

Programming in terms of interfaces is a fundamental concept in OO systems in general and the Gang-of-Four design patterns in particular. Nonetheless, many Java programmers make little use of interfaces (and overuse the extends relationship). This chapter explains the problems with extends and how you can solve some of those problems with interfaces. I also introduce a few of the Creational patterns that simplify interface-based programming.
Why extends Is Evil
The extends keyword is evil—maybe not at the Charles-Manson/Vlad-the-Impaler level, but bad enough that reputable designers don’t want to be seen in public with it. The Gang-of-Four Design Patterns book is, in fact, largely about replacing implementation inheritance (extends) with interface inheritance (implements). That’s why I’ve devoted this entire chapter to using interfaces. I’ll also introduce a couple of design patterns in this chapter: Template Method, Abstract Factory, and Singleton.
Before launching into the discussion of extends, I want to head off a few misconceptions.
First, the next few sections talk in depth about how extends can get you into trouble. Since I’m focusing on the downside with such intensity, you may come to the conclusion that I think you should never use extends. That’s not the case. I’m assuming you already are familiar with the upside of extends and its importance in OO systems, so I don’t talk about that upside at all. I don’t want to qualify every statement I make with an “on the other hand,” so please excuse me if I give the wrong impression at times. Implementation inheritance is certainly a valuable tool when used appropriately.
Second, an important issue is the language itself. Simply because a language provides some mechanism doesn’t mean that that mechanism should be used heavily or thoughtlessly. Adele Goldberg—a pioneer of object orientation—once quipped,
Many people tell the story of the CEO of a software company who claimed that his product would be object oriented because it was written in C++. Some tell the story without knowing that it is a joke.
Java programmers sometimes confuse language features, such as extends, with object orientation itself. They will equate a statement such as “extends has problems” with “don’t do things in an OO way.” Don’t make this mistake. Inheritance is certainly central to OO, but you can put inheritance into your program in lots of ways, and extends is just one of these ways.
Language features such as extends certainly make it easier to implement OO systems, but simply using derivation does not make a system object oriented. (Polymorphism—the ability to have multiple implementations of the same type—is central to object-oriented thinking. Since the notion of polymorphism is unique to OO, you could reasonably argue that a system that doesn’t use polymorphism isn’t object oriented. Nonetheless, polymorphism is best achieved through interfaces, not extends relationships.)
To my mind, data abstraction—the encapsulation of implementation details within the object—is just as central to OO thinking as polymorphism. Of course, procedural systems can use data abstraction, but they don’t have to do so. Hard-core data abstraction is not optional in an OO system, however.
As I discussed in the preface, using a language feature mindlessly, without regard to the negative consequences of using the feature, is a great way to create bad programs. Implementation inheritance (extends) is valuable in certain situations, but it also can cause a lot of grief when used incorrectly. Polymorphism (redefining base-class behavior with a derived-class override) is central to object orientation, and you need some form of inheritance to get polymorphism. Both extends and implements are forms of inheritance, though. The class that implements an interface is just as much a derived class as one that extends another class.1
The similarity between extends and implements is quite clear in a language such as C++, simply because C++ doesn’t distinguish between the two syntactically. For you C++ programmers, a C++ interface is a virtual base class containing nothing but “pure” virtual functions. The lack of syntactic sugar to support interface-based programming doesn’t mean that C++ doesn’t support interfaces. It’s just that it doesn’t have an interface keyword.
Interfaces vs. Classes
I once attended a Java User’s Group meeting where James Gosling (Java’s inventor) spoke about some eminently forgettable topic. Afterward, in a memorable Q&A session, someone asked him, “If you could do Java over again, what would you change?” His reply was, “I’d leave out classes.” After the laughter died down, he explained that the real problem wasn’t classes per se but rather implementation inheritance (the extends relationship). Interface inheritance (the implements relationship) is much preferred. Avoid implementation inheritance whenever possible.
Losing Flexibility
So, why? The first problem is that explicit use of a concrete-class name locks you into a specific implementation, making down-the-line changes unnecessarily difficult.
At the core of the contemporary “agile” development methodologies is the concept of parallel design and development. You start programming before you have fully specified the program. This way of working flies in the face of traditional wisdom—that a design should be complete before programming starts—but many successful projects have proven that you can use the technique to develop good-quality code even more rapidly (and cost effectively) than with the traditional pipelined approach. Agile development isn’t a good fit for every project, but it works nicely on small projects whose requirements change during development.
At the core of Agile parallel development is the notion of flexibility. You have to write your code in such a way that you can incorporate newly discovered requirements into the existing code as painlessly as possible. Rather than implementing features you may need, you implement only the features you do need, but in a way that accommodates change. Without flexibility, parallel development simply isn’t possible. Programming to interfaces is at the core of flexible structure. To see why, let’s look at what happens when you don’t use them. Consider the following code:
void f()
{ LinkedList list = new LinkedList();
//...
modify( list );
}
void modify( LinkedList list )
{
list.add( ... );
doSomethingWith( list );
}
Suppose that a new requirement for fast lookup has now emerged, so the LinkedList isn’t working. You need to replace it with a HashSet. In the existing code, that change is not localized since you’ll have to modify not only the initial definition (in f ()), but also the modify() definition (which takes a LinkedList argument). You’ll also have to modify the definition of doSomethingWith(), and so on, down the line.
So, let’s rewrite the code as follows so that modify() takes a Collection rather than a LinkedList argument:
void f()
{ Collection list = new LinkedList();
//...
modify( list );
}
void modify( Collection list )
{ list.add( ... );
doSomethingWith( list );
}
Let’s also presuppose that you make that change—from LinkedList to Collection everywhere else the concrete-class name appears in your code. This change makes it possible to turn the linked list into a hash table simply by replacing the new LinkedList() with a new HashSet() in the original definition (in f()). That’s it. No other changes are necessary.
As another example, compare the following code, in which a method just needs to look at all the members of some collection:
f()
{
Collection c = new HashSet();
//...
examine( c );
}
void examine( Collection c )
{ for( Iterator i = c.iterator(); i.hasNext() ;)
//...
}
to this more-generalized version:
void f()
{
Collection c = new HashSet();
//...
examine( c.iterator() );
}
void examine( Iterator i )
{ for(; i.hasNext() ; i.next() )
//...
}
Since examine() now takes an Iterator argument rather than a Collection, it can traverse not only Collection derivatives but also the key and value lists that you can get from a Map. In fact, you can write iterators that generate data instead of traversing a collection. You can write iterators that feed information from a test scaffold or a file to the program. g2() can accommodate all these changes without modification. It has enormous flexibility.
Coupling
A more important problem with implementation inheritance is coupling, the undesirable reliance of one part of a program on another part. Global variables are the classic example of why strong coupling is bad. If you change the type of a global variable, for example, all the code that uses that variable—that is coupled to the variable—can be affected, so all this code must be examined, modified, and retested. Moreover, all the methods that use the variable are coupled to each other through the variable. That is, one method may incorrectly affect the behavior of another method simply by changing the variable’s value at an awkward time. This problem is particularly hideous in multithreaded programs.
You should strive to minimize coupling relationships. You can’t eliminate coupling altogether, because a method call from an object of one class to an object of another is a form of coupling. Without some coupling, you’d have no program. Nonetheless, you can minimize coupling considerably by diligently following OO precepts, the most important being that the implementation of an object should be completely hidden from the objects that use it. For example, any fields that aren’t constant should always be private. Period. No exceptions. Ever. I mean it. (You can occasionally use protected methods to good effect, but protected instance variables are an abomination; protected is just another way to say public.)
As I discussed in depth in Chapter One, you should never use accessors and mutators (get/set functions that just provide access to a field) for the same reason—they’re just overly complicated ways to make a field public. Methods that return full-blown objects rather than a basic-type value are reasonable in situations where the class of the returned object is a key abstraction in the design. Similarly, a function called getSomething() can be reasonable if it’s a fundamental activity of the object to be a provider of information. (A getTemperature() on a Thermometer object makes sense, provided that this method returns a Temperature.) If the easiest way to implement some method is simply to return a field, that’s fine. It’s not fine to look at things the other way around (“I have this field, so I need to provide access”).
I’m not being pedantic here. I’ve found a direct correlation in my own work between the “strictness” of my OO approach, how fast the code comes together, and how easy it is to maintain the code. Whenever I violate a central OO principle such as implementation hiding, I find myself rewriting that code (usually because the code is impossible to debug). I don’t have time to write programs twice, so I’m really good about following the rules. I have no interest in purity for the sake of purity—my concern is entirely practical.
The Fragile-Base-Class Problem
Now let’s apply the concept of coupling to inheritance. In an implementation-inheritance system (one that uses extends), the derived classes are tightly coupled to the base classes, and this close connection is undesirable. Designers have applied the moniker “the fragile-base-class problem” to describe this behavior. Base classes are considered “fragile” because you can modify a base class in a seemingly safe way, but this new behavior, when inherited by the derived classes, may cause the derived classes to malfunction. You just can’t tell whether a base-class change is safe simply by examining the methods of the base class in isolation; you have to look at (and test) all derived classes as well. Moreover, you have to check all code that uses both base-class and derived-class objects, since the new behavior may also break this code. A simple change to a key base class can render an entire program inoperable.
Let’s look at the fragile-base-class and base-class-coupling problems together. The following class extends Java’s ArrayList class to make it behave like a stack (a bad idea, as you’ll see in a moment):
class Stack extends ArrayList
{ private int topOfStack = 0;
public void push( Object article )
{ add( topOfStack++, article );
}
public Object pop()
{ return remove( --topOfStack );
}
public void pushMany( Object[] articles )
{ for( int i = 0; i < articles.length; ++i )
push( articles[i] );
}
}
Even a class as simple as this one has problems. Consider what happens when a user leverages inheritance and uses the ArrayList’s clear() method to pop everything off the stack, like so:
Stack aStack = new Stack();
aStack.push("1");
aStack.push("2");
aStack.clear();
The code compiles just fine, but since the base class doesn’t know anything about the index of the item at the top of the stack (topOfStack), the Stack object is now in an undefined state. The next call to push() puts the new item at index 2 (the current value of the topOfStack), so the stack effectively has three elements on it, the bottom two of which are garbage.
One (hideously bad) solution to the inheriting-undesirable-methods problem is for Stack to override all the methods of ArrayList that can modify the state of the array to manipulate the stack pointer. This is a lot of work, though, and doesn’t handle problems such as adding a method like clear() to the base class after you've written the derived class.
You could try to fix the clear() problem by providing an override that threw an exception, but that’s a really bad idea from a maintenance perspective. The ArrayList contract says nothing about throwing exceptions if a derived class doesn’t want some base-class method to work properly. This behavior will be completely unexpected. Since a Stack is an ArrayList, you can pass a Stack to an existing method that uses clear(), and this client method will certainly not be expecting an exception to be thrown on a clear() call. It’s impossible to write code in a polymorphic environment if derived-class objects violate the base-class contract at all, much less this severely.
The throw-an-exception strategy also moves what would be a compile-time error into runtime. If the method simply isn’t declared, the compiler kicks out a method-not-found error. If the method is there but throws an exception, you won’t find out about the call until the program is actually running. Not good.
You would not be wrong if you said that extending ArrayList to define a Stack is bad design from a conceptual level as well. A Stack simply doesn’t need most of the methods that ArrayList provides, and providing access to those methods through inheritance is not a good plan. That is, many ArrayList operations are nonsensical in a Stack.
As an aside, Java’s Stack class doesn’t have the clear() problem because it uses the baseclass size() method in lieu of a top-of-stack index, but you could still argue that java.util.Stack should not extend java.util.Vector. The removeRange() and insertElementAt() methods inherited from Vector have no meaning to a stack, for example. There’s nothing to stop someone from calling these methods on a Stack object, however.
A better design of the Stack class uses encapsulation instead of derivation. That way, no inherited methods exist at all. The following new-and-improved version of Stack contains an ArrayList object rather than deriving from ArrayList:
class Stack
{ private int topOfStack = 0;
private ArrayList theData = new ArrayList();
public void push( Object article )
{ theData.add( topOfStack++, article );
}
public Object pop()
{ return theData.remove( --topOfStack );
}
public void pushMany( Object[] articles )
{ for( int i = 0; i < articles.length; ++i )
push( articles[i] );
}
public int size() // current stack size.
{ return theData.size();
}
}
The coupling relationship between Stack and ArrayList is a lot looser than it was in the first version. You don’t have to worry about inheriting methods you don’t want. If changes are made to ArrayList that break the Stack class, you would have to rewrite Stack to compensate for those changes, but you wouldn’t have to rewrite any of the code that used Stack objects. I do have to provide a size() method, since Stack no longer inherits size() from ArrayList.
So far so good, but now let’s consider the fragile-base-class issue. Let’s say you want to create a variant of Stack that keeps track of the maximum and minimum stack sizes over a period of time. The following implementation maintains resettable “high-water” and “low-water” marks:
class MonitorableStack extends Stack
{
private int highWaterMark = 0;
private int lowWaterMark = 0;
public void push( Object o )
{ push(o);
if( size() > highWaterMark )
highWaterMark = size();
}
public Object pop() { Object poppedItem = pop();
if( size() < lowWaterMark )
lowWaterMark = size();
return poppedItem;
}
public int maximumSize() { return highWaterMark; }
public int minimumSize() { return lowWaterMark; }
public void resetMarks () { highWaterMark = lowWaterMark = size(); }
}
This new class works fine, at least for a while. Unfortunately, the programmer chose to inherit the base-class pushMany() method, exploiting the fact that pushMany() does its work by calling push(). This detail doesn’t seem, at first, to be a bad choice. The whole point of using extends is to be able to leverage base-class methods.
One fine day, however, somebody runs a profiler and notices the Stack is a significant bottleneck in the actual execution time of the code. Our intrepid maintenance programmer improves the performance of the Stack by rewriting it not to use an ArrayList at all. Here’s the new lean-and-mean version:
class Stack
{
private int topOfStack = -1;
private Object[] theData = new Object[1000];
public void push( Object article )
{ theData[ ++topOfStack ] = article;
}
public Object pop()
{ Object popped = theData[ topOfStack-- ];
theData[topOfStack] = null; // prevent memory leak
return popped;
}
public void pushMany( Object[] articles )
{ assert (topOfStack + articles.length) < theData.length;
System.arraycopy(articles, 0, theData, topOfStack+1,
articles.length);
topOfStack += articles.length;
}
public int size() // current stack size.
{ return topOfStack + 1;
}
}
Notice that pushMany() no longer calls push() multiple times—it just does a block transfer.
The new version of Stack works just fine; in fact, it’s better (or at least, faster) than the previous version. Unfortunately, the MonitorableStack derived class doesn’t work any more, since it won’t correctly track stack usage if pushMany() is called. The derived-class version of push() is no longer called by the inherited pushMany() method, so the highWaterMark is no longer updated by pushMany(). Stack is a fragile base class.
Let’s imagine you can fix this problem by providing the following pushMany() implementation in MonitorableStack:
public void pushMany( Object[] articles )
{ for( int i = 0; i < articles.length; ++i )
push( articles[i] );
}
This version explicitly calls the local push() override, so you’ve “fixed” the problem, but note that similar problems may exist in all the other overrides of Stack, so you’ll have to examine all of them to make sure they still work.
Now let’s imagine that a new requirement emerges—you need to empty a stack without explicitly popping the items. You go back into the Stack declaration and add the following:
public void discardAll()
{ stack = new Object[1000];
topOfStack = -1;
}
Again, adding a method seems both safe and reasonable. You wouldn’t expect derived-class (or any other) code to break if you simply add a base-class method, since no derived class could possibly leverage the previously nonexistent addition. Unfortunately, this reasonable-seeming modification to the base-class definition has broken the derived classes yet again. Since discardAll() doesn’t call pop(), the high- and low-water marks in MonitorableStack are not updated if the entire stack is discarded.
So how can you structure the code so fragile base classes are less likely to exist? You’ll find a clue in the work you had to do. Every time you modified the base class, you had to override all the base-class methods in the derived classes and provide derived-class versions. If you find yourself overriding everything, you should really be implementing an interface, not extending a base class.
Under interface inheritance, there’s no inherited functionality to go bad on you. If Stack were an interface, implemented by both a SimpleStack and a MonitorableStack, then the code would be much more robust.
Listing 2-1 provides an interface-based solution. This solution has the same flexibility as the implementation-inheritance solution: You can write your code in terms of the Stack abstraction without having to worry about what kind of concrete stack you’re actually manipulating. You can also use an interface reference to access objects of various classes polymorphically. Since the two implementations must provide versions of everything in the public interface, however, it’s much more difficult to get things wrong.
Note that I’m not saying that implementation inheritance is “bad,” but rather that it’s a potential maintenance problem. Implementation inheritance is fundamental to OO systems, and you can’t (in fact, don’t want to) eliminate it altogether. I am saying that implementation inheritance is risky, and you have to consider the consequences before using it.
Generally, it’s safer to implement an interface using a delegation model as I've done with the MonitorableStack in Listing 2.1. (You delegate interface operations to a contained object of what would otherwise be the base class.) Both of these strategies are viable ways to incorporate inheritance into your system.
But, as with any design decision, you are making a trade-off by using a delegation model. The delegation model is harder to do. You’re giving up implementation convenience to eliminate a potential fragile-base-class bug. On the other hand, being able to use inherited functionality is a real time-saver, and these small “pass-through” methods increase the code size and impact maintainability. It’s your decision whether you’re willing to take the risk of a difficult-to-find bug emerging down the line in order to save you a few lines of code now. Sometimes it’s worth the risk—the base class may have 200 methods, and you’d have to implement all of them in the delegation model. That’s a lot of work to do.
Listing 2-1. Eliminating Fragile Base Classes Using Interfaces
1 import java.util.*;
2
3 interface Stack
4 {
5 void push( Object o );
6 Object pop();
7 void pushMany( Object[] articles );
8 int size();
9 }
10
11 class SimpleStack implements Stack
12 {
13 private int topOfStack = 0;
14 private ArrayList theData = new ArrayList();
15
16 public void push( Object article )
17 { theData.add( topOfStack++, article );
18 }
19
20 public Object pop()
21 { return theData.remove( --topOfStack );
22 }
23
24 public void pushMany( Object[] articles )
25 { for( int i = 0; i < articles.length; ++i )
26 push( articles[i] );
27 }
28
29 public int size() // current stack size.
30 { return theData.size();
31 }32 }
33
34 class MonitorableStack implements Stack
35 {
36 private int highWaterMark = 0;
37 private int lowWaterMark = 0;
38
39 SimpleStack stack = new SimpleStack();
40
41 public void push( Object o )
42 { stack.push(o);
43
44 if( stack.size() > highWaterMark )
45 highWaterMark = stack.size();
46 }
47
48 public Object pop()
49 {
50 Object returnValue = stack.pop();
51 if( stack.size() < lowWaterMark )
52 lowWaterMark = stack.size();
53 return returnValue;
54 }
55
56 public void pushMany( Object[] articles )
57 { for( int i = 0; i < articles.length; ++i )
58 push( articles[i] );
59
60 if( stack.size() > highWaterMark )
61 highWaterMark = stack.size();
62 }
63
64 public int maximumSize() { return highWaterMark; }
65 public int minimumSize() { return lowWaterMark; }
66 public void resetMarks () { highWaterMark = lowWaterMark = size(); }
67 public int size() { return stack.size(); }
68 }
Multiple Inheritance
Languages that support multiple inheritance let you have the equivalent of multiple extends relationships in a class definition. If extends is “bad,” surely multiple extends relationships are worse, but occasionally the moral equivalent of multiple inheritance is legitimately useful. For example, in the next chapter I’ll introduce the concept of a “menu site”—a frame window that has a menu bar. The main window of my application is both a frame window (a JFrame) and a MenuSite. A frame that acts as a menu site has all the properties of both base classes, so multiple inheritance seems reasonable in this context.
I’ve implemented this feature using interfaces and the delegation model I discussed in the previous section. (My class extends JFrame and implements the MenuSite interface, delegating all MenuSite operations to a default implementation object.) Conceptually, this solution accomplishes the same thing as multiple inheritance. Since this delegation-based solution is in common use, you could call this architecture the Multiple Inheritance design pattern.
Here’s the general form of the pattern:
interface Base
{ void f();
static class Implementation implements Base
{ public void f(){/*...*/}
}
}
// Effectively extend both Something and Base.Implementation:
class Derived extends Something implements Base
{ Base delegate = new Base.Implementation();
public void f()
{ delegate.f();
}
}
The implement/delegate idiom, like inheritance, has the benefit of not having to write the base-class code more than once. I’m using encapsulation of a default version rather than derivation from that default version to achieve that end. On the downside, I have to access the default implementation through a trivial accessor method in the encapsulating class, such as the one on the first line in f(), above. Similarly, the MonitorableStack.push(...) method (on line 41 of Listing 2-1) has to call the equivalent method in SimpleStack. Programmers grumble about having to write these one-liners, but writing an extra line of code is a trivial price to pay for eliminating a fragile base class. C++ programmers will also note that the implement/delegate idiom eliminates all of C++’s multiple-inheritance-related problems (such as implementation ambiguity).
Frameworks
A discussion of fragile base classes wouldn’t be complete without a mention of framework-based programming. Frameworks such as Microsoft’s Foundation Class (MFC) library have become a popular way of building class libraries. Though MFC itself is mercifully fading away, the structure of MFC has been entombed in countless Microsoft shops where the programmers assume that if Microsoft does it that way, it must be good.
A framework typically starts out with a library of half-baked classes that don’t do everything they need to do; but, rather, they rely on a derived class to provide key functionality that’s needed for the base class to operate properly. A good example in Java is the paint() method of the AWT Component class, which represents a rectangular area of the screen. Component defines paint(), but you’re expected to override paint() in the derived class to actually draw something on the screen. The paint() method is effectively a placeholder for the rendering code, and the real version of paint() must be provided by a derived class. Most frameworks are comprised almost entirely of these partially implemented base classes.
This derivation-based architecture is unpleasant for several reasons. The fragile-base-class issue I’ve been discussing is one of these. The proliferation of classes required to get the framework to work is an even more compelling problem. Since you have to override paint() to draw a window, each different window requires a derived class that overrides paint() to draw that window. You must derive a unique class from Component for every window that has to paint itself in some unique way. A program with 15 different windows may require 15 different Component derivatives.
One of my rules of thumb in OO estimation is that a class takes, on average, two to three weeks to fully implement in Java (including documentation and debugging) and longer in C++. The more classes you have, the longer it takes to write your program.
Here’s another perspective on the proliferation-of-classes problem: The customization-viaderivation strategy just doesn’t work if the hierarchy is at all deep. Consider the class hierarchy in Figure 2-1. The Editor class handles basic text manipulation. It accepts keystrokes and modifies an internal buffer in response to those keystrokes. The actual buffer update is performed by the (protected) updateBuffer() method, which is passed keystrokes and updates the buffer appropriately. In theory, you can change the way that particular keystrokes are interpreted by overriding this method (Custom Editor in gray in Figure 2-1).

Figure 2-1. A failure of Template Method
Unfortunately, the new behavior is available to only those classes that extend Custom Editor, not to any existing classes that extend Editor itself. You’ll have to derive classes from Editor, EditableTextControl, and Standalone Editor to get the new key mappings to be universally supported. You’ve doubled the size of this part of the class hierarchy. It would be nice to inject a class between Editor and its derivatives, but you’d have to change the source code to do that, and you may not have the source code. Design patterns such as Strategy, which I’ll discuss later in this chapter and in Chapter 4, can solve this problem nicely, but a pure derivation-based approach to customization won’t often work.
The Template-Method and Factory-Method Patterns
The updateBuffer() in Figure 2-1 is an example of the Template-Method pattern. In Template Method, base-class code calls an overridable placeholder method, the real implementation of which is supplied by the derived class. The base-class version may be abstract, or it may actually implement a reasonable default operation that the derived class will customize.
Template Method is best used in moderation; an entire class “framework” that depends on derivation-based customization is brittle in the extreme. The base classes are just too fragile. When I was programming in MFC, I had to rewrite all my applications every time Microsoft released a new version. Often the code compiled just fine but didn’t work anymore because some base-class method had changed. Template Method is not used in any of the code I supply in this book.
It’s a telling condemnation of Template Method that most of the Java-library code works pretty well “out of the box” and that the Java libraries are more useful than MFC ever was. You can extend the Java classes if you need to customize them for an off-the-wall application, but they work just fine without modification for the vast majority of applications. This sort of itworks-out-of-the-box structure is just better than a derivation-based framework. It’s easier to maintain, it’s easier to use, and it doesn’t put your code at risk if a vendor-supplied class changes its implementation.
Template Method is also an example of how fine the line between “idiom” and “pattern” can sometimes be. You can easily argue that the Template Method is just a trivial use of polymorphism and shouldn’t be glorified by the exalted title of pattern.
One reason for discussing Template Method in the current chapter is that you can use a trivial variant of Template Method to create objects that instantiate an unknown concrete class. The Factory-Method pattern describes nothing more than a Template Method that creates an object whose concrete class isn’t known to the base class. The declared return value of the Factory Method is some interface that the created object implements. Factory Method describes another way to hide concrete-class names from base-class code. (Factory Method is an unfortunate choice of name. People have a natural tendency to call any method that creates an object a factory method, but these creational methods are not the Factory-Method pattern.)
Swing’s JEditorPane class provides an example of Factory Method that demonstrates both what’s right and what’s wrong with Swing. JEditorPane implements a text-control widget that can display HTML and, as such, is incredibly useful. For example, the following code pops up a frame that displays some simple HTML text:
JFrame mainFrame = new JFrame();
JEditorPane pane = new JEditorPane();
pane.setContentType ( "text/html" );
pane.setEditable ( false );
pane.setText
(
"<html>" +
"<head>" +
"</head>" +
"<body>" +
"<center><b>Hello</b> <i>World</i></center>" +
"</body>" +
"</html>"
);
mainFrame.setContentPane(pane);
mainFrame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
mainFrame.pack();
mainFrame.show();
All you need do is set the content type to "text/html" to get the JEditorPane to interpret the tags for you.
The flip side of JEditorPane is that its underlying design is so complex that it’s excruciating to change its behavior in even trivial ways. The problem I wanted to solve was clientside-UI layout. Swing’s layout-manager mechanism can be difficult to use for laying out nontrivial UIs. Looking at Java’s JavaServer Pages (JSP) system, I thought, “how nice it would be to do most of my layout in HTML but have a simple mechanism (such as JSP custom tags) to call in custom controls where I needed them.” Essentially, I wanted a Panel whose layout could be specified in HTML (with custom tags). I called this class MarkupPanel because its layout could be specified with a markup language (HTML + custom tags).
I looked, first, at solving this problem by creating a custom LayoutManager, but I abandoned this approach for two reasons: I didn’t want to build an HTML parser, and it was difficult to associate the Component objects that I dropped into the Container with specific locations in the HTML that specified the layout. I decided to create my panel by modifying the JEditorPane, which did most of what I wanted already, to support custom tags. Listing 2-2 shows a stripped-down version of the real MarkupPanel class. I’ve added support for a <today> tag, which displays today’s date on the output screen, rather than implementing the generic mechanism I actually use. Even in its stripped-down form, you get a feel for the work involved in modifying the class to accept custom tags. It’s not a pretty picture.
HTML parsing is done by something called an EditorKit that’s used internally by the JEditorPane. To recognize a custom tag, you have to provide your own EditorKit. You do this by passing the JEditorPane object a setEditorKit(myCustomKit) message, and the most convenient way to do that is to extend JEditorKit and set things up in the constructor (Listing 2-2, line 15). By default the JEditorKit uses an EditorKit extension called HTMLEditorKit, which does almost all the necessary work.
The main thing you have to change is something called a ViewFactory, which the JEditorKit uses to build the visible representation of the HTML page. I’ve created an HTMLEditorKit derivative called MarkupPanelEditorKit that returns my custom view factory to the JEditorPane (Listing 2-2, line 21).
The CustomViewFactory (Listing 2-2, line 29) overrides a single method, create(). Every time the JEditorPane recognizes a new HTML element in the input, it calls create(), passing it an Element object that represents the element actually found. The create() method extracts the tag name from the Element. If the tag is a <today> tag (recognized on line 40), create() returns an instance of yet another class: a View, whose createComponent() method returns the Component that’s actually displayed on the screen in place of the <today> tag.
Whew! As I said, Swing is not an example of simplicity and clarity in program design. This is an awful lot of complexity for an obvious modification. Swing’s architecture is, I think, way too complex for what it does. One of the reasons for this overcomplexity is that someone went crazy with patterns without considering whether the resulting system was usable. I wouldn’t disagree if you argued that Factory Method was not the best choice of patterns in the previous code.
Be that as it may, this code demonstrates an abundance of Factory Method reifications—the pattern is used thee times in an overlapping fashion.
Figure 2-2 shows the structure of the system. The design patterns are indicated using the collaboration symbol: a dashed oval labeled with the pattern name. The lines that connect to the oval indicate the classes that participate in the pattern, each of which is said to fill some role. The role names are standardized—they’re part of the formal pattern description in the Gang-of-Four book, for example. The roles taken on by some class are identified in UML by putting the names at the end of the line that comes out of the collaboration symbol.
Look at the first of the Factory Method reifications: By default, an HTMLEditorKit creates an HTMLEditorKit.HTMLFactory by calling getViewFactory() (the Factory Method). MarkupPanelEditorKit extends HTMLEditorKit and overrides the Factory Method (getViewFactory()) to return an extension of the default HTMLEditorKit.HTMLFactory class.
In this reification, HTMLEditorKit has the role of Creator. HTMLEditorKit.HTMLFactory has the role of Product, and the two derived classes, MarkupPanelEditorKit and CustomViewFactory, have the roles of Concrete Creator and Concrete Product.
Now shift focus and look at the classes and patterns from a slightly different perspective. In the second reification of Factory Method, HTMLEditorKit.HTMLFactory and ComponentView have the roles of Creator and Product. The Factory Method is create(). I extend HTMLEditorKit.HTMLFactory to create the Concrete Creator, CustomViewFactory, whose override of create() manufactures the Concrete Product: the anonymous inner class that extends ComponentView.
Now refocus again. In the third reification, ComponentView and the anonymous inner class have the roles of Creator and Product. The Factory Method is createComponent(). I extend ComponentView to create the Concrete Creator, the anonymous inner class, whose override of createComponent() manufactures the Concrete Product: a JLabel.
So, depending on how you look at it, HTMLEditorKit.HTMLFactory is either a Product or a Creator, and CustomViewFactory is either a Concrete Product or a Concrete Creator. By the same token, ComponentView is itself either a Creator or a Product, and so on.
Listing 2-2. Using the Factory Method
1 import java.awt.*;
2 import javax.swing.*;
3 import javax.swing.text.*;
4 import javax.swing.text.html.*;
5 import java.util.Date;
6 import java.text.DateFormat;
7
8 public class MarkupPanel extends JEditorPane
9 {
10 public MarkupPanel()
11 { registerEditorKitForContentType( "text/html",
12 "com.holub.ui.MarkupPanel$MarkupPanelEditorKit" );
13 setEditorKitForContentType(
14 "text/html",new MarkupPanelEditorKit() );
15 setEditorKit( new MarkupPanelEditorKit() );
16
17 setContentType ( "text/html" );
18 setEditable ( false );
19 }
20
21 public class MarkupPanelEditorKit extends HTMLEditorKit
22 {
23 public ViewFactory getViewFactory()24 { return new CustomViewFactory();
25 }
26 //...
27 }
28
29 private final class CustomViewFactory extends HTMLEditorKit.HTMLFactory
30 {
31 public View create(Element element)
32 { HTML.Tag kind = (HTML.Tag)(
33 element.getAttributes().getAttribute(
34 javax.swing.text.StyleConstants.NameAttribute) );
35
36 if( kind instanceof HTML.UnknownTag
37 && element.getAttributes().getAttribute(HTML.Attribute.ENDTAG)
38 ==null)
39 { // <today> tag
40 if( element.getName().equals("today") )
41 { return new ComponentView(element)
42 { protected Component createComponent()
43 { DateFormat formatter = DateFormat.
44 getDateInstance(DateFormat.MEDIUM);
45 return new JLabel( formatter.format(;
46 new Date() ) );
47 }
48 };
49 }
50 }
51 return super.create(element);
52 }
53 }
54 }
If you’re appalled by the complexity of this system, you’re not alone. Factory Method is just a bad choice of architecture. It takes way too much work to add a custom tag, an obvious modification to any HTML parser. You’ll see many other design patterns in subsequent chapters (such as Strategy) that would have been better choices.
If you’re mystified by why things are so complex, consider that the Swing text packages are extraordinarily flexible. In fact, they’re way more flexible than they need to be for any applications I’ve ever written. (I’ve been told there are actually requirements for this level of complexity in real programs, but I haven’t seen it.) Many designers fall into the trap of making up requirements because something may have to work in a certain way (as compared to requirements actually demanded by real users). This trap leads to code that’s more complex than it needs to be, and this complexity dramatically impacts the system’s maintainability and ease of use.
In my experience, the degree of flexibility built into Swing is a bogus requirement—a “feature” that nobody actually asked for or needed. Though some systems indeed need to be this complex, I have a hard time even imagining why I would need the level of flexibility that Swing provides, and the complexity increases development time with no obvious payback. In strong support of my claim that nobody needs to customize Swing to this degree is that nobody (who I know, at least) actually does it. Though you can argue that nobody can figure out how to do it, you can also argue that nobody has been lobbying for making customization easier.
I’ll finish up with Factory Method by noting that the pattern forces you to use implementation inheritance just to get control over object creation. This is really a bogus use of extends because the derived class doesn’t really extend the base class; it adds no new functionality, for example. This inappropriate use of the extends relationship leads to the fragile-base-class problem I discussed earlier.
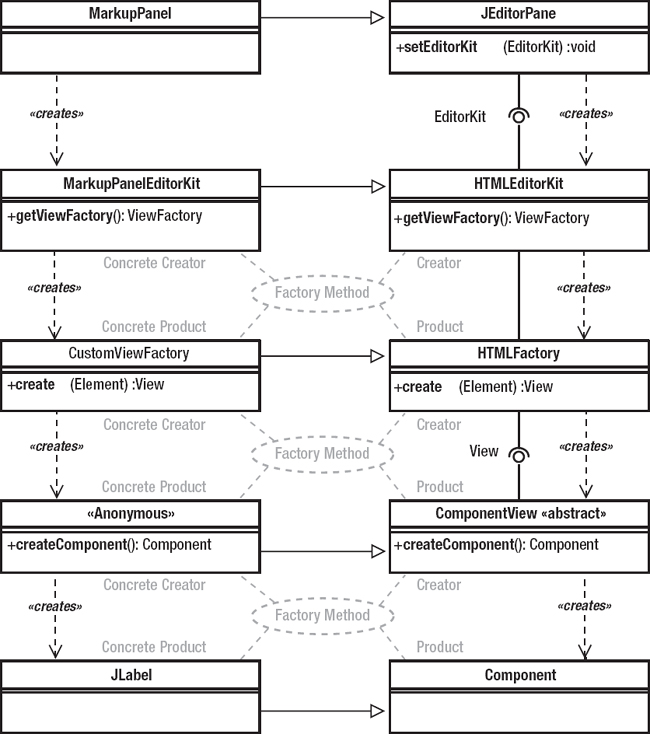
Figure 2-2. Overlapping uses of Factory Method in MarkupPanel
Summing Up Fragile Base Classes
I published an early version of parts of this chapter on JavaWorld, and I know from the responses there that many JavaWorld readers have discounted at least some of what I’ve just said because they’ve come up with workarounds for the problem. That is, you have a “solution” to the problem, so the issue is somehow invalid.
If that’s the case, you’re missing the point.
You should write your code so you don’t need to even think about these sorts of “solutions.” The problem with fragile base classes is that you are forced to worry about these sorts of “solutions” all the time, even after you think you have a debugged, functional class. No “solution” is permanent, since someone can come along and add a method to the base class that breaks all the derived classes. (Again, imagine that clear() wasn’t part of the original ArrayList class but was added after you wrote the Stack class. The addition seemed harmless, but it broke your Stack implementation.) The only real solution to the adding-a-malicious-method problem is encapsulation.
If you’ve come up with a solution that works, great. My point is that that’s what you should have done to begin with, and that many of the design patterns discussed later in this book are elegant solutions to the fragile-base-class problem. All the Gang-of-Four-design-pattern solutions depend on encapsulation and interfaces, however.
In general, it’s best to avoid concrete base classes and extends relationships. My rule of thumb is that 80 percent of my code at minimum should be written in terms of interfaces. I never use a reference to a HashMap, for example; I use references to the Map interface. (I’m using the word interface loosely here. An InputStream is effectively an interface when you look at how it’s used, even though it’s implemented as an abstract class.)
The more abstraction you add, the greater the flexibility. In today’s business environment, where requirements change regularly as the program is under development, this flexibility is essential. Moreover, most of the “agile” development methodologies (such as Crystal and Extreme Programming) simply won’t work unless the code is written in the abstract. On the other hand, flexibility typically comes at a cost: more complexity. Swing, I think, can be improved by making it less flexible, which would make it simpler to program and easier to maintain. Trade-offs always exist.
If you examine the Gang-of-Four patterns closely, you’ll see that a significant number of them provide ways to eliminate implementation inheritance in favor of interface inheritance, and that’s a common characteristic of many patterns you find. By definition, successful design patterns are extracted from well-written, easy-to-maintain code, and it’s telling that so much of this well-written, easy-to-maintain code avoids implementation inheritance like the plague.
Also bear in mind that extends is sometimes the best solution to a problem (see the next section). I know I’ve spent a lot of time arguing strongly against using extends, but that’s not to say that implementation inheritance is never valuable. Use extends with care, however, and only in situations where the fragility issue is outweighed by other considerations. As is the case with every design trade-off, you should weigh both the good and the bad points of every alternative and choose the alternative that has the most going for it. Implementation inheritance is certainly convenient and is often the simplest solution to a problem. Nonetheless, the base class is fragile, and you can always get inheritance without extends by implementing an interface that defines methods that access a contained instance of a default implementation.
When extends Is Appropriate
Having thoroughly vilified the extends relationship, let’s talk about when it’s appropriate to use it.
One good use of extends is in class normalization (a term I’ve borrowed from database design). A normalized class hierarchy concentrates into base classes code that would otherwise be implemented identically in multiple derived classes. Let’s explore this issue in some depth.
Though this book is not about the object-oriented design process, the way in which you go about producing a design can have a large effect on the quality of the result, and it’s important to discuss the process, at least superficially, so that you can see how extends relationships end up in the model.
Bad designs tend to be created inside out. The designer starts by creating a towering edifice of a static model (a giant “class diagram”) without any thought as to how those classes will actually be used in the actual program. The result is an ungainly mess—ten times larger than necessary, impossible to implement, and probably unusable without serious modification in the real program.
In practice, the class diagram should be little more than a convenient way of annotating information that you discover elsewhere in the design process. It’s an artifact of the process, not a driving force. Done properly, OO design involves the following steps:
- Learn the “problem domain” (accounting, order processing, and so on).
- Talk to your users to figure out the problems they need to solve.
- Identify use cases—stand-alone tasks performed by an end user that have some useful outcome—that cover all these problems.
- Figure out the activities you need to do to accomplish the goals established in the use case.
- Create a “dynamic model” that shows how a bunch of objects will send messages to one another at runtime to perform the activities identified in the previous step.
While you’re modeling dynamically, create a class diagram that shows how the objects interact. For example, if an object of class A sends a message to an object of class B, then the class diagram will show an association between these classes and a “operation” in the class representing the receiving object.
Working this way, the static model is as lightweight as possible. It contains only those operations that are actually used in the design. Only those associations that need to exist actually exist.
So where does implementation inheritance (extends) come into the picture? It’s often the case that you notice that certain kinds of objects use only a subset of the operations in a given class. Whenever you see a subset, you should think “normalization.” All operations that are used by all the objects in the system should be defined in a common base class. All operations that are used by only a subset of the objects in a class should be defined in a class that extends that “normalized” base class. Adding derivation, then, is a design activity that occurs well into the design process, after you’ve done enough dynamic modeling that you can identify the common operations. It’s a way of concentrating common operations into a shared base class. So, normalization is one quite reasonable use of implementation inheritance.
Now let’s discuss the “is-a” relationship. Many books teach that you can use the phrase “ is a” to recognize inheritance relationships. If you can say that “an employee is a manager,” then the Manager class should derive from Employee. “Is a” works well when reading a classhierarchy diagram. (“A HashSet ‘is a’ Collection.”) It’s not a great design tool, however.
Don’t be thrown by the English language here. Simply because a real-world manager is an employee does not mean that you have Employee and Manager classes or that these classes have any relationship with each other in your model, much less an extends relationship. You could just as easily say that “this employee has management responsibilities” (which implies some sort of encapsulation) as say that “a manager is an employee” (which implies derivation).
I can think of several valid ways to associate Manager and Employee classes, but each way makes sense in only one context: If Employee and Manager do the same thing—have the same operations implemented in the same way—then they’re really the same class. Employees could be distinguished from managers by how they’re stored (the Employee objects in some list have managerial permissions), by an internal attribute, or by some other mechanism. Don’t confuse an employee in a managerial role (in other words, an instance of Employee that’s referenced by a variable called manager) with a Manager class.
If the two classes perform identical operations but do so differently, then there should be a common interface that each class implements. For example, Employee could be an interface that is implemented in different ways by both the Manager and Engineer classes.
If the two classes have no operations in common, then they are completely distinct, and no extends or implements relationship exists at all. For example, Employees may fill out timesheets, and Managers may authorize them. No common operations exist.2
If one of the classes adds a few operations to the other (a Manager does everything an Employee does, plus a bit), then extends may be appropriate.
The key to the inheritance structure is in the operations that are performed, whether these operations are shared, and so on.
The other issue affecting the should-I-use-extends decision is compile-time type checking. If you want the compiler to guarantee that certain operations can be executed only at certain times, then use extends. For example, if a Manager extends Employee, then you can’t perform managerial operations in methods that are passed Employee objects. This restriction is usually a good thing, but if there’s a reasonable default thing to do (nothing, for example), then it may make sense to dispense with the derivation and put a few empty methods in the base class. Simple class hierarchies are easier to build and maintain than complicated ones.
Of course, you could accomplish the same thing with interfaces. If a Manager was an Employee that implemented the Managerial interface, then you could pass around references to Managerial objects when appropriate and pass around Employee references when Managerial capabilities weren’t needed. I’d probably decide (between extends and implements) by looking at the complexity of the two solutions, choosing the simpler one.
I’ll mention one caveat: You don’t want any base-class methods that do nothing but throw exceptions. This practice moves compile-time errors into runtime and results in buggier programs. Sometimes the class hierarchy is simplified enough so that a runtime error is okay, but not often. For example, the methods of the various Java Collection classes that throw UnsupportedOperationException are reasonable, but only because it’s unlikely you’ll see this exception thrown once the code is debugged. (I’ve been told that the reason UnsupportedOperationException exists is that assertions weren’t part of the language when the collections were designed, which is fair enough. To my mind, UnsupportedOperationException should extend AssertionError, since it’s really identifying a problem that should be found at debug time.)
Getting Rid of extends
So let’s say you’re refactoring your system (improving its structure without changing its external behavior) and you notice that you need an interface where what you have now is a class. How do you do it?
Let’s start from the beginning. Here’s your existing class:
class Employee
{ //...
public void youAreFired()
{ // lots of code
}
}
and there’s a lot of code scattered through the system that looks something like this:
Employee fred = new Employee();
//...
fred.youAreFired();
Follow these steps:
- Create an interface that has the same name as the existing class, like so:
interface Employee
{ void youAreFired();
} - Rename the existing class, like so:
class Peon implements Employee // used to be Employee
{ public void youAreFired()
{ // lots of code
}
}
Now comes the hard part. You need to change every place that you create an Employee using new. The obvious modification simply replaces new Employee() with new Peon(), but that change will put you in the same position you were in when you started. If you need to change the interface or class name again, you'll still have to go back and change a lot of code. You really want to get rid of that new altogether, or at least hide it.
Factories and Singletons
One good strategy for avoiding the must-change-all-new-invocations problem is to use the Abstract-Factory pattern, which is usually combined with a second creational pattern, Singleton, when it's implemented. Abstract Factory is something of a building-block pattern, since many other patterns rely on Abstract Factories for at least some of their implementation. I’ll introduce the pattern now, and you’ll see many applications of it in subsequent chapters.
The common theme to all reifications of Abstract Factory is that you use a Factory to create an object whose exact type you don’t know. You do know the interfaces that the created object implements, but you don’t know the created object’s actual class. Listing 2-3 shows a workable example. (The UML is in Figure 2-3, though I don’t expect you to understand this diagram fully yet.) Using the Employee.Factory, you can replace all calls to new Employee() with Employee.Factory.create(). Since the create() method can return an instance of any class that implements the Employee interface, your code is isolated from any knowledge of the implementation class. You can change this class to some other Employee implementer without affecting your code.
Listing 2-3. A Workable Factory Implementation
1 public interface Employee
2 { void youAreFired();
3 }
4
5 public static class EmployeeFactory
6 { private Factory(){/*empty*/}
7
8 public static Employee create()
9 { return new Peon();
10 }
11 }
12
13 /*package*/ class Peon implements Employee
14 { public void youAreFired()
15 { // lots of code
16 }
17 }

Note in Listing 2-3 that I’ve made the “concrete class” (Peon) package access to limit its scope. Since I expect users of the Peon to get instances via EmployeeFactory.create(), and I expect them to access the instances through only the Employee interface, no one needs to be able to access Peon at all.
I could restrict access to the concrete class even further by making it a private inner class of the factory, like this:
public static class EmployeeFactory
{ private EmployeeFactory(){/*empty*/}
public static Employee create()
{ return new Peon();
}
private static class Peon implements Employee
{ public void youAreFired()
{ // lots of code
}
}
}
Now, nobody (including classes in the same package as EmployeeFactory) can instantiate Peon objects directly.
It’s also interesting to look at the following anonymous-inner-class version of the factory:
public static class EmployeeFactory
{ private Factory(){/*empty*/}
public static Employee create()
{ return new Employee()
{ public void youAreFired()
{ // lots of code
}
}
}
}
In this version, the concrete-class name is so private that you—the programmer—don’t even know what it is.
I’m just touching the surface of Abstract Factory for now. I’ll explore this pattern a bit further later in the current chapter.
The other design pattern in Listing 2-3 is Singleton. A Singleton is a one-of-a-kind object; only one instance of it will ever exist. You must be able to access the Singleton globally, in the same way that you could call new globally. Anything that satisfies these two requirements (uniqueness [or at least a constrained number of instances] and global access) is a reification of Singleton. In the current example, the Employee.Factory object is a Singleton because it meets both conditions of the pattern.
It’s often the case that Singleton is used to get an Abstract Factory, which is in turn used to get an object whose actual class is unknown. You’ll see several examples of this melding of Singleton and Abstract Factory in the Java libraries. For example, the following returns a Singleton:
Runtime.getRuntime()
Here is another example from the java.awt package. In the following call, the Toolkit.getDefaultToolkit() call returns a Singleton implementer of the Toolkit interface:
ButtonPeer peer = Toolkit.getDefaultToolkit().createButton(b);
This Toolkit object is itself an Abstract Factory of objects that implements the ButtonPeer interface.
Returning to the UML diagram in Figure 2-3, you can see that Employee.Factory participates simultaneously in both Abstract Factory and Singleton.
Singleton
Now let’s look at the patterns I just used in more depth, starting with Singleton.
Java has lots of Singletons in its libraries, such as the Toolkit object just described. Every time you call getDefaultToolkit(), you get the same object back. Although Toolkit is actually an abstract class, it’s effectively an interface because you can’t instantiate a ToolKit explicitly. The fact that methods are actually defined in the abstract class doesn’t matter. It’s functioning as an interface. You could, of course, create an interface made up of the abstract methods, implement that interface in a class, and then extend the class, but whether you use that approach or use an abstract class is really an implementation-level decision that doesn’t impact the design at all.
Another example of Singleton is the following:
Runtime runtimeEnvironment = Runtime.getRuntime();
Again, every time you call getRuntime(), you get the same object back.
You’ll look at lots of possible reifications of Singleton in subsequent chapters, but returning to the one in Listing 2-3, the easiest way to deal with the Singleton’s global-access requirement is to make everything static. That way, I can say something such as Employee.Factory.create() to create an Employee without needing the equivalent of a static getRuntime() method.
The main point of confusion with the make-everything-static reification of Singleton is the illusion that there’s no object, per se, only a class. In Java, though, the line between a class and an object is a fine one. A class comprised solely of static methods and fields is indistinguishable from an object. It has state (the static fields) and behavior (you can send messages to it that are handled by the static methods). It’s an object.
Moreover, the class actually is an object with a runtime presence: For every class, there’s a class object-an implicit Class class instance that holds metadata about the class (a list of the class’s methods, for example), among other things. In broad terms, the class object is created by the JVM when it loads the .class file, and it remains in existence as long as you can access or create objects of the class. The class object is itself a Singleton: There’s only one instance that represents a given class, and you can access the instance globally through MyClassName.class or by calling Class.forName(“MyClass”). Interestingly, in this particular reification of Singleton, many instances of the Class class exist, but they’re all unique.
Returning to the code, the Employee.Factory Singleton in Listing 2-3 has one nonstatic method: a private constructor. Because the constructor is inaccessible, any attempts to call new Employee.Factory() kick out a compiler error, thereby guaranteeing that only one object exists.
Threading Issues in Singleton
The everything-is-static approach is nice, but it’s not workable in many situations. If everything is static, you need to know enough at compile time to fully specify it. It’s not often the case that you have this much information. Consider the Toolkit Singleton, which needs to know the operating system that the program is actually executing under in order to instantiate itself correctly.
Also, you don’t have much reason to derive a class from an everything-is-static variant of Singleton since there are no overridable methods. If you anticipate that someone will want to use derivation to modify the behavior of (or add methods to) a Singleton, then you have to use the classic Gang-of-Four approach, discussed next.
It’s often the case that the Singleton class is abstract and the runtime instantiation returned by createInstance() or the equivalent is an unknown class that extends the abstract class. Many possible classes could be derived from the Singleton class, each instantiated in different circumstances. You can use the everything-is-static reification of Singleton only when you’ll never want to derive a class from the Singleton-when there is only one possible implementation.
You can solve these problems with the “classic” Gang-of-Four implementation of Singleton, which allows for runtime initialization. The “classic” reification of Singleton looks like this:
1 class Singleton
2 { private static Singleton instance = null;
3 public static instance()
4 { if( instance == null )
5 { instance = new Singleton();
6 }
7 return instance;
8 }
9 //...
10 }
Lots of threading issues are associated with classic Singletons, the first of which being accessor synchronization. The following will eventually happen in a multithreaded scenario:
- Thread 1 calls
instance(), executes test on line 4, and is preempted by a clock tick before it gets tonew. - Thread 2 calls
instance()and gets all the way through the method, thereby creating the instance. - Thread 3 now wakes up, thinks that the instance doesn’t exist yet (it finished the test before it was suspended), and makes a second instance of the Singleton.
You can solve the problem by synchronizing instance(), but then you have the (admittedly minor) overhead of synchronization every time you access the Singleton. You really need to synchronize only once, the first time the accessor method is called.
The easy solution is to use a static initializer. Here’s the general structure:
class Singleton2
{ private static Singleton instance = new Singleton();
public instance() { return instance; }
//...
}
The explanation of why static initializers work is actually pretty complicated, but the Java Language Specification guarantees that a class will not be initialized twice, so the JVM is required to guarantee that the initializer is run in a thread-safe fashion.
The only time the static-initializer approach isn’t workable is when initialization information must be passed into the constructor at runtime. Consider a database-connection Singleton that must be initialized to hold the URL of the server. You need to establish the URL quite early, but you don’t want to open the connection until you actually need it. For example, I could put the following in main(...):
public static void main( String[] args )
{ //...
Connection.pointTo( new URL(args[i]) );
//...
}
Elsewhere in the program, I get access to the connection by calling this:
Connection c = Connection.instance();
I don’t want the connection to be opened until the first call to instance(), and I don’t want to pass the URL into every call to instance(). I can’t initialize the URL in a static initializer because I don’t know what URL to use at class-load time.
I can solve the problem with a “classic” Gang-of-Four Singleton, like this:
class Connection
{ private static URL server;
public static pointAt( URL server ){ this.server = server; }
private Connection()
{ //...
establishConnectionTo( server );
//...
}
private static Connection instance;
public synchronized static Connection instance()
{ if( instance == null )
instance = new Connection();
return connection();
}
}
Double-Checked Locking (Don’t Do It)
The main problem with the classic Singleton approach is synchronization overhead. The synchronized keyword does something useful only on the first call. Usually, this extra overhead is trivial, but it may not be if access is heavily contested.
Unfortunately, the “solution” to this problem that’s used most often—called Double-Checked Locking (DCL)—doesn’t work with JVM versions prior to 1.5. Listing 2-4 shows the idiom. Generally, you shouldn’t use DCL because you have no guarantee that the JVM your program is using will support it correctly (it has been said that getting rid of double-checked locking is like trying to stamp out cockroaches; for every 10 you squash, 1,000 more are lurking under the sink.) My advice is this: if you come across a double-checked lock in legacy code, immediately replace it with solutions such as those discussed in the previous section.
Listing 2-4. Double-Checked Locking
1 class DoubleChecked
2 { private static volatile DoubleChecked instance = null;
3 private static Object lock = new Object();
4
5 public static DoubleChecked instance()
6 { if( instance == null )
7 synchronized( lock )
8 { if( instance == null )
9 instance = new DoubleChecked();
10 }
11 }
12 return instance;
13 }
14 }
The intent of DCL in the context of a Singleton is to synchronize only during creation, when instance is null. You have to check twice because a thread could be preempted just after the first test but before synchronization completes (between lines 6 and 7 in Listing 2-4). In this case, a second thread could then come along and create the object. The first thread would wake up and, without the second test, would create a second object.
The reason why DCL doesn’t work is complicated and has to do with the way with something called a memory barrier works in the hardware. Though DCL is intuitive, your intuition is most likely wrong. I’ve listed a few articles on DCL and why it doesn’t work on the web page mentioned in the preface (http://www.holub.com/goodies/patterns/). It’s been my experience that many programmers don’t understand the DCL problem, even when they read about it. Every time I’ve written something on this subject, I’ve received dozens of messages from tooclever programmers who think they’ve come up with a solution. They’re all wrong. None of these so-called solutions work. Please don’t send them to me. The only universal solutions (which work across all JVMs) is either to synchronize the accessor or to use a static initializer.
Note, by the way, that Listing 2-4 should work correctly starting with Java version 1.5, running under Sun’s HotSpot JVM, provided that you remember to include the volatile keyword in the instance declaration on line 2. DCL won’t work with earlier versions of Java and probably won’t work with other JVMs. It’s best to avoid DCL altogether.
Killing a Singleton
The only topic left to discuss about Singletons is how to get rid of the things. Imagine a Singleton that wraps a global (outside-of-the-program) resource such as a database connection. How do you close the connection gracefully? Of course, the socket will be slammed shut when the program terminates; slamming the door closed is not exactly graceful, but it must be handled nonetheless.
First, let’s look at what you can’t do.
You can’t send a close() message to the Singleton object, because you have no way to guarantee that someone won’t need the Singleton after you’ve closed it.
You can’t use a finalizer to clean up the resource. Finalizers just don’t work. Finalizers are called only if the garbage collector reclaims the memory used by the object. You have absolutely no guarantee that a finalizer will ever be called. (It won’t be called if the object is waiting to be reclaimed when the program shuts down, for example.) Finalizers are also nasty to use. They can slow down the garbage collector by an order of magnitude or more. The finalizer semantics have thread-related problems that make it possible for an object to be used by a thread after it has been finalized. My general advice about finalizer is: don’t use them.
Java provides only one viable way to shut down a Singleton that uses global resources—the Runtime.addShutdownHook(...) method—and that method works only if the program shuts down normally.
A “shutdown hook” is an initialized, but dormant, thread that’s executed when the program shuts down, after all the user threads have terminated. Memory referenced from the shutdownhook object will not be garbage collected until the hook runs. Listing 2-5 shows the boilerplate code. The objectClosed flag (set on line 10 and tested in all the public methods) makes sure that an error is printed on the console window if someone tries to use the Singleton while shutdown is in progress.
Listing 2-5. Shutting Down a Singleton
1 class Singleton
2 { private static Singleton instance = new Singleton();
3 private volatile boolean objectClosed = false;
4
5 private Singleton()
6 { Runtime.getRuntime().addShutdownHook
7 ( new Thread()
8 { public void run()
9 { objectClosed = true;
10 // Code that clean’s up global resources
11 }
12 }
13 );
14
15 // Code goes here to initialize global
16 // resources.
17 }
18
19 public static Singleton instance()
20 { return instance;
21 }
22
23 public void method()
24 { if( objectClosed )
25 throw new Exception("Tried to use Singleton after shut down");
26 //...
27 }
28 }
Note, by the way, that the Runtime.getRuntime() call on line 6 of Listing 2-5 is another example of a classic Gang-of-Four Singleton. It’s a static method that creates an object the first time it’s called and returns the same object every time it’s called.
If you use the everything-is-static reification, establish the hook in a static-initializer block, as follows:
class StaticSingleton
{ static
{ Runtime.getRuntime().addShutdownHook
( new Thread()
{ public void run()
{ // Code that cleans up global resources.
}
}
);
// Code goes here to initialize global resources.
}
}
The shutdown hook isn’t an ideal solution. It’s possible for the program to be terminated abnormally (in Unix, with a kill -9, for example), in which case the hook never executes. If you register several shutdown hooks, all the shutdown hooks can run concurrently, and you have no way to predict the order in which they’ll be started. It’s possible, then, to have deadlock problems in the hooks that hang the VM and prevent it from terminating. Finally, if you use a Singleton in a shutdown hook, you run the risk of creating a zombie Singleton that rises from the dead.
Abstract Factory
If you can remember back that far, I started out talking about Singleton working in concert with a second pattern, Abstract Factory, to create objects, so let’s explore Abstract Factories a bit further. I’ll present the classic reification now, but you’ll see lots of this pattern in subsequent chapters.
The Employee.Factory object in Listing 2-3 (page 59) is a Singleton, but it’s also a factory of Peon objects. The actual class of the object returned from Employee.Factory.create() is unknown to the caller—a requirement of the Abstract Factory pattern. All you know about the returned object is the interfaces that it implements (in this case, Employee). Consequently, you can modify the concrete Peon class at will—even change its name—without impacting any surrounding code.
Of course, changing the Employee interface in an “unsafe” way—removing methods or modifying method arguments, for example—is hard work. Adding methods to the interface is usually safe, however, and that’s the downside of interface-based programming generally. You have to be careful when you’re designing your interfaces.
If you look up Abstract Factory in Appendix A, you’ll see that the Employee.Factory is not a classic reification (though it’s probably the most commonplace variant). A good example of a classic Abstract Factory in Java is in the Collection class, which serves as an Iterator factory. Consider this code:
void g()
{ Collection stuff = new LinkedList();
//...
f( stuff );
}
void client( Collection c )
{ for( Iterator i = c.iterator(); c.hasNext() ; )
doSomething( i.next() );
}
Not only is the product (the Iterator) abstract—in the sense that you don’t know its actual class, only the interface it implements—but the iterator factory (the Collection) is abstract too. Listing 2-6 shows a stripped-down version of this system, and Figure 2-4 shows the associated UML. Collection and Iterator are both interfaces (which have the roles of Abstract Factory and Abstract Product in the design pattern). Collection is an Abstract Factory of things that implement Iterator, the Abstract Product. LinkedList has the role of Concrete Factory, which is the class that actually does the creating, and it creates an object that has the role of Concrete Product (some class whose name you don’t know that implements the Iterator interface). Collection also demonstrates another characteristic of the Abstract Factory pattern. Abstract Factories create one of a “family” of related classes. The family of classes in this case is the family of iterators. A given abstract factory can create several different Iterator derivatives depending on which Concrete Factory (data structure) you’re actually talking to at any given moment.
The main benefit of Abstract Factory is that the isolation it gives you from the creation means you can program strictly in terms of interfaces. The client() method doesn’t know that it’s dealing with a LinkedList, and it doesn’t know what sort of Iterator it’s using. Everything is abstract. This structure gives you enormous flexibility. You can pass any sort of Collection to client()—even instances of classes that don’t exist when you wrote the client() method—and client() doesn’t care.
Listing 2-6. A Classic Abstract Factory (Collection)
1 interface Collection
2 { Iterator iterator();
3 //...
4 }
5
6 interface Iterator
7 { Object next();
8 boolean hasNext();
9 //...
10 }
11
12 class Tree
13 { public Iterator iterator()
14 { return new Walker();
15 }
16
17 private class Walker implements Iterator
18 { public Object next() { /*...*/ return null; }
19 public boolean hasNext(){ /*...*/ return false; }
20 }
21 }
Let’s move back to the Factory object in Listing 2-3 (on page 59). It differs from the classic reification in that it leaves out the Abstract Factory interface entirely (a commonplace variant when the Factory is also a Singleton). Employee.Factory is the Concrete Factory. It still produces an Abstract Product, however: the Employee derivative (Peon) is the Concrete Product.

Figure 2-4. Structure of a classic Abstract Factory (Collection)
Let’s fiddle a bit more with our solution and really make the product abstract. Consider this variation:
interface Employee
{ void youAreFired();
public static class Factory
{ private Factory(){ }
static Employee create()
{ return new Employee()
{ public void youAreFired()
{ // lots of code
}
}
}
}
}
I’ve simplified things (always good) by using an anonymous inner class rather than a named one. The anonymous-inner-class mechanism lets me leverage the language to enforce the Concrete-Product-is-unknown rule. I don’t even know the actual name of the inner class. As before, the structure of the code has changed, but I still have a reasonable reification of Abstract Factory and Singleton. The structure of the system has only a loose correlation to the underlying pattern.
How about yet another variant? I don’t like saying Employee.Factory.create(). I'd rather say Employee.create(), which is shorter. I can do that by changing the interface into an abstract class, like so:
abstract class Employee
{ abstract void youAreFired();
static Employee create()
{ return new Employee()
{ public void youAreFired()
{ // lots of code
}
}
}
}
This reification has a big disadvantage—it’s a class, so it will use up the extends relationship. On the other hand, all the methods except create() are abstract, so you don’t have a fragile-base-class problem. The fact that I’ve declared the class using abstract class rather than interface is just an implementation issue; from a design perspective, Employee is an interface, regardless of the syntax I use to declare the thing. One advantage to the abstract-class approach is that the Singleton-ness is enforced by the compiler, since new Employee() is illegal on an abstract class. It would certainly be nice if Java supported static methods in interfaces, but it doesn’t.
This example demonstrates two main design-pattern issues. First, the classes you’ve been looking at reify two patterns simultaneously. Factory has two roles: Concrete Factory in the Abstract Factory pattern and Singleton in the Singleton pattern. That’s two patterns in one class. Next, you’ve looked at several possible reifications, but they’re all legitimate reifications of the same patterns. A tenuous connection exists between a pattern and the structure of the reification.
Pattern Stew
While we’re on the subject of Abstract Factory, let’s look at another interesting example from Java that illustrates the things-change-when-you-refocus issue I discussed in Chapter 1. Consider the following code, which dumps the main page of my web site to the console verbatim. (It doesn’t interpret the HTML at all; it just prints it on the screen.)
URL url = new URL("http://www.holub.com/index.html");
URLConnection connection = url.openConnection();
connection.setDoInput(true);
connection.setDoOutput(false);
connection.connect();
InputStream in = connection.getInputStream();
int c;
while( (c = in.read()) != -1 )
{ System.out.print( (char)c );
}
The code in Listing 2-7 shows a simplified implementation of the classes used in this example. Figure 2-5 shows the associated UML.
Here you see two overlapping reifications of Abstract Factory. The URL class is a Concrete Factory of objects that implement URLConnection (the Abstract Product). The actual concrete class for the current example is HttpURLConnection (the Concrete Product). But in another context—if a different protocol were specified in the URL constructor, for example—the factory would produce a different derivative (FtpURLConnection, and so on). Since all possible Concrete Products implement URLConnection, the client code doesn’t care what class is actually created. This reification is different from the one in the Gang-of-Four book in that it’s missing an interface in the Abstract-Factory role.
Refocusing, the URLConnection is itself an Abstract Factory of InputStream derivatives. (InputStream is actually an abstract class, but it’s always used as an interface.) In the current context, an InputStream derivative that understands HTTP is returned, but again, a different sort of stream (one that understands FTP, for example) would be returned in a different context. This reification is a classic reification of the Gang-of-Four pattern.
Listing 2-7. A Stripped-Down URLConnection Implementation
1 interface URLConnection
2 { void setDoInput (boolean on);
3 void setDoOutput (boolean on);
4 void connect ();
5
6 InputStream getInputStream();
7 }
8
9 abstract class InputStream // used as interface
10 { public abstract int read();
11 }
12
13 class URL
14 { private String spec;
15
16 public URL( String spec ){ this.spec = spec; }
17
18 public URLConnection openConnection()
19 { return new HttpURLConnection(this);
20 }
21 }
22
23 class HttpURLConnection implements URLConnection
24 { public HttpURLConnection(URL toHere) { /*...*/ }
25 public InputStream getInputStream()
26 { return new InputStream()
27 { public int read()
28 { // code goes here to read using the HTTP Protocol
29 return -1;
30 }
31 };
32 }
33
34 public void setDoInput (boolean on) { /*...*/ }
35 public void setDoOutput (boolean on) { /*...*/ }
36 public void connect ( ) { /*...*/ }
37 }
The main point of this exercise is to solidify the notion of focus. When you focus on the design in different ways, you see different patterns. In Figure 2-5, the URLConnecction class has two roles (Abstract Factory and Abstract Product), depending on how you focus. The overlapping combination of patterns, and simultaneous participation of a single class in multiple patterns, is commonplace.
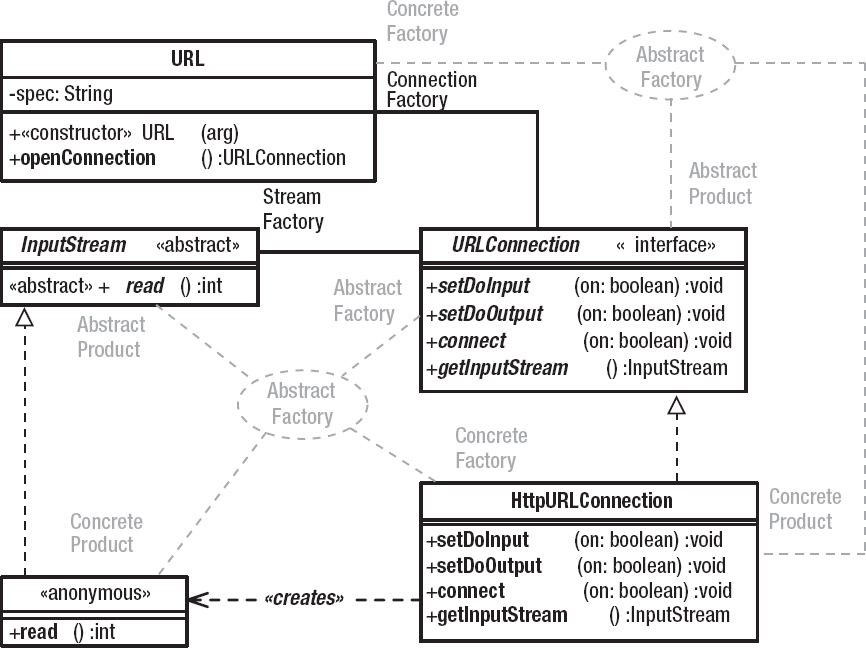
Figure 2-5. Design patterns in URLConnection
Dynamic Creation in a Factory
The URL/URLConnection system has another interesting facet. How does the URL object know which sort of URLConnection derivative to create? You could use code such as the following:
public class URL
{ private String spec;
public URL( String spec )
{ this.spec = spec;
}
public URLConnection openConnection()
{
if ( spec.startsWith("http:") ) return new HttpURLConnection();
else if( spec.startsWith("ftp:") ) return new FtpURLConnection();
//...
else
throw new IllegalArgumentException("Unknown Protocol");
}
}
class HttpURLConnection implements URLConnection { /*...*/ }
class FtpURLConnection implements URLConnection { /*...*/ }
interface URLConnection { /*...*/ }
The only problem with this approach is long-term flexibility. I’d like to be able to add support for new protocols without having to modify the existing code at all. In fact, I want to be able to add new protocols without even shutting down a running application. This sort of flexibility is particularly important in server-side applications, where you need to modify the server’s behavior without bouncing it (shutting down and then restarting the server).
Java, fortunately, provides you with an easy solution to this problem. The code in Listing 2-8 uses dynamic creation to manufacture a class of the correct type. The first few lines of openConnection() create a string that holds a class name representing the connection. The class name is formed by extracting the protocol (everything to the left of the colon) in the URL specification, converting the first character of the protocol to upper-case, prefixing a package name, and appending the string "URLConnection". For example, given new URL("xxx://www.holub.com"), the openConnection() method manufactures the class name com.holub.protocols.XxxURLConnection.
The openConnection() method then calls Class.forName() to create the class object for the class whose name you’ve just synthesized (an example of Singleton). Finally, openConnection() passes the class object a newInstance() message to instantiate an instance of the class (an example of Abstract Factory: Class has the role of Abstract Factory, the Class instance that represents the synthesized name is in the Concrete-Factory role, Object has the role of Abstract Product, and the created instance has the role of Concrete Product). Note that the created object must implement a known interface (URLConnection) for all this stuff to work.
Listing 2-8. Dynamic Instantiation
1 import java.io.IOException;
2
3 public class URL
4 { private String spec;
5
6 public URL( String spec )
7 { this.spec = spec;
8 }
9
10 public URLConnection openConnection() throws IOException
11 {
12 // Assemble the class name by prefixing a package
13 // and appending URLConnection to the protocol.
14 // The first character of the protocol is mapped to
15 // uppercase.
16
17 StringBuffer name = new StringBuffer( "com.holub.protocols." );
18 String prefix = spec.substring( 0, spec.indexOf(":"));
19
20 name.append( Character.toUpperCase(prefix.charAt(0)) );
21 name.append( prefix.substring(1) );
22 name.append( "URLConnection" );
23
24 String className = name.toString();
25
26 // Manufacture an object of the class whose name we just
27 // assembled:
28
29 try
30 { Class factory = Class.forName( className );
31 return (URLConnection)( factory.newInstance() );
32 }
33 catch( Exception e )
34 {
35 // Throw an IOException whose message is the one
36 // associated with the exception that got us here.
37
38 IOException toThrow = new IOException();
39 toThrow.initCause( e );
40 throw toThrow;
41 }
42 }
43 }
44
45 class HttpURLConnection implements URLConnection
46 { //...
47 }
48
49 class FtpURLConnection implements URLConnection
50 { //...
51 }
52
53 interface URLConnection
54 { //...
55 }
Another example of the same structure is Java’s Toolkit Singleton, which uses dynamic creation to manufacture a Toolkit derivative that knows about the current operating environment. The getDefaultToolkit() method uses System.getProperty(...) to learn the operating-system name and then assembles an appropriate class name using that string.
The main advantage of the dynamic-creation strategy is that the name of the class that handles a protocol doesn’t need to be known at runtime. If I need to add support for a new protocol, all I need do is create a class that implements URLConnection whose name starts with the protocol name. I then compile the class and move the .class file to the directory associated with the com.holub.protocols package. That’s it. I’m done. No recompile. No server bounce. The next time the user specifies a URL for the new protocol, the server instantiates and loads the new class.
The main downside of dynamic creation is that it’s difficult to pass arguments to the object’s constructor. You can do that using the Introspection API methods of the Class class, but it requires a lot of complicated code that I don’t want to go into here.
Command and Strategy
Another useful pattern for creating objects in an abstract way is Strategy, which is a specialization of the more general pattern Command.
Command is a building-block pattern upon which almost all the Gang-of-Four Behavioral patterns rely. You’ll see many variants throughout the book.
The basic idea of Command is to pass around knowledge of how to do something by encapsulating that knowledge within an object. In C or C++, you’d pass around an algorithm by writing a function that implements the algorithm and then pass a function pointer—a syntactic mechanism that allows a programmer to call a function if the programmer knows the function’s address—its location in memory. If you’ve programmed in C, you’ll be reminded of the qsort() function.
You don’t need function pointers in object-oriented systems, because you can pass around an algorithm by passing around an object that implements the algorithm. (Typically you’d pass an interface reference to the method that used the algorithm, and the method executes the algorithm by calling an interface method.)
One basic-to-Java use of Command is in threading. The following code shows a way to run a bit of code on its own thread that emphasizes the use of the Command pattern:
class CommandObject implements Runnable
{ public void run()
{ // stuff to do on the thread goes here
}
};
Thread controller = new Thread( new CommandObject() );
controller.start(); // fire up the thread
You pass the Thread object a Command object that encapsulates the code that runs on the thread. This way, the Thread object can be completely generic—it needs to know how to create and otherwise manage threads, but it doesn’t need to know what sort of work the thread will perform. The controller object executes the code by calling run(). One of the main characteristics of the Command pattern is that the “client” class—the class that uses the Command object—doesn’t have any idea what the Command object is going to do.
You can use Command, itself, in more sophisticated ways to solve complex problems such as “undo” systems. I’ll come back to the pattern in Chapter 4. For now, I want to move on to a simple variant on Command: Strategy. The idea is simple: Use a Command object to define a strategy for performing some operation and pass the strategy into the object at runtime. You can often use Strategy instead of implementation inheritance if you’re extending a class solely to change behavior.
Strategy is used all over the place in Java. Consider the array-sorting problem, as solved in the Arrays utility. You can sort an array into reverse order like this:
public static void main( String[] args )
{
// sort the command-line arguments:
Arrays.sort
( args,
new Comparator()
{ public int compare( Object o1, Object o2 )
{
// By using a minus sign to reverse the sign
// of the result, "larger" items will be
// treated as if they're "smaller."
return -( o1.compareTo(o2) );
}
}
);
}
You pass into the sort method an object that defines a strategy for comparing two array elements. The sort method compares objects by delegating to the Strategy object. Listing 2-9 shows a Shell sort implementation that uses Strategy for comparison purposes. shellSort(...) delegates to the Strategy object on line 29.
Listing 2-9. Sorters.java: Using Strategy
1 package com.holub.tools;
2
3 import java.util.Comparator;
4
5 /** Various sort algorithms */
6
7 public class Sorters
8 { /** A Straightforward implementation of Shell sort. This sorting
9 * algorighm works in O(n<sup>1.2</sup>) time, and is faster than
10 * Java's Arrays.sort(...) method for small
11 * arrays. The algorithm is described by Robert Sedgewick in
12 * <em>Algorithms in Java, Third Edition, Parts 1-4</em>
13 * (Reading: Addison-Wesley, 2003 [ISBN 0-201-36120-5]), pp. 300-308,
14 * and in most other algorithms books.
15 */
16
17 public static void shellSort(Object[] base, Comparator compareStrategy)
18 { int i, j;
19 int gap;
20 Object p1, p2;
21
22 for( gap=1; gap <= base.length; gap = 3*gap + 1 )
23 ;
24
25 for( gap /= 3; gap > 0 ; gap /= 3 )
26 for( i = gap; i < base.length; i++ )
27 for( j = i-gap; j >= 0 ; j -= gap )
28 {
29 if( compareStrategy.compare( base[j], base[j+gap] ) <= 0 )
30 break;
31
32 Object t = base[j];
33 base[j] = base[j+gap];
34 base[j+gap] = t;
35 }
36 }
37
38 //...
39
40 private static class Test
41 { public static void main( String[] args )
42 {
43 String array[] = { "b", "d", "e", "a", "c" };
44 Sorters.shellSort
45 ( array,
46 new Comparator()
47 { public int compare( Object o1, Object o2 )
48 { // sort in reverse order
49 return -( ((String)o1).compareTo((String)o2) );
50 }
51 }
52 );
53
54 for( int i = 0; i < array.length; ++i )
55 System.out.println( array[i] );
56 }
57 }
58 }
Another good example of Strategy in Java is the LayoutManager used by java.awt.Container and its derivatives. You add visual objects to a container, which it lays out by delegating to a Strategy object that handles the layout. For example, the following code lays out four buttons side by side:
Frame container = new Frame();
container.setLayout( new FlowLayout() );
container.add( new Button("1") );
container.add( new Button("2") );
container.add( new Button("3") );
container.add( new Button("3") );
You can lay the buttons out in a two-by-two grid like this:
Frame container = new Frame();
container.setLayout( new GridLayout(2,2) );
container.add( new Button("1") );
container.add( new Button("2") );
container.add( new Button("3") );
container.add( new Button("3") );
If you were using implementation inheritance rather than Strategy, you’d have to have a FlowFrame class that extended Frame and did flow-style layout and another GridFrame class that extended Frame and did grid-style layout. Using the LayoutManager Strategy object (which implements the LayoutManager interface but doesn’t extend anything) lets you eliminate the implementation inheritance and simplify the implementation.
Strategy provides a good alternative to Factory Method. Rather than use implementation inheritance to override a creation method, use a Strategy object to create the auxiliary objects. If I were king, I would rewrite the JEditorPane to work like this:
interface ProxyCreator
{ JComponent proxy( String tagName, Properties tagArguments );
}
MyJEditorPane pane = new MyJEditorPane();
pane.setProxyCreator
( new ProxyCreator()
{ public JComponent proxy( Sting tagName, Properties tagArguments )
{
/** Return a JComponent that replaces the tag
* on the page
*/
}
}
);
MyJEditorPane would look like this:
public class MyJEditorPane
{ private ProxyCreator default =
new ProxyCreator()
{ public JComponent proxy( Sting tagName, Properties tagArguments )
{
/** Return a JComponent that replaces the tag
* on the page
*/
}
}
public setProxyCreator( ProxyCreator creationStrategy )
{ default = creationStrategy;
}
private void buildPage( String html_input )
{ //...
JComponent proxy = factory.proxy( tagName, tagArguments );
//...
}
}
Every time MyJEditorPane encounters a tag, it calls the ProxyCreator’s proxy(...) method to get a JComponent to display in place of that tag. No implementation inheritance is required.
Summing Up
So, to sum up, as much as 80 percent of your code should be written in terms of interfaces, not concrete classes, to give you the flexibility you need to modify your program easily as requirements change. You’ve looked at the following patterns that help you create objects in such a way that you know the interfaces the object implements but not the actual class the object instantiates:
- Singleton: A one-of-a-kind object.
- Abstract Factory: A “factory” that creates a “family” of related objects. The concrete class of the object is hidden, though you know the interface it implements.
- Template Method A placeholder method at the base-class level that’s overridden in a derived class.
- Factory Method: A Template Method that creates an object whose concrete class is unknown.
- Command: An object that encapsulates an unknown algorithm.
- Strategy: An object that encapsulates the strategy for solving a known problem. In the context of creation, pass the creating object a factory object that encapsulates the strategy for instantiating auxiliary classes.
Singleton, in particular, is deceptively simple. It’s difficult to implement it correctly, and many reifications are in common use. You’ve also spent a lot of time looking at how the patterns merge and overlap in real code.
Of these four patterns, I don’t use Template Method and Factory Method often because they depend on implementation inheritance with the associated fragile-base-class problems.
You’ll look at other Creational patterns (to use the Gang-of-Four term) in context later in the book, but Singleton and Abstract Factory are used the most often. You’ll see lots of different applications of both of these patterns.
__________
1. Pedagogically, an interface defines a type, not a class, so is not properly called a base class. That is, when you say class, you really mean a “class of objects that share certain characteristics.” Since interfaces can’t be instantiated, they aren’t really “classes of objects,” so some people use the word type to distinguish interfaces from classes. I think the argument is pedantic, but feel free to use whatever semantics you want.
2. Don’t confuse the object model with the physical users. It’s reasonable for the same person to log on sometimes in the role of Manager and other times in the role of Employee. The object model concerns itself with the roles that the physical users take on, not with the users themselves.