
Native Development
Although the Android framework is designed purely for Java-based applications, the Android Native Development Kit (NDK) is also provided by Google as an official companion toolset for the Android SDK to enable developers to implement and embed performance-critical portions of their applications using native machine code–generating programming languages, such as C, C++, and assembly.
Through the Java Native Interface (JNI) technology, the native components can be accessed seamlessly as ordinary Java methods. Both the Java and native code portions of the application run within the same process. Although the JNI technology permits both the Java and the native code to coexist within the same application, it does not expand the boundaries of the Dalvik Virtual Machine (VM). The Java code is still managed and executed by the Dalvik VM, and all native code is expected to manage itself throughout the life cycle of the application. This imposes additional responsibilities on developers.
To execute effectively side by side with the virtual machine, the native components are expected to be good neighbors and interact with their Java counterparts maintaining a delicate boundary. If this interaction is not properly managed, the native components can cause hardly traceable errors within the application; such errors can even take the entire application down by crashing the virtual machine.
In this chapter, you will learn some of the best practices for developing well-behaving native components on the Android platform.
Deciding Where to Use Native Code
The first best practice that you will learn in this chapter is to properly identify the components of your application that can benefit from using native code support.
Where Not to Use Native Code
The biggest and most common false assumption about native code is the expectation of an automatic performance gain by simply coding application modules in native code instead of Java.
Using native machine code does not always result in an automatic performance boost. Although earlier versions of Java were known to be much slower than native code, the latest Java technology is highly optimized, and the speed difference is negligible in many cases. The JIT compilation feature of the Java Virtual Machine, specifically the Dalvik VM in the case of Android, allows the translation from the interpreted byte-code into machine code during application startup. The translated machine code is then used throughout the execution of the application, making the Java applications run as fast as their native counterparts.
Caution Using native machine code does not always result in an automatic performance improvement.
Be aware that overusing the native code support in your application can easily lead to much bigger stability problems. Because native code is not managed by the Dalvik VM, most of that memory management code has to be written by you; and this itself increases the complexity and the code size of the overall application.
Where to Use Native Code
Using native code in Android applications is definitely not a bad practice. In certain cases, it becomes highly beneficial because it can provide for code reuse and improve the performance of some complex applications. Here is a list of some common areas that can benefit from native code support:
- Use of Existing Third Party Libraries: Imagine that you will be developing a Video Editing application on the Android platform. For your application to operate, it needs to be able to read and write in various video formats, such as the Theora video codec. The Java framework does not provide any APIs to deal with Theora. Developing the code necessary to deal with this video format is not an efficient use of time, so your best option is to utilize an already available third-party library that can understand the Theora video codec. Despite the popularity of the Java programming language, the code library ecosystem is still highly mandated by C/C++-based native code libraries. There is a much better chance that you will find various implementations of the Theora video codec as C/C++ libraries. Native code support becomes really handy here, as it can enable you to blend the native C/C++ library into your Android application seamlessly. It is a good practice to use native code support to promote code reuse, as that facilitates the development process.
- Hardware Specific Optimization of Performance Critical Code: As a platform-independent programming language, Java does not provide any mechanism for using the CPU-specific features for optimizing the performance-critical portions of Android applications. Compared to desktop platforms, mobile device resources are highly scarce. For complex applications with high performance requirements, such as 3D games and multimedia applications, effectively using every possible CPU feature is crucial. ARM processors, such as ARM NEON and ARM VFPv3-D32, provide additional instruction sets to allow mobile applications to hardware-accelerate many performance-critical operations. It is a good practice to use native code support to benefit from these CPU specific features.
Java Native Interface
As indicated earlier in this chapter, JNI is a mechanism and a set of APIs that are exposed by the Java Virtual Machine to enable developers to write parts of a Java application using a native programming language. These native components can be accessed transparently from the Java code as ordinary Java methods. JNI also provides a set of API functions to enable the native code to access the Java objects. Native components can create new Java objects or use objects created by the Java application, which can inspect, modify, and invoke methods on these objects to perform tasks.
Difficulties Writing Native Code Using JNI
Integrating native code into a Java application through JNI requires native functions to be declared with a specially crafted name conforming to JNI specification. In addition to the function name, each parameter to the native function should also use the JNI data types. Because the Java and the native code are compiled in separate silos, any issues in this part of the code are not visible at compile-time.
Reaching back from native code to Java space also requires a sequence of API calls. As the native programming language has no knowledge about the Java portion of the code, it cannot provide any compile-time errors if you use a wrong API call. In addition, a change in the Java portion of the code could also break the native portion of the code, and you would not be informed about this at compile-time, either.
Even if you take extraordinary measures to prevent bugs from occurring, keeping native methods and their declarations in Java space aligned can be a cumbersome and redundant task. In this section, you will learn how to benefit from the available tools to auto-generate the necessary code instead of typing it manually.
Generate the Code Using a Tool
A common good practice in almost every programming language is that as a good developer, you should always minimize the number of code lines you manually produce. Any code line that you produce, you will have to maintain throughout the lifetime of your application. As a good practice, you should always take advantage of the code generators that are provided by the SDKs and the IDEs to achieve that.
Tip Benefit from the code generators that are provided by the SDKs to minimize the amount of code that you need to write.
Generating C/C++ Header Files Using javah
The javah tool is part of the Java JDK distribution. It operates on the Java class files with native method declarations and generates corresponding C/C++ header files with appropriate signatures based on the JNI specification. Because the generated header files are not expected to be modified by the developer, you can invoke javah as many times as you like to keep the native method declarations in sync.
The javah tool is a standalone application that is located in the <JDK_HOME>/bin directory on your machine. Invoking it without any command-line arguments would present a list of available arguments. Depending on your project structure and unique requirements, you can decide where to involve the javah tool in your build process.
Following is a simple example demonstrating how javah works. For the sake of simplicity, and to be as platform-independent as possible, in this example you will be using javah through an ANT build script that is extending the Android ANT build framework. Only the relevant portions of the source code will be highlighted here. You can download the full source code from the book’s website.
- As shown in Listing 5-1, define a new ANT task called headers in the custom_rules.xml file in order to extend the Android build system with the ability to generate C/C++ header files for native methods. List your classes with native modules accordingly. The javah tool will process only the classes that are explicitly mentioned.
Listing 5-1. Content of custom_rules.xml File
<?xml version="1.0" encoding="UTF-8"?>
<project name="custom_rules">
<target name="headers" depends="debug">
<path id="headers.classpath">
<path refid="project.all.jars.path" />
<path path="${out.classes.absolute.dir}" />
</path>
<property name="headers.bootclasspath.value"
refid="project.target.class.path" />
<property name="headers.classpath.value"
refid="headers.classpath" />
<property name="headers.destdir" value="jni" />
<echo message="Generating C/C++ header files..." />
<mkdir dir="${headers.destdir}" />
<javah destdir="${headers.destdir}"
classpath="${headers.classpath.value}"
bootclasspath="${headers.bootclasspath.value}"
verbose="true">
<!-- List of classes with native methods. -->
<class name="com.apress.example.MainActivity" />
</javah>
</target>
</project> - Assume that your Android application contains a native method, called nativeMethod, within the MainActivity class as shown in Listing 5-2.
Listing 5-2. Content of MainActivity.java file with a Native Method
public class MainActivity extends Activity
{
...
/**
* Native method that is implemented using C/C++.
*
* @param index integer value.
* @param activity activity instance.
* @return string value.
* @throws IOException
*/
private static native String nativeMethod(int index,
Activity activity) throws IOException;
} - You can now use the ANT script by invoking the following on the command line:
ant headers - This will first trigger a full compile of your application, for the class files to be generated. Then it will invoke the javah tool on the specified class files to parse the method signatures of your native methods. While the javah tool is working, it will print a status message as shown in Listing 5-3.
Listing 5-3. The javah Tool Generating the Header Files
headers:
[echo] Generating C/C++ header files...
[mkdir] Created dir: C:srcJavahTestjni
[javah] [Creating file ... [com_apress_example_MainActivity.h]] - The javah tool will generate a set of header files in the jni subdirectory of your project. The header files will be named according to the name of the Java class that encapsulates the native method. In this example, the header file com_apress_example_MainActivity.h header fill will be generated. As shown in Listing 5-4, the content of this header file will include the native function signature for each native method that you need to implement.
Listing 5-4. Generated C/C++ Header File
/* DO NOT EDIT THIS FILE - it is machine generated */
#include <jni.h>
/* Header for class com_apress_example_MainActivity */
#ifndef _Included_com_apress_example_MainActivity
#define _Included_com_apress_example_MainActivity
#ifdef __cplusplus
extern "C" {
#endif
...
/*
* Class: com_apress_example_MainActivity
* Method: nativeMethod
* Signature: (ILandroid/app/Activity;)Ljava/lang/String;
*/
JNIEXPORT jstring JNICALL Java_com_apress_example_MainActivity_nativeMethod
(JNIEnv *, jclass, jint, jobject);
#ifdef __cplusplus
}
#endif
#endif - As suggested at the top of the header file, you should not modify this header file directly, because it will be overwritten each time you execute the javah tool. Instead, you are expected to provide the implementation of all native methods that are declared in this header file in a separate C/C++ source file.
Because the Java and native portions of the code are in two separate silos, the Android build system does not perform any validation while building your application. Any missing native function merely triggers a java.lang.UnsatisfiedLinkError once it is called at runtime. The javah tool helps you to prevent these errors by auto-generating signatures.
Tip Using the javah tool helps to prevent java.lang.UnsatisfiedLinkError runtime exceptions in your Android application.
As each native method is declared in the header files, any missing implementations of those functions trigger a compile-time error to prevent you from releasing your Android application with missing implementations.
Generating the JNI Code using SWIG
In the previous section, you learned how to utilize the javah tool. Although javah helps you by generating the native function signatures and keeping them in sync with the Java code, you still have to provide the wrapper code to glue the native implementation of those native functions to the Java layer. This will require you to use plenty of JNI API calls, which is a cumbersome and time-consuming development task.
In this section, you will learn about another powerful tool, known as Simplified Wrapper and Interface Generator (SWIG). It simplifies the process of developing native functions by generating the necessary JNI wrapper code. SWIG is an interface compiler, merely a code generator; it does not define a new protocol nor is it a component framework or a specialized runtime library. SWIG takes an interface file as its input and produces the necessary code to expose that interface in Java. SWIG is not a stub generator; it produces code that is ready to be compiled and run. You can download SWIG from its official website at www.swig.org. A simple example application will help you better understand how SWIG can help.
In this example, assume that you need to obtain the Unix username of your Android application during runtime. This information is available through the POSIX getlogin function, which is accessible only from the native C/C++ code, but not from Java. Although the implementation of this function is already provided by the platform, you still have to write JNI API calls to expose the result of this function to Java space, as shown in Listing 5-5.
Listing 5-5. Getlogin Function Exposed Through JNI
JNIEXPORT jstring JNICALL Java_com_apress_example_Unix_getlogin(JNIEnv* env, jclass clazz) {
jstring loginString = 0;
const char* login = getlogin();
if (0 != login) {
loginString = env->NewStringUTF(login);
}
return loginString;
}
SWIG can help you by generating this code automatically. In order to let SWIG know about which function to wrap, you will need to specify it in a SWIG interface file. As indicated earlier, SWIG is an interface compiler; it generates code based on the provided interface. The SWIG interface file for exposing the getlogin function looks as shown in Listing 5-6.
Listing 5-6. The Unix.i SWIG Interface File
/* Module name is Unix. */
%module Unix
%{
/* Include the POSIX operating system APIs. */
#include <unistd.h>
%}
/* Ask SWG to wrap getlogin function. */
extern char* getlogin(void);
Assuming that you have installed the SWIG tool on your workstation, and the SWIG binary directory is added to your PATH environment variable, invoke the following on the command prompt all in one line:
swig -java
-package com.apress.example
-outdir src/com/apress/example
jni/Unix.i
The SWIG tool processes the Unix.i interface file and generates the Unix_wrap.c C/C++ JNI wrapper code, as shown in Listing 5-7, in the jni directory as well as the UnixJNI.java and Unix.java Java proxy classes in the com.apress.example Java package.
Listing 5-7. The Unix_wrap.c Native Source File Generated by SWIG
/* ----------------------------------------------------------------------------
* This file was automatically generated by SWIG (http://www.swig.org).
* Version 2.0.11
*
* This file is not intended to be easily readable and contains a number of
* coding conventions designed to improve portability and efficiency. Do not make
* changes to this file unless you know what you are doing--modify the SWIG
* interface file instead.
* ----------------------------------------------------------------------------- */
#define SWIGJAVA
...
/* Include the POSIX operating system APIs. */
#include <unistd.h>
#ifdef __cplusplus
extern "C" {
#endif
SWIGEXPORT jstring JNICALL Java_com_apress_example_UnixJNI_getlogin(JNIEnv *jenv, jclass jcls) {
jstring jresult = 0 ;
char *result = 0 ;
(void)jenv;
(void)jcls;
result = (char *)getlogin();
if (result) jresult = (*jenv)->NewStringUTF(jenv, (const char *)result);
return jresult;
}
...
To use the native function, you can now simply use the getlogin Java method from the com.apress.example.Unix class in your application. Without writing any JNI wrapper code, SWIG enabled you to utilize the native function in your Android application.
Minimize the Number of JNI API Calls
Although SWIG tool is highly promising, needless to say there will be still cases where automatic code generation is simply not an option. In those cases, you will need to write the necessary JNI API calls to provide the functionality. Even when manual JNI API calls cannot be prevented, minimizing the number of such calls can still help in optimizing the overall application and reducing the code footprint. In this section you will learn about some of the best practices to minimize the number of JNI API calls needed in your application.
Use Primitive Data Types as Native Method Parameters
There are two sorts of data types in the Java programming language: the primitive data types, such as byte, short, int, and float, and the complex data types, such as Object, Integer, and String. JNI can automatically map most of the primitive data types to C/C++ primitive data types. The native function can use data that is passed as primitive types directly without the need to make any specific JNI API call, as shown in Table 5-1.
Table 5-1. Primitive Data Type Mapping
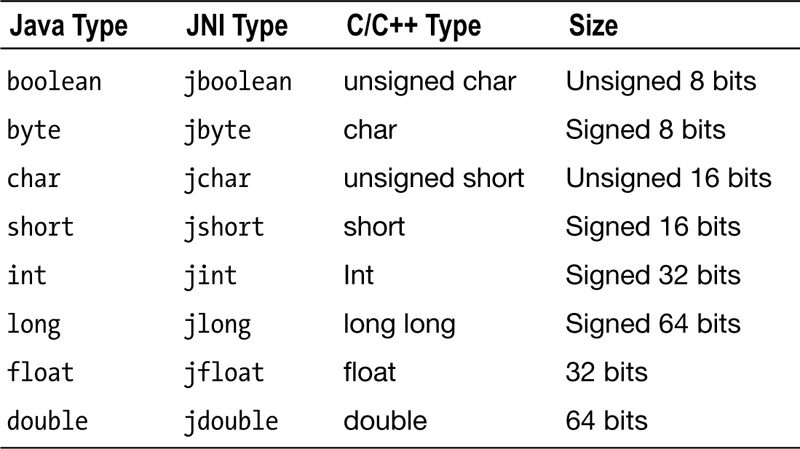
However, the complex data types are passed as opaque references to the native function. In order to use that data, the native function must make various JNI API calls to extract the pieces of the data in a primitive data format that can be used in native code. When defining your native methods, as a best practice, focus on eliminating complex data types in both the parameter list and the return value as much as possible. This will help you to minimize the number of JNI API calls in your native code, and it will also improve the performance of the native function drastically.
Minimize Reach-Back from Native Code to Java Space
A native function is not limited by the data that is passed to it through its parameters. JNI provides the necessary API to enable the native code to interact with the Java space. This flexibility comes with a cost. Using JNI API calls to reach back from native code to Java space consumes CPU cycles and impacts the application performance; meanwhile, it increases the complexity of the native code because of the number of necessary JNI API calls.
As a best practice, make sure you are passing all of the required data into your native function through its parameters, instead of having the native function reach back to Java space to obtain them.
Take a look at the following code example. As shown in Listing 5-8, the native code makes multiple JNI API calls to access the data it needs.
Listing 5-8. Native Method Accessing Two Fields from the Object Instance
JNIEXPORT void JNICALL Java_com_apress_example_Unix_method(JNIEnv* env, jobject obj) {
jclass clazz = env->GetObjectClass(obj);
jfieldID field1Id = env->GetFieldID(clazz, "field1", "Ljava/lang/String;");
jstring field1Value = env->GetObjectField(obj, field1Id);
jfieldID field2Id = env->GetFieldID(clazz, "field2", "Ljava/lang/Integer;");
jobject field2Value = env->GetObjectField(obj, field2Id);
...
}
As shown in Listing 5-9, the native method declaration can be modified to include field1 and field2 as part of the native method parameters to eliminate those JNI API calls.
Listing 5-9. Both the field1 and field2 Passed to Native Method Directly
JNIEXPORT jstring JNICALL Java_com_apress_example_Unix_method(JNIEnv* env, jobject obj,
jstring field1, jobject field2) {
...
}
To avoid redundant coding in Java space, it is also a common practice to utilize helper methods that would aggregate these extra data items prior calling the native method instead of requiring the developer to pass them each time, as shown in Listing 5-10.
Listing 5-10. Helper Method that Aggregates the Necessary Parameters
public void method() {
jniMethod(field1, field2);
}
public native void jniMethod(String field1, Integer field2);
Memory Usage
Compared to desktop-based platforms, memory is a scarce resource on mobile devices. Java is known as a managed programming language, meaning that the Java Virtual Machine (JVM) manages the application memory on behalf of the developer. During the execution of an application, JVM keeps an eye on the available references to the allocated memory regions. When JVM detects that an allocated memory region can no longer be reached by the application code, it releases the memory automatically through a mechanism known as garbage collection. This frees the developer from managing the application memory directly, and it drastically reduces the complexity of the code.
JVM garbage collectors boundaries are limited to the Java space only. Because the native code does not run in the managed environment, the JVM garbage collector cannot monitor or free the memory that your application allocates in the native space. It is the developer’s responsibility to manage the application memory in native space properly. Otherwise, the application can easily cause the device to run out of memory. This can jeopardize the stability of both the application and the device.
In this section, you will learn about some of the best practices for using memory efficiently in the native space.
As they do in the Java space, references continue to play an important role in the native space as well. JNI supports three kinds of references: local references, global references, and weak global references. Because the JVM garbage collector does not apply to native space, JNI provides a set of API calls to enable the developer to manage the lifecycle of each of these reference types.
All parameters passed to the native function are local references. In addition, most JNI API calls also return local references.
Never Cache Local References
The lifespan of a local reference is limited to that of the native method itself. Once the native method returns, JVM frees all local references that are either passed in or allocated within the native method. Therefore, you cannot cache and reuse these local references in subsequent invocations. To reuse a reference, you must explicitly create a global reference based on the local reference, using the NewGlobalRef JNI API call, as shown in Listing 5-11.
Listing 5-11. Obtaining a Global Reference from a Local Reference
jobject globalObject = env->NewGlobalRef(localObject);
if (0 != globalObject) {
// You can now cache and reuse globalObject
}
You can release the global reference when it is no longer needed using the DeleteGlobalRef JNI API call:
env->DeleteLocalRef(globalObject);
As always, global references in native space can be avoided by passing the necessary data as a parameter to the native method directly. Otherwise, it is the developer’s responsibility to manage the lifecycle of global references in native code, as they are not managed by the JVM.
Release Local References in Complex Native Methods
Although JVM still manages the lifecycle of local references, it can only do so once the native method returns. Because JVM has no knowledge about the internals of your native method, it cannot touch the local references while the native method is executing. For that reason it is the developer’s responsibility to manage the local references during the execution of the native method.
Caution Please note that the memory footprint of the local references is not the only reason you need to manage them; the JVM local reference table can hold only up to 512 local references during the execution of your native method. If the local reference table overflows, your application will be terminated by the JVM.
To better understand the problem, take a look at the code shown in Listing 5-12.
Listing 5-12. Native Code Allocating Local References
jsize len = env->GetArrayLength(nameArray); // len = 600
for (jsize i=0; i < len; i++) {
jstring name = env->GetObjectArrayElement(nameArray, i);
...
}
As you can see, if the number of elements in the stockQuotes array is greater than 512, your application will crash. To resolve this problem, take a look at the body of the for-loop. Each time the loop iterates, the value of the variable quote is used only once, and the previous value becomes unreachable; however, it still stays in the local reference table, as the JVM has no knowledge about the internals of your native method.
To address the problem, you should use the DeleteLocalRef JNI API call to release the local reference once it is known that the local reference won’t be used in the native method. After the necessary change is made, the code looks as shown in Listing 5-13.
Listing 5-13. Native Code Releasing Local References
jsize len = env->GetArrayLength(nameArray);
for (jsize i=0; i < len; i++) {
jstring name = env->GetObjectArrayElement(nameArray, i);
...
env->DeleteLocalRef(name);
}
This code can handle a much larger number of elements without crashing the application, as the local reference table will not overflow.
Java strings are handled by the JNI as reference types. These reference types are not directly usable as native C strings. JNI provides the necessary functions to convert these Java string references to C strings and back, as shown in Listing 5-14.
Listing 5-14. Converting a Java String into a C String
const jbyte* str;
jboolean isCopy;
str = env->GetStringUTFChars(javaString, &isCopy);
if (0 != str) {
/* You can use the string as an ordinary C string. */
}
Once the Java string is converted to a C string, it is simply a pointer to a character array. Because JNI cannot manage that memory allocation automatically anymore, it is the developer’s responsibility to release these character arrays explicitly using the ReleaseString or ReleaseStringUTF functions, as shown inListing 5-15. Otherwise, memory leaks will occur.
Listing 5-15. Releasing the C string
const jbyte* str;
jboolean isCopy;
str = env->GetStringUTFChars(javaString, &isCopy);
if (0 != str) {
/* You can use the string as an ordinary C string. */
env->ReleaseStringUTFChars(javaString, str);
str = 0;
}
Use Proper Memory Management Function
Although the Java programming language has no memory management functions, the C/C++ space has multiple ways of managing the memory. In addition, JNI also introduces its set of functions to manage the lifecycle of references:
- The malloc and free functions are the way to manage memory in C code.
- The new and delete functions are introduced by C++ and are the proper way to manage memory in C++ applications.
- The DeleteLocalRef, DeleteGlobalRef, and other functions are provided by JNI to enable the application to manage the memory of JNI objects in the native space. Any reference that is obtained by JNI should be released using those methods.
In a complex application, because there is no clear way to detect the method used to allocate the memory for a data variable, developers can easily introduce problems in the code by using the wrong pair of memory-management functions. At the very least, it is a good practice to replace malloc and free with new and delete in C++ code.
As described earlier in this chapter, although the primitive data types are mapped directly to native data types, the complex data types are passed as opaque references, and the native code can utilize them through a set of JNI API calls. Because arrays are also part of the complex data types, JNI provides API calls to manipulate Java arrays in native space as well. The main reason for multiple API methods is that each one of them is specifically crafted for different use cases. Using the right API call for the unique needs of your application is a good practice and can improve the performance of your application. Likewise, using the wrong API, or using the right API with carelessly set parameters, can badly impact your application’s overall performance.
Do Not Request Unnecessary Array Elements
In order to keep both the Java code and the native code running in separate silos without impacting each other, JNI does not provide direct access to the actual data. Through the opaque references it provides, JNI enables the native code to interact with the actual data through the designated JNI API functions. This ensures that the communication flows only through the JNI APIs and no other media. In certain scenarios, such as operating on arrays, reaching back from native to Java space for each piece of the data introduces unbearable performance overhead. JNI resolves this problem by duplicating the actual data and letting the native code interact on it as an ordinary native data set. Calling the Get<Type>ArrayElements JNI API produces a full replica of the actual array in native code. Although this sounds like a convenient way of operating on arrays, it comes with a price. When operating on large arrays, the entire array needs to be duplicated for the native code to start working on it. Once the native code is finished operating on the array data, it can invoke the Release<Type>ArrayElements JNI API call to apply the changes back to the Java array and also release its duplicate copy. As indicated earlier, the internals of the native method are fully opaque to JNI, and it will not know which elements of the array were modified in the native code. Therefore, it simply copies back each element to the original Java array. To better understand the consequences, take a look at the example code shown in Listing 5-16.
Listing 5-16. Modifying the Entire Java Array in Native Code
jsize len = env->GetArrayLength(stockQuotesArray); // len = 1000
jint* stockQuotes = env->GetIntArrayElements(stockQuotesArray, 0);
stockQuotes[0] = 1;
stockQuotes[1] = 2;
env->ReleaseIntArrayElements(stockQuotesArray, stockQuotes, 0);
There are two main problems with this code:
- Although the entire 1000 elements were duplicated by the GetIntArrayElements, only the first two elements were accessed by the native code. The remaining 998 elements in this example are simply a waste of CPU cycles and of runtime memory.
- Upon invoking the ReleaseIntArrayElements, JNI starts copying all 1000 elements from the native array back to the Java array, as JNI is unaware that only the first two elements were modified by the native code.
As a good practice, make sure you are requesting only the relevant piece of data from JNI. If your application requires only a subset of the larger array, replace the API calls to the Get<Type>ArrayElements API functions with Get<Type>ArrayRegion. The Get<Type>ArrayRegion JNI API allows you to define the data region, and it duplicates that specific region only. This ensures that only the data that matters will be processed, as shown in Listing 5-17.
Listing 5-17. Modifying a Portion of the Java Array in Native Code
jint stockQuotes[2];
env->GetIntArrayRegion(stockQuotesArray, 0, 2, stockQuotes);
stockQuotes[0] = 1;
stockQuotes[1] = 2;
env->SetIntArrayRegion(stockQuotesArray, 0, 2, stockQuotes);
Prevent Updating Unchanged Arrays
In certain scenarios you would only need to access the Java array to read its values. Although the JNI does not support the concept of read-only data, you can explicitly inform JNI to not to write the values back to the Java array. To do that, use the final parameter of the Release<Type>ArrayElements function, mode;
void Release<Type>ArrayElements(JNIEnv* env, ArrayType array,
NativeType* elements, jint mode );
The mode parameter can take the following values:
- 0: Copy back the content and free the native array.
- JNI_COMMIT: Copy back the content but do not free the native array.
- JNI_ABORT: Free the native array without copying its content.
Most developers simply ignore this parameter by passing 0 to it to trigger the default mode of operation. Instead, it is a good practice to pass the proper mode to the JNI API call depending on the unique use case. If the developer is aware that the data is not going to be modified in the native method, the code should instead pass JNI_ABORT to inform JNI that it can release the native array without copying back its content.
Although minimizing the impact of the array copy by limiting it to a small subset of the larger data can benefit many use cases, there will still be cases where this best practice cannot be applied. For example, developing a multimedia application will require you to operate on large arrays containing data such as high-resolution video frames or multiple channels of audio data. In such situations, you will not be able to limit the boundaries of the data to a small set, as all that will need to be consumed by the native code.
In such scenarios, you can rely on the JNI Native I/O (NIO) API calls. NIO provides improved performance in the areas of buffer management, scalable network and file I/O, and character-set support. JNI provides functions to use the NIO buffers from native code. Compared to array operations, NIO buffers deliver much better performance. NIO does not duplicate the data; it simply provides direct memory access to it. NIO buffers are therefore highly suitable for delivering a vast amount of data between the native code and the Java application.
Assuming the NIO buffer is allocated on the Java space as an instance of the java.nio.ByteBuffer class, you can obtain a direct pointer to its memory by invoking the GetDirectBufferAddress JNI API call, as shown in Listing 5-18.
Listing 5-18. Getting the Direct Pointer to Byte Buffer Memory
unsigned char* buffer;
buffer = (unsigned char*) env->GetDirectBufferAddress(directBuffer);
Operating using NIO buffers is the best practice for data-intensive Android applications that would like to benefit from native code support.
Caching Classes, Method and Field IDs
JNI does not expose the fields and methods of Java classes directly in the native code. Instead, it provides a set of APIs to access them indirectly. For example, to get the value of a field of a class, the following steps will be taken:
- Obtain a reference to the class object, through the FindClass function.
- Obtain the ID for the field that will be accessed, through the GetFieldID function.
- Obtain the actual value of the field by supplying the class instance and the field ID to the Get<Type>Field function.
Although they are used very frequently in JNI applications, both the GetFieldID and GetMethodID functions are very heavy function calls by their nature. As you would imagine, these functions have to traverse through the entire inheritance chain for the class to identify the right ID to return. Because neither the Class object, the Class inheritance, nor the field ID can change during the execution of the application, those values can actually be cached in the native layer for subsequent access with fewer API calls.
The return type of the FindClass function is a local reference. In order to cache that, you will need to create a global reference first through the NewGlobalRef function. On the other hand, the return value of GetFieldID is jfieldID, which is simply an integer, and it can be cached as is.
Tip Although you can improve the performance of JNI functions in accessing Java fields and methods from the native space, the transition between the Java and native code is a costly operation. It is strongly recommended that you take this into the account when deciding where to split the Java and the native code. Minimizing the reach-backs between Java and native code can improve your application’s performance.
As a good practice, you should focus on caching both the field and method IDs for the pieces that are accessed multiple times during the execution of your application.
JNI does not enforce any limitations on the execution model of the native code. Both the Java code and the native code can achieve parallel processing through the use of threads. These threads can be either Java threads or platform threads, like POSIX threads. This flexibility makes it easier to reuse existing native modules as part of a Java application through JNI, as the threading model remains compatible.
Although both threading mechanisms can run simultaneously side by side, there are certain constraints of JNI to keep in mind if you expect your native, non-Java threads to access any of the JNI functions.
Never Cache the JNI Environment Interface Pointer
As indicated earlier in this chapter, local references that are obtained either through method parameters or through JNI API calls cannot be cached and reused outside the execution scope of that native method call.
Moreover, in order to execute any JNI API function, a pointer to the JNI environment interface (JNIEnv) needs to be available to the native code. As with the local references, the JNIEnv interface pointer is also valid only during the execution scope of native method calls, and it cannot be cached and reused.
In order to obtain the proper JNIEnv interface pointer for the current thread, it needs to be attached to the Java VM.
Never Access Java Space from Detached Native Threads
You can attach your non-Java threads to the Java VM through the AttachCurrentThread function of the JavaVM interface. The JavaVM interface pointer can be obtained from a valid JNIEnv interface through the GetJavaVM function call, as shown in Listing 5-19.
Listing 5-19. The GetJavaVM Function Obtaining the JavaVM
static JavaVM* vm = 0;
JNIEXPORT jstring JNICALL Java_com_apress_example_Unix_init(JNIEnv* env, jclass clazz) {
if (0 != env->GetJavaVM( &vm)) {
/* Error occured. */
} else {
/* JavaVM obtained. */
}
}
The obtained JavaVM pointer can be cached and used in native threads. Upon invoking the AttachCurrentThread function using the JavaVM interface from your non-Java thread, the native threads will be added to the Java VM’s list of known threads, and a unique JNIEnv interface pointer for the current thread will be returned, as shown in Listing 5-20.
Listing 5-20. Attaching Current Native Thread to Java VM
void threadWorker() {
JNIEnv* env = 0;
if (0 = (*vm)->AttachCurrentThread(vm, &env, NULL)) {
/* Error occurred. */
} else {
/* JNI API can be accessed using the JNIEnv. */
}
}
Note If the non-Java thread is already attached to the Java VM, subsequent calls won’t have any side effect.
Now using the proper JNIEnv interface pointer you can access the JNI API functions from your non-Java thread. The JNIEnv interface pointer for the thread remains valid until the thread is detached using the DetachCurrentThread function, as shown in Listing 5-21.
Listing 5-21. Detaching the Current Native Thread from Java VM
(*vm)->DetachCurrentThread();
env = 0;
Troubleshooting
Despite the ease of the Java code, debugging the native code can be very complicated. When you are facing the unexpected, having troubleshooting skills becomes a life-saver. Knowing the right tools and techniques enables you to resolve problems rapidly. In this section, you will briefly explore some of the best practices for troubleshooting problems in native code.
In order to deliver high performance at runtime, the JNI functions do very little error checking. Errors usually result in a crash that is hard to troubleshoot. Dalvik VM provides an extended checking mode for JNI calls, known as CheckJNI. When it is enabled, JavaVM and JNIEnv interface pointers are switched to tables of functions that perform an extended level of error checking before calling the actual implementation. CheckJNI can detect the following problems:
- Attempt to allocate a negative-sized array
- Bad or NULL pointers passed to JNI functions’ Syntax errors while passing class names
- Making JNI calls while in critical section
- Bad arguments passed to NewDirectByeBuffer
- Making JNI calls when an exception is pending
- JNIEnv interface pointer used in wrong thread
- Field type and Set<Type>Field function mismatch
- Method type and Call<Type>Method function mismatch, such as DeleteGlobalRef/DeleteLocalRef called with wrong reference type
- Bad release mode passed to Release<Type>ArrayElement function
- Incompatible type returned from native method
- Invalid UTF-8 sequence passed to a JNI call
By default, the CheckJNI mode is enabled only in the emulator, not on the regular Android devices, because of its effect on the overall performance of the system. On a regular device, the CheckJNI mode can be enabled by issuing the following on the command prompt:
adb shell setprop debug.checkjni 1
This won’t affect the running applications, but any application launched afterwards will have CheckJNI enabled. It is a good practice to observe your application running in the CheckJNI mode to spot any problems in your native code before they lead the application into much complicated problems.
Always Check for Java Exceptions
Exception handling is an important aspect of the Java programming language. Exceptions behave differently in the JNI than they do in Java. In Java, when an exception is thrown, the virtual machine stops the execution of the code block and goes through the call stack in reverse order to find an exception handler code block that can handle the specific exception type. This is also called catching an exception. The virtual machine clears the exception and transfers the control to the exception handler block. In contrast, the JNI requires developers to explicitly implement the exception handling flow after an exception has occurred.
You can catch Java exceptions in native code using the JNI API call ExceptionOccurred. This function queries the Java VM for any pending exception, and it returns a local reference to the exception Java object, as shown in Listing 5-22.
Listing 5-22. Catching and Handling Exceptions in Native Code
jthrowable ex;
...
env->CallVoidMethod(instance, throwingMethodId);
ex = env->ExceptionOccurred(env);
if (0 != ex) {
env->ExceptionClear(env);
/* Exception handler. */
}
Failure to do so will not block the execution of your native function; however, any subsequent calls to JNI API will silently fail. This can become very hard to troubleshoot, as the actual exception does not leave any traces behind.
As a good practice, you should always check whether a Java exception has been thrown after invoking any Java methods that may throw an exception.
Upon handling the exception, you should also clear it using the ExceptionClear function to inform the Java VM that the exception is handled and JNI can resume serving requests to Java space.
Always Check JNI Return Values
Exceptions are extensions of the programming language for developers to report and handle exceptional events that require special processing outside the actual flow of the application. Although exceptions have been part of the Java programming language since its very beginning, exception support is not widely available for C/C++ programming language on all platforms. Because JNI is designed to be a universal solution to facilitate integration of native modules into Java applications, it does not use exceptions. The JNI API functions instead rely on their return values to indicate any errors during the execution of the API call, as shown in Listing 5-23.
Listing 5-23. Checking the Return Value of JNI API Calls
jclass clazz;
...
clazz = env->FindClass("java/lang/String");
if (0 == clazz) {
/* Class could not be found. */
} else {
/* Class is found, you can use the return value. */
}
Thus, as a good practice, never assume it is safe to use the return value of a JNI API call as is. Always check the return value to make sure the JNI API call was successfully executed and the proper usable value is returned to your native function.
Always Add Log Lines While Developing
Logging is the most important part of troubleshooting, but it is tricky to achieve, especially on mobile platforms where the development and the execution of the application happen on two different machines. As a good practice, you should always include log messages while developing your application, not when you are trying to troubleshoot a problem, as it will be too late by then. Having proper logging part of your application can help you to troubleshoot problems much easily by simply looking at the log output of your applications. Needless to say, reading and sharing log messages is much easier process than using sophisticated debugger applications to inspect the execution of an application.
Although adding logging into your application is an appealing solution, having an extensive amount of logging will impact the performance of your application, and it will also expose too much about the internal flow of your application to external parties. Although it’s good to have extensive logging during the development and troubleshooting stage, you should strip those components from your application before releasing it. Despite the vast number of logging frameworks that are available in Java space, the options are fairly limited for C/C++ code. In this section, you will fill this gap by building a small logging framework for C/C++ code.
In order to achieve the same functionality that is offered by the advanced logging frameworks, the solution that is presented in this section will be rely heavily on the preprocessor support provided by the native C/C++ compiler. The my_log.h header file that is shown in Listing 5-24 through a set of preprocessor directives, wraps the Android native logging APIs to provide a compile-time control over the intensity of logging.
Listing 5-24. The my_log.h Logging Header File
#pragma once
/**
* Basic logging framework for NDK.
*
* @author Onur Cinar
*/
#include <android/log.h>
#define MY_LOG_LEVEL_VERBOSE 1
#define MY_LOG_LEVEL_DEBUG 2
#define MY_LOG_LEVEL_INFO 3
#define MY_LOG_LEVEL_WARNING 4
#define MY_LOG_LEVEL_ERROR 5
#define MY_LOG_LEVEL_FATAL 6
#define MY_LOG_LEVEL_SILENT 7
#ifndef MY_LOG_TAG
# define MY_LOG_TAG __FILE__
#endif
#ifndef MY_LOG_LEVEL
# define MY_LOG_LEVEL MY_LOG_LEVEL_VERBOSE
#endif
#define MY_LOG_NOOP (void) 0
#define MY_LOG_PRINT(level,fmt,...)
__android_log_print(level, MY_LOG_TAG, "(%s:%u) %s: " fmt,
__FILE__, __LINE__, __PRETTY_FUNCTION__, ##__VA_ARGS__)
#if MY_LOG_LEVEL_VERBOSE >= MY_LOG_LEVEL
# define MY_LOG_VERBOSE(fmt,...)
MY_LOG_PRINT(ANDROID_LOG_VERBOSE, fmt, ##__VA_ARGS__)
#else
# define MY_LOG_VERBOSE(...) MY_LOG_NOOP
#endif
#if MY_LOG_LEVEL_DEBUG >= MY_LOG_LEVEL
# define MY_LOG_DEBUG(fmt,...)
MY_LOG_PRINT(ANDROID_LOG_DEBUG, fmt, ##__VA_ARGS__)
#else
# define MY_LOG_DEBUG(...) MY_LOG_NOOP
#endif
#if MY_LOG_LEVEL_INFO >= MY_LOG_LEVEL
# define MY_LOG_INFO(fmt,...)
MY_LOG_PRINT(ANDROID_LOG_INFO, fmt, ##__VA_ARGS__)
#else
# define MY_LOG_INFO(...) MY_LOG_NOOP
#endif
#if MY_LOG_LEVEL_WARNING >= MY_LOG_LEVEL
# define MY_LOG_WARNING(fmt,...)
MY_LOG_PRINT(ANDROID_LOG_WARN, fmt, ##__VA_ARGS__)
#else
# define MY_LOG_WARNING(...) MY_LOG_NOOP
#endif
#if MY_LOG_LEVEL_ERROR >= MY_LOG_LEVEL
# define MY_LOG_ERROR(fmt,...)
MY_LOG_PRINT(ANDROID_LOG_ERROR, fmt, ##__VA_ARGS__)
#else
# define MY_LOG_ERROR(...) MY_LOG_NOOP
#endif
#if MY_LOG_LEVEL_FATAL >= MY_LOG_LEVEL
# define MY_LOG_FATAL(fmt,...)
MY_LOG_PRINT(ANDROID_LOG_FATAL, fmt, ##__VA_ARGS__)
#else
# define MY_LOG_FATAL(...) MY_LOG_NOOP
#endif
#if MY_LOG_LEVEL_FATAL >= MY_LOG_LEVEL
# define MY_LOG_ASSERT(expression, fmt, ...)
if (!(expression))
{
__android_log_assert(#expression, MY_LOG_TAG,
fmt, ##__VA_ARGS__);
}
#else
# define MY_LOG_ASSERT(...) MY_LOG_NOOP
#endif
In order to use this tiny logging framework, simply include the my_log.h header file:
#include "my_log.h"
This will make the logging macros available to the source code. You can then use them in your native code, as shown in Listing 5-25.
Listing 5-25. Native Code with Logging Macros
...
MY_LOG_VERBOSE("The native method is called.");
MY_LOG_DEBUG("env=%p thiz=%p", env, thiz);
MY_LOG_ASSERT(0 != env, "JNIEnv cannot be NULL.");
...
The tiny logging framework still relies on the Android logging functions. As the last step, you should modify the Android.mk build file as shown in Listing 5-26.
Listing 5-26. Setting the Log Level Through the Build Script
LOCAL_MODULE := module
...
# Define the log tag
MY_LOG_TAG := module
# Define the default logging level based build type
ifeq ($(APP_OPTIM),release)
MY_LOG_LEVEL := MY_LOG_LEVEL_ERROR
else
MY_LOG_LEVEL := MY_LOG_LEVEL_VERBOSE
endif
# Appending the compiler flags
LOCAL_CFLAGS += -DMY_LOG_TAG=$(MY_LOG_TAG)
LOCAL_CFLAGS += -DMY_LOG_LEVEL=$(MY_LOG_LEVEL)
LOCAL_SRC_FILES := module.c
# Dynamically linking with the log library
LOCAL_LDLIBS += -llog
You can always improve this simple logging framework based on the unique requirements of your application. Using a logging framework is a good practice, as it will enable you to control the amount of logging your application will produce, without making any modifications to the source code. Having logging available in advance can save you time while troubleshooting complicated errors in native components.
Native Code Reuse Using Modules
Because C/C++ is more a programming language than a complete framework like Java, you will often rely on third-party libraries to achieve basic operations, such as accessing a URL through the HTTP protocol using the libcurl HTTP client library.
It is always a best practice to keep those third-party modules outside the main code base, so that they can be reused, shared across multiple modules, and updated seamlessly. Starting from version R5, the Android NDK allows sharing and reusing modules between NDK projects.
To resume our previous example, the libcurl third-party module can be shared between multiple NDK projects easily by doing the following:
- Move the shared module to its own location outside any NDK project, such as /home/cinar/shared-modules/libcurl.
Note In order to prevent name conflicts, the directory structure can also include the module’s provider name, such as /home/cinar/shared-modules/haxx/libcurl. The Android NDK build system does not accept the space character in shared module paths.
- Every shared module also required its own Android.mk build file. An example build file is shown in Listing 5-27.
Listing 5-27. Shared Module Android.mk Build File
LOCAL_PATH := $(call my-dir)
#
# LibCURL HTTP client library.
#
include $(CLEAR_VARS)
LOCAL_MODULE := curl
LOCAL_SRC_FILES := curl.c
include $(BUILD_SHARED_LIBRARY) - Now the shared module can be imported in other Android NDK projects using the import-module macro as shown in Listing 5-28. The import-module macro call should be placed at the end of the Android.mk build file to prevent any build system conflicts.
Listing 5-28. Project Importing the Shared Module
#
# Native module
#
include $(CLEAR_VARS)
LOCAL_MODULE := module
LOCAL_SRC_FILES := module.c
LOCAL_SHARED_LIBRARIES := curl
include $(BUILD_SHARED_LIBRARY)
$(call import-module,haxx/libcurl) - The import-module macro must first locate the shared module and then import it into the NDK project. By default, only the <Android NDK>/sources directory is searched by the import-module macro. In order to include the /home/cinar/shared-modules directory into the search, define a new environment variable called NDK_MODULE_PATH and set it to the root directory of shared modules:
export NDK_MODULE_PATH=/home/cinar/shared-modules - Now running the ndk-build script will pull the shared module during the build process.
Maintaining the common modules using this method is a good practice, as it will promote reuse and make it easier to add functionality into your Android NDK project without any additional effort.
Benefit from Compiler Vectorization
The last best practice you will learn in this chapter is compiler vectorization, which improves the performance of your native functions by seamlessly benefiting from the available Single Instruction Multiple Data (SIMD) support in mobile CPUs. SIMD enables data-level parallelism by performing the same operation on multiple data points all at once. It is also known as NEON support on ARM-based processors. Using SIMD support can drastically improve the performance of native functions that are applying the same set of operations to large data sets. For example, multimedia applications can benefit from SIMD greatly as they apply the same set of operations to multiple audio and video frames.
Using the assembly language or the compiler intrinsics is not the only way of benefitting from SIMD support. If the native code is structured in a form that can be parallelized, the compiler can seamlessly inject the necessary instructions to benefit from the SIMD support seamlessly. This process is known as compiler vectorization.
Compiler vectorization is not enabled by default. In order to enable it, please follow these simple steps:
- Open the Application.mk build script and make sure that the APP_ABI contains armeabi-v7a.
APP_ABI := armeabi armeabi-v7a - Open the Android.mk build script for your NDK project, and add the –ftree-vectorize argument to the LOCAL_CFLAGS build system variable as shown in Listing 5-29.
Listing 5-29. Enabling Compiler Vectorization Support
...
LOCAL_MODULE := module
...
LOCAL_CFLAGS += -ftree-vectorize
... - For the compiler vectorization to occur, the native code should also be compiled with ARM NEON support if the target CPU architecture is ARM. In order to do so, update the Android.mk build script file as shown in Listing 5-30.
Listing 5-30. Enabling ARM NEON Support
...
LOCAL_MODULE := module
LOCAL_CFLAGS += -ftree-vectorize
...
# Add ARM NEON support to all source files
ifeq ($(TARGET_ARCH_ABI),armeabi-v7a)
LOCAL_ARM_NEON := true
endif
...
Simply enabling compiler vectorization is not enough. As indicated earlier in this section, the C/C++ language does not provide any mechanism to specify parallelizing behavior. You will have to give the C/C++ compiler additional hints about where it is safe to have the code automatically vectorized. For a list of automatically vectorizable loops, please consult the “Auto-vectorization in GCC” documentation at http://gcc.gnu.org/projects/tree-ssa/vectorization.html.
Tip Getting the loops vectorized is a delicate operation. The C/C++ compiler can provide you with a detailed analysis of the native loops in your native code if you append –ftree-vectorizer-verbose=2 to LOCAL_CFLAGS.
Summary
In this chapter you have learned about some of the best practices to follow while developing native components for your Android applications. By following these simple recommendations you can easily improve the reliability of your native components and you can minimize the time spent troubleshooting problems in the native space. In the next chapter, you will discover some of the best practices in Android security.