
12.5 Lazy Evaluation
12.5.1 Introduction
At its core, lazy evaluation is a parameter-passing strategy in which an operand is evaluated only when its value is needed. This simple idea has compelling consequences. An obvious advantage of this approach is that if the value of an operand is never needed in the body of a function, then the time required to evaluate it is saved. Most languages, including Python and Java, implement short-circuit evaluation, which is an instance of lazy evaluation restricted to boolean operators. For instance, in the expression false && (true || false), there is no need to evaluate the subexpression on the right-hand side of the logical “and” (&&) operator.
In what follows, we first describe the mechanics of the lazy evaluation parameter-passing mechanism and briefly consider how to implement it. We then discuss the compelling implications it has for programming.
12.5.2 β-Reduction
Lazy evaluation supports the simplest possible form of reasoning about a program:
Replace every function call with its body.
Replace every reference to a parameter in the body of a function with the corresponding argument.
Formally, this evaluation strategy in λ-calculus is called β-reduction (or the copy rule). More practically, we can say lazy evaluation involves simple string substitution (e.g., substitution of a function name for the function body, and substitution of parameters for arguments); for this reason, the lazy evaluation parameter-passing mechanism is sometimes generally referred to as pass-by-name.
We use Scheme to demonstrate β-reduction. Consider the following simple squaring function: (define square (lambda (x) (* x x))). Let us temporarily forget that this is a Scheme function that can be evaluated. Instead, we will simply think of this expression as associating the string (lambda (x) (* x x)) with the mnemonic square. Now, consider the following expression: (square 2). We will temporarily suspend the association of this expression with an “invocation” of square and simply think of it as a string. Now, let us apply the two substitutions. Step 1 involves replacing the mnemonic (i.e., identifier) square with the string associated with it (i.e., the body of the function); step 2 involves replacing each x in the replacement string (from step 1) with 2 (i.e., replacing each reference to a parameter in the body of the function with the corresponding argument):
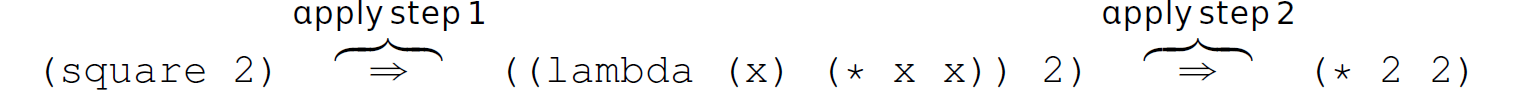
Expressing the steps of β-reduction in λ-calculus, if square “ (λ x . x * x), then
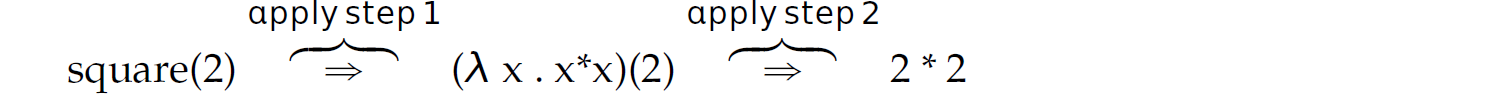
Thinking of these steps as a parameter-passing mechanism (i.e., pass-by-name) may seem foreign, especially since most readers may be most familiar with pass-by-value semantics and internally conceptualize run-time stacks visually (e.g., Figures 12.2–12.8). However, when viewed through a purely mathematical lens, this “parameter-passing mechanism” is quite natural. For instance, if we told someone without a background in computing that x “ (3 ⋄ 2), and then inquired as to the representation of x ⋄ x, that person would likely intuitively respond with (3 ⋄ 2) ⋄ (3 ⋄ 2). Thus, if x “ (3 * 2), the representation of x * x is, similarly, (3 * 2) * (3 * 2), not 6 * 6. Again, this interpretation is purely mathematical and independent of any implementation approaches or constraints. Now let us consider another “invocation” of square: (square (* 3 2)). Using β-reduction:
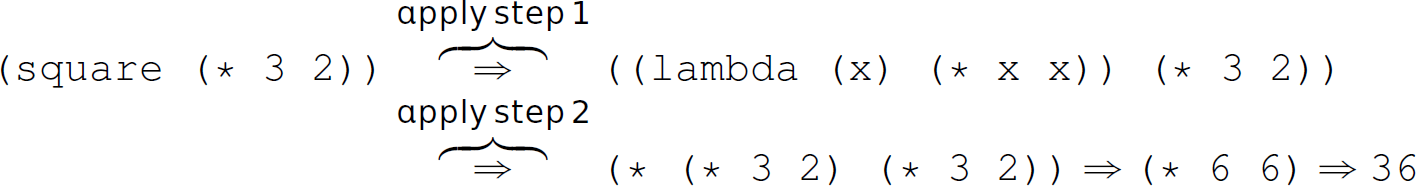
We can compare this evaluation of the function with the typical programming language semantics for this invocation:
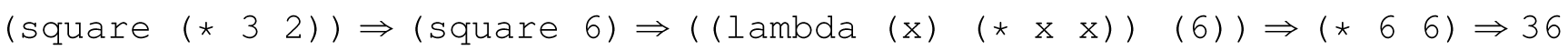
The following Scheme code presents another comparison of these two approaches:

The former approach is called lazy evaluation or normal-order evaluation: It evaluates the arguments to a function if they are needed during the evaluation of the body of the function. Thus, lazy evaluation is sometimes generally referred to as pass-byneed. The latter approach is called eager evaluation or applicative-order evaluation: It evaluates the arguments to a function prior to evaluating the body of the function.
Intuitively, it would seem that the use of lazy evaluation (of arguments) is intended for purposes of efficiency. Specifically, if the argument is not needed in the body of the function, the time that would have been spent on evaluating it is saved. However, upon closer examination, in a (perceived) attempt to be efficient, the evaluation of the expression (square (* 3 2)) requires double the work— the expression (* 3 2) passed as an argument is evaluated twice! (We discuss the relationship between lazy evaluation and space complexity in Section 13.7.4).
When considering the savings in time resulting from not evaluating an unused argument, one might question why a programmer would define a function that accepts an argument it does not use. In other words, it seems as if lazy evaluation is a safeguard against poorly defined functions. However, when we think about boolean operators as functions, and operands to boolean operators as arguments to a function, then suddenly it makes sense not to use eager evaluation: false && (true || false). Similarly, when thinking of an if conditional structure as a ternary boolean function and thinking of the conditional expression, true branch, and false branch as arguments to this function, using eager evaluation is unreasonable:

Thus, in many languages using pass-by-value semantics, including Camille, the if conditional structure is implemented as a syntactic form as opposed to a user-defined function; for example, we implement conditionals in Camille in evaluate_expr and not as a user-defined function. Since arguments to functions are evaluated eagerly in these languages, the if structure must be implemented as a syntactic form. This is also why programmers cannot extend (or modify) control structures (e.g. if, while, or for) in such languages using standard mechanisms (e.g., a user-defined function) within the language itself.
The terms on each of the main rows of Table 12.3 are generally used interchangeably to refer to evaluation strategies for function arguments. However, sometimes the term used depends on the scope to which it is applied: a specific language in its entirety (e.g., “Haskell is a lazy language”), a particular function invocation (e.g., “evaluate f(x,3*2) using normal-order evaluation”), or a specific argument (e.g., “x is a non-strict argument”). Also, do not be misled by the word normal. Applicative-order evaluation most likely seems “normal” to readers familiar with programming in languages like Python and Java. However, as mentioned previously, the β-reduction approach is more intuitive, natural, or “normal” to someone without a background in computing.
Table 12.3 Terms Used to Refer to Evaluation Strategies for Function Arguments in Three Progressive Contexts
Language Level Invocation Level Argument Level |
eager evaluation = applicative-order evaluation = strict |
12.5.3 C Macros to Demonstrate Pass-by-Name: β-Reduction Examples
Let us apply β-reduction to multiple programs and make some notable observations on the results. The expansion of macros defined in C/C++ using #define by the C preprocessor involves the string substitution in β-reduction. Thus, (the expansion of) C macros can be used to demonstrate the β-reduction involved in functions whose arguments are evaluated lazily.1 We begin with a brief introduction to C macros. Consider the following C program:
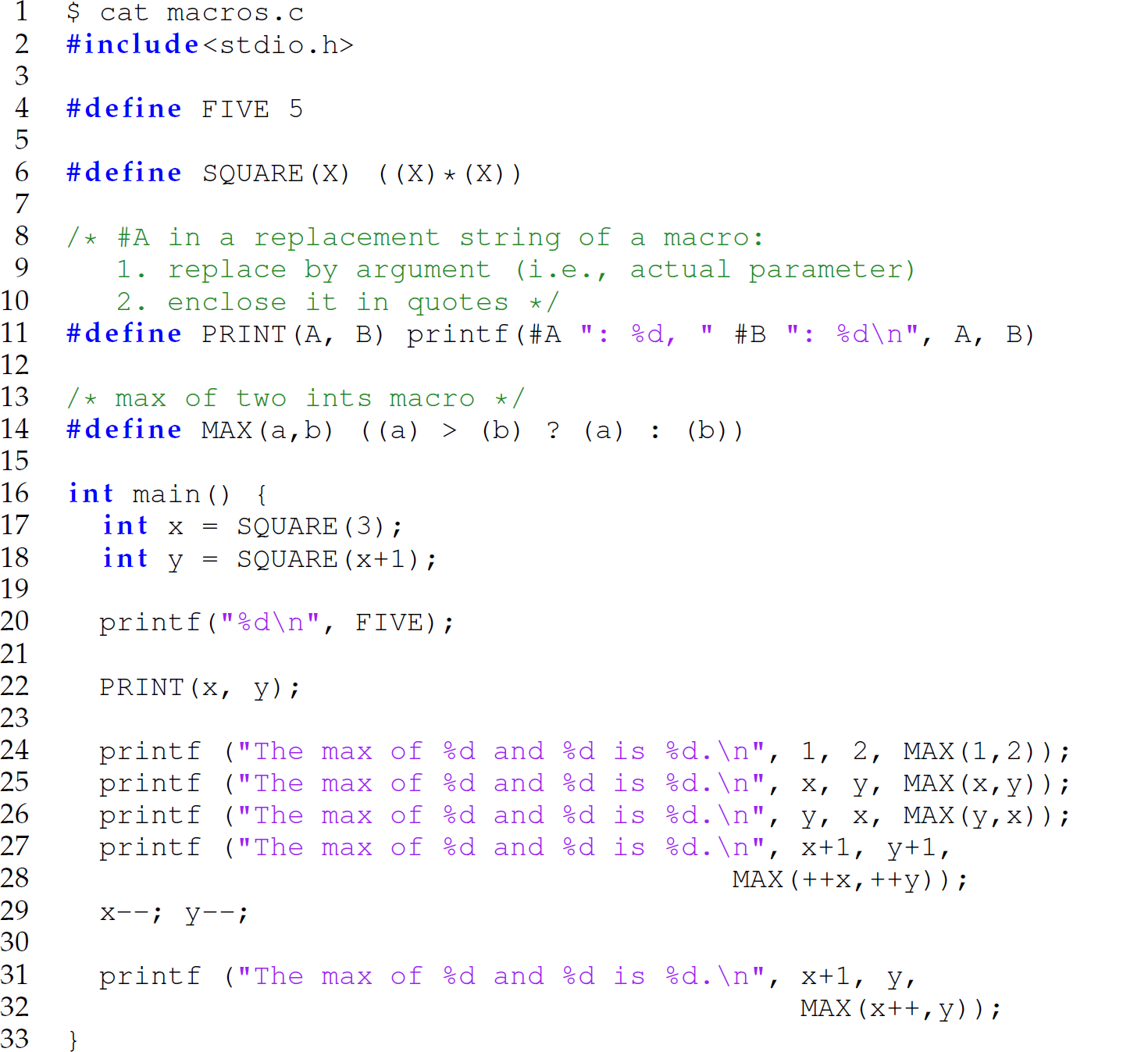
The following code is the result of the expansion of the four macros on lines 4, 6, 11, and 14:
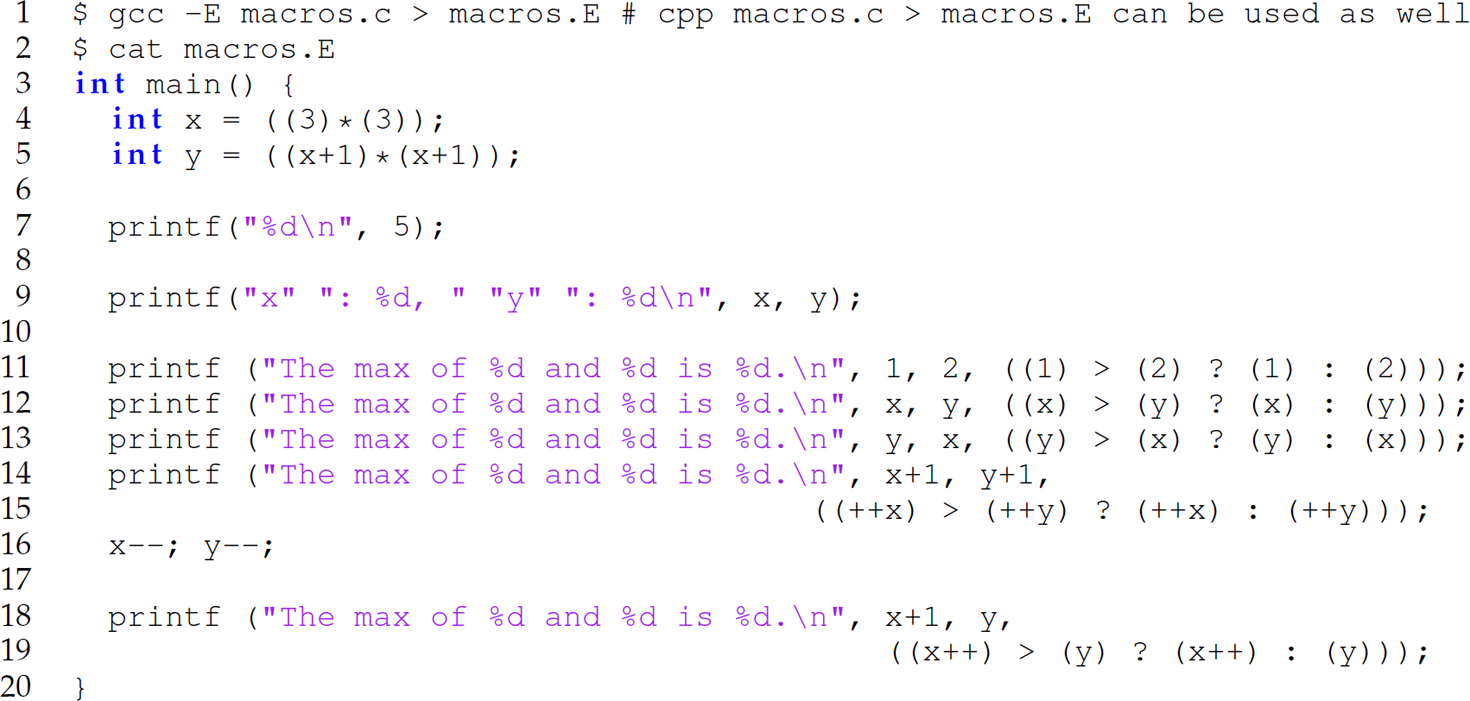
When the C preprocessor encounters a #define, it substitutes the third string on the same line of code as the definition for all occurrences in the program of the second string on that line. For instance, line 4 of the unexpanded program is the definition of the macro FIVE: #define FIVE 5. Thus, the preprocessor replaces the statement
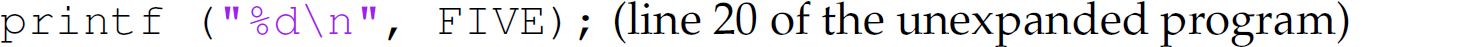
with
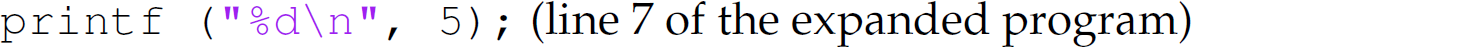
In other words, FIVE is textually replaced with 5. This substitution can be thought of as solely step 1 of β-reduction.
Expanding the macros defined on lines 6, 11, and 14 involves both steps 1 and 2 of β-reduction. For instance, consider the SQUARE macro defined on line 6 of the unexpanded version. Using this macro to demonstrate β-reduction:
All occurrences of the string SQUARE in the program (e.g., lines 17 and 18) are replaced with ((X) * (X));.
All occurrences of X in the replacement string are substituted with 3.
Thus, the statement
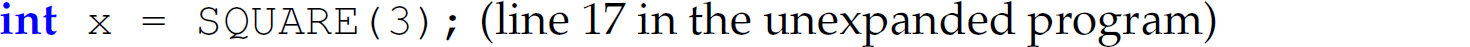
is replaced with the statement
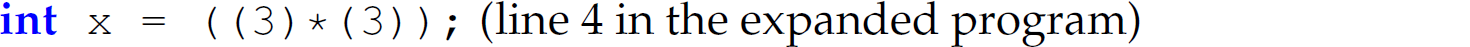
Similarly, the statement

is replaced with
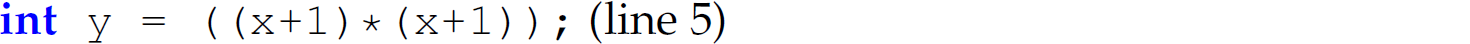
Prefacing a string representing a parameter in the replacement string of a macro with # causes the corresponding argument to be enclosed in double quotes after it is replaced for the parameter. For instance, the statement

is replaced with the statement
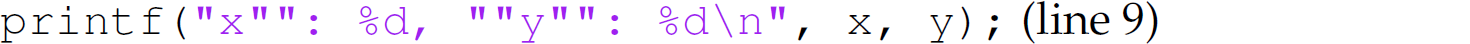
because the PRINT(A, B) macro is defined as
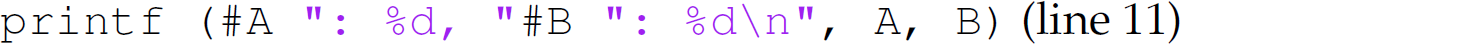
The MAX macro defined on line 14 is similarly expanded; that is, lines 24–26, 28, and 32 are replaced with lines 11–13, 15, and 19, respectively. The output of this program is

Line 8 of this output appears to be incorrect or, at least, inaccurate. Conceptual Exercise 12.5.1 explores why.
With an understanding of the β-reduction conducted by the C preprocessor as it expanded macros, we can define the classical swap function as a macro to explore pass-by-name semantics. Consider the following C program:

The swap macro is defined on line 4. The preprocessed version of this program with the SWAP macro expanded is

The output of this program is

The output indicates that the pass-by-name swap macro worked. However, another use of this swap macro tells a different story:

The output of this program is

The values of i and a[1] are not swapped after the expanded code from the swap macro executes: a[1] is 5 both before and after the replacement code of the macro executes. This outcome occurs because of side effect. The expansion of the macro replaces the statement

with
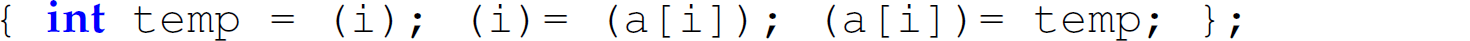
The side effect of the second assignment statement (i) = (a[i]) changes the value of i from 1 to 5. Thus, the third assignment, (a[i]) = temp;, places the original value of i (i.e., 1) in array element a[5] rather than a[1]. Consequently, after the replacement code of the macro executes, a[1] is unchanged. Side effect caused a similar problem in the execution of the replacement code of the MAX macro on line 28 in the first C program in Section 12.5.3, which produced the following output: The max of 10 and 101 is 102. Thus, we rephrase the first sentence of Section 12.5.2 as “lazy evaluation in a language without side effects supports the simplest possible form of reasoning about a program.” We explore the implications of side effect for the pass-by-name parameter-passing mechanism further in the Conceptual Exercises.
12.5.4 Two Implementations of Lazy Evaluation
Reconsider the square function defined in Scheme in Section 12.5.2: (define square (lambda (x) (* x x))). Recall that the β-reduction involved in the pass-by-name semantics of the (square (* 3 2)) invocation of square resulted in the argument expression (* 3 2) being evaluated twice because the parameter x is referenced twice in the body of the square function. Implementations of lazy evaluation differ in how they handle multiple references to the same parameter, as in the body of a function:
Pass-by-name: Evaluate the argument expression every time the parameter is referenced in the body of the function being evaluated.
Pass-by-need: Only evaluate the argument expression the first time the parameter is referenced in the body of the function, but save the value so that it can be retrieved for any subsequent references to the parameter. This saves the time needed to reevaluate the argument expression with each subsequent reference.
In a function without side effect, evaluating arguments to the function with pass-by-name semantics yields the same result as doing so with pass-by-need semantics. Thus, in languages without side effects, it is practical to use pass-byneed semantics to save the time required to repeatedly reevaluate an expression argument (i.e., a thunk) that will always returns the same value. However, in a function with side effects, evaluating arguments to the function with pass-by-name semantics may not yield the same result as doing so with pass-by-need semantics. For instance, consider the following Python program:


If the argument inc_x() is passed by name to the double function on line 12, then the double function returns 3 (= 1 + 2) because the parameter x is referenced twice in the body of the double function (line 10). Thus, the argument expression inc_x() is evaluated twice: The first time it is evaluated inc_x() returns 1, and the second time it returns 2 because inc_x has a side effect (i.e., it increments the global variable x). In contrast, if the argument inc_x() is passed by need to the double function on line 12, then the double function returns 2 (= 1 + 1) because the argument expression inc_x() is evaluated only once: The first time inc_x() returns the value 1, which is stored so that it can be retrieved the second time the parameter x is referenced.
Contrast the definitions of the double (lines 9–10) and add (line 16–17) functions: The double function accepts one parameter, which it references twice in its body (line 10); the add function accepts two parameters, each of which it references once in its body (line 17). However, the add function is invoked with the same expression for each argument (line 22). If each argument inc_x() is passed by name to the add function on line 22, then the add function returns 2 (= 1 + 2). While the parameters x and y are each referenced only once in the body of the add function (line 17), the argument expression inc_x() is evaluated twice, but for a different reason than it is for the pass-by-name invocation of the double function on line 12. Here, the argument expression inc_x() is evaluated once for each of the x and y parameters because the same argument expression is passed for both parameters. The first time inc_x() is evaluated, it returns 1, and the second time it returns 2 because inc_x has a side effect. Evaluating the invocation of the add function on line 22 using pass-by-need semantics yields the same result. Since each parameter is referenced only once in the body of the add function (line 17), there is no opportunity to retrieve the return value of each argument expression recorded. In other words, there is no opportunity to obviate a reevaluation during a subsequent reference because there are no subsequent references. Thus, unlike the invocation of the double function on line 12, the invocation of the add function on line 22 yields the same result when using pass-by-name or pass-byneed semantics.
Note that the Java or C analog of the invocation to the add function on line 22 is x=0; x++ + x++;, where x++ is an argument that is passed (by name or by need) twice to the + function. In summary,

ALGOL 60 was the first language to use pass-by-name, while Haskell was the first modern language to use pass-by-need. The statistical programming language R also uses the pass-by-name parameter-passing mechanism.
12.5.5 Implementing Lazy Evaluation: Thunks
Implementing lazy evaluation involves building support for pass-by-name and pass-by-need arguments. Lazy evaluation is easily implemented in a programming language with first-class functions and closures (e.g., Python or Scheme). We must delay the evaluation of an operand (perhaps indefinitely) by encapsulating it within the body of a function with no arguments—called a thunk. A thunk acts as a shell for a delayed argument expression. A thunk must contain all the information required to produce the value of the argument expression when it is needed in the body of a function, as if it had been evaluated at the time of the function application. Thus, a thunk is sometimes called a promise—invoking a thunk promises to return the value of the expression that the thunk encapsulates. To produce the value of the expression on demand, a thunk must have access to both the argument expression and the environment at the time of the call. Consider the following Python function f:

In the function call on line 5, y is not an invocation of some arbitrary Python function defined elsewhere, but rather the second parameter to the function f. When f is invoked with a non-zero integer as the first argument and the expression (1/0) as the second argument in a language that uses eager evaluation (e.g., Scheme, Java, or Python), it produces a run-time error:

To avoid this run-time error, we can pass the second argument to f by name. Thus, instead of passing the expression (1/0) as the second argument, we must pass a thunk:


When the argument being passed involves references to variables [e.g., (x/y) instead of (1/0)], the thunk created for the argument requires more information. Specifically, the thunk needs access to the referencing environment that contains the bindings to the variables being referenced.
Rather than hard-code a thunk every time we desire to delay the evaluation of an argument (as shown in the preceding example), we desire to develop a pair of functions for forming and evaluating a thunk (Table 12.4). We can then invoke the thunk-formation function each time the evaluation of an argument expression should be delayed (i.e., each time a pass-by-name argument is desired). Thus, we want to abstract away the process of thunk formation. Since a thunk is simply a nullary (i.e., argumentless) function, evaluating it is straightforward:
Table 12.4 Terms Used to Refer to Forming and Evaluating a Thunk
forming a thunk (or a promise) = freezing an expression operand = delaying its evaluation |

The definition of the thunk to be created depends on the use of pass-by-name or pass-by-need semantics. On the one hand, if the argument to be delayed is to be passed by name, thunk formation is straightforward:

The Python function eval accepts a string representing a Python expression, evaluates it, and returns the result of the expression evaluation. Implementing pass-by-need semantics, on the other hand, requires us to
Record the value of the argument expression the first time it is evaluated (line 36).
Record the fact that the expression was evaluated once (line 37).
Look up and return the recorded value for all subsequent evaluations (line 41).


Notice that the delay function builds the thunk as a first-class closure so that it can “remember” the return value of the evaluated argument expression in the variable result after delay returns. First-class closures are an important construct for implementing a variety of concepts from programming languages.
Since delay is a user-defined function and uses applicative-order evaluation, we must pass a string representing an expression, rather than an expression itself, to prevent the expression from being evaluated. For instance, in the invocation delay (1/0), the argument to be delayed [i.e., (1/0)] is a strict argument and will be evaluated eagerly (i.e., before it is passed to delay). Thus, we must only pass strings (representing expressions) to delay:

Enclosing the argument in quotes in Python is the analog of using the quote function or single quote in Scheme—for example, (quote (/ 1 0)) or '(/ 1 0).
Now let us apply our newly defined functions for lazy evaluation in Python to function invocations whose arguments involve references to variables as opposed to solely literals. Thus, we reconsider the Python program from Section 12.5.4:


In this program, we call delay to suspend the evaluation of the arguments in the function invocations (lines 59 and 71), and we use the function force in the body of functions to evaluate the argument expressions represented by the parameters when those parameters are needed (lines 57 and 67). In other words, a thunk is formed and passed for each argument using the delay function, and those thunks are evaluated using the force function when referenced in the bodies of the functions. Again, notice the difference in the two functions invoked with non-strict arguments. The function double is a unary function that references its sole parameter twice; the function add is a binary function that references each of its parameters once. Thus, the advantage of pass-by-need is only manifested with the invocation to double. The output of the invocation of double (line 59) is

The second reference to x does not cause a reevaluation of the thunk. The output of the invocation of add on line 71 is

In the invocation of the add function, one thunk is created for each argument and each thunk is separate from the other. While the two thunks are duplicates of each other, each thunk is evaluated only once.
The Scheme delay and force syntactic forms (which use pass-by-need semantics, also known as memoized lazy evaluation) are the analogs of the Python function delay and force defined here. Programming Exercise 12.5.19 entails implementing the Scheme delay and force syntactic forms as user-defined Scheme functions.
The Haskell programming language was designed as an intended standard for lazy, functional programming. In Haskell, pass-by-need is the default parameter-passing mechanism and, thus, the use of syntactic forms like delay and force is unnecessary. Consider the following transcript with Haskell:2
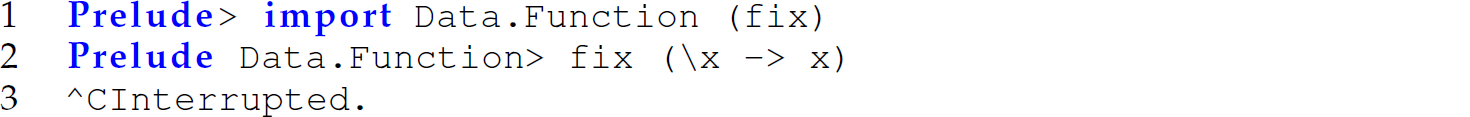

The Haskell function fix returns the least fixed point of a function in the domain theory interpretation of a fixed point. A fixed point of a function is a value x such that f(x) “ x. For instance, a fixed point of a square root function ![]() is 1 because
is 1 because ![]() . Since there is no least fixed point of an identity function f(x) “ x, the invocation fix (x -> x) never returns—it searches indefinitely (lines 2–3). Haskell supports pass-by-value parameters as a special case. When an argument is prefaced with $!, the argument is passed by value or, in other words, the evaluation of the argument is forced. In this case, the argument is treated as a strict argument and evaluated eagerly:
. Since there is no least fixed point of an identity function f(x) “ x, the invocation fix (x -> x) never returns—it searches indefinitely (lines 2–3). Haskell supports pass-by-value parameters as a special case. When an argument is prefaced with $!, the argument is passed by value or, in other words, the evaluation of the argument is forced. In this case, the argument is treated as a strict argument and evaluated eagerly:
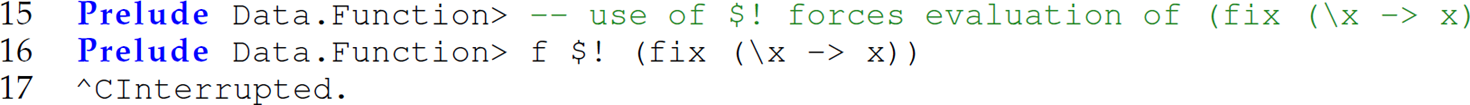
The built-in Haskell function seq evaluates its first argument before returning its second. Using seq, we can define a function strict:
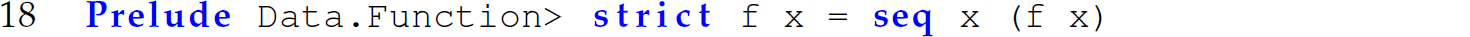
We can then apply strict to treat an argument to a function f as strict. In other words, we evaluate the argument x eagerly before evaluating the body of f:

There is an interesting relationship between the space complexity of a function and the strategy used to evaluate parameters (e.g., non-strict or strict). We discuss the details in Section 13.7.4. For now, it is sufficient to know that an awareness of the space complexity of a program is important, especially in languages using lazy evaluation. Moreover, “[t]he space behavior of lazy programs is complex: . . . some programs use less space than we might predict, while others use more” (Thompson 2007, p. 413). Finally, strict parameters are primarily used in lazy languages to improve the space complexity of a function.
12.5.6 Lazy Evaluation Enables List Comprehensions
Lazy evaluation leads to potentially infinite lists that are referred to as list comprehensions or streams. More generally, lazy evaluation leads to infinite data structures (e.g., trees). For instance, consider the Haskell expression ones = 1 : ones. Since the evaluation of the arguments to cons are delayed by default, ones is an infinite list of 1s. Haskell supports the definition of list comprehension using syntactic sugar:

We can define functions take1 and drop1 to access parts of list comprehensions:3

Let us unpack the evaluation of take1 2 ones:

Since only enough of the list comprehension is explicitly realized when needed, we can think of this as laying down railroad track as we travel rather than building the entire railroad prior to embarking on a voyage. Thus, we must be mindful when applying functions to streams so to avoid enumerating the list ad infinitum. Consider the following continuation of the preceding transcript:

Note on line 36 that Haskell uses notation similar to set-former or set-builder notation from mathematics to define the squares list comprehension: squares “ {n * n | n ∈ N, where N “ {1, 2, . . . , ∞}}. We can see that Haskell brings programming closer to mathematics. Here, the invocation of the built-in elem (or member) function (line 37) returns True because 16 is a square. However, the elem function does not know that the input list is sorted, so it will search for 15 (line 39) indefinitely. While doing so, it will continue to enumerate the list comprehension indefinitely. Defining a sortedElem function that assumes its list argument is sorted causes the search and enumeration (line 51) to be curtailed once it encounters a number greater than its first argument.
Lazy evaluation also leads to terse implementation of complex algorithms. Consider the implementation of both the Sieve of Eratosthenes algorithm for generating prime numbers (in two lines of code) and the quicksort sorting algorithm (in four lines of code):


Let us trace the sieve [2,3,4,5,6,7,8,9,10] invocation:
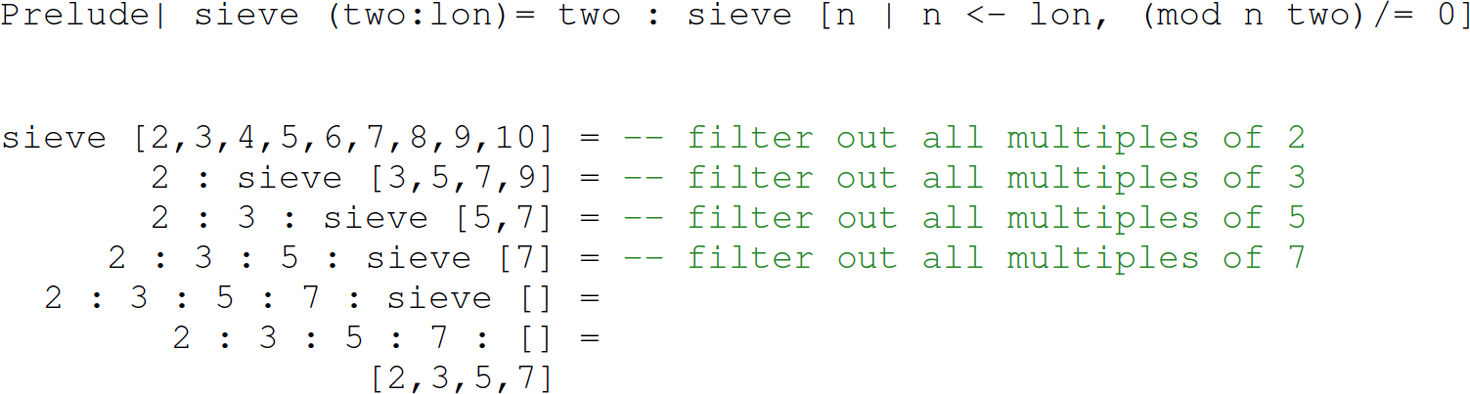
The beauty of using lazy evaluation in the implementation of this algorithm is that the filter will filter the list only as far as the function that called sieve (e.g., take1) requires. We can see in the sieve function that lazy evaluation enables a generate-filter style of programming (Hughes 1989) resembling the filter style of programming common in Linux, where concurrent processes are not only communicating, but also maintaining synchronous execution with each other, through a possible infinite stream of data flowing through pipes—for example, cat lazy.txt | aspell list | sort | uniq | wc -l. Similarly, let us trace the quicksort [10,9,8,7,6,5,4,3,2,1] invocation:


While Python evaluates arguments eagerly, it does have facilities that enable the program to define infinite streams, thereby obviating the enumeration of a large list in memory. Python makes a distinction between a list comprehension and a generator comprehension or generator expression. In Python, a generator expression is what we call a list comprehension in Haskell—that is, a function that generates list elements on demand. List comprehensions in Python, however, are syntactic sugar for defining an enumerated list without a loop using set-former notation. Consider the following transcript with Python:


Syntactically, the only difference between lines 3 and 14 is the use of square brackets in the definition of the list comprehension (line 3) and the use of parentheses in the definition of the generator expression (line 14). However, lines 9 and 20 reveal a significant savings in space required for the generator expression. In terms of space complexity, a list comprehension is preferred if the programmer intends to iterate over the list multiple times; a generator expression is preferred if the list is to be iterated over once and then discarded. Thus, if only the sum of the list is desired, a generator expression (line 30) is preferable to a list comprehension (line 27). Generator expressions can be built using functions calling yield:

Lines 1–7 define a generator for the natural numbers (e.g., [1..] in Haskell). Without the yield statement on line 6, this function would spin in an infinite loop and never return. The yield statement is like a return, except that the next time the function is called, the state in which it was left at the end of the previous execution is “remembered” (see the concept of coroutine in Section 13.6.1). The take function defined on lines 11–14 realizes in memory a portion of a generator and returns it as a list (lines 16–17).
12.5.7 Applications of Lazy Evaluation
Streams and infinite data structures are useful in a variety of artificial intelligence problems and applications involving search (e.g., a game tree for tic-tac-toe or chess) for avoiding the need to enumerate the entire search space, especially since large portions of the space need not ever be explored. The power of lazy evaluation in obviating the need to enumerate the entire search space prior to searching it is sufficiently demonstrated in the solution to the simple, yet emblematic for purposes of illustration, same-fringe problem. The same-fringe problem is a classical problem from functional programming that requires a generator-filter style of programming. The problem entails determining if the non-null n atoms in two S-expressions are equal and in the same order. A straightforward approach proceeds in this way:
Flatten both lists.
Recurse down each flat list until a mismatch is found.
If a mismatch is found, the lists do not have the same fringe.
Otherwise, if both lists are exhausted, the fringes are equal.
Problem: If the first non-null atoms in each list are different, we flattened the lists for naught. Lazy evaluation, however, will realize only enough of each flattened list until a mismatch is found. If the lists have the same fringe, each flattened list must be fully generated. The same-fringe problem calls for the power of lazy evaluation and the streams it enables. Programming Exercises 12.5.21 and 12.5.22 explore solutions to this problem.
12.5.8 Analysis of Lazy Evaluation
Three properties of lazy evaluation are:
“[I]f there exists any evaluation sequence which terminates for a given expression, then [pass]-by-name evaluation will also terminate for this expression, and produce the same final result (Hutton 2007, p. 129).
[A]rguments are evaluated precisely once using [pass]-by-value evaluation, but may be evaluated many times using [pass]-byname (Hutton 2007, p. 130).
[U]sing lazy evaluation, expressions are only evaluated as much as required by the context in which they are used” (Hutton 2007, p. 132).
The power of lazy evaluation is manifested in the form of solutions to problems it enables. By acting as the glue binding entire programs together, lazy evaluation enables a generate-filter style of programming that is reminiscent of the filter style of programming in which pipes are used to connect processes communicating through I/O in UNIX (e.g., cat lazy.txt | aspell list | sort | uniq | wc -l). Lazy evaluation and higher-order functions are tools that can be used to both modularize a program and generalize the modules, which makes them reusable (Hughes 1989).
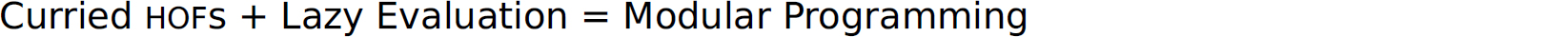
12.5.9 Purity and Consistency
Lazy evaluation encourages uniformity in languages because it obviates the need for syntactic forms for constructs for which applicative-order evaluation is unreasonable (e.g., if). As a consequence, a language can be extended by a programmer in standard ways, such as through a user-defined function. Consider Scheme, which uses applicative-order evaluation by default.
Syntactic forms such as if and cond use normal-order evaluation:

Description The boolean operators and and or are also special syntactic forms and use normal-order evaluation:

Description Arithmetic operators such as + and > are procedures (i.e., functions). Thus, like user-defined functions, they use applicative-order evaluation:

Description
The Scheme syntactic forms delay and force permit the programmer to define and invoke functions that use normal-order evaluation. A consequence of this impurity is that programmers cannot extend (or modify) control structures (e.g., if, while, or for) in such languages using standard mechanisms (e.g., a user-defined function).
Why is lazy evaluation not more prevalent in programming languages? Certainly there is overhead involved in freezing and thawing thunks, but that overhead can be reduced with memoization (i.e., pass-by-need semantics) in the absence of side effects. In the presence of side effects, pass-by-need cannot be used. More importantly, in the presence of side effects, lazy evaluation renders a program difficult to understand. In particular, lazy evaluation generally makes it difficult to determine the flow of program control, which is essential to understanding a program with side effects. An attempt to conceptualize the control flow of a program with side effects using lazy evaluation requires digging deep into layers of evaluation, which is contrary to a main advantage of lazy evaluation—namely, modularity (Hughes 1989). Conversely, in a language with no side effects, flow of control has no effect on the result of a program. As a result, lazy evaluation is most common in languages without provisions for side effects (e.g., Haskell) and rarely found elsewhere.
Conceptual Exercises for Section 12.5
Exercise 12.5.1 Explain line 8 of the output in Section 12.5.3 (replicated here) of the first C program with a MAX macro:
The max of 10 and 101 is 102.
Exercise 12.5.2 Describe what problems might occur in a variety of situations if the MAX macro on line 14 of the first C program in Section 12.5.3 is defined as follows:

(i.e., without each parameter in the replacement string enclosed in parentheses). Which uses of this macro would cause the identified problems to manifest? Explain.
Exercise 12.5.3 Consider the following swap macro using pass-by-name semantics defined on line 4 (replicated here) of the second C program in Section 12.5.3:
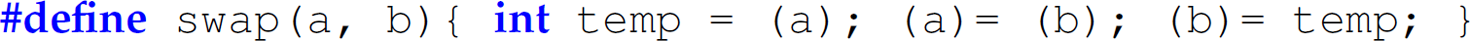
For each of the following main programs in C, give the expansion of the swap macro in main and indicate whether the swap works.
(a)

(b)

Exercise 12.5.4 Consider the following C program:
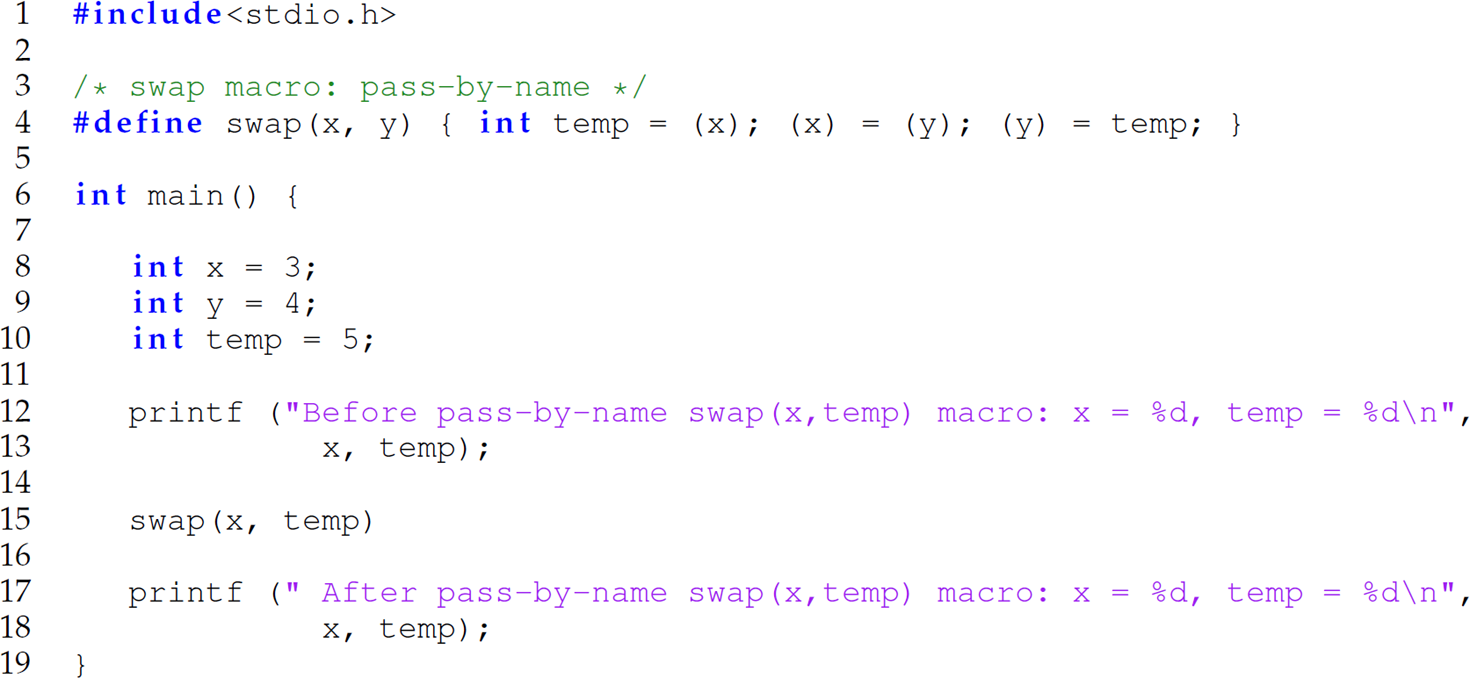
The preprocessed version of this program with the swap macro expanded is

The output of this program is

While this (pass-by-name) swap macro works when invoked as swap(x,y) on line 14 in the second C program in Section 12.5.3, here it does not swap the arguments—the values of x and temp are the same both before and after the code from the expanded swap macro executes. This outcome occurs because there is an identifier in the replacement string of the macro (line 4 of the unexpanded version) that is the same as the identifier for one of the variables being swapped, namely temp. When the macro is expanded in main (line 10), the identifier temp in main is used to refer to two different entities: the variable temp declared in main on line 5 and the local variable temp declared in the nested scope on line 10 (from the replacement string of the macro). The identifier temp in main collides with the identifier temp in the replacement string of the macro. What can be done to avoid this type of collision in general?
Exercise 12.5.5 Consider the following f macro using pass-by-name semantics:
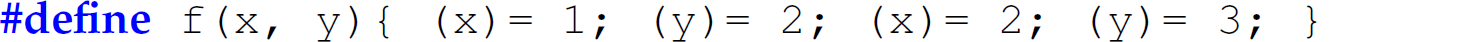
Consider the following main program in C that uses this macro:

Expand the f macro in main and give the values of i and a[i] before and after the statement f(i, a[i]).
Exercise 12.5.6 Consider the following f macro using pass-by-name semantics:

Consider the following main program in C that uses this macro:

Expand the f macro in main and give the values of i, j, and k before and after the statement f(k+1, j, i).
Exercise 12.5.7 Consider the following f macro using pass-by-name semantics:

Consider the following main program in C that uses this macro:

Assume the invocation of read() reads an integer from an input stream. Give the expansion of the f macro in main.
Exercise 12.5.8 In Section 12.5.3, we demonstrated that the expansion of macros defined in C/C++ using #define by the C preprocessor involves the string substitution in β-reduction. However, not all functions can be defined as macros in C. What types of functions do not lend themselves to definition as macros?
Exercise 12.5.9 Verify which semantics of lazy evaluation Racket uses through the delay and force syntactic forms: pass-by-name or pass-by-need. Specifically, modify the following Racket expression so that the parameters are evaluated lazily. Use the return value of the expression to determine which semantics of lazy evaluation Racket implements.

Given that Scheme makes provisions for side effects (through the set! operator), are the semantics of lazy evaluation that Scheme implements what you expected? Explain.
Exercise 12.5.10 Common Lisp uses applicative-order evaluation for function arguments. Is it prudent to treat the if expression in Common Lisp as a function or a syntactic form (i.e., not a function) and why?
The following is an example of an if expression in Common Lisp: (if (atom 'x)'yes 'no).
Exercise 12.5.11 The second argument to each of the Haskell built-in boolean operators && and || is non-strict. Define the (&&) :: Bool -> Bool -> Bool and (||) :: Bool -> Bool -> Bool operators in Haskell.
Exercise 12.5.12 Consider the following definition of a function f defined using Python syntax:

Is it advisable to evaluate f using normal-order evaluation or applicative-order evaluation? Explain and give your reasoning.
Exercise 12.5.13 Give an expression that returns different results when evaluated with applicative-order evaluation and normal-order evaluation.
Exercise 12.5.14 For each of the following programming languages, indicate whether the language uses short-circuit evaluation and give a program to unambiguously defend your answer.
(a) Common Lisp
(b) ML
Exercise 12.5.15 Lazy evaluation can be said to encapsulate other parameter-passing mechanisms. Depending on the particular type and form of an argument, lazy evaluation can simulate a variety of other parameter-passing mechanisms. For each of the following types of arguments, indicate which parameter-passing mechanism lazy evaluation is simulating. In other words, if each of the following types of arguments is passed by name, then the result of the function invocation is the same as if the argument was passed using which other parameter-passing mechanism?
(a) A scalar variable (e.g., x)
(b) A literal or an expression involving only literals [e.g., 3 or (3 * 2)]
Exercise 12.5.16 Recall that Haskell is a (nearly) pure functional language (i.e., provision for side effect only for I/O) that uses lazy evaluation. Since Haskell has no provision for side effect and pass-by-name and pass-by-need semantics yield the same results in a function without side effects, it is reasonable to expect that any Haskell interpreter would use pass-by-need semantics to avoid reevaluation of thunks. Since a provision for side effect is necessary to implement the pass-by-need semantics of lazy evaluation, can a self-interpreter for Haskell (i.e., an interpreter for Haskell written in Haskell) be defined? Explain. What is the implementation language of the Glasgow Haskell Compiler?
Programming Exercises for Section 12.5
Exercise 12.5.17 Rewrite the entire first Python program in Section 12.5.4 as a single Camille expression.
Exercise 12.5.18 Consider the following Scheme expression, which is an analog of the entire first Python program in Section 12.5.4:

Rewrite this Scheme expression using the Scheme delay and force syntactic forms so that the arguments passed to the two anonymous functions on lines 7 and 8 are passed by need. The return value of this expression is '(2 5) using pass-by-need.
Exercise 12.5.19 The Scheme programming language uses pass-by-value. In this exercise, you implement lazy evaluation in Scheme. In particular, define a pair of functions, freeze and thaw, for forming and evaluating a thunk, respectively. The functions freeze and thaw have the following syntax:

The thaw and freeze functions are the Scheme analogs of the Python functions force and delay presented in Section 12.5.5. The thaw and freeze functions are also the user-defined function analogs of the Scheme built-ins force and delay, respectively.
In this implementation, an expression subject to lazy evaluation is not evaluated until its value is required; once evaluated, it is never reevaluated, (i.e., pass-by-need semantics). Specifically, the first time the thunk returned by freeze is thawed, it evaluates expr and remembers the return value of expr as demonstrated in Section 12.5.5. For each subsequent thawing of the thunk, the saved value of the expression is returned without any additional evaluation. Add print statements to the thunk formed by the freeze function, as done in Section 12.5.5, to distinguish between the first and subsequent evaluations of the thunk.
Examples:

Be sure to quote the argument expr passed to freeze (line 1) to prevent it from being evaluating when freeze is invoked (i.e., eagerly). Also, the body of the thunk formed by the freeze function must invoke the Scheme function eval (as discussed in Section 8.2). So that the evaluation of the frozen expression has access to the base Scheme bindings (e.g., bindings for primitives such as car and cdr) and any other user-defined functions, place the following lines at the top of your program:

Then pass ns as the second argument to eval [e.g., (eval expr ns)]. See https://docs.racket-lang.org/guide/eval.html for more information on using Racket Scheme namespaces.
Exercise 12.5.20 (Scott 2006, Exercise 6.30, pp. 302–303) Use lazy evaluation through the syntactic forms delay and force to implement a lazy iterator object in Scheme. Specifically, an iterator is either the null list or a pair consisting of an element and a promise that, when forced, returns an iterator. Define an uptoby function that returns an iterator, and a for-iter function that accepts a one-argument function and an iterator as arguments and returns an empty list. The functions for-iter and uptoby enable the evaluation of the following expressions:

The function for-iter, unlike the built-in Scheme form for-each, does not require the existence of a list containing the elements over which to iterate. Thus, the space required for (for-iter f (uptoby 1 n 1)) is O(1), rather than O(n).
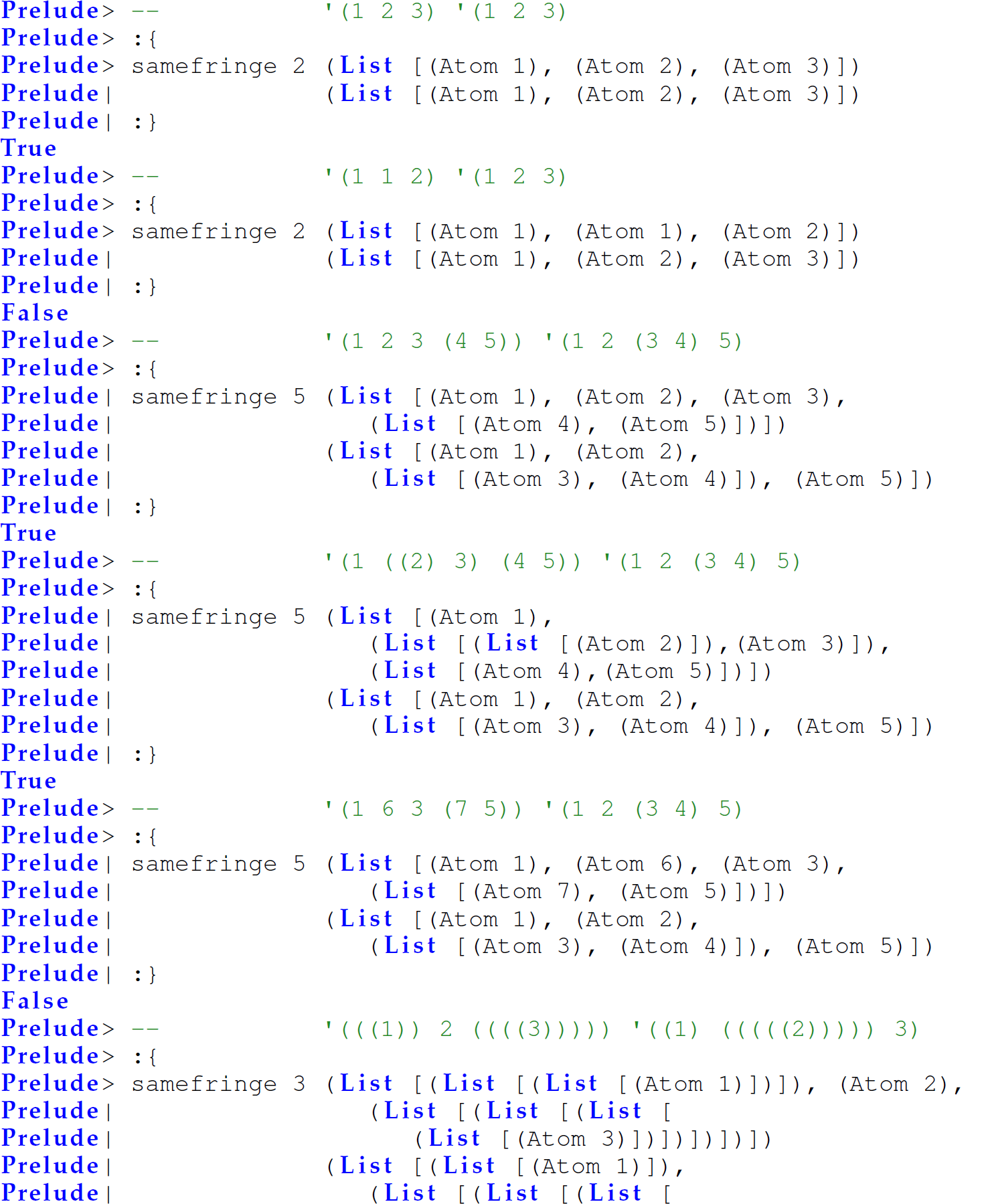
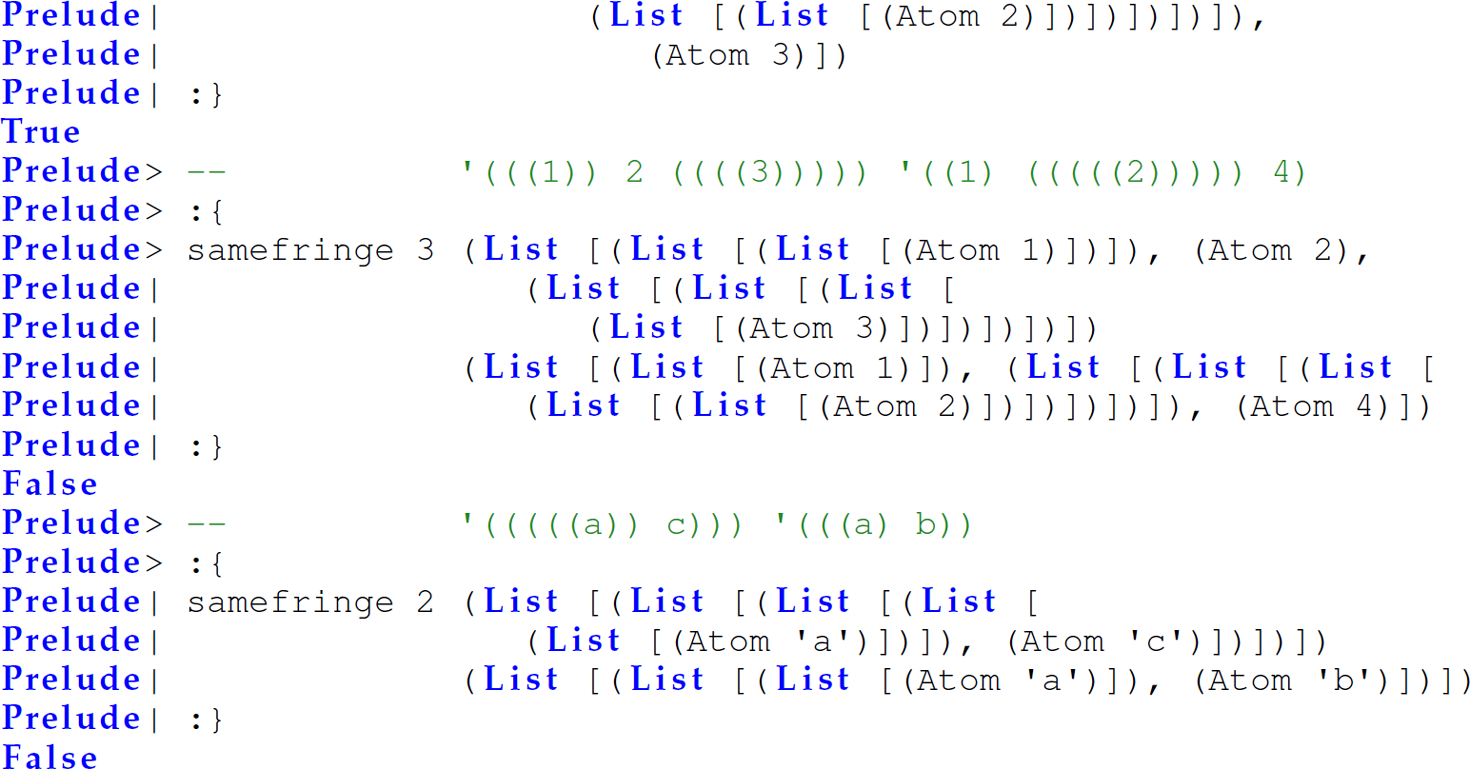
Exercise 12.5.21 Use lazy evaluation (delay and force) to solve Programming Exercise 5.10.12 (repeated here) in Scheme. Define a function samefringe in Scheme that accepts an integer n and two S-expressions, and returns #t if the first non-null n atoms in each S-expression are equal and in the same order and #f otherwise.
Examples:

Exercise 12.5.22 Solve Programming Exercise 5.10.12 (repeated here) in Haskell. Define a function samefringe in Haskell that accepts an integer n and two S-expressions, and returns True if the first non-null n atoms in each S-expression are equal and in the same order and False otherwise. Because of the homogeneous nature of lists in Haskell, we cannot use a list to represent an S-expression in Haskell. Thus, use the following definition of an S-expression in Haskell:

Examples:
Exercise 12.5.23 Define the built-in Haskell function iterate :: (a -> a) -> a -> [a] as iterate1 in Haskell. The iterate function accepts a unary function f with type a -> a and a value x of type a; it generates an (infinite) list by applying f an increasing number of times to x (i.e., iterate f x = [x, (f x), f (f x), f (f (f x)), ...]).
Examples:

Exercise 12.5.24 Define the built-in Haskell function filter :: (a -> Bool) -> [a] -> [a] as filter1 using list comprehensions (i.e., set-former notation) in Haskell. The filter function accepts a predicate [i.e., (a -> Bool)] and a list (i.e., [a]), in that order, and returns a list (i.e., [a]) filtered based on the predicate.
Examples:

Exercise 12.5.25 Read John Hughes’s essay “Why Functional Programming Matters” published in The Computer Journal, 32(2), 98–107, 1989, and available at https://www.cse.chalmers.se/~rjmh/Papers/whyfp.html. Read this article with the Glasgow Haskell Compiler (GHC) open so you can enter the expressions as you read them, which will help you to better understand them. You will need to make some minor adjustments, such as replacing cons with :. The GHC is available at https://www.haskell.org/ghc/. Study Sections 1–3 of the article. Then implement one of the numerical algorithms from Section 4 in Haskell (e.g., Newton-Raphson square roots, numerical differentiation, or numerical integration). If you are interested in artificial intelligence, implement the search described in Section 5. Your code must run using GHCi—the interactive interpreter that is part of GHC.
1. The examples of C macros in this chapter are not intended to convey that C macros correspond to lazy evaluation. “Macros do not correspond to lazy evaluation. Laziness is a property of when the implementation evaluates arguments to functions. . . . Indeed, macro expansion (like type-checking) happens in a completely different phase than evaluation, while laziness is very much a part of evaluation. So please don’t confuse the two” (Krishnamurthi 2003). The examples of C macros used here are simply intended to help the reader get a feel for the pass-by-name parameter-passing mechanism and β-reduction; they are used entirely for purposes of demonstration.
2. We cannot use the simpler argument expression 1/0 to demonstrate a non-strict argument in Haskell because 1/0 does not generate a run-time error in Haskell—it returns Infinity.
3. We use the function names take1 and drop1 because these functions are defined in Haskell as take and drop, respectively.