
In this chapter, we'll look at the concepts behind search engine optimization and how they apply to a content management system. We will touch on some usability concepts that will make your site more accessible to disabled users. We'll also discuss ways to facilitate your users arriving at URLs that are memorable, friendly, and easily shared; this concept is as useful to a search engine as it is to a human user. Although we'll discuss the broader concepts of SEO first, we will spend the majority of our time developing a system for handling friendlier URLs, because this requires a greater amount of specific coding to implement.
Note
The search engine ecosystem is complex, and there are entire cottage industries built around helping people improve their site rankings; some are legitimate, and some are pure snake oil of the worst kind. This chapter does not aim to perform the task of SEO analysis because each site and organization's needs are unique and distinct. The purpose is to introduce some key concepts, put SEO into context for developer concerns, and show how to make the CMS a bit more user-friendly than it would be otherwise.
Engaging in search engine optimization is to attempt to increase the visibility of and traffic to a particular site by improving the rank associated with it by a given search engine. In plain English, you want people to frequently visit the site you worked so hard on, and a component of that desired success is the need for search engines to rank you as not only of high quality but as high relevance to the topics being investigated by users.
At a high level, a search engine performs the tasks that used to be handled manually by systems administrators. As new web servers came online in the early 1990s, public lists were updated to reflect new web presences and help those early adopters find one another. It's not hard to imagine how this sort of tracking becomes impossible, especially given the history of the Internet and how quickly it exploded into the massive ecosystem that it has become today. Search engines began to pop up in the mid-90s, indexing pages and helping to identify content that existed on the Web. This is something of an oversimplification of the history; search engines are now backed by complex algorithms that determine the relevance (or rank) of content, weighing one piece of content against many others to help users find the most appropriate information based on their search criteria.
With that in mind, how does a search engine go about making these decisions? What makes page A stand out from the crowd of pages B, C, and D? It used to be the case that engines relied heavily on HTML <meta> tags (such as the description and keyword values) to make decisions about what was on a page and whether it was relevant to a given search; this evolved somewhat into an analysis of keyword density within a page. These proved to be heavily flawed implementations because each of these factors are easily manipulated by anyone with access to the markup of a page. I could easily hide the words auto loan throughout the markup of a page that was about donating money to charity; my page may not have anything to do with auto loans, but users searching for those keywords would theoretically be more likely to arrive at my page anyway.
Note
Keyword density refers to the number of times a particular word or phrase appears within a piece of content.
Depending on which side of the fence you sit on, search engine optimization could be one or the other. In reality, it's both. Part of the vagueness arises because there is no singular search engine (even though Google and Yahoo are fairly synonymous with Internet searches at this point, and Bing is making headway), and the specific algorithms that go into the sorting and ranking of pages are essentially trade secrets for each individual company. Without a standard, it can be difficult to precisely anticipate the expectations of individual engines; it's also the reason why a search for a term in Google will return something potentially very different than Yahoo, or than Bing, and so on.
The fun doesn't stop there, however. It's fairly common among the search engine heavyweights to allow users to create accounts for themselves that uniquely identify them within the particular site; as users search and browse content, the search engine is able to better offer personalized results.
Not only are you contending with a given search engine's algorithms, you also have to consider the individual search history and needs of particular users and how that impacts their specific search results. It can all seem fairly daunting; Bruce Clay, a well-known SEO consultant and speaker, famously declared in 1998 that "ranking is dead" because of personalized user search results.
It may seem like SEO is something of a moving target. Search engine manufacturers change their algorithms frequently, for reasons ranging from staying current to reducing the ability of malicious parties to game their systems and influence results in unintended ways. Although the exact algorithms and processes are proprietary, SEO can (for our purposes) be boiled down to a few key points:
Sites that have been around for a while are regarded with a somewhat higher level of trust.
Although titles and meta tags are a bit less important these days, their relation is considered helpful.
JavaScript should enhance the site features, but a site should not rely on it for functionality.
Provide
alttext for images to aid users who are disabled.Choose color schemes that permit color-deficient users to navigate and read comfortably.
Offer user-friendly URLs that make use of relevant keywords.
Handle redirects (permanent versus temporary) appropriately.
Not all of this can be influenced by good coding practices, but what can be influenced is fairly easy to do. In essence, the search engines are simply looking for clean, well-organized web sites that make use of best practices rather than kludges and trickery.
The bullet points regarding alt text and color schemes are listed with SEO but serve what are arguably more accurately described as usability purposes. There is a direct correlation to SEO, however, because search engines place heavy emphasis on both the number of inbound links to your site from other web presences, as well as the number of users who click through to your site from search engine results. A site that is usable to a wide audience in addition to offering quality content is one that will be ranked favorably compared to inaccessible ones.
Note
Google offers an excellent primer in SEO topics and tips it considers most helpful to developers at http://www.google.com/webmasters/docs/search-engine-optimization-starter-guide.pdf.
If browsers do one thing very well, it's managing to competently and adequately render the massive amounts of tag soup on the Internet today. Tag soup refers to the tangled mess of HTML that results from sloppy web design; browsers may encounter malformed tags, tags that are nested improperly, and unescaped characters. Unfortunately, although browsers can render the nest of vipers that is a semantically poor page, search engines don't look upon the practice quite so kindly.
For example, the markup in Listing 9-1 is incorrect; the tags are nested improperly. In semantically valid HTML, tags can be thought of as a stack (a "last in, first out" data structure): when you push tags onto the stack by opening them, they must be popped off in reverse order.
Example 9-1. Semantically Incorrect HTML
<p>
<div>
<strong><em>This</strong></em> is some markup. It's fun!
</p>
</div>This is an excellent example of tag soup. Although the application of CSS style attributes to this will likely result in some interesting display characteristics, the browser will dutifully render it. Bearing in mind that the tags could be viewed as a stack, let's clean the markup appropriately (see Listing 9-2).
Example 9-2. Semantically Valid HTML
<div>
<p>
<strong><em>This</em></strong> is some markup. It's fun!
</p>
</div>Note the operations present in Listing 9-2; the <div> is opened, then the <p>, then the <strong>, and finally the <em>. They are then closed in reverse order; first the <em>, then the <strong>, then the <p>, and finally the <div>. We have also escaped the apostrophe using the ' value, which the browser will interpret as an apostrophe and insert it accordingly. The motivation for escaping characters is simply that certain character elements are sensitive for security or encoding purposes; encoding them ensures that the behavior of the page is consistent, secure, and as expected.
A variety of standards exist that enforce different levels of structural and semantic requirements, as well as validators that examine the markup of a page and identify problems based on the standard being tested against. The World Wide Web Consortium (W3C) is the authoring body of these standards and also provides a very useful validator for both HTML and CSS, available at http://validator.w3.org.
Although page titles and metadata used to be regarded highly in terms of search engine optimization, they have fallen out of favor in recent years because of abuse. It was an all-too-common practice to stuff these fields with keywords that were not necessarily related to the content in an attempt to drive traffic from unrelated searches to a particular piece of content.
They do still have a place in the search engine world in search engine results pages (SERPs). For example, use Google to do a search on the word Target. In the results, the web site for Target.com should be the first link available. Note the information for this link as displayed in Figure 9-1.

If you view the source to the http://www.target.com page, you should see the information in Listing 9-3 toward the top. Note the usage of the <title> tag to establish the link title and the <meta name="description"> tag to create the text immediately below the link title; the <meta name="keywords"> tag defines potential areas of interest that the site supplies but isn't visibly used in the SERPs.
Example 9-3. The http://www.target.com Title and Metadata Information
<title>Target.com - Furniture, Patio Furniture, Baby, Swimwear, Toys and more</title> <meta name="description" content="Shop Target online for Furniture, Patio Furniture, Gardening Tools, Swimwear, Electronics, Toys, Men's and Women's Clothing, Video Games, and Bedding. Expect More. Pay less." /> <meta name="keywords" content="patio furniture, furniture, gardening tools, swimwear, baby, electronics, toys, bedding, shoes, home décor, sporting goods, shop online" />
In previous iterations of .NET, you had to create the meta tags manually, meaning you had to structure the markup accordingly and insert them into the Page object before being rendered to the client. Microsoft now provides convenience methods for performing this task in the form of the Page.MetaKeywords() and Page.MetaDescription() methods. Listing 9-4 demonstrates how we would add the meta tags to the Target home page in .NET 4.
Example 9-4. Setting the Page Keywords and Description
protected void Page_Load(object sender, EventArgs e)
{
Page.MetaDescription = "Shop Target online for Furniture, Patio Furniture, Gardening Tools,
Swimwear, Electronics, Toys, Men's and Women's Clothing, Video Games, and Bedding. Expect
More. Pay less.";
Page.MetaKeywords = "patio furniture, furniture, gardening tools, swimwear, baby,
electronics, toys, bedding, shoes, home décor, sporting goods, shop online";
}Search engines used to have a devil of a time handling pages that were heavy JavaScript users; to a degree, this is still true. Developers are encouraged to use JavaScript on noncritical parts of pages to enhance the experience rather than create it.
Examine Listing 9-5; in it, we've chosen to create navigation for our site that is heavily reliant on JavaScript for functionality.
Note
The typical application of JavaScript for navigation is usually to aid in drop-down animations and similar features; demonstrating that fully would require additional CSS and JavaScript that would clutter the conversation. With that said, I will testify that I have actually seen this done in a production site, so perhaps it's worth demonstrating if only as a cautionary tale of woe.
Example 9-5. JavaScript-Based Navigation
<ul id="navigation"> <li><a href="#" onclick="window.location='http://mysite.com/home';">Home</a></li> <li><a href="#" onclick="window.location='http://mysite.com/services';">Services</a></li> <!-- additional pages... --> </ul>
In Listing 9-5, the JavaScript makes the experience; without it, the user is simply not able to navigate the site in any fashion. If a user without JavaScript enabled (or available in their browser of choice) can't navigate the site, it's safe to assume that a search engine won't be able to either, and the results of your efforts will be greatly diminished.
A quick way to get a sense of how a search engine will browse your page is to run it through a text-based browser such as Lynx. This has the added benefit of showing you how your page will look to users that are disabled; the output of a text-based browser is highly comparable to screen readers as well as search engines. There is a free service available at http://cgi.w3.org/cgi-bin/html2txt that will convert a given page to its text-based equivalency. Figure 9-2 shows the text-browser output of the Best Buy home page.

This point is more of an accessibility issue than a search engine one, but it's something that validators will flag as important (and it is). Images on a web page should possess alt text attributes for two reasons:
First, if an image fails to load, the text will be present in its place.
Second, users with text-based browsers will by definition not see any of the images on your page (instead seeing the
alttext, if present).
Also, although the focus is on accessibility for disabled users, search engines do look at alt text to help identify what is contained in a particular image.
Listing 9-6 shows the markup for an image that has an alt attribute applied. If for some reason the browser cannot retrieve the image resource or the user is on a text-based browser, the words "Login error" will appear in place of the image; depending on the image and what its relation to the content is, this can be an absolutely critical step for users of your site.
Example 9-6. Supplying alt Text for Images
<div id="loginFailed"> <img src="error.png" alt="Login error" /> <p>Your login credentials could not be authenticated. Please try again.</p> </div>
Note
The Google webmaster blog provides a video on alt text, providing alt keywords, and further accessibility issues at http://googlewebmastercentral.blogspot.com/2007/12/using-alt-attributes-smartly.html.
Developing an effective color scheme that accommodates the various color deficiencies users may possess is a unique challenge to be tackled on a site-by-site basis. Validators will sometimes flag color issues (such as using a light gray color for both the foreground and background in a style sheet) but in general, it's best to rely on tools designed to identify and aid in determining color issues specifically.
Tip
Adobe has a great online tool for generating color schemes called Kuler; it's available for free from http://kuler.adobe.com/. There are already a great deal of community-submitted color schemes, and generating color schemes of your own is trivial. When designing the color content of your sites, it's an excellent idea to combine the color output of Kuler schemes with the results of the Color Contrast Comparison tool described next.
One such tool for determining the accessibility of a set of colors is Joseph Dolson's Color Contrast Comparison site, available at http://www.joedolson.com/color-contrast-compare.php. You can enter two hexadecimal color codes, and the site will evaluate them against Web Content Accessibility Guideline (WCAG) standards and give a pass/fail return value.
In Figure 9-3, I have used the tool to evaluate the contrast between two fairly close shades of red. The site has indicated that they fail the WCAG accessibility test as the level of contrast between the two colors is insufficient for easy readability. I chose the two variants of red, #FF0000 and #FF6666, because they (or some similar combination) appear quite frequently in so-called Web 2.0 dialog boxes, particularly in the form of confirmation, warning, and error boxes. Noting that color selection can play a huge role in site usability is important to hammer home and often overlooked.

One thing that dynamic sites are frequently not good at is the implementation of URLs in a fashion that gels with the expectations of users. It's easy as a developer to think in terms of GUIDs or other system details (such as "the home page lives at contentID 18003214"); this has context and purpose that is obvious to someone who understands the underlying code. To search engines (and users), this is meaningless. When designing a system that is intended to (or potentially might) face the generic public, it's wise to hide these sorts of low-level system implementation details that provide nothing of value to the user. It's more meaningful and comfortable to have a URL like /about-us/.
In addition to the usage benefits, search engines themselves have evolved over the years. Search engines used to take issue with dynamic URLs (such as those provided by a CMS). For example, to a search engine, the following URLs are all unique and distinct:
/content.aspx?id=5730299/content.aspx?page=about-us/content/about-us//about-us/
For various reasons, it makes sense to have /about-us/ be the desired (and indexed) location so that users have the capacity to arrive from the others if necessary but directed to the canonical link immediately. Search engines should index just the canonical link, ensuring that most users arrive via the route you prefer.
Tip
Canonical links were created by Google as a way to indicate to the search engine which URL a given page preferred to have indexed as the true location. It's a hint to the search engine, not a directive; Google seems to respect it consistently in my experience, and other major search providers have picked up on it and are respecting it in their own results. You can find more information at http://googlewebmastercentral.blogspot.com/2009/02/specify-your-canonical.html.
IIS7 now has an optional add-on for URL rewriting, mapping one URL to another. It requires more maintenance than we can really expect for the potential growth that a CMS contains; it's quite easy to balloon up in content very quickly, and no one wants to maintain this sort of list by hand. As such, we will design a custom solution that will allow us to map URLs from an ugly, system-usable form to something that users and search engines prefer; our solution will parse incoming HTTP requests directed to the application using our idealized URLs and (behind the scenes) serve markup to the client that has been rendered by the content.aspx page.
The data requirements for a friendly URL are much simpler than the actual code that drives them, so we'll begin there. What exactly do we need to have for a friendly URL to function properly?
The content ID for a particular page; this should be unique (one entry per ID allowed)
The friendly URL
We should decide on an important design consideration right now: do we want to support aliases for a friendly URL? By alias, I am referring to /aboutus/ and /about/ referring to and automatically redirecting the user to the canonical /about-us/. Although we may not need the functionality now, let's design an alias system as well. An alias would need the following:
The content ID for a particular page; not unique (many entries per ID)
The alias URL
Now we can start the business of designing tables to support these systems. Let's begin with a table called FriendlyURLs. The T-SQL to create this table is defined in Listing 9-7.
Example 9-7. The T-SQL to Create the FriendlyURLs Table
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[FriendlyURLs](
[contentID] [int] NOT NULL,
[url] [nvarchar](200) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,CONSTRAINT [PK_FriendlyURLs] PRIMARY KEY CLUSTERED
(
[contentID] ASC
)
WITH (
PAD_INDEX = OFF,
IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]As before, we can add a bit of sample data to the table for use as we develop code to support these URLs. Figure 9-4 shows the sample.

Next, we'll create the AliasURLs table that will allow us to provide alternative ways of reaching this content if desired. Listing 9-8 defines the T-SQL to create this table.
Example 9-8. The T-SQL to Create the FriendlyURLs Table
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[AliasURLs](
[contentID] [int] NOT NULL,
[url] [nvarchar](200) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL
) ON [PRIMARY]Note that we didn't apply any primary key constraints; we do intend for multiple URLs to be available for accessing a particular piece of content. There can be only one primary URL, but many aliases. Let's create a few aliases for use in a bit, as shown in Figure 9-5.

We need to create a few stored procedures that will allow us to get the information we need when retrieving content data. First, let's create the GetContentIDByPrimaryURL procedure that will return the content ID for a given friendly URL (shown in Listing 9-9).
Example 9-9. The T-SQL to Create the GetContentIDByPrimaryURL Stored Procedure
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROCEDURE [dbo].[GetContentIDByPrimaryURL]
@url nvarchar(200)
AS
BEGIN
SELECT contentID FROM FriendlyURLs WHERE url=@url
ENDNext, we need a stored procedure that will determine the correct primary URL when an alias is the method of arriving at the CMS. GetPrimaryURLByAlias, as shown in Listing 9-10.
Example 9-10. The T-SQL to Create the GetPrimaryURLByAlias Stored Procedure
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROCEDURE [dbo].[GetPrimaryURLByAlias]
@aliasURL nvarchar(200)
AS
BEGIN
SELECT url FROM FriendlyURLs WHERE contentID =
(SELECT contentID FROM AliasURLs WHERE url = @aliasURL)
END
GOEarlier, when we supplied test data we said that the primary (or canonical, if you prefer to think in Google-speak) URL for content ID 1 was /homepage-test/. Let's run the GetPrimaryURLByAlias stored procedure with the alias /home/ provided and ensure we're getting the correct result, which is shown in Figure 9-6.
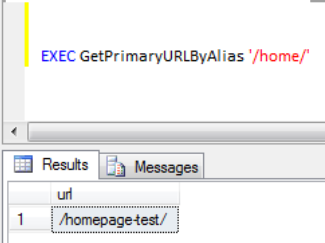
If a user arrives at our site via one of the aliases, say /home/, the CMS will examine the alias data first. If a suitable alias is found, the URL will be returned, and the CMS will redirect the user to that new page. If an alias is not found, then the primary URL table will be checked for a matching URL. If a match is not found in the primary table, then the CMS should return a friendly Page Not Found.
To handle something like extensionless URLs, we've got to dig into the life cycle of a typical page in .NET. Although I'm not going to break down every event here, I will highlight the one that we need to focus on: Application_BeginRequest.
You can work with page events in the Global.asax file in the root of your application. Right-click the Web project and click Add New Item. Select Global Application Class, and add it to the project. Once added, you'll see that a variety of methods have already been provided for you. Remove everything between the script tags, and add the Application_BeginRequest method, as shown in Listing 9-11.
Example 9-11. The Clean Global.asax File with Application_BeginRequest Added
<%@ Application Language="C#" %>
<script runat="server">
void Application_BeginRequest(object sender, EventArgs e)
{
}
</script>This event fires when a user requests a page from your application. We will use this event as a point at which we can interrupt the normal processing of a request and handle things our own way. We can perform a simple experiment first to see how effective this method really is. Modify the Global.asax file so that it looks like Listing 9-12.
Example 9-12. Catching Requests and Passing Them to a Predetermined URL
<%@ Application Language="C#" %>
<script runat="server">
void Application_BeginRequest(object sender, EventArgs e)
{
HttpContext.Current.RewritePath("content.aspx?id=1", false);
}
</script>Run the application again; try navigating to /Web/not-a-real-page, and you should see the output as displayed in Figure 9-7.
Tip
You'll notice that the style sheet we created earlier is no longer applied to the page. This is because we have interrupted the normal processing of a page, and all requests get routed to the content.aspx per our instructions. We will fix this issue shortly; for now, just note that it is both normal and not unexpected at this stage.

I hope it's clear that you now have what amounts to absolute control over URL processing for these pages. Essentially any input can be handled, so long as the web server is capable of processing the request and sending it to your application.
Now we can go ahead and exclude certain types of requests from the pipeline immediately, which will allow us to restore our style sheet. We'll begin by writing code in the Global.asax file and fleshing out the other libraries as needed.
At this point, we could come up with a list of media files and exclude them from the request pipeline in the Application_BeginRequest method, but that's not a clean solution. A better way would be to instantiate our Business library and let it handle this type of task, as shown in Listing 9-13.
Example 9-13. Setting Up Code to Exclude Certain Requests
<%@ Application Language="C#" %>
<script runat="server">
void Application_BeginRequest(object sender, EventArgs e)
{
var request = HttpContext.Current.Request.RawUrl.ToString().ToLower();
// all excluded types should signal an exit from the rewrite pipeline
if (Business.Rewrite.IsExcludedRequest(request)) return;
HttpContext.Current.RewritePath("content.aspx?id=1", false);
}
</script>So, the question becomes, what types of requests do we want to exclude? Based on experience, here is the list that covers most common requests in a CMS:
.css.js.png.gif.bmp.jpg/.jpeg.mov.ashx.asmx
Open the Business project, and create a new class file called Rewrite. This class will serve as the overall manager of the request pipeline moving forward. Listing 9-14 shows the code for the Rewrite class.
Example 9-14. The Code to Exclude Certain Types of Requests
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace Business
{
public static class Rewrite
{
/// <summary>
/// Checks incoming request against a list of excluded types
/// </summary>
/// <param name="request">the incoming request</param>
/// <returns>true if the current request should be excluded</returns>
public static bool IsExcludedRequest(string request)
{
if (request.Contains(".css") ||
request.Contains(".js") ||
request.Contains(".png") ||
request.Contains(".gif") ||
request.Contains(".bmp") ||
request.Contains(".jpg") ||
request.Contains(".jpeg") ||
request.Contains(".mov") ||
request.Contains(".ashx") ||
request.Contains(".asmx"))
{
return true;
}
return false;
}
}
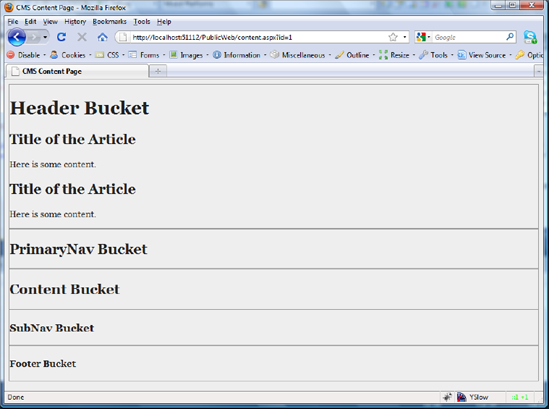
}Running the application again shows that our code was successful in identifying that the .css file request was processed by the .NET pipeline and intercepted by our own rewrite pipeline (see Figure 9-8).
Note
If you browse to /Web/, you'll see a directory listing; the content.aspx file is never hit. The default page in the Visual Studio server is Default.aspx. This problem can be solved when run through IIS by adding content.aspx as a default content page.
We have established what the CMS needs to ignore on a request-by-request basis; now we can turn our attention to retrieving content based on friendly URLs.
Although the CMS will check alias URLs first, we'll build the primary URL feature first, as shown in Listing 9-15. (It's redundant to check primary URLs first; if an alias is the correct match, the code would have to check the primary, the alias, and then the primary again after a redirection.)
Example 9-15. Checking Primary URLs for a Matching Request
<%@ Application Language="C#" %>
<script runat="server">
void Application_BeginRequest(object sender, EventArgs e)
{
var request = HttpContext.Current.Request.RawUrl.ToString().ToLower();
int? contentID = null;
// all excluded types should signal an exit from the rewrite pipeline
if (Business.Rewrite.IsExcludedRequest(request)) return;
// attempt to pull up a content ID by checking the primary URLs
contentID = Business.Rewrite.GetIDByPrimaryURL(request);
if (contentID != null) HttpContext.Current.RewritePath("content.aspx?id=" + contentID, false);
}
</script>We have a nullable content ID, in case no proper value can be found after we check the database. The Business library's Rewrite class needs a GetIDByPrimaryURL method that should return an integer value for the content ID (or null if no value is found). If the contentID value is not null, we'll rewrite the execution path to the correct ID and retrieve content for that particular value.
Let's modify the Rewrite class in Business with our desired result, as shown in Listing 9-16.
Example 9-16. The Rewrite Class Calls Down to the Data Tier for the Necessary Information
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace Business
{
public static class Rewrite
{
/// <summary>
/// Checks incoming request against a list of excluded types
/// </summary>
/// <param name="request">the incoming request</param>
/// <returns>true if the current request should be excluded</returns>
public static bool IsExcludedRequest(string request)
{
if (request.Contains(".css") ||
request.Contains(".js") ||request.Contains(".png") ||
request.Contains(".gif") ||
request.Contains(".bmp") ||
request.Contains(".jpg") ||
request.Contains(".jpeg") ||
request.Contains(".mov") ||
request.Contains(".ashx") ||
request.Contains(".asmx"))
{
return true;
}
return false;
}
/// <summary>
/// Attempts to pull up a content ID for an incoming friendly URL
/// </summary>
/// <param name="request">the incoming request</param>
/// <returns>a nullable integer for the content ID if available</returns>
public int? GetIDByPrimaryUrl(string request)
{
return Data.Rewrite.GetIDByPrimaryUrl(request);
}
}
}Since we've already performed the leg-work of writing the stored procedure for retrieving primary URLs, it's a pretty simple task of writing the necessary data access code. Add a Rewrite class to the Data project with the content from Listing 9-17.
Example 9-17. The Data Access code for Retrieving Primary URLs
using System;
using System.Data;
using System.Data.SqlClient;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace Data
{
public static class Rewrite
{
/// <summary>
/// Returns a content ID for a particular request
/// </summary>
/// <param name="request">the incoming request</param>
/// <returns>a nullable content ID for the content if available</returns>
public static int? GetIDByPrimaryUrl(string request)
{
int? contentID = null;
using (var conn = Factory.GetConnection()){
var comm = Factory.GetCommand("GetContentIDByPrimaryURL");
comm.CommandType = CommandType.StoredProcedure;
comm.Parameters.AddWithValue("@url", request);
try
{
conn.Open();
var reader = comm.ExecuteReader();
if (reader.Read())
{
contentID = reader.GetInt32(0);
}
conn.Close();
}
finally
{
conn.Close();
}
}
return contentID;
}
}
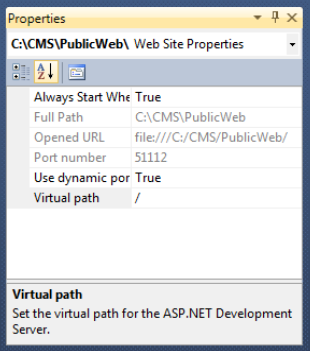
}While we're on the subject of cleaning URLs, there's no real reason for users to see the /Web/ segment of the URL that we've displayed so far. To remove it, click the Web project, and in the Properties tab below the Solution Explorer, change the Virtual path property from /Web to just /. Figure 9-9 shows this particular property.
Because we changed the Virtual path property of the project, we need to make one more small tweak to the Global.asax file so that the content.aspx file is at the expected path, as shown in Listing 9-18.
Example 9-18. A Minor Tweak to the content.aspx Path
<%@ Application Language="C#" %>
<script runat="server">
void Application_BeginRequest(object sender, EventArgs e)
{
var request = HttpContext.Current.Request.RawUrl.ToString().ToLower();
int? contentID = null;
// all excluded types should signal an exit from the rewrite pipeline
if (Business.Rewrite.IsExcludedRequest(request)) return;
// attempt to pull up a content ID by checking the primary URLs
contentID = Business.Rewrite.GetIDByPrimaryUrl(request);
if (contentID != null) HttpContext.Current.RewritePath("/content.aspx?id=" + contentID, false);
}
</script>Now you can run the application again; try browsing to any URL that isn't defined in the FriendlyURLs table. You should be presented with a stark 404 error indicating that the particular page couldn't be loaded, as shown in Figure 9-10. We will provide a more friendly 404 page at the end of this chapter.

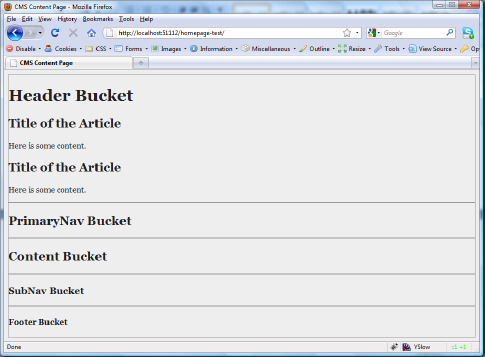
Now try browsing to /homepage-test/; you should find that content ID 1 loads properly, and all the buckets, embeddable, and style sheet information is functional, as shown in Figure 9-11.
Now that we have the necessary functionality to support primary URLs, we can turn our attention toward alias URLs. We've already created the stored procedure for returning the primary URL based on an incoming alias URL, so let's jump right into designing our code in Global.asax, which is shown in Listing 9-19.
Example 9-19. Accounting for Alias URLs and Their Redirections
<%@ Application Language="C#" %>
<script runat="server">
void Application_BeginRequest(object sender, EventArgs e)
{
var request = HttpContext.Current.Request.RawUrl.ToString().ToLower();
int? contentID = null;
string foundPrimaryViaAlias = String.Empty;
// all excluded types should signal an exit from the rewrite pipeline
if (Business.Rewrite.IsExcludedRequest(request)) return;
// attempt to pull up a primary URL by checking aliases
foundPrimaryViaAlias = Business.Rewrite.GetPrimaryUrlByAlias(request);
// if we found a primary, indicating this was an alias, redirect to the primary
if (!String.IsNullOrEmpty(foundPrimaryViaAlias))
{
Response.RedirectPermanent(foundPrimaryViaAlias);
}
// attempt to pull up a content ID by checking the primary URLs
contentID = Business.Rewrite.GetIDByPrimaryUrl(request);
if (contentID != null) HttpContext.Current.RewritePath("/content.aspx?id=" + contentID, false);
}
</script>Note
Response.RedirectPermanent is a new addition to .NET in version 4. Most developers are familiar with the older Response.Redirect, which issued a temporary redirect (302) to new content. Although functional, it's not accurate in the eyes of search engines under some conditions. For example, our alias is an available method of arriving at content, but it's not the permanent home for it; a 302 redirect would indicate that the alias only temporarily points to the parent content. The RedirectPermanent method allows for 301 redirects ("Moved Permanently"), which is more accurate information for a search engine. To the end user, there is no difference in experience while using the site.
This code calls the Business library's Rewrite class and attempts to get a primary URL as a result. If it is able to do so, then the class must have been able to find an alias, so therefore the request should be permanently redirected to the primary URL. Let's make some changes to the Rewrite class in the Business library to support this code, as shown in Listing 9-20.
Example 9-20. A Business Tier Pass-Through for the Data Tier
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace Business
{
public static class Rewrite
{
/// <summary>
/// Checks incoming request against a list of excluded types
/// </summary>
/// <param name="request">the incoming request</param>
/// <returns>true if the current request should be excluded</returns>
public static bool IsExcludedRequest(string request)
{
if (request.Contains(".css") ||
request.Contains(".js") ||
request.Contains(".png") ||
request.Contains(".gif") ||
request.Contains(".bmp") ||
request.Contains(".jpg") ||
request.Contains(".jpeg") ||
request.Contains(".mov") ||
request.Contains(".ashx") ||
request.Contains(".asmx"))
{
return true;
}
return false;
}
/// <summary>
/// Attempts to pull up a content ID for an incoming friendly URL
/// </summary>
/// <param name="request">the incoming request</param>
/// <returns>a nullable integer for the content ID if available</returns>
public static int? GetIDByPrimaryUrl(string request)
{
return Data.Rewrite.GetIDByPrimaryUrl(request);
}
/// <summary>
/// Attempts to pull up a primary URL based on an incoming alias
/// </summary>
/// <param name="request">the incoming request</param>/// <returns>a primary URL string, if available</returns>public static string GetPrimaryUrlByAlias(string request){return Data.Rewrite.GetPrimaryUrlByAlias(request);}} }
Simple enough. Now we only need to add code in the Data tier to call our stored procedure and return a primary URL if one can be found. Open the Rewrite class, and make the modifications shown in Listing 9-21.
Example 9-21. The Rewrite Class in the Data Tier, Modified to Return Primary URLs
using System;
using System.Data;
using System.Data.SqlClient;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace Data
{
public static class Rewrite
{
/// <summary>
/// Returns a content ID for a particular request
/// </summary>
/// <param name="request">the incoming request</param>
/// <returns>a nullable content ID for the content if available</returns>
public static int? GetIDByPrimaryUrl(string request)
{
int? contentID = null;
using (var conn = Factory.GetConnection())
{
var comm = Factory.GetCommand("GetContentIDByPrimaryURL");
comm.CommandType = CommandType.StoredProcedure;
comm.Parameters.AddWithValue("@url", request);
try
{
conn.Open();
var reader = comm.ExecuteReader();
if (reader.Read())
{
contentID = reader.GetInt32(0);
}
conn.Close();
}
finally
{conn.Close();
}
}
return contentID;
}
/// <summary>
/// Attempts to pull up a primary URL based on an incoming alias
/// </summary>
/// <param name="request">the incoming request</param>
/// <returns>a primary URL string, if available</returns>
public static string GetPrimaryUrlByAlias(string request)
{
string primaryURL = String.Empty;
using (var conn = Factory.GetConnection())
{
var comm = Factory.GetCommand("GetPrimaryURLByAlias");
comm.CommandType = CommandType.StoredProcedure;
comm.Parameters.AddWithValue("@aliasUrl", request);
try
{
conn.Open();
var reader = comm.ExecuteReader();
if (reader.Read())
{
primaryURL = reader.GetString(0);
}
conn.Close();
}
finally
{
conn.Close();
}
}
return primaryURL;
}
}
}Now run the application, and browse to /home/. You should immediately be redirected to the primary URL, which is /homepage-test/, as shown in Figure 9-12. Feel free to experiment with the other aliases and ensure that everything is working properly.

This wraps up the discussion of how to implement a content management system, as well as the book itself. In this chapter, we explored some key SEO concepts and went over some guidelines to follow when carrying out SEO. We then saw where these concepts and guidelines fit in the context of the CMS as a whole. We implemented a custom system for mapping URLs between unfriendly and friendly types and made use of .NET 4's new RedirectPermament method to improve the accuracy of how search engines view content within the site.
Building a CMS that is both extensible and high-performance is a complex task at best, but .NET 4.0 has a lot of technology behind it to make the process easier, if not outright enjoyable. As such, I recommend again that you grab a copy of the source code from the Apress site, because it contains a lot of additional code and examples that simply wouldn't all fit into the book.
I hope that the CMS serves as a good starting point for your future endeavors; maybe we will meet again for .NET 5.0.