

This chapter presents a complete subsystem that demonstrates all the remaining Gang-of-Four design patterns: a miniature SQL interpreter (and JDBC interface) that you can embed in your applications. This package is not a full-blown database but is a small in-memory database suitable for many client-side applications.
As was the case with the Game of Life game discussed in the previous chapter, I’ve set up a web page at http://www.holub.com/software/holubSQL/ that lists various links to SQL resources and provides an applet that lets you play with the interpreter I’m about to discuss. You can find the most recent version of the source code from this chapter on the same web page.
As was also the case with Life, I’ve opted to present a complete subsystem, so this chapter has a lot of code in it. As before, I don’t expect you to read every line—I’ve called out the important stuff in the text.
With the exception of “The Interpreter Pattern” section, you don’t need to know anything special to read this chapter. That section, which covers how the actual SQL interpreter and the parser that builds it works, is a doozy, though. After a lot of thought, I decided not to turn this chapter into a treatise on compiler writing, simply because the subject rarely comes up in normal programming. Moreover, the Interpreter Pattern section introduces only one design pattern, which is used only to build interpreters. If you’re not going to build an interpreter, you can safely skip it (both the pattern and the section). If you’re bold enough to proceed, however, I’m assuming (in that section only) that you know how write simple SQL statements, you know how to read an LL(1) BNF grammar, and you know how recursive-descent parsing works. The web page I just mentioned has links to SQL and JDBC resources if you need to learn that material, and it also links to a long introduction of formal grammars and recursive-descent parsing.
The Requirements
I originally wrote the small database engine in this chapter to handle the persistence layer for a client-side-only “shrink-wrap” application. My program used only a few tables and did only simple joins, and I didn’t want the size, overhead, and maintenance problems of a “real” database. I also didn’t need full-blown SQL—just a reasonable subset that supports table creation, modification, and simple queries (including joins) was sufficient. I didn’t need views, triggers, functions, and the other niceties of a real database. I did, however, need the tables that comprised the database to be stored in some human-readable ASCII format such as comma-separated values (preferred) or XML, and none of the databases that I could find satisfied this last requirement.
I rolled my own database for other reasons as well. The database needed to be “embedded” into the rest of the program rather than being a stand-alone server. I just didn’t want the hassle of installing (and maintaining) a stand-alone third-party database server that was likely to be an order of magnitude larger than the application itself. I wanted a small, lean implementation.
I wanted to talk to the database using JDBC so that I could replace it with something that was more fully featured if necessary. The database engine had to be written entirely in Java so that it was platform independent.
Finally, several times I’ve wanted to store a small amount of data in a database-like way, but without the overhead of an actual database. For example, it’s handy to put configuration options into a database-like data structure so that you can issue queries against the configuration. Using a database to keep track of ten configuration options was just too much overhead, however. I wanted the data structures that underlie the SQL interpreter to be useable in their own right as a sort of “collection,” but without the SQL.
I checked the web to see if there was anything that would do the job, but I couldn’t find anything at the time, so I rolled up my sleeves and wrote my own. (I’ve subsequently discovered a couple small public-domain SQL interpreters, but that’s life—it took less than two weeks to write the SQL engine you’re about to examine, so I didn’t waste any time.)
The Architecture
I approached the design of my small-database subsystem by breaking it into three distinct layers, each accessed through well-defined interfaces (see Figure 4-1). This use of interfaces to isolate subsystems from each other is a simple reification of the Bridge pattern, which I’ll discuss in greater depth later in the current chapter. The basic idea of Bridge is to separate subsystems with a set of interfaces so you can modify one subsystem without impacting the other.
The data-storage layer manages the actual data that comprises a table and also handles persistence. This layer exposes two interfaces: Table (which defines access to the table itself) and Cursor, which provides an iterator across rows in the table (an object that lets you visit each row of the table in sequence).
The data-storage classes are wrapped in a SQL-engine layer, which implements the SQL interpreter and uses the underlying data-storage classes to manage the actual data. This layer exposes result sets (the set of rows that result from a SQL select operation) as Table objects, and you can examine the result set with a Cursor, so these two interfaces isolate both “faces” of the subsystem. (Like Janus, one face looks backward at the data-storage layer, and the other face looks forward at the JDBC layer.)
Finally, a JDBC-driver layer wraps the SQL engine with classes that implement the various interfaces required by JDBC, so you can access my simple database just like you would any other database. Using the JDBC Bridge also lets you easily replace my simple database with something that’s more fully featured without having to modify your code. The JDBC layer completely hides the underlying Table and Cursor interfaces. (You won’t have to worry about JDBC-related stuff until you get to “The JDBC Layer” section toward the end of this chapter. Everything I discuss up to that point has nothing to do with JDBC. I’ll explain how JDBC works when you get to that section, and when I do get to it, JDBC classes will be clearly indicated by using their fully qualified class names: java.sql.Xxx. If you don’t see the java.sql, then the class is one of mine.)
The messaging between layers is effectively unidirectional. For example, the SQL engine knows about, and send messages to, the data-storage layer, but the data-storage layer knows nothing about the SQL engine and sends no messages to any of the objects that comprise the SQL engine. This one-way communication vastly simplifies maintenance because you know that the effects of a given change are limited. Since these three layers are completely independent of one another, I can also discuss them independently.
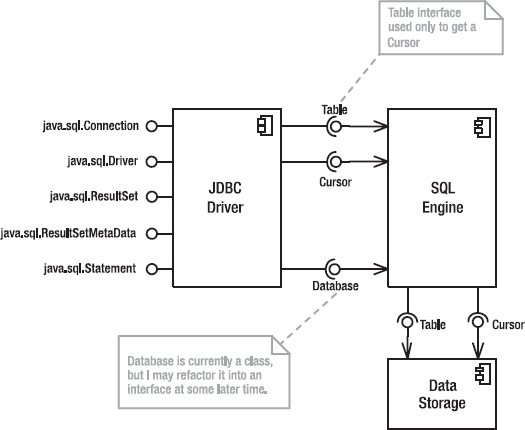
Figure 4-1. Database-classes architecture
The Data-Storage Layer
At the core of everything is the Table interface, its implementation (ConcreteTable), and various support classes and interfaces. As I did in the previous chapter, I’ll start with a couple of monstrous figures, which will seem confusing at first but make sense as I discuss the program one bit at a time. Figure 4-2 shows the static structure of the classes that comprise the data-storage layer: the Table interface and all its implementations and supporting classes. Figure 4-3 shows the design patterns. As was the case with Life, there are almost as many patterns as there are classes, which is to say that several classes participate in more than one pattern. You should bookmark these figures so that you can refer to them as I discuss the various patterns.
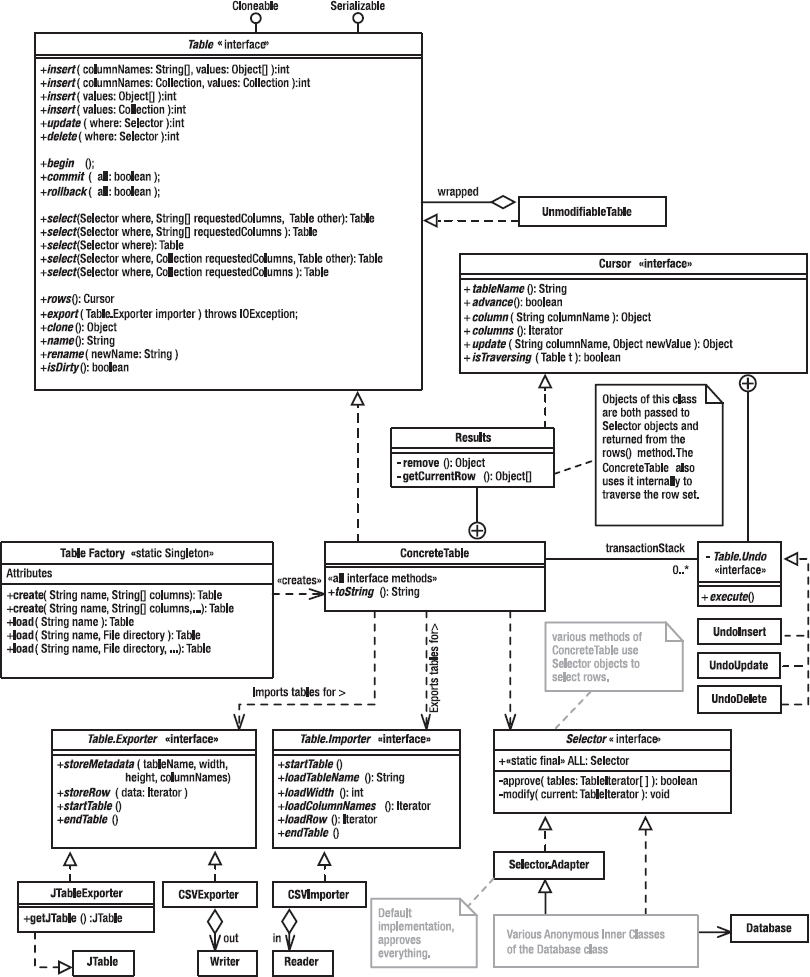
Figure 4-2. Data-storage layer: static structure
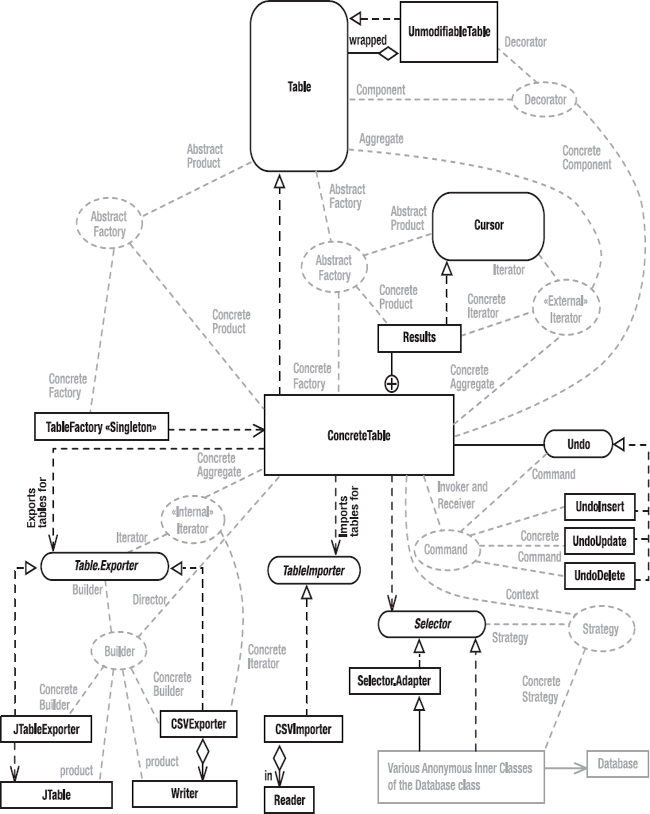
Figure 4-3. Data-storage layer: design patterns
The Table Interface
The Table interface (Listing 4-1) defines the methods you use to talk to a table. I’ve designed the Table so that it (and the underlying implementation) is useful as a data structure in its own right, without needing to wrap it with the SQL-related layers. Sometimes, you just need a searchable table rather than a whole database.
A Table is an in-memory data structure that you can use rather like a Collection. The interface doesn’t extend Collection, however, because a Table is really doing a different thing than a standard Collection—they just both happen to be data structures. There would be no way to implement most of the methods of the Collection interface in the Table. A Table supports the database notion of a column. You can think of a Table as a set of rows, each of which has several columns that are identified by name. It’s like a two-dimensional array, except that it’s searchable and the columns have names, not column indexes. (JDBC lets you specify a column by index, but I don’t do that in my own code, so I haven’t implemented the feature. Index-based access—as compared to named access—has given me grief when I’ve had to add columns to the database and the column indexes have changed as a consequence, so I don’t use them.)
Every cell (the intersection of a column and row) can hold an object. The rows in a Table are not ordered. You find a particular row by searching the table for rows whose columns match certain criteria (which you specify—more in a moment).
Table is an interface, not a class. An interface makes it possible to isolate the parts of the program that use the Table from the parts of the program that implement the Table. I can change everything about the implementation—even the concrete-class name—without any code on the “client” side of the interface changing. The comments in Listing 4-1 describe the various Table operations adequately, and I’ll have more to say about them when I look at the implementations.
Listing 4-1. Table.java
1 package com.holub.database;
2
3 import java.io.*;
4 import java.util.*;
5 import com.holub.database.Selector;
6
7 /** A table is a database-like table that provides support for
8 * queries.
9 */
10
11 public interface Table extends Serializable, Cloneable
12 {
13 /** Return a shallow copy of the table (the contents are not
14 * copied.
15 */
16 Object clone() throws CloneNotSupportedException;
17
18 /** Return the table name that was passed to the constructor
19 * (or read from the disk in the case of a table that
20 * was loaded from the disk.) This is a "getter," but
21 * it's a harmless one since it's just giving back a
22 * piece of information that it was given.
23 */
24 String name();
25
26 /** Rename the table to the indicated name. This method
27 * can also be used for naming the anonymous table that's
28 * returned from {@link #select select(...)}
29 * or one of its variants.
30 */
31 void rename( String newName );
32
33 /** Return true if this table has changed since it was created.
34 * This status isn't entirely accurate since it's possible
35 * for a user to change some object that's in the table
36 * without telling the table about the change, so a certain
37 * amount of user discipline is required. Returns true
38 * if you modify the table using a Table method (such as
39 * update, insert, etc.). The dirty bit is cleared when
40 * you export the table.
41 */
42 boolean isDirty();
43
44 /** Insert new values into the table corresponding to the
45 * specified column names. For example, the value at
46 * <code>values[i]</code> is put into the column specified
47 * in <code>columnNames[i]<code>. Columns that are not
48 * specified are initialized to <code>null.</code>.
49 *
50 * @return the number of rows affected by the operation.
51 * @throws IndexOutOfBoundsException One of the requested columns
52 * doesn't exist in either table.
53 */
54 int insert( String[] columnNames, Object[] values );
55
56 /** A convenience overload of {@link #insert(String[],Object[])} */
57
58 int insert( Collection columnNames, Collection values );
59
60 /** In this version of insert, values must have as many elements as there
61 * are columns, and the values must be in the order specified when the
62 * Table was created.
63 * @return the number of rows affected by the operation.
64 */
65 int insert( Object[] values );
66
67 /** A convenience overload of {@link #insert(Object[])}
68 */
69
70 int insert( Collection values );
71
72 /**
73 * Update cells in the table. The {@link Selector} object serves
74 * as a visitor whose <code>includeInSelect(...)</code> method
75 * is called for each row in the table. The return value is ignored,
76 * but the Selector can modify cells as it examines them. It's your
77 * responsibility not to modify primary-key and other constant
78 * fields.
79 * @return the number of rows affected by the operation.
80 */
81
82 int update( Selector where );
83
84 /** Delete from the table all rows approved by the Selector.
85 * @return the number of rows affected by the operation.
86 */
87
88 int delete( Selector where );
89
90 /** begin a transaction */
91 public void begin();
92
93 /** Commit a transaction.
94 * @throw IllegalStateException if no {@link #begin} was issued.
95 *
96 * @param all if false, commit only the innermost transaction,
97 * otherwise commit all transactions at all levels.
98 * @see #THIS_LEVEL
99 * @see #ALL
100 */
101 public void commit( boolean all ) throws IllegalStateException;
102
103 /** Roll back a transaction.
104 * @throw IllegalStateException if no {@link #begin} was issued.
105 * @param all if false, commit only the innermost transaction,
106 * otherwise commit all transactions at all levels.
107 * @see #THIS_LEVEL
108 * @see #ALL
109 */
110 public void rollback( boolean all ) throws IllegalStateException; 111
112 /** A convenience constant that makes calls to {@link #commit}
113 * and {@link #rollback} more readable when used as an
114 * argument to those methods.
115 * Use <code>commit(Table.THIS_LEVEL)</code> rather than
116 * <code>commit(false)</code>, for example.
117 */
118 public static final boolean THIS_LEVEL = false;
119
120 /** A convenience constant that makes calls to {@link #commit}
121 * and {@link #rollback} more readable when used as an
122 * argument to those methods.
123 * Use <code>commit(Table.ALL)</code> rather than
124 * <code>commit(true)</code>, for example.
125 */
126 public static final boolean ALL = true;
127
128 /**Described in the text on page 235*/
129
130 Table select(Selector where, String[] requestedColumns, Table[] other);
131
132 /** A more efficient version of
133 * <code>select(where, requestedColumns, null);</code>
134 */
135 Table select(Selector where, String[] requestedColumns );
136
137 /** A more efficient version of <code>select(where, null, null);</code>
138 */
139 Table select(Selector where);
140
141 /** A convenience method that translates Collections to arrays, then
142 * calls {@link #select(Selector,String[],Table[])};
143 * @param requestedColumns a collection of String objects
144 * representing the desired columns.
145 * @param other a collection of additional Table objects to join to
146 * the current one for the purposes of this SELECT
147 * operation.
148 */
149 Table select(Selector where, Collection requestedColumns,
150 Collection other);
151
152 /** Convenience method, translates Collection to String array, then
153 * calls String-array version.
154 */
155 Table select(Selector where, Collection requestedColumns );
156
157 /** Return an iterator across the rows of the current table.
158 */
159 Cursor rows();
160
161 /** Build a representation of the Table using the
162 * specified Exporter. Create an object from an
163 * {@link Table.Importer} using the constructor with an
164 * {@link Table.Importer} argument. The table's
165 * "dirty" status is cleared (set false) on an export.
166 * @see #isDirty
167 */
168 void export( Table.Exporter importer ) throws IOException;
169
170 /*******************************************************************
171 * Used for exporting tables in various formats. Note that
172 * I can add methods to this interface if the representation
173 * requires it without impacting the Table's clients at all.
174 */
175 public interface Exporter
176 { public void startTable() throws IOException;
177 public void storeMetadata(
178 String tableName,
179 int width,
180 int height,
181 Iterator columnNames ) throws IOException;
182 public void storeRow(Iterator data) throws IOException;
183 public void endTable() throws IOException;
184 }
185
186 /*******************************************************************
187 * Used for importing tables in various formats.
188 * Methods are called in the following order:
189 * <ul>
190 * <li><code>start()</code></li>
191 * <li><code>loadTableName()</code></li>
192 * <li><code>loadWidth()</code></li>
193 * <li><code>loadColumnNames()</code></li>
194 * <li><code>loadRow()<code> (multiple times)</li>
195 * <li><code>done()</code></li>
196 * </ul>
197 */
198 public interface Importer
199 { void startTable() throws IOException;
200 String loadTableName() throws IOException;
201 int loadWidth() throws IOException;
202 Iterator loadColumnNames() throws IOException;
203 Iterator loadRow() throws IOException;
204 void endTable() throws IOException;
205 }
206 }
The Bridge Pattern
The Table interface is part of the Bridge design pattern mentioned earlier. A Bridge separates subsystems from each other so that they can change independently. Unlike Facade (which you looked at in the previous chapter in the context of the menuing subsystem), a Bridge provides complete isolation between subsystems. Code on one side of the Bridge has no idea what’s on the other side. (Facade, you’ll remember, doesn’t hide the subsystem—it just simplifies access to it.)
I’ll explain Bridge by presenting several examples, shown in Figure 4-4. The top section shows Java’s older AWT subsystem, and though you probably won’t be familiar with it unless you’re doing something such as PalmPilot programming, the architecture is a nice reification of the classic Gang-of-Four Bridge. The “client” classes (the ones that use java.awt.Window) can change completely without impacting the implementation of AWT. By the same token, the classes on the other side of the bridge (various “peer” classes that interface to the operating system’s GUI layer) can change without impacting the client classes. AWT leverages this ability to change in order to make the GUI model platform independent, so your PalmPilot application’s UI may well run on Windows, Linux, or some other operating system without modification.
The peer classes (the classes that implement the xxxPeer interfaces) are created at runtime using an Abstract Factory called java.awt.Toolkit. (Abstract Factory was discussed in Chapter 2, but to refresh your memory, a Collection is an Abstract Factory of Iterator objects. A Concrete Factory [ArrayList, for example] implements the Abstract-Factory interface to produce a Concrete Products [some implementation of Iterator whose class is unknown]. Other implementations of Collection may [or may not—you don’t know or care] produce different Concrete Products that implement the same Iterator interface in a way that makes sense for that particular data structure.) Toolkit is an abstract class used as an interface. (It has to be abstract because it needs to contain a static method.) The Singleton pattern is used to fetch a concrete instance of the Toolkit “interface.” That is, the Toolkit.getDefaultToolkit() method determines the operating environment at runtime (typically, by looking at a system property) and then instantiates a Toolkit implementer appropriate for that environment. I’ve shown the Windows and Motif variants in Figure 4-4, but a Toolkit implementation must exist for every environment on which a particular JVM runs.
The concrete Toolkit object acts as an Abstract Factory of “peer” objects. The peers are system-dependent implementers of various graphical objects. I’ve shown one such peer (the WindowPeer, which implements an unbordered stand-alone window) in Figure 4-4, but 27 peer interfaces exist and create the whole panoply of graphical objects (ButtonPeer, CanvasPeer, CheckboxPeer, and so on). For each of these interfaces, a system-dependent implementation exists that’s manufactured by the system-dependent concrete Toolkit in response to one of its createxxx(...) methods. For example, the Windows Toolkit (sun.awt.windows.WToolkit) will produce a Windows-specific peer (sun.awt.windows.WWindowPeer) when you call Toolkit. createWindow(). The Motif Toolkit (sun.awt.windows.MToolkit) will produce a Motif-specific peer (sun.awt.motif.MWindowPeer) when you call Toolkit.createWindow().
The Abstract Factory I’ve just described is used in concert with the Bridge pattern to isolate the mechanics of switching subsystems. The java.awt.Window class understands Toolkits and peers. When you create a Window, that object creates the appropriate peer. As long as you program in terms of Window objects, you don’t need to know that the peer exists. Consequently, everything on the other side of the bridge (all the peers) can change radically, even at runtime, without your program’s side of the bridge being impacted. By the same token, none of the peer implementations knows or cares how they’re used. Consequently, your program can change radically without the peer implementations knowing or caring.
It is commonplace for Abstract Factory and Bridge to be used together in the way I just described. You will rarely see a Bridge without an Abstract Factory helping to create the Concrete Implementor objects (for example, WWindowPeer and MWindowPeer).
Another example of Singleton, Abstract Factory, and Bridge working together includes the java.text.NumberFormat class, which is used to parse and print numbers in a Locale-specific way. When you call NumberFormat.getInstance(), you’re using Singleton to access an Abstract Factory that creates some subclass of NumberFormat that understands the current Locale. The NumberFormat “interface” serves as a Bridge that isolates your program from the rather complicated subsystem that deals with Locale-specific formatting. That subsystem could change (to support new Locales, for example), and your code wouldn’t know it.
Now let’s apply the notion of Bridge to the current problem. Referring again to Figure 4-4, the Table uses an Abstract-Factory/Bridge strategy much like AWT and NumberFormat, but things are simplified a bit. I’ll cover the Abstract-Factory issues in the next section, but the figure shows a small bridge consisting of the Database class (the core of the SQL engine, which I’ll describe shortly) and the Table interface. If you program in terms of Database objects, you don’t know or care that the Table exists. It’s possible, then, to completely change the underlying table implementation—even at runtime—without your code caring about the change. For example, at some future date I may introduce several kinds of Tables that store the underlying data in a way that’s particularly efficient for a particular data set. The Bridge, however, isolates your code from that change.
I’ll come back to Bridge (and to the third part of Figure 4-4) later in this chapter.
Creating a Table, Abstract Factory
Now let’s look at the Abstract-Factory component of the Table creation process. The following code creates a Table named people whose rows have three columns named last, first, and addrID (for address identifier—not a particularly readable name, but short column names are good because they improve search times):
Table people = TableFactory.create(
"people", new String[]{"last", "first", "addrId" } );
You can also create a table from data stored on the disk in comma-separated-value (CSV) format. The following call reads a table called address (which must be stored in a file named address) from the specified directory:
Table address = tableFactory.load( "address.csv", "c:/data/directory" );
The data is stored in CSV format, where every row of the table is on its own line and commas separate the column values from each other. Here’s a short sample:
address
addrId, street, city, state, zip
0, 12 MyStreet, Berkeley, CA, 99998
1, 34 Quarry Ln., Bedrock, AZ, 00000
The first line is the table name, the second line names the columns, and the remaining lines specify the rows.
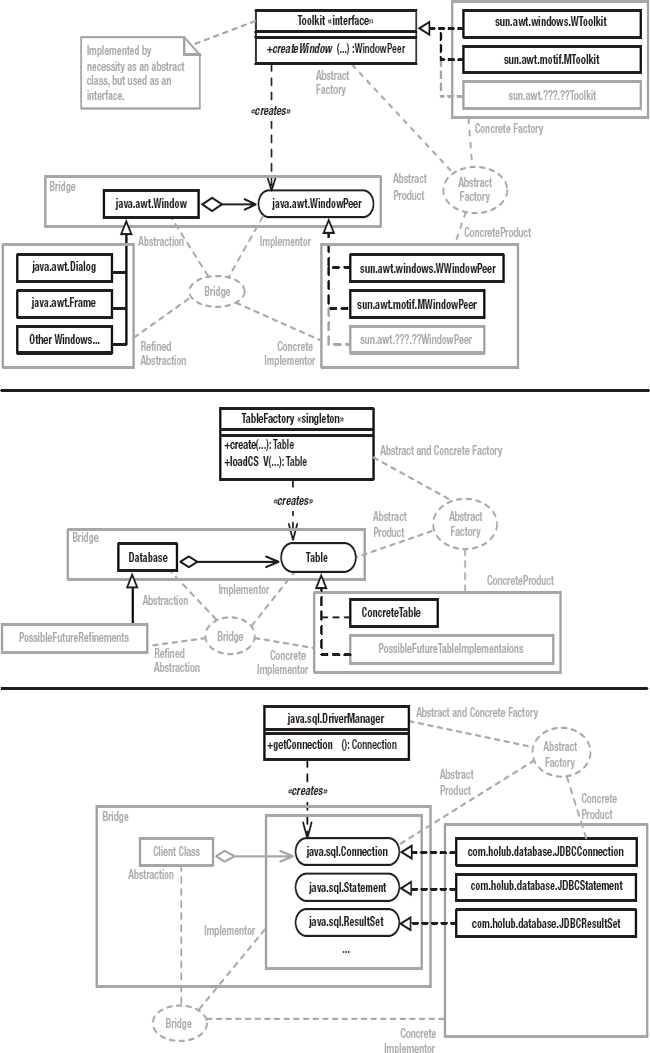
Figure 4-4. The Bridge Pattern in AWT, com.holub.database, and JDBC
The TableFactory demonstrates the reification of Abstract Factory that I’ve used most often. Unlike the classic reification (as embodied by Collection and Iterator), there’s no interface in the Abstract Factory role of which Collection is an example. (More precisely, the TableFactory class serves as its own interface, as if Collection were an actual class, not an interface). You just have no need to complicate the code with a separate interface. What makes this reification an Abstract Factory is that it satisfies the same “intent” as a classic Abstract Factory: It provides a means of “creating families of related or dependant objects without specifying their concrete classes,” to quote the Gang of Four. TableFactory is another example of how reifications of a particular pattern can differ in form.
This particular Factory creates Table implementers, of which only one is currently present—the ConcreteTable, which I’ll discuss in subsequent sections. This particular reification of Abstract Factory is in some ways just the skeleton of a pattern, put in place primarily so that I can provide alternative Table implementations in the future. That is, this particular Factory isn’t producing a “family” of objects right now but is put into the code to make it easy to increase the size of the “family” to some number greater than 1 if the need arises. Putting a small factory into the code up front has virtually no cost but provides for a lot of down-the-line flexibility, so the potential payback is high. On the other hand, the Factory does add a small amount of extra complexity to the code.
The TableFactory source code is in Listing 4-2. For the most part, its methods do nothing but hide calls to new. The load()method (Listing 4-2, line 57) is interesting in that the method can potentially load a table from various file formats on the disk. I’ll explain the code in the load() method in greater depth in the next section, but let’s look now at what the method does rather than how it does it.
The load() method is passed a filename and location, and it creates a Table from the data it finds in that file. Right now, it examines the filename extension to determine the data format, but it could just as easily examine the contents of the file. It’s a trivial matter to make it load from an XML file rather than a CSV file, for example. It could even be passed a .sql file and load the Table by using the SQL. In other words, the method potentially isolates you completely from the underlying data format. The file read by the load() method may also specify a particular type of Table that could represent the data in a more efficient way than the current Table implementation, and the Factory could produce that specific Concrete Product. Since load() hides the complexity of creating a table, you can also think of TableFactory as a simple Facade |reification.
Listing 4-2. TableFactory.java
1 package com.holub.database;
2
3 import java.io.*;
4
5 public class TableFactory
6 {
7 /** Create an empty table.
8 * @param name the table name
9 * @param columns names of all the columns
10 * @return the table
11 */
12 public static Table create( String name, String[] columns )
13 { return new ConcreteTable( name, columns );
14 }
15
16 /** Create a table from information provided by a
17 * {@link Table.Importer} object.
18 */
19 public static Table create( Table.Importer importer )
20 throws IOException
21 { return new ConcreteTable( importer );
22 }
23
24 /** This convenience method is equivalent to
25 * <code>load(name, new File(".") );</code>
26 *
27 * @see #load(String,File)
28 */
29 public static Table load( String name ) throws IOException
30 { return load( name, new File(".") );
31 }
32
33 /** This convenience method is equivalent to
34 * <code>load(name, new File(location) );</code>
35 *
36 * @see #load(String,File)
37 */
38 public static Table load( String name, String location )
39 throws IOException
40 { return load( name, new File(location) );
41 }
42
43 /* Create a table from some form stored on the disk.
44 *
45 * <p>At present, the filename extension is used to determine
46 * the data format, and only a comma-separated-value file
47 * is recognized (the filename must end in .csv).
48 *
49 * @param the filename. The table name is the string to the
50 * left of the extension. For example, if the file
51 * is "foo.csv," then the table name is "foo."
52 * @param the directory within which the file is found.
53 *
54 * @throws java.io.IOException if the filename extension is not
55 * recognized.
56 */
57 public static Table load( String name, File directory )
58 throws IOException
59 {
60 if( !(name.endsWith( ".csv" ) || name.endsWith( ".CSV" )) )
61 throw new java.io.IOException(
62 "Filename (" +name+ ") does not end in "
63 +"supported extension (.csv)" );
64
65 Reader in = new FileReader( new File( directory, name ));
66 Table loaded = new ConcreteTable( new CSVImporter( in ));
67 in.close();
68 return loaded;
69 }
70 }
Creating and Saving a Table: Passive Iterators and Builder
Now let’s move onto the ConcreteTable implementation of Table. You can bring tables into existence in two ways. A run-of-the-mill constructor is passed a table name and an array of strings that define the column names. Here’s an example:
Table t = new ConcreteTable( "table-name",
new String[]{ "column1", "column2" } );
The sources for ConcreteTable up to and including this constructor definition are in Listing 4-3. The ConcreteTable represents the table as a list of arrays of Object (rowSet, line 32). The columnNames array (line 33) is an array of Strings that both define the column names and organize the Object arrays that comprise the rows. A one-to-one relationship exists between the index of a column name in the columnNames table and the index of the associated data in one of the rowSet arrays. If you find the column name X at columnNames[i], then you can find the associated data for column X at the ith position in one of these Object arrays.
The private indexOf method on line 49 is used internally to do this column-name-to-index mapping. It’s passed a column name and returns the associated index.
Note that everything is 0 indexed, which is intuitive to a Java programmer. Unfortunately, SQL is 1 indexed, so you have to be careful if you implement any of the SQL methods that specify column data using indexes. I’ve taken the coward’s way out and have not implemented any of the index-based JDBC methods. Be careful of off-by-one errors if you add these methods to my implementation.
Of the other fields at the top of the class definition, tableName does the obvious, and isDirty is true if the table has been modified. (I use this field to avoid unnecessary writes to disk). I’ll discuss transactionStack soon, when I discuss transaction processing.
Listing 4-3. ConcreteTable.java: Simple Table Creation
1 package com.holub.database;
2
3 import java.io.*;
4 import java.util.*;
5 import com.holub.tools.ArrayIterator;
6
7 /** The concrete class that implements the Table "interface."
8 * This class is not thread safe.
9 * Create instances of this class using {@link TableFactory} class,
10 * not <code>new</code>.
11 *
12 * <p>Note that a ConcreteTable is both serializable and "Cloneable,"
13 * so you can easily store it onto the disk in binary form
14 * or make a copy of it. Clone implements a shallow copy, however,
15 * so it can be used to implement a rollback of an insert or delete,
16 * but not an update.
17 */
18
19 /*package*/ class ConcreteTable implements Table
20 {
21 // Supporting clone() complicates the following declarations. In
22 // particular, the fields can't be final because they're modified
23 // in the clone() method. Also, the rows field has to be declared
24 // as a LinkedList (rather than a List) because Cloneable is made
25 // public at the LinkedList level. If you declare it as a List,
26 // you'll get an error message because clone()—for reasons that
27 // are mysterious to me—is declared protected in Object.
28 //
29 // Be sure to change the clone() method if you modify anything about
30 // any of these fields.
31
32 private LinkedList rowSet = new LinkedList();
33 private String[] columnNames;
34 private String tableName;
35
36 private transient boolean isDirty = false;
37 private transient LinkedList transactionStack = new LinkedList();
38
39 //----------------------------------------------------------------------
40 public ConcreteTable( String tableName, String[] columnNames )
41 { this.tableName = tableName;
42 this.columnNames = (String[]) columnNames.clone();
43 }
44
45 //----------------------------------------------------------------------
46 // Return the index of the named column. Throw an
47 // IndexOutOfBoundsException if the column doesn't exist.
48 //
49 private int indexOf( String columnName )
50 { for( int i = 0; i < columnNames.length; ++i )
51 if( columnNames[i].equals( columnName ) )
52 return i;
53
54 throw new IndexOutOfBoundsException(
55 "Column ("+columnName+") doesn't exist in " + tableName );
56 }
The second constructor (shown in Listing 4-4) is more interesting. Here, the constructor is passed an object that implements the Table.Importer interface, defined on line 198 of Listing 4-1. The constructor uses the Importer to import data into an empty table. The source code is in Listing 4-4 (p. 196). As you can see, the constructor just calls the various methods of the Importer in sequence to get table metadata (the table name, column names, and so forth). It then calls loadRow() multiple times to load the rows.
Each call to loadRow() returns a standard java.util.Iterator, which iterates across the data representing a single row in left-to-right order. By using an iterator (rather than an array), I’ve isolated myself completely from the way that the row data is stored internally. The Iterator returned from the Importer could even synthesize the data internally.
The load process finishes up with a call to done().
Listing 4-4. ConcreteTable.java Continued: Importing and Exporting
57 //----------------------------------------------------------------------
58 public ConcreteTable( Table.Importer importer ) throws IOException
59 { importer.startTable();
60
61 tableName = importer.loadTableName();
62 int width = importer.loadWidth();
63 Iterator columns = importer.loadColumnNames();
64
65 this.columnNames = new String[ width ];
66 for(int i = 0; columns.hasNext() ;)
67 columnNames[i++] = (String) columns.next();
68
69 while( (columns = importer.loadRow()) != null )
70 { Object[] current = new Object[width];
71 for(int i = 0; columns.hasNext() ;)
72 current[i++] = columns.next();
73 this.insert( current );
74 }
75 importer.endTable();
76 }
77 //----------------------------------------------------------------------
78 public void export( Table.Exporter exporter ) throws IOException
79 { exporter.startTable();
80 exporter.storeMetadata( tableName,
81 columnNames.length,
82 rowSet.size(),
83 new ArrayIterator(columnNames) );
84
85 for( Iterator i = rowSet.iterator(); i.hasNext(); )
86 exporter.storeRow( new ArrayIterator((Object[]) i.next()) );
87
88 exporter.endTable();
89 isDirty = false;
90 }
The CSVImporter class (Listing 4-5) demonstrates how to build an Importer. The following code shows a simplified version of how the TableFactory, discussed earlier, uses the CSVImporter to load a CSV file. The importer is created in the constructor call on the second line of the method. It’s passed a Reader to use for input. The ConcreteTable constructor then calls the various methods of the CSVImporter to initialize the table.
public static Table loadCSV( String name, File directory ) throws IOException
{
Reader in = new FileReader( new File( directory, name ));
Table loaded = new ConcreteTable( new CSVImporter( in ));
in.close();
return loaded;
}
As you can see in Listing 4-5, there’s not that much to building an importer. The startTable() method reads the table name first, and then it reads the metadata (the column names) from the second line and splits them into an array of String objects. The loadRow() method then reads the rows and then splits them. I’ll discuss the ArrayIterator class called on line 30 in a moment.
Listing 4-5. CSVImporter.java
1 package com.holub.database;
2
3 import com.holub.tools.ArrayIterator;
4
5 import java.io.*;
6 import java.util.*;
7
8 public class CSVImporter implements Table.Importer
9 { private BufferedReader in; // null once end-of-file reached
10 private String[] columnNames;
11 private String tableName;
12
13 public CSVImporter( Reader in )
14 { this.in = in instanceof BufferedReader
15 ? (BufferedReader)in
16 : new BufferedReader(in)
17 ;
18 }
19 public void startTable() throws IOException
20 { tableName = in.readLine().trim();
21 columnNames = in.readLine().split("\s*,\s*");
22 }
23 public String loadTableName() throws IOException
24 { return tableName;
25 }
26 public int loadWidth() throws IOException
27 { return columnNames.length;
28 }
29 public Iterator loadColumnNames() throws IOException
30 { return new ArrayIterator(columnNames);
31 }
32
33 public Iterator loadRow() throws IOException
34 { Iterator row = null;
35 if( in != null )
36 { String line = in.readLine();
37 if( line == null )
38 in = null;
39 else
40 row = new ArrayIterator( line.split("\s*,\s*"));
41 }
42 return row;
43 }
44
45 public void endTable() throws IOException
46 }
A more interesting importer is in Listing 4-6. The PeopleImporter loads a Table using the interactive UI pictured in Figure 4-5. You create a table that initializes itself interactively as follows:
Table t = TableFactory.create( new PeopleImporter() );
System.out.println( t.toString() );
System.exit(0);
My main intent is to illustrate the techniques used, so this class isn’t really production quality, but it demonstrates an effective way to separate a UI from the “business object.” I can completely change the structure of the user interface by changing the definition of the PeopleImporter. The Table implementation is completely unaffected by changes to the UI. In fact, the Table doesn’t even know that it’s being initialized from an interactive user interface.
Looking at the implementation, the getRowDataFromUser() method (Listing 4-6, line 46) creates the user interface, and the button handlers at the bottom of the method transfer the row data from the text-input fields to the rows LinkedList (declared on line 19). The balance of the class works much like the CSVImporter, but it transfers data from the rows array to the Table.

Figure 4-5. The PeopleImporter user interface
Listing 4-6. PeopleImporter.java
1 import com.holub.tools.ArrayIterator;
2 import com.holub.database.Table;
3 import com.holub.database.TableFactory;
4
5 import java.io.*;
6 import java.util.*;
7 import javax.swing.*;
8 import java.awt.*;
9 import java.awt.event.*;
10
11 /** A very simplistic demonstration of using Builder for
12 * interactive input. Doesn't do validation, error detection,
13 * etc. Also, I read all the user data, then import it to the
14 * table, rather than reading the UI on a per-row basis.
15 */
16
17 public class PeopleImporter implements Table.Importer
18 {
19 private LinkedList rows = new LinkedList();
20
21 public void startTable() throws IOException
22 { getRowDataFromUser();
23 }
24 public String loadTableName() throws IOException
25 { return "people";
26 }
27 public int loadWidth() throws IOException
28 { return 3;
29 }
30 public Iterator loadColumnNames() throws IOException
31 { return new ArrayIterator(
32 new String[]{"first", "last", "addrID"});
33 }
34 public Iterator loadRow() throws IOException
35 { try
36 { String[] row = (String[])( rows.removeFirst() );
37 return new ArrayIterator( row );
38 }
39 catch( NoSuchElementException e )
40 { return null;
41 }
42 }
43
44 public void endTable() throws IOException
45
46 private void getRowDataFromUser()
47 {
48 final JTextField first = new JTextField(" ");
49 final JTextField last = new JTextField(" ");
50 final JDialog ui = new JDialog();
51
52 ui.setModal( true );
53 ui.getContentPane().setLayout( new GridLayout(3,1) );
54
55 JPanel panel = new JPanel();
56
57 panel.setLayout( new FlowLayout() );
58 panel.add( new JLabel("First Name:") );
59 panel.add( first );
60 ui.getContentPane().add( panel );
61
62 panel = new JPanel();
63
64 panel.setLayout( new FlowLayout() );
65 panel.add( new JLabel("Last Name:") );
66 panel.add( last );
67 ui.getContentPane().add( panel );
68
69 JButton done = new JButton("Done");
70 JButton next = new JButton("Next");
71 panel = new JPanel();
72
73 done.addActionListener
74 ( new ActionListener()
75 { public void actionPerformed( ActionEvent e )
76 { rows.add
77 ( new String[]{ first.getText().trim(),
78 last.getText().trim() }
79 );
80 ui.dispose();
81 }
82 }
83 );
84
85 next.addActionListener
86 ( new ActionListener()
87 { public void actionPerformed( ActionEvent e )
88 { rows.add
89 ( new String[]{ first.getText().trim(),
90 last.getText().trim() }
91 );
92 first.setText("");
93 last.setText("");
94 }
95 }
96 );
97 panel.add( next );
98 panel.add( done );
99 ui.getContentPane().add( panel );
100
101 ui.pack();
102 ui.show();
103 }
104
105 public static class Test
106 { public static void main( String[] args ) throws IOException
107 { Table t = TableFactory.create( new PeopleImporter() );
108 System.out.println( t.toString() );
109 System.exit(0);
110 }
111 }
112 }
The other method of interest in Listing 4-4 is the export() method, which exports the table data similarly to the way the constructor imports the data. The export() method takes a Table.Exporter argument and sends the Exporter the metadata and the rows. (The Exporter interface is also an inner class of Table, defined on line 175 of Listing 4-1.)
As with the Importer constructor, the export() method first asks the Exporter to store the table metadata, and then it passes the Exporter the rows one at a time. As was the case with the Importer constructor, the export() method passes the Exporter a java.util.Iterator across the columns of a row rather than passing an Object array. This way, the Table implementor is not tied into a particular representation of the underlying data. (The ConcreteTable, for example, isn’t giving away the fact that it stores rows as Object arrays.)
The CSVExporter class in Listing 4-7 demonstrates how to build an Exporter. It’s passed a Writer and just writes the table data to that stream.
Listing 4-7. CSVExporter.java
1 package com.holub.database;
2
3 import java.io.*;
4 import java.util.*;
5
6 public class CSVExporter implements Table.Exporter
7 { private final Writer out;
8 private int width;
9
10 public CSVExporter( Writer out )
11 { this.out = out;
12 }
13
14 public void storeMetadata( String tableName,
15 int width,
16 int height,
17 Iterator columnNames ) throws IOException
18
19 { this.width = width;
20 out.write(tableName == null ? "<anonymous>" : tableName );
21 out.write("
");
22 storeRow( columnNames ); // comma-separated list of column IDs
23 }
24
25 public void storeRow( Iterator data ) throws IOException
26 { int i = width;
27 while( data.hasNext() )
28 { Object datum = data.next();
29
30 // Null columns are represented by an empty field
31 // (two commas in a row). There's nothing to write
32 // if the column data is null.
33 if( datum != null )
34 out.write( datum.toString() );
35
36 if( --i > 0 )
37 out.write(", ");
38 }
39 out.write("
");
40 }
41
42 public void startTable() throws IOException {/*nothing to do*/}
43 public void endTable() throws IOException {/*nothing to do*/}
44 }
A more interesting example of an exporter is the JTableExporter in Listing 4-8, which builds the UI in Figure 4-6. The code that created the UI in the Test class is at the bottom of Listing 4-8 (line 45), but here’s the essential stuff:
Table people = ...;
JFrame frame = ...;
JTableExporter tableBuilder = new JTableExporter();
people.export( tableBuilder );
frame.getContentPane().add(
new JScrollPane( tableBuilder.getJTable() ) );
You pass the Table’s export() method a JTableExporter() rather than a CSVExporter(). The JTableExporter() creates a JTable and populates it from the table data. You then extract the JTable from the exporter with the getJTable() call. (This “get” method is not really an accessor since the whole point of the JTableExporter is to create a JTable—I’m not giving away any surprising implementation details here.)
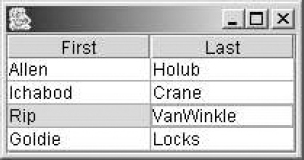
Figure 4-6. The JTableExporter user interface
Listing 4-8. JTableExporter.java
1 package com.holub.database;
2
3 import java.io.*;
4 import java.util.*;
5 import javax.swing.*;
6
7 public class JTableExporter implements Table.Exporter
8 {
9 private String[] columnHeads;
10 private Object[][] contents;
11 private int rowIndex = 0;
12
13 public void startTable() throws IOException { rowIndex = 0; }
14
15 public void storeMetadata( String tableName,
16 int width,
17 int height,
18 Iterator columnNames ) throws IOException
19 {
20 contents = new Object[height][width];
21 columnHeads = new String[width];
22
23 int columnIndex = 0;
24 while( columnNames.hasNext() )
25 columnHeads[columnIndex++] = columnNames.next().toString();
26 }
27
28 public void storeRow( Iterator data ) throws IOException
29 { int columnIndex = 0;
30 while( data.hasNext() )
31 contents[rowIndex][columnIndex++] = data.next();
32 ++rowIndex;
33 }
34
35 public void endTable() throws IOException {/*nothing to do*/}
36
37 /** Return the Concrete Product of this builder—a JTable
38 * initialized with the table data.
39 */
40 public JTable getJTable()
41 { return new JTable( contents, columnHeads );
42 }
43
44 public static class Test
45 { public static void main( String[] args ) throws IOException
46 {
47 Table people = TableFactory.create( "people",
48 new String[]{ "First", "Last" } );
49 people.insert( new String[]{ "Allen", "Holub" } );
50 people.insert( new String[]{ "Ichabod", "Crane" } );
51 people.insert( new String[]{ "Rip", "VanWinkle" } );
52 people.insert( new String[]{ "Goldie", "Locks" } );
53
54 javax.swing.JFrame frame = new javax.swing.JFrame();
55 frame.setDefaultCloseOperation( JFrame.EXIT_ON_CLOSE );
56
57 JTableExporter tableBuilder = new JTableExporter();
58 people.export( tableBuilder );
59
60 frame.getContentPane().add(
61 new JScrollPane( tableBuilder.getJTable() ) );
62 frame.pack();
63 frame.show();
64 }
65 }
66 }
The import/export code you’ve just been looking at is an example of the Builder design pattern. The basic idea of Builder is separate the code that creates an object from the object’s internal representation so that the same construction process can be used to create different sorts of representations. Put another way, Builder separates a “business object” (an object that models some domain-level abstraction) from implementation-specific details such as how to display that business object on the screen or put it in a database. Using Builder, a domain-level object can create multiple representations of itself without having to be rewritten. The business object has the role of Director in the pattern, and objects in the role of Concrete-Builder (which implement the Builder interface) create the representation. In the current example, ConcreteTable is the Director, Table.Exporter is the Builder, and CSVExporter is the Concrete Builder.
To my mind Table.Importer is also a Builder (of Table objects) and CSVImporter is the matching Concrete Builder, though this way of looking at things is rather backward since I’m turning multiple representations into a single object rather than the other way around. The implementation is certainly similar, however.
As you saw in the PeopleImporter and JTableExporter classes, Builder nicely solves the object-oriented UI conundrum mentioned way back in Chapter 2. If an object can’t expose implementation details (so you can’t have getter and setter methods), then how do you create a user interface, particularly if an object has to represent itself in different ways to different subsystems? An object could have a method that returns a JComponent representation of itself or of some attribute of itself, but what if you’re building a server-side UI and you need an HTML representation? What if you’re talking to a database and you need an XML or SQL representation? Adding a billion methods to the class, one for each possible representation (getXML(), getJComponent(), getSQL(), getHTML(), and so on) isn’t a viable solution—it’s too much of a maintenance hassle to go into the class definition every time a new business requirement needs a new representation..
As you just saw, however, a Builder is perfectly able to accommodate disparate representations, and adding a new Builder doesn’t require any modifications to the domain-level object at all. Any Table can be represented as a CSV list and also as a JComponent, all without having to modify the Table implementation. In fact, Builder provides a nice way to concentrate all the UI logic in a single place (the Concrete Builder) and to separate the UI logic from the “business logic” (all of which is in the Director).
Using Builder lets me support representations that don’t need to exist when the program is first written. Adding XMLImporter and XMLExporter implementations of Table.Importer and Table.Exporter is an easy matter. Once I create these new classes, a Table can now store itself in XML format and load itself from an XML file. Moreover, I’ve added XML export/import to every Table implementation (all of which have to be Directors), not just ConcreteTable.
The only difficulty with Builder is in the design of the Builder interface itself. This interface has to have methods that accommodate all displayable state information. Consequently, a tight coupling relationship exists between the objects in the Director and Builder roles, simply because the Builder interface has to have methods that are “tuned” for use by the Director. It’s possible that the Director could change in such a way that you would have to modify the Builder interface (and all the Concrete Builders, too) to accommodate the change. This problem is really the getter problem I discussed in Chapter 1. Builder, however, restricts the scope of the problem to a small number of classes (the Concrete Builders). I’d have a much worse situation if I were to put get/set methods in the Director (the Table). Unknown coupling relationships with random classes would be scattered all over the program. In any event, I haven’t often needed to make those sorts of changes in practice.
Populating the Table
The next order of business is to put some data into the table. Several methods are provided for this purpose. The simplest method, shown below, inserts a new row into the table. It’s up to you to assure that the order of array elements matches the order of columns specified when the table was created.
people.insert( new Object[]{ "Holub", "Allen", "1" } );
The foregoing method is delicate—it depends on a particular column ordering to work correctly. It’s too easy to get the column ordering wrong. A second overload of insert(...) solves the problem by requiring both column names and their contents. The columns don’t have to be in declaration order, but the two arrays much match. When firstArgument[i] specifies a column, secondArgument[i] must specify that column’s contents. Here’s an example:
people.insert( new String[]{ "addrId", "first", "last" },
new Object[]{ "1", "Fred", "Flintstone"} );
Also, Collection versions of both methods exist. The following code creates a row from the Collection elements:
List rowData = new ArrayList();
rowData.add("Flintstone");
rowData.add("Wilma");
rowData.add("1")
people.insert(rowData);
The following codes does the same thing, but with rows specified in an arbitrary order:
List columnNames = new ArrayList();
columnNames.add("addrId");
columnNames.add("first");
columnNames.add("last");
List rowData = new ArrayList();
rowData.add("1")
rowData.add("Pebbles");
rowData.add("Flintstone");
people.insert( columnNames, rowData );
This last method seems to be of dubious value, but it turns out that a two-collection variant is quite useful when building the SQL interpreter, as you’ll see later in the chapter.
Finally, I’ve provided a Map version where the keys are the column names and the values are the contents.
The source code for the methods that insert rows is in Listing 4-9. The overloads that don’t take column-name arguments just add a new object array to the rowSet. The other methods go through the column names in sequence, determine the index in the object array associated with that column (using indexOf(...)), and put the appropriate data into the appropriate element of the Object array that represents the row.
The actual inserting of the object array into the list representing the table is done by the doInsert() method (Listing 4-9, line 148). I’ll come back to the registerInsert(...) method that’s called at the top of doInsert() in a moment, when I talk about the undo system. For now, note that all insert operations mark the table as “dirty.” This boolean is initially false; it’s marked true by all operations that modify the table, and it’s reset to false by the export() method discussed earlier. A client class can determine the “dirty” state of the table by calling someTable.isDirty(). The SQL-engine layer uses this mechanism to avoid flushing to disk tables that have been read, but not modified, when you issue a SQL DUMP request.
The isDirty() method, by the way, is not a “get” method of the sort I was railing against in Chapter 1, even though it’s implemented in the simplest possible way to return a private field:
public boolean isDirty(){ return isDirty; }
The fact that the “dirty” state is stored in a boolean, and that isDirty() returns that boolean, is just an implementation convenience. I’m not exposing any implementation details (there’s no way that the client can determine how the table decides whether it’s dirty), and since there’s no setDirty(), there’s no way for the “dirty” state to be corrupted from outside. I can change the implementation and represent the “dirty” state in some other way without impacting the interface or the classes that use the interface.
If you find this explanation confusing, think about the design process. I decided at design time that a “dirty” state was necessary, so I provided an isDirty() method in the interface. Later, I added the simplest implementation possible. This way of working is fundamentally different from starting with a isDirty field in the class and then adding getDirty() and setDirty() as a matter of course. It would be a serious error for a setDirty() method to exist because, where that method present, a client object could break a Table object by making the Table think it didn’t need to be flushed to disk when it actually did; setDirty() has no valid use.
Listing 4-9. ConcreteTable.java Continued: Inserting Rows
91 //----------------------------------------------------------------------
92 // Inserting
93 //
94 public int insert( String[] intoTheseColumns, Object[] values )
95 {
96 assert( intoTheseColumns.length == values.length )
97 :"There must be exactly one value for "
98 +"each specified column" ;
99
100 Object[] newRow = new Object[ width() ];
101
102 for( int i = 0; i < intoTheseColumns.length; ++i )
103 newRow[ indexOf(intoTheseColumns[i]) ] = values[i];
104
105 doInsert( newRow );
106 return 1;
107 }
108 //----------------------------------------------------------------------
109 public int insert( Collection intoTheseColumns, Collection values )
110 { assert( intoTheseColumns.size() == values.size() )
111 :"There must be exactly one value for "
112 +"each specified column" ;
113
114 Object[] newRow = new Object[ width() ];
115
116 Iterator v = values.iterator();
117 Iterator c = intoTheseColumns.iterator();
118 while( c.hasNext() && v.hasNext() )
119 newRow[ indexOf((String)c.next()) ] = v.next();
120
121 doInsert( newRow );
122 return 1;
123 }
124 //----------------------------------------------------------------------
125 public int insert( Map row )
126 { // A map is considered to be "ordered," with the order defined
127 // as the order in which an iterator across a "view" returns
128 // values. My reading of this statement is that the iterator
129 // across the keySet() visits keys in the same order as the
130 // iterator across the values() visits the values.
131
132 return insert ( row.keySet(), row.values() );
133 }
134 //----------------------------------------------------------------------
135 public int insert( Object[] values )
136 { assert values.length == width()
137 : "Values-array length (" + values.length + ") "
138 + "is not the same as table width (" + width() +")";
139
140 doInsert( (Object[]) values.clone() );
141 return 1;
142 }
143 //----------------------------------------------------------------------
144 public int insert( Collection values )
145 { return insert( values.toArray() );
146 }
147 //----------------------------------------------------------------------
148 private void doInsert( Object[] newRow )
149 {
150 rowSet.add( newRow );
151 registerInsert( newRow );
152 isDirty = true;
153 }
Examining a Table: The Iterator Pattern
Now that you’ve populated the table, you may want to examine it. The design pattern is Iterator, of which Java’s java.util.Iterator class is a familiar reification. The basic idea is that Iterator provides a way to access the elements of some aggregate object (some data structure) without exposing the internal representation of the aggregate. Java’s Iterator is just one way to accomplish this end. Any reification that you invent that lets a client object examine an aggregate one element at a time is a reification of Iterator.
Another simple reification of Iterator is the ArrayIterator class, shown in Listing 4-10. This class just wraps an array with a class that implements the java.util.Iterator interface, so you can pass arrays to methods that take Iterator arguments. The ArrayIterator is also an example of the Adapter design pattern that I’ll discuss later. ArrayIterator adapts an array object to implement an interface that an array doesn’t normally implement.
Listing 4-10. ArrayIterator.java
1 package com.holub.tools;
2
3 import java.util.*;
4
5 /** A simple implementation of java.util.Iterator that enumerates
6 * over arrays. Use this class when you want to isolate the
7 * data structures used to hold some collection by passing an
8 * Enumeration to some method.
9 * <!-- ... -->
10 * @author Allen I. Holub
11 */
12
13 public final class ArrayIterator implements Iterator
14 {
15 private int position = 0;
16 private final Object[] items;
17
18 public ArrayIterator(Object[] items){ this.items = items; }
19
20 public boolean hasNext()
21 { return ( position < items.length );
22 }
23
24 public Object next()
25 { if( position >= items.length )
26 throw new NoSuchElementException();
27 return items[ position++ ];
28 }
29
30 public void remove()
31 { throw new UnsupportedOperationException(
32 "ArrayIterator.remove()");
33 }
34
35 /** Not part of the Iterator interface, returns the data
36 * set in array form. Modifying the returned array will
37 * not affect the iteration at all.
38 */
39 public Object[] toArray()
40 { return (Object[]) items.clone();
41 }
42 }
Though most iterators don’t give you control over the order of traversal (the ArrayIterator just goes through the array elements in order), no requirement exists that an iterator visit nodes in any particular order. A ReverseArrayIterator could traverse from high to low indexes, for example. A tree class may have inOrderIterator(), preOrderIterator(), and postOrderIterator() methods, all of which returned objects that implemented the Iterator interface, but those objects would traverse the tree nodes “in order,” root first or depth first. You can define an iterator to handle whatever ordering you like—even random ordering is okay—as long as the ordering is specified in the class contract. Some iterators—such as the tree iterators just discussed—may make requirements on the underlying data structure, however.
Iterators can also modify the underlying data structure. Some of the java.util.Iterator implementers support a remove() operation that lets you remove the current element from the underlying data structure, for example.
Iterator is used all over the ConcreteTable, but most important, it’s used to examine or modify the rows. Listing 4-11 defines the Cursor interface used by the Table, but let’s look at how it’s used before looking at the code. The following method prints all the rows of the Table passed into the method as an argument:
public void print( Table someTable )
{
Cursor current = someTable.rows();
while( current.advance() )
{ for( java.util.Iterator columns = current.columns(); columns.hasNext(); )
System.out.print( (String) columns.next() + " " );
}
}
The Cursor knows about columns, so you could print only the first- and last-name fields of some Table as follows:
public void printFirstAndLast( Table someTable )
{
for(Cursor current = someTable.rows(); current.advance() ;)
{
System.out.print( current.column("first").toString() + " " +
current.column("last").toString() + " " );
}
}
A Cursor can also update the contents of a row or delete the current row. (You actually modify the underlying table when you use these methods.) The following code changes the names of all people named Smith to Jones. It also deletes all rows representing people named Doe:
public void modify( Table people )
{
for( Cursor current = people.rows(); current.advance() ;)
{ if( current.column("last").equals( "Smith" ) )
current.update("last", "Jones" );
else if( current.column("last").equals( "Doe" ) )
current.delete();
}
}
This functionality works properly with the transaction system that I’ll discuss later in the chapter, so you can roll back modifications if necessary.
Listing 4-11. Cursor.java
1 package com.holub.database;
2
3 import java.util.Iterator;
4 import java.util.NoSuchElementException;
5
6 /** The Cursor provides you with a way of examining the
7 * tables that you create and the tables that are created
8 * as a result of a select or join operation. This is
9 * an "updateable" cursor, so you can modify columns or
10 * delete rows via the cursor without problems. (Updates
11 * and deletes done through the cursor <em>are</em> handled
12 * properly with respect to the transactioning system, so
13 * they can be committed or rolled back.)
14 */
15
16 public interface Cursor
17 {
18 /** Metadata method required by JDBC wrapper--Return the name
19 * of the table across which we're iterating. I am deliberately
20 * not allow access to the Table itself, because this would
21 * allow uncontrolled modification of the table via the
22 * iterator.
23 * @return the name of the table or null if we're iterating
24 * across a nameless table like the one created by
25 * a select operation.
26 */
27 String tableName();
28
29 /** Advances to the next row, or if this iterator has never
30 * been used, advances to the first row.
31 * @throws NoSuchElementException if this call would advance
32 * past the last row.
33 * @return true if the iterator is positioned at a valid
34 * element after the advance.
35 */
36 boolean advance() throws NoSuchElementException;
37
38 /** Return the contents of the requested column of the current
39 * row. You should
40 * treat the cells accessed through this method as read only
41 * if you ever expect to use the table in a thread-safe
42 * environment. Modify the table using {@link Table#update}.
43 *
44 * @throws IndexOutOfBoundsException --- the requested column
45 * doesn't exist.
46 */
47
48 Object column( String columnName );
49
50 /** Return a java.util.Iterator across all the columns in
51 * the current row.
52 */
53 Iterator columns();
54
55 /** Return true if the iterator is traversing the
56 * indicated table.
57 */
58 boolean isTraversing( Table t );
59
60 /** Replace the value of the indicated column of the current
61 * row with the indicated new value.
62 *
63 * @throws IllegalArgumentException if the newValue is
64 * the same as the object that's being updated.
65 *
66 * @return the former contents of the now-modified cell.
67 */
68 Object update( String columnName, Object newValue );
69
70 /** Delete the row at the current cursor position.
71 */
72 void delete();
73 }
The comments in Listing 4-11 describe the remainder of the methods in the interface adequately, so let’s move onto the implementation in Listing 4-12.
Cursors are extracted from a Table using a classic Gang-of-Four Abstract Factory. The Table interface defines an Abstract Cursor Factory; the ConcreteTable, which implements that interface, is the Concrete Factory; the Cursor interface defines the Abstract Product; the Concrete Product an instance of the Results class on line 161 of Listing 4-12. As you saw in the earlier examples, you get a Cursor by calling rows() (Listing 4-12, line 157), which just instantiates and returns a Results object.
Looking at the implementation, the Results object traverses the List of rows using a standard java.util.Iterator. The advance() method on line 169 of Listing 4-12 just delegates to the Iterator, for example.
The interesting methods are update() and delete(), at the end of the listing. Other than do what their names imply, both methods set the table’s “dirty” flag to indicate that something has changed. They also register the operation with the transaction-processing system (described on p. 226) by calling registerUpdate() or registerDelete().
Listing 4-12. ConcreteTable.java Continued: Traversing and Modifying
154 //----------------------------------------------------------------------
155 // Traversing and cursor-based Updating and Deleting
156 //
157 public Cursor rows()
158 { return new Results();
159 }
160 //----------------------------------------------------------------------
161 private final class Results implements Cursor
162 { private final Iterator rowIterator = rowSet.iterator();
163 private Object[] row = null;
164
165 public String tableName()
166 { return ConcreteTable.this.tableName;
167 }
168
169 public boolean advance()
170 { if( rowIterator.hasNext() )
171 { row = (Object[]) rowIterator.next();
172 return true;
173 }
174 return false;
175 }
176
177 public Object column( String columnName )
178 { return row[ indexOf(columnName) ];
179 }
180
181 public Iterator columns()
182 { return new ArrayIterator( row );
183 }
184185 public boolean isTraversing( Table t )
186 { return t == ConcreteTable.this;
187 }
188
189 // This method is for use by the outer class only and is not part
190 // of the Cursor interface.
191 private Object[] cloneRow()
192 { return (Object[])( row.clone() );
193 }
194
195 public Object update( String columnName, Object newValue )
196 {
197 int index = indexOf(columnName);
198
199 // The following test is required for undo to work correctly.
200 if( row[index] == newValue )
201 throw new IllegalArgumentException(
202 "May not replace object with itself");
203
204 Object oldValue = row[index];
205 row[index] = newValue;
206 isDirty = true;
207
208 registerUpdate( row, index, oldValue );
209 return oldValue;
210 }
211
212
213 public void delete()
214 { Object[] oldRow = row;
215 rowIterator.remove();
216 isDirty = true;
217
218 registerDelete( oldRow );
219 }
220 }
Passive Iterators
The iterators we’ve been looking at are called external (or active) iterators because they’re separate objects from the data structure they’re traversing.
The storeRow() method of the Builder discussed in the previous section is an example of another sort of Iterator. Rather than creating an iterator object that’s external to the data structure, the export() method effectively implements the traversal mechanism inside the data-structure class (the ConcreteTable). The export() method iterates by calling the Exporter’s storeRow() method multiple times. We’re still visiting every node in turn, so this is still the Iterator pattern, but things are now inside out.
This kind of iterator is known as an internal (or passive) iterator. The idea of a passive iterator is that you provide some data structure with a Command object, one method of which is called repetitively (once for each node) and is passed the “current” node.
Passive iterators are quite useful when the data structure is inherently difficult to traverse. Consider the case of a simple binary tree such as the one shown in Listing 4-13. A passive iterator is a simple recursive function, easy to write. The traverseInOrder method (Listing 4-13, line 31) demonstrates a passive iterator. This textbook recursive-traversal algorithm just passes each node to the Examiner object (declared just above this method, on line 23) in turn. You could print all the nodes of a tree like this:
Tree t = new Tree();
//...
t.traverse
( new Examiner()
{ public void examine( Object currentNode )
{ System.out.println( currentNode.toString() );
}
}
);
Now consider the implementation of an active (external) iterator across a tree. The Tree class’s iterator() method (line 49) returns a standard java.util.Iterator that visits every node of the tree in order. My main point in showing you this code is to show you how opaque this code is. The algorithm is short but difficult to both understand and write. (In essence, I use a stack to keep track of parent nodes as I traverse the tree.)
Listing 4-13. Tree.java: A Simple Binary-Tree Implementation
1 import java.util.*;
2
3 /** This class demonstrates how to make both internal and external
4 * iterators across a binary tree. I've deliberately used a tree
5 * rather than a linked list to make the external in-order iterator
6 * more complicated.
7 */
8
9 public class Tree
10 {
11 private Node root = null;
12
13 private static class Node
14 { public Node left, right;
15 public Object item;
16 public Node( Object item )
17 { this.item = item;
18 }
19 }
20 //----------------------------------------------------------------- 21 // A Passive (internal) iterator
22 //
23 public interface Examiner
24 { public void examine( Object currentNode );
25 }
26
27 public void traverse( Examiner client )
28 { traverseInOrder( root, client );
29 }
30
31 private void traverseInOrder(Node current, Examiner client)
32 { if( current == null )
33 return;
34
35 traverseInOrder(current.left, client);
36 client.examine (current.item );
37 traverseInOrder(current.right, client);
38 }
39
40 public void add( Object item )
41 { if( root == null )
42 root = new Node( item );
43 else
44 insertItem( root, item );
45 }
46 //-----------------------------------------------------------------
47 // An Active (external) iterator
48 //
49 public Iterator iterator()
50 { return new Iterator()
51 { private Node current = root;
52 private LinkedList stack = new LinkedList();
53
54 public Object next()
55 {
56 while( current != null )
57 { stack.addFirst( current );
58 current = current.left;
59 }
60
61 if( stack.size() != 0 )
62 { current = (Node)
63 ( stack.removeFirst() );
64 Object toReturn=current.item;
65 current = current.right;
66 return toReturn;
67 } 68
69 throw new NoSuchElementException();
70 }
71
72 public boolean hasNext()
73 { return !(current==null && stack.size()==0);
74 }
75
76 public void remove()
77 { throw new UnsupportedOperationException();
78 }
79 };
80 }
81 //-----------------------------------------------------------------
82
83 private void insertItem( Node current, Object item )
84 { if(current.item.toString().compareTo(item.toString())>0)
85 { if( current.left == null )
86 current.left = new Node(item);
87 else
88 insertItem( current.left, item );
89 }
90 else
91 { if( current.right == null )
92 current.right = new Node(item);
93 else
94 insertItem( current.right, item );
95 }
96 }
97
98 public static void main( String[] args )
99 { Tree t = new Tree();
100 t.add("D");
101 t.add("B");
102 t.add("F");
103 t.add("A");
104 t.add("C");
105 t.add("E");
106 t.add("G");
107
108 Iterator i = t.iterator();
109 while( i.hasNext() )
110 System.out.print( i.next().toString() );
111
112 System.out.println("");
113
114 t.traverse( new Examiner()115 { public void examine(Object o)
116 { System.out.print( o.toString() );
117 }
118 } );
119 System.out.println("");
120 }
121 }
I’m not really done with the Iterator pattern because I haven’t discussed the problems that iterators can cause in mulithreading situations, so I’ll come back to them later in the current chapter. For now, I want to move onto the transaction-support subsystem.
Implementing Transactions (Undo) with the Command Pattern
The next interesting chunk of the ConcreteTable class is the “undo” subsystem that you need to support transactions. The design pattern here is the lowly Command pattern I discussed in Chapter 1. To refresh your memory, a Command object encapsulates knowledge of how to do some unspecified operation. For you C/C++ programmers, it’s the object-oriented equivalent of a “function pointer,” but rather than passing around a function that does something, you pass around an object who knows how to do it. The simplest reification of Command is Java’s Runnable class, which encapsulates knowledge of what to do on a thread. You create a Command object like this:
Runnable backgroundTask = new Runnable()
{ public void run()
{ System.out.println("Hello World");
}
};
and then pass it to a Thread object:
Thread controller = new Thread( backgroundTask );
You then start up the thread like this:
controller.start();
and the controller asks the Command object to do whatever it does by calling run().
That last statement is key to differentiating the Command pattern from some of the other design patterns that use Command objects (such as Strategy, discussed in Chapter 1 and later in this chapter). In Command, the Invoker (the Thread object) doesn’t actually know what the Concrete Command object (backgroundTask) is going to do.
One of the more interesting uses of the Command pattern is in implementing an undo system. Since I use the Table to implement a database, it must be possible to roll back a transaction at the Table level. (JDBC doesn’t actually require transactions, but I do.) Put another way, a modification to the Table may require several operations (inserts, updates, and so on), any one of which could fail for some reason. This group of logically connected operations forms a single transaction, and if any operation in the transaction fails, they all should fail. If you perform the first two operations of a transaction, for example, and the third operation then fails, then you must be able to undo the effect of the first two operations. This undo to the beginning of the transaction is called a rollback.
The complementary notion to a rollback is a commit. Once a transaction is committed, it becomes permanent. You can’t roll it back anymore. Formally, once you begin a transaction, you can terminate the transaction by issuing a rollback request (which puts the table back into the state it was in when you issued the begin), or you commit the transaction.
The situation is made only marginally more complicated by the notion of nested transactions. Consider the following SQL:
BEGIN
Operation-group A
BEGIN
Operation-group B
ROLLBACK
Operation-group C
COMMIT
The rollback causes the operations in Operation-group B to be ignored, so the result of the foregoing is to perform the operations in group A and C, but not B. On the other hand, the following SQL does nothing at all since the outermost transaction is rolled back:
BEGIN
Operation-group A
BEGIN
Operation-group B
COMMIT
Operation-group C
ROLLBACK
Transaction processing can get a lot more complicated than what I’ve just described, but since my database is built on a single-user, single-process model and I’m doing only simple things with it, the transaction system I just described is adequate, so I won’t go further into the topic.
One way to implement commit/rollback is to take a snapshot of the entire table every time you begin a transaction. A rollback restores the previous state from the snapshot. A commit just throws away the snapshot. You can implement nested transactions using a snapshot strategy by pushing a snapshot of the Table onto a stack every time you issue a BEGIN statement. You roll back by restoring the table to whatever state was remembered in the snapshot at the top of the stack. You commit a transaction simply by throwing away the snapshot at the top of the stack.
The main problem with a snapshot strategy for undo is that it’s too inefficient in both time and memory. The other commonplace problem with snapshots (not really an issue here but often an issue in other applications) is that an operation may have side effects, and simply restoring an object or objects to a previous state doesn’t undo the side effects. For example, consider an operation that both changes the internal state of the program but also modifies a database. The matching undo must not only put the program back into its original state, but also put the database back into its original state. A snapshot does only the former.
To your rescue comes a more sophisticated use of the Command pattern than the one I used earlier. I define an interface that a Table can use to request an undo operation (the Undo interface on line 224 of Listing 4-14). I then implement that interface with three separate classes (UndoInsert, UndoDelete, and UndoUpdate on lines 228, 238, and 248 of Listing 4-14). Taking UndoInsert as characteristic, you pass its constructor a reference to the inserted row. When the Table passes an execute() message to this object, it removes that row from the List that represents the table. The Invoker (the ConcreteTable object) doesn’t actually know or care what the Concrete-Command objects (the Undo implementers) actually do, as long as the undo something.
Now that I’ve defined the Command objects, I need to organize them. The Undo stack was defined at the top of the class definition (Listing 4-3, line 37, previously) as follows:
private transient LinkedList transactionStack = new LinkedList();
The stack is actually a stack of lists, one list for each transaction level. Consider the following calls (which I’ve indented to show the transaction nesting).
1 Table t new new ConcreteTable("x", "data"); // a single-column table
2
3 t.begin();
4 t.insert( "data", "A" )
5 t.insert( "data", "B" )
6 t.begin();
7 t.insert( "data", "C" )
8 t.insert( "data", "D" )
9 t.commit(false);
10 t.commit(false);
Transactioning is disabled until you issue the outermost begin() call: All operations are effectively committed when executed, and the transactionStack() is empty. Issuing a begin causes an empty list to be pushed onto the stack, and every insert, delete, or update operation will add a corresponding Undo object to the list at top of stack. The transactionStack will look like this just before the commit() on line 9, previously, is issued:
The four objects on the stack are instances of UndoInsert that remember the rows that they inserted. If a rollback() had been issued instead of the commit() on line 9, previously, the ConcreteTable would traverse the list of Undo objects at top of stack, asking each one to execute(), thereby undoing the operation. The list at top of stack is then discarded (so the A and B nodes are still on the stack). The commit() on line 9 doesn’t execute anything, however. Rather, the ConcreteStack concatenates the operations in the list at the top of stack to the list just under it on the stack. After the first commit(), the transactionStack looks like this:
Again, if you issued a rollback at this juncture, the system would traverse the entire list asking each undo object to execute() and then discarding the list. Since this is a commit operation, though, the undo system just discards the list at the top of stack.
The implementation of this system starts on line 265 of Listing 4-14. The begin() method pushes a new list onto the stack. The register methods create the proper sort of undo object and add them to the end of the list at the top of stack. (Note that nothing is added if the stack is empty, because no begin has been issued in that case.) Finally, commit(...) and rollback(...) modify the list and execute Undo objects, as described previously.
Listing 4-14. ConcreteTable.java Continued: Transaction Support
221 //----------------------------------------------------------------------
222 // Undo subsystem.
223 //
224 private interface Undo
225 { void execute();
226 }
227 // - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
228 private class UndoInsert implements Undo
229 { private final Object[] insertedRow;
230 public UndoInsert( Object[] insertedRow )
231 { this.insertedRow = insertedRow;
232 }
233 public void execute()
234 { rowSet.remove( insertedRow );
235 }
236 }
237 // - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
238 private class UndoDelete implements Undo
239 { private final Object[] deletedRow;
240 public UndoDelete( Object[] deletedRow )
241 { this.deletedRow = deletedRow;
242 }
243 public void execute()
244 { rowSet.add( deletedRow );
245 }
246 }
247 // - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
248 private class UndoUpdate implements Undo
249 {
250 private Object[] row;251 private int cell;
252 private Object oldContents;
253
254 public UndoUpdate( Object[] row, int cell, Object oldContents )
255 { this.row = row;
256 this.cell = cell;
257 this.oldContents = oldContents;
258 }
259
260 public void execute()
261 { row[ cell ] = oldContents;
262 }
263 }
264 // - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
265 public void begin()
266 { transactionStack.addLast( new LinkedList() );
267 }
268 // - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
269 private void register( Undo op )
270 { ((LinkedList) transactionStack.getLast()).addLast( op );
271 }
272 private void registerUpdate(Object[] row, int cell, Object oldContents)
273 { if( !transactionStack.isEmpty() )
274 register( new UndoUpdate(row, cell, oldContents) );
275 }
276 private void registerDelete( Object[] oldRow )
277 { if( !transactionStack.isEmpty() )
278 register( new UndoDelete(oldRow) );
279 }
280 private void registerInsert( Object[] newRow )
281 { if( !transactionStack.isEmpty() )
282 register( new UndoInsert(newRow) );
283 }
284 // - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
285 public void commit( boolean all ) throws IllegalStateException
286 { if( transactionStack.isEmpty() )
287 throw new IllegalStateException("No BEGIN for COMMIT");
288 do
289 { LinkedList currentLevel =
290 (LinkedList) transactionStack.removeLast();
291
292 if( !transactionStack.isEmpty() )
293 ((LinkedList)transactionStack.getLast())
294 .addAll(currentLevel);
295
296 } while( all && !transactionStack.isEmpty() );
297 }298 // - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
299 public void rollback( boolean all ) throws IllegalStateException
300 { if( transactionStack.isEmpty() )
301 throw new IllegalStateException("No BEGIN for ROLLBACK");
302 do
303 { LinkedList currentLevel =
304 (LinkedList) transactionStack.removeLast();
305
306 while( !currentLevel.isEmpty() )
307 ((Undo) currentLevel.removeLast()).execute();
308
309 } while( all && !transactionStack.isEmpty() );
310 }
311 // - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Modifying a Table: The Strategy Pattern
Once you’ve built a table, you may want to change it. As you saw earlier, you can use a Cursor for this purpose, but that’s sometimes inconvenient. Consequently, two methods are provided to do updates and deletes without using a Cursor explicitly.
By way of demonstration, the following code deletes everyone named Flintstone from the people table:
people.delete
( new Selector.Adapter()
{ public boolean approve( Cursor[] tables )
{ return tables[0].column("lastName").equals("Flintstone");
}
}
);
The design pattern here is Strategy—introduced in Chapter 2. Pass into the Table an object that knows how to select rows: a Selector (that encapsulates a selection strategy). The delete method calls the Strategy object’s approve() method as many times as there are rows, and approve() must return true if that row should be deleted. The one complication is that approve() is passed an array of Table objects rather than a single Table reference. In the current example, the array has only one Table in it, but you will see situations in a moment where that is not the case.
Update operations are done more-or-less like deletes, but you have to override a modify() method as well as the approve(...) method of the Selector. The following code moves everyone who lives in Arizona to California; it examines the entire “address” table and changes all rows whose “state” columns have the value “AZ” to “CA”: The modify(...) method is passed a cursor that’s prepositioned at the current row, and it updates the row through the cursor.
address.update
( new Selector()
{ public boolean approve( Cursor[] tables ) { return tables[0].column("state").equals("AZ");
}
public void modify( Cursor current )
{ current.update("state", "AZ");
}
}
);
Astute readers (that’s you, I’m sure) will notice that I extended Selector.Adapter in the earlier example, and I implemented the Selector interface directly in the latter example. Selector.Adapter implements Selector by providing default implementations of its two methods: approve() and modify(). This is the same naming and implementation strategy that’s used by the AWT/Swing event model, which provides default implementations of the listener interfaces. (MouseAdapter implements MouseListener, for example.) This naming convention is unfortunate in that we’re not reifying the Adapter design pattern, in spite of the class name. Don’t get confused.
This code also demonstrates the passive (or internal) variant of the Iterator pattern that I discussed earlier. The approve(...) method of the Selector object is called for every row of the table. Since the traversal algorithm is in the Table, Selector is a passive iterator across Table objects. (I haven’t shown this use of Iterator in Figure 4-2, only because there wasn’t enough room to cram it in.)
The Selector interface is in Listing 4-15. The Selector.Adapter is declared as a static inner class of Selector (on line 49 of Listing 4-15). It approves everything and complains with an exception toss if it’s used in an update() call. From a design point of view, I wrestled with the throw-an-exception strategy that I ended up using. As I mentioned earlier, I really dislike the notion of unsupported operations throwing exceptions because this structure effectively moves a compile-time error into runtime. The alternative was splitting the interface into two single-method interfaces, but I didn’t like this solution any better because it complicates an otherwise trivial system. I wouldn’t argue with you if you said that I made the wrong decision, however.
An instance of Selector.Adapter called ALL is declared at the end of the listing. This instance is used primarily in the “select” operations discussed in the following section, but you could use it as follows to delete all the rows of a table:
people.delete( Selector.ALL );
The implementations of update(...) and delete(...) are in Listing 4-16. All that these methods do is hide the iteration code and call the Strategy object’s methods where appropriate.
Listing 4-15. Selector.java
1 package com.holub.database;
2
3 /** A Selector is a Strategy object that is used by
4 * {@link Table#select} to determine
5 * whether a particular row should be included in the result.
6 * The passed Cursor is positioned at the correct row, 7 * and attempts to advance it will fail.
8 */
9
10 interface Selector
11 {
12 /** This method is passed rows from the tables being joined
13 * and returns true if the aggregate row is approved for the
14 * current operation. In a select, for example, "aproval"
15 * means that the aggregate row should be included in the
16 * result-set Table.
17 * @param rows An array of iterators, one for the current
18 * row in each table to be examined (The array will
19 * have only one element unless a you're approving
20 * rows in a join.) These iterators are already
21 * positioned at the correct row. Attempts to
22 * advance the iterator result in an exception
23 * toss ({@link java.lang.IllegalStateException}).
24 * @return true if the aggregate row should has been approved
25 * for the current operation.
26 */
27 boolean approve( Cursor[] rows );
28
29 /** This method is called only when an update request for a
30 * row is approved by {@link #approve approve(...)}. It should
31 * replace the required cell with a new value.
32 * You must do the replacement using the iterator's
33 * {@link Cursor#update} method. A typical implementation
34 * takes this form:
35 * <PRE>
36 * public Object modify( Cursor current )
37 * { return current.update( "columnName", "new-value" );
38 * }
39 * </PRE>
40 * @param current Iterator positioned at the row to modify
41 */
42 void modify( Cursor current );
43
44 /** An implementation of {@link Selector} whose approve method
45 * approves everything, and whose replace() method throws an
46 * {@link UnsupportedOperationException} if called. Useful
47 * for creating selectors on the fly with anonymous inner classes.
48 */
49 public static class Adapter implements Selector
50 { public boolean approve( Cursor[] tables )
51 { return true;
52 }
53 public void modify( Cursor current )54 { throw new UnsupportedOperationException(
55 "Can't use a Selector.Adapter in an update");
56 }
57 }
58
59 /** An instance of {@link Selector.Adapter),
60 * pass Selector.ALL to the {@link Table}'s
61 * {@link Table#select select(...)} or
62 * {@link Table#delete delete(...)} methods to select all rows
63 * of the table. May not be used in an update operation.
64 */
65 public static final Selector ALL = new Selector.Adapter();
66
67 }
Listing 4-16. ConcreteTable.java Continued: Updating and Deleting
312 //-----------------------------------------------------------------
313 public int update( Selector where )
314 {
315 Results currentRow = (Results)rows();
316 Cursor[] envelope = new Cursor[]{ currentRow };
317 int updated = 0;
318
319 while( currentRow.advance() )
320 { if( where.approve(envelope) )
321 { where.modify(currentRow);
322 ++updated;
323 }
324 }
325
326 return updated;
327 }
328 //----------------------------------------------------------------------
329 public int delete( Selector where )
330 { int deleted = 0;
331
332 Results currentRow = (Results) rows();
333 Cursor[] envelope = new Cursor[]{ currentRow };
334
335 while( currentRow.advance() )
336 { if( where.approve( envelope) )
337 { currentRow.delete();
338 ++deleted;
339 }
340 }
341 return deleted;
342 }
Selection and Joins
The final significant ability of Table is to do a SQL-like “select/join” operation. A simple select extracts from one table only those rows that satisfy some criterion. For example, the following code extracts from the people table those rows whose “lastName” column contains the value “Flintstone” (In SQL: SELECT * FROM people WHERE lastName="Flintstone"):
Selector flintstoneSelector =
new Selector.Adapter()
{ public boolean approve( Cursor[] tables )
{ return tables[0].column("lastName").equals("Flintstone");
}
};
Table result = people.select( flintstoneSelector );
The select() method returns a Table (typically called a result set) that contains only the selected rows. This table differs from one you may declare in that it’s “unmodifiable.” Attempts to modify it result in an exception toss. You can make the table modifiable like this:
result = ((UnmodifiableTable)result).extract();
I’ll explain this code further in a moment.
You can also get a result set that contains only specified columns of the selected rows. The following code extracts all people whose last name is Flintstone but includes only the first- and last-name columns in the result set (in SQL: SELECT first,last FROM people WHERE lastName="Flintstone"):
Table result = people.select(flintstoneSelector,
new String[]{"firstName", "lastName"}
Create a result set that contains selected columns of every row like this:
Table result = people.select(Selector.ALL,
new String[]{"firstName", "lastName"}
Finally, the following variant lets you specify the desired columns in a Collection rather than an array:
List columns = new ArrayList();
columns.add("firstName");
columns.add("lastName");
Table result = people.select(flintstoneSelector, columns);
Though selection is useful in and of itself, an even more powerful variant on selection is a “join” operation. The basic idea is to select simultaneously from multiple tables. The word join comes from the notion that you’re joining multiple tables together to make one big virtual table and then selecting a row from that virtual table. It’s well beyond the scope of this book to describe why joins are useful, but for those of you who know a little database stuff, this SQL
SELECT firstName, lastName, street, city, state, zip"
FROM people, address
WHERE people.addrId = address.addrId
is performed as follows:
String[] columns= new String[]{ "firstName","lastName",
"street","city","state","zip"};
Table [] tables = new Table[] { address }; // additional tables to
// join to current table.
Table result=
people.select
( new Selector.Adapter()
{ public boolean approve( Cursor[] tables )
{ return
tables[0].column("addrId"). /*people.addrId*/
equals(tables[1].column("addrId") /*=address.addrId*/ );
}
},
columns,
tables
);
The array of Cursor objects passed into approve() is ordered identically to the array of Table objects that you pass into select(...).
Every possible combination of rows from the two tables is considered when the result set is built. (Formally, a result table holding every combination of rows from a set of source tables is said to be the Cartesian product of the source tables.) Given one table with the rows A, B, and C and a second table with the rows D and E, the following calls to approve() are made (where A, B, C, D, and E) are cursors positioned at the appropriate rows:
approve( Cursor[]{ A, D } );
approve( Cursor[]{ A, E } );
approve( Cursor[]{ B, D } );
approve( Cursor[]{ B, E } );
approve( Cursor[]{ C, D } );
approve( Cursor[]{ C, E } );
You can join any number of tables, but bear in mind that every time you add a table, you multiply the amount of work by the number of rows in the added table. (Joining two 5-row tables requires 25 calls to approve() [5×5]; joining three, 5-row tables requires 125 [5×5×5] approvals.) In a real database, you can do some clever work to reduce this overhead, but the number of tables always significantly increases the cost of the join operation.
An overload of this method lets you use Collection objects rather than arrays for the columns and tables arguments.
Listing 4-17 shows the code that implements the various select() overloads. From a design-pattern perspective, there’s nothing interesting here. The select() overloads are just additional reifications of Strategy. From a programming perspective, the selectFromCartesian-Product(...) method on line 437 is worth examining. This is the method that does the actual join. It uses a recursive algorithm to assemble arrays of cursors representing each row of the Cartesian product and then passes that array off to your approve() method. The code is elegant (if I do say so myself), but the recursion makes it somewhat opaque.
Listing 4-17. ConcreteTable.java Continued: Selection and Joins
343 //----------------------------------------------------------------------
344 public Table select( Selector where )
345 { Table resultTable = new ConcreteTable( null,
346 (String[]) columnNames.clone() );
347
348 Results currentRow = (Results) rows();
349 Cursor[] envelope = new Cursor[]{ currentRow };
350
351 while( currentRow.advance() )
352 { if( where.approve(envelope) )
353 resultTable.insert( (Object[]) currentRow.cloneRow() );
354 }
355 return new UnmodifiableTable(resultTable);
356 }
357 // - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
358 public Table select(Selector where, String[] requestedColumns )
359 { if( requestedColumns == null )
360 return select( where );
361
362 Table resultTable = new ConcreteTable( null,
363 (String[]) requestedColumns.clone() );
364
365 Results currentRow = (Results) rows();
366 Cursor[] envelope = new Cursor[]{ currentRow };
367
368 while( currentRow.advance() )
369 { if( where.approve(envelope) )
370 { Object[] newRow = new Object[ requestedColumns.length ];
371 for( int column=0; column < requestedColumns.length;
372 ++column )
373 { newRow[column]=
374 currentRow.column(requestedColumns[column]);
375 }
376 resultTable.insert( newRow );
377 }
378 }
379 return new UnmodifiableTable(resultTable);380 }
381 // - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
382 // This version of select does a join
383 //
384 public Table select( Selector where, String[] requestedColumns,
385 Table[] otherTables )
386 {
387 // If we're not doing a join, use the more efficient version
388 // of select().
389
390 if( otherTables == null || otherTables.length == 0)
391 return select( where, requestedColumns );
392
393 // Make the current table not be a special case by effectively
394 // prefixing it to the otherTables array.
395
396 Table[] allTables = new Table[ otherTables.length + 1 ];
397 allTables[0] = this;
398 System.arraycopy(otherTables, 0, allTables, 1, otherTables.length );
399
400 // Create places to hold the result of the join and to hold
401 // iterators for each table involved in the join.
402
403 Table resultTable = new ConcreteTable(null,requestedColumns);
404 Cursor[] envelope = new Cursor[allTables.length];
405
406 // Recursively compute the Cartesian product, adding to the
407 // resultTable all rows that the Selector approves
408
409 selectFromCartesianProduct( 0, where, requestedColumns,
410 allTables, envelope, resultTable );
411
412 return new UnmodifiableTable(resultTable);
413 }
414 // - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
415 // Think of the Cartesian product as a kind of tree. That is
416 // given one table with rows A and B, and another table with rows
417 // C and D, you can look at the product like this:
418 //
419 // root
420 // ______|______
421 // | |
422 // A B
423 // ____|____ ____|____
424 // | | | |
425 // C D C D
426 //427 // The tree is as deep as the number of tables we're joining.
428 // Every possible path from the root to a leaf represents one row
429 // in the Cartesian product. The current method effectively traverses
430 // this tree recursively without building an actual tree. It
431 // assembles an array of iterators (one for each table) positioned
432 // at the current place in the set of rows as it recurses to a leaf,
433 // and then asks the selector whether to approve that row.
434 // It then goes up a notch, advances the correct iterator, and
435 // recurses back down.
436 //
437 private static void selectFromCartesianProduct(
438 int level,
439 Selector where,
440 String[] requestedColumns,
441 Table[] allTables,
442 Cursor[] allIterators,
443 Table resultTable )
444 {
445 allIterators[level] = allTables[level].rows();
446
447 while( allIterators[level].advance() )
448 { // If we haven't reached the tips of the branches yet,
449 // go down one more level.
450
451 if( level < allIterators.length - 1 )
452 selectFromCartesianProduct(level+1, where,
453 requestedColumns,
454 allTables, allIterators, resultTable);
455
456 // If we are at the leaf level, then get approval for
457 // the fully-assembled row, and add the row to the table
458 // if it's approved.
459
460 if( level == allIterators.length - 1 )
461 { if( where.approve(allIterators) )
462 insertApprovedRows( resultTable,
463 requestedColumns, allIterators );
464 }
465 }
466 }
467 // - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
468 // Insert an approved row into the result table:
469 // for( every requested column )
470 // for( every table in the join )
471 // if the requested column is in the current table
472 // add the associated value to the result table
473 //474 // Only one column with a given name is added, even if that column
475 // appears in multiple tables. Columns in tables at the beginning
476 // of the list take precedence over identically named columns that
477 // occur later in the list.
478 //
479 private static void insertApprovedRows( Table resultTable,
480 String[] requestedColumns,
481 Cursor[] allTables )
482 {
483
484 Object[] resultRow = new Object[ requestedColumns.length ];
485
486 for( int i = 0; i < requestedColumns.length; ++i )
487 { for( int table = 0; table < allTables.length; ++table )
488 { try
489 { resultRow[i] =
490 allTables[table].column(requestedColumns[i]);
491 break; // if the assignment worked, do the next column
492 }
493 catch(Exception e)
494 { // otherwise, try the next table
495 }
496 }
497 }
498 resultTable.insert( /*requestedColumns,*/ resultRow );
499 }
500 // - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
501 /**
502 * A collection variant on the array version. Just converts the collection
503 * to an array and then chains to the other version
504 * ({@linkplain #select(Selector,String[],Table[]) see}).
505 * @param requestedColumns the value returned from the {@link #toString}
506 * method of the elements of this collection are used as the
507 * column names.
508 * @param other Collection of tables to join to the current one,
509 * <code>null</code>if none.
510 * @throws ClassCastException if any elements of the <code>other</code>
511 * collection do not implement the {@link Table} interface.
512 */
513 public Table select(Selector where, Collection requestedColumns,
514 Collection other)
515 {
516 String[] columnNames = null;
517 Table[] otherTables = null;
518
519 if( requestedColumns != null ) // SELECT *
520 {521 // Can't cast an Object[] to a String[], so make a copy to ensure
522 // type safety.
523
524 columnNames = new String[ requestedColumns.size() ];
525 int i = 0;
526 Iterator column = requestedColumns.iterator();
527
528 while( column.hasNext() )
529 columnNames[i++] = column.next().toString();
530 }
531
532 if( other != null )
533 otherTables = (Table[]) other.toArray( new Table[other.size()] );
534
535 return select( where, columnNames, otherTables );
536 }
537 // - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
538 public Table select(Selector where, Collection requestedColumns)
539 { return select( where, requestedColumns, null );
540 }
Miscellany
The remainder of the ConcreteTable definition is in Listing 4-18. It contains a few housekeeping and workhorse methods (such as toString(), which returns a String representation of all the elements in the table). Listing 4-18 ends with a long unit-test class that has several examples of the calls I’ve been discussing. I like to put my unit tests into inner classes (which I always call Test) so that the test code will be in a separate .class file than the class I’m testing. I don’t ship the test-class files with the product. Run the test using this:
java com.holub.database.ConcreteTable$Test
(but omit the backslash if you’re testing from a Windows “DOS box”). Normally, I like test classes such as this to print nothing at all if everything’s okay, and I like to report the number of errors as the test-program’s exit status. This way, I can automate the tests easily, and the result of running the test is a list of what went wrong. If you print too many “this is okay” messages, you’ll lose the error messages in the clutter.
The problem with this approach is that the inner-class unit test has access to parts of the class that a normal “client” wouldn’t be able to see. I am careful, when I use this unit-test strategy, to pretend that I do not have this special access. Of course, you can guarantee that you don’t have access by putting your tests in a separate class in a separate package, but then the test code is in a different directory and is harder to augment if you change the interface to the class.
Having said all that, I haven’t followed my usual testing guidelines in the current situation. I test by redirecting the output of the program to a file and then using the Unix diff utility to compare that output with an expected-output file. I test the class by running the following shell script, which prints the words PASSED or FAILED, depending on whether the actual output matches the expected output:
java com.holub.database.ConcreteTable$Test > $TMP/ConcreteTable.test.tmp
diff $TMP/ConcreteTable.test.tmp ConcreteTable.test.out
case $? in
(0) print ConcreteTable PASSED
;;
(1) print ConcreteTable FAILED
;;
(*) print Unknown diff failure
;;
esac
It’s ugly, but it works.
Listing 4-18. ConcreteTable.java Continued: Miscellany
541 //----------------------------------------------------------------------
542 // Housekeeping stuff
543 //
544 public String name() { return tableName; }
545 public void rename(String s) { tableName = s; }
546 public boolean isDirty() { return isDirty; }
547 private int width() { return columnNames.length; }
548 //----------------------------------------------------------------------
549 public Object clone() throws CloneNotSupportedException
550 { ConcreteTable copy = (ConcreteTable) super.clone();
551 copy.rowSet = (LinkedList) rowSet.clone();
552 copy.columnNames = (String[]) columnNames.clone();
553 copy.tableName = tableName;
554 return copy;
555 }
556 //----------------------------------------------------------------------
557 public String toString()
558 { StringBuffer out = new StringBuffer();
559
560 out.append( tableName == null ? "<anonymous>" : tableName );
561 out.append( "
" );
562
563 for( int i = 0; i < columnNames.length; ++i )
564 out.append(columnNames[i] + " ");
565 out.append("
----------------------------------------
");
566
567 for( Cursor i = rows(); i.advance(); )
568 { Iterator columns = i.columns();
569 while( columns.hasNext() )
570 { Object next = columns.next();
571 if( next == null )572 out.append( "null " );
573 else
574 out.append( next.toString() + " " );
575 }
576 out.append('
');
577 }
578 return out.toString();
579 }
580
581 //----------------------------------------------------------------------
582 public final static class Test
583 {
584 public static void main(String[] args)
585 { new Test().test();
586 }
587
588 Table people = TableFactory.create(
589 "people", new String[]{"last", "first", "addrId" } );
590
591 Table address = TableFactory.create(
592 "address", new String[]{"addrId","street","city","state","zip"});
593
594 public void report( Throwable t, String message )
595 { System.out.println( message + " FAILED with exception toss" );
596 t.printStackTrace();
597 System.exit(1);
598 }
599
600 public void test()
601 { try{ testInsert(); }catch(Throwable t){ report(t,"Insert"); }
602 try{ testUpdate(); }catch(Throwable t){ report(t,"Update"); }
603 try{ testDelete(); }catch(Throwable t){ report(t,"Delete"); }
604 try{ testSelect(); }catch(Throwable t){ report(t,"Select"); }
605 try{ testStore(); }catch(Throwable t){ report(t,"Store/Load");}
606 try{ testJoin(); }catch(Throwable t){ report(t,"Join" ); }
607 try{ testUndo(); }catch(Throwable t){ report(t,"Undo" ); }
608 }
609
610 public void testInsert()
611 { people.insert(new Object[]{"Holub", "Allen","1" });
612 people.insert(new Object[]{"Flintstone","Wilma","2" });
613 people.insert(new String[]{"addrId", "first","last" },
614 new Object[]{"2", "Fred", "Flintstone"});
615
616 address.insert( new Object[]{"1","123 MyStreet",
617 "Berkeley","CA","99999" } );
618619 List l = new ArrayList();
620 l.add("2");
621 l.add("123 Quarry Ln.");
622 l.add("Bedrock ");
623 l.add("XX");
624 l.add("12345");
625 assert( address.insert(l) == 1 );
626
627 l.clear();
628 l.add("3");
629 l.add("Bogus");
630 l.add("Bad");
631 l.add("XX");
632 l.add("12345");
633
634 List c = new ArrayList();
635 c.add("addrId");
636 c.add("street");
637 c.add("city");
638 c.add("state");
639 c.add("zip");
640 assert( address.insert( c, l ) == 1);
641
642 System.out.println( people.toString() );
643 System.out.println( address.toString() );
644
645 try
646 { people.insert( new Object[]{ "x" } );
647 throw new AssertionError(
648 "insert wrong number of fields test failed");
649 }
650 catch(Throwable t){ /* Failed correctly, do nothing */ }
651
652 try
653 { people.insert( new String[]{ "?" }, new Object[]{ "y" });
654 throw new AssertionError(
655 "insert-nonexistent-field test failed");
656 }
657 catch(Exception t){ /* Failed correctly, do nothing */ }
658 }
659
660 public void testUpdate()
661 { System.out.println("update set state='YY' where state='XX'" );
662 int updated = address.update
663 ( new Selector()
664 { public boolean approve( Cursor[] tables )
665 { return tables[0].column("state").equals("XX");666 }
667 public void modify( Cursor current )
668 { current.update("state", "YY");
669 }
670 }
671 );
672 print( address );
673 System.out.println( updated + " rows affected
" );
674 }
675
676 public void testDelete()
677 {
678 System.out.println("delete where street='Bogus'" );
679 int deleted =
680 address.delete
681 ( new Selector.Adapter()
682 { public boolean approve( Cursor[] tables )
683 { return tables[0].column("street").equals("Bogus");
684 }
685 }
686 );
687 print( address );
688 System.out.println( deleted + " rows affected
" );
689 }
690
691 public void testSelect()
692 { Selector flintstoneSelector =
693 new Selector.Adapter()
694 { public boolean approve( Cursor[] tables )
695 { return tables[0].column("last").equals("Flintstone");
696 }
697 };
698
699 // SELECT first, last FROM people WHERE last = "Flintstone"
700 // The collection version chains to the string version, so the
701 // following call tests both versions
702
703 List columns = new ArrayList();
704 columns.add("first");
705 columns.add("last");
706
707 Table result = people.select(flintstoneSelector, columns);
708 print( result );
709
710 // SELECT * FROM people WHERE last = "Flintstone"
711 result = people.select( flintstoneSelector );
712 print( result );713
714 // Check that the result is indeed unmodifiable
715
716 try
717 { result.insert( new Object[]{ "x", "y", "z" } );
718 throw new AssertionError(
719 "Insert to Immutable Table test failed");
720 }
721 catch( Exception e ){ /*it failed correctly*/ }
722
723 try
724 { result.update( flintstoneSelector );
725 throw new AssertionError(
726 "Update of Immutable Table test failed");
727 }
728 catch( Exception e ){ /*it failed correctly*/ }
729
730 try
731 { result.delete( flintstoneSelector );
732 throw new AssertionError(
733 "Delete of Immutable Table test failed");
734 }
735 catch( Exception e ){ /*it failed correctly*/ }
736 }
737
738 public void testStore() throws IOException, ClassNotFoundException
739 { // Flush the table to disk, then reread it.
740 // Subsequent tests that use the "people" table will
741 // fail if this operation fails.
742
743 Writer out = new FileWriter( "people" );
744 people.export( new CSVExporter(out) );
745 out.close();
746
747 Reader in = new FileReader( "people" );
748 people = new ConcreteTable( new CSVImporter(in) );
749 in.close();
750 }
751
752 public void testJoin()
753 {
754 // First test a two-way join
755
756 System.out.println("
SELECT first,last,street,city,state,zip"
757 +" FROM people, address"
758 +" WHERE people.addrId = address.addrId");
759760 // Collection version chains to String[] version,
761 // so this code tests both:
762 List columns = new ArrayList();
763 columns.add("first");
764 columns.add("last");
765 columns.add("street");
766 columns.add("city");
767 columns.add("state");
768 columns.add("zip");
769
770 List tables = new ArrayList();
771 tables.add( address );
772
773 Table result= // WHERE people.addrID = address.addrID
774 people.select
775 ( new Selector.Adapter()
776 { public boolean approve( Cursor[] tables )
777 { return tables[0].column("addrId")
778 .equals( tables[1].column("addrId") );
779 }
780 },
781 columns,
782 tables
783 );
784
785 print( result );
786 System.out.println("");
787
788 // Now test a three-way join
789 //
790 System.out.println(
791 "
SELECT first,last,street,city,state,zip,text"
792 +" FROM people, address, third"
793 +" WHERE (people.addrId = address.addrId)"
794 +" AND (people.addrId = third.addrId)");
795
796 Table third = TableFactory.create(
797 "third", new String[]{"addrId","text"} );
798 third.insert ( new Object[]{ "1", "addrId=1" } );
799 third.insert ( new Object[]{ "2", "addrId=2" } );
800
801 result=
802 people.select
803 ( new Selector.Adapter()
804 { public boolean approve( Cursor[] tables )
805 { return
806 (tables[0].column("addrId")807 .equals(tables[1].column("addrId"))
808 &&
809 tables[0].column("addrId")
810 .equals(tables[2].column("addrId"))
811 );
812 }
813 },
814
815 new String[]{"last", "first", "state", "text"},
816 new Table[]{ address, third }
817 );
818
819 System.out.println( result.toString() + "
" );
820 }
821
822 public void testUndo()
823 {
824 // Verify that commit works properly
825 people.begin();
826 System.out.println(
827 "begin/insert into people (Solo, Han, 5)");
828
829 people.insert( new Object[]{ "Solo", "Han", "5" } );
830 System.out.println( people.toString() );
831
832 people.begin();
833 System.out.println(
834 "begin/insert into people (Lea, Princess, 6)");
835
836 people.insert( new Object[]{ "Lea", "Princess", "6" } );
837 System.out.println( people.toString() );
838
839 System.out.println( "commit(THIS_LEVEL)
"
840 +"rollback(Table.THIS_LEVEL)
");
841 people.commit (Table.THIS_LEVEL);
842 people.rollback (Table.THIS_LEVEL);
843 System.out.println ( people.toString() );
844
845 // Now test that nested transactions work correctly.
846
847 System.out.println( people.toString() );
848
849 System.out.println("begin/insert into people (Vader,Darth, 4)");
850 people.begin();
851 people.insert( new Object[]{ "Vader","Darth", "4" } );
852 System.out.println( people.toString() );
853854 System.out.println(
855 "begin/update people set last=Skywalker where last=Vader");
856
857 people.begin();
858 people.update
859 ( new Selector()
860 { public boolean approve( Cursor[] tables )
861 { return tables[0].column("last").equals("Vader");
862 }
863 public void modify(Cursor current)
864 { current.update( "last", "Skywalker" );
865 }
866 }
867 );
868 System.out.println( people.toString() );
869
870 System.out.println("delete from people where last=Skywalker");
871 people.delete
872 ( new Selector.Adapter()
873 { public boolean approve( Cursor[] tables )
874 { return tables[0].column("last").equals("Skywalker");
875 }
876 }
877 );
878 System.out.println( people.toString() );
879
880 System.out.println(
881 "rollback(Table.THIS_LEVEL) the delete and update");
882 people.rollback(Table.THIS_LEVEL);
883 System.out.println( people.toString() );
884
885 System.out.println("rollback(Table.THIS_LEVEL) insert");
886 people.rollback(Table.THIS_LEVEL);
887 System.out.println( people.toString() );
888 }
889
890 public void print( Table t )
891 { // tests the table iterator
892 Cursor current = t.rows();
893 while( current.advance() )
894 { for(Iterator columns = current.columns();columns.hasNext();)
895 System.out.print( (String) columns.next() + " " );
896 System.out.println("");
897 }
898 }
899 }
900 }
Variants on the Table: The Decorator Pattern
If you look back at the various select() overrides in Listing 4-17, you’ll notice that they all take the following form:
public Table select(...)
{
Table resultTable = new ConcreteTable( ... );
/* populate the resultTable... */
return new UnmodifiableTable(resultTable);
}
They create a ConcreteTable, populate it, and then return an UnmodifiableTable that wraps the actual result table. Listing 4-19 shows the UnmodifiableTable class. As you can see, its methods are divided into two categories. The methods that can modify a Table (insert(), update(), delete()) all do nothing but throw an exception if called. The remainder of the methods just delegate to the wrapped table. Finally, the UnmodifiableTable adds an extract() method (Listing 4-19, line 88) that just returns the wrapped Table. (As it says in the comment preceding the method, this last method is somewhat problematic because it provides a way to get around the unmodifiability, but the SQL-engine layer requires it to implement the SELECT INTO request efficiently.)
Listing 4-19. UnmodifiableTable.java
1 package com.holub.database;
2 import java.io.*;
3 import java.util.*;
4
5 /** This decorator of the Table class just wraps another table,
6 * but restricts access to methods that don't modify the table.
7 * The following methods toss an
8 * {@link UnsupportedOperationException} when called:
9 * <PRE>
10 * public void insert( String[] columnNames, Object[] values )
11 * public void insert( Object[] values )
12 * public void update( Selector where )
13 * public void delete( Selector where )
14 * public void store ()
15 * </PRE>
16 * Other methods delegate to the wrapped Table. All methods of
17 * the {@link Table} that are declared to return a
18 * <code>Table</code> actually return an
19 * <code>UnmodifiableTable</code>.
20 * <p>
21 * Refer to the {@link Table} interface for method documentation.
22 */
23
24 public class UnmodifiableTable implements Table
25 { private Table wrapped;
26
27 public UnmodifiableTable( Table wrapped )
28 { this.wrapped = wrapped;
29 }
30
31 /** Return an UnmodifiableTable that wraps a clone of the
32 * currently wrapped table. (A deep copy is used.)
33 */
34 public Object clone() throws CloneNotSupportedException
35 { UnmodifiableTable copy = (UnmodifiableTable) super.clone();
36 copy.wrapped = (Table)( wrapped.clone() );
37 return copy;
38 }
39
40 public int insert(String[] c, Object[] v ){ illegal(); return 0;}
41 public int insert(Object[] v ){ illegal(); return 0;}
42 public int insert(Collection c,Collection v ){ illegal(); return 0;}
43 public int insert(Collection v ){ illegal(); return 0;}
44 public int update(Selector w ){ illegal(); return 0;}
45 public int delete( Selector w ){ illegal(); return 0;}
46
47 public void begin ( ){ illegal(); }
48 public void commit (boolean all){ illegal(); }
49 public void rollback (boolean all){ illegal(); }
50
51 private final void illegal()
52 { throw new UnsupportedOperationException();
53 }
54
55 public Table select(Selector w,String[] r,Table[] o)
56 { return wrapped.select( w, r, o );
57 }
58 public Table select(Selector where, String[] requestedColumns)
59 { return wrapped.select(where, requestedColumns );
60 }
61 public Table select(Selector where)
62 { return wrapped.select(where);
63 }
64 public Table select(Selector w,Collection r,Collection o)
65 { return wrapped.select( w, r, o );
66 }
67 public Table select(Selector w, Collection r)
68 { return wrapped.select(w, r);
69 }
70 public Cursor rows()
71 { return wrapped.rows();
72 }
73 public void export(Table.Exporter exporter) throws IOException
74 { wrapped.export(exporter);
75 }
76
77 public String toString() { return wrapped.toString(); }
78 public String name() { return wrapped.name(); }
79 public void rename(String s){ wrapped.rename(s); }
80 public boolean isDirty() { return wrapped.isDirty(); }
81
82 /** Extract the wrapped table. The existence of this method is
83 * problematic, since it allows someone to defeat the unmodifiability
84 * of the table. On the other hand, the wrapped table came in from
85 * outside, so external access is possible through the reference
86 * that was passed to the constructor. Use the method with care.
87 */
88 public Table extract(){ return wrapped; }
89 }
What I’ve done with UnmodifiableTable is used a wrapping strategy to do something that I could also have done using inheritance. My goal was to change the behavior of several of the methods of ConcreteTable so that the Table was effectively immutable. I was reluctant to put an isImmutable flag into the ConcreteTable and test the flag all over the place—that solution was just too complicated. I could also have derived a class and overridden the methods that modified the table to throw an exception, but that solution introduces a fragile-base scenario. (I could inadvertently add a method to the superclass that modified the table and forget to override that method in the subclass.) Finally, the derivation solution leaves open the potential for hard-to-maintain code that reports errors at runtime that should really be compile-time errors. (If I try to assign a Table to an UnmodifiableTable reference, I’ll get a compile-time error.)
I solved the problem by replacing implementation inheritance with an interface-inheritance/delegation strategy. I implement the same interface as the object that I’m wrapping (the object that would otherwise be the superclass) and delegate to the wrapped object when necessary.
This solution to the fragile-base-class problem, which allows me to change behavior without using extends, is an example of the Decorator pattern.
You’ve seen decorators if you’ve used Java’s I/O classes. For example, if you need to read a compressed stream of bytes efficiently, you use a chain of decorators. Here, Decorator reduces a complex task to a set of simple tasks, each of which is implemented independently. You could implement a massive efficiently-read-a-compressed-stream class, but it’s easier to break the problem into the following three distinct subproblems:
- Reading bytes.
- Making reads more efficient with buffering.
- Decompressing a stream of bytes.
Java solves the first problem with three classes. You start with FileInputStream, instantiated like this:
try
{ InputStream in = new FileInputStream( "file.name" );
}
catch( IOException e )
{ System.err.println( "Couldn't open file.name" );
e.printStackTrace();
}
You then add buffering with a decoration (or wrapping) strategy. You wrap the InputStream object with another InputStream implementer that buffers bytes. You ask the wrapper for a byte; it asks the wrapped stream for many bytes and returns the first one. The decorator wrapping goes like this:
try
{ InputStream in = new FileInputStream( "file.name" );
in = new BufferedInputStream( in );
}
catch( IOException e )
{ System.err.println( "Couldn't open file.name" );
e.printStackTrace();
}
Add decompression with another decorator, like so:
try
{ InputStream in = new FileInputStream( "file.name" );
in = new BufferedInputStream( in );
in = new GZipInputStream( in );
}
catch( IOException e )
{ System.err.println( "Couldn't open file.name" );
e.printStackTrace();
}
You can add additional filtering by adding additional decorators.
This solution is very flexible. You can mix and match the decorators to get the features you need. More important, each of the decorators is itself relatively simple, because it solves only one problem. Consequently, the decorators are easy to write, debug, and modify without impacting the rest of the system. I could change the buffering algorithm by rewriting BufferedInputStream, for example, and not have to touch any of the other decorators (or any of the code that used them). I could also add new filter functionality simply by implementing a new decorator. (Classes such as CipherInputStream were added to Java in this way.)
Though Decorator can effectively decompose a complex problem into simple pieces, the main intent of Decorator is to provide an alternative to implementation inheritance when you would be tempted to use extends to modify base-class behavior or add a few minor methods. In addition to the fragile-base-class problem discussed in Chapter 2, extends can add a lot of complexity when you need to change a lot of behavior. Consider Java’s collection classes. By design, the collection classes are not thread safe. Collections are not often accessed from nonsynchronized methods, so making them thread safe is just wasting CPU time as the program runs. You do, occasionally, need a thread-safe collection, however. Figure 4-7 shows how you’d have to extend the core collection classes to add thread safety. (The new classes are in gray.) I’ve had to double the number of concrete classes in the system.
Figure 4-7. Using implemenation inheritance to add thread safety to collections
Now what if I want to add unmodifiable collections, perhaps by adding a lock() method that causes all the methods that would normally modify the collection to start throwing exceptions? When I use implementation inheritance for this modification, I have to double the number of concrete classes again. Figure 4-8 shows the result.
Figure 4-8. Using implementation inheritance to add unmodifiability to collections
With an inheritance-based solution, I have to double the number of concrete classes every time I add a new feature, assuming that I want to support every possible combination of features. I can leave off some combinations, of course, but those combinations will probably be the ones I need two weeks from now.
The designers of the Collection classes solved the thread-safety problem with a Decorator. Here’s the code:
Collection threadSafe =
Collections.synchronizedCollection( new LinkedList() );
The Collections class looks something like this:
public class Collections // utility
{
//...
public static Collection synchronizedCollection(final Collection wrapped)
{ return new SynchronizedCollection(wrapped);
}
private static class SynchronizedCollection implements Collection
{ private Collection unsafe;
public SynchronizedCollection( Collection unsafe )
{ this.unsafe = unsafe;
}
public synchronized boolean add( Object toAdd )
{ return unsafe.add( toAdd );
}
public synchronized boolean remove( Object toAdd )
{ return unsafe.remove( toAdd );
}
// Implement synchronized version of all other Collection
// methods here ...
}
}
Collections is a utility class—a class made up of static “helper” methods that augment some existing class or library. Utilities are not Singletons because utilities don’t behave like objects; they’re just a bag full of functions. In this case, the Collections utility serves as a Concrete Factory of abstract Collection types. The ThreadSafeCollection class both is a Collection and wraps a Collection. The methods of ThreadSafeCollection are synchronized, however. Note that ThreadSafeCollection is private. The user of the Collections knows only that the object returned from unmodifiableCollection(...) implements Collection without allowing modifications to the backing collection. The concrete class name is unknown.
You can provide unmodifiable versions of a Collection with a similar wrapper, just as I did with the UnmodifiableTable class discussed at the beginning of this section.
You can get a synchronized unmodifiable collection with double wrapping, as follows:
Collection myList = new LinkedList();
//...
myList = Collections.synchronizedCollection
( Collections.unmodifiableCollection
( myList
)
);
The point of using Decorator is that I’ve added a grand total of two classes but accomplished the same thing that required 18 classes in an implementation-inheritance solution.
As I mentioned earlier, Java’s I/O system uses Decorator heavily. Figure 4-9 shows enough of Java’s input system that you can see the general structure. (I’ve left out the Reader classes, and so on.) I’ll discuss the Adapter pattern shown in this figure at the end of the current chapter. For now, I want to focus on Decorator.
Structurally, all the Decorators contain an instance of some class that implements the same interface as the Decorator itself. I think of Decorator as the big-fish/little-fish pattern, as shown here. The big fish (the Decorator) swallows the little fish (the Concrete Component), but they’re both fish (the Component). This is also the Gepetto (or Jonah) school of fish digestion: The little fish swims around happily in the big fish’s stomach until it’s disgorged. If a fisherman had caught the little fish just before it was swallowed (in other words, if you have a reference to a wrapped Component), then the fisherman could talk directly to the little fish by tying a tin can to the end of the fishing line and yelling into the can. (You can talk directly to a LineNumberInputStream that had been wrapped in another Decorator by keeping a reference to it, for example.) Finally, the bigger fish doesn’t know whether it has swallowed a Concrete Component or another Decorator. They’re all fish. Figure 4-10 shows the message flow during a write operation for the objects used in the previous InputStream example. Each of the Decorators gets its input from the wrapped object. This wrapped object could be another decorator or a Concrete Component; the Decorator knows nothing about that wrapped object other than the interface it implements. The order of wrapping is important. If the BufferedInputStream wrapped the PushBackInputStream in the earlier example, then a pushed-back character would effectively move to the end of the current buffer—the pushed-back characters would appear to be pushed back to random places in the input stream. Also note that since the PushBackInputStream wraps the LineNumberInputStream, pushing back a newline does not roll back the line number. On output, you want to compress before encrypting for efficiency reasons (the encryption algorithm is less efficient than the compression algorithm).
Also note that the unread(...) method that’s used to push back characters is not defined in InputStream. Consequently, you can’t access this functionality through an InputStream reference.
We’re now done with the data-storage layer. Whew!
Figure 4-9. The static structure of Decorator
Figure 4-10. The dynamic structure of Decorator
Adding SQL to the Mix
(This is not the dreaded SQL-interpreter section, so don’t skip over it.)
The Table classes are pretty useful in and of themselves. They provide a reasonably lightweight solution to the problem of an embedded database and could be better than something such as JDBC in situations where “lightweight” is mandatory—for database-like storage of configuration information without the overhead of a database, for example.
My main goal was to use a database as a persistence layer, however, and though I wanted the lightest-weight database I could get, I also wanted to be able to swap out that database with a more full-featured version should the need arise, all without having to modify any of my code. If I wrote code directly to the Table interface, then I’d have to modify that code to go to the JDBC interface required by a real database server.
It’s tempting to implement a JDBC layer directly in terms of the Table interface (or, put another way, to implement the SQL interpreter inside the JDBC classes). JDBC has more complexity than I needed for the current application, though, and JDBC imposes a relatively complex structure that I didn’t want to deal with quite yet. Consequently, I opted to go with a three-layer approach and wrap the Table with a simple SQL engine implemented with one primary class. This way I can focus on building the SQL interpreter without the complications of imposing the JDBC structure onto my interpreter. I also end up with a SQL-based table class that’s easier to use than the JDBC classes.
The interpreter itself is good sized (about 50KB of byte code), and it certainly imposes a performance penalty on the system. A SQL where clause has to be reinterpreted with every row of a query, for example, as compared to executing a small Java method (probably inlined by the HotSpot JVM) on every row.
On the other hand, any SQL database will introduce similar inefficiencies. I wasn’t doing all that much database access, and the ability to swap persistence layers without a rewrite was an important requirement.
I should also say that much of the work that I’ve done building the interpreter could be done using one of the Java “compiler-compilers” (such as JavaCUP at http://www.cs.princeton.edu/~appel/modern/java/CUP/ or JavaCC at https://javacc.dev.java.net/). Without getting too much into the technical details, I would certainly use a compiler-compiler for implementing any language that was at all complicated. In the case of the small SQL subset that I’m implementing, the structure of the language lends itself to a parser technology called recursive descent, which can usually be hand built in such a way as to be more efficient than the generic, table-driven parsers created by tools such as CUP. Since the language was small, and minimum size and maximum efficiency were two of my design goals, I opted for a handcrafted approach, thinking that I could do a better job by hand than the tools could do. This may not actually be the case, however. I haven’t implemented the language using a compiler-compiler and benchmarked the results against the hand-built version, so I really don’t know. In any event, the hand-built version provides a few nice examples of design patterns.
So, back to the salt mines.
SQL-Engine Structure
Figure 4-11 and Figure 4-12 show the static structure of (and design patterns used by) the SQL-engine layer. As before, you may want to bookmark these figures so you can refer to them later.
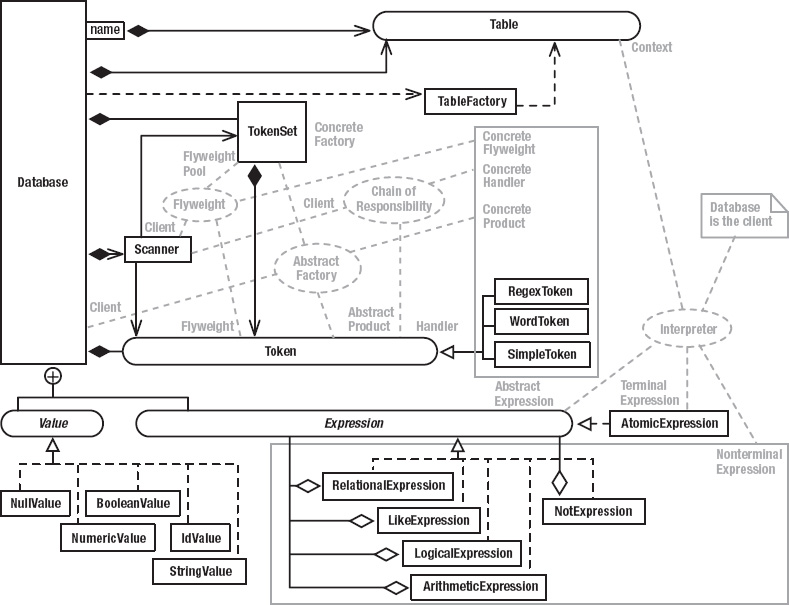
Figure 4-11. SQL engine and JDBC layers: design patterns
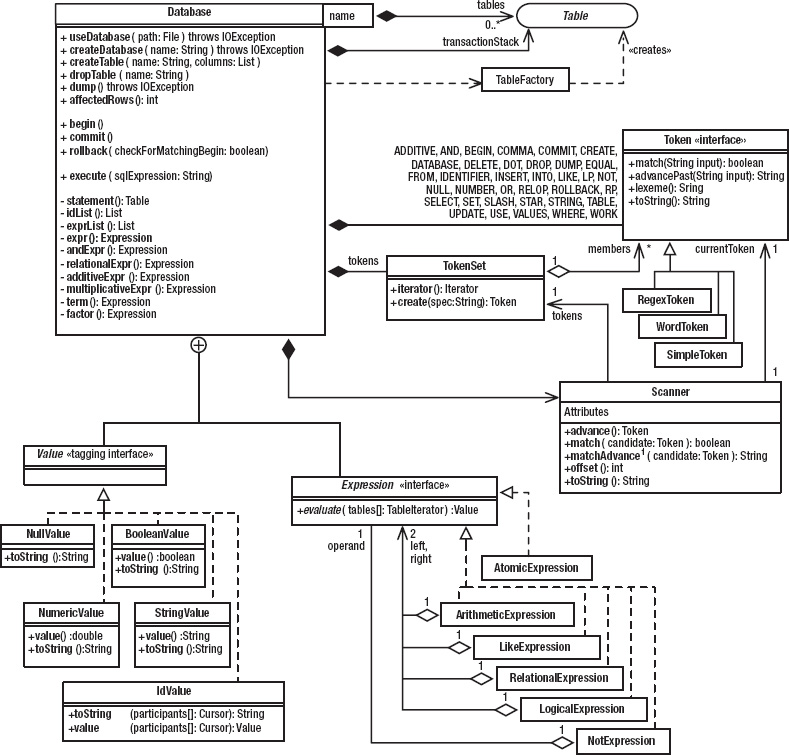
Figure 4-12. SQL engine and JDBC layers: static structure
Input Tokenization, Flyweight Revisited, and Chain of Responsibility
One of the requirements for a parser that is also a requirement for virtually any program that has to look at text-based input is input tokenization, or scanning, which is the process of breaking up a long input string into smaller pieces based on the way the input looks, and then representing those smaller strings as well-defined constants so you don’t have to constantly rescan them.
In compilers, a token is the smallest meaningful lexical unit of the input. For example, a keyword such as while is a token, as are each of the various operators. A one-to-one relationship does not necessarily exist between the actual input characters and the token type. Identifiers, for example, are all represented by an IDENTIFIER token, even though the identifiers may consist of different combinations of characters. Sometimes, semantically similar operators are grouped together into a single token. For example, the <, >, <=, ==, and != operators could be grouped together into a single RELATIONAL_OPERATOR token. A scanner inputs a stream of characters and outputs a stream of token objects that represent that input. Put another way, the scanner extracts substrings of the input and translates these substrings into tokens.
The token objects must be unique. Every time the scanner encounters an identifier in the input, for example, it returns the same IDENTIFIER object that it did the last time it encountered an identifier. This way you can tell whether you’ve read an identifier with a simple statement such as this:
if( currentToken == IDENTIFIER )
//...
An important attribute of the IDENTIFIER object (and of all tokens) is the input string that’s associated with the token, called a lexeme. Once you get an IDENTIFIER token, for example, you can figure out which identifier you just read by examining the associated lexeme.
Given that a scanner always returns the same token object for a given input sequence, the scanner is a good example of a Flyweight-pool manager. The token objects themselves are Flyweights—the lexeme is the extrinsic data—and the scanner repeatedly returns the same token object for a particular input sequence. (I discussed Flyweights in Chapter 4. Go back and read about them if the preceding didn’t make any sense.)
Java has a couple of generic tokenizers: java.util.StringTokenizer and java.io.StreamTokenizer. The former does only half of what a real scanner does: It breaks up the input into meaningful lexemes and return them to you, but it doesn’t translate the lexemes into tokens. The StreamTokenizer does return tokens, but it recognizes only four of them: TT_EOF (end of file), TT_EOL (end of line), TT_NUMBER (a number), and TT_WORD (anything else). TT stands for token type. In the case of TT_NUMBER and TT_WORD, the associated lexemes can be examined via the nval and sval fields of the tokenizer (not a great design decision—public accessors would be better).
The StreamTokenizer is too limited for a compiler application, however. I want unique tokens for every keyword, for example. Lumping all the keywords and identifiers in the input into a single TT_WORD token is too coarse grained to be useful. A real scanner would return IDENTIFIER, WHILE, IF, and ELSE tokens as appropriate.
So, let’s look at the more capable scanner used by the SQL engine. The first order of business is to define a set of tokens for the scanner to use. The individual tokens are responsible for recognizing the associated input lexemes. Tokens are always part of a set, so I didn’t want anyone to create one without connecting it to an associated token set. Consequently, a TokenSet object serves as a Token factory. You create tokens as follows:
TokenSet tokens = new TokenSet();
Token COMMA = tokens.create( "','" ),
INPUT = tokens.create( "INPUT" ),
IN = tokens.create( "IN" ),
IDENTIFIER = tokens.create( "[a-zA-Z_][a-zA-Z_0-9]*" );
The argument to create() is a regular expression that describes the lexeme associated with this token. Surrounding the expression with single-quote marks causes all characters to be treated literally (rather than as regular-expression metacharacters. That is, the specification "'...'" is treated identically to the regular expression "Q...E". The closing quote is optional.
The TokenSet participates in several design patterns, but here it’s in the Concrete Factory role of Abstract Factory. (There is no interface in the Abstract Factory role.) Token is the Abstract-Product interface, and implementers of the Token interface (which we’ll look at shortly) are the Concrete Products.
The client class (the Database) doesn’t know the actual classes of the Concrete Products: the Token objects returned from create(...). Nonetheless, the system supports three distinct Token subclasses that differ only in how efficient they are in processing the input string. That is, it’s the job of each Token object to look at the input stream and tell whether the next few input characters match a lexeme associated with that token.
- A
RegexTokenuses Java’s regular-expression system to match the input stream against the specification, so it is powerful but relatively inefficient. It is case insensitive. - A
SimpleTokenmatches tokens for which there is only one possible lexeme. Its recognizer, which just performs a literal match of the pattern against the input string, is by far the most efficient of the three token types. To make it as efficient as possible, the recognizer for aSimpleTokenis not case insensitive (unlike the other twoTokentypes). This inconsistency is, in some ways, a design flaw, but I was loath to slow down a recognizer that’s used primarily for finding punctuation and operators. The factory uses aSimpleTokenwhen the specifier passed tocreate(...)is either surrounded by single quotes or contains no regular-expression metacharacters. - A
WordTokenis aSimpleTokenthat must be terminated at a “word boundary.” (Either it must be followed by a character that’s not legal in a Java identifier or it must be the last token in the input string.) The regular-expression subsystem isn’t used for word tokens. The tokens are recognized in a case-insensitive way.
The TokenSet factory simplifies token creation by deciding which of the three Token implementers to create, based on what the specification looks like. In particular, if the string contains any of the regular-expression metacharacters and isn’t surrounded by single-quote marks, RegexToken objects are created. In the case of quoted strings or strings that don’t contain metacharacters, the factory creates a WordToken if the specification ends in a character that’s legal in a Java identifier; otherwise, it creates a SimpleToken.
Given a conflict in the lexemes (in other words, two Token specifications can match the same input sequence), the token that’s created first takes precedence. In the earlier example, the INPUT token must be created before the IN token or the string "input" will be processed incorrectly. (An IN token will be recognized, and then an IDENTIFIER with the value “put” is recognized.) Similarly, IDENTIFIER has to come last; otherwise, it would suck up all the keywords.
The TokenSet reification of Abstract Factory omits the interface in the Abstract-Factory role. The downside of this incomplete reification is that you have to modify the source code for the TokenSet class if you add a new token type. You can create a token type simply by extending Token, of course, but you won’t be able to create instances of your token via the factory unless you modify the factory as well. My main goal with this particular factory was to simplify the code, however. I just wanted to declare tokens without worrying about which Token subclass was needed for a particular input specification. Since I don’t expect to add new token types, the lack of expansibility isn’t a large concern (famous last words).
Moving onto the code, the Token class is in Listing 4-20, and the three implementations are in Listing 4-21 (SimpleToken.java), Listing 4-22 (WordToken.java), and Listing 4-23 (Regex-Token.java). SimpleToken (Listing 4-21) is the simplest, so let’s start there. The constructor is passed a template input sequence. The match(String input) method returns true if the first characters on the input line match that template. Finally, lexeme() returns the most recently recognized lexeme.
The WordToken class in Listing 4-22 is only marginally more complicated. The match(...) method checks the input against the pattern, but it also looks to make sure that the character that follows couldn’t occur in a Java identifier (in other words, is on a “word” boundary).
The RegexToken class in Listing 4-23 is the most complicated because it uses Java’s regex package. It’s a straightforward use of the Pattern and Matcher classes, but note that the pattern is compiled only once, when the RegexToken is created. As is the case in the other Token implementation, patterns are recognized in a case-insensitive way.
Listing 4-20. Token.java
1 package com.holub.text;
2
3 public interface Token
4 { boolean match (String input, int offset);
5 String lexeme( );
6 }
Listing 4-21. SimpleToken.java
1 package com.holub.text;
2
3 import java.util.*;
4 import java.util.regex.*;
5
6 /** Matches a simple symbol that doesn't have to be on a "word"
7 * boundary, punctuation, for example. SimpleToken
8 * is very efficient but does not recognize characters in
9 * a case-insensitive way, as does {@link WordToken} and
10 * {@link RegexToken}.
11 */
12
13 public class SimpleToken implements Token
14 {
15 private final String pattern;
16
17 /** Create a token.
18 * @param description a string that defines a literal-match lexeme.
19 */
20
21 public SimpleToken( String pattern )
22 { this.pattern = pattern.toLowerCase();
23 }
24
25 public boolean match( String input, int offset )
26 { return input.toLowerCase().startsWith( pattern, offset );
27 }
28
29 public String lexeme() { return pattern; }
30 public String toString(){ return pattern; }
31 }
Listing 4-22. WordToken.java
1 package com.holub.text;
2
3 import java.util.*;
4 import java.util.regex.*;
5
6 /** Recognize a token that looks like a word. The match
7 * is case insensitive. To be recognized, the input
8 * must match the pattern passed to the constructor
9 * and must be followed by a non-letter-or-digit.
10 * The returned lexeme is always all-lowercase
11 * letters, regardless of what the actual input
12 * looked like.
13 */
14
15 public class WordToken implements Token
16 {
17 private final String pattern;
18
19 /** Create a token.
20 * @param description a regular expression
21 * ({@linkplain java.util.Pattern see}) that describes
22 * the set of lexemes associated with this token.
23 */
24
25 public WordToken( String pattern )
26 { this.pattern = pattern.toLowerCase();
27 }
28
29 public boolean match(String input, int offset)
30 {
31 // Check that the input matches the patter in a
32 // case-insensitive way. If you don't want case
33 // insenstivity, use the following, less-complicated code:
34 //
35 // if( !input.toLowerCase().startsWith(pattern, offset) )
36 // return false;
37
38 if( (input.length() - offset) < pattern.length() )
39 return false;
40
41 String candidate = input.substring( offset,
42 offset+pattern.length() );
43 if( !candidate.equalsIgnoreCase(pattern) )
44 return false;
45
46 // Return true if the lexeme is at the end of the
47 // input string or if the character following the
48 // lexeme is not a letter or digit.
49
50 return ((input.length() - offset) == pattern.length())
51 || (!Character.isLetterOrDigit(
52 input.charAt(offset + pattern.length()) ));
53 }
54
55 public String lexeme() { return pattern; }
56 public String toString(){ return pattern; }
57 }
Listing 4-23. RegexToken.java
1 package com.holub.text;
2
3 import java.util.*;
4 import java.util.regex.*;
5
6 /** Matches a token specified using a regular expression
7 */
8
9 public class RegexToken implements Token
10 {
11 private Matcher matcher;
12 private final Pattern pattern;
13 private final String id;
14
15 /** Create a token.
16 * @param description a regular expression
17 * ({@linkplain java.util.Pattern see}) that describes
18 * the set of lexemes associated with this token.
19 * The expression is case insensitive, so the
20 * expression "ABC" also recognizes "abc".
21 */
22 public RegexToken(String description)
23 { id = description;
24 pattern = Pattern.compile(description, Pattern.CASE_INSENSITIVE);
25 }
26
27 public boolean match(String input, int offset)
28 { matcher = pattern.matcher( input.substring(offset) );
29 return matcher.lookingAt();
30 }
31
32 public String lexeme() { return matcher.group(); }
33 public String toString(){ return id; }
34 }
The tokenSet class is in Listing 4-24. Its members field (Listing 4-24, line 8) holds the members of the Flyweight pool (the previously created tokens).
The create(...) method (Listing 4-24, line 39) adds all the tokens that it creates to this collection. It also decides which subclass of Token to create by examining the input specification.
You can get an java.util.Iterator across all the Flyweights in the pool by calling iterator() (Listing 4-24, line 15). Note that this iterator is guaranteed to present the Token objects in the same order that they were added to the pool. This guaranteed ordering will be important when I implement the scanner, shortly.
Listing 4-24. TokenSet.java
1 package com.holub.text;
2
3 import java.util.*;
4 import java.util.regex.*;
5
6 public class TokenSet
7 {
8 private Collection members = new ArrayList();
9
10 /** Return an iterator across the Token pool. This iterator
11 * is guaranteed to return the tokens in the order that
12 * {@link create()} was called.
13 */
14
15 public Iterator iterator()
16 { return members.iterator();
17 }
18
19 /**********************************************************************
20 * Create a Token based on a specification.
21 * <p>
22 * An appropriate token type is chosen by examining the input
23 * specification. In particular, a {@link RegexToken} is
24 * created unless the input string contains no regular-expression
25 * metacharacters (<em>\[]{</em>()$^*+?|}) or starts with a single-quote
26 * mark ('). In this case, a
27 * {@link WordToken} is created if the specification ends
28 * in any character that could occur in a Java identifier;
29 * otherwise a {@link SimpleToken} is created.
30 * If a string that starts with a single-quote mark also
31 * ends with a single-quote mark, the end-quote mark
32 * is discarded. The end-quote mark is optional.
33 * <p>
34 * Tokens are always extracted
35 * from the beginning of a String, so the characters that
36 * precede the token are irrelevant.
37 */
38
39 public Token create( String spec )
40 { Token token;
41 int start = 1;
42
43 if( !spec.startsWith("'") )
44 { if( containsRegexMetacharacters(spec) )
45 {
46 token = new RegexToken( spec );
47 members.add(token);
48 return token;
49 }
50
51 --start; // don't compensate for leading quote
52
53 // fall through to the "quoted-spec" case
54 }
55
56 int end = spec.length();
57
58 if( start==1 && spec.endsWith("'") ) // saw leading '
59 --end;
60
61 token = Character.isJavaIdentifierPart(spec.charAt(end-1))
62 ? (Token) new WordToken ( spec.substring(start,end) )
63 : (Token) new SimpleToken( spec.substring(start,end) )
64 ;
65
66 members.add( token );
67 return token;
68 }
69
70 /** Return true if the string argument contains any of the
71 * following characters: \[]$^*+?|()
72 */
73 private static final boolean containsRegexMetacharacters(String s)
74 { // This method could be implemented more efficiently,
75 // but its not called very often.
76 Matcher m = metacharacters.matcher(s);
77 return m.find();
78 }
79 private static final Pattern metacharacters =
80 Pattern.compile("[\\\[\]$\^*+?|()]");
81 }
The Scanner: Chain of Responsibility
The Scanner class (Listing 4-25) uses the TokenSet to implement a scanner. You create a scanner for a particular token set like this:
TokenSet tokens = new TokenSet();
Token COMMA = tokens.create( "','" ),
INPUT = tokens.create( "INPUT" ),
IN = tokens.create( "IN" ),
IDENTIFIER = tokens.create( "[a-zA-Z_][a-zA-Z_0-9]*" );
Scanner tokenizer = new Scanner( tokenSet, inputReader );
The Scanner looks for tokens in the specified set, reading characters from the specified Reader. The interface to the Scanner is straightforward, but it may be surprising if you’ve never built a parser. Parsers, in general, are more interested in seeing if the next input token (called the lookahead token) is what they expect than they are in actually reading the next token (removing it from the input). Consequently, the Scanner interface does not have a getToken() method, simply because such a method wouldn’t be used. You use the scanner more or less like this:
TokenSet tokens = new TokenSet();
Token DESIRED_TOKEN = tokens.create(...);
Token DIFFERENT_TOKEN = tokens.create(...);
//...
Reader inputReader = ...;
Scanner tokenizer = new Scanner( tokens, inputReader );
//...
if( tokenizer.match(DESIRED_TOKEN) )
{ Token t = tokenizer.advance();
doSomething( t.lexeme(); ) // or use DESIRED_TOKEN.lexeme()
}
else if( tokenizer.match(DIFFERENT_TOKEN) )
{ //...
}
//...
The match(...) method just checks to see if the desired token is the next one in the input stream. The advance() method actually reads (and returns) the next input token. This match/advance strategy is much more efficient than reading the token because you’d otherwise have to repetitively push uninteresting tokens back onto the input.
Two convenience methods are provided to simplify scanning: First, matchAdvance(Token) (Listing 4-25, line 111) combines the match and advance operations. If the token argument matches the current token, the scanner advances to the next token and returns the current lexeme. Otherwise, the scanner does nothing and returns null. Second, the required(Token) method (Listing 4-25, line 127) is a more forceful version of matchAdvance(). It throws a ParseFailure exception if the specified token isn’t the current token.
The Scanner is implemented in Listing 4-25. From the design-patterns perspective, the interesting code is the for loop on line 76. I get an iterator across the entire token set and then ask each token in turn whether its lexeme specification matches the current input sequence. The work of detecting the match is delegated to the Token objects, each of which checks for a match in the most efficient way possible.
The design pattern here is Chain of Responsibility (sometimes called Chain of Command). The idea is to handle an event (or in this case, an input sequence) by passing it in turn to a set of Command objects. Those objects that are able to handle the event do so. The object that does the routing can’t predict which handler (some object in the pattern’s Handler role) will handle the event (or input), and usually doesn’t care, as long as that event (or input) gets handled. It’s important to note that the list of handlers is put together at runtime. The Client has no way to know at compile time which handlers will be invoked in which sequence.
This characteristic is important in the current context because the order in which Token objects attempt to match themselves against the input is important. In the SQL engine, for example, you have an IN and also an INPUT token. It’s important that the Scanner looks for a match of IN before it looks for INPUT; otherwise it will never find the latter. Similarly, it’s important that the IDENTIFIER token, which is declared like this:
IDENTIFIER = tokens.create( "[a-zA-Z_0-9/\\:~]+" );
be at the end of the list of tokens, because the specified regular expression will also match all the keywords. Were IDENTIFIER not declared last, keywords would be incorrectly recognized as identifiers.
The Scanner stops routing the input to Token objects once a Handler (a Token) recognizes an input sequence. The design pattern doesn’t require this behavior, however. Several Handlers could all process all or part of the same event. Similarly, Chain of Responsibility doesn’t require a separate “router” object that controls who gets a crack at the input. A Handler may keep around a pointer to its own successor, for example, and handle the routing locally.
Listing 4-25. Scanner.java
1 package com.holub.text;
2
3 import java.util.Iterator;
4 import java.io.*;
5 import com.holub.text.ParseFailure;
6
7 public class Scanner
8 {
9 private Token currentToken = new BeginToken();
10 private BufferedReader inputReader = null;
11 private int inputLineNumber = 0;
12 private String inputLine = null;
13 private int inputPosition = 0;
14
15 private TokenSet tokens;
16
17 public Scanner( TokenSet tokens, String input )
18 { this( tokens, new StringReader(input) );
19 }
20
21 public Scanner( TokenSet tokens, Reader inputReader )
22 { this.tokens = tokens;
23 this.inputReader =
24 (inputReader instanceof BufferedReader)
25 ? (BufferedReader) inputReader
26 : new BufferedReader( inputReader )
27 ;
28 loadLine();
29 }
30
31 /** Load the next input line and adjust the line number
32 * and inputPosition offset.
33 */
34 private boolean loadLine()
35 { try
36 { inputLine = inputReader.readLine();
37 if( inputLine != null )
38 { ++inputLineNumber;
39 inputPosition = 0;
40 }
41 return inputLine != null;
42 }
43 catch( IOException e )
44 { return false;
45 }
46 }
47
48 /** Return true if the current token matches the
49 * candidate token.
50 */
51 public boolean match( Token candidate )
52 { return currentToken == candidate;
53 }
54
55 /** Advance the input to the next token and return it.
56 * This token is valid only until the next advance() call.
57 */
58 public Token advance() throws ParseFailure
59 { try
60 {
61 if( currentToken != null ) // not at end of file
62 {
63 inputPosition += currentToken.lexeme().length();
64 currentToken = null;
65
66 if( inputPosition == inputLine.length() )
67 if( !loadLine() )
68 return null;
69
70 while( Character.isWhitespace(
71 inputLine.charAt(inputPosition)) )
72 if( ++inputPosition == inputLine.length() )
73 if( !loadLine() )
74 return null;
75
76 for( Iterator i = tokens.iterator(); i.hasNext(); )
77 { Token t = (Token)(i.next());
78 if( t.match(inputLine, inputPosition) )
79 { currentToken = t;
80 break;
81 }
82 }
83
84 if( currentToken == null )
85 throw failure("Unrecognized Input");
86 }
87 }
88 catch( IndexOutOfBoundsException e ){ /* nothing to do */ }
89 return currentToken;
90 }
91
92 /* Throws a ParseException object initialized for the current
93 * input position. This method lets a parser that's using the
94 * current scanner report an error in a way that identifies
95 * where in the input the error occurred.
96 * @param message the "message" (as returned by
97 * {@link java.lang.Throwable.getMessage}) to attach
98 * to the thrown <code>RuntimeException</code> object.
99 * @throws ParseFailure always.
100 */
101 public ParseFailure failure( String message )
102 { return new ParseFailure(message,
103 inputLine, inputPosition, inputLineNumber);
104 }
105
106 /** Combines the match and advance operations. Advance automatically
107 * if the match occurs.
108 * @return the lexeme if there was a match and the input was advanced,
109 * null if there was no match (the input is not advanced).
110 */
111 public String matchAdvance( Token candidate ) throws ParseFailure
112 { if( match(candidate) )
113 { String lexeme = currentToken.lexeme();
114 advance();
115 return lexeme;
116 }
117 return null;
118 }
119
120 /** If the specified candidate is the current token,
121 * advance past it and return the lexeme; otherwise,
122 * throw an exception with the error message
123 * "XXX Expected".
124 * @throws ParseFailure if the required token isn't the
125 * current token.
126 */
127 public final String required( Token candidate ) throws ParseFailure
128 { String lexeme = matchAdvance(candidate);
129 if( lexeme == null )
130 throw failure(
131 """ + candidate.toString() + "" expected.");
132 return lexeme;
133 }
134
135 /*--------------------------------------------------------------*/
136 public static class Test
137 {
138 private static TokenSet tokens = new TokenSet();
139
140 private static final Token
141 COMMA = tokens.create( "'," ),
142 IN = tokens.create( "'IN'" ),
143 INPUT = tokens.create( "INPUT" ),
144 IDENTIFIER = tokens.create( "[a-z_][a-z_0-9]*" );
145
146 public static void main(String[] args) throws ParseFailure
147 {
148 assert COMMA instanceof SimpleToken: "Factory Failure 1";
149 assert IN instanceof WordToken : "Factory Failure 2";
150 assert INPUT instanceof WordToken : "Factory Failure 3";
151 assert IDENTIFIER instanceof RegexToken : "Factory Failure 4";
152
153 Scanner analyzer=new Scanner(tokens, ",aBc In input inputted" );
154
155 assert analyzer.advance() == COMMA : "COMMA unrecognized";
156 assert analyzer.advance() == IDENTIFIER : "ID unrecognized";
157 assert analyzer.advance() == IN : "IN unrecognized";
158 assert analyzer.advance() == INPUT : "INPUT unrecognized";
159 assert analyzer.advance() == IDENTIFIER : "ID unrecognized 1";
160
161 analyzer = new Scanner(tokens, "Abc IN
Cde");
162 analyzer.advance(); // advance to first token.
163
164 assert( analyzer.matchAdvance(IDENTIFIER).equals("Abc") );
165 assert( analyzer.matchAdvance(IN).equals("in") );
166 assert( analyzer.matchAdvance(IDENTIFIER).equals("Cde") );
167
168 // Deliberately force an exception toss
169 analyzer = new Scanner(tokens, "xyz
abc + def");
170 analyzer.advance();
171 analyzer.advance();
172 try
173 { analyzer.advance(); // should throw an exception
174 assert false : "Error Detection Failure";
175 }
176 catch( ParseFailure e )
177 { assert e.getErrorReport().equals(
178 "Line 2:
"
179 + "abc + def
"
180 + "____^
" );
181 }
182
183 System.out.println("Scanner PASSED");
184
185 System.exit(0);
186 }
187 }
188 }
One anti-example of the Chain-of-Responsibility pattern (that is, an example that demonstrates the pattern’s shortcomings) is the Windows event model. A Windows UI is a runtime hierarchy of objects. Consider a typical dialog box with a text field on it. Figure 4-13 shows the associated runtime object hierarchy. Now imagine you’re typing in the text field and accidentally hit a typically easy-to-remember “hot key” such as Ctrl+Alt+Shift+F12. As you can see by following the sequence of arrows, the key-pressed event can go to many potential handlers (from the text control to its parent window (the Dialog Frame) to its parent (the MDI Child) to its parent (the Main Frame) to the menu bar, to each menu on the menu bar to menu item on that menu bar. Finally, when the key-pressed event gets to the last menu item on the last menu on the menu bar, it’s discarded. The same sequence will happen every time the mouse moves one pixel. That’s a lot of motion, but no action. This is one reason why Java abandoned this message-routing mechanism with Java 1.1 in favor of its Observer-based system.
Figure 4-13. Chain of Command in a Windows UI
Java has lots of good examples of Chain of Responsibility. One of the better ones is the servlet filter. A servlet is a small program that’s invoked automatically by the web server in response to an HTTP Post or Get request. Typical servlets are passed data that’s specified in an HTML form, and they create a HTML page that’s displayed on the client-side browser in response to that form submission. Once you’ve written a few servlets, you come to realize that they often duplicate the code of other servlets. For example, authentication is a commonplace activity in a servlet. The servlet may read a username and password from the submitted form data, for example, and refuse to proceed with a transaction if the password isn’t correct. Alternatively, a servlet may check the session data (a packet of information that’s associated with the user) to assure that a given user is indeed logged in. Duplicating this authentication code in every servlet increases the complexity of the system as a whole and also tends to create lack-of-consistency problems in the user interface. (Different servlets may handle the same problem in different ways.) Other common problems include things such as database lookup. That is, the session data may contain a key that you need to use to get additional information out of a server-side database. This lookup may occur in several servlets, which can cause serious maintenance problems if the data dictionary needs to change, for example. By the same token, information in the session data may have to be stored persistently in a database.
Chain of Responsibility, as reified in the servlet filter, solves all these problems. Figure 4-14 shows the general flow of data through a system of servlets and filters as some form is being processed. The first filter does authentication. If the user has logged in, this filter is just a pass through, doing nothing but passing its input to the next filter in the chain. The second filter handles persistent session information—information that resides in a database rather than information that is created during the course of the session—performing all the required database lookup.
You should note two important points: First, the filters are put into place by the web server, not the servlet. As far as the servlet is concerned, the user is authenticated, and the database information is fetched and stored by magic. Second, each filter handles its part of the current operation and then either allows the next object in the chain of responsibility (the next Filter or the servlet itself) to do additional work or short-circuits the process. Runtime configuration and the relative autonomy of the Handlers are both defining characteristics of the Chain of Responsibility.
One other problem I’ve solved with Chain of Responsibility deserves mention: user-input processing. You saw earlier how you can use the Builder pattern to isolate UI generation from the underlying “business object,” but it’s sometimes awkward to use Builder on the input side. For example, you can use Builder to ask an object to build an HTML representation of itself for insertion into a generated page (or build an XML representation of itself that’s passed through a XSLT translator to build the HTML). In fact, several objects may contribute user interfaces to the page in this way. (A UI could be built, in fact, by a series of servlet filters, each of which augments a generated HTML page by adding a UI for a particular object.)
The page is served, the user hits the submit button, and the form data comes back to another servlet, but then what? You don’t really want the servlet to know how to talk to all the objects that contributed to the original page because it’s too much of a maintenance problem. If those objects change their user interfaces in some way, you need to change the servlet as well. These coupling relationships are too tight.
Chain of Responsibility solves the coupling problem. All that the servlet (or some filter) needs to do is keep a list of the objects that contributed to the UI. The servlet passes those objects the complete set of form-input data, and the objects parse out of that list whatever is interesting to them. Since the objects built the form to begin with, the object can generate unique field names on the output side, and the object can search for these same names on the input side. The actual servlet is completely generic with respect to the UI: It just keeps a list of contributing objects, gets HTML from the objects, and routes the form data back to the objects on the list. It has no idea what the objects actually do, and the interface is extremely simple. More important, you can make massive changes to the objects without impacting the code that comprises the servlet at all.
Figure 4-14. Chain of Command in a Windows UI
The ParseFailure Class
Finishing up loose ends before moving onto the SQL interpreter itself, the one class you haven’t looked at yet is the ParseFailure class in Listing 4-26. (I was going to call this class ParserException, but that name was too much like java.text.ParseException.)
Other than the obvious use of having something to throw when a parse error occurs, the ParseFailure object is interesting in the way that I use it to eliminate getter functions from the Scanner class in order to reduce coupling relationships between the Scanner and the rest of the program. Rather than using a getter to find out where on the line that an error occurs, that information is carried around by the exception object itself. This way, you can catch a parse error and print a reasonable error message without having to talk to the Scanner that detected the error at all. The ParseFailure object carries around the input line, line number, and position-on-the-line information, and you can generate a contextual error message that looks like this:
Context-specific message
Line 17:
a = b + @ c;
________^
try
{ // ...
}
catch( ParseFailure e )
{ System.err.println( e.getMessage() );
System.err.println( e.getErrorReport() );
}
I’ve provided no getter methods (in the sense of methods that access internal state data such as the line number or offset to the error position), simply because they aren’t required. Remember the golden rule of implementation hiding: don’t ask for the information that you need to do the work; rather, ask the object that has the information to do the work for you.
One final issue exists: Not only is it reasonable for a Scanner to throw ParseFailure objects, but it’s reasonable for the parser that uses the scanner to throw them as well. The scanner throws a ParseFailure if the input sequence matches no known token, for example. The parser needs to throw a ParseFailure if it finds malformed SQL.
Since the ParseFailure object contains information that’s provided by the scanner (the line number and input position), then it makes sense for Scanner objects to act as ParseFailure factories. Rather than having the parser extract line number and position information from the Scanner in order to create a parser-related error message, the parser requests a ParseFailure object that encapsulates that information.
The Scanner, then, is a ParseFailure Factory. When the parser encounters an error at the language (as compared to the lexical-analysis) level, it can throw a ParseFailure object that indicates where the error occurred with code like the following:
Scanner lexicalAnalyzer = new Scanner( ... );
//...
if( some_parser_error_occurs() )
{ throw lexicalAnalyzer.failure("Parser-related error message");
}
Listing 4-26. ParseFailure.java
1 package com.holub.text;
2
3 /** Thrown in the event of a Scanner (or parser) failure
4 */
5
6 public class ParseFailure extends Exception
7 {
8 private final String inputLine;
9 private final int inputPosition;
10 private final int inputLineNumber;
11
12 public ParseFailure( String message,
13 String inputLine,
14 int inputPosition,
15 int inputLineNumber )
16 {
17 super( message );
18 this.inputPosition = inputPosition;
19 this.inputLine = inputLine;
20 this.inputLineNumber = inputLineNumber;
21 }
22
23 /** Returns a String that shows the current input line and a
24 * pointer indicating the current input position.
25 * In the following sample, the input is positioned at the
26 * @ sign on input line 17:
27 * <PRE>
28 * Line 17:
29 * a = b + @ c;
30 * ________^
31 * </PRE>
32 *
33 * Note that the official "message" [returned from
34 * {@link Throwable#getMessage()}] is not included in the
35 * error report.
36 */
37
38 public String getErrorReport()
39 {
40 StringBuffer b = new StringBuffer();
41 b.append("Line ");
42 b.append(inputLineNumber + ":
");
43 b.append(inputLine);
44 b.append("
");
45 for( int i = 0; i < inputPosition; ++i)
46 b.append("_");
47 b.append("^
");
48 return b.toString();
49 }
50 }
The Database Class
The Database encapsulates the SQL interpreter. Its main job is to transform a set of SQL statements into calls that a Table understands. By introducing SQL into the mix, however, you free the program from needing to know anything about Table objects.
Using the Database
You can use a Database in one of two ways: as a stand-alone class that represents a SQL database or as a Decorator that wraps a com.holub.database.Table temporarily so that you can access the table using SQL. The only difference between these two uses is the constructor you use. Open a stand-alone database like this:
Database standalone = new Database("/src/com/holub/database/test");
The (optional) argument specifies the path to a directory that represents the database itself. (Tables are stored as individual files.) Convenience constructors let you specify the path with a File or URI object instead of a String. Also, you do not have a no-arg constructor that just puts tables into the current directory. A SQL USE DATABASE directoryName request causes the Database to use the named directory instead of the one specified in the constructor.
To use the Database as a Decorator of an existing table (or set of tables), use the following alternative constructor:
Table table1 = TableFactory.create( "table1", ... );
Table table2 = TableFactory.create( "table2", ... );
//...
Database wrapped = new Database( "/src/com/holub/database/test",
new Table[]{ table1, table2 } );
This isn’t a full-blown Gang-of-Four Decorator since Database doesn’t implement the Table interface. It does satisfy the intent of the pattern, however, in that it allows you to augment the Table interface by adding SQL support.
Once you’ve created the database, you talk to it using a single method that takes a String argument that specifies a single SQL command. For example, the following code (taken from the Database class’s unit test) reads a series of SQL statements from a file and executes them:
Database d = new Database();
BufferedReader sqlScript = new BufferedReader(
new FileReader( "Database.test.sql" ));
String test;
while( (test = sqlScript.readLine()) != null )
{ test = test.trim();
if( test.length() == 0 ) // ignore blank lines
continue;
System.out.println("Parsing: " + test);
Table result = d.execute( test ); // Result sets come back in a Table
if( result != null ) // it was a SELECT of some sort
System.out.println( result.toString() );
}
Listing 4-27 shows the SQL that the test-script uses, but it’s pretty standard stuff.
Though you can do everything through the execute(...) method, Database provides a few additional methods that let you create, load, and drop tables; dump tables to disk; and manage transactions. I’ve listed these methods in Table 4-1. An exception toss that occurs when processing a SQL expression submitted to execute() causes an automatic rollback as a side effect. This automatic-rollback behavior is not implemented by the methods in Table 4-1, however. If you use these methods, you’ll have to catch any exceptions manually and call rollback(...) or commit(...) explicitly.
Table 4-1. Methods of the Database Class
| Method | Description |
int affectedRows() |
Returns the number of rows that were affected by the most recent execute(java.lang.String) call. |
void begin() |
Begins a transaction. |
void commit(boolean checkForMatchingBegin) |
Commits a transaction. |
void createDatabase(String name) |
Creates a database by opening the indicated directory. |
void createTable(String name, List columns) |
Creates a new table. |
void dropTable(String name) |
Destroys both internal and external (on the disk) versions of the specified table. |
void dump() |
Flushes to the persistent store (for example, disk) all tables that are “dirty” (which have been modified since the database was last committed). |
Table execute(String expression) |
Executes a SQL statement. |
void rollback(boolean checkForMatchingBegin) |
Rolls back a transaction. |
void useDatabase(File path) |
Uses an existing “database.” |
Listing 4-27. Database.Test.sql
1 create database Dbase
2
3 create table address
4 (addrId int, street varchar, city varchar,
5 state char(2), zip int, primary key(addrId))
6
7 create table name(first varchar(10), last varchar(10), addrId integer)
8
9 insert into address values( 0,'12 MyStreet','Berkeley','CA','99999')
10 insert into address values( 1, '34 Quarry Ln.', 'Bedrock' , 'XX', '00000')
11
12 insert into name VALUES ('Fred', 'Flintstone', '1')
13 insert into name VALUES ('Wilma', 'Flintstone', '1')
14 insert into name (last,first,addrId) VALUES('Holub','Allen',(10-10*1))
15
16 update address set state = "AZ" where state = "XX"
17 update address set zip = zip-1 where zip = (99999*1 + (10-10)/1)
18
19 insert into name (last,first) VALUES( 'Please', 'Delete' )
20 delete from name where last like '%eas%'
21
22 select * from address
23 select * from name
24
25 select first, last from name where last = 'Flintstone'
26 select first, last, street, city, zip
27 from name, address where name.addrId = address.addrId
28
29 create table id (addrId, description)
30 insert into id VALUES (0, 'AddressID=0')
31 insert into id VALUES (1, 'AddressID=1')
32 select first, last, street, city, zip, description
33 from name, address, id
34 WHERE name.addrId = address.addrId AND name.addrId = id.addrId
35
36 drop table id
37
38 select first, last from name where last='Flintstone'
39 AND first='Fred' OR first like '%lle%'
40
41 create table foo (first, second, third, fourth)
42 insert into foo (first,third,fourth) values(1,3,4)
43 update foo set fourth=null where fourth=4
44 select * from foo
45 select * from foo where second=NULL AND third<>NULL
46 drop table foo
47
48 select * into existing_copy from existing
49 select * from existing_copy
50
51 create table foo (only)
52 insert into foo values('xxx')
53 begin
54 insert into foo values('should not see this')
55 rollback
56 select * from foo
57
58 begin
59 insert into foo values('yyy')
60 select * from foo
61 begin
62 insert into foo values('should not see this')
63 rollback
64 begin
65 insert into foo values('zzz')
66 select * from foo
67 commit
68 select * from foo
69 commit
70 select * from foo
71 insert into foo values('end')
72 select * from foo
73 drop table foo
74
75 create table foo (only)
76 begin
77 insert into foo values('a')
78 insert into foo values('b')
79 begin
80 insert into foo values('c')
81 insert into foo values('d')
82 select * from foo
83 commit
84 rollback
85 select * from foo
86
87 drop table foo
The Proxy Pattern
The first part of the Database class is in Listing 4-28. Of the fields at the top of the listing, the tables Map (line 41) holds the tables that comprise the database. They’re indexed by table name. tables is declared as a Map, but it actually holds a specialization of HashMap (TableMap, declared on line 52).
This specialization adds table-specific behavior to a standard HashMap. First, the get() override uses lazy instantiation: When a specific table is first requested, it’s loaded from the disk using the CSV Builder. Database methods can act as if all the tables were preloaded into a standard Map, but the tables are actually loaded when they’re requested for the first time.
The other modification to the standard HashMap is a put() override, which handles a transaction-related problem that’s a side effect of lazy instantiation. The current transaction-nesting level is stored in transactionLevel field declared on line 46. It’s incremented by a BEGIN operation and decremented by a COMMIT or ROLLBACK. The code that does the commit/rollback assumes that all the tables in the Map are at the same transaction level. That is, it just commits or rolls back all of them, all at once. If you begin a transaction and then use a table that you haven’t used before, that table will not have had a begin() issued against it, yet. The loop in put() solves the problem by issuing begin() requests against the newly loaded table.
Since I don’t use it and didn’t want to rewrite it, I also overloaded putAll() to throw an UnsupportedOperationException(). I’m playing pretty fast and loose with the class contract here. I wouldn’t argue if someone flagged this change as a defect in a code review and forced me to provide a putAll(), but the TableMap is a private inner class—so it can’t be extended or used from outside the class definition—I decided that the deviation from the contract was acceptable. I would not make a change of this magnitude if the class were globally accessible.
The remainder of the methods in the Map interface just map through to the contained Map object.
Listing 4-28. Database.java: Private Data and the TableMap
1 package com.holub.database;
2
3 import java.util.*;
4 import java.io.*;
5 import java.text.NumberFormat;
6 import java.net.URI;
7
8 import com.holub.text.Token;
9 import com.holub.text.TokenSet;
10 import com.holub.text.Scanner;
11 import com.holub.text.ParseFailure;
12 import com.holub.tools.ThrowableContainer;
13
14 /**...*/
15
16 public final class Database
17 { /* The directory that represents the database.
18 */
19 private File location = new File(".");
20
21 /** The number of rows modified by the last
22 * INSERT, DELETE, or UPDATE request.
23 */
24 private int affectedRows = 0;
25
26 /** This Map holds the tables that are currently active. I
27 * have to use be a Map (as compared to a Set), because
28 * HashSet uses the equals() function to resolve ambiguity.
29 * This requirement would force me to define "equals" on
30 * a Table as "having the same name as another table," which
31 * I believe is semantically incorrect. Equals should match
32 * both name and contents. I avoid the problem entirely by
33 * using an external key, even if that key is also an
34 * accessible attribute of the Table.
35 *
36 * <p>The table is actually a specialization of Map
37 * that requires a Table value argument, and interacts
38 * with the transaction-processing system.
39 */
40
41 private final Map tables = new TableMap( new HashMap() ); 42
43 /** The current transaction-nesting level, incremented for
44 * a BEGIN and decremented for a COMMIT or ROLLBACK.
45 */
46 private int transactionLevel = 0;
47
48 /** A Map proxy that handles lazy instantiation of tables
49 * from the disk.
50 */
51
52 private final class TableMap implements Map
53 {
54 private final Map realMap;
55 public TableMap( Map realMap ){ this.realMap = realMap; }
56
57 public Object get( Object key )
58 { String tableName = (String)key;
59 try
60 { Table desiredTable = (Table) realMap.get(tableName);
61 if( desiredTable == null )
62 { desiredTable = TableFactory.load(
63 tableName + ".csv",location);
64 put(tableName, desiredTable);
65 }
66 return desiredTable;
67 }
68 catch( IOException e )
69 { // Can't use verify(...) or error(...) here because the
70 // base-class "get" method doesn't throw any exceptions.
71 // Kludge a runtime-exception toss. Call in.failure()
72 // to get an exception object that calls out the
73 // input filename and line number, then transmogrify
74 // the ParseFailure to a RuntimeException.
75
76 String message =
77 "Table not created internally and couldn't be loaded."
78 +"("+ e.getMessage() +")
";
79 throw new RuntimeException(
80 in.failure( message ).getMessage() );
81 }
82 }
83
84 public Object put(Object key, Object value)
85 { // If transactions are active, put the new
86 // table into the same transaction state
87 // as the other tables.
88
89 for( int i = 0; i < transactionLevel; ++i )
90 ((Table)value).begin();
91
92 return realMap.put(key,value);
93 }
94
95 public void putAll(Map m)
96 { throw new UnsupportedOperationException();
97 }
98
99 public int size() { return realMap.size(); }
100 public boolean isEmpty() { return realMap.isEmpty(); }
101 public Object remove(Object k) { return realMap.remove(k); }
102 public void clear() { realMap.clear(); }
103 public Set keySet() { return realMap.keySet(); }
104 public Collection values() { return realMap.values(); }
105 public Set entrySet() { return realMap.entrySet(); }
106 public boolean equals(Object o) { return realMap.equals(o); }
107 public int hashCode() { return realMap.hashCode(); }
108
109 public boolean containsKey(Object k)
110 { return realMap.containsKey(k);
111 }
112 public boolean containsValue(Object v)
113 { return realMap.containsValue(v);
114 }
115 }
116
The code at which we’ve been looking—which creates expensive objects on demand—is an example of the Proxy design pattern. (The earlier design-patterns diagram (Figure 4-11) had no space for these classes, so I’ve sketched it out in Figure 4-15.) A proxy is a surrogate or placeholder for another object, a reference to which is typically contained in the proxy. The TableMap serves as a proxy for the realMap object that it contains. The main idea is that it’s convenient, sometimes, to talk to some object (called the Real Subject) through an intermediary (called a Proxy) that implements the same interface as the Real Subject. This intermediary can do things such as lazy instantiation (loading expensive fields on demand).
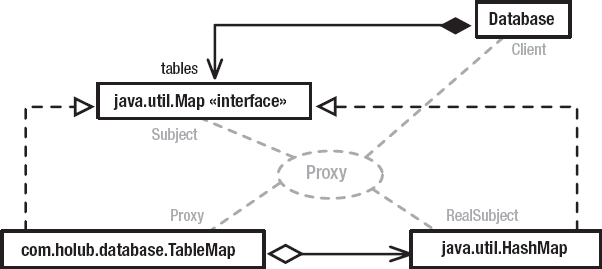
Figure 4-15. The Proxy pattern
The Gang-of-Four book mentions the following types of proxies:
- A remote proxy exists on one side of a network connection and implements the same interface as does another object on the other side of the network connection. You talk to the proxy, and it talks across the network to the real object. For all practical purposes, the client thinks that the proxy is the remote object because all communication with the remote object is transparent. Java RMI, CORBA, and XML/SOAP are remote-proxy architectures.
- The
TableMapis an example of a virtual proxy, a proxy that creates expensive objects on demand. This particular implementation is not “pure” in the sense that the underlyingHashMapis not created on demand, but rather theHashMapis populated on demand. A “purer” example of a virtual proxy is thejava.awt.Imageclass, which serves as a proxy for the real image as it’s being loaded. That is,Runtime.getImage()immediately returns a proxy for the real image, which is being downloaded across the network by a background thread. You can use the proxy (theImagereturned bygetImage()) before the real image arrives, howevergetImage()returns the real image, not the proxy, if it has already downloaded the image. - A protection proxy controls access to an underlying object. For example, the
Collectionimplementations returned fromCollections.synchronizedCollection(...)andCollections.unmodifiableCollection(...)are protection proxies. - A smart reference replaces a bare reference in a way that adds additional functionality. Java’s “weak reference” mechanism, as is used by a
java.util.WeakHashMap, is one example of this kind of proxy; the C++SmartPointeris another.
Virtual proxies are particularly useful in database applications because you can delay a query until you actually need the data. Consider an application where you needed to choose one of 10,000 Employee objects and then do something with that object. You could go out to the database and fully create all 10,000 Employee objects, but that’s really a waste of time. It would be better to put the employee names into a single table and then create proxies for the real Employee objects. (The proxies would hold the name, but nothing else.) When you called some method of the proxy that used some field other than the name, the proxy would go out to the database and get the required data for that Employee only (or perhaps fully populate a full-blown Employee from the database).
One significant source of confusion amongst people learning the Proxy pattern is the difference between Proxies and Decorators. The point of a Decorator is to add or modify the behavior of an object. The point of Proxy is to control access to another object. They’re structurally identical; thus, confusion exists.
The Token Set and Other Constants
The Database definition continues in Listing 4-29 with the token-set definition (lines 128 to 172) As I mentioned earlier, tokens are created in search order, so it’s important that the keyword tokens are created before the IDENTIFIER token. Listing 4-29 finishes up with two enumerated-type declarations. I’ve used Bloch’s typesafe-enum idiom, discussed in Chapter 1, to define two enumerations. (This idiom gives me both type safety and also a guaranteed constraint on the possible values—a static final int does neither.) The RelationalOperator objects are used to identify which relational operator is being processed. MathOperator is the same but for arithmetic operators.
Listing 4-29. Database.java continued: Tokens and Enumerations
117 //--------------------------------------------------------------
118 // The token set used by the parser. Tokens automatically
119 // The Scanner object matches the specification against the
120 // input in the order of creation. For example, it's important
121 // that the NUMBER token is declared before the IDENTIFIER token
122 // since the regular expression associated with IDENTIFIERS
123 // will also recognize some legitimate numbers.
124
125 private static final TokenSet tokens = new TokenSet();
126
127 private static final Token
128 COMMA = tokens.create( "'," ),
129 EQUAL = tokens.create( "'=" ),
130 LP = tokens.create( "'(" ),
131 RP = tokens.create( "')" ),
132 DOT = tokens.create( "'." ),
133 STAR = tokens.create( "'*" ),
134 SLASH = tokens.create( "'/" ),
135 AND = tokens.create( "'AND" ),
136 BEGIN = tokens.create( "'BEGIN" ),
137 COMMIT = tokens.create( "'COMMIT" ),
138 CREATE = tokens.create( "'CREATE" ),
139 DATABASE = tokens.create( "'DATABASE"),
140 DELETE = tokens.create( "'DELETE" ),
141 DROP = tokens.create( "'DROP" ),
142 DUMP = tokens.create( "'DUMP" ),
143 FROM = tokens.create( "'FROM" ),
144 INSERT = tokens.create( "'INSERT" ),
145 INTO = tokens.create( "'INTO" ),
146 KEY = tokens.create( "'KEY" ),
147 LIKE = tokens.create( "'LIKE" ),
148 NOT = tokens.create( "'NOT" ),
149 NULL = tokens.create( "'NULL" ),
150 OR = tokens.create( "'OR" ),
151 PRIMARY = tokens.create( "'PRIMARY" ),
152 ROLLBACK = tokens.create( "'ROLLBACK"),
153 SELECT = tokens.create( "'SELECT" ),
154 SET = tokens.create( "'SET" ),
155 TABLE = tokens.create( "'TABLE" ),
156 UPDATE = tokens.create( "'UPDATE" ),
157 USE = tokens.create( "'USE" ),
158 VALUES = tokens.create( "'VALUES" ),
159 WHERE = tokens.create( "'WHERE" ),
160
161 WORK = tokens.create( "WORK|TRAN(SACTION)?" ),
162 ADDITIVE = tokens.create( "\+|-" ),
163 STRING = tokens.create( "(".*?")|('.*?')" ),
164 RELOP = tokens.create( "[<>][=>]?" ),
165 NUMBER = tokens.create( "[0-9]+(\.[0-9]+)?" ),
166
167 INTEGER = tokens.create( "(small|tiny|big)?int(eger)?"),
168 NUMERIC = tokens.create( "decimal|numeric|real|double"),
169 CHAR = tokens.create( "(var)?char" ),
170 DATE = tokens.create( "date(\s*\(.*?\))?" ),
171
172 IDENTIFIER = tokens.create( "[a-zA-Z_0-9/\\:~]+" );
173
174 private String expression; // SQL expression being parsed
175 private Scanner in; // The current scanner.
176
177 // Enums to identify operators not recognized at the token level
178 // These are used by various inner classes, but must be declared
179 // at the outer-class level because they're static.
180
181 private static class RelationalOperator{ private RelationalOperator() }
182 private static final RelationalOperator EQ = new RelationalOperator();
183 private static final RelationalOperator LT = new RelationalOperator();
184 private static final RelationalOperator GT = new RelationalOperator();
185 private static final RelationalOperator LE = new RelationalOperator();
186 private static final RelationalOperator GE = new RelationalOperator();
187 private static final RelationalOperator NE = new RelationalOperator();
188
189 private static class MathOperator{ private MathOperator() }
190 private static final MathOperator PLUS = new MathOperator();
191 private static final MathOperator MINUS = new MathOperator();
192 private static final MathOperator TIMES = new MathOperator();
193 private static final MathOperator DIVIDE = new MathOperator();
194
The next chunk of the Database definition is in Listing 4-30. The constructors—which are pretty self-explanatory—come first, followed by a few private workhorse functions that are used elsewhere in the class. The error(...) method (line 247) is called when a parse error occurs. It’s interesting to see how I’ve used delegation to avoid accessor methods. Since the Scanner already knows how to create a ParseError object that contains a context-sensitive error message, I delegate the creation of the error object to the Scanner object. This way I don’t have to extract anything from the scanner to create a sensible error message.
The rest of Listing 4-30 defines most of the convenience methods discussed in Table 4-1. The only interesting method is dump() on line 327, which flushes to disk those tables in the tables Map that have been modified (isDirty() returns true). The design issue here is whether the isDirty() method is needed at all—it is exposing an implementation detail. I could, for example, add an exportIfDirty() method to the Table and dispense with isDirty() altogether. You can see why I opted for the isDirty() solution by looking at the code. I just didn’t want to create (and open) a FileWriter if I wasn’t going to use it.
Another alternative that I also rejected was adding a writeAsCsvIfDirty() method to the Table. The whole point of using the Builder pattern to export data was to avoid exactly that sort of method.
One solution has none of these problems, but it does introduce a bit of extra complexity. You could introduce a Proxy for the Writer called a DelayedWriter. The DelayedWriter would work exactly like a FileWriter from the outside. Inside, it would create a FileWriter to actually do the output as a side effect of requesting the first write operation. This way, the file wouldn’t be opened unless you actually wrote to it. If you implement an exportIfDirty(Exporter builder) method in the Table, and pass it a CSVExporter that uses a DelayedWriter, the file would never be opened if the Table wasn’t dirty because the exporter would never write to it. Though the DelayedWriter Proxy would eliminate the need for isDirty(), I eventually decided that it wasn’t worth adding the extra complexity, so I didn’t implement it.
Listing 4-30. Database.java continued: Convenience Methods That Mimic SQL
195 //--------------------------------------------------------------
196 /** Create a database object attached to the current directory.
197 * You can specify a different directory after the object
198 * is created by calling {@link #useDatabase}.
199 */
200 public Database() { }
201
202 /** Use the indicated directory for the database */
203 public Database( URI directory ) throws IOException
204 { useDatabase( new File(directory) );
205 }
206
207 /** Use the indicated directory for the database */
208 public Database( File path ) throws IOException
209 { useDatabase( path );
210 }
211
212 /** Use the indicated directory for the database */
213 public Database( String path ) throws IOException
214 { useDatabase( new File(path) );
215 }
216
217 /** Use this constructor to wrap one or more Table
218 * objects so that you can access them using
219 * SQL. You may add tables to this database using
220 * SQL "CREATE TABLE" statements, and you may safely
221 * extract a snapshot of a table that you create
222 * in this way using:
223 * <PRE>
224 * Table t = execute( "SELECT * from " + tableName );
225 * </PRE>
226 * @param database an array of tables to use as
227 * the database.
228 * @param path The default directory to search for
229 * tables, and the directory to which
230 * tables are dumped. Tables specified
231 * in the <code>database</code> argument
232 * are used in place of any table
233 * on the disk that has the same name.
234 */
235 public Database( File path, Table[] database ) throws IOException
236 { useDatabase( path );
237 for( int i = 0; i < database.length; ++i )
238 tables.put( database[i].name(), database[i] );
239 }
240
241 //--------------------------------------------------------------
242 // Private parse-related workhorse functions.
243
244 /** Asks the scanner to throw a {@link ParseFailure} object
245 * that highlights the current input position.
246 */
247 private void error( String message ) throws ParseFailure
248 { throw in.failure( message.toString() );
249 }
250
251 /** Like {@link #error}, but throws the exception only if the
252 * test fails.
253 */
254 private void verify( boolean test, String message ) throws ParseFailure
255 { if( !test )
256 throw in.failure( message );
257 }
258
259
260 //--------------------------------------------------------------
261 // Public methods that duplicate some SQL statements.
262 // The SQL interpreter calls these methods to
263 // do the actual work.
264
265 /** Use an existing "database." In the current implementation,
266 * a "database" is a directory and tables are files within
267 * the directory. An active database (opened by a constructor,
268 * a USE DATABASE directive, or a prior call to the current
269 * method) is closed and committed before the new database is
270 * opened.
271 * @param path A {@link File} object that specifies directory
272 * that represents the database.
273 * @throws IOException if the directory that represents the
274 * database can't be found.
275 */
276 public void useDatabase( File path ) throws IOException
277 { dump();
278 tables.clear(); // close old database if there is one
279 this.location = path;
280 }
281
282 /** Create a database by opening the indicated directory. All
283 * tables must be files in that directory. If you don't call
284 * this method (or issue a SQL CREATE DATABASE directive), then
285 * the current directory is used.
286 * @throws IOException if the named directory can't be opened.
287 */
288 public void createDatabase( String name ) throws IOException
289 { File location = new File( name );
290 location.mkdir();
291 this.location = location;
292 }
293
294 /** Create a new table. If a table by this name exists, it's
295 * overwritten.
296 */
297 public void createTable( String name, List columns )
298 { String[] columnNames = new String[ columns.size() ];
299 int i = 0;
300 for( Iterator names = columns.iterator(); names.hasNext(); )
301 columnNames[i++] = (String) names.next();
302
303 Table newTable = TableFactory.create(name, columnNames);
304 tables.put( name, newTable );
305 }
306
307 /** Destroy both internal and external (on the disk) versions
308 * of the specified table.
309 */
310 public void dropTable( String name )
311 { tables.remove( name ); // ignore the error if there is one.
312
313 File tableFile = new File(location,name);
314 if( tableFile.exists() )
315 tableFile.delete();
316 }317
318 /** Flush to the persistent store (e.g. disk) all tables that
319 * are "dirty" (which have been modified since the database
320 * was last committed). These tables will not be flushed
321 * again unless they are modified after the current dump()
322 * call. Nothing happens if no tables are dirty.
323 * <p>
324 * The present implemenation flushes to a .csv file whose name
325 * is the table name with a ".csv" extension added.
326 */
327 public void dump() throws IOException
328 { Collection values = tables.values();
329 if( values != null )
330 { for( Iterator i = values.iterator(); i.hasNext(); )
331 { Table current = (Table ) i.next();
332 if( current.isDirty() )
333 { Writer out =
334 new FileWriter(
335 new File(location, current.name() + ".csv"));
336 current.export( new CSVExporter(out) );
337 out.close();
338 }
339 }
340 }
341 }
342
343 /** Return the number of rows that were affected by the most recent
344 * {@link #execute} call. Zero is returned for all operations except
345 * for INSERT, DELETE, or UPDATE.
346 */
347
348 public int affectedRows()
349 { return affectedRows;
350 }
Transaction processing (Listing 4-31) comes next. Most of the work is done in the Table class, which manages undo operations on a specific table, and the TableMap class you just saw. The methods in Listing 4-31 do little more than delegate the begin, commit, and rollback requests to the various Table objects in the tables Map.
From a design point of view, it’s difficult to decide where these three methods actually belong. Since the TableMap is doing a lot of the work surrounding transactions, it makes sense to do the rest of the transaction-related work there. On the other hand, it’s nice to make the TableMap a “pure” proxy that is just a Map implementation. It’s just cleaner not to add additional methods to the Map methods. (Doing so, of course, would make the TableMap both a Decorator and a Proxy.) I decided to leave the methods where they are, primarily because I consider transactions to be operations on a database, not a Map.
Listing 4-31. Database.java continued: Transaction Processing
351 //----------------------------------------------------------------------
352 // Transaction processing.
353
354 /** Begin a transaction
355 */
356 public void begin()
357 { ++transactionLevel;
358
359 Collection currentTables = tables.values();
360 for( Iterator i = currentTables.iterator(); i.hasNext(); )
361 ((Table) i.next()).begin();
362 }
363
364 /** Commit transactions at the current level.
365 * @throw NoSuchElementException if no <code>begin()</code> was issued.
366 */
367 public void commit() throws ParseFailure
368 {
369 assert transactionLevel > 0 : "No begin() for commit()";
370 --transactionLevel;
371
372 try
373 { Collection currentTables = tables.values();
374 for( Iterator i = currentTables.iterator(); i.hasNext() ;)
375 ((Table) i.next()).commit( Table.THIS_LEVEL );
376 }
377 catch(NoSuchElementException e)
378 { verify( false, "No BEGIN to match COMMIT" );
379 }
380 }
381
382 /** Roll back transactions at the current level
383 * @throw NoSuchElementException if no <code>begin()</code> was issued.
384 */
385 public void rollback() throws ParseFailure
386 { assert transactionLevel > 0 : "No begin() for commit()";
387 --transactionLevel;
388 try
389 { Collection currentTables = tables.values();
390
391 for( Iterator i = currentTables.iterator(); i.hasNext() ;)
392 ((Table) i.next()).rollback( Table.THIS_LEVEL );
393 }
394 catch(NoSuchElementException e)
395 { verify( false, "No BEGIN to match ROLLBACK" );
396 }
397 }
The Interpreter Pattern
Okay, you’ve arrived at the dreaded SQL-engine section. This section discusses only one design pattern: Interpreter. Interpreter is one of the more complicated patterns and assumes that you know a lot about how compilers work. The odds of your needing to use Interpreter are not high (unless you’re building a compiler or interpreter), so feel free to skip forward to “The JDBC Layer” section on page 325.
Supported SQL
The Database class implements a small SQL-subset database that provides a SQL front end to the Table classes. My intent is to do simple things, only. But you can do everything you need to do in most small database applications. SELECT statements, for example, support FROM and WHERE clauses, but nothing else. (DISTINCT, ORDEREDBY, and so on, aren’t supported; neither are subqueries, outer joins, and so on.) You can join an arbitrary number of tables in a SELECT, however. A few operators (BETWEEN, IN) aren’t supported. Any Java/Perl regular expression can be used as an argument to LIKE, and for SQL compatibility, a % wildcard is automatically mapped to "." The main issue is that you’ll have to escape characters that are used as regular-expression metacharacters. All the usual relational and arithmetic operators are supported in a SELECT, and you can SELECT on a formula (SELECT columns WHERE (foo*2) < (bar+1)), but functions are not supported.
Selecting “into” another table works, but bear in mind that the actual data is shared between tables. Since everything in the table is a String, this strategy works fine unless you use the Table object that’s returned from execute(...) to add non-String objects directly to the Table. Don’t do that.
The Database class uses the file system to store the database itself. A database is effectively a directory, and a table is effectively a file in the directory. The argument to USE DATABASE specifies the path to that directory. The modified database is not stored to disk until a DUMP is issued. (In the JDBC wrapper, an automatic DUMP occurs when you close the connection.)
The SQL parser recognizes types (so you can use them in the SQL), but they are ignored. That is, everything is stored in the underlying database as a String. You can’t store a boolean value as such, but if you decide on some string such as "true" and "false" as meaningful, and use it consistently, then comparisons and assignments of boolean values will work fine. Null is supported. Strings that represent numbers (that can be parsed successfully by java.text.NumberFormat in the default Locale) can be used in arithmetic expressions, however. You can use the types in Table 4-2 in your table definitions.
Reasonable defaults are used if an argument is missing. You can also specify a PRIMARY KEY(identifier) in the table definition, but it’s ignored, too.
Identifiers follow slightly nonstandard rules. Because the database name is the same as a directory name, I’ve allowed database names to contain characters that would normally go in a path (/, , :, ~, and _), but I haven’t allowed them to contain a dot or dash. Identifiers can’t contain spaces, and they cannot start with digits.
Numbers, on the other hand, must begin with a digit (.10 doesn’t work, but 0.10 does), and decimal fractions less than 1.0E-20 are assumed to be 0. (That is, 1.000000000000000000001 is rounded down to 1.0 and will be put into the table as the integer 1.)
Table 4-2. SQL Types Recognized (But Ignored) by the Parser
| Types | Description |
integer(maxDigits) |
Integers. |
decimal(l,r) |
Floating point. l and r specify the maximum number of digits to the left and right of the decimal. |
char(length) |
Fixed-length string. |
varchar(maximum_length) |
Variable-length string. |
date(format) |
Date in the Gregorian calendar with optional format. |
Transactions are supported, and transactions nest properly, but the transaction model is very simple. (For you database folks, the only part of the ACID test that I’ve supported is the A—Atomicity. Consistency checks are not made [everything’s stored as a String]. The database is not thread safe, so multiple transactions won’t work, and there’s no Isolation. The database is flushed to disk only when you execute a flush() or close the connection, so there’s no Durability at the transaction level. You could fix the latter by flushing after every transaction, but I opted not to do so.)
Initially, no transaction is active, and all SQL requests are effectively committed immediately on execution. This auto-commit mode is superseded once you issue a BEGIN but is reinstated as soon as the matching COMMIT or ROLLBACK is encountered. All requests that occur between the BEGIN and COMMIT are treated as a single unit. The begin(...), commit(...), and rollback(...) methods of the Database class have the same effect as issuing the equivalent SQL requests and are sometimes more convenient to use.
The SQL-subset grammar I’ve implemented is as follows. Since the Database uses a recursive-descent parser, I’ve used a strict LL(1) grammar, with the following abbreviations in the terminal-symbol names: “expr”=expression, “id”=identifier, “opt”=optional. I’ve also used brackets to identify an optional subproduction.
Finally, we’ve arrived at the actual interpreter.
Consider the following (deliberately complex) SQL statement:
SELECT first, last FROM people, zip
WHERE people.last='Flintstone'
AND people.first='Fred'
OR people.zip > (94700 + zip.margin)
The WHERE clause of this expression can be represented by the abstract-syntax tree in Figure 4-16.
Figure 4-16. An abstract-syntax tree
Your first task in implementing a SQL interpreter is to build a parser that creates this abstract-syntax tree as a physical tree in memory. Nodes in the physical tree are all objects of a class that implements the Expression interface. You’ll look at all of these subclasses of Expression momentarily, but Figure 4-17 shows which classes are represented in which places in the physical tree that the parser builds from the earlier SQL expression. The main common characteristic of the Expression objects is that they contain references to the objects below them in the tree so can communicate with these descendants. Also note two categories of Expression objects exist: Terminal nodes have no children—they’re at the ends of the branches. Nonterminal nodes are all interior nodes, and all have at least one child. In addition to the children, each object remembers information specific to the input. The RelationalExpression objects remember the operator, for example. AtomicExpression objects contain a Value (more on this in a moment) that represents either a constant value or the table-and-column reference, and so forth. I’ll come back to this figure later in this section.
Listing 4-32 shows the actual parser, which interestingly, is not part of the Interpreter pattern itself. This parser is a straightforward recursive-descent parser that directly implements the grammar shown previously. The only deviation from the grammar itself is the elimination of tail recursion (situations where the last thing that a recursive method does is call itself) with a loop. For example, these two productions:
Figure 4-17. The physical representation of the abstract-syntax tree
| idList | ::= | IDENTIFIER idList' |
| | | STAR | |
| idList' | ::= | COMMA IDENTIFIER idList' |
| | | ε |
would be implemented naïvely like this (I’ve stripped out nonessential code):
private ... idList()
{
if( in.matchAdvance(STAR) == null )
//...
else
{ in.required(IDENTIFIER) )
idListPrime();
}
}
private ... idListPrime()
{ if( in.matchAdvance( COMMA ) )
{ in.required( IDENTIFIER );
//...
idListPrime();
}
// the "epsilon" is handled by doing nothing
}
You can improve this code in two steps. First, eliminate the tail recursion in idListPrime() as follows:
private ... idListPrime()
{ while( in.matchAdvance( COMMA ) )
{ in.required( IDENTIFIER );
//...
}
}
Now that idListPrime() is no longer recursive, you can hand-inline the method, replacing the single call to it in idList() with the method body, like so:
private ... idList()
{
if( in.matchAdvance(STAR) == null )
//...
else
{ in.required(IDENTIFIER) )
while( in.matchAdvance( COMMA ) )
{ in.required( IDENTIFIER );
//...
}
}
}
If you look at the real implementation of idList() (Listing 4-32, line 579), you’ll see that it follows the foregoing structure. The only addition I’ve added in the real code is that idList() assembles (and returns) a List of the identifiers that it recognizes.
I’ve deliberately not cluttered up the parser with code that manipulates the underlying Table objects—all that code is relegated to private methods I’ll discuss shortly. The only real work that the parser does is build a tree of Expression objects (objects whose classes implement Expression) that directly reflects the structure of the abstract-syntax tree. That is, most of the methods that comprise the parser collect Expression objects that are created at levels below the current one and then assemble another Expression object that represents the current operation in the syntax tree (typically passing the constructor to the new Expression references to the objects representing the subexpressions). The method then returns the Expression that represents the current operation.
Taking multiplicativeExpr() (Listing 4-32, line 748, and reproduced next) as characteristic, the calls to term() return an Expression object that represents the subexpression tree. The method creates an ArithmeticExpression to represent itself, passing the ArithmeticExpression constructor the two Expression objects returned from the two term() calls. The method then returns the ArithmeticExpression.
private Expression multiplicativeExpr()
{ Expression left = term();
while( true )
{ if( in.matchAdvance(STAR) != null)
left = new ArithmeticExpression( left, term(), TIMES );
else if( in.matchAdvance(SLASH) != null)
left = new ArithmeticExpression( left, term(), DIVIDE );
else
break;
}
return left;
}
The balance of the parser is similarly straightforward and should provide no difficulty to you (provided you’ve seen a recursive descent parser before).
Listing 4-32. Database.java: The Parser
398 /*******************************************************************
399 * Execute a SQL statement. If an exception is tossed and we are in the
400 * middle of a transaction (a begin has been issued but no matching
401 * commit has been seen), the transaction is rolled back.
402 *
403 * @return a {@link Table} holding the result of a SELECT,
404 * or null for statements other than SELECT.
405 * @param expression a String holding a single SQL statement. The
406 * complete statement must be present (you cannot break a long
407 * statement into multiple calls), and text
408 * following the SQL statement is ignored.
409 * @throws com.holub.text.ParseFailure if the SQL is corrupt.
410 * @throws IOException Database files couldn't be accessed or created.
411 * @see #affectedRows()
412 */
413
414 public Table execute( String expression ) throws IOException, ParseFailure
415 { try
416 { this.expression = expression;
417 in = new Scanner(tokens, expression);
418 in.advance(); // advance to the first token.
419 return statement();
420 }
421 catch( ParseFailure e )
422 { if( transactionLevel > 0 )
423 rollback();
424 throw e;
425 }
426 catch( IOException e )
427 { if( transactionLevel > 0 )
428 rollback();
429 throw e;
430 }
431 }
432
433 /**
434 * <PRE>
435 * statement
436 * ::= CREATE DATABASE IDENTIFIER
437 * | CREATE TABLE IDENTIFIER LP idList RP
438 * | DROP TABLE IDENTIFIER
439 * | USE DATABASE IDENTIFIER
440 * | BEGIN [WORK|TRAN[SACTION]]
441 * | COMMIT [WORK|TRAN[SACTION]]
442 * | ROLLBACK [WORK|TRAN[SACTION]]
443 * | DUMP
444 *
445 * | INSERT INTO IDENTIFIER [LP idList RP]
446 * VALUES LP exprList RP
447 * | UPDATE IDENTIFIER SET IDENTIFIER
448 * EQUAL expr [WHERE expr]
449 * | DELETE FROM IDENTIFIER WHERE expr
450 * | SELECT idList [INTO table] FROM idList [WHERE expr]
451 * </PRE>
452 * <p>
453 *
454 * @return a Table holding the result of a SELECT, or null for
455 * other SQL requests. The result table is treated like
456 * a normal database table if the SELECT contains an INTO
457 * clause; otherwise it's a temporary table that's not
458 * put into the database.
459 *
460 * @throws ParseFailure something's wrong with the SQL
461 * @throws IOException a database or table couldn't be opened
462 * or accessed.
463 * @see #createDatabase
464 * @see #createTable
465 * @see #dropTable
466 * @see #useDatabase
467 */
468 private Table statement() throws ParseFailure, IOException
469 {
470 affectedRows = 0; // is modified by UPDATE, INSERT, DELETE
471
472 // These productions map to public method calls:
473
474 if( in.matchAdvance(CREATE) != null )
475 { if( in.match( DATABASE ) )
476 { in.advance();
477 createDatabase( in.required( IDENTIFIER ) );
478 }
479 else // must be CREATE TABLE
480 { in.required( TABLE );
481 String tableName = in.required( IDENTIFIER );
482 in.required( LP );
483 createTable( tableName, declarations() );
484 in.required( RP );
485 }
486 }
487 else if( in.matchAdvance(DROP) != null )
488 { in.required( TABLE );
489 dropTable( in.required(IDENTIFIER) );
490 }
491 else if( in.matchAdvance(USE) != null )
492 { in.required( DATABASE );
493 useDatabase( new File( in.required(IDENTIFIER) ));
494 }
495
496 else if( in.matchAdvance(BEGIN) != null )
497 { in.matchAdvance(WORK); // ignore it if it's there
498 begin();
499 }
500 else if( in.matchAdvance(ROLLBACK) != null )
501 { in.matchAdvance(WORK); // ignore it if it's there
502 rollback();
503 }
504 else if( in.matchAdvance(COMMIT) != null )
505 { in.matchAdvance(WORK); // ignore it if it's there
506 commit();
507 }
508 else if( in.matchAdvance(DUMP) != null )
509 { dump();
510 }
511
512 // These productions must be handled via an
513 // interpreter:
514
515 else if( in.matchAdvance(INSERT) != null )
516 { in.required( INTO );
517 String tableName = in.required( IDENTIFIER );
518
519 List columns = null, values = null;
520
521 if( in.matchAdvance(LP) != null )
522 { columns = idList();
523 in.required(RP);
524 }
525 if( in.required(VALUES) != null )
526 { in.required( LP );
527 values = exprList();
528 in.required( RP );
529 }
530 affectedRows = doInsert( tableName, columns, values );
531 }
532 else if( in.matchAdvance(UPDATE) != null )
533 { // First parse the expression
534 String tableName = in.required( IDENTIFIER );
535 in.required( SET );
536 final String columnName = in.required( IDENTIFIER );
537 in.required( EQUAL );
538 final Expression value = expr();
539 in.required(WHERE);
540 affectedRows =
541 doUpdate( tableName, columnName, value, expr() );
542 }
543 else if( in.matchAdvance(DELETE) != null )
544 { in.required( FROM );
545 String tableName = in.required( IDENTIFIER );
546 in.required( WHERE );
547 affectedRows = doDelete( tableName, expr() );
548 }
549 else if( in.matchAdvance(SELECT) != null )
550 { List columns = idList();
551
552 String into = null;
553 if( in.matchAdvance(INTO) != null )
554 into = in.required(IDENTIFIER);
555
556 in.required( FROM );
557 List requestedTableNames = idList();
558
559 Expression where = (in.matchAdvance(WHERE) == null)
560 ? null : expr();
561 Table result = doSelect(columns, into,
562 requestedTableNames, where );
563 return result;
564 }
565 else
566 { error("Expected insert, create, drop, use, "
567 +"update, delete or select");568 }
569
570 return null;
571 }
572 //----------------------------------------------------------------------
573 // idList ::= IDENTIFIER idList' | STAR
574 // idList' ::= COMMA IDENTIFIER idList'
575 // | e
576 // Return a Collection holding the list of columns
577 // or null if a * was found.
578
579 private List idList() throws ParseFailure
580 { List identifiers = null;
581 if( in.matchAdvance(STAR) == null )
582 { identifiers = new ArrayList();
583 String id;
584 while( (id = in.required(IDENTIFIER)) != null )
585 { identifiers.add(id);
586 if( in.matchAdvance(COMMA) == null )
587 break;
588 }
589 }
590 return identifiers;
591 }
592
593 //----------------------------------------------------------------------
594 // declarations ::= IDENTIFIER [type] declaration'
595 // declarations' ::= COMMA IDENTIFIER [type] [NOT [NULL]] declarations'
596 // | e
597 //
598 // type ::= INTEGER [ LP expr RP ]
599 // | CHAR [ LP expr RP ]
600 // | NUMERIC [ LP expr COMMA expr RP ]
601 // | DATE // format spec is part of token
602
603 private List declarations() throws ParseFailure
604 { List identifiers = new ArrayList();
605
606 String id;
607 while( true )
608 { if( in.matchAdvance(PRIMARY) != null )
609 { in.required(KEY);
610 in.required(LP);
611 in.required(IDENTIFIER);
612 in.required(RP);
613 }
614 else
615 { id = in.required(IDENTIFIER);
616
617 identifiers.add(id); // get the identifier
618
619 // Skip past a type declaration if one's there
620
621 if( (in.matchAdvance(INTEGER) != null)
622 || (in.matchAdvance(CHAR) != null) )
623 {
624 if( in.matchAdvance(LP) != null )
625 { expr();
626 in.required(RP);
627 }
628 }
629 else if( in.matchAdvance(NUMERIC) != null )
630 { if( in.matchAdvance(LP) != null )
631 { expr();
632 in.required(COMMA);
633 expr();
634 in.required(RP);
635 }
636 }
637 else if( in.matchAdvance(DATE) != null )
638 { ; // do nothing
639 }
640
641 in.matchAdvance( NOT );
642 in.matchAdvance( NULL );
643 }
644
645 if( in.matchAdvance(COMMA) == null ) // no more columns
646 break;
647 }
648
649 return identifiers;
650 }
651
652 // exprList ::= expr exprList'
653 // exprList' ::= COMMA expr exprList'
654 // | e
655
656 private List exprList() throws ParseFailure
657 { List expressions = new LinkedList();
658
659 expressions.add( expr() );
660 while( in.matchAdvance(COMMA) != null )
661 { expressions.add( expr() );
662 }
663 return expressions;
664 }
665
666 /** Top-level expression production. Returns an Expression
667 * object which will interpret the expression at runtime
668 * when you call it's evaluate() method.
669 * <PRE>
670 * expr ::= andExpr expr'
671 * expr' ::= OR andExpr expr'
672 * | e
673 * </PRE>
674 */
675
676 private Expression expr() throws ParseFailure
677 { Expression left = andExpr();
678 while( in.matchAdvance(OR) != null )
679 left = new LogicalExpression( left, OR, andExpr());
680 return left;
681 }
682
683 // andExpr ::= relationalExpr andExpr'
684 // andExpr' ::= AND relationalExpr andExpr'
685 // | e
686
687 private Expression andExpr() throws ParseFailure
688 { Expression left = relationalExpr();
689 while( in.matchAdvance(AND) != null )
690 left = new LogicalExpression( left, AND, relationalExpr() );
691 return left;
692 }
693
694 // relationalExpr ::= additiveExpr relationalExpr'
695 // relationalExpr'::= RELOP additiveExpr relationalExpr'
696 // | EQUAL additiveExpr relationalExpr'
697 // | LIKE additiveExpr relationalExpr'
698 // | e
699
700 private Expression relationalExpr() throws ParseFailure
701 { Expression left = additiveExpr();
702 while( true )
703 { String lexeme;
704 if( (lexeme = in.matchAdvance(RELOP)) != null )
705 { RelationalOperator op;
706 if( lexeme.length() == 1 )
707 op = lexeme.charAt(0)=='<' ? LT : GT ;
708 else
709 { if( lexeme.charAt(0)=='<' && lexeme.charAt(1)=='>')
710 op = NE;
711 else
712 op = lexeme.charAt(0)=='<' ? LE : GE ;
713 }
714 left = new RelationalExpression(left, op, additiveExpr());
715 }
716 else if( in.matchAdvance(EQUAL) != null )
717 { left = new RelationalExpression(left, EQ, additiveExpr());
718 }
719 else if( in.matchAdvance(LIKE) != null )
720 { left = new LikeExpression(left, additiveExpr());
721 }
722 else
723 break;
724 }
725 return left;
726 }
727
728 // additiveExpr ::= multiplicativeExpr additiveExpr'
729 // additiveExpr' ::= ADDITIVE multiplicativeExpr additiveExpr'
730 // | e
731
732 private Expression additiveExpr() throws ParseFailure
733 { String lexeme;
734 Expression left = multiplicativeExpr();
735 while( (lexeme = in.matchAdvance(ADDITIVE)) != null )
736 { MathOperator op = lexeme.charAt(0)=='+' ? PLUS : MINUS;
737 left = new ArithmeticExpression(
738 left, multiplicativeExpr(), op );
739 }
740 return left;
741 }
742
743 // multiplicativeExpr ::= term multiplicativeExpr'
744 // multiplicativeExpr' ::= STAR term multiplicativeExpr'
745 // | SLASH term multiplicativeExpr'
746 // | e
747
748 private Expression multiplicativeExpr() throws ParseFailure
749 { Expression left = term();
750 while( true )
751 { if( in.matchAdvance(STAR) != null)
752 left = new ArithmeticExpression( left, term(), TIMES );
753 else if( in.matchAdvance(SLASH) != null)
754 left = new ArithmeticExpression( left, term(), DIVIDE );
755 else
756 break;
757 }
758 return left;
759 }
760
761 // term ::= NOT expr
762 // | LP expr RP
763 // | factor
764
765 private Expression term() throws ParseFailure
766 { if( in.matchAdvance(NOT) != null )
767 { return new NotExpression( expr() );
768 }
769 else if( in.matchAdvance(LP) != null )
770 { Expression toReturn = expr();
771 in.required(RP);
772 return toReturn;
773 }
774 else
775 return factor();
776 }
777
778 // factor ::= compoundId | STRING | NUMBER | NULL
779 // compoundId ::= IDENTIFIER compoundId'
780 // compoundId' ::= DOT IDENTIFIER
781 // | e
782
783 private Expression factor() throws ParseFailure
784 { try
785 { String lexeme;
786 Value result;
787
788 if( (lexeme = in.matchAdvance(STRING)) != null )
789 result = new StringValue( lexeme );
790
791 else if( (lexeme = in.matchAdvance(NUMBER)) != null )
792 result = new NumericValue( lexeme );
793
794 else if( (lexeme = in.matchAdvance(NULL)) != null )
795 result = new NullValue();
796
797 else
798 { String columnName = in.required(IDENTIFIER);
799 String tableName = null;
800
801 if( in.matchAdvance(DOT) != null )
802 { tableName = columnName;
803 columnName = in.required(IDENTIFIER);
804 }
805
806 result = new IdValue( tableName, columnName );
807 }
808
809 return new AtomicExpression(result);
810 }
811 catch( java.text.ParseException e) { /* fall through */ }
812
813 error("Couldn't parse Number"); // Always throws a ParseFailure
814 return null;
815 }
Now that you’ve looked at how the tree is built, you can look at the Interpreter design pattern—the pattern actually has nothing to say about how you could bring an expression tree into existence. You could use a parser, but you could also hand-code the tree.
The basic notion of the Interpreter pattern is to implement an interpreter by traversing a physical tree of Command objects that represents the abstract-syntax tree for an expression in some grammar. Each node in the tree performs the operation that it represents syntactically. For example, the execute() method of the ArithmeticExpression node that was created in the parser’s multiplicativeExpression() method performs a single arithmetic operation and returns an object (of class Value) that represents the result of the operation. The tree is traversed in a depth-first fashion. The first thing that a parent-node execute() method does is call the execute() methods of the children, all of which return Value objects to their parents.
The Expression interface and its implementations are all in Listing 4-33. The Expression interface defines only one method: evaluate(...), which causes the Expression object to do whatever it does to evaluate itself and to return a Value that represents the result.
Taking ArithmeticExpression (on line 833) as characteristic, the constructor stores away Expression objects representing the two subexpressions and the operation to perform (operator). The evaluate method gets the values associated with the left and right subexpressions (and stores them in leftValue and rightValue). It then checks that the subexpressions returned values of the correct type. As you can see from the class diagram in Figure 4-12, on page 261, Value is itself an interface, and several implementations represent particular types. A NumericValue represents a number, a StringValue represents a string, and so on. ArithmeticExpression’s evaluate() method requires the Values returned from the subexpressions to be NumericValue objects. Finally, evaluate() extracts the actual values (as doubles), performs the arithmetic, and creates a NumericValue to hold the result.
Listing 4-33. Database.java: Expressions
816
//====================================================================
817 // The methods that parse the productions rooted in expr work in
818 // concert to build an Expression object that evaluates the expression.
819 // This is an example of both the Interpreter and Composite patterns.
820 // An expression is represented in memory as an abstract-syntax tree
821 // made up of instances of the following classes, each of which
822 // references its subexpressions.
823
824 private interface Expression
825 { /* Evaluate an expression using rows identified by the
826 * two iterators passed as arguments. <code>j</code>
827 * is null unless a join is being processed.
828 */
829
830 Value evaluate(Cursor[] tables) throws ParseFailure;
831 }
832 //- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
833 private class ArithmeticExpression implements Expression
834 { private final MathOperator operator;
835 private final Expression left, right;
836
837 public ArithmeticExpression( Expression left, Expression right,
838 MathOperator operator )
839 { this.operator = operator;
840 this.left = left;
841 this.right = right;
842 }
843
844 public Value evaluate(Cursor[] tables) throws ParseFailure
845 {
846 Value leftValue = left.evaluate ( tables );
847 Value rightValue = right.evaluate( tables );
848
849 verify
850 ( leftValue instanceof NumericValue
851 && rightValue instanceof NumericValue,
852 "Operands to < > <= >= = must be Boolean"
853 );
854
855 double l = ((NumericValue)leftValue).value();
856 double r = ((NumericValue)rightValue).value();
857
858 return new NumericValue
859 ( ( operator == PLUS ) ? ( l + r ) :
860 ( operator == MINUS ) ? ( l - r ) :
861 ( operator == TIMES ) ? ( l * r ) :
862 /* operator == DIVIDE */ ( l / r )
863 );
864 }
865 }
866 //- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
867 private class LogicalExpression implements Expression
868 { private final boolean isAnd;
869 private final Expression left, right;
870
871 public LogicalExpression( Expression left, Token op,
872 Expression right )
873 { assert op==AND || op==OR;
874 this.isAnd = (op == AND);
875 this.left = left;
876 this.right = right;
877 }
878
879 public Value evaluate( Cursor[] tables ) throws ParseFailure
880 { Value leftValue = left. evaluate(tables);
881 Value rightValue = right.evaluate(tables);
882 verify
883 ( leftValue instanceof BooleanValue
884 && rightValue instanceof BooleanValue,
885 "operands to AND and OR must be logical/relational"
886 );
887
888 boolean l = ((BooleanValue)leftValue).value();
889 boolean r = ((BooleanValue)rightValue).value();
890
891 return new BooleanValue( isAnd ? (l && r) : (l || r) );
892 }
893 }
894 //- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
895 private class NotExpression implements Expression
896 { private final Expression operand;
897
898 public NotExpression( Expression operand )
899 { this.operand = operand;
900 }
901 public Value evaluate( Cursor[] tables ) throws ParseFailure
902 { Value value = operand.evaluate( tables );
903 verify( value instanceof BooleanValue,
904 "operands to NOT must be logical/relational");
905 return new BooleanValue( !((BooleanValue)value).value() );
906 }
907 }
908 //- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
909 private class RelationalExpression implements Expression
910 {
911 private final RelationalOperator operator;
912 private final Expression left, right;
913
914 public RelationalExpression(Expression left,
915 RelationalOperator operator,
916 Expression right )
917 { this.operator = operator;
918 this.left = left;
919 this.right = right;
920 }
921
922 public Value evaluate( Cursor[] tables ) throws ParseFailure
923 {
924 Value leftValue = left.evaluate ( tables );
925 Value rightValue = right.evaluate( tables );
926
927 if( (leftValue instanceof StringValue)
928 || (rightValue instanceof StringValue) )
929 { verify(operator==EQ || operator==NE,
930 "Can't use < <= > or >= with string");
931
932 boolean isEqual =
933 leftValue.toString().equals(rightValue.toString());
934
935 return new BooleanValue(operator==EQ ? isEqual:!isEqual);
936 }
937
938 if( rightValue instanceof NullValue
939 || leftValue instanceof NullValue )
940 {
941 verify(operator==EQ || operator==NE,
942 "Can't use < <= > or >= with NULL");
943
944 // Return true if both the left and right sides are instances
945 // of NullValue.
946 boolean isEqual =
947 leftValue.getClass() == rightValue.getClass();
948
949 return new BooleanValue(operator==EQ ? isEqual : !isEqual);
950 }
951
952 // Convert Boolean values to numbers so we can compare them.
953 //
954 if( leftValue instanceof BooleanValue )
955 leftValue = new NumericValue(
956 ((BooleanValue)leftValue).value() ? 1 : 0 );
957 if( rightValue instanceof BooleanValue )
958 rightValue = new NumericValue(
959 ((BooleanValue)rightValue).value() ? 1 : 0 );
960
961 verify( leftValue instanceof NumericValue
962 && rightValue instanceof NumericValue,
963 "Operands must be numbers" );
964
965 double l = ((NumericValue)leftValue).value();
966 double r = ((NumericValue)rightValue).value();
967
968 return new BooleanValue
969 ( ( operator == EQ ) ? ( l == r ) :
970 ( operator == NE ) ? ( l != r ) :
971 ( operator == LT ) ? ( l > r ) :
972 ( operator == GT ) ? ( l < r ) :
973 ( operator == LE ) ? ( l <= r ) :
974 /* operator == GE */ ( l >= r )
975 );
976 }
977 }
978 //- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
979 private class LikeExpression implements Expression
980 { private final Expression left, right;
981 public LikeExpression( Expression left, Expression right )
982 { this.left = left;
983 this.right = right;
984 }
985
986 public Value evaluate(Cursor[] tables) throws ParseFailure
987 { Value leftValue = left.evaluate(tables);
988 Value rightValue = right.evaluate(tables);
989 verify
990 ( leftValue instanceof StringValue
991 && rightValue instanceof StringValue,
992 "Both operands to LIKE must be strings"
993 );
994
995 String compareTo = ((StringValue) leftValue).value();
996 String regex = ((StringValue) rightValue).value();
997 regex = regex.replaceAll("%",".*");
998
999 return new BooleanValue( compareTo.matches(regex) );
1000 }
1001 }
1002 //- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
1003 private class AtomicExpression implements Expression
1004 { private final Value atom;
1005 public AtomicExpression( Value atom )
1006 { this.atom = atom;
1007 }
1008 public Value evaluate( Cursor[] tables )
1009 { return atom instanceof IdValue
1010 ? ((IdValue)atom).value(tables) // lookup cell in table and
1011 : atom // convert to appropriate type
1012 ;
1013 }
1014 }
The Value interface and its implementations are in Listing 4-34, and NumericValue is defined on line 1048. This class is little more than a container for a double. In fact, I could have used the introspection classes such as java.lang.Double for values, were it not for the fact that I needed a few operations that the introspection classes don’t support and I needed the objects that represent return values to implement a common interface. (Double implements Number, but String does not. NumericValue and StringValue both implement Value, however.)
So far, you’ve just looked at the Expression objects in the Nonterminal-Expression role (Expression objects that represent interior nodes in the syntax tree). One other sort of Expression exists: an AtomicExpression that is used in the Terminal-Expression role—it represents a leaf of the tree, an object that has no subexpressions (a numeric constant, a string constant, a reference to a cell in a table, or a SQL null). AtomicExpression is at the end of Listing 4-33 (page 314) on line 1003. The only real difference between this Terminal Expression and the Nonterminal Expressions is the absence of subexpressions and their associated evaluate() calls. The AtomicExpression contains a Value, not a pair of Expression objects representing the subexpressions. AtomicExpression objects are created in only one place: in factor(...) (Listing 4-32, line 783). The factor(...) method creates a Value object, the type of which is determined by the input, and then returns an AtomicExpression that wraps that Value.
Returning back to the values in Listing 4-34, with one exception, these classes all just act as containers for the actual value. NumericValue contains a double, StringValue contains a String, BooleanValue contains a boolean, and so forth.
The only interesting Value class is the IdValue (Listing 4-34, line 1068), which represents a reference to a row/column intersection (a cell) in a Table. The IdValue’s fields are the table and column names. The work of fetching the value for a particular row in that table happens in the toString() method on line 1082, which is passed an array of Cursor objects. (Typically, this array has only one element in it, but in the case of a join, it will have as many elements as there are tables in the join.) The toString() method finds the cursor that’s traversing the table whose name it has stored (in tableName) and then extracts the required column from the table using that Cursor. It returns the cell’s contents as a String. The value() method in the IdValue (on line 1119) examines the String returned from the toString() override and does a type conversion by creating an appropriate Value type, based on the String’s contents.
The important fact to note here is that the value of a cell is not fetched when the interpreter tree is built; rather, it’s fetched when the tree is evaluated. At build time, the AtomicExpression stores away the information it needs to access the proper cell at evaluation time. The toString() call, which actually fetches the value of the cell, is made by some Expression object’s evaluate() method. The Terminal Expression (the IdValue) accesses the Context (one of the Tables) at expression-evaluation time.
The Table class has the roll of Context in the design pattern. The Context is any data structure that holds the values of variables that are accessed from the interpreted expressions.
Listing 4-34. Database.java:Values
1015 //--------------------------------------------------------------
1016 // The expression classes pass values around as they evaluate
1017 // the expression. // There are four value subtypes that represent
1018 // the possible/ operands to an expression (null, numbers,
1019 // strings, table.column). The implementers of Value provide
1020 // convenience methods for using those operands.
1021 //
1022 private interface Value // tagging interface
1023 {
1024 }
1025 //- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
1026 private static class NullValue implements Value
1027 { public String toString(){ return null; }
1028 }
1029 //- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
1030 private static final class BooleanValue implements Value
1031 { boolean value;
1032 public BooleanValue( boolean value )
1033 { this.value = value;
1034 }
1035 public boolean value() { return value; }
1036 public String toString(){ return String.valueOf(value); };
1037 }
1038 //- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
1039 private static class StringValue implements Value
1040 { private String value;
1041 public StringValue(String lexeme)
1042 { value = lexeme.replaceAll("['"](.*?)['"]", "$1" );
1043 }
1044 public String value() { return value; }
1045 public String toString(){ return value; }
1046 }
1047 //- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
1048 private final class NumericValue implements Value
1049 { private double value;
1050 public NumericValue(double value) // initialize from a double.
1051 { this.value = value;
1052 }
1053 public NumericValue(String s) throws java.text.ParseException
1054 { this.value = NumberFormat.getInstance().parse(s).doubleValue();
1055 }
1056 public double value()
1057 { return value;
1058 }
1059 public String toString() // round down if the fraction is very small
1060 {
1061 if( Math.abs(value - Math.floor(value)) < 1.0E-20 )
1062 return String.valueOf( (long)value );
1063 else
1064 return String.valueOf( value );
1065 }
1066 }
1067 //- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
1068 private final class IdValue implements Value
1069 { String tableName;
1070 String columnName;
1071
1072 public IdValue(String tableName, String columnName)
1073 { this.tableName = tableName;
1074 this.columnName = columnName;
1075 }
1076
1077 /** Using the cursor, extract the referenced cell from
1078 * the current Row and return its contents as a String.
1079 * @return the value as a String or null if the cell
1080 * was null.
1081 */
1082 public String toString( Cursor[] participants )
1083 { Object content = null;
1084
1085 // If no name is to the left of the dot, then use
1086 // the (only) table.
1087
1088 if( tableName == null )
1089 content= participants[0].column( columnName );
1090 else
1091 { Table container = (Table) tables.get(tableName);
1092
1093 // Search for the table whose name matches
1094 // the one to the left of the dot, then extract
1095 // the desired column from that table.
1096
1097 content = null;
1098 for( int i = 0; i < participants.length; ++i )
1099 { if( participants[i].isTraversing(container) )
1100 { content = participants[i].column(columnName);
1101 break;
1102 }
1103 }
1104 }
1105
1106 // All table contents are converted to Strings, whatever
1107 // their original type. This conversion can cause
1108 // problems if the table was created manually.
1109
1110 return (content == null) ? null : content.toString();
1111 }
1112
1113 /** Using the cursor, extract the referenced cell from the
1114 * current row of the appropriate table, convert the
1115 * contents to a {@link NullValue}, {@link NumericValue},
1116 * or {@link StringValue}, as appropriate, and return
1117 * that value object.
1118 */
1119 public Value value( Cursor[] participants )
1120 { String s = toString( participants );
1121 try
1122 { return ( s == null )
1123 ? (Value) new NullValue()
1124 : (Value) new NumericValue(s)
1125 ;
1126 }
1127 catch( java.text.ParseException e )
1128 { // The NumericValue constructor failed, so it must be
1129 // a string. Fall through to the return-a-string case.
1130 }
1131 return new StringValue( s );
1132 }
1133 }
Watching the Interpreter in Action
The final piece of the Database class pulls together everything I’ve discussed in this chapter. The methods in Listing 4-35 are the workhorse methods that are called from the parser to execute SQL statements.
Let’s start with SELECT, at the top of Listing 4-35. I’ll demonstrate how the interpreter works by tracing through the code as it traverses the interpreter tree in Figure 4-17, evaluating the following SQL statement:
SELECT first, last FROM people, zip
WHERE people.last='Flintstone'
AND people.first='Fred'
OR people.zip > (94700 + zip.margin)
Here’s the parser code (from Listing 4-32) that’s executed when a SELECT is encountered:
else if( in.matchAdvance(SELECT) != null )
{ List columns = idList();
String into = null;
if( in.matchAdvance(INTO) != null )
into = in.required(IDENTIFIER);
in.required( FROM );
List requestedTableNames = idList();
Expression where = (in.matchAdvance(WHERE) == null)
? null : expr();
Table result = doSelect(columns, into,
requestedTableNames, where );
return result;
}
The first call to idList() parses the list of columns and returns a java.util.List that contains the two strings "first" and "last". (The idList() method is on line 579 of Listing 4-32.) The second call to idList() does the same thing, but with tables listed in the FROM clause. The call to expr() (Listing 4-32, line 676) builds the tree of Expression objects shown in Figure 4-17, previously. The expr() method returns the RelationalExpression object at the root of the tree.
All this information is then passed to doSelect() (Listing 4-35, line 1137). This method first converts the table names to actual tables by looking up the names in the tables map. It then creates a Strategy object that the Table’s select() method can use to select rows and passes it into the primary table. Here’s the code for the Strategy object (from Listing 4-32, line -1):
Selector selector = (where == null) ? Selector.ALL :
new Selector.Adapter()
{ public boolean approve(Cursor[] tables)
{ Value result = where.evaluate(tables);
verify( result instanceof BooleanValue,
"WHERE clause must yield boolean result" );
return ((BooleanValue)result).value();
}
};
Table result = primary.select(selector, columns, participantsInJoin);
As the Table processes the select() statement, it calls approve() for every row, which causes the anonymous Selector.Adapter to ask the root node in the expression tree to evaluate itself. (This ConcreteTable code is way back in Listing 4-17, line 384.)
The topmost node in the expression tree is a RelationalExpression, and the first thing that its evaluate(...) method (Listing 4-33, line 922) does is evaluate the subexpressions.
Value leftValue = left.evaluate ( tables );
Value rightValue = right.evaluate( tables );
All of the Nonterminal Expressions start this way, in fact. In the current case, the left child of the root node is itself a RelationalExpression, so you’ll traverse the tree recursively down to the AtomicExpression at the far left.
The AtomicExpression’s evaluate(...) method (Listing 4-33, line 1008) just delegates to the contained Value, in this case an IdValue, so go to its value(...) method (Listing 4-34, line 1119). This method looks up the value of the last column on the current row of the people table and returns its value as a StringValue (shown in Figure 4-17 as an upward-pointing error on the edge leading into the AtomicExpression node). The RelationalExpression object that called the AtomicExpression’s evaluate(...) method now calls evaluate on its right child and gets back a StringValue that holds the String "Flintstone". It compares the two strings and creates a BooleanValue object that holds the result of the comparison and then returns that BooleanValue object. The code looks like this:
if( (leftValue instanceof StringValue)
|| (rightValue instanceof StringValue) )
{ verify(operator==EQ || operator==NE,
"Can't use < <= > or >= with string");
boolean isEqual =
leftValue.toString().equals(rightValue.toString());
return new BooleanValue(operator==EQ ? isEqual:!isEqual);
}
The remainder of the RelationalExpression’s evaluate() method doesn’t come into play in this scenario, but it handles the evaluation of relational operators that have numeric or null operands.
The remainder of the expression evaluation proceeds in the same fashion. The evaluate() call gets Value objects from the child nodes, evaluates those values appropriately, and returns a Value that holds the result. By the time you finish with the evaluate() method of the root node, you will have evaluated the entire expression.
The select() method is the most complex of the methods in Listing 4-35. The others work in pretty much the same way, however. They create a Selector that invokes the execute(...) method of the root node of the WHERE-clause expression tree, and the Selector approves or rejects rows by running the interpreter. The remainder of Listing 4-35 is a small unit-test class that runs the SQL script in Listing 4-27.
Listing 4-35. Database.java: Interpreter Invocation
1134
//====================================================================
==
1135 // Workhorse methods called from the parser.
1136 //
1137 private Table doSelect( List columns, String into,
1138 List requestedTableNames,
1139 final Expression where )
1140 throws ParseFailure
1141 {
1142
1143 Iterator tableNames = requestedTableNames.iterator();
1144
1145 assert tableNames.hasNext() : "No tables to use in select!" ;
1146
1147 // The primary table is the first one listed in the
1148 // FROM clause. The participantsInJoin are the other
1149 // tables listed in the FROM clause. We're passed in the
1150 // table names; use these names to get the actual Table
1151 // objects.
1152
1153 Table primary = (Table) tables.get( (String) tableNames.next() );
1154
1155 List participantsInJoin = new ArrayList();
1156 while( tableNames.hasNext() )
1157 { String participant = (String) tableNames.next();
1158 participantsInJoin.add( tables.get(participant) );
1159 }
1160
1161 // Now do the select operation. First create a Strategy
1162 // object that picks the correct rows, then pass that
1163 // object through to the primary table's select() method.
1164
1165 Selector selector = (where == null) ? Selector.ALL :
1166 new Selector.Adapter()
1167 { public boolean approve(Cursor[] tables)
1168 { try
1169 {
1170 Value result = where.evaluate(tables);
1171
1172 verify( result instanceof BooleanValue,
1173 "WHERE clause must yield boolean result" );
1174 return ((BooleanValue)result).value();
1175 }
1176 catch( ParseFailure e )
1177 { throw new ThrowableContainer(e);
1178 }
1179 }
1180 };
1181
1182 try
1183 { Table result = primary.select(selector, columns, participantsInJoin);
1184
1185 // If this is a "SELECT INTO <table>" request, remove the
1186 // returned table from the UnmodifiableTable wrapper, give
1187 // it a name, and put it into the tables Map.
1188
1189 if( into != null )
1190 { result = ((UnmodifiableTable)result).extract();
1191 result.rename(into);
1192 tables.put( into, result );
1193 }
1194 return result;
1195 }
1196 catch( ThrowableContainer container )
1197 { throw (ParseFailure) container.contents();
1198 }
1199 }
1200 //- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
1201 private int doInsert(String tableName, List columns, List values)
1202 throws ParseFailure
1203 {
1204 List processedValues = new LinkedList();
1205 Table t = (Table) tables.get( tableName );
1206
1207 for( Iterator i = values.iterator(); i.hasNext(); )
1208 { Expression current = (Expression) i.next();
1209 processedValues.add(
1210 current.evaluate(null).toString() );
1211 }
1212
1213 // finally, put the values into the table.
1214
1215 if( columns == null )
1216 return t.insert( processedValues );
1217
1218 verify( columns.size() == values.size(),
1219 "There must be a value for every listed column" );
1220 return t.insert( columns, processedValues );
1221 }
1222 //- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
1223 private int doUpdate( String tableName, final String columnName,
1224 final Expression value, final Expression where)
1225 throws ParseFailure
1226 {
1227 Table t = (Table) tables.get( tableName );
1228 try
1229 { return t.update
1230 ( new Selector()
1231 { public boolean approve( Cursor[] tables )
1232 { try
1233 { Value result = where.evaluate(tables);
1234
1235 verify( result instanceof BooleanValue,
1236 "WHERE clause must yield boolean result" );
1237
1238 return ((BooleanValue)result).value();
1239 }
1240 catch( ParseFailure e )
1241 { throw new ThrowableContainer(e);
1242 }
1243 }
1244 public void modify( Cursor current )
1245 { try
1246 { Value newValue=value.evaluate( new Cursor[]{current} );
1247 current.update( columnName, newValue.toString() );
1248 }
1249 catch( ParseFailure e )
1250 { throw new ThrowableContainer(e);
1251 }
1252 }
1253 }
1254 );
1255 }
1256 catch( ThrowableContainer container )
1257 { throw (ParseFailure) container.contents();
1258 }
1259 }
1260 //- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
1261 private int doDelete( String tableName, final Expression where )
1262 throws ParseFailure
1263 { Table t = (Table) tables.get( tableName );
1264 try
1265 { return t.delete
1266 ( new Selector.Adapter()
1267 { public boolean approve( Cursor[] tables )
1268 { try
1269 { Value result = where.evaluate(tables);
1270 verify( result instanceof BooleanValue,
1271 "WHERE clause must yield boolean result" );
1272 return ((BooleanValue)result).value();
1273 }
1274 catch( ParseFailure e )
1275 { throw new ThrowableContainer(e);
1276 }
1277 }
1278 }
1279 );
1280 }
1281 catch( ThrowableContainer container )
1282 { throw (ParseFailure) container.contents();
1283 }
1284 }
One other aspect of the doSelect(...) method at the top of Listing 4-35 (p. 316) bears mentioning. Here’s a stripped-down version of the call to the Table’s select() method with the interesting code in bold:
Selector selector = (where == null) ? Selector.ALL :
new Selector.Adapter()
{ public boolean approve(Cursor[] tables)
{ try
{ Value result = where.evaluate(tables);
//...
}
catch( ParseFailure e )
{ throw new ThrowableContainer(e);
}
}
};
try
{ Table result = primary.select(selector, columns, participantsInJoin);
//...
}
catch( ThrowableContainer container )
{ throw (ParseFailure) container.contents();
}
What’s that ThrowableContainer doing? The interface defined by Table and Selector is very generic by necessity. The approve() method, for example, is not declared as throwing any sort of exception because it’s impossible to predict what that exception may be.
The evaluate() method called in approve() throws a ParseFailure object, and ParseFailure is a checked exception—I have to deal with it. I want that exception toss to propagate out of approve(...), but to do that, I’d have to add a throws ParseFailure to the approve(...) declaration. The compiler will then (quite rightly) complain, because the definition of approve() in the Selector interface is not declared as throwing any sort of exception at all. I don’t want to append a throws ParseFailure the approve() definition in the Selector, however. A ParseFailure exception is used by the current parser only; it is irrelevant to all other implementers of Selector, and I don’t want to couple the Table/Selector interfaces to the SQL-interpreter layer.
I’ve solved the problem with the ThrowableContainer class in Listing 4-36. This class is quite simple; it’s nothing but a RuntimeException subclass that holds a Throwable object. The approve(...) method packages the ParseFailure exception into the container and then throws the container. The catch clause that surrounds the select(...) call (which calls approve(...)) catches the container, unpacks the contained ParseException object, and then throws the ParseException object.
The ThrowableContainer is effectively performing what I think of as a lateral type conversion—sideways in the class hierarchy—not to a subclass or superclass type, but to a sibling type. It’s as if I have converted an ArrayList to a LinkedList.
The obvious downside of this wrapping strategy is that it subverts the type-safety system. For example, if doSelect(...) were behaving badly, it could just let the ThrowableContainer propagate out to the calling method rather than catching the container and throwing the contained object. The calling method wouldn’t have a clue what to do with the ThrowableContainer, however. Also on the downside is that I’ve converted a checked-exception object into a RuntimeException that is not checked, which defeats the whole purpose of checked exceptions. It would be a serious problem, in other words, if I didn’t convert the exception object back to its original type by unwrapping it.
These negatives are pretty severe. I’m willing to put up with them in the current code because the packaging and unpackaging operations all occur within a few lines of each other in the source code, so the code remains reasonably maintainable.
Listing 4-36. ThrowableContainer.java
1 package com.holub.tools;
2
3 /** A convenient container for realying a checked Exception
4 * from a method that can't declare a throws clause to
5 * a calling method that can.
6 */
7
8 public class ThrowableContainer extends RuntimeException
9 { private final Throwable contents;
10 public ThrowableContainer( Throwable contents )
11 { this.contents = contents;
12 }
13 public Throwable contents()
14 { return contents;
15 }
16 }
The JDBC Layer
You’ll be happy to hear that the hard part is over (whew!). All that’s left is writing a JDBC driver, which turns out to be a trivial enterprise. A few interesting applications of design patterns exist in the JDBC-driver code, however.
Most of the classes in the following discussion are mine. To make the discussion clear, however, I’ve set off any classes or interfaces that are part of Java by using their fully qualified class name (java.sql.Xxx). If you don’t see the (java.sql), then the class is one of mine.
Figure 4-18 shows the structure and patterns for the JDBC layer, and I’ll explain this diagram in depth over the course of this section.
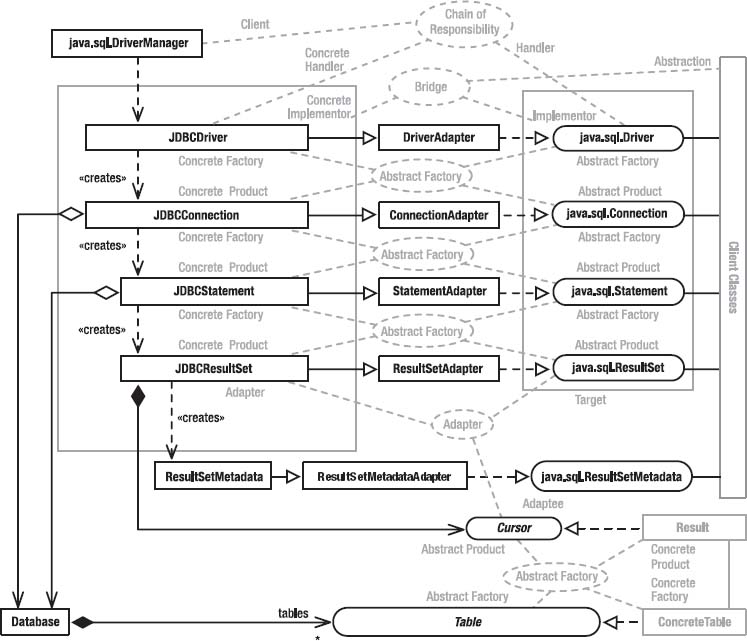
Figure 4-18. The structure and patterns of the JDBC layer
If you’ve never used JDBC, the easiest way to learn it is to look at a simple application. Listing 4-37 is a small test program that’s a minor adaptation of the example in Sun’s JDBC documentation. I’ll explain this listing throughout the rest of this section.
Listing 4-37. JDBCTest.java
1 package com.holub.database.jdbc;
2
3 import java.sql.*;
4
5 public class JDBCTest
6 {
7 static String[] data =
8 { "(1, 'John', 'Mon', 1, 'JustJoe')",
9 "(2, 'JS', 'Mon', 1, 'Cappuccino')",
10 "(3, 'Marie', 'Mon', 2, 'CaffeMocha')",
11 };
12
13 public static void main(String[] args) throws Exception
14 {
15 Class.forName( "com.holub.database.jdbc.JDBCDriver" )
16 .newInstance();
17
18 Connection connection = null;
19 Statement statement = null;
20 try
21 { connection = DriverManager.getConnection(
22 "file:/c:/src/com/holub/database/jdbc/Dbase",
23 "harpo", "swordfish" );
24
25 statement = connection.createStatement();
26
27 statement.executeUpdate(
28 "create table test (" +
29 " Entry INTEGER NOT NULL" +
30 ", Customer VARCHAR (20) NOT NULL" +
31 ", DOW VARCHAR (3) NOT NULL" +
32 ", Cups INTEGER NOT NULL" +
33 ", Type VARCHAR (10) NOT NULL" +
34 ", PRIMARY KEY( Entry )" +
35 ")"
36 );
37
38 for( int i = 0; i < data.length; ++i )
39 statement.executeUpdate(
40 "insert into test VALUES "+ data[i] );
41
42 // Test Autocommit stuff. If everything's working
43 // correctly, there James should be in the databse,
44 // but Fred should not.
45
46 connection.setAutoCommit( false );
47 statement.executeUpdate(
48 "insert into test VALUES "+
49 "(4, 'James', 'Thu', 1, 'Cappuccino')" );
50 connection.commit();
51
52 statement.executeUpdate(
53 "insert into test (Customer) VALUES('Fred')");
54 connection.rollback();
55 connection.setAutoCommit( true );
56
57 // Print everything.
58
59 ResultSet result = statement.executeQuery( "select * from test" );
60 while( result.next() )
61 { System.out.println
62 ( result.getInt("Entry") + ", "
63 + result.getString("Customer") + ", "
64 + result.getString("DOW") + ", "
65 + result.getInt("Cups") + ", "
66 + result.getString("Type")
67 );
68 }
69 }
70 finally
71 {
72 try{ if(statement != null) statement.close(); }catch(Exception e)
73 try{ if(connection!= null) connection.close();}catch(Exception e)
74 }
75 }
76 }
Probably the most confusing part of using JDBC is the driver-management mechanism. The problem Sun is trying to solve is a single program that needs to talk to a heterogeneous set of databases. That is, you need to talk to Oracle, Sybase, and SQL Server in a single program, and each database has a different driver.
Sun’s solution is a little odd, however. The java.sql.DriverManager class is an everything-is-static Singleton whose job is, not surprisingly, to manage a set of JDBC drivers. Before you can use the java.sql.DriverManager, however, you have to bring the vendor-specific drivers into existence. These drivers typically register themselves with the java.sql.DriverManager when they’re loaded (code in the driver’s static initializer block does the registration). So you have to load the class files for all the JDBC drivers that you need to use before you use the java.sql.DriverManager. That loading is done by the forName() call at the top of main() (Listing 4-37, line 15), which loads the class file and brings an instance into existence, causing the static-initializer block to execute as a side effect.
The JDBC driver for the current implementation is the JDBCDriver class in Listing 4-38. There’s not much to it. The static-initializer block that registers the driver object with the java.sql.DriverManager is on line 18. The jdbcCompliant() override (Listing 4-38, line 43) is small but important. By returning false it tells the users of this driver that the driver is not fully JDBC compliant. In other words, it’s perfectly okay for a JDBC implementation to be minimal, as long as it announces this to the world. As you’ll see in a moment, attempts to call unsupported methods in this minimal implementation result in an exception toss. Unfortunately, there’s no standard for “minimal,” so every driver has to document operations it supports. No “introspection” mechanism exists that you can use to find this information at runtime.
The other critical method is the acceptsURL(...) method on line 27 of Listing 4-38. To see why, go back to line 21 of Listing 4-37, reproduced here:
import java.sql.DriverManager;
//...
connection = DriverManager.getConnection(
"file:/c:/usr/src/com/holub/database/jdbc/Dbase",
"Harpo", "swordfish" );
All calls to a database start out by getting a java.sql.Connection to that database from the java.sql.DriverManager—you can’t talk to the database at all without a connection to it. To get a java.sql.Connection object that represents the connection, you call DriverManager.getConnection() with three arguments: a URL that typically specifies both the database type (MySQL, PostgreSQL, and so on) and the name of the database, along with a username and password. My code just uses a simple “file:” URL with no database-identifying prefix, but a more realistic example may look like this:
jdbc:postgresql=//postgresql.holub.com:1234/sales_database
Everything between the first colon and the equals sign specifies what sort of driver to use; the remainder of the URL identifies the server and port number on which the database resides and the name of the database itself.
The java.sql.DriverManager chooses the correct driver using the Chain-of-Responsibility pattern. It keeps a list of registered drivers, and when you request a connection, it passes each driver in the list an acceptsURL(...) message. As you can see in the version in Listing 4-38 (line 27), all this method typically does is examine the first part of the URL and report true if the current database is described. The PostgreSQL driver probably implements the method as follows:
public boolean acceptsURL(String url) throws SQLException
{ return url.startsWith("jdbc:postgresql");
}
Once the java.sql.DriverManager has identified the correct driver, it requests a connection by calling the driver’s connect() method. The current implementation is on line 31 of Listing 4-38. As you can see from Figure 4-18 (on p. 326), the JDBCDriver (up at the top of the picture) is both an Abstract java.sql.Connection Factory and a Chain-of-Responsibility Handler.
Listing 4-38. JDBCDriver.java
1 package com.holub.database.jdbc;
2
3 import java.sql.*;
4 import java.util.*;
5 import java.net.*;
6
7 /** A JDBC driver for a small in-memory database that wraps
8 * the {@link com.holub.database.Database} class. See that
9 * class for a discussion of the supported SQL.
10 *
11 * @see com.holub.database.Database
12 */
13
14 public class JDBCDriver implements java.sql.Driver
15 {
16
17 private JDBCConnection connection;
18 static
19 { try
20 { java.sql.DriverManager.registerDriver( new JDBCDriver() );
21 }
22 catch(SQLException e)
23 { System.err.println(e);
24 }
25 }
26
27 public boolean acceptsURL(String url) throws SQLException
28 { return url.startsWith("file:/");
29 }
30
31 public Connection connect(String uri, Properties info)
32 throws SQLException
33 { try
34 { return connection = new JDBCConnection(uri);
35 }
36 catch( Exception e )
37 { throw new SQLException( e.getMessage() );
38 }
39 }
40
41 public int getMajorVersion() { return 1; }
42 public int getMinorVersion() { return 0; }
43 public boolean jdbcCompliant() { return false; }
44
45 public DriverPropertyInfo[]
46 getPropertyInfo(String url, Properties info) throws SQLException
47 { return new DriverPropertyInfo[0];
48 }
49 }
The next step in the JDBC process is to create a java.sql.Statement object that encapsulates the SQL processing. You get a java.sql.Statement from a java.sql.Connection and then use the java.sql.Statement to issue a SQL request like this:
java.sql.Statement SQLStatement = connection.createStatement();
SQLStatement.executeUpdate
( "create table test (" +
" Entry INTEGER NOT NULL" +
", Customer VARCHAR (20) NOT NULL" +
", Cups INTEGER NOT NULL" +
", Type VARCHAR (10) NOT NULL" +
", PRIMARY KEY( Entry )" +
")"
);
A java.sql.Connection is an Abstract java.sql.Statement Factory, which is interesting because the single class serves in different roles in two separate reifications of Abstract Factory. JDBConnection is a Concrete Product (created by the JDBCDriver factory) in one reification and a Concrete Factory (of java.sql.Statement objects) in the other. Looking at Figure 4-11, you’ll see that the same dual participation occurs with several other JDBC classes as well. A JDBCDriver is a factory of JDBCConnection objects, which are, in turn, JDBCStatement factories, which are themselves JDBCResultSet factories.
The JDBCConnection class that I’ll describe in the following section (in Listing 4-40) implements the java.sql.Connection interface, but it does so indirectly. JDBCConnection extends com.holub.database.jdbc.adapters.ConnectionAdapter (in Listing 4-39), which implements java.sql.Connection. The ConnectionAdapter class implements all the interface methods with versions that throw exceptions. It provides a way of not cluttering up the real code with methods that aren’t implemented. I’ve used the same strategy to handle unsupported methods in the java.sql.ResultSet, java.sql.ResultSetMetaData, and java.sql.Statement interfaces. The ResultSetAdapter, ResultSetMetaDataAdapter, and StatementAdapter classes implement the matching interface with methods that do nothing but throw an exception. I haven’t bothered to provide listings for these classes here, but they’re in the source code on the web site.
Listing 4-39. ConnectionAdapter.java (Partial Listing)
1 package com.holub.database.jdbc.adapters;
2 import java.sql.*;
3 public class ConnectionAdapter implements java.sql.Connection
4 {
5 public ConnectionAdapter()
6 throws SQLException
7
8 public ConnectionAdapter(java.sql.Driver driver, String url,
9 java.util.Properties info)
10 throws SQLException
11 {throw new SQLException("unsupported"); }
12
13 public void setHoldability(int h)
14 throws SQLException
15 {throw new SQLException("unsupported"); }
16
17 public int getHoldability()
18 throws SQLException
19 {throw new SQLException("unsupported"); }
20
21 //...
22
23 public void setTypeMap(java.util.Map map)
24 throws SQLException
25 {throw new SQLException("unsupported"); }
26 }
27
The State Pattern and JDBCConnection
The JDBCConnection class (Listing 4-40) serves as a wrapper for the Database class. It implements that part of the JDBC bridge that represents the database itself. The Database object is created by the JDBCConnection constructors, and the database contents are dumped to disk when the connection is closed.
Most of the methods of JDBCConnection implement JDBC’s rather odd (to me) transaction mechanism: When you set auto-commit mode off by calling setAutoCommit(false), the system issues a BEGIN request. Subsequent calls to commit() or rollback() issue the matching SQL and then issue another BEGIN request. No begin() method exists. If you never call setAutoCommit(false), then every SQL request you issue is treated as a transaction and cannot be rolled back. JDBC does not support nested transactions. Nonetheless, you can ignore all the methods I’ve just been discussing and do transactions using executeUpdate(...) to issue BEGIN, COMMIT, and ROLLBACK requests at the SQL level.
I’ve implemented the auto-commit behavior using the Gang-of-Four State pattern, pictured in Figure 4-19. The State pattern provides a way of organizing a class whose objects change behavior when they change state. In the current example, the behavior of four methods (close(), commit(), rollback(), and setAutoCommit(...)) changes, depending on whether the connection is in the auto-commit-enabled state.
The naïve way to implement behavior that changes with state is to put a field in the class that indicates the current state and then put a switch statement or equivalent in every method, with the state-related behavior put into the case statements. Here’s a simplistic example:
class ChangesBehaviorWithState
{
private static int state = 0;
public void methodOne()
{ switch( state )
{
case 0: /* behavior for state 0 goes here */ break;
case 1: /* behavior for state 1 goes here */ break;
case 2: /* behavior for state 2 goes here */ break;
}
}
public void methodTwo()
{ switch( state )
{
case 0: /* behavior for state 0 goes here */ break;
case 1: /* behavior for state 1 goes here */ break;
case 2: /* behavior for state 2 goes here */ break;
}
}
//...
}
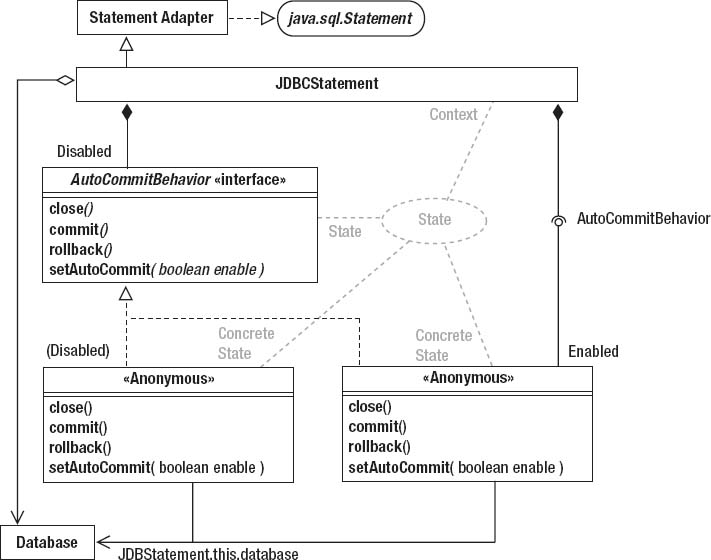
Figure 4-19. The State pattern in com.holub.database.jdbc.JDBCConnection
This approach has two problems. First, all those switch statements add a lot of clutter to the code and make it hard to read. Second, the code is inherently difficult to maintain since the behavior associated with a given state is scattered all over the class definition. Changing the underlying state machine (the rules that determine how you get from one state to another and definitions of the behavior associated with each state) is particularly difficult.
The State pattern solves both problems. Here’s the structure:
First create an interface that contains definitions for those methods whose behavior changes with state. I’ve done that in Listing 4-40 with the AutoCommitBehavior interface on line 104. In the State pattern, this interface has the role of State.
Next, implement that interface as many times as there are states. Each implementation defines the behavior associated with one and only one state. In Listing 4-40, the auto-commit-enabled behavior is defined in the anonymous inner class assigned to enabled on line 111; the auto-commit-disabled behavior is defined in the anonymous inner class assigned to disabled on line 124. In the State pattern, these implementers of the State have the role of Concrete State.
Next, define a variable that points at an object representing the behavior associated with the current state. I’ve done that with the autoCommitState field declared on line 165 in Listing 4-40.
Finally, in the methods whose behavior changes with state, you delegate to the object that represents the current-state’s behavior. For example, rollback() (on line 143 of Listing 4-40) just calls autoCommitState.rollback(). The class that uses the State objects (the JDBCConnection) has the role of Context in the pattern.
In the current implementation, state changes are accomplished by the setAutoCommit() calls in the Concrete State objects. The pattern does not require that you change state in this particular way, however.
As a final observation on State, you often find State and Proxy combined. Consider a proxy for a slowly loading object such as Java’s Image class. (To remind you, the getImage() method returns a proxy for the real image that is being downloaded slowly in the background. You can use the Image proxy even before the entire actual image has been pulled across the network.) This sort of Proxy can be in two states (Real Subject available and Real Subject unavailable), and you can use the State pattern for the code that handles these states.
Listing 4-40. JDBCConnection.java
1 package com.holub.database.jdbc;
2
3 import java.io.*;
4 import java.net.*;
5 import java.util.*;
6 import java.sql.*;
7
8 import com.holub.database.*;
9 import com.holub.database.jdbc.adapters.*;
10 import com.holub.text.ParseFailure;
11
12 /** A limited version of the Connection class. All methods
13 * undocumented base-class overrides throw a
14 * {@link SQLException} if called.
15 * <p>
16 * Note that you can't
17 * mix non-autocommit behavior with explicit
18 * SQL begin/commit statements. For example, if you
19 * turn off autocommit mode (which causes a SQL begin
20 * to be issued), and then execute a SQL begin manually,
21 * a call to <code>commit</code> will commit the inner transaction,
22 * but not the outer one. In effect, you can't do
23 * nested transactions using the JDBC {@link commit} or
24 * {@link rollback} methods.
25 */
26
27 public class JDBCConnection extends ConnectionAdapter
28 {
29 private Database database;
30
31 // Establish a connection to the indicated database.
32 //
33 public JDBCConnection(String uri) throws SQLException,
34 URISyntaxException,
35 IOException
36 { this( new URI(uri) );
37 }
38
39 public JDBCConnection(URI uri) throws SQLException,
40 IOException
41 { database = new Database( uri );
42 }
43
44 /** Close a database connection. A commit is issued
45 * automatically if auto-commit mode is disabled.
46 * @see #setAutoCommit
47 */
48 public void close() throws SQLException
49 { try
50 {
51 autoCommitState.close();
52
53 database.dump();
54 database=null; // make the memory reclaimable and
55 // also force a nullPointerException
56 // if anybody tries to use the
57 // connection after it's closed.
58 }
59 catch(IOException e)
60 { throw new SQLException( e.getMessage() );
61 }
62 }
63
64 public Statement createStatement() throws SQLException
65 { return new JDBCStatement(database);
66 }
67
68 /** Terminate the current transactions and start a new
69 * one. Does nothing if auto-commit mode is on.
70 * @see #setAutoCommit
71 */
72 public void commit() throws SQLException
73 { autoCommitState.commit();
74 }
75
76 /** Roll back the current transactions and start a new
77 * one. Does nothing if auto-commit mode is on.
78 * @see #setAutoCommit
79 */
80 public void rollback() throws SQLException
81 { autoCommitState.rollback();
82 }
83
84 /**
85 * Once set true, all SQL statements form a stand-alone
86 * transaction. A begin is issued automatically when
87 * auto-commit mode is disabled so that the {@link #commit}
88 * and {@link #rollback} methods will work correctly.
89 * Similarly, a commit is issued automatically when
90 * auto-commit mode is enabled.
91 * <p>
92 * Auto-commit mode is on by default.
93 */
94 public void setAutoCommit( boolean enable ) throws SQLException
95 { autoCommitState.setAutoCommit(enable);
96 }
97
98 /** Return true if auto-commit mode is enabled */
99 public boolean getAutoCommit() throws SQLException
100 { return autoCommitState == enabled;
101 }
102
103 //----------------------------------------------------------------------
104 private interface AutoCommitBehavior
105 { void close() throws SQLException;
106 void commit() throws SQLException;
107 void rollback() throws SQLException;
108 void setAutoCommit( boolean enable ) throws SQLException;
109 }
110
111 private AutoCommitBehavior enabled =
112 new AutoCommitBehavior()
113 { public void close() throws SQLException {/* nothing to do */}
114 public void commit() {/* nothing to do */}
115 public void rollback() {/* nothing to do */}
116 public void setAutoCommit( boolean enable )
117 { if( enable == false )
118 { database.begin();
119 autoCommitState = disabled;
120 }
121 }
122 };
123
124 private AutoCommitBehavior disabled =
125 new AutoCommitBehavior()
126 { public void close() throws SQLException
127 { try
128 { database.commit();
129 }
130 catch( ParseFailure e )
131 { throw new SQLException( e.getMessage() );
132 }
133 }
134 public void commit() throws SQLException
135 { try
136 { database.commit();
137 database.begin();
138 }
139 catch( ParseFailure e )
140 { throw new SQLException( e.getMessage() );
141 }
142 }
143 public void rollback() throws SQLException
144 { try
145 { database.rollback();
146 database.begin();
147 }
148 catch( ParseFailure e )
149 { throw new SQLException( e.getMessage() );
150 }
151 }
152 public void setAutoCommit( boolean enable ) throws SQLException
153 { try
154 { if( enable == true )
155 { database.commit();
156 autoCommitState = enabled;
157 }
158 }
159 catch( ParseFailure e )
160 { throw new SQLException( e.getMessage() );
161 }
162 }
163 };
164
165 private AutoCommitBehavior autoCommitState = enabled;
166 }
Statements
As you saw earlier, you issue a SQL request through a java.sql.Statement object that is manufactured by the java.sql.Connection’s createStatement() call. (The version on line 64 of Listing 4-41, discussed next, just hides a call to new.)
The JDBCStatment class (my implementation of java.sql.Statement) is laid out in Listing 4-41. There’s not much to it. The executeUpdate(...) method is used for all SQL statements that don’t return a value (everything except a SELECT); executeQuery(...) is used for SELECT. Both methods just delegate to the underlying Database object, though executeQuery(...) wraps in a java.sql.ResultSet object the Cursor across the rows of the Table object that holds the query results.
Listing 4-41. JDBCStatement.java
1 package com.holub.database.jdbc;
2
3 import java.sql.*;
4 import java.io.*;
5
6 import com.holub.database.*;
7 import com.holub.database.jdbc.adapters.*;
8
9 public class JDBCStatement extends StatementAdapter
10 { Database database;
11
12 public JDBCStatement(Database database)
13 { this.database = database;
14 }
15
16 public int executeUpdate(String sqlString) throws SQLException
17 { try
18 { database.execute( sqlString );
19 return database.affectedRows();
20 }
21 catch( Exception e )
22 { throw new SQLException( e.getMessage() );
23 }
24 }
25
26 public ResultSet executeQuery(String sqlQuery) throws SQLException
27 { try
28 { Table result = database.execute( sqlQuery );
29 return new JDBCResultSet( result.rows() );
30 }
31 catch( Exception e )
32 { throw new SQLException( e.getMessage() );
33 }
34 }
35 }
The Adapter Pattern (Result Sets)
The only Gang-of-Four design pattern I haven’t yet covered is Adapter, and the JDBCResultSet class has an example of it (Listing 4-42). Figure 4-20 shows the generalized form of the pattern.
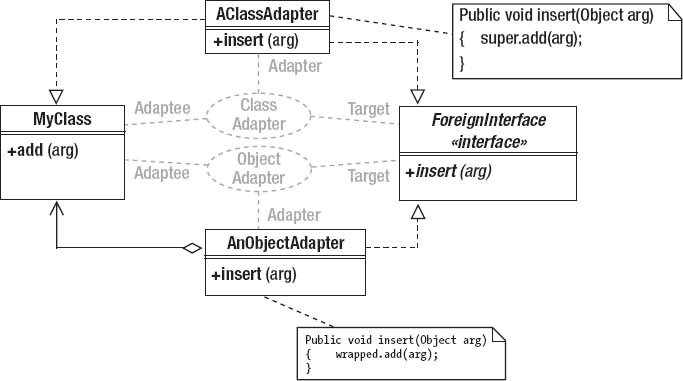
Figure 4-20. Object and class forms of Adapter
The term Adapter stems from an electrical adapter. You want to plug your 110v-60Hz-3-prong-plug radio into a European 220v-70Hz-2-cylindrical-prong outlet, so you use an adapter. This way, your radio’s interface to the power system appears to be the interface that the power system expects. Adapting this notion to software (so to speak), an Adapter makes an existing object of some class appear to implement an interface that it doesn’t actually implement (a “foreign” interface).
In the current situation, no difference really exists at all between a Cursor and a java.sql.ResultSet, at least in terms of core functionality. The JDBCResultSet class wraps a Cursor object so that the Cursor object can appear to implement the JDBCResultSet interface. The JDBCResultSet is an Adapter that makes a Cursor (the Adaptee) implement a foreign (or Target) interface (the java.sql.ResultSet).
Another example of Adapter is the ArrayIterator class (in Listing 4-10) you saw earlier. This Adapter lets you access an array as if it implements the Iterator interface.
The flavor of Adapter characterized by JDBCResultSet—which uses a wrapping strategy—is called an Object Adapter. Adapter has two other flavors, one identified by the Gang of Four and another that they don’t talk about but is worth examining. A Class Adapter uses extends relationships rather than wrapping.
If the Results class (the Concrete Class implemented by the Cursor returned from the ConcreteTable) was public, I could implement a Class-Adapter version of JDBCResultSet like this:
class ClassAdapterResultSet extends Results implements java.sql.ResultSet
{
// Implement all methods of ResultSet here, delegating to
// superclass (Results) methods whenever possible.
}
Class Adapters do have the advantage of simultaneously being the Adapter and Adaptee. (I could pass a ClassAdapterResultSet object to a method that took a Result or Cursor argument, and I could also pass it to a method that took a ResultSet argument.) Nonetheless, I haven’t used them much in practice, primarily because of the overhead of creating one. That is, if you have a Cursor in hand, and you need a JDBCResultSet, you must copy all the state data from the Cursor object to the JDBCResultSet object if it’s a class adapter. This copying also usually mandates a tight coupling relationship that makes me uncomfortable.
A third possibility would work just fine in the current context. I think of it as an Interface Adapter (not a Gang-of-Four variant of Adapter). Since the Results object implements Cursor, I could get the advantages of both the Class- and Object-Adapter forms like this:
class InterfaceAdapterResultSet implements Cursor, java.sql.ResultSet
{
private Cursor adaptee;
public InterfaceAdapterResultSet( Cursor adaptee )
{ this.adaptee = adaptee;
}
// Implement all methods of both interfaces here. Cursor
// methods do nothing but delegate to the adaptee.
}
This way, I’m still using containment rather than implementation inheritance, so none of the copying and the tight coupling that the copying implies is required. I implement both the Target and Adaptee interfaces, however, so I have the flexibility of the Class Adapter. You obviously can’t use this form of Adapter if the Adaptee doesn’t implement a well-defined interface.
The only use of Adapter in the Java libraries that comes to mind are the I/O system adapters, some of which were shown in Figure 4-9. A StringBufferInputStream, for example, is adapting StringBuffer so that it appears to implement the InputStream interface. StringBufferInputStream effectively changes the interface to a StringBuffer so that it can be treated as an InputStream.
The Java libraries don’t have many other Adapters, primarily because Adapters are usually used to force-fit a library into an existing context. You’ll typically find them in the code that uses the library, not in the library itself. Let’s say, for example, that you had written an application that used AWT for its user interface and that your boss suddenly announced that AWT was garbage, and you had to reimplement the application in terms of some off-the-wall library written by your boss’s brother-in-law. Refactoring 100,000 lines of code is one possibility, but it’s easier to write a set of Adapters that make the brother-in-law library appear to be AWT. This way you don’t have to rewrite your existing code.
People often confuse Bridge and Adapter. Keep things straight by keeping the intent of the pattern in mind. The point of Bridge is to isolate subsystems. The point of Adapter is to shoehorn a class into a program that was written in terms of an interface that the class doesn’t implement. Also, Bridges are big things, and Adapters are little things.
People also confuse Adapters and Decorators since they’re both wrappers. The point of a Decorator, however, is to change the behavior of one or more methods of some class without using extends. In terms of structure, a Decorator will always implement the same interface as the object it’s decorating. An Adapter probably won’t implement the interface of the wrapped object (though it may).
Getting back to the JDBC-layer code, the JDBCResultSet class (in Listing 4-42) is interesting in that it’s a true Gang-of-Four Object Adapter. It makes objects that implement Cursor appear to implement the ResultSet interface. For example, it changes the name of the advance() method to next(), and it hides the generic column(...) method (which gets a specified column of the current row) in a set of methods that get the column and do a type conversion as well (getString(), getDouble(), and so on). It also provides a few type-safe updatexxx() methods. These database accessors are useful in that they provide a modicum of type safety when the underlying system provides no type safety at all. (The Table stores everything as an Object, and the Database stores everything as a String.)
One final word on the subject of adapters is in order. My earlier use of the word Adapter in the JDBC-interface-implementation-class names (for example, ConnectionAdapter) is somewhat misleading. I’ve used the word Adapter because Java uses a similar default-implementation-that-does-nothing strategy in the AWT event model, and all those classes are called Adapters. (For example, MouseAdapter implements MouseListener.) These “Adapter” classes are not Adapters in the design-pattern sense of a class that makes an object appear to implement a foreign interface. This use of “Adapter” is just an unfortunate Java naming convention.
Listing 4-42. JDBCResultSet.java
1 package com.holub.database.jdbc;
2
3 import java.sql.*;
4 import java.text.*;
5
6 import com.holub.database.*;
7 import com.holub.database.jdbc.adapters.*;
8
9 /** A limited version of the result-set class. All methods
10 * not shown throw a {@link SQLException} if called. Note
11 * the underlying table actually holds nothing but
12 * strings, so the numeric accessors and mutators
13 * (e.g. {@link getDouble} and {@link setDouble})
14 * are doing string-to-number and number-to-string
15 * conversions. These conversions might fail if the
16 * underlying String doesn't represent a number.
17 */
18
19 public class JDBCResultSet extends ResultSetAdapter
20 {
21 private final Cursor cursor;
22 private static final NumberFormat format =
23 NumberFormat.getInstance();
24
25 /** Wrap a result set around a Cursor. The cursor
26 * should never have been advanced; just pass this constructor
27 * the return value from {@link Table#rows}.
28 */
29 public JDBCResultSet(Cursor cursor) throws SQLException
30 { this.cursor = cursor;
31 }
32
33 public boolean next()
34 { return cursor.advance();
35 }
36
37 public String getString(String columnName) throws SQLException
38 { try
39 { Object contents = cursor.column(columnName);
40 return (contents==null) ? null : contents.toString();
41 }
42 catch( IndexOutOfBoundsException e )
43 { throw new SQLException("column "+columnName+" doesn't exist" );
44 }
45 }
46
47 public double getDouble(String columnName) throws SQLException
48 { try
49 { String contents = getString(columnName);
50 return (contents == null)
51 ? 0.0
52 : format.parse( contents ).doubleValue()
53 ;
54 }
55 catch( ParseException e )
56 { throw new SQLException("field doesn't contain a number");
57 }
58 }
59
60 public int getInt(String columnName) throws SQLException
61 { try
62 { String contents = getString(columnName);
63 return (contents == null)
64 ? 0
65 : format.parse( contents ).intValue()
66 ;
67 }
68 catch( ParseException e )
69 { throw new SQLException("field doesn't contain a number");
70 }
71 }
72
73 public long getLong(String columnName) throws SQLException
74 { try
75 { String contents = getString(columnName);
76 return (contents == null)
77 ? 0L
78 : format.parse( contents ).longValue()
79 ;
80 }
81 catch( ParseException e )
82 { throw new SQLException("field doesn't contain a number");
83 }
84 }
85
86 public void updateNull(String columnName )
87 { cursor.update(columnName, null );
88 }
89 public void updateDouble(String columnName, double value)
90 { cursor.update(columnName, format.format(value) );
91 }
92 public void updateInt(String columnName, long value)
93 { cursor.update(columnName, format.format(value) );
94 }
95 public ResultSetMetaData getMetaData() throws SQLException
96 { return new JDBCResultSetMetaData(cursor);
97 }
98 }
Finishing Up the Code
The final implementation class is JDBCResultSetMetaData in Listing 4-43, which normally provides metadata information about the columns. Since there is no typing in the current implementation, all columns are treated as a SQL VARCHAR.
Listing 4-43. JDBCResultSetMetaData.java
1 package com.holub.database.jdbc;
2
3 import java.sql.*;
4 import java.util.*;
5
6 import com.holub.database.*;
7 import com.holub.database.jdbc.adapters.*;
8
9 /** A limited version of the result-set metadata class. All methods
10 * not shown throw a {@link SQLException} if called.
11 */
12 public class JDBCResultSetMetaData extends ResultSetMetaDataAdapter
13 {
14 private final Cursor cursor;
15
16 public JDBCResultSetMetaData(Cursor cursor)
17 { this.cursor = cursor;
18 }
19
20 public int getColumnType(int column) throws java.sql.SQLException
21 { return java.sql.Types.VARCHAR;
22 }
23
24 public String getColumnTypeName(int column)throws java.sql.SQLException
25 { return "VARCHAR";
26 }
27 }
When Bridges Fail
The JDBC layer that you’ve been looking at is another example of the Bridge pattern discussed earlier (in “The Bridge Pattern” section). You’re seeing only the implementation half of the Bridge, however (see Figure 4-4, on p. 199). As a Bridge, JDBC does serve to isolate your code from some of the problems that can emerge when you change databases.
JDBC is also a good example of how the Bridge pattern can fail, however. The problem is the SQL itself. Every database seems to use a different dialect of SQL, which is an enormous problem from a portability perspective. The whole point of Bridge is to replace some subsystem (for example, a database) with a completely different implementation (for example, a different database) without impacting your application code. You can certainly replace a SQL Server driver with a PostgreSQL driver with no difficulty. Unfortunately, though your code will still compile just fine, it probably won’t work anymore because PostgreSQL won’t recognize the SQL Server SQL dialect.
This problem has some solutions, but nobody has implemented them. One solution is to eliminate SQL altogether and provide a set of methods in the Bridge that does everything that you would normally do with SQL. A conforming driver would then have to implement these methods appropriately for its database. The main (significant) downside to this approach is that you can’t get a DBA to write SQL for you anymore; everything has to be done in Java.
A second “solution” is to require all drivers to support some defined standard SQL and to map this standard SQL to the native dialect as necessary. To really guarantee portability, the driver would also have to detect an attempt to issue a nonstandard SQL request and refuse to execute the request. The problem with this approach is a practical one. Most databases support a host of useful nonstandard features, and it’s often these nonstandard features that drive the decision to adopt a particular database. It’s simply not practical or appropriate to prevent a user of JDBC from using the very features that led him or her to select a particular database. It’s true that there’s a nontrivial common intersection between major SQL dialects, but you have to give up too much if you restrict yourself to that subset.
The same problem exists with the AWT bridge I mentioned earlier in the chapter. In both the JDBC and AWT case, you can even change runtime environments (or databases) on the fly as the program works. You certainly don’t have to recompile if you’re using a Bridge. However, as with JDBC, the behavior of the UI under AWT will change with the new environment, and things that used to work don’t work anymore. People used to jokingly call AWT the Write-Once-Test-Everywhere environment (as a foil to Sun’s Write-Once-Run-Everywhere slogan). The fact that Bridge rarely gives you complete isolation between subsystems is not insurmountable. Eclipse’s SWT library uses the Bridge pattern more effectively than did AWT, for example, primarily by making the Bridge so powerful that nobody needs to use OS-specific features. It is difficult to achieve true independence between subsystems, however.
Whew!
So, that’s all of the Gang-of-Four design patterns, all tangled together in two programs. As I said back in the preface, this is the way the patterns appear in the real world, and I hope you’ll develop a better understanding of the patterns by looking at them in a realistic context than you would by looking at a catalog. (Nonetheless, I’ve provided a catalog as an Appendix so that you can have a quick pattern reference.)
You’ll find two things start to happen as you become more familiar with the patterns. First, it will be a lot easier to talk about your code to other pattern-savvy programmers. It’s a lot easier to say “this is a Visitor” than it is to describe the structure of the code every time you talk about it.
The second emanation of pattern savvy is more important. As you build a mental catalog of not only the Gang-of-Four patterns but also the myriad other patterns that are documented in the literature, you’ll find that you code more effectively. You’ll be able to see where a pattern applies before you write the code and then write it “right” from the beginning.
So, go forth and program!