
C H A P T E R 13
Load Balancing in the Cloud
Cloud computing is one of the newest developments in IT and is becoming more and more pervasive as time goes by. In view of its growing popularity and market presence, it is important to understand the impact of load balancing within the cloud.
This chapter aims to provide the following:
- A clear and concise definition of what cloud computing is!
- A ground up view of what comprises a cloud platform and cloud server.
- Methods for taking advantage of cloud computing to load balance your application loads.
- Common methods for load balancing the cloud itself.
- An overview of some of the specific implications of working within the cloud.
Cloud Computing
As with any new technology, there is a significant amount of conjecture about what exactly constitutes cloud computing. There are a number of definitions held by various people and the term cloud is used almost interchangeably by many different people.
While these definitions normally contain a measure of what true cloud computing is they often fail to provide many of the other characteristics that make cloud computing such a robust solution.
In our opinion the best definition of cloud computing platform is “a fully automated server platform that allows users to purchase, remotely create, dynamically scale, and administer system.”
By this definition, a cloud computing platform is “fully orchestrated,” which means that it functions without the need of its owner to perform basic business tasks. This means that the platform can - within reason, of course - operate without human intervention. Servers can be created, destroyed, modified, and users charged all by the system without the need for an administrator to intervene. In addition to this a cloud computing system is “elastic”; the amount of resources available to a server can be expanded and contracted with little or no intervention or downtime.
This is indeed a very broad definition, but covers the entirety of what it means to have cloud servers. While this definition provides some context, it lacks substance. Realistically, a cloud system is one that allows you as the customer to readily create a cloud server without needing the owner to perform any tasks. This server is in every way the same as a server physically owned by you, except that you have no responsibility for the hardware.
In addition, with little intervention you can change the resources available for your server to use. A cloud computer is simply a server that customers can scale to their needs and use exactly like one they purchase but without knowledge of the hardware and only accessible via the Internet.
As an example, you will see how to perform some of these modifications on the cloud platform provided by serverlove.com. First, before diving into using the system, you need to understand how server platforms like this function – you need to walk before you run. Serverlove uses a system called virtualization to provide a way for multiple users to take advantage of the resources of a cluster of servers. Given that virtualization introduces a significant amount of complexity into a server you should become familiar with it.
Virtualization
Virtualization is a method for creating what are called virtual servers that run on a cluster of a number of real servers. When you create these servers, you are allowing one very powerful server to emulate the function of several lesser servers.
While at a high level, this simply sounds like introducing a complex system to create fancy servers. Virtualization allows for a smaller number of high-powered servers to create a larger number of lesser servers while reducing the overall cost in space, power, and other infrastructure.
The real advantage of virtualized servers and hardware are that if one machine is at or near idle, others within its cluster can take advantage of its resources to perform their processing. This is the same in principle as clustered groups of servers, but virtualization allows for an even higher level of resource sharing.
The reason why this is so effective is that often a server will never use anywhere near its full capacity, so this excess capacity is shared with other servers until needed again. Even in situations in which you have heavily clustered your environment, there will still be some spare resources at any given moment.
This sharing of resources is what allows one high capacity server to host several virtualized servers all at once.
The way a virtualized server functions is that it introduces an abstraction layer between the hardware and the operating system. This abstraction layer is called the hypervisor.
Hypervisor
A hypervisor is a piece of software that acts as a resource allocation and hardware abstraction layer on a physical server.
This means that a hypervisor is software that slices up and shares the hardware resources of a single physical server among a number of virtual servers.
Figure 13-1 depicts the normal relationship between a server and an operating system (OS). A server hosts an OS, which in turn runs applications.

Figure 13-2 depicts a hypervisor, which sits between the server and the OS and allows one server to host several operating system instances.
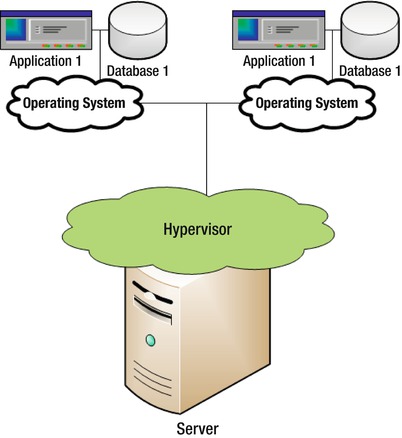
Figure 13-2. Server with hypervisor
There are two types of hypervisors (see Figure 13-3). The first is called a bare metal hypervisor, which is the basic hypervisor system that you have gone over above.
The second type is called a hosted hypervisor, which is not installed to the hardware itself, but within an operating system on the server, and thus is under the control of that operating system.
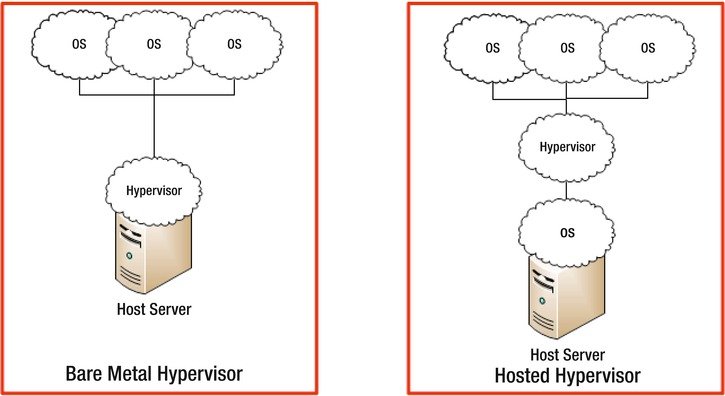
Figure 13-3. Bare metal hypervisor versus hosted hypervisor
The differences between the two hypervisors trade off flexibility in control against performance. The bare metal hypervisor has a significantly higher level of control over the resources available to it because it does not have to go through an intermediary to access the resources.
This comes at a cost since most bare metal hypervisors lack friendly user interfaces; some do not allow any user intervention at all. Hosted hypervisors, on the other hand, are limited by the operating system they are placed on; they can't allocate resources beyond what the parent operating system will provide them to use, and are governed by the resource control systems of the parent.
Hosted hypervisors are significantly easier to access, set up, and manage as they are normally able to take advantage of the parent operating systems graphical user interface to provide their own graphical management system.
Today there are a number of hypervisors on the market in both styles. The best known ones are these:
Bare metal
- VMware
- HyperV
Hosted
- VMware Player
- VirtualBox
- Xen
While hypervisors do give a significant advantage in allowing a large number of virtual servers to share resources, these setups are still limited by the resources available to the host server.
This means that only the amount of server resources on a host server is available for use, and if several servers at once try to use a significantly higher than expected amount of resources this can lead to the “starvation” of other servers.
For this reason many virtualization platforms employ a system of clustering to share resources whenever possible. However, before you go into examining how virtual clusters work, you should look at virtualized resources.
Virtualized Resources
Traditionally, a server's resources are limited to compute power, memory, physical storage, and network bandwidth. There are others, but those would be specialist resources that would be used depending on the situation.
Virtualization allows for these resources to be shared among a number of virtual servers. The first thing that you need to understand is how.
The first resource you will look at is storage. Storage is the long term storage attached to a server - for instance, the hard drive that contains the full working image of your operating system.
Storage is potentially one of the least virtualized resources available. Simply put, the virtual platform creates a section of its storage space and then allocates this aside for use by each virtual server. The issue here becomes whether a number of servers are trying to do a large volume of disk writes at the same time because this means that the amount of data pending to be written to disk continues to increase.
While these issues are extremely rare, they are normally solved by using higher performance disks, RAID arrays for speed, and network storage systems, which allow a much higher level of throughput. Allocation of these resources is straightforward and based on the ongoing full need of the server.
The second resource is network bandwidth. Bandwidth is like storage, in that is a simple resource that is easily split among several different virtual servers from a physical one. One 10Gbit link can be the same as 100 x 100Mbit links. In addition to this virtualization can begin to make a real advantage here, whereby 1x 10Gbit link could be shared as a gigabit connection over 20 virtual servers.
This is called overprovisioning and takes advantage of the fact that none of the virtual servers will be using the fill gigabit of bandwidth at all times.
The third resource involved in this case is Memory. Memory is a runtime dependant resource of a server and as such requires a significant amount of care to balance. RAM like disk and network is simply a shared resource that is split per physical server among all the virtual servers.
Each virtual server is given an allocation and can in theory consume memory up to that amount. While each server is allocated a maximum, it is rare for any machine to use anywhere near that amount. For example, the desktop we are using to write this is currently consuming only one-fourth of its available capacity, despite running several intensive applications in the background. Even if we ramp up and start running more applications, we only really reach a maximum of one-third of our capacity.
While this is a desktop and the applications we are running are not performing the kind of workload a complex business application would you should be able to see that it is not common for a computer to consume the entire amount of RAM available to it.
Finally, it is important to note that some hypervisors allow for “memory reclamation.” This happens in times of crisis and is designed to reclaim RAM from each of the virtual servers to better balance the load and occurs by each virtual server having an application spawned by the hypervisor, which begins consuming RAM and then feeding this consumed RAM back to store data for other servers.
The final resource, CPU, is shared via the concept of time slicing, which means that all the current requests for processing are sliced up, and these are all shared between the various virtual servers.
This works the same as having multiple processes on a regular server; each of the processes queues until it can gain access to the CPU, process and then return to idle.
CPU is one of the hardest resources to share as the hypervisor not only needs to give a portion to each server but also needs to do so regularly, since CPU requests need to be attended to in a timely manner.
This introduces one of additional measures of a CPU, which is the “waiting time” measure. This measure tells how long a particular server has been sitting in the ready-and-waiting state before being able to gain access to the CPU to process.
A small measure of wait time for a CPU is expected; this occurs in all PCs when they are running, however, excessive wait times can cause serious issues with computers, their internal clocks and cause major issues with running applications.
While it is obviously impossible to have a constant level of 0 waiting time, if the levels get too excessive (say over a second), you can begin seeing real performance issues.
Managing Virtual Resources
Although for anyone who will be building a server in a public cloud there will be little scope for changing the resource allocation, there is still significant benefit in understanding how performance can be altered and potentially discussing with your cloud provider to see ways to improve performance.
So, let's start looking at managing resources from a hypervisor perspective.
To understand how to examine the performance of a virtual server, you will need to become familiar with the basic measures available to you within a hypervisor (when referring to the server with the hypervisor on it, you call it a host) and how each of them is sliced among the virtual machines.
To begin with, you should look at how your resources are shared among your servers. With networking resources, you normally allocate one of the basic forms of networking to a server (10Mbit, 100Mbit, 1Gbit, and so on); each represents either the whole of a physical adapter or a fixed portion of its available capacity.
Performance management of networking is really about ensuring that you have enough capacity to deal with the data you are looking to transfer. For metrics, network is the same as for a regular server proportion of bandwidth consumed over a time period.
Storage as a resource is similar to networking as mentioned earlier. Storage metrics are predominantly around the capacity. There are two metrics: how much is available to each individual virtual machine and how much is available to the host as a whole.
Running out of storage on your virtual machine can simply require you to expand the capacity available to it, which often requires as little as a few configuration changes and a restart. The host running out of space can be more troubling if the storage is hosted within it.
This would require that you purchase more storage capacity from the provider to add to the host and likely reboot it and all the virtual machines hosted on it. Finally, if storage is on a network device, that simply means expanding the amount available via the network device.
The other common measures you will see for storage are the throughput measures, which show how much data is being written to storage at any given time and often a storage block measure that shows the amount of time, if any, that your virtual machine has been waiting to write but has been unable to due to other machines using the disk.
Memory as a resource works in a similar fashion. You will have a current usage versus the total available capacity metrics that show the current usage, and both these measures are available for the host and for each virtual machine.
This should allow you to evaluate the current performance of your server and host. In addition to the usage metrics, you can have a memory reclamation measure. These reclamation measures are never a good sign as they are forcing the virtual machine operating system to work as if it were under extreme load.
To need to be using the reclamation measure, your host must be in need of memory that it doesn't have. This lack can occur during a period of peak processing or if your host is too far overprovisioned. One final measure you may see is the virtual memory measure.
With virtual memory, your computer uses a portion of its disk storage to act as longer-term memory; the problem is that the time taken to read and write to and from virtual memory is significantly higher than that of using normal RAM, which can cause delays.
Ideally, a computer will use some virtual memory, but using too much might be a sign that your virtual machine is under some strain and you should look to alter its allocation and increase the amount of memory available to it.
CPU is the final resource (and in our opinion the most important) because it is not being shared as simply portions of a fixed CPU; it represents a number of clock cycles offered to the virtual machine to process. The main CPU measures are like the previous measures: a proportion of the allocation CPU run time used per virtual server and a proportion of the total available processing resources consumed by all the virtual machines.
While CPU has both measures for consumption, it also has the waiting measure mentioned earlier. CPU waiting time can be a real problem for virtual machines because they are unusable while they are in the waiting state.
This makes it vital to ensure that an adequate amount of processing capacity is available to all servers. In times of high load, that you should either shut down unnecessary virtual machines or find a way to limit the amount of CPU these other machines use.
Now that you know the basic resources, you can look at how to balance these out to gain higher performance.
Balancing
There is a multitude of different systems and software that you can use to modify performance. As such, we cannot give specific application advice; what follows here is a series of steps and guidelines we have used to balance the performance of virtual machines on a virtual platform.
As with any form of load balancing, you should examine your performance beforehand, make the change, and then examine. You should be looking for improvements and aiming to make things more efficient.
If you cannot control which machines are running on a host, there is little you can do. However, gaining some background into how a virtual platform works will give you an edge in working with virtual machines.
The key concept on a virtual platform is to have enough servers running on the host that the resources are taxed, which minimizes waste, but are not overtaxed, which would lead to some of your servers being starved for resources.
One of the first things any virtualization software systems provisioning manual normally covers is the idea that you need to mix your virtual machines up; some will be performing nighttime processing, and some will perform daytime processing, for example. This way, you will have one doing heavy processing while the other rests. This can be advantageous for virtual machine owners to keep in mind because you can work to find some equilibrium as well.
So, with this in mind you need to ensure that the servers on your cluster are doing different forms of processing at different times. Mixing workloads will go a long way to leveling out the kinds of total workload you have.
Next is to look at allocations per virtual machine, which requires a measure of historical information about your server and will need for it to have been running for a time, the longer the better.
You need to look at the performance over this period and find the average and the maximum. If there are some significant spikes that don't occur regularly, you should look over your servers running logs and find out why these occur.
If you have found that you have need for excess capacity at a certain point during the day or week, you should look to arrange a flexible CPU amount overall, but set your allocation lower totally.
You should look to be running as high a CPU consumption as you can without affecting the performance of the application, depending on the OS, application, and so on. Under a good running workload, this can be 60% of your CPU allocation.
This theory runs completely contrary to the normal way people allocate resources: you add as much as you can to deal with growth and any extra need for processing power.
While this is advantageous in a virtual machine, it is a waste to have all that extra capacity sitting idle on your server. Moreover, in the cloud it actually costs you more to have this because in the cloud you pay for the resources you are given. (This is true for most of the resources you will have.) If you don't need the extra capacity, do not ask for it and get rid of it. While you are doing this, you should always be looking at not only your system performance but also your application performance. This is the ultimate balancing act.
Looking from a higher level at the host side of things, everything becomes more fixed. You cannot juggle the available resources to find that sweet spot as you would with a virtual machine.
Instead it becomes about ensuring that the collection of virtual machines is okay and able to function. This means that you are realistically monitoring all these resources to ensure that you don't have too many virtual machines on one host.
Examining the values for how much CPU and RAM are good beginning indicators, and like a virtual machine you will want these values to be high, but not full.
Storage ensures that you have enough disk space to continue running, and networking is the same: that you have enough to continue allowing all your servers to function. In addition to this disk space, storage also encompasses the input and output to storage devices, which is referred to as I/O. Beyond having enough capacity, it is also very important to ensure that your storage devices are not flooded with requests for storage. Having higher levels of storage I/O can cause major problems with storage as each server will need to wait longer and longer in a queue for its turn to store data.
Now beyond these basic raw consumption measures, you will have some other metrics, such as the CPU waiting time measure and the memory reclamation measure. These are very important measures as having any memory reclamation is a sign that your host is under load, and you need to remove some of the applications consuming memory.
This is not the same for the CPU waiting time because having a hypervisor introduces this by default, which means you will only be able to achieve a waiting time of 0 for all your servers at all times when you have less virtual machines that your host has logical processors. Having a small wait time on each server is normal and simply makes the server function at the same level as it would with physical resources. This is not to say that waiting time is a low-impact resource.
You must at all times ensure that waiting times for your servers are low, normally under one second; any more time that this and you run the risk of severely crippling the virtual machines running on the host. As with most of these resources, it is simply another measure that says you have added too many virtual machines to your server.
Much of this would be trial and error, but the primary overriding concept is that you want to have your host so that it contains as many virtual machines as possible while maintaining as little impact to the regular running of all and leaving enough overhead to deal with peak processing loads.
Overprovisioning
In order to achieve the ideal aim of having a large number of virtual machines on a single host with no impact you need to become familiar with a concept called.
Overprovisioning means allocating more resources and (normally) more virtual machines that your host has available to it. This is for many people an odd concept at first. They key is in understanding how servers are loaded - which in and of itself will help you understand your long-term performance. In a server running just an operating system, you should expect to see very low levels and flat graphs - as the usage of the server doesn't change over time, it's just sitting there.
From this basic operating system level you can now add the application - the purpose for us having a server. Now that you have this running, you should see an increase in your base running, but in addition to this you will likely see some periods of higher running or regular spikes.
These indicate periods of higher processing by your application; as an example, times when a larger number of users is connected. From these you should be able to find what would be the normal expected level of usage when your application is under server processing load from high usage.
Once you have an idea what level of resources your server will use while processing, you can use this level as the realistic maximum and then give your server this amount of resources and a small amount of overhead, in case its workload exceeds your expectations (normally this overhead is somewhere between one-third to one-fifth). It is that overhead between your normal workload, peak workload, and the small amount of excess that gives a whole lot of excess resources and is where virtualization shines!
All those slivers of leftover overhead, all that space that is not being used at any one given moment when combined form a significant volume of resources, and all of them when combined are enough to power several virtual machines. This is what you call overprovisioning, adding more servers than you have provisioned for, because you know that you will have spare extra capacity to use with these servers. This is similar to what most airlines do with bookings: to avoid having unfilled seats they book for more people than a plane can carry – assuming that some passengers won't show up!
Working overprovisioning correctly is similar in manner to how you allocate resources to a virtual machine, simply find your “normal” loaded resource consumption and then add virtual machines, while continually checking to ensure you aren't affecting any one virtual machine.
Additionally, this is where resources such as CPU waiting time and memory reclamation come into their own. They can provide real-time indication that your host is in trouble and you can react by shutting down a virtual machine or redistributing resources.
Planning
Much of what is required to make a virtual machine or virtual machine host function correctly is planning. Planning in this context is simply about the collection of data and adapting your systems based on this data.
So to start your planning system, you need to collect data. Most virtual machine platforms have a significant performance history system within them, so take advantage of this and find times when your virtual machines' loads have peaked. Match this with any load or user information you have on your servers, such as times when you were performing backups or times when you had a significantly heavy user volume.
In addition, you can also look at what kind of levels you have when your system is quiet, so between the two you can begin to make comparisons and find commonalities between the loads.
Consider the example illustrated in Figure 13-4.
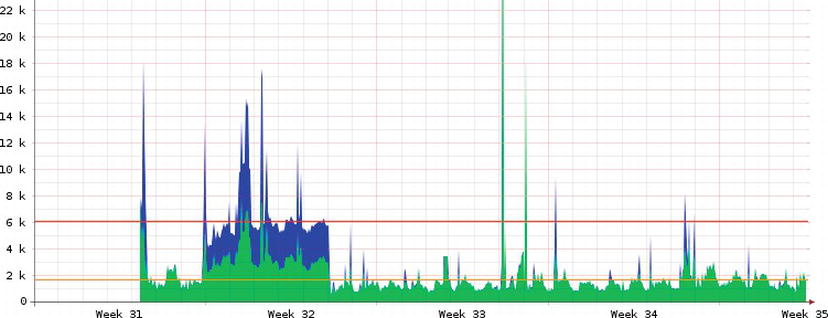
Figure 13-4. Performance graph
In the figure, you can see that you have several high load spikes: one big spike during the first week when the server was being stress tested and big spikes once a week. They occur on Saturday night as this is when you are performing stress and load tests. Knowing this, you could set up systems within our virtual platform to help cope. Before our load is expected to increase (say on Saturday morning), we make a request to our cloud provider (or virtual machine host) to double the capacity of our server, temporarily. This means that when the load comes, our server is ready and will function effectively. Finally, after the peak period we can drop the server off to the lower normal level.
These kinds of changes take full advantage of the cloud; we can dynamically expand our capacity in real time to accommodate a known period of heavy load. In addition, we minimize costs by keeping the allocation of resources to our server low during the periods of lower workload.
Cloud Elasticity
Cloud servers that are virtualized have other advantages to boot. In addition to being able to be scaled, they are portable.
The portable nature of cloud servers comes from the style that their storage takes. In the case of most virtual machines, the storage for them are written to hard drive files on disk, which allows them to be easily backed up, allocated per virtual machine, and so on.
The added benefit here is that each file can be treated as one would normally treat a file: it can be moved, renamed, or copied. This is an extremely useful thing since a copy of an existing virtual machine can give you an identical clone of an existing server.
Many cloud providers offer the ability to clone a server from an existing one using this method. This means that if you are aware of an incoming period of excessive usage, you can take advantage of this feature, clone your machine, and set this up to work as a clustered partner with your existing server.
Or if you already have an existing cluster, simply add this server to the load balancer, and it will function. After the load has passed, you can shut down the server, which has dealt with some excessive load and again minimized costs to you by leveraging the flexibility of the cloud.
There is an even greater advantage: if you see the load spike again later, you can simply power the server up again and (assuming you have a high availability cluster, as discussed in Chapter 12) power the server up. It would register with heartbeat and would begin working until the server is no longer needed!
Working with a Cloud Server
So, now that you understand the full power of a cloud server, let's have a look at working with one. All the testing needs were covered by a group of cloud servers provided by serverlove.com, so we will show you how you can configure a virtual cloud server as outlined previously.
So, to begin with let's look at resource renegotiation. To perform this, we needed to log in to the Serverlove management page. From here, you can see a list of the servers you have been using (Figure 13-5).
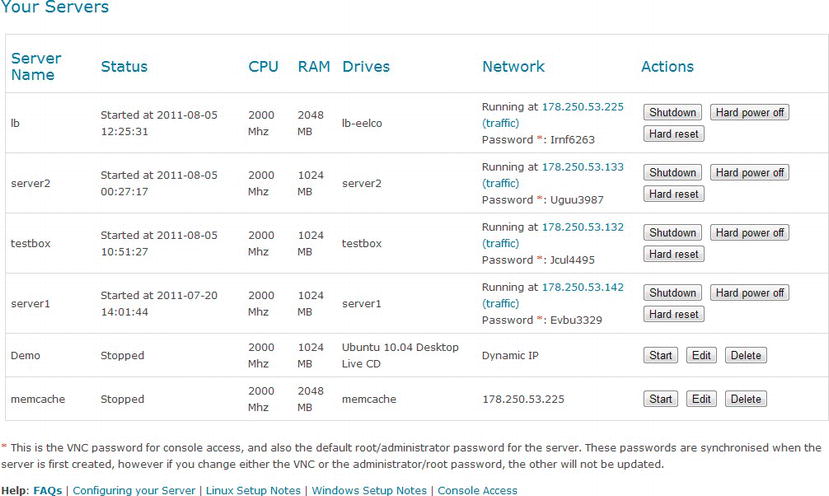
Figure 13-5. Server list page
From the server list page, you can power on or off a server. Unfortunately, just like with a real server, you need to shut down and reboot the server to make a change to the resources allocated it. This is due to the fact that most, if not all, modern operating systems cannot dynamically reconfigure their internal memory allocation from scratch.
Once you have shut the server down, you can press Edit to bring up the server configuration page. The configuration page allows you to edit the available CPU, RAM, Hard Drives, Network Adapter, VNC, and other specific details. From this panel (see Figure 13-6) you can elastically alter the resources as needed (with the altered costs, of course).
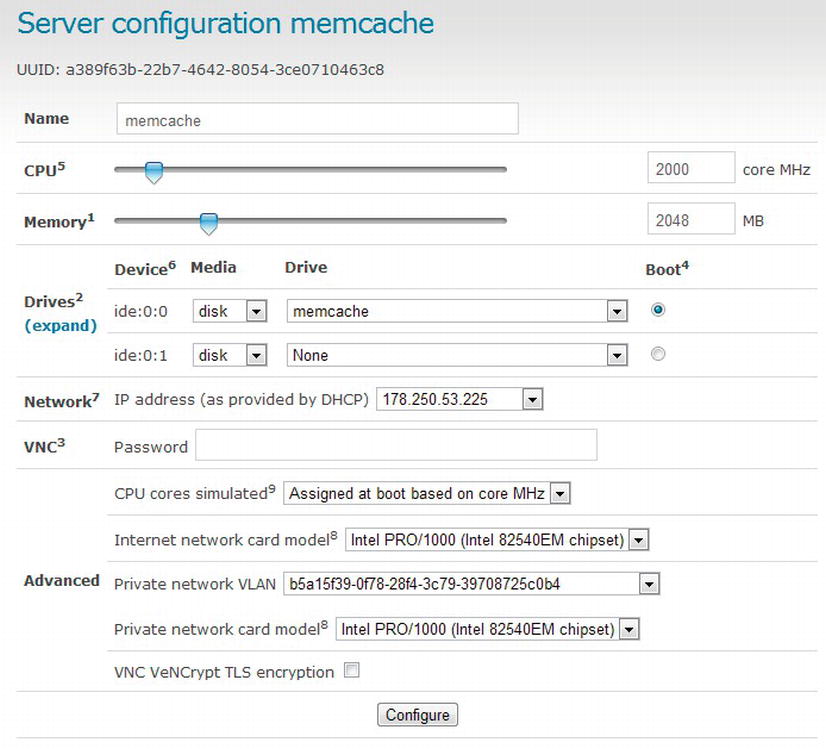
Figure 13-6. Server config panel
Keeping in mind that the drive selector is a drop-down, you can head back to the main page (see Figure 13-7) to see the hard-drive creation utilities in which you can create virtual hard disks to attach to the virtual machines.
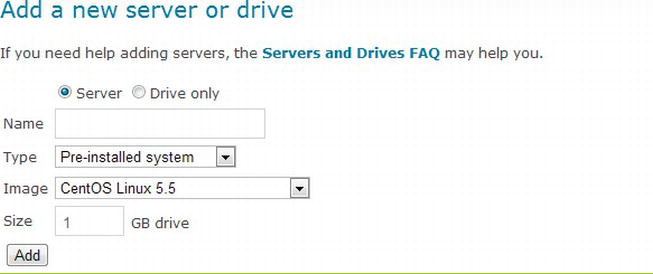
Figure 13-7. Adding a new drive
In addition to creating new virtual drives you can also scroll down and modify and clone the drives that already exist with the servers (see Figure 3-8).
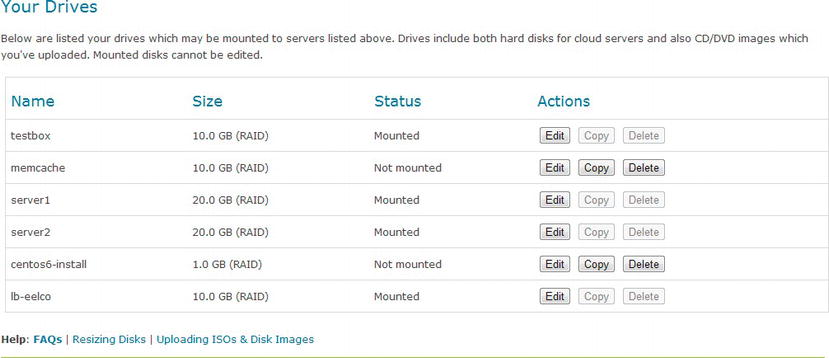
Figure 13-8. Modify drives
From the preceding examples, you should be now be aware of exactly how flexible a cloud server can be and how easy it is to expand the power and capacity of your servers – as needed.
Summary
Having been through this chapter, you should now be familiar with the real benefits offered by the new cloud technologies emerging all over the planet. You learned about cloud services – how they are built and run. The chapter also discussed virtualization, one of the key technologies that work with cloud. Finally, you should now have some of the basic strategies with which to take advantage of cloud servers to increase your server performance and minimize costs.