an error occurs and its context becomes important to make an educated decision.
From the perspective of the entities reporting the emergency situations it is also important that they can produce the notifications efficiently as they are often in the critical path of dealing with some incident such as the emergency situation they are about to report. In case of AMF, for example, while it is busy in orchestrating the fail-over of the service instances served from a failed node (reported by Platform Management service (PLM) via (CLM)) to a healthy one any additional work of reporting and logging is undesirable, so we would like to keep it at the minimum.
Notice also that in the above scenario not only AMF, but the complete service stack, that is, PLM and CLM will also report their view of the issue. Later, when the administrator fixes the failed node (e.g., replaces the hardware) this action tends to clear the problem for all AIS services and not only for PLM. There is no need to deal separately with the CLM issue unless there is indeed some connectivity problem too. So it is just as much important that the system can tell whether an emergency situation has been dealt with or need further actions as reporting the emergency situation.
The SA Forum NTF was defined with these goals in mind. It was also aligned with the existing related specification of the International Telecommunication Union, the ITU-T X.7xx recommendations [72, 85, 86], and [87].
It provides a single communication channel dedicated to signaling significant changes and situations in the system, most importantly circumstances, when the problem persists and the system cannot resolve it permanently or at all; and therefore external resolution is required. It defines the format of these incident reports so that all interested parties can read the information and also it can be organized properly.
Let's see in more details how these are achieved.
8.3.2 Overview of the SA Forum Notification Service
Maybe the best everyday-life analogy to the NTF is the 911 emergency number. People call it when they find themselves in a situation they are unable of handling. It is a single point of access to all emergency services: The Police, the Ambulance, and the Fire Department.
The SA Forum Notification is a similar single well-known point of access through which system components can report issues they cannot deal with or ‘consider’ important. Any service or application may use the NTF for reporting situations of significance. In terms of the NTF these services and applications are the producers of the incident reports or notifications as shown in Figure 8.2.
Figure 8.2 The overall view of the Notification service.
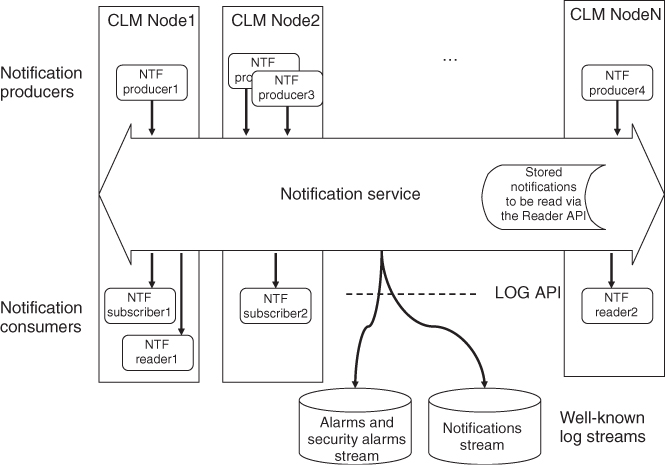
Most AIS services are producers of notifications and the service specification defines the ‘situations of significance’ that an implementation of the service shall ‘consider’ important and therefore should report.
On the other side, there are entities inside and outside of the system, whose task is to listen to the different reports and if a problem is reported then to resolve it. It is like the Fire Department, the Ambulance, or the Police at the other end of the 911 phone line. The dispatcher takes the report of an emergency situation and alerts the appropriate service or services, which then in turn take over the handling of the situation based on the report they have received. They are the consumers of the emergency reports; hence in the NTF there is the notion of the consumer of notifications.
The notification producers typically do not know who or which entity is going to be the consumer of their notifications. Neither does the NTF, at least not in advance. System entities need to express their interest in the different kinds of notifications to the NTF, so it can deliver them the notifications accordingly. This subscription mechanism replaces the 911 dispatcher and allows the NTF to deliver the right notifications to the right consumer. The consumer may be internal (e.g., another service) or external (e.g., system administrator) to the system. It is also possible that multiple consumers listen to the same notifications, or that nobody listens to some of them.
To make sure that even though at a particular moment there is nobody listening to some notifications these notifications are not lost—after all they are reporting some important situations—the NTF implementation has the obligation to store the notifications persistently. Any consumer that misses some notifications that are of significance can read them back from the NTF, from these stored notifications.
The question still remains how consumers express their interest in a certain set of notifications and how the NTF can sort the received notifications to match the subscribers' interest.
The AIS specifications define the different notifications the AIS services produce, so a possibility would be to list them based on the different specifications. However this approach would render a NTF implementation obsolete each time a new notification is defined the implementation needs to be updated. Also, the NTF would be completely useless for applications.
The NTF specification defines the data structure for the notifications. Since the information carried in the notifications ranges from incident reporting to state change notifications, the content is divided into a common part and some specific one that depends on the type of the information the notification carries. Accordingly the NTF distinguishes different types of notifications. There are
- alarms,
- security alarms,
- state change notifications,
- object create/delete notifications,
- attribute change notifications, and
- miscellaneous notifications.
The data structure of all notifications includes the common part, which is also referred as the notification header. Except for the miscellaneous notifications the different notification types extend the common header with their appropriate data structure.
When a consumer expresses its interest in a particular set of notifications it does so by defining a filter which refers to a particular notification type and field values of that notification type. Any notification received by the NTF that matches the values in the filter then delivered by the service to the consumer who defined the filter.
Besides the different contents, these notification types also imply different importance. An alarm is generally perceived as the indication of some real urgency, while an attribute change notification is usually considered less important. The idea is that alarms—both security and regular—reflect incidents that the system cannot deal with and to resolve them human intervention is required. Strictly speaking these are the true 911 cases, while the other notifications are typically consumed internally by other services of the system or provide context for the alarms.
The NTF functionality linked with the importance of notifications is the notification suppression. When in the system there is no consumer for certain notifications it may be a reason not to produce them on the first place as producing notification takes away processing time, bandwidth, and other system resources. Other times even though there would be consumers, but some shortage of resources—due to extreme high traffic, for example—might require that less important notifications are turned off. The suppression mechanism allows for this type of tuning of the system at runtime by the administrator.
The NTF specification requires that its implementations guarantee the delivery of at least the alarms and security alarms. They also must store alarms persistently. We have already seen in Section 8.2.2 that the LOG provides a well-known alarm log stream for this purpose, which cannot be filtered either.
An implementation may however provide lower delivery guarantees for other types of notifications and also may not store them persistently. The LOG specification defines a second well-known stream also for notifications.
For all notifications however it is required that all NTF implementations deliver only complete notifications and that each subscriber receives each notification at most once. Moreover with respect to the same producer subscribers receive notifications in order, that is, in the same order as they were produced.
Finally the NTF also supports localization to the extent that it provides the API call to get the localized message associated with a notification. The specification does not cover the method the localized information is provided to the service; it is left to each service implementation. The appendix of the specification only outlines at high level the general idea behind this localized message catalog and its mapping to notification parameters.
8.3.3 User Perspective
The NTF specification defines three sets of API functions. They are for the notifications producers, subscribers, and readers. Regardless which portion of the API a user wants to use it needs to link the NTF library.
8.3.3.1 Producer API
Producing a notification means creating and filling in the required data structure and submitting it to the NTF.
The most important moment about producing notifications is that it often happens during some critical operations, considering, for example, the AMF when it is handling a fail-over. According to the specification AMF needs to produce a series of notifications with the fail-over as the different entities change their states. This also means that AMF needs to produce many similar notifications as, for example, at a service unit (SU) fail-over each of its components and the SU itself will change several of their state (i.e., the presence, the readiness, and the high availability (HA) states at least, but the operational state may also change).
The NTF producer API offers some optimization possibilities:
First of all, an NTF user that wants to produce some notifications may pre-allocate a notification identifier. Normally the notification identifier, which is a cluster-wide unique identification number, is allocated during the send operation. The NTF returns the notification id at the completion of the send operation and a user may reference it in subsequent notifications that are related to the sent one. The need to reference related notifications serializes the send operation as well as any invocations requiring the notification id, which may take some time. However if there is a pre-allocated notification identifier the user may use it right away in any related notifications and invocations. Since there is no ordering requirement associated with the notification id, NTF implementations may use different strategies for the allocation of this cluster-wide unique number that may also shorten the send time.
The second optimization possibility that users may consider is the reuse of the allocated data structure. Again allocations may take some time and also use additional resources. If more than one notification of the same type needs to be sent (e.g., state change notifications for all components of an SU failing over its services) they will use the same data structure. Therefore the user may allocate this data structure once and reuse it as many times as needed by updating it with the values appropriate for each new notification. Of course, this again serializes the operations as each data setting needs to be sent before the data structure could be used for the next.
Finally, if a producer provided the appropriate callback at initialization time, the NTF will inform it whenever some notifications are suppressed in the system. Thus, the producer can stop generating them all together potentially saving valuable time and resources.
Toward the producer NTF passes the suppression as a bitmap of the event types, for which the producer should stop generating any notifications. The event type is one of the common attributes of all notification types.
8.3.3.2 Subscriber API
When it comes to the consumer API, the first task a ‘want to be subscriber’ or a ‘want to be reader’ needs to do is to set up the filters that describe the notifications it would like to receive or read.
The filter setting requires the setting of a similar data structure as the notification data structure itself as the filter conditions are set for this very same data structure. Even though this subscription setup is usually not part of critical operations, for symmetry the NTF API supports data structure reuse between different subscriptions.
With the different filters in place the user is ready to initiate the subscription from which moment on it will receive a callback if a notification matching any of the filters is broadcast in the system. The notification is delivered within the callback.
For each notification instance delivered the NTF consumes some of its resources that are freed only when the subscriber has processed the notification. In some cases when a subscriber does not consume the notifications fast enough, NTF may run out of its resources. In this case, the NTF cannot deliver any more notifications, instead it informs the subscriber that it dropped some notifications and provides the required information for the subscriber to retrieve these discarded notifications using the Reader API.
8.3.3.3 Reader API
If the notification consumer wants to read persisted notifications in addition to setting up the filters it also needs to define a search criterion to find the first notification to be read. To understand this we need to indulge a bit more in the way notifications are persisted:
Since there are many notification producers in the system, they may try to send notifications simultaneously. The NTF serializes these notifications by that creating a single sequence of notifications which are then written to some persistent storage, such as a file on a disk. Alternatively the NTF may use the already discussed LOG to record the notifications in which case the serialization is effectively performed by the LOG.
In any case, the result is an ordered list of notifications within which, however, the order may not exactly be the same as the time stamp associated with each of the notifications. When reading the notifications this recorded order prevails and the time stamp can only be used as a search criterion to find a first notification to read. From this first notification, however, the reader may navigate forward or backward in the list selecting the direction on each read operation.
An easier way to identify the first notification to be read—provided it is known—is its notification identifier.
As we described in Section 8.3.3.2, under certain circumstances the NTF may not be able to deliver a notification to a particular subscriber (e.g., the subscriber is consuming the notifications it is receiving too slowly). In this case it will still deliver a callback that it had to discard a notification with a particular notification identifier. The subscriber can use the reader API to retrieve the notification using the provided notification identifier.
8.3.4 Correlation of Notifications
We mentioned in the previous section that it is desirable that a notification producer references related notifications in each generated notification. This is referred as correlation of notifications.
The correlation of notification is particularly important at root-cause analysis as an error may trigger multiple reactions as the error or its consequences reach the different layers and subsystem. The notifications they generate can be organized into a tree.
For example, if a hardware node goes down at least the PLM, the CLM and the AMF react as each handles its own entities that resided on the node:
In addition PLM also informs all its interested tracking users about the change. In this track callback again PLM provides the notification identifier of the notification reporting the triggering state change.
Again, the same way as PLM reports the failure through the track API, CLM does the same also including the notification identifiers as appropriate.
In these state change notifications AMF references the notification identifier associated with the triggering event. However, the AMF does not propagate the notification identifiers automatically within its callbacks. The user process requiring it can obtain the ids by calling the appropriate function and providing the invocation identifier of the callback.
These events trigger the following set of notifications. By #n we indicated the notification id here, but it also reflects a possible sequence of the generated notifications. In parenthesis we also indicate the root and the parent notification ids referenced as correlated:
#1: PLM HE alarm ( , )
#2: PLM HE operational state change notification (1, )
#3: PLM HE presence state change notification (1, 2)
#4: PLM HE readiness state change notification (1, 3)
#5: PLM EE presence state change notification (1, 4)
#6: PLM EE readiness state change notification (1, 5)
#7: CLM member node exit notification (1, 6)
#8: AMF node operational state change notification (1, 7)
#9: AMF SU readiness state change notification (1, 8)
#10: AMF component readiness state change notification (1, 9)
#11: AMF component presence state change notification (1, 10)
#12: AMF SU presence state change notification (1, 11)
We see that there is a sequencing involved here. The assumption is that CLM receives the track callback from PLM before it detects itself that a node left the cluster and the same is true for AMF. Only in this case the generated notifications can reflect the reality and only if they are correlated properly. Even though the failures and error are definitely related and compose a chain of reactions the timing of the different error reporting and detection mechanisms may show them unrelated or related.
It is possible that a PLM implementation generates notifications #2-#4 as direct consequences of #1, but not each other. Same may go for notifications #5-#6, and at the AMF level for #9-#12. This would change the notification tree, but still put the hardware failure as the root-cause of the entire tree:
#1: PLM HE alarm ( , )
#2: PLM HE operational state change notification (1, )
#3: PLM HE presence state change notification (1, )
#4: PLM HE readiness state change notification (1, )
#5: PLM EE presence state change notification (1, 4)
#6: PLM EE readiness state change notification (1, 4)
#7: CLM member node exit notification (1, 6)
#8: AMF node operational state change notification (1, 7)
#9: AMF SU readiness state change notification (1, 8)
#10: AMF component readiness state change notification (1, 8)
#11: AMF component presence state change notification (1, 8)
#12: AMF SU presence state change notification (1, 8)
However if CLM detects the node leaving the cluster before PLM reports the readiness status change via the tracking API, the two incidents become unrelated. This is reflected in the correlation of the notifications:
#1: PLM HE alarm ( , ) #2: PLM HE operational state change notification (1, ) #3: PLM HE presence state change notification (1, ) #4: PLM HE readiness state change notification (1, ) #5: PLM EE presence state change notification (1, 4) #6: PLM EE readiness state change notification (1, 4) #7: CLM member node exit notification ( , ) #8: AMF node operational state change notification (7, ) #9: AMF SU readiness state change notification (7, 8) #10: AMF component readiness state change notification (7, 8) #11: AMF component presence state change notification (7, 8) #12: AMF SU presence state change notification (7, 8)
Seeing all these events as related, partially related, or unrelated may make all the difference whether a management entity observing the notifications takes the right action.
Our example used a scenario of some AIS services, however any notification producer process generating notifications should follow the same principles. If there is dependency between the generated notification and previously reported triggering events the process should reference the related notification identifiers.
Within the AIS services APIs that report some kind of status changes expect the user to provide some notification identifiers when calling the API. A typical example is the error report API of AMF, which assumes that whoever reports the error toward AMF also produced a notification toward NTF. Passing the notification ids in the API call allows AMF to correlate its own notifications with that produced by the error reporter.
There is also a set of notifications which come in pairs. A typical case is the alarm: An alarm is reported when the emergency situation arises and a second alarm clearing the emergency is reported when the situation has been resolved. The second alarm always references the first to indicate what situation has been cleared and it references it in a third position.
#22: PLM HE alarm (20, 21, ) ... #27: PLM HE alarm cleared (20, 21, 22)
From all this we can see that it is the responsibility of the NTF user to correlate the different notifications, the NTF only provides the data structure to do so.
There could be several correlated notifications. Considering the tree of correlated notifications discussed above one may see that it is typically rooted in a single incident, which was reported in a single notification. This we refer as the root notification and NTF distinguishes it from other correlated notifications. In addition there is usually an immediate ‘parent’ node in the notification tree reporting a change that triggered one or more subsequent notifications. Not surprisingly this notification is referred as the parent notification and its identifier also distinguished in the data structure provided by NTF.
No additional notification is distinguished, but any number of them can be reported in a notification just by listing them. For example, the clearing of an alarm references the alarm being cleared in this nondistinguished position.
8.3.5 Administrative and Management Aspects
The administration of the NTF is about controlling the suppression of notifications generated in a system. It consists of two steps:
- First the administrator sets up the static filters for notifications that may need to be suppressed. These filters are configured as objects of the NTF information model. The NTF configuration classes mirror the data structure of the different notification types and allow the administrator to set for them filter expressions.
- Subsequently the administrator may activate and deactivate these filters as necessary through administrative operations.
There could be different reasons for the suppression of notifications:
Among programmers there is a tendency to provide as much information as possible about the behavior of the application or system for the case when there is a problem its root-cause can easily be identified. The line between the sufficient and too much is not well defined and different designers may draw it differently. In an open system where applications may come from different vendors this causes heterogeneity. Of course the operator of the system on which these applications are deployed also has its own ideas and goals, so through notification suppression the system can be tuned to generate only the information one is interested in.
There is however another more significant reason: Notification suppression allows one to free up some resources, which in an overloaded system may become critical in service provisioning.
The opposite is also true: When a problem persists less suppression can provide more information about the context and help in the resolution of the problem.
The precondition of efficient suppression is that the notification producers are prepared for suppression. Whenever the administrator activates a filter, the NTF informs its users, who provided the appropriate callback that they shall not produce the particular set of notifications. If so the producers will not waste resources as if a user still tries to produce a notification matching any of the active filters the NTF will drop the notification right at the source not to waste further any resources for something not wanted.
Note however that there is a difference between the suppression filtering criteria specified by the administrator and the information propagated toward the producers. In the callback to the producers only the event types can be specified while the administrator may specify additional criteria in the filter configuration. That is, to the producers NTF can indicate only the event types that are suppressed all together. If only some notifications of an event type are suppressed, the NTF itself needs to do the filtering, which means some wasting of resources.
As mentioned earlier alarms and security alarms cannot be suppressed. There is no filter class defined for these notification types. This means that an application designer needs to take special care of deciding when an alarm is really necessary. To make this decision easier it is worth mentioning that an operator would map alarms to emergency calls to or to paging the maintenance personnel to attend the situation. So even if the situation seems to be critical for the application, but it is another entity within the system that needs to take care of it then there is no need for an alarm, but a notification should suffice. An example within the AIS services is the upgrade related errors detected during an upgrade campaign. AMF generates state change notifications only which are intended to be intercepted by the SMF, which then decides when to suspend the campaign execution.
Before leaving the subject it is probably worthwhile to compare dynamic filtering and static suppression of notifications. They might be confusing at first glance as both mechanisms use filters but in somewhat different ways:
- Static suppression sets the filter at the producer end and stops the generation of the notifications matching the filter completely in the system. It is configured and controlled by the administrator. It cannot be applied to alarms and security alarms.
- Dynamic notification filtering sets the filters at the consumer end of the communication channel and it is specific to a particular subscriber. That is, the subscriber using the NTF API restricts what notifications are delivered by indicating what notifications it is interested in. So as opposed to the suppression, notifications that match the filter are delivered. All notification types can be filtered this way including alarms.
8.3.6 Service Interaction
By its nature the NTF is expected to interact with most services and applications in the system. More specifically, all entities in the system should use the NTF to provide at runtime information useful for fault management. In this role the NTF provides the means for this common functionality. The specification of each of the AIS services contains a section defining the alarms and notifications the service generates following the common data structures laid out in the NTF specification itself.
In the rest of this section we look at those service interactions where the NTF appears in the role of the service user.
8.3.6.1 Interaction with CLM
The NTF, just like other AIS services, uses the membership information provided by the CLM [37] to determine the scope of the cluster and provides the NTF API only on nodes that are members of the CLM cluster.
This single common communication channel provided by NTF is a cluster-wide entity accessible simultaneously from any node but only within the cluster. It is not provided to processes residing on nonmember nodes even if it is a configured node. Just like in case of the LOG if there are incidents that would need to be reported while the node is not a member yet, NTF cannot be used and some other mechanism needs to be provided by the platform or middleware solution.
This also means that an NTF implementation is required to finalize all associations with processes residing on a node that drops out of the membership and any initialization of the service should fail as long as the node remains outside of the cluster.
To obtain the cluster membership information the NTF needs to be a client of the CLM and track the membership changes.
This situation is, however, somewhat contradictory as both the PLM and the CLMs define notifications and even alarms. The PLM is below CLM and does not require membership at all. Similarly the CLM reports incidents and state changes related to member and also nonmember nodes.
The resolution comes from the understanding that the NTF provides a cluster-wide collection and distribution of the notifications. As long as the producer's node is within the cluster it can a generate notifications even if those report incidents and changes were outside of the cluster. That is, the node on which the CLM generates the notification about a cluster change needs to be member, but it does not—it cannot be the one which has left, for example.
Similarly the dissemination of the information happens within the cluster boundaries only, but this does not limit the use of agents to provide external connections and delivery of this information beyond the cluster.
The point is that the integrity of the service is guaranteed within the cluster boundaries only, beyond that the respective producers and consumers are responsible for it, hence the restriction.
8.3.6.2 Interaction with IMM
As for all AIS services for NTF also the IMM [38] maintains the information model and provides the administrative interface.
At system start up the NTF implementation obtains the configuration of suppression filters and deploys the active ones in the system as appropriate. It also registers with IMM as the OI for the NTF information model portion of the system model. It does so in all available roles.
From this moment on IMM will deliver to the NTF implementation any change in the filter settings and also the administrative commands issued on them.
The actual setting and the activation status of the different filters are exposed to the external world through the IMM OM-API.
The NTF has no runtime objects to implement. It exposes no information through the information model about its producers, consumers, or even outstanding alarms.
8.3.6.3 Interaction with LOG
When it comes to the interaction between the NTF and the LOG we need to look at two different aspects and also that the specification does not mandate the use of the LOG by NTF; it only recommends so.
Whether to use the LOG or any other mechanism is really a question with respect to the NTF reader API and not so much with respect to the well-known configuration log streams defined by the LOG. We have mentioned that the LOG provides two distinct well-known configuration log streams: one for the alarms and security alarms and a second for other notifications.
According to the reader API, the NTF needs to persistently record the notifications and particularly all the alarms generated in the system so they can be read back for an NTF user should it request so.
One possible option for an NTF implementation is to use the SA Forum LOG for this persistent recording. This seems to be particularly suited as the LOG is also expected to provide two configuration log streams dedicated to NTF content.
However, as we pointed out in earlier discussions, these log streams are configuration streams and therefore may be reconfigured ‘at the whim’ of an administrator. By that information essential for NTF reader API may be lost or the format may be inefficient for the particular NTF implementation. These streams also separate alarms from other notifications, which complicates the sequential reading as it is provided by the reader API.
For these reasons if using the LOG the use of a runtime stream set up by and tailored for the NTF implementation itself is more suitable. However since the use of LOG is optional, an NTF implementation may come up with its own solution.
The main benefit of the alarm and notification configuration log streams is that they are well-known streams, which makes them easily locatable for everyone in an SA Forum system for reading as well as for writing. This raises the question who writes to these streams.
The intention is that in the presence of a LOG implementation an NTF implementation writes alarms and security alarms to the alarm log stream and all other notifications to the notifications stream.
Alternatively the LOG implementation may subscribe to all notifications and write to the two streams appropriately. Yet another option is to bridge the services at system integration time as it is easy to come up with a dedicated application that subscribes to the NTF for the missing notifications and writes them to the appropriate stream.
In any case to avoid any duplication, applications should not log their alarms and notifications themselves but leave this task to the middleware.
8.3.7 Open Issues and Recommendation
The NTF is also one of the more mature services within the AIS therefore relatively few open issues remain after the release of its fourth version. However, many find the interface rather complex and therefore difficult to understand and use. The disliked features are mostly related to the way the API addresses efficiency with respect to data structure reuse. It is debatable whether the efficiency concern should be addressed by the API or can be left to compilers, which today are capable of doing an excellent job of code optimization. It is hard to debug and fix complex code, so a simpler API is something to consider in the future.
A more difficult and unresolved issue at the time of writing is the different service interactions: Namely, the interaction with services that do not require cluster membership (see Section 8.3.6.1), and the interaction between the NTF and the LOG (discussed in Section 8.3.6.3). These are currently left to the middleware implementation and therefore applications should not make assumptions.
We have provided some guidelines regarding the use of alarms versus notification, and the conclusion was that if the information is consumed internally by the system, notifications are more appropriate. In this case however APIs may also be a solution. The question again is which to use and when:
An API can provide a prompt reaction to an issue, but on a one-to-one basis. We could observe this in the AIS track APIs. They provide similar state change information as the state change notifications, but via an API, so that a receiver can immediately act and react to the information. In fact it can even provide a response. Note however that services providing the track APIs also produce notification as the information is important for fault management purposes.
Notifications, on the other hand, are like broadcasts, all interested parties receive the information, and they are also anonymous at least to the party producing the information. The reaction to this information is typically not well-defined; it may require ‘other means’ such as manual intervention, or it may not be time critical. An example of this is the use of AMF notifications by the SMF discussed in Chapter 9. In this case time is not as critical, AMF is also not aware of the reacting party. For AMF it is a ‘to whom it may concern’ type of announcement to which some type of administrative action is expected.
To summarize the NTF it provides a common communication mechanism primarily for fault-related incidents as well as changes that give some context to these incidents and therefore allowing for more educated reaction to emergency situations. Depending on their contents the reports may fall into different categories that require different handling: they may be correlated, raised and cleared, and so on. While NTF allows for these different functionalities it is actually quite oblivious to the notifications it delivers. It really provides the means for the notification delivery and expects the users, notification producers to use this infrastructure meaningfully.
On the consumer side it provides both push and pull mechanisms of dissemination. It pushes the notifications to its interested subscribers in a timely fashion and for those who missed any information or do not subscribe it also provides a pull interface through which the same information can be retrieved. In both cases the consumers express their interest by defining dynamic filters and therefore they receive only the information they need or capable of handling.
Static filters allow system administrators to suppress the generation of notifications and therefore limit the resource usage in overload situations, for example.
In short the NTF allows the system to report its state and solicit reaction from when the situation requires it. Next we will look at what methods the reacting party—a management application or a system administrator can use to express its reactions of handling the situation. We will continue our investigation with the IMM.
8.4 Information Model Management Service
8.4.1 Background: Issues, Controversies, and Problems
Once an alarm has been received the administrator needs to take actions to deal with the emergency situation. This may range from issuing administrative operations on different entities in the system to reconfiguring part of the system including the AIS services and also applications running in the system.
In the discussion of the different AIS services we have already seen that most of them define an information model with the idea of providing manageability. Services are configured using objects of the configuration classes of their information model, they expose the status of their entities and themselves through runtime attributes and objects, and finally administrative operations target also these objects. So the question was posed how to present all these in a coherent way toward system management: Should each AIS service expose separately the management mechanisms it defines? Or should there be a common management access point for the entire system through which the individual services can be reached too?
There was a consensus within the SA Forum Technical Workgroup that it is beneficial to provide a single entry point for all management access. A number of existing system management standards were examined to facilitate integration with existing system management applications through the north-bound interface. An initial proposal to use the Common Information Model Web Based Enterprise Management (CIM/WBEM) from the Distributed Management Task Force (DMTF) was made. However in the process of constructing the model for the services by specializing the standard object classes from the CIM schema it was found that the resulting model would be too large and complex for many practical applications. The Simple Network Management Protocol from the Internet Engineering Task Force (IETF) was also considered. While it provided a simpler interface to management systems the naming and navigation between objects exposed in the model made it awkward to reflect the natural hierarchical structure of the AMF's system model. It was finally decided that there was no suitable standard that could be used ‘as is.’ The team finally agreed to base the solution on the well known Lightweight Directory Access Protocol from the IETF [60] incorporating the eXtensible Markup Language (XML) [81] approach of WBEM [94]. It provided a convenient hierarchical naming structure together with a flexible object model. Thus the idea of the IMM was born. This meant the following requirements toward IMM:
It needed to be able to integrate the information model of the different AIS services, those that have been already defined at the time this decision was made and also those that would come later. This required some flexibility, which in turn would allow applications to use the same means for their own information models and management needs.
Thus such a solution could provide common management not only for the AIS services, but also for the applications running in an SA Forum compliant system.
IMM then would expose the entire integrated model to any management application or agent that requires management access to the system. This would provide a uniform view of the model and a uniform handling of its objects, their classes, and operations. The management entity would not need to be aware to which service or application process implements a particular object and how to reach this service or application. Instead the IMM becomes a mediator that dispatches management request to the service or application whose portion of the information model is being manipulated.
IMM needed to offer an easy way to integrate with the different AIS service implementations and also with applications that expose their information model through IMM. Considering the HA environment this also meant that this integration had to allow for easy fail-over and switch-over of roles between different processes of these implementations even if that occurs during the execution of a particular operation.
AIS services and applications exposing their model through IMM needed to be able to obtain their configuration described in their information model. They should also receive any modification that occurs and the administrative operations issued on the model objects.
With this respect the main issue was the preservation of the integrity of the information model in spite of the fact that multiple managers may have access simultaneously to the model. Considering a bank account to which many people have access it is like trying to keep the account in the black while these people depositing and withdrawing from the account simultaneously. It may be challenging.
Even if it is a single manager that makes modifications to the configuration, the changes may impact more than one service and/or application in the system. There is often a dependency among different configuration objects, which means that changes need coordination.
The problem with this is that a management entity may only be aware of a new configuration it wants to achieve, but it may not know all the dependencies that need to be taken into account. Moreover transitioning a live system may impose further dependencies such as the ordering of the modifications.
Let's assume again the bank account with a current balance of zero and a single person accessing it. He or she would like to transfer some amount from the account and of course to deposit the amount to cover the transaction. As long as the deposit covers the transferred amount the account is in a good the standing. To guarantee this common sense dictates that the two transactions need to be in a specific order: first the deposit and then the transfer.
Since we are talking about the same account it is easy to see the issue and resolve the problem. The situation may be similar in the information model: Dependencies may exist among attributes of the same or different objects of the configuration. The manager would need to know and take into account all dependencies to perform any intended change.
This may require a deep knowledge of the system and therefore be challenging. It would be easier if the ordering could be left to the system to resolve, that is, to bundle the transfer and the deposit as a single transaction and let the account manager figure out in which order they need to be applied to avoid penalty charges.
To leave the task to the system makes sense as services and applications in general need to be prepared to check the validity at least of their own configuration. Cross checking also easier and more consistent if it is done by the system than if it is left to an administrator who may not know all the issues; and of course the IMM needed to support all this.
In response to management operations, but also due to operational changes within the system the status of the different entities in the system may change. On the one hand side services and applications should be able to communicate and expose these changes. On the other hand, the managers should be able to collect this information efficiently. As opposed to configuration changes and administrative operations, which are considered being relatively infrequent in a system, reading the information model and particularly the status information is required frequently. Therefore the IMM needed to be bias toward the read access.
Finally, IMM needed to provide a way of inputting the information model to provide the system with an initial configuration and also to store any current configuration persistently so that when the system is restarted it can reuse it as needed. It can also be used at fault recovery to restore a known correct configuration.
In the rest of this chapter we will look at how the SA Forum solution addresses these different requirements and needs.
8.4.2 Overview of the SA Forum IMM Solution
The IMM maintains the integrated information model for the entire SA Forum system. It is a repository for the model objects.
IMM was designed with the AIS services in mind; however this does not restrict its use. Applications may use it for the same purpose as long as their needs align with the basic assumption of IMM, that is, it is primarily for read access, and modifications (i.e., write operations) happen infrequently.
By managing the information model the IMM has to interact with two groups of entities in the system:
- It interacts with the management side (also referred as northbound interface), that is, with management applications, management agents, or the system administrator. In IMM terminology they are the object managers (OM).
- IMM also interacts with the services and applications implementing the entities in the system that are represented by the managed objects in the model, hence they are called object implementers (OI).
Accordingly the IMM specification defines an API for each of these sides as shown in Figure 8.3.
Figure 8.3 The overall view of the Information Model Management service.
An object manager has the following functions:
- defining the information model by defining its object classes; this includes configuration as well as runtime object classes;
- creating and modifying the information model by creating, removing, and modifying configuration objects; all these changes prescribe for the related OIs the configuration they expected to implement in the system;
- applying administrative operations to both configuration and runtime objects;
- controlling the administrative ownership of objects; only the OM holding the administrative ownership may manipulate an object, for example, modify a configuration object and issue an administrative operation on any object;
- monitoring the system status through reading and accessing part or the entire contents of the information model.
On the OI side the IMM distinguishes three different roles:
The runtime owner is the entity in the system implementing the managed object. All objects need to have a runtime owner for deployment and each can have at most one at any given time. The runtime owner's responsibilities are:
- to update the relevant runtime information in the model: this includes the creation, deletion, and maintenance of owned runtime objects; and the update of the runtime attributes of owned configuration objects;
- to carry out the administrative operations issued by an OM on an owned object.
Besides the runtime owner configuration objects may also have CCB validators and CCB appliers. CCB stands for configuration change bundle, which is a container for transactions of configuration changes put together by an object manager.
These roles (CCB validator and CCB applier) are associated with the validation and deployment of such a transaction of configuration changes in the system.
Whenever an object manager wants to manipulate the system configuration it constructs the list of configuration changes that describe the difference between the current and the intended configuration of the system. Such a list composes a given content of a CCB. When it is complete the OM applies the whole CCB content as a single transaction of configuration changes. In turn IMM delivers these changes to the OI side, first to the CCB validators and subsequently to the CCB appliers if applicable.
Thus the IMM invokes first all the CCB validators of the objects involved in the given CCB transaction. The validators check whether the new-proposed-configuration is valid (e.g., the changes are consistent and complete) and whether the application of the CCB transaction is possible (e.g., if all the resources are available). CCB validators also ensure that if they accept the proposed changes then the deployment of the modifications cannot fail. To ensure this they may need to make some resource reservations or other preparations. If any of the CCB validators rejects the transaction IMM aborts the CCB transaction and the system remains in the same configuration as before and this also makes sure that all the reservations are released and preparations are reverted.
If the validation is successful, next IMM invokes the CCB appliers to carry out the transaction. They deploy all the changes necessary to implement the new configuration.
The IMM invokes the CCB appliers in a predefined order, which can be configured.
Let us consider again our bank account example. Considering that the account can be accessed by many people aka many object managers, the one that wants to carry out a transaction needs to obtain the administrative ownership of the account for the time of the transaction. Once it has done so it can go ahead and define the CCB transaction consisting of the money transfer and the deposit. It does not need to worry about the order of the operations whether the transfer or the deposit comes first. Next, it can apply the CCB transaction.
Accordingly the IMM first validates the transaction with the CCB validator, which checks that at the end of the transaction the account remains in good standing. If it is the case IMM invokes the CCB appliers to deploy the transaction. In our case we have two of them: one dealing with credit and another performing debit transactions.
To guarantee that an account can be debited it needs to be credited first; hence the applier dealing with credits is configured to be invoked first. Once the credits have been processed the applier responsible for debits can execute its task and complete the operation.
It is possible that the same entity performs in all three OI roles for a given object or even a group of objects within the information model. In fact for most of the AIS services it is the service implementation which is expected to take all three roles. The role of the CCB applier is also suitable for those entities that are interested in being alerted when configuration changes happen in the system regardless whether they need to adapt to the change or not.
After this high level overview of the IMM let's look in some details at its APIs to get a deeper understanding.
8.4.3 The Object Manager API
The IMM uses a ‘minimalist’ approach. The Unified Modeling Language (UML) representation used by the AIS services for their information model is significantly simplified and the IMM provides a toolbox only for the essential features necessary for system management. The IMM relies extensively on the knowledge of the OIs and OMs. It assumes that the object management side does not need to specify anything that can be known by the OI side. It also means that an OM needs to be aware of the information model. For example, considering the information model defined for the AMF, both the AMF implementation and an OM (e.g., an administrator) are expected to know the hierarchy of AMF entities: That a component can be defined as a child of a SU, which in turn needs to be a child of a service group, and so on. In other words the IMM representation of the information does not reflect class relations. Similarly, it does not reflect administrative operations, so one cannot specify in the IMM representation, for example, on which objects one may issue an administrative lock. The OM and AMF are expected to have this knowledge.
Thus, management applications having no previous knowledge about the information model typically will not be able to obtain it from the IMM to be able to manage the system meaningfully. This obviously imposes limitations on the possible use of the IMM.
8.4.3.1 Object Class Management API
On the positive side this means that the information model can be easily populated with new classes and their objects. There is no need for a complex API.
Indeed IMM provides the interface to create new object classes for the information model. To do so, an object manager indicates for each new object class the name, the category (configuration or runtime), and the attributes with their features. The attribute features are limited to:
- the type—one of the value types defined in the IMM representation, which are those common to all AIS services, if the required type is not among these common types it needs to be mapped into one;
- a set of flags—indicating the multiplicity and the handling of the attribute (e.g., configuration, runtime, cached, etc.); and
- an optional default value.
This part of the class definition can also be inquired using the OM class management API.
IMM complements each defined class with an appropriate set of service attributes that are necessary for IMM itself. These contain information such as the different OIs associated with the objects of the class, the administrative owner, and so on. Note that we used the word ‘complements’ as IMM also does not support inheritance even though ‘classes’ and ‘objects’ suggest an object-orientated approach. Accordingly no inheritance can be defined between object classes either.
The A.03.01 version of the IMM specification, the latest at the time of writing, allows only the deletion of object classes. It does not permit their modification, not even the extension with additional attributes, which is often allowed by similar services and therefore it is desirable to remove this limitation.
Once a class has been defined one can populate the information model with the objects of the class. Objects of configuration object classes are created, deleted, and modified via CCBs. Objects of runtime object classes are handled exclusively by the OIs.
An OM may delete an object class only if it is not used in the system, that is, it has no objects in the model.
8.4.3.2 Administrative Ownership
The administrative ownership is a kind of locking mechanism provided by the IMM that implies some exclusiveness for accessing and manipulating IMM objects.
One could think of this mechanism as a rudimentary password mechanism. An object manager wanting to manipulate some objects in the information model creates a password that represents an administrative owner. Then it asks IMM to flag the target objects with this password. As long as the requested objects have no other administrative owner associated with them, the operation is successful. From this moment on only object managers initializing the same password aka having the same administrative owner name are able to manipulate these objects.
If an object manager keeps this information for itself it will have exclusive access to the reserved objects until it releases the administrative ownership. If the first object manager shares the information with other object managers then IMM will allow all of them to manipulate the reserved objects and the resolution of any type of concurrency between these managers sharing the administrative ownership is left to themselves.
Holding the administrative ownership is required to perform administrative operations and configuration changes. It does not prevent read access, which means a reader may obtain an inconsistent view across objects if some of them are being manipulated at the same time.
8.4.3.3 Configuration Changes
To perform any type of configuration changes an administrator needs to create a CCB first (see Figure 8.4). It is a container for a set of configuration changes, which is associated with an administrative owner and an identifier. Only objects owned by this associated administrative owner can be manipulated within the CCB.
The OM may use the same CCB to compose and apply subsequent configuration change transactions. Each such transaction is a set of operations that create new configuration objects, modify, and delete existing ones. The administrative owner of a newly created object is the administrative owner of the CCB.
To create an object one needs to indicate its
- parent object indicating where the object is inserted in the information model;
- object class given by its name; the creator needs to know this name as it cannot be inquired from IMM;
- attribute values—at least the Relative Distinguished Name (RDN) value and those attribute flagged as ‘initialized’ in the object class need to be provided. To identify these, the class definition is obtainable from IMM.
To delete an existing object it is enough to indicate its DN. The object may have no child objects at the time of the deletion. We will reflect on the considerations that this restriction requires when the child object is a runtime object.
To modify a configuration object again the object's DN is required as well as the modification type (add, delete, and replace) and the attribute values need to be provided.
The set of changes defined in a CCB is applied to the information model as a single transaction meaning that either all the changes succeed or none of them. The IMM serializes the application of CCBs to avoid concurrent modifications of the information model potentially leading to inconsistency. As a result one may consider that the IMM specification is overly cautious and it certainly may cause performance limitations when it comes to configuration updates. Thus this restriction is based on the assumption of infrequent model changes.
Once the content of the CCB has been applied it is cleared regardless whether the application was successful or not. The CCB as a container can be reused by the same OM to construct a new configuration change transaction.
While constructing a configuration change transaction the CCB identifier can be used to read the information model as if the changes have been applied already.
8.4.3.4 Reading the Information Model
For an OM there are two ways to read the information model:
If an OM knows the DNs of the objects it wants to read it can use the accessor API and get all the attributes with their values for each of those objects using their DN.
If the OM does not know the names of the objects it is interested in, it can use the search API to let IMM find all objects in the information model that match the search criteria. If the search criterion is empty, all objects of the information model will match it and the IMM will return each one of them as the OM iterates through the model.
If the search criterion specifies the attribute name or even its value then only objects owning an attribute with the given name are returned and only if the specified value matches at least one of its values.
Depending on the specified search options IMM may return only the object names, some, or all of their attributes.
When initializing either of these APIs with a CCB identifier, IMM returns the result as if the referred CCB has been already applied to the information model. At this time however it is not guaranteed that after applying the CCB the picture will be the same as there could be other CCBs that were created in parallel and that have been applied before the one with the given id. The exception is the period when the CCB with the given id is being validated since only one CCB can be in this stage at any given time.
Note that even though these APIs have been defined on the object manager side an OI may also use them. Of course, when doing so it becomes an OM itself. In fact this is the only way an OI can obtain its initial configuration. This Janus-faced behavior is needed only at startup. Once the OI has obtained its initial configuration it does not need to use the OM-API any more and may completely rely on the OI-API as we will discuss it later.
OMs are not aware whether the objects they are manipulating have OIs at the time of the manipulation. They however may indicate to the IMM whether the configuration changes should be applied in the absence of the relevant OIs by initializing the CCB appropriately. They can indicate whether any CCB validator, any CCB applier or both may be absent at the application of the CCB transactions.
8.4.3.5 Administrative Operations
Administrative operations are applicable to both configuration and runtime objects. They also require the administrative ownership of the targeted object; however, they cannot be part of a CCB and an object cannot be targeted by an administrative operation and a configuration change transaction at the same time.
We point this out as configuration changes may require that the target object—or more appropriately, the entity it represents—is in a particular administrative state, which can only be achieved by issuing an appropriate administrative operation. That is, in such cases the OM needs to synchronize the administrative operation with the configuration change transaction.
A typical example of this synchronization case is AMF, which requires that before one is able to remove a SU and its components from the configuration the entities need to be terminated. This an administrator can only achieve by locking them for instantiation, which in turn requires a lock operation preceding the removal. Thus, the lock operation(s) needs to be issued before the delete change request is added to the CCB.
Each administrative operation requires a target object. An operation may have additional options, however very few AIS services use this possibility. When the OM issues the administrative operation toward the IMM, IMM forwards the request to the runtime owner of the target object. Only the runtime owner interprets the requested operation, executes it, and returns the result to IMM, which the forwards it to the OM.
The peculiarity of the API provided by IMM for administrative operation is related to the potentially long execution time of some operations and the HA nature of the system. If an object manager process requesting an administrative operation dies while the operation is in progress, IMM will not know to whom to return the result of the operation at the time it becomes available. Due to the HA nature however failures are handled by failovers, which means that there is normally a new process replacing the failed one that would like to receive the result. To do so, OMs initiating an administrative operation may provide an identifier with it. This identifier serves then as a token to obtain the result should the original process die during the execution of the operation. Of course the initiator process needs to share this information with its standby.
8.4.4 The Object Implementer API
The OI side of the ‘IMM world’ is more complex than the OM side. This is due to the intention of relieving the OMs of some of the tasks and knowledge that can be embedded in the system or more precisely in the OIs. So the intention is to put most of the burden on the OIs and not on the OMs.
8.4.4.1 Object Implementer Roles
As we mentioned earlier one of the major issue in the IMM is maintaining the consistency of the information model in the context of concurrent and interdependent changes. The third version of the IMM specification put most of the efforts into resolving this issue. Accordingly, it has introduced the three different OIs roles: the runtime owner, the CCB validators, and CCB appliers.
The need for the CCB applier role is most straightforward. As we have seen on the OM side, IMM provides no alert mechanism that a configuration object has been modified in the information model. A CCB applier is a process, which needs such an alert. The reason a process would like to receive an alert is usually because it needs to adapt somehow to the change. Hence it applies some of the changes introduced by the CCB to the system—it is a CCB applier.
Now if there are some constraints to what extent or in which cases this imaginary process can adapt to the change then it would want to make sure that the changes remain within those constraints. To achieve this it needs to validate first the proposed changes, that is, it needs to be a CCB validator. In the CCB validator role a process gets a ‘voting right’ whether the change is acceptable or not. It also gets the obligation to prepare for the change so if it gets accepted by all voters, that is, all CCB validators the CCB appliers indeed can go through and deploy the change.
The runtime owner is the process which maintains the runtime information presented in the information model. This reflects toward OMs the runtime status of the deployment. The runtime owner also carries out the administrative operations issued by an OM on a managed object.
The runtime owner typically would need to be a CCB validator and a CCB applier as well. However IMM does not imply this. OIs need to register with IMM for the roles they want to take up with respect to a given configuration object or an entire configuration object class.
In case of runtime objects the situation is much simpler: They only have runtime owners and it is the one who creates the object.
8.4.4.2 Object Implementer Role Registration
Because we are looking at HA systems we need to consider fail-overs and switch-overs with respect to the OI roles. To allow these the IMM specification defines an indirect registration process:
First of all we select an OI name to represent a process that will need to fulfill different OI roles for a set of objects. Then this name is set for these different objects in the intended OI roles. This can be done by setting the name for individual objects or for entire object classes.
Subsequently when a process capable fulfilling these OI roles wants to take up the roles for all those objects associated with the name, it only needs to registers for the name and with this registration it obtains all the appropriate OI roles for all the associated objects.
If the process fails unexpectedly the new process replacing the failed one needs to do the same: register for the OI name. If a process needs to turn the roles over to another process it can clear its own registration for the OI name after which a new process can register itself for the name and thus obtain the roles the OI name represents.
When an error occurs that an object has no OI that typically means that there is no process associated with the appropriate OI name. It is less likely that the OI names have not been set as the IMM attributes storing this information are persistent runtime attributes for all persistent objects (i.e., configuration and persistent runtime objects).
8.4.4.3 CCB Validator and CCB Applier API
When the OM constructing a configuration change transaction added all the required changes to the CCB it applies the CCB. This is the moment that the CCB validators and CCB appliers step in.
First the IMM calls back the CCB validators for all the objects involved in the CCB. This means the objects being manipulated, and if necessary their parent objects as well. For example, when an object is created the CCB validator for the parent object is invoked as there could be limitation on what type and what number of children it may have.
Each CCB validator receives only one callback per CCB transaction providing the CCB identifier only. The CCB validator needs to find out itself how many of its objects and in what type of changes are involved in the current transaction.
To find out this information the IMM provides a CCB iterator API on the OI side. For a given CCB id this API is available only from the moment the object manager applies the CCB and only until this function call returns.
The API is similar to the search API discussed on the object management side except it provides access only to the model changes of the given CCB transaction (i.e., the objects created, deleted, and modified).
The CCB validator needs to evaluate all the changes for all objects it is responsible for and if it finds them appropriate it needs to make all the preparation to ensure that the CCB can be applied. This may mean cross checking with other objects in the model or entities in the system and may go as far as resource reservations.
Once the CCB validator made sure that there is nothing on its side that would prevent the deployment of the CCB transaction, it can accept the CCB by returning an OK. Otherwise it returns an error and the CCB cannot proceed.
If any of the CCB validators responds with an error or does not respond within the expected period, the CCB transaction is aborted by the IMM. This means that the IMM invokes again all involved CCB validators to inform them about the abortion so that they can release any state or resources held for the perspective of the deployment of the transaction.
When the IMM receives an OK from all validators invoked for a CCB transaction, it proceeds by invoking the CCB appliers to deploy the configuration changes. IMM invokes the CCB appliers in the order of their configured ranks starting with the highest ranking appliers and invoking the next rank only after the first group has completed the operation and returned from the call or had enough time to do so.
Even if an applier does not respond to the callback (i.e., the associated timer expires before the callback completes or the applier process dies), the IMM proceeds with the deployment. The CCB transaction cannot fail after the CCB validators accepted it. All changes are applied at least to the information model and an applier may deploy them later when it becomes available again.
8.4.4.4 Runtime Owner API
Runtime owners maintain the runtime objects and attributes of the information model and also execute the administrative operations issued by OMs.
For the first task IMM provides an API that allows the creation and deletion of runtime objects; and the update of runtime attributes of any object let it be configuration or runtime. These are similar to the creation, deletion, and modification of configuration objects except that they are not bundled into transactions since only the runtime owner has write access to runtime objects and attributes and there is always at most one runtime owner for each object.
The nuance of the attribute update is that it may be performed in two ways: Either the runtime owner updates the attribute each time its value changes—these are the cached attributes—or the IMM asks the runtime owner to perform an update to satisfy an OM's request of obtaining the value of a non-cached runtime attribute. Whether a runtime attribute is cached or not is defined in the object class definition.
The IMM also calls back the runtime owner of an object if an OM issues an administrative operation on the object. Since the information model does not have any information on the applicability of administrative operations, it is the runtime owner which verifies whether the operation is valid for the particular object or not. If so, it executes the operations. In either case the runtime owner provides the IMM with result that in turn the IMM passes on to the OM, which requested the operation (or asked for the result).
The ‘result’ that the specification allows to pass through is simply an error code indicating whether the operation was successful or not. It does not allow the passing of any additional values, which in some cases could be beneficial.
That is, the IMM is quite ignorant about the administrative operations and only provides a very simple pass through mechanism between the OMs and the OIs.
However, even this simple mechanism allows for the switch or fail-over of the OM role requesting an administrative operation by providing an operation identifier, which can be used later by another process to obtain the result of the requested administrative operation.
8.4.5 IMM XML File
The IMM specification defines the OM-API and OI-API as part of its user interface. In addition it provides a standard XML schema, which defines the XML format to represent the content of the system information model. Any time the IMM is asked to export the content of the information model it stores the appropriate data in a file using this format. Such an XML file can also be given to IMM as an initial configuration of the system.
The schema defines two main schema elements: One for class definitions and another for object definitions. The sub-elements of the class definition describe the features of the class attributes; while sub-elements of the object definition assign values to the class attributes.
8.4.6 Administrative and Management Aspects
The IMM itself uses two configuration object classes: One for configuring the service itself and the second for configuring the CCB appliers. The single object of the first class allows an administrator to define:
- whether at startup IMM should use its internal repository or an XML file containing an initial configuration for the system;
- the timeout period to be used with CCB validators and CCB appliers.
In addition the object also provides different status information such as:
- the time of the last configuration update in the model;
- the current number of initialized CCBs, OIs, and administratively owned objects;
- the uniform resource identifier (URI) for the XML file where the IMM content was exported.
The IMM specification defines only one administrative operation, which is applicable to this same object. As a result of this administrative operation an IMM implementation exports the persistent content of the information model to a file with the path name given as a parameter to the administrative operation. Obviously, this also updates the URI status attribute mentioned above.
The second configuration object class is to configure CCB appliers by their name and rank. The rank determines the order in which IMM invokes them when applying a CCB transaction as we discussed in Section 8.4.4.3. This configuration is not exhaustive, that is, it is not necessary to list all CCB appliers in the system. CCB appliers that were not configured explicitly are invoked last after all configured CCB appliers.
8.4.7 Service Interaction
All the AIS services that have an information model use the IMM for storing their respective information model and to expose their administrative API, which allow the manipulation of the information model.
Each of the AIS services acts as the OI for its part of the system information model. That is, it registers with IMM as the OI for the object classes representing its entities.
Typically an AIS service takes all three OI roles for its configuration objects. Accordingly IMM calls the service back in the CCB validator role when any of its objects is part of a CCB that is being applied by an object manager. If the validation was successful, IMM also invokes the service in the CCB applier role. The application of the CCB may also result in status updates of the object(s), which the AIS service performs in the runtime owner role.
As a runtime owner a service is responsible to update all the runtime attributes and also create and delete runtime objects; as well as execute the administrative operations invoked on its objects. Runtime objects have only runtime owners.
However before any of the OIs can implement its configured objects it needs to take up the role of an OM to obtain the initial configuration as only the OM-API provides read access as we have seem in Section 8.4.3.
8.4.7.1 Interaction with CLM
The same ways as other cluster-wide services the IMM APIs are also available only on cluster member nodes. This means that an IMM implementation must use the CLM API to determine the scope of the cluster at any given moment in time and process user requests accordingly. That is, it needs to use the CLM track API.
On the flipside, the CLM as well as the PLM use IMM to store their respective information model. This creates a chicken and egg situation. The IMM specification leaves it to the implementations to resolve the issue and does not mandate any particular solution. One possibility though is to store some of the PLM and CLM configuration locally and use it during cluster formation until the node becomes part of the cluster. Once the cluster has formed, IMM becomes available and the implementation can adjust to the most up-to-date configuration available in the information model.
8.4.7.2 Interaction with NTF
The IMM does not generate any alarms, but it does generate notifications and uses NTF to communicate them to all interested parties.
Rather than the individual AIS services, it is the IMM which generates the notifications to indicate the start and the end of administrative manipulations such as administrative operations and configuration changes. This centralization is also geared toward the consistent handling of these aspects of the SA Forum system management.
Whenever an object manager invokes an administrative operation on an object in the information model, IMM generates the associated notification. It does the same when it returns to the OM the result received from the OI.
In both notifications IMM provides the name of the object targeted by the operation, the id, and the parameters of the administrative operation, and any correlated notification id as appropriate. On that note, an administrative operation end notification is always correlated at least with the administrative operation start notification.
IMM also generates notifications for CCB transactions: It generates a configuration update start notification when an OM applies a CCB; and it generates the corresponding configuration update end notification when the apply call returns. At this point the CCB might have been deployed successfully or aborted. In any case the notification contains the CCB identifier and the error code returned to the OM.
It is important to realize that the CCB identifier used in the notification is more of a session identifier and it does not uniquely identify the particular CCB transaction. On the other hand, the two notification ids generated by NTF at the beginning and at the end of the CCB transaction are unique for the CCB transaction. Moreover IMM returns to the OM the notification identifier generated at the end of the transaction as an out parameter to the OM's apply call. In addition the same way as for the administrative operations, IMM correlates the configuration update start and end notifications.
8.4.8 Open Issues
The IMM specification is a relative latecomer to the set of AIS specifications. The version in effect at the writing is A.03, which means that there were only a few revisions so far. In particular, the first two versions of the specification did not distinguish between the different OI roles. They were introduced by the A.03 version, which means that this most complicated portion of the API had no revision yet. Some question its maturity.
However the open issues are not limited to this newest portion of the specification, but also touch other portions.
One of the most debated issues probably is the separation between the north- and the southbound interfaces—in IMM terms between the OM-API and the OI-API.
As we have seen in Section 8.4.4 the OI-API does not provide the capability of reading the content of the information model. Any OI that needs to obtain its initial configuration has to become at least temporarily an OM to read its configuration.
The SA Forum Technical Workgroup came to the conclusion that it is mostly the question of taste whether complete separation exists between the two interfaces as it introduces the duplication of the functionality. In the attempt of keeping the APIs simpler for the time being the choice was not to repeat essentially the same API on both (OM and OI) sides if it was not necessary.
Other issues are also stem from this minimalist approach. Namely the class management API allows the creation and deletion of classes, but not for the modification. This means that whenever a class of the information model is upgraded all its objects need to be deleted first to be able to delete their class. Only after this the new version of the class can be created and repopulated with the earlier deleted objects now adjusted to the new class structure.
Many see this procedure as rather cumbersome and avoidable particularly when the new version of the class only extends the existing class with some new attributes. IMM implementations could handle such an update easily and efficiently even in a transactional manner, if it was required by the specification. However this implies additional class handling functions not present in the current API. Considering the life cycle of HA systems this issue demands a rather urgent resolution.
Another issue that needs short term resolution is the restriction that objects cannot be deleted if they have child objects. The reason for the urgency is that this means that applications effectively are able to ‘freeze’ the configuration by appending runtime objects as children to configuration objects. The IMM will not allow an administrator to delete any of such configuration objects unless the runtime objects are removed first. However there may not be a way or it may not be obvious how to make the OI to remove those runtime objects.
This shows that application designers need to pay particular attention when designing the information model of their application. Most of the AIS services give a free hand of inserting the runtime objects as most appropriate for the application rather than defining the relevant insertion point.
The issue has been discussed by the SA Forum Technical Workgroup and there is an agreement to allow an OM (e.g., the administrator) to delete from the information model configuration objects even if they are parents to other objects. This change will allow—albeit indirectly—the administrative deletion of runtime objects such as runtime log streams which contradicts with the current definition of the ‘runtime’ category and it is a paradigm change.
At the time of the writing it has not been decided yet how this will be handled on the OI side. The problem is that none of the AIS services that define runtime object classes is prepared for the situation that such an object is deleted by an administrator. Currently they are in full control of their runtime objects. This means that neither the IMM OI-API nor the different AIS service APIs define the appropriate functions. Considering a runtime log stream, for example, it is a big change in the service philosophy that such a log stream can cease to exist while being in use by any of the service users.
The last issue that we would like to address in our discussion is related to the serialization of CCB transactions. Namely, that IMM performs the validation and application of CCB transaction one at a time.
This issue is related to the basic assumption made at the outset of the definition of the IMM according to which IMM is used primarily for read operations as configuration updates occur infrequently. Changing this paradigm requires significant changes to the whole service definition, which is not desirable at this time. It requires more justification supported by deployment experience.
Obviously the bigger the information model an IMM implementation manages more restrictive this limitation may become. It may become necessary considering that the different CCBs may manipulate unrelated parts of the information model.
However today there is no definition what ‘unrelated’ means for CCBs. The problem is that even though an object manager may be manipulating only object X in the model, the manipulation may be based on reading objects Y, Z, and W. There is no way to know this relation. The traditional database handling paradigm would require a lock on all four objects accessed in such a case. Within IMM a similar effect can be achieved currently by the object manager obtaining the administrative ownership of all the additional objects. However IMM does not require this and another CCB may manipulate any of Y, Z, or W compared to the time of the reading. Even the serialization does not help in this case. It would be the CCB validators' task to catch such an inconsistency.
Note that since the CCB would include only object X, an OI (CCB validator or applier) would need to use the OM-API to check these objects, but due to the serialization during the validation phase the immutability is guaranteed.
What may become more critical is that some systems may need to handle embedded CCBs. That is, considering the previous example the modification of X included in a CCB would require not just the reading, but the modification of Y, Z, and W, which are not part of the current CCB. Typically this would be solved by nesting a new CCB into the current one, and it also requires that the current CCB should succeed only if the nested CCB succeeds. While obtaining the administrative ownership of Y, Z, and W can guarantee that they can be modified in a subsequent CCB as necessary, this mechanism cannot guarantee the rollback of both CCBs should any of them fail. This would require substantial effort on the CCB validator of object X.
8.4.9 Recommendation
Considering all the aspects of the IMM the most important recommendation is to use it only for cases when the basic assumption is true, that is, the model is mainly accessed for read and write operations happen relatively seldom.
Application designers using the AIS service APIs that trigger runtime object creation need to consider the consequences of inserting these objects at different places in the information model. The tendency may be to attach them to the configuration object they are in relation with. This may be appropriate if the administrative manipulation of the configuration object controls the lifecycle of the runtime objects. For example, if the administrative locking of the AMF SU, which triggers the removal of any CSI assignment from its components also removes the runtime objects. Therefore changing the configuration of components within the SU becomes possible as they will not have attached such runtime objects, which is one of the typical reasons why a lock operation would be issued, for example, during software upgrades.
One of the reason why using the component as a rooting point for runtime objects becomes tempting is that its name can be obtained via the AMF API at runtime. In reality, however, the related CSI name can also be collected from the API callbacks even if it cannot be obtained by solicitation. A CSI may serve as a better insertion point for service related runtime objects, such as a checkpoint associated with the service state of the served CSI. Although this may not be suitable for all cases.
Sometime the runtime objects' life cycle cannot be linked to any other object than the object representing the service or the application itself. This is the path the AIS information model recommends for many service specific configuration classes. For example, it is recommended that configuration log streams are rooted in the well-known AMF application object representing the LOG itself.
When no other option is suitable, objects can be placed at the root of the information model. However this is least recommended as it ‘pollutes’ the information model.
8.5 Conclusion
In this chapter we reviewed the AIS services that allow the control, management, and monitoring of an SA Forum compliant system.
In particular we looked at the IMM, which combines the information models of the different AIS services and applications into a single model to expose it to management entities (e.g., system administrators, management applications) in a coherent and consistent way. Using the IMM OM-API these management entities may monitor, configure, and otherwise manipulate the SA Forum system through monitoring and manipulating the objects in the information model. The IMM dispatches these actions to the OIs registered as responsible for the manipulated object. Object implementers are the implementations of the different AIS services and applications that expose their objects through the IMM.
As a result the IMM is the primary management interface to an SA Forum system and its applications. Its specification defines the OM-API and OI-API together with the information model that configures the IMM implementation itself. In addition the SA Forum also defined the XML schema to describe the content of the IMM information model, which can be used to provide the system with an initial configuration or to export the current configuration of an SA Forum system.
Through exposing the information model, the IMM provides an up-to-date view of the system, however it does not collect data over the system life-cycle that would suitable for the offline analysis of the system behavior, nor it is capable of alerting the system management whenever an urgency requires so.
To address these issues in addition to the IMM, the AIS provides API definitions for the LOG, and the NTF.
The LOG is tailored for collecting information about the system behavior over relatively long periods of time, even its lifetime. This means that the information gathered by the LOG is higher level information suitable for system management for the analysis at the system level rather than trace data that would allow the detailed analysis and debugging of specific applications and software components.
The LOG defines an API through which users write their log data to the appropriate log stream without needing to be aware of the formatting and other needs of the output file or files. The output formatting and other configuration features of the log files defined and managed separately, for example, via the IMM and the LOG deploys these changes transparently for the users using the impacted log streams.
The LOG provides API only to collect information; it does not provide API to access the collected data. The log files need to be harvested together with their associated configuration files for correct interpretation. On the other hand, using these means anyone shall be able to interpret the collected information within or without the system.
As oppose to the LOG's long-term data gathering, the NTF allows its users to dispatch alerts about significant changes in the system that potentially require immediate reaction from parties other than the dispatcher. This receiver could be another SA Forum service, an application, but most importantly an administrator—a person responsible for the system maintenance who may need to perform some manual intervention. For cases when such manual intervention may be necessary the NTF defines the categories of alarms and security alarms, while for cases that are expected to be handled by other components of the system or serve informational purpose the specification provides different categories of notifications such as state change, attribute change, object create and delete, and miscellaneous notifications.
Accordingly for entities dispatching notifications and alarms the specification defines the producer API, while entities monitoring these reports use the reader and/or subscriber API of the NTF.
Both the LOG and the NTF provide different filtering possibilities that allow users and administrators to protect against overload situations and also to customize the information collected or the delivered to their needs.
In summary the three services presented in this chapter define a consistent and coherent management view and access to an SA Forum system, its services as well as its applications using these services.
When the systems' expected in-service performance is five ‘9s’ or above system management becomes a deal breaker. However managing such complex systems in an open and expandable way is a complex task by itself. Therefore the uniform handling of different system management aspects allows one to focus on the actual issues at hand. While this feature is essential in HA systems, it may also be beneficial in other complex systems with less stringent requirements.
1 At the time of writing configuration log streams for applications are part of the upcoming release.