
Chapter 15
Migration Paths for Legacy Applications
15.1 Introduction
Systems that are required to provide highly available services typically have long life-cycles. Once deployed, they are in service easily for decades during which they go through periodic updates and upgrades of their hardware and software. Furthermore, during this time new technologies also emerge and for the system owners it becomes a challenge not just to understand these technologies but to decide whether any of them should be deployed in their existing system, and if the answer is yes then which ones.
As a result, we cannot speak about the updates in the traditional sense which would update some old hardware and/or software to a newer version of the same kind. The changes are more substantial. Some examples one may think of are: Replacing an object-oriented database with a relational one; migrating from one operating system to another; migrating from a legacy high availability (HA) middleware to the Service Availability (SA) Forum middleware. In this chapter we focus on this last case: On the migration of applications from a legacy HA middleware to the SA Forum Application Interface Specification (AIS) middleware.
We first look at the drivers for the migration, and then we continue with the review of the different aspects of system integration to define its levels with respect to the SA Forum specifications. Using this scale we set our ambition level for the migration, which is followed by a detailed discussion on how to achieve it. We present the applicable approaches and techniques that can be used for the different services and most importantly for the Availability Management Framework (AMF) [48].
Throughout this chapter we will use the term SA Forum middleware referring to a middleware implementation compliant to the SA Forum specifications.
15.2 Reasons for Migration
There are various benefits for migrating legacy software to a standard-based system, such as one based on the SA Forum specifications. They range from business benefits to technical benefits. In this section we focus on those relevant to system owners/operators and to software vendors.
15.2.1 Benefits for System Owners
System owners or operators who want to provide some application services in a highly available manner may achieve this in different ways.
The first option is that they develop themselves the functions that support the availability and management needs of the target application system. Since there are different application components and most of them need these functions, it makes sense to provide them as middleware services.
Sometimes this alternative seems attractive since when building a new application system the designers often perceive that they need only a subset of the functions typically found in an HA middleware. This choice however comes with the associated risk that as the application system evolves it will require more and more such features. In the long run this leads to a full-fledged proprietary middleware solution with the full maintenance responsibility as well as with significant integration efforts any time a third party product (3PP) component needs to be brought into the system.
Therefore a better alternative is to use an already available middleware. This avoids the efforts and expenses associated with the development and maintenance of the new proprietary middleware. It also allows the application system designers to focus on the logic of their application.
To build a complete application system, a number of application components may be needed such as a database, different protocols stacks, a web server, an Internet protocol (IP) load balancer, and so on. The number of components depends on the nature of application being built. An enterprise application will usually contain more application components while a low-end embedded system will have less. Using an existing middleware allows the designers to leverage the existing ecosystem of 3PP components resulting in a shorter time-to-market without compromising the overall system characteristics including availability.
There is a clear advantage of selecting a middleware with interfaces compliant to some standard. Such a choice increases the size of the ecosystem, that is, the number of already available application components. It also diminishes the chances to become locked-in with a proprietary middleware solution.
Up to date the only standard based solution is a middleware implementation compliant to the SA Forum specifications. At the same time there exist already a large number of application components, both commercial-of-the-shelf (COTS) and proprietary, that have been developed for different proprietary middleware solutions. Many of these have years and even decades of development investment. It is a no surprise that system owners would like to leverage these existing components and focus on building new added-value.
This is possible only by migrating these existing application components to the standard based middleware, that is, an SA Forum middleware.
15.2.2 Benefits for ISVs
From the discussion of Section 15.2.1 follows that the most important benefit for an independent software vendor (ISV) to produce COTS components, which have been integrated with an SA Forum middleware, is the portability of their product. In other words, the reduction of the integration efforts needed by their customers, owners of an SA Forum middleware based systems.
Thus, from the perspective of owners of SA Forum compliant systems ISVs who offer components already integrated with the SA Forum middleware would typically fall into the preferred category among providers of COTS components for their system.
In this chapter we discuss the efforts required to integrate applications with the availability management as well as with system management. These integration efforts are hardly ever negligible and far too often underestimated. We would like to point out also that the efforts needed to integrate an application with the system management are often at same level or even exceed the efforts required for the availability integration management.
15.3 Integration Criteria
15.3.1 Main Factors
When integrating an application with the SA Forum middleware and analyzing its different aspects a rather common question emerges:
What it means to integrate an application with SA Forum middleware?
More specifically, which SA Forum services the application component needs to use to qualify as an integrated component?
As we have concluded in Chapter 10, the standard is completely open here, so we need to come up with some criteria ourselves. For this we analyze the needs of the system owners operating the deployed systems as well as those relevant to vendors delivering end-solution, that is, complete systems. Note that in some cases the vendor and the customer are the same entity.
The two factors most important to operators or end-customers owning the deployed systems are: The service availability (SA) provided by the system, which is also referred as in-service-performance (ISP), and the cost of ownership, which the customer would like to have as low as possible.
- The ISP of the system: The system owner obviously would like to have the best possible availability figures as well as maintaining service continuity since any problem in this area directly impacts the user experience, which in turn impacts the system owner's business. It is not so easy to sell the services of an unreliable system.
To reduce downtime and have a good system ISP, it is important to have a system that is easy to manage, which has a streamlined architecture and which runs high quality code.
- Cost of ownership: HA systems are typically nonstop embedded systems with a long life-cycle, which accordingly, have a significant operational cost. Thus the system operator is interested in having these ownership costs as low as possible. Interestingly the criteria mentioned in the previous bullet apply here as well. The system needs to be easily manageable as handling problems impacting the ISP will decrease the revenue and increase cost; it needs to have a streamlined architecture so there is a common way of handling of the entire system; and it needs to run high quality code creating fewer problems and needing less troubleshooting.
The factors important for (end-)vendors are:
- Easy maintenance
This includes capabilities like easy localization of the source of problems when they occur; the capability of exposing events that have the potential of escalating into severer problems in the system; and a streamlined architecture.
- ISP: As we have seen bad ISP figures have a direct business impact on the system owners, that is, the vendors' customers, thus, they impact (in)-directly the (end-)vendor.
We can see that the easy management, the streamlined architecture, and the code quality are reoccurring factors that are important for both the system owners (end-customers) and the (end-) vendors. In following sections we take a deeper look at each of these factors to understand how they relate to the integration of applications with SA Forum middleware.
15.3.2 Easy Management
By easy management we mean that throughout the product life-cycle the system operator has an easy way of executing the typical management tasks. In other words, while managing the system the operator is able to achieve the desired results, deploy the desired changes in the system in a relatively simple way, and with a minimal risk of causing unwanted side-effects.
To determine this we consider the typical management use cases of configuration management, software management, and fault management.
We elaborate on each of these areas in following sections.
15.3.2.1 Configuration Management
During the prolonged operation of a system it is inevitable that an operator will need to change some of the configuration parameters as a result of changes in the operator's network, adjustments to service parameters, and so on. Most importantly the operator would like to perform these operations in a transactional fashion to ensure that the related configuration changes are either all applied to the system or none of them are applied.
It is more difficult to manage a system that does not support transactional handling of configuration changes because it allows for the partial deployment of the changes that may be inconsistent. Consequently it is easier to end up with a miss-configured node or a miss-configured application, which in the worst case may impact ISP and in turn the revenue.
By the ease of configuration management we also mean a uniform way of handling of the different parts of the system; that the configuration management of the whole system is done in a common way. An operator does not need to be aware of the internal structure of the system and its potential complexity. To reduce mistakes he or she should not be required to configure the different parts of the system in different ways.
With the definition of the Information Model Management service (IMM) discussed in Chapter 8 [38] the SA Forum offers a basic configuration infrastructure capable of changing configuration data in a transactional manner. It allows for application specific validation of configuration data represented as configuration objects and attributes as discussed in Chapter 4. It also provides a representation for the state and other runtime properties of the system via runtime attributes and objects.
By modeling in IMM any configurable property of the system (or application) that requires exposure to the operator, vendors can achieve an easy and uniform way of handling of configurations, which also results in a streamlined architecture for configuration management. Such a solution additionally offers:
- easier implementation options of the configuration data backup and restore procedures;
- the possibility of spanning transactions across the complete configuration space; and therefore
- a global consistency of configuration data across the entire system.
We need to mention another possible, but less attractive alternative of achieving the ease of configuration management: the aggregation of the different configuration management services of the different subsystems can be done closer to the operator.
While this approach seemingly achieves the same result as the integration with a single configuration management service (like IMM) there are severe drawbacks:
The most important drawback is that the consistency cannot be guaranteed across the complete configuration space since, typically, the different composing configuration services are not able to guarantee the transactional semantics for the changes spanning across multiple configuration services. Additionally, the internal architecture of such a solution is also not streamlined, which negatively impacts maintainability as among others it becomes more complicated to create a backup of the entire system configuration and to restore it.
15.3.2.2 Software Management
During the life-cycle of a system an operator will also need to upgrade the system numerous times let it be due to the periodic correction and functional releases provided by the software vendors, or because of the need to adapt the structure and size of the system to the new functional and performance requirements.
Similarly to the configuration management discussed in Section 15.3.2.1; by the ease of software management we mean that the same mechanism can be used no matter which part of the system is being upgraded. Whether the change is in some kernel modules of the operating system, in the middleware itself, or in an application running in a Portable Operating System Interface for Unix (POSIX) or a Java environment, it is beneficial for the system operator if all software upgrades are done in a uniform way in the system.
Considering HA systems and SA an even more critical factor is whether in-service upgrades are possible, that is, whether the software management solution has the capability of upgrading the system without any downtime and with no or minimum service disruption.
The SA Forum has specified the Software Management Framework (SMF) [49] to support the upgrade of systems from one deployment configuration to another while they are in-service. It defines the upgrade process in such a way that no manual steps are required during the upgrade. An important characteristic of the SMF is its close interaction with AMF, which ensures that the impact on the provided services is kept at minimum. SMF has been presented in Chapter 9.
To achieve a seamless software management, it should be possible to upgrade all components of the system via SMF. SMF is suitable for this task since it has been specified as a framework, which—among others—is open toward the different software packaging concepts.
The unappealing alternative to this uniform software management is a system with a different upgrade mechanism for each part of the system. For example, the operating system level functionality is upgraded using the operating system's software management functionality, while some application software running in the Java Application Server is upgraded via the upgrade mechanism specific to that particular Application Server. When such different mechanisms are directly exposed to the operator, the operator becomes aware of the heterogeneity of the system and the task of software management is not so easy any more. In such a system it is almost impossible to coordinate the simultaneous upgrade of multiple interdependent functionalities.
For SA Forum compliant systems the ease of software management can be achieved by ensuring that the upgrade of the different system components can be driven by SMF. As a result this enables operators to upgrade any part of the system in a seamless and transparent way.
15.3.2.3 Fault Management
Fault management refers to the capability of the system to notify the operator that some event happened in the system that requires attention and possibly the intervention of the operator. There are two main classes of such events:
- Alarms, which are events that require operator action to resolve the problem; and
- Notifications that are sent for informational purposes.
Similarly to the discussions on the configuration and software management we consider fault management easy if it is done in a common way using the same infrastructure service.
The SA Forum has defined the Notification service (NTF) [39] as such a service that provides support for fault management in SA Forum compliant clusters. The NTF allows for the classification of events as alarms and notifications and setting delivery guarantee policies, filtering, suppressions criteria. The service is described in more details in Chapter 8.
System components that generate these types of events need to be integrated with the NTF Producer application programming interface (API) so that they can report the events via the NTF.
Again the unattractive counterpart is a system, which internally has multiple different ways of reporting errors and problems. This complicates the fault management, since the internal complexity and heterogeneity of the system is exposed to the operator and it becomes hard to correlate the information about errors coming from different sources if is possible at all.
15.3.3 Streamlined Architecture
We have mentioned streamlined architecture several times, but have not defined what we meant by it. The best way to explain is through examples that make an architecture not streamlined.
In the context of our migration discussions we do not consider an architecture streamlined when there is a duplication of functionality in the system, and especially if these are functionalities of system-wide services that are required by many system components at all system levels such as multiple logging services, multiple configuration services, different availability managers, different ways of upgrading different parts of system. Multiplication of such services leads to a nonstreamlined architecture.
There can be multiple causes for the duplication of functionalities such as combining certain type 3PP software with (legacy) application components developed in-house, or when different parts of the system consists of components developed in different programming languages.
In an effort to make their product more adaptable to different environments and for faster portability some ISVs embed some basic availability and manageability support in their product. This is in contrast with the architectural pattern where the 3PP components contain only the core functional parts, but using a portability interface they are prepared to be fitted to different availability and management services already existing in the different environments they are being integrated with.
While embedding some HA functionality initially looks appealing since it is faster to get the 3PP up-and-running in the different environments, it is typically harder to achieve a good integration of such components. This approach duplicates the availability and management functionalities leading to a nonstreamlined architecture.
The cornerstone functions in any HA middleware are the group membership service and the availability management service. In the SA Forum architecture these are provided by the Cluster Membership service (CLM) [37] and the AMF [48].
Aligning the system in such a way that it uses a single instance of these services significantly helps in streamlining the availability management of the system. It results in better and more predictable availability characteristics, easier troubleshooting, and less service disruption during system upgrades. As an example we can see that in the SA Forum architecture SMF avoids duplication by interacting with AMF whenever it needs to ensure minimal service disruption during upgrades.
In the area of system management we have already identified that configuration management, fault management, and software management are the services that have direct impact on manageability. By applying the appropriate services across all the levels of the system we can streamline the management architecture as well.
In the SA Forum architecture it is the IMM that provides support for configuration management, the NTF provides support for fault management, and the SMF for software management.
During troubleshooting and root cause analysis of the problems occurred in the system it is important to be able to reach a conclusion about what went wrong and localize the fault based on the available logs. Having multiple logging services with different rules and settings for logging data, some being cluster-wide while others are node-local, with different rotation policies makes the troubleshooting task rather challenging. The SA Forum has also standardized a cluster-wide Log service (LOG) [40], which can be used for logging cluster-significant events. Adapting the functionality across the system and using the LOG makes the troubleshooting work easier.
Of course, we should not forget that in case of logging the largest responsibility lies always on the shoulders of the application designer—the user of the logging service—to ensure that the appropriate information is logged and with the appropriate severity level. It is an art by itself to make the right tradeoff between not logging too much information so that the logs indicating real problems are not rotated out too quickly, and at the same time also not to log too little so that based on the information present in the logs fault localization becomes impossible.
While the task of generating logging information can only be done by the application and components designers, the LOG provides the mechanisms that guarantees that such log records produced anywhere in the cluster are stored in a reliable and persistent way in the files associated with each centralized log stream.
The LOG has a few preconfigured log streams, but if it is desired to separate the logged information, application can configure and create their own additional log streams dynamically via the LOG API. Chapter 8 has more details on the LOG.
In some migration cases it could be rather challenging and costly to adapt 3PPs to use the LOG if they were not designed to use it, or if they do not support any portability interface to hook in different log implementations. Nevertheless efforts should be made at least to minimize the number of logging services used in the system.
15.3.4 Code Quality
Code quality depends on the quality assurance level a vendor is using in its development process. The SA Forum indirectly helps to achieve this by the facts that it has standardized a set of APIs, and that such standard APIs stimulate the growth of the ecosystem of components reusable even across company borders. This reuse results in improving quality since each time users reuse such a component they contribute to the quality by testing the component in their own deployment context.
While code quality is an important factor for both the vendors and the system owners, it cannot be associated with any specific service or services of the SA Forum architecture.
15.3.5 Integration Levels
Now that we defined them it is time to see how we can use the criteria of easy management and streamlined architecture to understand which services an application component needs to use to be qualified as integrated with the SA Forum middleware.
From our discussions we have seen that a streamlined architecture is an important prerequisite to ease system management. We have also seen that the AIS management services have the features that make system management easy, which makes them desirable integration points.
Additionally we identified for availability management CLM and AMF as crucial services therefore to streamline the architecture we need to integrate with them as well. This integration also indirectly eases software management using SMF, which collaborates with AMF during upgrade to minimize service disruption.
Accordingly we define the following integration levels for applications:
- Service Availability Forum (SAF)-Availability-integrated
For an application component to state that it is availability-integrated with the SA Forum middleware implies that its availability is managed by AMF. Note that according to the SA Forum architecture we do not need to require explicit integration with the CLM since the AMF itself is a user of CLM. Therefore applications managed by AMF do not need to use CLM directly.
- SAF-Manageability-integrated
For an application component to state that it is manageability-integrated with the SA Forum middleware implies that
- if the component requires any configuration data its configuration management uses the IMM;
- if the component generates any relevant notification it needs to do so via the NTF to facilitate fault management;
- for the purpose of software management it is upgradeable by the SMF; and
- optionally: for logging it uses the LOG.
Note that it is possible that a component uses only a subset of the listed management services. For example, it may use NTF and is upgradeable by SMF, but it is not configured via IMM, we consider such a component as partially-manageability-integrated.
- Well-SAF-integrated
To state about an application component that it is well-SAF-integrated with the SA Forum middleware implies that it is:
- SAF-Availability-integrated; and
- SAF-Manageability-integrated at the same time.
- Fully-SAF-integrated
For full integration we consider all AIS services therefore to state about an application component that it is fully-SAF-integrated with the SA Forum middleware implies that:
- it is well-SAF-integrated; and
- if the application component requires any functionality provided by some other SA Forum services—such as the AIS utility services—it uses those services.
- Using-SAF
Finally the statement that an application component uses the SA Forum middleware implies that:
- the component is not SAF-availability-integrated and is not SAF-manageability integrated (neither partially manageability integrated); but
- the component uses some of the SA Forum services that are not considered in availability and manageability domain. Examples of such services are the Checkpoint service, the Message service, and so on.
It is obvious that fully-integrated components and systems offer the highest benefit for streamlining the architecture and easing system management. Well-integrated components do offer similar benefits at least from the perspective of easing system management. Therefore for the purpose of migrating legacy HA applications we consider well-integration as the optimal goal to achieve. This is the ambition level we focus in the rest of this chapter.
Does this mean that the use of other services like the SA Forum utility services, which includes the Messaging, Checkpoint, Event services, is not needed? The answer is definitely no. Though such services are not directly contributing to the easy handling of the system, they do help in streamlining the architecture by avoiding duplication of the respective functionality.
15.4 How to Migrate
15.4.1 Availability Integration
There is a strategic choice that an application designer has to make when integrating some legacy software with the AMF. He or she has to decide whether to keep the legacy code intact or to modify it so that it interacts with AMF natively.
Here we give a short overview of the different possibilities and provide some general recommendation when some of these approaches are most appropriate.
One of the first questions to ask is whether the legacy software has the capability of being started without immediately providing its service. This means, for example, that a process can be started and it will not provide any service immediately but wait until it is instructed by an external entity to do so. In AMF terminology this is called pre-instantiable component. If a legacy software has the (hot-)standby capability that would typically indicate that it is capable of being started and remain idle until it needs to take either the active or the standby role for a specific task (service).
On the other hand if the legacy software starts to provide its service as soon as it is started, in AMF terminology it is called a non-pre-instantiable component. Components of the non-pre-instantiable category are never SA-aware.
The options in front of the application designer are to integrate the software natively with AMF, or to use one of the techniques offered by AMF for easy porting. These techniques include the wrapper process (WrapP) technique, the proxy-proxied technique and the non-SA-aware nonproxied technique. We describe these techniques further in subsequent sections.
15.4.1.1 Native Integration
The native integration approach is feasible for legacy software which is or could be turned into a component of the pre-instantiable category.
In this approach the legacy software code is adapted to directly interface with AMF, effectively transforming the non-SA-aware software to an SA-aware. While this approach seems to be intrusive at first glance, it is very common that only a minor part of legacy functionality needs to be adapted: Only those parts directly related to the control of the process life-cycle, the health monitoring, and the assignment of service responsibilities need to be considered. In most cases the core functional parts related to the service that the process provides, the traffic handling, and so on, do not need to be touched.
The biggest obstacle is that such modifications require access to and the knowledge of the source code, which is not the case with most 3PP software.
15.4.1.2 Wrapper Approach
The wrapper approach is a design pattern to make some 3PP functionality integrated with AMF so that, form the perspective of AMF, it behaves and it is treated as any other SA-aware component interacting directly with AMF. The essence of this approach is to make the 3PP, which natively does not use the AMF interfaces (thus by itself it is a non-SA-aware component) look like to AMF as if it was a normal SA-aware component.
The approach consists of developing a wrapper that encapsulates the legacy 3PP into an SA-aware component. The wrapper itself is typically a single process (though it can be several processes as well) which on one side interfaces directly with AMF and on the other it interacts with the legacy software. The task of the wrapper is to map the interactions with the AMF to the interface specific to the legacy software for the handling of its life-cycle, health monitoring, and workload assignments.
Mediating the life-cycle control and workload assignments is rather straightforward therefore here we focus on the health monitoring issues as error detection is key for availability management that the wrapper needs to enable.
Accordingly the wrapper may initiate one or more healthchecks, and evaluate the health of the 3PP process in a 3PP specific way within the context of these healthcheck invocations then report the result to AMF. The 3PP may already have some proprietary interface to check its health that the wrapper can use. Alternatively the WrapP can make its assessment by executing some application requests toward the 3PP component: If the 3PP is a web server, the WrapP could invoke HyperText Transmission Protocol (HTTP) requests for a test web page. If the 3PP is a database it can execute some database operation on some known content. Whenever the wrapper detects an error, it reports this error to AMF which then triggers a recovery procedure according to the recommendation provided by the WrapP in the error report or if no recommendation is given according to the configured recovery policy. It also applies any necessary escalation policy.
Alternatively or additionally to the healthcheck, the WrapP may register the processes of the 3PP with AMF for passive monitoring. In this case the AMF implementation will utilize an appropriate mechanism of the underlying operating system to detect if any of the monitored processes crashes.
It is important to note that for the AMF the legacy software integrated this way will look like any other SA-aware component. AMF can not see the difference between the legacy software that interacts with AMF through a WrapP and the software that was designed to interact with AMF natively.
Figure 15.1 illustrates at a high level an example of using the wrapper approach. It shows a subset of the AMF entities in the AMF information model (for readability we omitted the application entity). In the figure the shapes labeled 3PP represent instances of the legacy software which are hooked to the AMF via the wrapper processes—the shapes labeled WrapP.
Figure 15.1 Integration through a wrapper process.
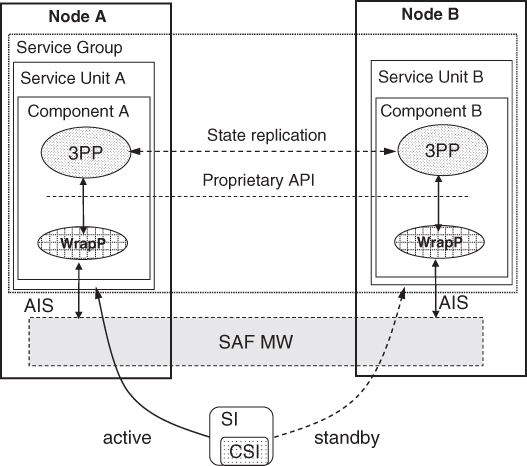
The WrapP and 3PP processes are encapsulated in a single AMF component. To achieve this there is not a single-line of code modified in the 3PP process. An AMF component containing a WrapP and a 3PP process is contained in each service unit. There are service units allocated to Nodes A and B. These service units are grouped into a service group which is defined to run in 2N redundancy to protect one service instance representing workload performed by the 3PP process.
Accordingly, at runtime AMF will assign one service unit active for the protected this service instance while the second service unit will be standby for the same service instance. Figure 15.1 illustrates also that the 3PP may use some internal mechanism for the state replication needed to achieve the hot-standby capability.
For more detailed descriptions on the AMF concepts like the AMF information model, and its associated entities like components, service units, service groups, service instances, healthcheck, and passive monitoring we refer the reader to Chapter 6.
15.4.1.3 Proxy-Proxied Approach
In the wrapper approach, the legacy software processes are wrapped by a new process so that the legacy software behaves and is represented in AMF information model as a standard SA-aware component. From implementation perspective the proxy-proxied approach is similar in that sense that there is a dedicated piece of software, which is SA-aware and which mediates the interaction between the AMF and legacy software.
The main difference is that in the proxy-proxied approach the mediation function and the legacy software are decoupled into separate components of the AMF information model. AMF is aware of the mediation software as the proxy component and the legacy software as the proxied component, as well as the workload (service instance and its component service instance (CSI)) representing mediation tasks of the proxy components; and workload served by legacy software, the proxied components.
This leads to an important characteristic of this approach. Namely that the proxy component and the proxied component are different entities with separate life-cycles. If the active proxy component fails AMF can request another component typically acting as the standby to the failed proxy component to resume the mediation task. This new proxy component then assumes the mediation task of the failed component and registers the proxied component again without affecting the service provided by the proxied component. Thus, the failure of the proxy component does not indicate a failure of the proxied components. Similarly, the AMF does not consider the failure of the proxied component to be a failure of the proxy component.
As in case of the wrapper approach the proxy component is the primary source of information for AMF for error detection on the proxied components. It may use similar techniques as discussed for the wrapper.
Since the proxy and the proxied components are different entities, the redundancy model of the proxy components can be different from that of the proxied components.
Note that the proxied component can be pre-instantiable or non-pre-instantiable. In case of non-pre-instantiable component the proxy component will start the proxied component only when it gets the active CSI assignment for this proxied component.
For more information on proxy and proxied components and the related concepts please see Chapter 6.
In general, the proxy-proxied solution is appropriate when one of the following is true:
- The redundancy model of the proxied component (the legacy software or hardware) needs to be different from the redundancy model of the proxy component. The proxy component usually requires a very simple redundancy model such as 2N, whereas the legacy component may need a more complex redundancy model such as N+M or N-way active.
- The failure semantics and the fault zone of the proxied component are different from the ones for the proxy component. For example, the proxied component may be running outside of the cluster, whereas the proxy component is always located on a node within the cluster.
Figure 15.2 illustrates an example where the processes mediating the requests (Proxy) from the AMF toward the legacy software processes (3PP) is allocated on two nodes (Node 1 and 2); and the two service units containing the proxy components (P1 and P2 each encapsulating a Proxy process) are allocated to a service group configured with the 2N redundancy model. This means that at runtime one of the proxy components (e.g., P2) will receive the active assignment for Mediation workload; while the other proxy component (P1) will have the standby assignment for the same Mediation workload.
Figure 15.2 Example of the proxy-proxied integration approach.
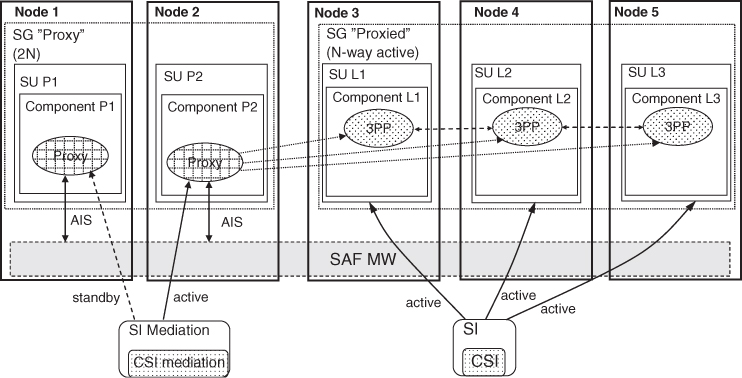
In this specific example the legacy software is modeled with the N-way-active redundancy model and it is configured in such a way that the number of preferred assignments for the service instance is equal to number of service units in the service groups (i.e., three).
From the AMF configuration the AMF knows that the service instance (mediation) is specific for proxying the components L1, L2, and L3. From the moment the proxy component P2 receives the active assignment for the Mediation service any AMF interaction related to any of these components will go via component P2. Examples of such interactions are the requests for instantiating the proxied components (if they are pre-instantiable components), the assignment of the CSI, as well as any healthcheck.
15.4.1.4 Nonproxied-Non-SA-Aware Approach
In this approach the role of the AMF is limited to the management of the component life-cycle (CLC). AMF instantiates the component when it needs to provide its service and AMF terminates the component when it must stop providing the service. The interaction with the component is only via Component Life-Cycle Command Line Interface (CLC-CLI); more specifically via the INSTANTIATE, TERMINATE, and CLEANUP commands.
This is the approach that requires the least integration efforts since for a basic integration not a single line of code is needed. The only things needed are the CLC-CLI scripts for instantiating, terminating, and cleaning up the component.
To be able to assess the health of the component it is common to combine this approach with the external active monitoring concept offered by AMF. The external active monitoring is supported with two CLC-CLI commands, namely the AM_START, which starts a monitoring process for the associated component and the AM_STOP, which stops the monitoring process for the component.
The monitor process may assess the health of the component by submitting some service requests to the component and checking that the service is provided in a timely fashion. The monitor process uses the AMF interface to report any error it detects. It can build on the AMF healthcheck facility to trigger the monitoring activity toward the legacy software but also to monitor its own health.
Additionally if the monitoring process (or another process started at the component instantiation) can find out the process identifier(s) associated with the legacy software it can start the AMF passive monitoring for the faster detection of process crashes or unexpected process exits.
15.4.1.5 Recommendations: Which Approach to Use
In the previous sections we went through several integration approaches and in this section we try to give some suggestions and recommendations on which approach is most appropriate for which case.
We start with the classification of legacy software that we use to provide a recommendation on the approach, which in our view is most suitable for the class.
Figure 15.3 Decision points for the classification of legacy software.
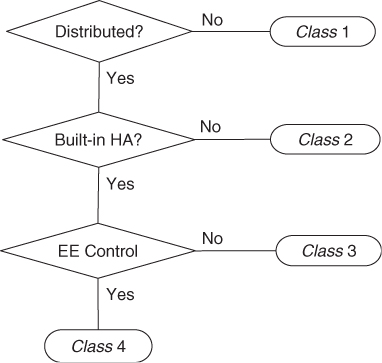
Figure 15.3 presents the following decision points:
- Distributed: Is the legacy software developed to run as distributed application or it runs within single node? In the later case the software belongs to Class 1, otherwise we continue with the next question.
- Built-in HA: Does the distributed legacy software have a built-in HA functionality? For example, does it maintain a group membership status of the different parts of its own functionality running on different nodes? Distributed software with no HA functionality forms Class 2.
- Execution environment (EE) Control: Does the distributed legacy software with built-in HA functionality also control the life-cycle of the encapsulating EE? Here by the term execution environment we refer to the entity defined in the Platform Management service discussed in Chapter 5. More specifically, what we are interested in is if as part of the error escalation and recovery procedures the software would restart its encapsulating EE such as the instance of the operating system.
Class 1: Nondistributed Legacy Software
Examples of this category are non-distributed software like an Simple Network Management Protocol (SNMP) daemon, a domain name server (DNS), a nondistributed Web server, an network time protocol (NTP) server. This class of software by itself is not capable of providing high-available services.
This type of software usually starts to provide its service as soon as it is started so from AMF's perspective it maps to a non-pre-instantiable component. When integrating this class of software with AMF, the nonproxied-non-SA-aware approach is used most often and that is what we recommend as well.
When integrating with AMF this class of software can be configured in a service group with the no-redundancy redundancy model, which includes one or more additional service units as spares. It can also be used in an N-way-active redundancy model when multiple service units share the workload associated with the same service.
When an instance of such a component needs to be assigned the active role for its service (its CSI), AMF instantiates it and the component starts to provide the service immediately. Other component instances with no active assignment stay uninstantiated spares. They will be started only when they need to provide service. In particular, in case of a switchover or a failover AMF will respectively terminate or clean up the component instance that previously provided service first then will instantiate one of the spare components.
Note that such a component can be combined with other components in other redundancy models as well. In this case AMF assigns the standby state only to those components that are capable of taking such an assignment. AMF will not attempt to assign the standby state to the non-pre-instantiable component running the software of this class.
Alternatively one may use the wrapper approach to create an SA-aware component that can take only active assignments. In this case when AMF instantiates the component only the WrapP is instantiated and it becomes responsible to handle the life-cycle of the processes of the legacy software. When AMF assigns a CSI in the active state the wrapper instantiates the processes and tears them down when the assignment is removed.
Class 2: Distributed Software with No Built-in HA
This category represents legacy software, which is designed to run in a distributed environment and to use of the availability services through a portability API. Some of these applications may also abstract the workload management via the portability API, though it is more common that they do not expose this.
If the components of an application of this class can be pre-instantiated, that is, it is capable of remaining idle when instantiated then the wrapper approach is recommended. This would be the case when the workload management is exposed.
If the application components cannot be instantiated without providing their services, that is, they map to non-pre-instantiable components then the nonproxied-non-SA-aware approach is usually the simplest choice.
Class 3: Distributed Software with Built-in HA Functionality
The legacy software of this class implements some basic availability functions most often to maintain the state of the group membership of its functional entities distributed across the cluster nodes. This is a rather common case for ISVs who develop distributed HA components. They try to increase the portability of their product across different environments and as a consequence embed some clustering support. They may provide some availability management functions as well for monitoring and restarting some of their entities. They typically still require some external middleware functions to start the base processes.
Examples of this class are some of the distributed protocol stacks, the distributed databases, some of the application servers like the Java 2 Enterprise Environment products.
If the legacy software has a centralized software entity, which manages rest of the legacy application then the proxy-proxied approach is preferred as it minimizes the integration efforts. Otherwise again we recommend the wrapper approach.
The nonproxied-non-SA-aware approach is also possible to use, but in our experience it is worthwhile to investment into a tighter integration in case of such complex applications. This relatively small initial integration cost using the wrapper or the proxy-proxied approaches pays off over time as they result in more flexible solution than the nonproxied-non-SA-aware approach. Particularly the proxy-proxied approach is easily adaptable for both pre-instantiable and non-pre-instantiable categories of components.
Class 4: Distributed Software with EE Control
The legacy software of this class is similar to Class 3 but has the major distinction that the built-in HA capabilities control more then their own functionality.
This is not common for 3PP components developed by ISVs, but it is relatively common for proprietary legacy applications. When a complete vertical solution was developed and there was no clear cut between the application and the middleware functions.
For this class of legacy software systems there is no simple approach to migrate them to an SA Forum based system or, for that matter, to any other middleware. The most feasible approach is to identify the parts of such a legacy software system that belong to Class 2 or at least Class 3; and then integrate them according those categories.
15.4.1.6 Integration Examples
Shared-Storage Database Management System
This is an example of the typical shared-storage database architecture. Such a database management system (DBMS) consists of a Database Connector implemented as a shared library delivering the DBMS API to applications, which for the application designers also abstracts the complexity of the rest of the DBMS architecture.
The Database Connector communicates with the core of the DBMS system. The DBMS server is typically distributed over a number of nodes for availability and capacity reasons. Each instance of the DBMS server is connected to a shared-storage system via the storage area network and has access to the complete persistently stored DBMS content.
In this architecture each instance of the DBMS server can serve application requests from the complete DBMS content. For better load balancing the Database Connector distributes the application requests among the instances of the DBMS servers.
Among the redundancy models defined by the AMF this can be best represented by the N-way-active redundancy model. In this redundancy model the service units of the service group protecting a given service instance are all assigned active for this service instance.
In this DBMS solution if any of the service units is locked or a node becomes unavailable, the remaining DBMS server instances can still provide the full service as it is the case with the N-way-active redundancy model. Thus, we map each DBMS server instance to a service unit of a service group configured for the N-way-active redundancy. In the AMF information model we also configure the service instance served by the DBMS servers in such way its preferred number of active assignments is equal to the number of service units in the service group of the DBMS server.
Application software components of this type usually have a very light built-in support for availability management. It mainly serves the needs of the Database Connector to detect the availability the DBMS server instances so that it can distribute among them the application requests. Therefore according to our classification method we classify this software as Class 2, where the portability API consists of the interface to manage the life-cycle of the DBMS server instances and the interface to assess the health of a DBMS server instance.
For legacy software of Class 2 we recommended the wrapper approach, which is shown in the following Figure 15.4.
Figure 15.4 DBMS integration using the wrapper approach.
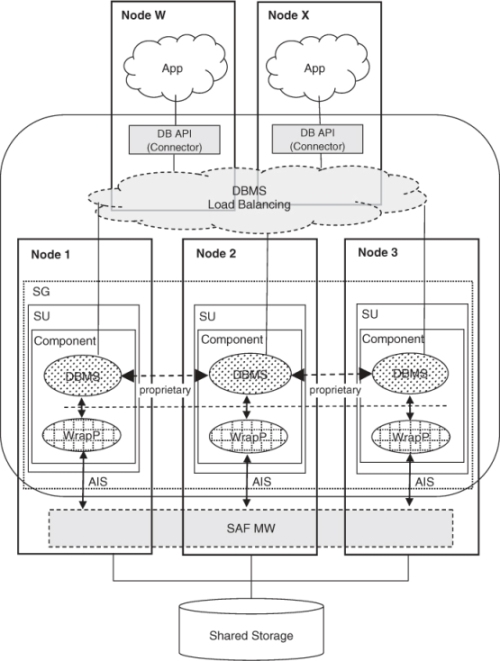
A WrapP encapsulates each DBMS server instance into an SA-aware component. In this example we assume that the legacy software is pre-instantiable (able to remain idle); thus it can be instantiated as part of wrapper instantiation.
If it could not stay idle and therefore it was non-pre-instantiable, then the WrapP would instantiate it as part of the procedure of accepting the active assignment for CSI representing DBMS workload. Note that in this later case the nonproxied-non-SA-aware approach is also a possibility.
As previously stated, the appropriate redundancy model is the N-way-active for the service group containing the DBMS server instance.
The Database Connectors are shared libraries and they will execute in the context of the application process using the DBMS. These application processes will be part of components grouped into service units and service groups with redundancy models suiting the application's needs.
Shared-Nothing DBMS
This is an example of the shared-nothing database architecture where neither the disk nor the memory is shared among the cluster nodes that host the DBMS.
The content of the DBMS is replicated in the memory of the nodes hosting the DBMS and it is periodically backed-up on a persistent file system. Such an in-memory DBMS system also has some disk log where each transaction performed since the last complete backup of the database is persisted. This way even in the case of a total outage such as a cluster restart these systems can operate without any data loss by restoring the data from the last backed up state, to which they apply all the transaction persisted from the log to recreate the last state before the outage.
Again the DBMS consists of a Database Connector implemented as a shared library, which delivers the DBMS API to application and abstracts the complexity of the DBMS architecture. It communicates with DBMS server, which is distributed on a set of nodes to improve the availability, processing, and memory capacity.
In this case the data is stored in-memory: it is partitioned to optimize the memory consumption and it is also replicated for availability. Each DBMS server instance has
- its own partition of data on which it can work without the risk of contention; and
- one or more partition of data replicated from other DBMS server instances for HA purposes.
Figure 15.5 illustrates an example of the partitioning and replication of the database content. In this example the data has been divided into four partitions, that is, P1, P2, P3, and P4. The DBMS system has been configured to create one replica for each database partition (P1', P2', P3', and P4'). In our example the DBMS system groups the partitions to create partition groups in such a way that the DBMS server instances, which are members of the same partition group, will have same content. For example, Partition Group A in Figure 15.5 has the content (P1 + P2) of the database. The partition group is also a replication domain, that is, an update of the content in one DBMS server will require the update of other DBMS servers within same partition group.
Figure 15.5 Data partitioning and replication of a share-nothing DBMS.
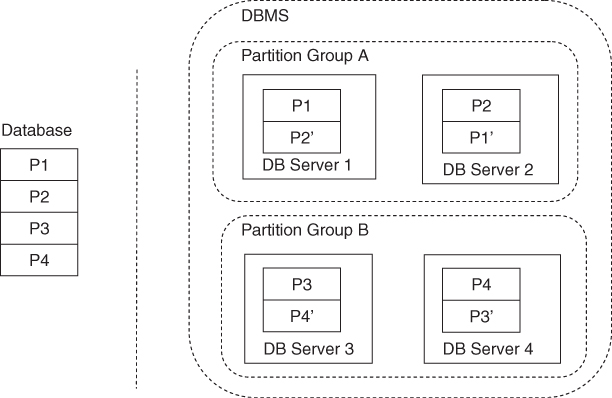
Note that there is a specific configuration case where the number of replicas is the same as number of DBMS servers resulting in a single partition group, and in the total replication of all the data. This use case is feasible when the amount of data is relatively small, and when the data is seldom written but often read such as in the case of configurations. In this case each DBMS server has a full copy of database. After the failure of any DBMS server the remaining ones will be able to serve the traffic since they have a full copy of database.
From the perspective of its integration with AMF this specific case becomes the same as our previous example with the shared-disk solution discussed in section ‘Shared-Storage Database Management System’. Therefore we will not consider it any further in this section; the conclusions for the shared-disk example are relevant for this specific case as well.
In this example we will assume that there exists a specific part of the DBMS software, the DBMS management daemon which controls the DBMS servers. This is a valid assumption as one of the most popular clustered in-memory databases use this approach.
Since the communication controlling the DBMS servers goes via the DBMS management daemon, we can apply the wrapper approach to the DBMS management daemons to make this component SA-aware and interact directly with AMF.
Subsequently we also apply the proxy-proxied approach and use the now SA-aware DBMS management daemons as proxies for the DBMS servers, which now become the proxied components.
This integration is relatively straightforward and fits naturally the legacy DBMS architecture.
The AMF modeling aspect is less straightforward and depends on the amount of built-in HA functionality.
Let first assume that there is no built-in HA capability. Such a DBMS maps to Class 2. All the HA support is abstracted via the portability API including the control of the number of partitions, the definitions of partition groups, the decision about the owners of the primary partitions and their replicas, and so on.
For the integration it is desirable to utilize the capabilities of the AMF to reproduce the DBMS behavior described previously. The following example shows the modeling approach that can achieve this behavior.
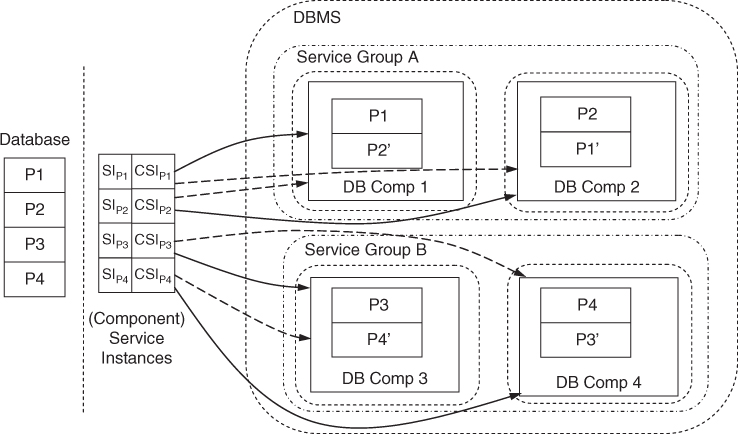
Each data partition is modeled as a specific service instance, and each partition group as a service group. That is, for our example we have four service instances and two service groups. Two of the service instances P1 and P2 are protected by the service group mapped to Protection Group A and the other two P3 and P4 are protected by the service group mapped to the Protection Group B.
Figure 15.6 illustrates AMF instance model for this specific case.
Figure 15.6 The AMF entities reflecting the data partitioning and replication example.
Now let us look at our example assuming that the legacy DBMS is of Class 3.
This means that it includes some built-in HA capabilities, for example, that based on the number of replicas configured the DBMS internally makes the decision about the number of partition groups and where within a partition group the primary and the secondary replicas of a given partition will reside.
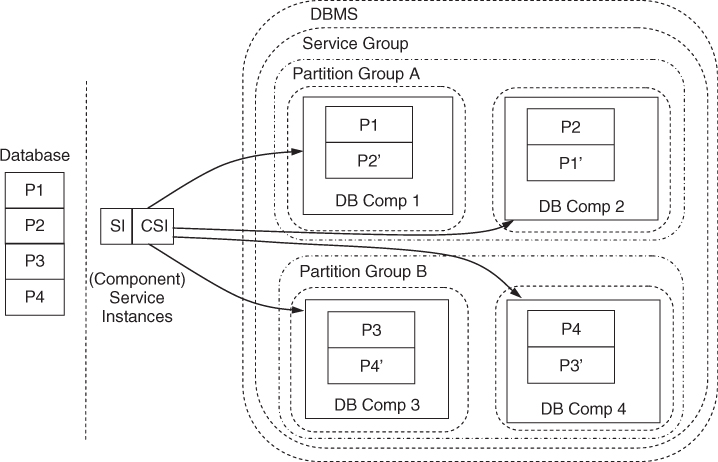
This means that looking from outside the DBMS behaves like a ‘black box.’ A certain set of DBMS servers will provide the service and the Database connector will ensure that each request is forwarded to the appropriate instance of the DBMS server. Any internal decision of the DBMS to reshuffle the partitions is not visible from outside the DBMS system.
As shown in Figure 15.7, this solution can be modeled with the N-way-active redundancy model since to the outside user and therefore to the AMF as well it looks like that all the DBMS server instances are providing same service. The difference compared to true N-way-active redundancy model is that if all DBMS servers of the same partition group suddenly go out-of-service—which of course should be an extremely rare occasion—then the DBMS cannot function anymore since the full DBMS content is not reachable anymore. This case needs to be escalated, for example, by the proxy component. It becomes aware of the situation using the proprietary interface of DBMS and reports to the AMF the error with the appropriate recovery recommendation.
Figure 15.7 Class 3 share-nothing DBMS integration example.
Although this integration example results in a light integration with AMF (due to the built-in HA capabilities of the DBMS) there are still benefits of performing it, and they are related to software management. It allows a smoother execution of software upgrades using the SMF since SMF interacts with AMF during upgrade to handle workload switchovers and to impose the least possible service impact.
15.4.2 Manageability Integration
In this section we present the approaches that can be used to integrate the system management aspects of legacy software with the SA Forum middleware. According to our definition of the manageability-integration we need to use for configuration management the IMM, for fault management the NTF, and for software management the SMF.
15.4.2.1 Configuration Management Using IMM
The process of integration of legacy software with IMM consists of the tasks of identifying the dynamic configuration space, designing the application's information model and encoding it, and implementing the Object Implementer (OI) interface of IMM, that is, the code which handles the validation of configuration changes as well as propagating them toward the legacy software.
Dynamic Configuration Space
In this step we need to identify those properties within the configuration of the legacy application that need to be configurable at runtime. These belong to the dynamic configuration space and need to be exposed as writable properties in IMM.
Other properties of the legacy application that are configured only at the installation time do not belong to the dynamic configuration space; they do not need to be exposed via IMM. (If desirable these can be represented as read-only properties.)
Identifying the dynamic configuration space is usually challenging for new (i.e., greenfield) applications, but it is quite trivial for legacy application since they already provide some configuration properties through some configuration framework. Whatever schema the legacy software uses to describe its configuration model, it normally contains sufficient information to understand the dynamic configuration space of the application and to derive model compliant to the SA Forum information model.
Designing the Information Model
After identifying the dynamic configuration space the next step is to design an information model, which reflects this configuration space. For this we need to identify the different relationships between the different configuration properties of the system we selected in the previous step.
In IMM terms this means that we need to map the properties as configuration attributes, group them into classes, and define relationship between those classes to create an information model. As discussed in Chapters 4 and 8, in the IMM meta-model there are no specific modeling concepts to specify the relationship among classes, except parent-child relatinonship, and this task is left to the OIs. They need to enforce all the needed constraints.
To document these relations among the different model elements it is advisable to use a high-level modeling language capable of describing the application's information model and the related constraints. The SA Forum itself uses UML (Unified Modeling Language) to describe the information model of AMF and other services that can be used as examples.
Note that there are also tools that support automatic code generation from UML and some other popular high-level modeling languages. So using these languages to describe the information model and its constraints allow the automatic generation of a skeleton code for the OI interface that would enforce the constraints described in the modeling language.
Typically the migration efforts will depend on the modeling language used to represent the information model of the legacy software. If the meta-model of this modeling language is in line with the main principles of the SA Forum information model and the associated IMM meta-model, then it may even be possible to use the information model of the legacy software directly or with few modifications by defining the transformation rules. This allows the automatic transformation of the instance models used with the legacy software to their IMM representations. This significantly simplifies the migration to IMM. The main principles of the SA Forum information model that need to be aligned to simplify the transformation are the tree-based structure, where each object in the model has no more then single parent, and objects are accessed using single key.
The classes and objects of the information model can be created in IMM programmatically using the IMM Object Management API or by providing a initial configuration according to the IMM XML (eXtensible Markup Language) schema as defined in [109].
For more information on the SA Forum information model and IMM see Chapters 4 and 8 respectively.
OI Interface Implementation
Finally, the legacy application needs to interact with IMM to receive its configuration changes. For this the application code that implements the related IMM API needs to be written. More specifically IMM OI API needs to be implementation to register the legacy application with IMM as the implementer of the classes and/or objects of the information model defined for the legacy application in section ‘Designing the Information Model’.
This piece of code receives the configuration changes proposed on any of these objects, validates the changes, and subsequently it propagates them to the legacy application itself for deployment when IMM indicates that the validation has passed by all involved OIs.
The amount of the work depends on the complexity of the information model; more specifically on the complexity of the constraints that need to be enforced. As indicated in the previous section ‘Designing the Information Model’ it may be possible to automate this process to some degree by generating the OI skeleton code based the constraints defined in the information model.
15.4.2.2 Fault Management Using NTF
The process of integrating some legacy software with NTF consists of the steps: identifying the events that are relevant to fault management and among them those that need to be sent to the system administrator; the classification of these events into the notification types as defined by NTF; and adapting the application code to the NTF API, more specifically, to the NTF producer API used to send notifications presented in Chapter 8.
Identify Notifications
The task is first to identify the events that are relevant to fault management and among them those that need to be exposed to the system administration and then to identify to which NTF notification type each of the events should be mapped. NTF defines six notification types: alarms, security alarms, state change notifications, object create/delete notifications, attribute change notifications, and miscellaneous notifications.
A legacy application might already use some other fault management mechanism for which the events have already been identified and classified into different categories. Those categories may not match exactly the notification types defined by NTF nevertheless the mapping between the categories used by the legacy software and the NTF notification types are usually straightforward. The reasons for this is that legacy HA applications are often compliant to the ITU X.73X recommendations (International Telecommunication Union) [85], which lies at the basis of the NTF specification as well.
Sending Notifications Using the NTF API
Compared to the previously discussed services, the migration to the NTF requires much less efforts and it is usually straightforward. The easiest approach is to map the API used by the legacy software to the producer API of the NTF. This approach then minimizes the impact on the application code.
15.4.2.3 Software Management Using SMF
The process of integrating legacy software with SMF consists of the following steps: describing the software in an entity types file (ETF), packaging of the software, and creating an upgrade campaign specification (UCS). For the actually deployment only the last two are needed, but ETF helps to automate these and other integration tasks.
The biggest value of using the SMF comes when the upgrade would impact entities controlled by AMF. In this case, SMF can indeed reduce the impact on the availability of their services during upgrades. However SMF can orchestrate upgrades regardless whether the software is under the control of AMF or not.
For more information on the SMF refer to Chapter 9 and [49].
Creating an Entity Types File
As described in Chapter 9, in the ETF the software vendor describes the accompanying software bundle. The software bundle description provides the information on how to install and uninstall the software in question, the CLI commands provided by the vendor for this purpose and if applicable the scope of impact they may have (e.g., if the node is rebooted). This information serves as input to the upgrade campaign designer and it may need adjustments for the particular deployment.
Additionally, for AMF integrated software, the vendor also specifies the AMF prototypes from which the AMF types and their entities can be derived for the AMF configuration. This is an input for the availability integration, for the AMF model design mentioned in Section 15.4.1.
Note that ETFs may or may not directly be consumed by an SMF implementation as the information is related to the AMF configuration and the software repository, which is not standardized by the first version of the SMF specification.
Software Packaging
The SMF has been specified as a framework and it does not define any particular packaging mechanism; it leaves this aspect to the SMF implementation. As we have seen in case of the AMF CLC-CLIs, SMF also interacts with different software bundles—often referred as software packages—via CLI commands specified in the information model. As a result SMF is flexible enough to install and uninstall (i.e., upgrade) almost any type of software. Typically an SMF implementation supports the packaging technologies established by the operating systems (like rpm, deb, jar, and so on) it is able to execute on.
Each software bundle in the software repository is represented in IMM as an object in the SMF information model. The attributes of this object contain the CLI commands as they apply to the actual deployment. They are derived from the CLI commands provided by the vendor in the ETF. The software bundle object is created with this information usually when the software bundle is imported to the system's software repository.
Upgrade Campaign Design
The software is deployed in a SA Forum compliant system through an upgrade campaign executed by SMF. Hence in this step a campaign designer need to create an UCS compliant to the XML schema defined by SMF specification to instruct SMF of the appropriate procedures.
The UCS is based on the desired configuration of the legacy software created using the description contained in its ETF and the current configuration of the system. It is desirable that the campaign designer uses a tool to generate the UCS as upgrades are probably the riskiest operations in HA systems. If no tool is available, we prefer to develop that rather than use manual design. It is too error prone. Using a tool for UCS generation simplifies the integration of legacy software with SMF as well as guarantees the creation of reliable upgrade campaigns.
15.5 Open Issues
From the perspective of manageability the most important open issue is the lack of a standard system-wide trace service, which could provide a common tracing mechanism across the complete system. The SA Forum has not yet specified such a service even though it has been on the roadmap for some time. When it comes to the integration of system management, this has been identified as a gap toward the specifications.
Until such a service specification becomes available the solution is left to the middleware implementers to offer a system-wide tracing solution and if that is also not available then the system integrators need to find their own solution, which might be challenging.
15.6 Conclusion
In this chapter we described the main drivers for migrating legacy application to the SA Forum middleware. We listed the benefits of such a migration and defined a set of integration levels that can be used as reference when discussing software with respect to the SA Forum middleware. Finally we made some recommendations to help application designers during the migration process.
Our strong belief is that the SA Forum architecture offers a number of mechanisms that can ease the migration path of legacy applications and systems to the SA Forum middleware. These range between techniques explicitly supported by the specific services such as the techniques enabled by the AMF that we discussed in Section 15.4.1 and the fact that the SA Forum architecture is very tolerant in supporting a stepwise migration. By that we mean that the architecture does not couple the services for the service users. For example one does not need to create an AMF component to use the IMM or any other AIS services; nor is it required the use of IMM API to configure an AMF component. Basically, an application or component may start with using a single AIS service and migrate its other functionalities gradually. Of course, the full benefit from the use of the middleware is reached once the application is well-integrated with SA Forum services.
When it comes to migrating to a standardized, open middleware combined with the business aspects, the SA Forum architecture is the system of choice for applications that do not have the luxury to compromise their SA.