
Using JDBC is a popular choice for working with a relational database. Most of Spring’s JDBC support is provided in the spring-jdbc module of the Spring Framework itself. A good guide for this JDBC support is Just Spring Data Access by Madhusudhan Konda [Konda12]. The Spring Data JDBC Extensions subproject of the Spring Data project does, however, provide some additional features that can be quite useful. That’s what we will cover in this chapter. We will look at some recent developments around type-safe querying using Querydsl.
In addition to the Querydsl support, the Spring Data JDBC Extensions subproject contains some database-specific support like connection failover, message queuing, and improved stored procedure support for the Oracle database. These features are limited to the Oracle database and are not of general interest, so we won’t be covering them in this book. The Spring Data JDBC Extensions subproject does come with a detailed reference guide that covers these features if you are interested in exploring them further.
We have been using strings to define database queries in our Java
programs for a long time, and as mentioned earlier this can be quite
error-prone. Column or table names can change. We might add a column or
change the type of an existing one. We are used to doing similar
refactoring for our Java classes in our Java IDEs, and the IDE will guide
us so we can find any references that need changing, including in comments
and configuration files. No such support is available for strings
containing complex SQL query expressions. To avoid this problem, we
provide support for a type-safe query alternative in Querydsl. Many data
access technologies integrate well with Querydsl, and Chapter 3 provided some background on it. In this section we
will focus on the Querydsl SQL module and how it integrates with
Spring’s JdbcTemplate usage, which
should be familiar to every Spring developer.
Before we look at the new JDBC support, however, we need to discuss some general concerns like database configuration and project build system setup.
We are using the HyperSQL database version
2.2.8 for our Querydsl examples in this chapter. One nice
feature of HyperSQL is that we can run the database in both server mode
and in-memory. The in-memory option is great for integration tests since
starting and stopping the database can be controlled by the application
configuration using Spring’s EmbeddedDatabaseBuilder,
or the <jdbc:embedded-database>
tag when using the spring-jdbc XML namespace. The build scripts download the
dependency and start the in-memory database automatically. To use the
database in standalone server mode, we need to download the distribution
and unzip it to a directory on our system. Once that is done, we can
change to the hsqldb directory
of the unzipped distribution and start the database using this
command:
java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:data/test --dbname.0 test
Running this command starts up the server, which generates some log output and a message that the server has started. We are also told we can use Ctrl-C to stop the server. We can now open another command window, and from the same hsqldb directory we can start up a database client so we can interact with the database (creating tables and running queries, etc.). For Windows, we need to execute only the runManagerSwing.bat batch file located in the bin directory. For OS X or Linux, we can run the following command:
java -classpath lib/hsqldb.jar org.hsqldb.util.DatabaseManagerSwing
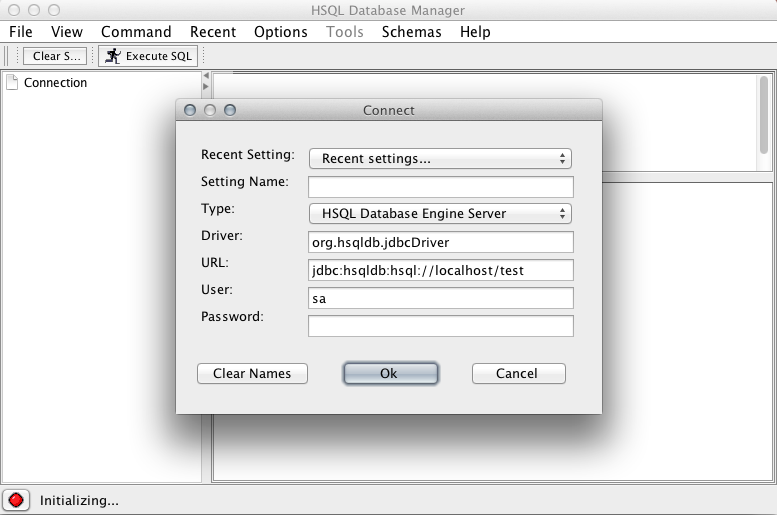
This should bring up the login dialog shown
in Figure 5-1. We need to change the Type
to HSQL Database Engine Server and add “test” as the name of the
database to the URL so it reads
jdbc:hsqldb:hsql://localhost/test. The default user is “sa”
with a blank password. Once connected, we have an active GUI database
client.
The SQL module of Querydsl provides a type-safe option for the Java developer to work with relational databases. Instead of writing SQL queries and embedding them in strings in your Java program, Querydsl generates query types based on metadata from your database tables. You use these generated types to write your queries and perform CRUD operations against the database without having to resort to providing column or table names using strings.
The way you generate the query types is a bit different in the SQL module compared to other Querydsl modules. Instead of relying on annotations, the SQL module relies on the actual database tables and available JDBC metadata for generating the query types. This means that you need to have the tables created and access to a live database before you run the query class generation. For this reason, we recommend running this as a separate step of the build and saving the generated classes as part of the project in the source control system. We need to rerun this step only when we have made some changes to our table structures and before we check in our code. We expect the continuous integration system to run this code generation step as well, so any mismatch between the Java types and the database tables would be detected at build time.
We’ll take a look at what we need to
generate the query types later, but first we need to understand what
they contain and how we use them. They contain information that Querydsl
can use to generate queries, but they also contain information you can
use to compose queries; perform updates, inserts, and deletes; and map
data to domain objects. Let’s take a quick look at an example of a table
to hold address information. The address table has
three VARCHAR columns: street,
city, and country. Example 5-1 shows the SQL statement to create this
table.
Example 5-2
demonstrates the generated query type based on this
address table. It has some constructors, Querydsl
path expressions for the columns, methods to create primary and foreign key types, and a
static field that provides an instance of the QAddress class.
Example 5-2. A generated query type—QAddress
packagecom.oreilly.springdata.jdbc.domain;importstaticcom.mysema.query.types.PathMetadataFactory.*;importcom.mysema.query.types.*;importcom.mysema.query.types.path.*;importjavax.annotation.Generated;/*** QAddress is a Querydsl query type for QAddress*/@Generated("com.mysema.query.sql.codegen.MetaDataSerializer")publicclassQAddressextendscom.mysema.query.sql.RelationalPathBase<QAddress>{privatestaticfinallongserialVersionUID=207732776;publicstaticfinalQAddressaddress=newQAddress("ADDRESS");publicfinalStringPathcity=createString("CITY");publicfinalStringPathcountry=createString("COUNTRY");publicfinalNumberPath<Long>customerId=createNumber("CUSTOMER_ID",Long.class);publicfinalNumberPath<Long>id=createNumber("ID",Long.class);publicfinalStringPathstreet=createString("STREET");publicfinalcom.mysema.query.sql.PrimaryKey<QAddress>sysPk10055=createPrimaryKey(id);publicfinalcom.mysema.query.sql.ForeignKey<QCustomer>addressCustomerRef=createForeignKey(customerId,"ID");publicQAddress(Stringvariable){super(QAddress.class,forVariable(variable),"PUBLIC","ADDRESS");}publicQAddress(Path<?extendsQAddress>entity){super(entity.getType(),entity.getMetadata(),"PUBLIC","ADDRESS");}publicQAddress(PathMetadata<?>metadata){super(QAddress.class,metadata,"PUBLIC","ADDRESS");}}
By creating a reference like this:
QAddressqAddress=QAddress.address;
in our Java code, we can reference the
table and the columns more easily using qAddress instead of resorting to using
string literals.
In Example 5-3, we query for the street, city, and country for any address that has London as the city.
Example 5-3. Using the generated query class
QAddressqAddress=QAddress.address;SQLTemplatesdialect=newHSQLDBTemplates();SQLQueryquery=newSQLQueryImpl(connection,dialect).from(qAddress).where(qAddress.city.eq("London"));List<Address>results=query.list(newQBean<Address>(Address.class,qAddress.street,qAddress.city,qAddress.country));
First, we create a reference to the query
type and an instance of the correct SQLTemplates
for the database we are using, which in our case is HSQLDBTemplates. The
SQLTemplates encapsulate the differences between
databases and are similar to Hibernate’s Dialect.
Next, we create an SQLQuery with the JDBC
javax.sql.Connection and the SQLTemplates as the parameters.
We specify the table we are querying using the
from method, passing in the query type. Next,
we provide the where clause or predicate via the
where method, using the
qAddress reference to specify the criteria that
city should equal London.
Executing the
SQLQuery, we use the
list method, which will return a
List of results. We also provide a mapping
implementation using a QBean, parameterized with
the domain type and a projection consisting of the columns
street, city, and
country.
The result we get back is a
List of Addresses, populated
by the QBean. The QBean is
similar to Spring’s
BeanPropertyRowMapper, and it requires that the domain type follows the
JavaBean style. Alternatively, you can use
a MappingProjection, which is
similar to Spring’s familiar RowMapper in that
you have more control over how the results are mapped to the domain object.
Based on this brief example, let’s summarize the components of Querydsl that we used for our SQL query:
The
SQLQueryImplclass , which will hold the target table or tables along with the predicate or where clause and possibly a join expression if we are querying multiple tablesThe
Predicate, usually in the form of aBooleanExpressionthat lets us specify filters on the resultsThe mapping or results extractor, usually in the form of a
QBeanorMappingProjectionparameterized with one or moreExpressions as the projection
So far, we haven’t integrated with any Spring features, but the rest of the chapter covers this integration. This first example is just intended to introduce the basics of the Querydsl SQL module.
The code for the Querydsl part of this chapter is located in the jdbc module of the sample GitHub project.
Before we can really start using Querydsl in our project, we need to configure our build system so that we can generate the query types. Querydsl provides both Maven and Ant integration, documented in the “Querying SQL” chapter of the Querydsl reference documentation.
In our Maven pom.xml file, we add the plug-in configuration shown in Example 5-4.
Example 5-4. Setting up code generation Maven plug-in
<plugin><groupId>com.mysema.querydsl</groupId><artifactId>querydsl-maven-plugin</artifactId><version>${querydsl.version}</version><configuration><jdbcDriver>org.hsqldb.jdbc.JDBCDriver</jdbcDriver><jdbcUrl>jdbc:hsqldb:hsql://localhost:9001/test</jdbcUrl><jdbcUser>sa</jdbcUser><schemaPattern>PUBLIC</schemaPattern><packageName>com.oreilly.springdata.jdbc.domain</packageName><targetFolder>${project.basedir}/src/generated/java</targetFolder></configuration><dependencies><dependency><groupId>org.hsqldb</groupId><artifactId>hsqldb</artifactId><version>2.2.8</version></dependency><dependency><groupId>ch.qos.logback</groupId><artifactId>logback-classic</artifactId><version>${logback.version}</version></dependency></dependencies></plugin>
We will have to execute this plug-in explicitly using the following Maven command:
mvn com.mysema.querydsl:querydsl-maven-plugin:export
You can set the plug-in to execute as part of the
generate-sources life cycle phase by specifying an
execution goal. We actually do this in the example project, and we also
use a predefined HSQL database just to avoid forcing you to start up a
live database when you build the example project. For real work, though,
you do need to have a database where you can modify the schema and rerun
the Querydsl code generation.
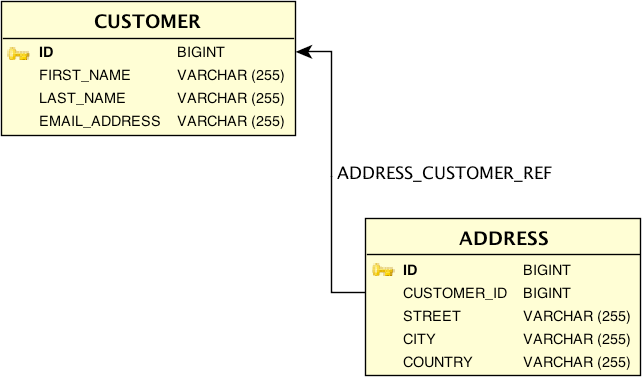
Now that we have the build configured, we can generate the query
classes, but let’s first review the database schema that we will be
using for this section. We already saw the
address table, and we are now adding a
customer table that has a one-to-many
relationship with the address table. We define
the schema for our HSQLDB database as shown in Example 5-5.
Example 5-5. schema.sql
CREATETABLEcustomer(idBIGINTIDENTITYPRIMARYKEY,first_nameVARCHAR(255),last_nameVARCHAR(255),email_addressVARCHAR(255));CREATEUNIQUEINDEXix_customer_emailONCUSTOMER(email_addressASC);CREATETABLEaddress(idBIGINTIDENTITYPRIMARYKEY,customer_idBIGINTCONSTRAINTaddress_customer_refFOREIGNKEYREFERENCEScustomer(id),streetVARCHAR(255),cityVARCHAR(255),countryVARCHAR(255));
The two tables,
customer and address, are
linked by a foreign key reference from address to
customer. We also define a unique index on the
email_address column of the
address table.
This gives us the domain model implementation shown in Figure 5-2.
We have already seen the schema for the database, and now we will
take a look at the corresponding Java domain classes we will be using
for our examples. We need a Customer class plus
an Address class to hold the data from our
database tables. Both of these classes extend an
AbstractEntity class that, in addition to
equals(…) and
hashCode(), has setters and getters for the
id, which is a Long:
publicclassAbstractEntity{privateLongid;publicLonggetId(){returnid;}publicvoidsetId(Longid){this.id=id;}@Overridepublicbooleanequals(Objectobj){…}@OverridepublicinthashCode(){…}}
The Customer class
has name and email information along with a set of addresses. This
implementation is a traditional JavaBean with getters and setters for
all properties:
publicclassCustomerextendsAbstractEntity{privateStringfirstName;privateStringlastName;privateEmailAddressemailAddress;privateSet<Address>addresses=newHashSet<Address>();publicStringgetFirstName(){returnfirstName;}publicvoidsetFirstName(StringfirstName){this.firstName=firstName;}publicStringgetLastName(){returnlastName;}publicvoidsetLastName(StringlastName){this.lastName=lastName;}publicEmailAddressgetEmailAddress(){returnemailAddress;}publicvoidsetEmailAddress(EmailAddressemailAddress){this.emailAddress=emailAddress;}publicSet<Address>getAddresses(){returnCollections.unmodifiableSet(addresses);}publicvoidaddAddress(Addressaddress){this.addresses.add(address);}publicvoidclearAddresses(){this.addresses.clear();}}
The email address is stored as a
VARCHAR column in the database, but in the Java class we
use an EmailAddress value object type that also
provides validation of the email address using a regular expression.
This is the same class that we have seen in the other chapters:
publicclassEmailAddress{privatestaticfinalStringEMAIL_REGEX=…;privatestaticfinalPatternPATTERN=Pattern.compile(EMAIL_REGEX);privateStringvalue;protectedEmailAddress(){}publicEmailAddress(StringemailAddress){Assert.isTrue(isValid(emailAddress),"Invalid email address!");this.value=emailAddress;}publicstaticbooleanisValid(Stringsource){returnPATTERN.matcher(source).matches();}}
The last domain class is the
Address class, again a traditional JavaBean with
setters and getters for the address properties. In addition to the
no-argument constructor, we have a constructor that takes all address
properties:
publicclassAddressextendsAbstractEntity{privateStringstreet,city,country;publicAddress(){}publicAddress(Stringstreet,Stringcity,Stringcountry){this.street=street;this.city=city;this.country=country;}publicStringgetCountry(){returncountry;}publicvoidsetCountry(Stringcountry){this.country=country;}publicStringgetStreet(){returnstreet;}publicvoidsetStreet(Stringstreet){this.street=street;}publicStringgetCity(){returncity;}publicvoidsetCity(Stringcity){this.city=city;}}
The preceding three classes make up our
domain model and reside in the
com.oreilly.springdata.jdbc.domain package of the
JDBC example project. Now we are ready to look at the interface
definition of our CustomerRepository:
publicinterfaceCustomerRepository{CustomerfindById(Longid);List<Customer>findAll();voidsave(Customercustomer);voiddelete(Customercustomer);CustomerfindByEmailAddress(EmailAddressemailAddress);}
We have a couple of finder methods and save
and delete methods. We don’t have any repository methods to save and
delete the Address objects since they are always
owned by the Customer instances. We will have to
persist any addresses provided when the Customer
instance is saved.
The central class in the Spring Data integration with Querydsl is the
QueryDslJdbcTemplate. It is a wrapper around a
standard Spring JdbcTemplate that has methods for
managing SQLQuery instances and executing queries
as well as methods for executing inserts, updates, and deletes using
command-specific callbacks. We’ll cover all of these in this section, but
let’s start by creating a
QueryDslJdbcTemplate.
To configure the
QueryDslJdbcTemplate, you simply pass in either a
DataSource:
QueryDslJdbcTemplateqdslTemplate=newQueryDslJdbcTemplate(dataSource);
or an already configured JdbcTemplate in the
constructor:
jdbcTemplatejdbcTemplate=newJdbcTemplate(dataSource);QueryDslJdbcTemplateqdslTemplate=newQueryDslJdbcTemplate(jdbcTemplate);
Now we have a fully configured
QueryDslJdbcTemplate to use. We saw earlier that
usually you need to provide a Connection and an
SQLTemplates matching your database when you create
an SQLQuery object. However, when you use the
QueryDslJdbcTemplate, there is no need to do this.
In usual Spring fashion, the JDBC layer will manage any database resources
like connections and result sets. It will also take care of providing the
SQLTemplates instance based on database metadata
from the managed connection. To obtain a managed instance of an
SQLQuery, you use the
newSqlQuery static factory method of the
QueryDslJdbcTemplate:
SQLQuerysqlQuery=qdslTemplate.newSqlQuery();
The SQLQuery instance
obtained does not yet have a live connection, so you need to use the query
methods of the QueryDslJdbcTemplate to allow
connection management to take place:
SQLQueryaddressQuery=qdslTemplate.newSqlQuery().from(qAddress).where(qAddress.city.eq("London"));List<Address>results=qdslTemplate.query(addressQuery,BeanPropertyRowMapper.newInstance(Address.class),qAddress.street,qAddress.city,qAddress.country);
There are two query methods:
query returning a List and
queryForObject returning a single result. Both of
these have three overloaded versions, each taking the following
parameters:
The first two mappers, RowMapper and
ResultSetExtractor, are standard Spring interfaces
often used with the regular JdbcTemplate. They are
responsible for extracting the data from the results returned by a query.
The ResultSetExtractor extracts data for all rows returned,
while the RowMapper handles only one row at the time and will
be called repeatedly, once for each row. QBean and
MappingProjection are Querydsl classes that also
map one row at the time. Which ones you use is entirely up to you; they
all work equally well. For most of our examples, we will be using the
Spring types—this book is called Spring Data, after
all.
Now we will look at how we can use the QueryDslJdbcTemplate to
execute queries by examining how we should implement the query methods of
our CustomerRepository.
The implementation will be autowired with a
DataSource; in that setter, we will
create a QueryDslJdbcTemplate and a projection
for the table columns used by all queries when retrieving data needed
for the Customer instances. (See Example 5-6.)
Example 5-6. Setting up the QueryDslCustomerRepository instance
@Repository@TransactionalpublicclassQueryDslCustomerRepositoryimplementsCustomerRepository{privatefinalQCustomerqCustomer=QCustomer.customer;privatefinalQAddressqAddress=QAddress.address;privatefinalQueryDslJdbcTemplatetemplate;privatefinalPath<?>[]customerAddressProjection;@AutowiredpublicQueryDslCustomerRepository(DataSourcedataSource){Assert.notNull(dataSource);this.template=newQueryDslJdbcTemplate(dataSource);this.customerAddressProjection=newPath<?>[]{qCustomer.id,qCustomer.firstName,qCustomer.lastName,qCustomer.emailAddress,qAddress.id,qAddress.customerId,qAddress.street,qAddress.city,qAddress.country};}@Override@Transactional(readOnly=true)publicCustomerfindById(Longid){…}@Override@Transactional(readOnly=true)publicCustomerfindByEmailAddress(EmailAddressemailAddress){…}@Overridepublicvoidsave(finalCustomercustomer){…}@Overridepublicvoiddelete(finalCustomercustomer){…}}
We are writing a repository, so we start
off with an @Repository annotation. This is a
standard Spring stereotype annotation, and it will make your component
discoverable during classpath scanning. In addition, for repositories
that use ORM-style data access technologies, it will also make your
repository a candidate for exception translation between the
ORM-specific exceptions and Spring’s
DataAccessException hierarchy. In our case, we are using a template-based approach, and
the template itself will provide this exception translation.
Next is the
@Transactional annotation. This is also a standard Spring annotation that indicates
that any call to a method in this class should be wrapped in a database
transaction. As long as we provide a transaction manager implementation
as part of our configuration, we don’t need to worry about starting and
completing these transactions in our repository code.
We also define two references to the two
query types that we have generated, QCustomer and
QAddress. The array
customerAddressProjection will hold the Querydsl
Path entries for our queries, one
Path for each column we are retrieving.
The constructor is annotated with
@Autowired, which means that when the repository implementation is
configured, the Spring container will inject the
DataSource that has been defined in the
application context. The rest of the class comprises the methods from
the CustomerRepository that we need to provide
implementations for, so let’s get started.
First, we will implement the findById method
(Example 5-7). The ID we are looking for is
passed in as the only argument. Since this is a read-only method, we can
add a @Transactional(readOnly =
true) annotation to provide a hint that some JDBC drivers
will use to improve transaction handling. It never hurts to provide this
optional attribute for read-only methods even if some JDBC drivers won’t
make use of it.
Example 5-7. Query for single object
@Transactional(readOnly=true)publicCustomerfindById(Longid){SQLQueryfindByIdQuery=template.newSqlQuery().from(qCustomer).leftJoin(qCustomer._addressCustomerRef,qAddress).where(qCustomer.id.eq(id));returntemplate.queryForObject(findByIdQuery,newCustomerExtractor(),customerAddressProjection);}
We start by creating an
SQLQuery instance. We have already mentioned that
when we are using the QueryDslJdbcTemplate, we
need to let the template manage the SQLQuery
instances. That’s why we use the factory method
newSqlQuery() to obtain an instance. The
SQLQuery class provides a fluent interface where
the methods return the instance of the SQLQuery.
This makes it possible to string a number of methods together, which in
turn makes it easier to read the code. We specify the main table we are
querying (the customer table) with the
from method. Then we add a left outer join
against the address table using the
leftJoin(…) method. This will include any
address rows that match the foreign key reference between address and
customer. If there are none, the address columns will be
null in the returned results. If there is more than one
address, we will get multiple rows for each customer, one for each
address row. This is something we will have to handle in our mapping to
the Java objects later on. The last part of the
SQLQuery is specifying the predicate using the
where method and providing the criteria that
the id column should equal the id
parameter.
After we have the
SQLQuery created, we execute our query by calling
the queryForObject method of the
QueryDslJdbcTemplate, passing in the
SQLQuery and a combination of a mapper and a
projection. In our case, that is a
ResultSetExtractor and the
customerAddressProjection that we created earlier.
Remember that we mentioned earlier that since our query contained a
leftJoin, we needed to handle potential
multiple rows per Customer.
Example 5-8 is the
implementation of this CustomerExtractor.
Example 5-8. CustomerExtractor for single object
privatestaticclassCustomerExtractorimplementsResultSetExtractor<Customer>{CustomerListExtractorcustomerListExtractor=newCustomerListExtractor(OneToManyResultSetExtractor.ExpectedResults.ONE_OR_NONE);@OverridepublicCustomerextractData(ResultSetrs)throwsSQLException,DataAccessException{List<Customer>list=customerListExtractor.extractData(rs);returnlist.size()>0?list.get(0):null;}}
As you can see, we use a
CustomerListExtractor that extracts a
List of Customer objects, and we
return the first object in the List if there is
one, or null if the List is
empty. We know that there could not be more than one result since we set
the parameter expectedResults to
OneToManyResultSetExtractor.ExpectedResults.ONE_OR_NONE
in the constructor of the CustomerListExtractor.
Before we look at the
CustomerListExtractor, let’s look at the base class, which is a special implementation named
OneToManyResultSetExtractor that is provided by
the Spring Data JDBC Extension project. Example 5-9
gives an outline of what the
OneToManyResultSetExtractor provides.
Example 5-9. Outline of OneToManyResultSetExtractor for extracting List of objects
publicabstractclassOneToManyResultSetExtractor<R,C,K>implementsResultSetExtractor<List<R>>{publicenumExpectedResults{ANY,ONE_AND_ONLY_ONE,ONE_OR_NONE,AT_LEAST_ONE}protectedfinalExpectedResultsexpectedResults;protectedfinalRowMapper<R>rootMapper;protectedfinalRowMapper<C>childMapper;protectedList<R>results;publicOneToManyResultSetExtractor(RowMapper<R>rootMapper,RowMapper<C>childMapper){this(rootMapper,childMapper,null);}publicOneToManyResultSetExtractor(RowMapper<R>rootMapper,RowMapper<C>childMapper,ExpectedResultsexpectedResults){Assert.notNull(rootMapper);Assert.notNull(childMapper);this.rootMapper=rootMapper;this.childMapper=childMapper;this.expectedResults=expectedResults==null?ExpectedResults.ANY:expectedResults;}publicList<R>extractData(ResultSetrs)throwsSQLException,DataAccessException{…}/*** Map the primary key value to the required type.* This method must be implemented by subclasses.* This method should not call {@link ResultSet#next()}* It is only supposed to map values of the current row.** @param rs the ResultSet* @return the primary key value* @throws SQLException*/protectedabstractKmapPrimaryKey(ResultSetrs)throwsSQLException;/*** Map the foreign key value to the required type.* This method must be implemented by subclasses.* This method should not call {@link ResultSet#next()}.* It is only supposed to map values of the current row.** @param rs the ResultSet* @return the foreign key value* @throws SQLException*/protectedabstractKmapForeignKey(ResultSetrs)throwsSQLException;/*** Add the child object to the root object* This method must be implemented by subclasses.** @param root the Root object* @param child the Child object*/protectedabstractvoidaddChild(Rroot,Cchild);}
This
OneToManyResultSetExtractor extends the ResultSetExtractor,
parameterized with List<T> as the return
type. The method extractData is responsible for
iterating over the ResultSet and extracting row
data. The OneToManyResultSetExtractor has three
abstract methods that must be implemented by subclasses
mapPrimaryKey,
mapForeignKey, and
addChild. These methods are used when iterating
over the result set to identify both the primary key and the foreign key
so we can determine when there is a new root, and to help add the mapped
child objects to the root object.
The
OneToManyResultSetExtractor class also needs
RowMapper implementations to provide the mapping
required for the root and child objects.
Now, let’s move on and look at the actual implementation of the
CustomerListExtractor responsible for extracting
the results of our customer and address results. See Example 5-10.
Example 5-10. CustomerListExtractor implementation for extracting List of objects
privatestaticclassCustomerListExtractorextendsOneToManyResultSetExtractor<Customer,Address,Integer>{privatestaticfinalQCustomerqCustomer=QCustomer.customer;privatefinalQAddressqAddress=QAddress.address;publicCustomerListExtractor(){super(newCustomerMapper(),newAddressMapper());}publicCustomerListExtractor(ExpectedResultsexpectedResults){super(newCustomerMapper(),newAddressMapper(),expectedResults);}@OverrideprotectedIntegermapPrimaryKey(ResultSetrs)throwsSQLException{returnrs.getInt(qCustomer.id.toString());}@OverrideprotectedIntegermapForeignKey(ResultSetrs)throwsSQLException{StringcolumnName=qAddress.addressCustomerRef.getLocalColumns().get(0).toString();if(rs.getObject(columnName)!=null){returnrs.getInt(columnName);}else{returnnull;}}@OverrideprotectedvoidaddChild(Customerroot,Addresschild){root.addAddress(child);}}
The
CustomerListExtractor extends this
OneToManyResultSetExtractor, calling the superconstructor passing in the needed
mappers for the Customer class,
CustomerMapper (which is the root of the
one-to-many relationship), and the mapper for the
Address class,
AddressMapper (which is the child of the same
one-to-many relationship).
In addition to these two mappers, we need
to provide implementations for the
mapPrimaryKey,
mapForeignKey, and
addChild methods of the abstract
OneToManyResultSetExtractor class.
Next, we will take a look at the
RowMapper implementations we are using.
The RowMapper
implementations we are using are just what you would use with the regular
JdbcTemplate. They implement a method named
mapRow with a ResultSet
and the row number as parameters. The only difference with using a QueryDslJdbcTemplate is
that instead of accessing the columns with string literals, you use the
query types to reference the column labels. In the
CustomerRepository, we provide a static method
for extracting this label via the toString
method of the Path:
privatestaticStringcolumnLabel(Path<?>path){returnpath.toString();}
Since we implement the
RowMappers as static inner classes, they
have access to this private static method.
First, let’s look at the mapper for the
Customer object. As you can see in Example 5-11, we reference columns specified in the
qCustomer reference to the
QCustomer query type.
Example 5-11. Root RowMapper implementation for Customer
privatestaticclassCustomerMapperimplementsRowMapper<Customer>{privatestaticfinalQCustomerqCustomer=QCustomer.customer;@OverridepublicCustomermapRow(ResultSetrs,introwNum)throwsSQLException{Customerc=newCustomer();c.setId(rs.getLong(columnLabel(qCustomer.id)));c.setFirstName(rs.getString(columnLabel(qCustomer.firstName)));c.setLastName(rs.getString(columnLabel(qCustomer.lastName)));if(rs.getString(columnLabel(qCustomer.emailAddress))!=null){c.setEmailAddress(newEmailAddress(rs.getString(columnLabel(qCustomer.emailAddress))));}returnc;}}
Next, we look at the mapper for the
Address objects, using a
qAddress reference to the
QAddress query type (Example 5-12).
Example 5-12. Child RowMapper implementation for Address
privatestaticclassAddressMapperimplementsRowMapper<Address>{privatefinalQAddressqAddress=QAddress.address;@OverridepublicAddressmapRow(ResultSetrs,introwNum)throwsSQLException{Stringstreet=rs.getString(columnLabel(qAddress.street));Stringcity=rs.getString(columnLabel(qAddress.city));Stringcountry=rs.getString(columnLabel(qAddress.country));Addressa=newAddress(street,city,country);a.setId(rs.getLong(columnLabel(qAddress.id)));returna;}}
Since the Address
class has setters for all properties, we could have used a standard
Spring BeanPropertyRowMapper
instead of providing a custom implementation.
When it comes to querying for a list of objects, the process is exactly the
same as for querying for a single object except that you now can use the
CustomerListExtractor directly without having to
wrap it and get the first object of the List. See
Example 5-13.
We create an
SQLQuery using the
from(…) and leftJoin(…)
methods, but this time we don’t provide a predicate since we want all
customers returned. When we execute this query, we use the
CustomerListExtractor directly and the same
customerAddressProjection that we used earlier.
We will finish the CustomerRepository
implementation by adding some insert, update, and delete capabilities in
addition to the query features we just discussed. With Querydsl, data is
manipulated via operation-specific clauses like
SQLInsertClause,
SQLUpdateClause, and
SQLDeleteClause. We will cover how to use them with
the QueryDslJdbcTemplate in this section.
When you want to insert some data into the
database, Querydsl provides the
SQLInsertClause class. Depending on whether your
tables autogenerate the key or you provide the key explicitly, there are
two different execute(…) methods. For the case
where the keys are autogenerated, you would use the
executeWithKey(…) method. This method will
return the generated key so you can set that on your domain object. When
you provide the key, you instead use the
execute method, which returns the number of
affected rows. The QueryDslJdbcTemplate has
two corresponding methods:
insertWithKey(…) and
insert(…).
We are using autogenerated keys, so we will
be using the insertWithKey(…) method for our
inserts, as shown in Example 5-14. The
insertWithKey(…) method takes a reference to
the query type and a callback of type
SqlInsertWithKeyCallback parameterized with the
type of the generated key. The
SqlInsertWithKeyCallback callback interface has a single method named
doInSqlInsertWithKeyClause(…). This method has
the SQLInsertClause as its parameter. We need to
set the values using this SQLInsertClause and
then call executeWithKey(…). The key that gets
returned from this call is the return value of the
doInSqlInsertWithKeyClause.
Example 5-14. Inserting an object
LonggeneratedKey=qdslTemplate.insertWithKey(qCustomer,newSqlInsertWithKeyCallback<Long>(){@OverridepublicLongdoInSqlInsertWithKeyClause(SQLInsertClauseinsert)throwsSQLException{EmailAddressemailAddress=customer.getEmailAddress();StringemailAddressString=emailAddress==null?null:emailAddress.toString();returninsert.columns(qCustomer.firstName,qCustomer.lastName,qCustomer.emailAddress).values(customer.getFirstName(),customer.getLastName(),emailAddress);.executeWithKey(qCustomer.id);}});customer.setId(generatedKey);
Performing an update operation is very similar to the insert except that
we don’t have to worry about generated keys. The method on the
QueryDslJdbcTemplate is called update, and it expects a reference to
the query type and a callback of type
SqlUpdateCallback. The
SqlUpdateCallback has the single method
doInSqlUpdateClause(…) with the
SQLUpdateClause as the only parameter. After
setting the values for the update and specifying the where clause, we
call execute on the
SQLUpdateClause, which returns an update count.
This update count is also the value we need to return from this
callback. See Example 5-15.
Example 5-15. Updating an object
qdslTemplate.update(qCustomer,newSqlUpdateCallback(){@OverridepubliclongdoInSqlUpdateClause(SQLUpdateClauseupdate){EmailAddressemailAddress=customer.getEmailAddress();StringemailAddressString=emailAddress==null?null:emailAddress.toString();returnupdate.where(qCustomer.id.eq(customer.getId())).set(qCustomer.firstName,customer.getFirstName()).set(qCustomer.lastName,customer.getLastName()).set(qCustomer.emailAddress,emailAddressString).execute();}});
Deleting is even simpler than updating. The QueryDslJdbcTemplate method you
use is called delete, and it expects a
reference to the query type and a callback of type SqlDeleteCallback. The
SqlDeleteCallback has the single method
doInSqlDeleteClause with the
SQLDeleteClause as the only parameter. There’s no
need to set any values here—just provide the where clause and call
execute. See Example 5-16.