
This chapter introduces an interesting kind of NoSQL store: graph databases. Graph databases are clearly post-relational data stores, because they evolve several database concepts much further while keeping other attributes. They provide the means of storing semistructured but highly connected data efficiently and allow us to query and traverse the linked data at a very high speed.
Graph data consists of nodes connected with directed and labeled relationships. In property graphs, both nodes and relationships can hold arbitrary key/value pairs. Graphs form an intricate network of those elements and encourage us to model domain and real-world data close to the original structure. Unlike relational databases, which rely on fixed schemas to model data, graph databases are schema-free and put no constraints onto the data structure. Relationships can be added and changed easily, because they are not part of a schema but rather part of the actual data.
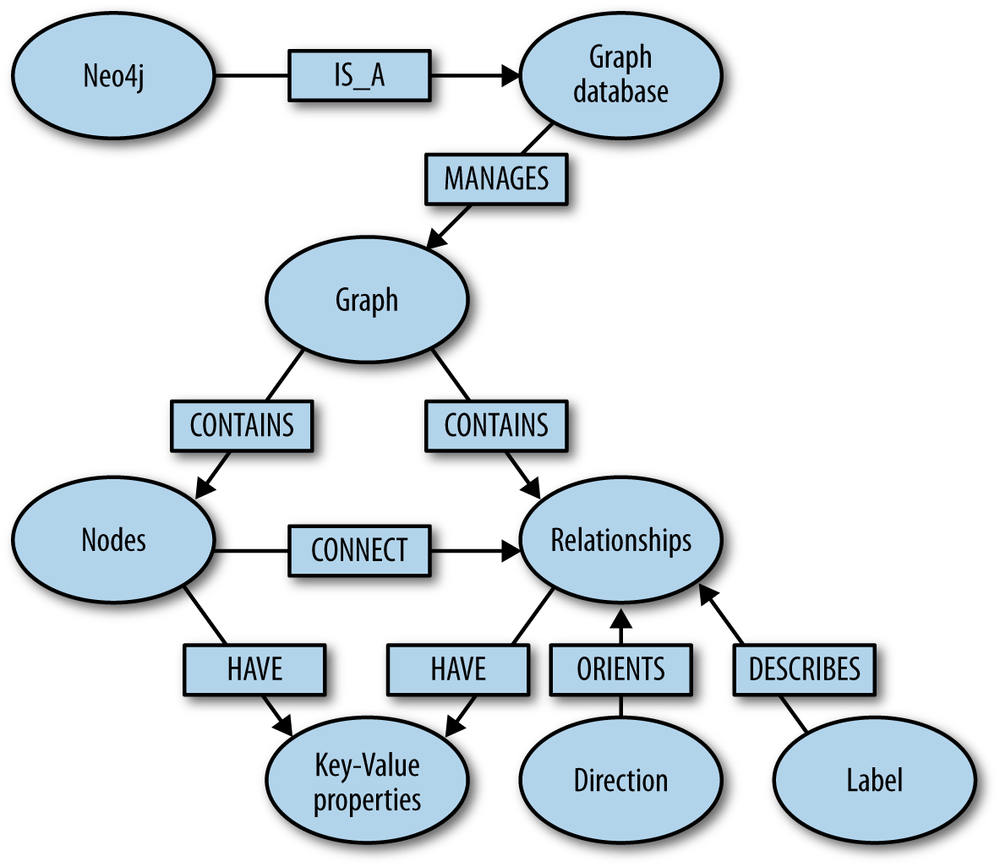
We can attribute the high performance of graph databases to the fact that moving the cost of relating entities (joins) to the insertion time—by materializing the relationships as first-level citizens of the data structure—allows for constant time traversal from one entity (node) to another. So, regardless of the dataset size, the time for a given traversal across the graph is always determined by the number of hops in that traversal, not the number of nodes and relationships in the graph as a whole. In other database models, the cost of finding connections between two (or more) entities occurs on each query instead.
Thanks to this, a single graph can store many different domains, creating interesting connections between entities from all of them. Secondary access or index structures can be integrated into the graph to allow special grouping or access paths to a number of nodes or subgraphs.
Due to the nature of graph databases, they don’t rely on aggregate bounds to manage atomic operations but instead build on the well-established transactional guarantees of an ACID (atomicity, consistency, isolation, durability) data store.
Neo4j is the leading implementation of a property graph database. It is written predominantly in Java and leverages a custom storage format and the facilities of the Java Transaction Architecture (JTA) to provide XA transactions. The Java API offers an object-oriented way of working with the nodes and relationships of the graph (show in the example). Traversals are expressed with a fluent API. Being a graph database, Neo4j offers a number of graph algorithms like shortest path, Dijkstra, or A* out of the box.
Neo4j integrates a transactional, pluggable
indexing subsystem that uses Lucene as
the default. The index is used primarily to locate starting points for
traversals. Its second use is to support unique entity creation. To start
using Neo4j’s embedded Java database, add the
org.neo4j:neo4j:<version> dependency to your build
setup, and you’re ready to go. Example 7-1
lists the code for creating nodes and relationships with properties within
transactional bounds. It shows how to access and read them later.
Example 7-1. Neo4j Core API Demonstration
GraphDatabaseServicegdb=newEmbeddedGraphDatabase("path/to/database");Transactiontx=gdb.beginTx();try{Nodedave=gdb.createNode();dave.setProperty("email","[email protected]");gdb.index().forNodes("Customer").add(dave,"email",dave.getProperty("email");NodeiPad=gdb.createNode();iPad.setProperty("name","Apple iPad");Relationshiprel=dave.createRelationshipTo(iPad,Types.RATED);rel.setProperty("stars",5);tx.success();}finally{tx.finish();}// to access the dataNodedave=gdb.index().forNodes("Customer").get("email","[email protected]").getSingle();for(Relationshiprating:dave.getRelationships(Direction.OUTGOING,Types.RATED)){aggregate(rating.getEndNode(),rating.getProperty("stars"));}
With the declarative Cypher query language, Neo4j makes it easier to get started for everyone who knows SQL from working with relational databases. Developers as well as operations and business users can run ad-hoc queries on the graph for a variety of use cases. Cypher draws its inspiration from a variety of sources: SQL, SparQL, ASCII-Art, and functional programming. The core concept is that the user describes the patterns to be matched in the graph and supplies starting points. The database engine then efficiently matches the given patterns across the graph, enabling users to define sophisticated queries like “find me all the customers who have friends who have recently bought similar products.” Like other query languages, it supports filtering, grouping, and paging. Cypher allows easy creation, deletion, update, and graph construction.
The Cypher statement in Example 7-2 shows a typical use case. It starts by looking up a customer from an index and then following relationships via his orders to the products he ordered. Filtering out older orders, the query then calculates the top 20 largest volumes he purchased by product.
Example 7-2. Sample Cypher statement
START customer=node:Customer(email = "[email protected]") MATCH customer-[:ORDERED]->order-[item:LINEITEM]->product WHERE order.date > 20120101 RETURN product.name, sum(item.amount) AS product ORDER BY products DESC LIMIT 20
Being written in Java, Neo4j is easily embeddable in any Java application which refers to single-instance deployments. However, many deployments of Neo4j use the standalone Neo4j server, which offers a convenient HTTP API for easy interaction as well as a comprehensive web interface for administration, exploration, visualization, and monitoring purposes. The Neo4j server is a simple download, and can be uncompressed and started directly.
It is possible to run the Neo4j server on top of an embedded database, which allows easy access to the web interface for inspection and monitoring (Figure 7-2).
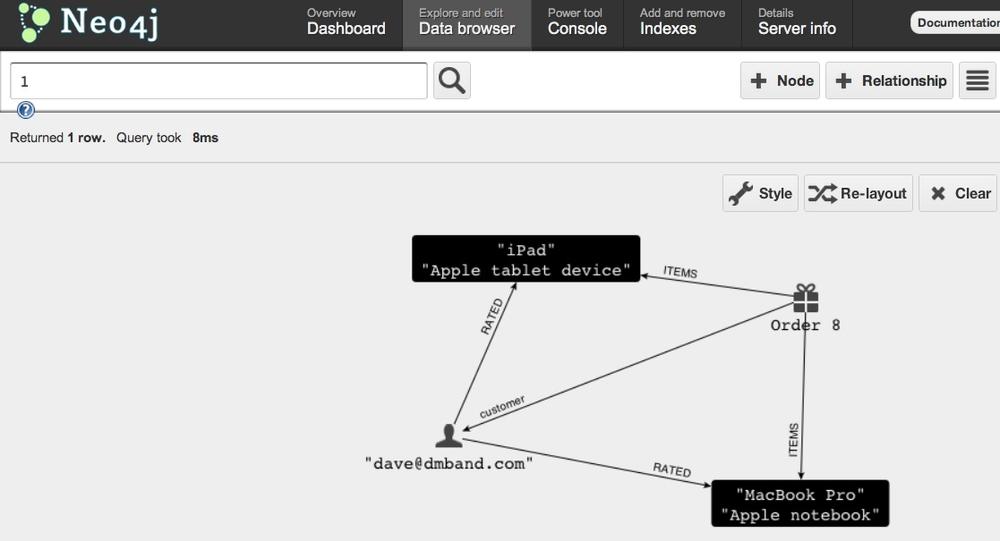
In the web interface, you can see statistics about your database. In the data browser, you can find nodes by ID, with index lookups, and with cypher queries (click the little blue question mark for syntax help), and switch to the graph visualizer with the right-hand button to explore your graph visually (as shown in Figure 7-2). The console allows you to enter Cypher statements directly or even issue HTTP requests. Server Info lists JMX beans, which, especially in the Enterprise edition, come with much more information.
As an open source product, Neo4j has a very rich and active ecosystem of contributors, community members, and users. Neo Technology, the company sponsoring the development of Neo4j, makes sure that the open source licensing (GPL) for the community edition, as well as the professional support for the enterprise editions, promote the continuous development of the product.
To access Neo4j, you have a variety of drivers available, most of them being maintained by the community. There are libraries for many programming languages for both the embedded and the server deployment mode. Some are maintained by the Neo4j team, Spring Data Neo4j being one of them.
Spring Data Neo4j was the original Spring Data project initiated by Rod Johnson and Emil Eifrem. It was developed in close collaboration with VMware and Neo Technology and offers Spring developers an easy and familiar way to interact with Neo4j. It intends to leverage the well-known annotation-based programming models with a tight integration in the Spring Framework ecosystem. As part of the Spring Data project, Spring Data Neo4j integrates both Spring Data Commons repositories (see Chapter 2) as well as other common infrastructures.
As in JPA, a few annotations on POJO (plain
old Java object) entities and their fields provide the necessary
metainformation for Spring Data Neo4j to map Java objects into graph elements. There are annotations for
entities being backed by nodes (@NodeEntity) or relationships (@RelationshipEntity). Field
annotations declare relationships to other entities (@RelatedTo), custom conversions,
automatic indexing (@Indexed), or computed/derived
values (@Query). Spring Data Neo4j allows us to
store the type information (hierarchy) of the entities for performing
advanced operations and type conversions. See Example 7-3.
Example 7-3. An annotated domain class
@NodeEntitypublicclassCustomer{@GraphIdLongid;StringfirstName,lastName;@Indexed(unique=true)StringemailAddress;@RelatedTo(type="ADDRESS")Set<Address>addresses=newHashSet<Address>();}
The core infrastructure of Spring Data Neo4j
is the Neo4jTemplate, which offers (similar to
other template implementations) a variety of lower-level functionality
that encapsulates the Neo4j API to support mapped domain objects. The
Spring Data Neo4j infrastructure and the repository implementation uses
the Neo4jTemplate for its operations. Like the other Spring
Data projects, Spring Data Neo4j is configured via two XML namespace elements—for general setup and repository
configuration.
To tailor Neo4j to individual use cases, Spring Data Neo4j supports both the embedded mode of Neo4j as well as the server deployment, where the latter is accessed via Neo4j’s Java-REST binding. Two different mapping modes support the custom needs of developers. In the simple mapping mode, the graph data is copied into domain objects, being detached from the graph. The more advanced mapping mode leverages AspectJ to provide a live, connected representation of the graph elements bound to the domain objects.
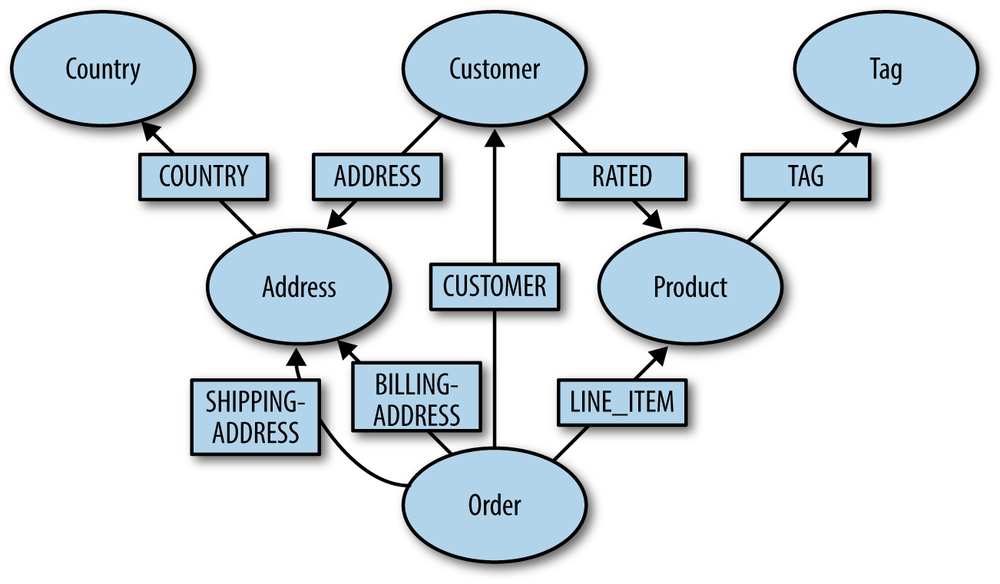
The domain model described in Chapter 1 is already a good fit for a graph database like Neo4j (see Figure 7-3). To allow some more advanced graph operations, we’re going to normalize it further and add some additional relationships to enrich the model.
The code samples listed here are not complete but contain the necessary information for understanding the mapping concepts. See the Neo4j project in the sample source-repository for a more complete picture.
In Example 7-4, the
AbstractEntity as a superclass was kept with the same id field
(which got a @GraphId annotation and
equals(…) and hashCode() methods, as previously
discussed). Annotating the id is required in the simple
mapping mode, as it is the only way to keep the node or relationship
id stored in the entity. Entities can be be loaded
by their id with
Neo4jTemplate.findOne(), and a similar method exists in the GraphRepository.
The simplest mapped class is just marked with
@NodeEntity to make it known to Spring Data Neo4j’s mapping infrastructure. It
can contain any number of primitive fields, which will be treated as node
properties. Primitive types are mapped directly. Types not supported by
Neo4j can be converted to equivalent primitive representations by supplied
Spring converters. Converters for Enum and Date
fields come with the library.
In Country, both fields are just simple strings, as
shown in Example 7-5. The code field
represents a unique “business” key and is marked as
@Indexed(unique=true) which causes the built-in facilities for unique indexes to be
used; these are exposed via Neo4jTemplate.getOrCreateNode().
There are several methods in the Neo4jTemplate to
access the Neo4j indexes; we can find entities by their indexed keys
with Neo4jTemplate.lookup().
Example 7-5. Country as a simple entity
@NodeEntitypublicclassCountryextendsAbstractEntity{@Indexed(unique=true)Stringcode;Stringname;}
Customers are stored as nodes; their unique key is the
emailAddress. Here we meet the first references to other
objects (in this case, Address), which are represented as
relationships in the graph. So fields of single references or collections
of references always cause relationships to be created when updated, or
navigated when accessed.
As shown in Example 7-6,
reference fields can be annotated with @RelatedTo, to
document the fact that they are reference fields or set
custom attributes like the relationship type (in this case,
"ADDRESS"). If we do not provide the type, it defaults to the
field name. The relationship points by default to the referred object
(Direction.OUTGOING), the opposite direction can be specified
in the annotation; this is especially important for bidirectional
references, which should be mapped to just a single relationship.
Example 7-6. Customer has relationships to his addresses
@NodeEntitypublicclassCustomerextendsAbstractEntity{privateStringfirstName,lastName;@Indexed(unique=true)privateStringemailAddress;@RelatedTo(type="ADDRESS")privateSet<Address>addresses=newHashSet<Address>();}
The Address is pretty simple again. Example 7-7 shows how the country reference
field doesn’t have to be annotated—it just uses the field name as the
relationship type for the outgoing relationship. The customers connected
to this address are not represented in the mapping because they are not
necessary for our use case.
Example 7-7. Address connected to country
@NodeEntitypublicclassAddressextendsAbstractEntity{privateStringstreet,city;privateCountrycountry;}
The Product has a unique name and shows the use of a
nonprimitive field; the price will be converted to a primitive
representation by Springs’ converter facilities. You can register your own
converters for custom types (e.g., value objects) in your application context.
The description field will be indexed by an index that allows
full-text search. We have to name the index explicitly, as it uses a
different configuration than the default, exact index. You can then find
the products by calling, for instance,
neo4jTemplate.lookup("search","description:Mac*"), which
takes a Lucene query string.
To enable interesting graph operations, we added a Tag
entity and relate to it from the Product. These tags can be
used to find similar products, provide recommendations, or analyze buying
behavior.
To handle dynamic attributes of an entity (a map of arbitrary
key/values), there is a special support class in Spring Data Neo4j. We
decided against handling maps directly because they come with a lot of
additional semantics that don’t fit in the context. Currently,
DynamicProperties are converted into properties of the node with prefixed names
for separation. (See Example 7-8.)
Example 7-8. Tagged product with custom dynamic attributes
@NodeEntitypublicclassProductextendsAbstractEntity{@Indexed(unique=true)privateStringname;@Indexed(indexType=IndexType.FULLTEXT,indexName="search")privateStringdescription;privateBigDecimalprice;@RelatedToprivateSet<Tag>tags=newHashSet<Tag>();privateDynamicPropertiesattributes=newPrefixedDynamicProperties("attributes");}
The only unusual thing about the Tag is the
Object value property. This property is converted according
to the runtime value into a primitive value that can be stored by Neo4j.
The @GraphProperty annotation, as shown in Example 7-9, allows some customization of the storage (e.g., the used
property name or a specification of the primitive target type in the
graph).
Example 7-9. A simple Tag
@NodeEntitypublicclassTagextendsAbstractEntity{@Indexed(unique=true)Stringname;@GraphPropertyObjectvalue;}
The first @RelationshipEntity we encounter is something
new that didn’t exist in the original domain model but which is
nonetheless well known from any website. To allow for some more
interesting graph operations we add a Rating relationship
between a Customer and a Product. This entity is
annotated with @RelationshipEntity to mark it as such. Besides two simple fields holding the
rating stars and a comment, we can
see that it contains fields for the actual start and end of the
relationship, which are annotated appropriately (Example 7-10).
Example 7-10. A Rating between Customer and Product
@RelationshipEntity(type="RATED")publicclassRatingextendsAbstractEntity{@StartNodeCustomercustomer;@EndNodeProductproduct;intstars;Stringcomment;}
Relationship entities can be created as normal POJO classes,
supplied with their start and endpoints, and saved via
Neo4jTemplate.save(). In Example 7-11, we show with the Order how these entities
can be retrieved as part of the mapping. In the more in-depth discussion
of graph operations—see Leverage Similar Interests (Collaborative Filtering)—we’ll see
how to leverage those relationships in Cypher queries with
Neo4jTemplate.query or repository finder methods.
The Order is the most connected entity so far; it sits
in the middle of our domain. In Example 7-11, the
relationship to the Customer shows the inverse
Direction.INCOMING for a bidirectional reference that shares
the same relationship.
The easiest way to model the different types of addresses (shipping and billing) is to use different relationship types—in this case, we just rely on the different field names. Please note that a single address object/node can be used in multiple places for example, as both the shipping and billing address of a single customer, or even across customers (e.g., for a family). In practice, a graph is often much more normalized than a relational database, and the removal of duplication actually offers multiple benefits both in terms of storage and the ability to run more interesting queries.
Example 7-11. Order, the centerpiece of the domain
@NodeEntitypublicclassOrderextendsAbstractEntity{@RelatedTo(type="ORDERED",direction=Direction.INCOMING)privateCustomercustomer;@RelatedToprivateAddressbillingAddress;@RelatedToprivateAddressshippingAddress;@Fetch@RelatedToViaprivateSet<LineItem>lineItems=newHashSet<LineItem>();}
The LineItems are not modeled as nodes but rather as
relationships between Order and Product. A
LineItem has no identity of its own and just exists as
long as both its endpoints exist, which it refers to via its
order and product fields. In this model,
LineItem only contains the quantity
attribute, but in other use cases, it can also contain different
attributes.
The interesting pieces in Order and
LineItem are the @RelatedToVia annotation
and @Fetch, which is discussed shortly. The annotation on the
lineItems field is similar to @RelatedTo in
that it applies only to references to relationship entities.
It is possible to specify a custom relationship type or direction. The
type would override the one provided in the @RelationshipEntity (see Example 7-12).
Example 7-12. A LineItem is just a relationship
@RelationshipEntity(type="ITEMS")publicclassLineItemextendsAbstractEntity{@StartNodeprivateOrderorder;@Fetch@EndNodeprivateProductproduct;privateintamount;}
This takes us to one important aspect of object-graph mapping: fetch declarations. As we know from JPA, this can be tricky. For now we’ve kept things simple in Spring Data Neo4j by not fetching related entities by default.
Because the simple mapping mode needs to copy data out of the graph
into objects, it must be careful about the fetch depth; otherwise you can
easily end up with the whole graph pulled into memory, as graph structures
are often cyclic. That’s why the default strategy is to load related
entities only in a shallow way. The @Fetch annotation
is used to declare fields to be loaded eagerly and fully. We
can load them after the fact by template.fetch(entity.field).
This applies both to single relationships (one-to-one) and
multi-relationship fields (one-to-many).
In the Order, the LineItems are fetched by
default, becuse they are important in most cases when an order is loaded.
For the LineItem itself, the Product is eagerly
fetched so it is directly available. Depending on your use case, you would
model it differently.
Now that we have created the domain classes, it’s time to store their data in the graph.
Before we can start storing domain objects in the graph, we should set
up the project. In addition to your usual Spring dependencies, you need
either
org.springframework.data:spring-data-neo4j:2.1.0.RELEASE (for
simple mapping) or
org.springframework.data:spring-data-neo4j-aspects:2.1.0.RELEASE
(for advanced AspectJ-based mapping (see Advanced Mapping Mode) as a dependency. Neo4j is pulled in
automatically (for simplicity, assuming the embedded Neo4j
deployment).
The minimal Spring configuration is a single namespace config that also sets up the graph database (Example 7-13).
Example 7-13. Spring configuration setup
<?xml version="1.0" encoding="UTF-8"?><beansxmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:neo4j="http://www.springframework.org/schema/data/neo4j"xsi:schemaLocation="http://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans.xsdhttp://www.springframework.org/schema/data/neo4jhttp://www.springframework.org/schema/data/neo4j/spring-neo4j.xsd"><neo4j:configstoreDirectory="target/graph.db"/><neo4j:repositoriesbase-package="com.oreilly.springdata.neo4j"/></beans>
As shown in Example 7-14, we can also
pass a graphDatabaseService instance to neo4j:config, in order to configure the
graph database in terms of caching, memory usage, or upgrade policies.
This even allows you to use an in-memory
ImpermanentGraphDatabase for testing.
Example 7-14. Passing a graphDatabaseService to the configuration
<neo4j:configgraphDatabaseService="graphDatabaseService"/><beanid="graphDatabaseService"class="org.neo4j.test.ImpermanentGraphDatabase"/><!-- or --><beanid="graphDatabaseService"class="org.neo4j.kernel.EmbeddedGraphDatabase"destroy-method="shutdown"><constructor-argvalue="target/graph.db"/><constructor-arg><!-- passing configuration properties --><map><entrykey="allow_store_upgrade"value="true"/></map></constructor-arg></bean>
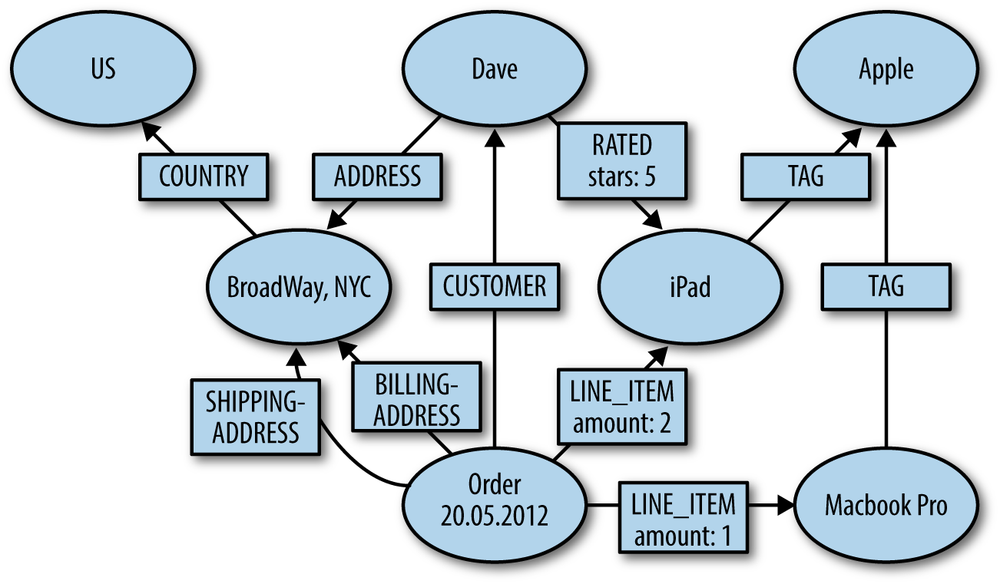
After defining the domain objects and the
setup, we can pretty easily generate the sample dataset that will be used
to illustrate some use cases (see Example 7-15
and Figure 7-4). Both the domain classes, as
well as the dataset generation and integration tests documenting the use
cases, can be found in the GitHub repository for the book (see The Sample Code for details). To import the data, we
can simply populate domain classes and use
template.save(entity), which either merges the entity with
the existing element in the graph or creates a new one. That depends on
mapped IDs and possibly unique field declarations, which would be used to
identify existing entities in the graph with which we're merging.
Example 7-15. Populating the graph with the sample dataset
Customerdave=template.save(newCustomer("Dave","Matthews","[email protected]"));template.save(newCustomer("Carter","Beauford","[email protected]"));template.save(newCustomer("Boyd","Tinsley","[email protected]"));Countryusa=template.save(newCountry("US","United States"));template.save(newAddress("27 Broadway","New York",usa));ProductiPad=template.save(newProduct("iPad","Apple tablet device").withPrice(499));Productmbp=template.save(newProduct("MacBook Pro","Apple notebook").withPrice(1299));template.save(newOrder(dave).withItem(iPad,2).withItem(mbp,1));
The entities shown here use some convenience methods for construction to provide a more readable setup (Figure 7-4).
The Neo4jTemplate is like other Spring templates: a convenience API over a
lower-level one, in this case the Neo4j API. It adds the usual benefits,
like transaction handling and exception translation, but more
importantly, automatic mapping from and to domain entities. The
Neo4jTemplate is used in the other infrastructural parts of Spring Data
Neo4j. Set it up by adding the <neo4j:config/>
declaration to your application context or by creating a
new instance, which is passed a Neo4j GraphDatabaseService
(which is available as a Spring bean and can be injected into your
code if you want to access the Neo4j API directly).
The operations for creating entities, nodes, and relationships and
finding or removing them by id comprise the
basics (save(),
getOrCreateNode(), findOne(),
getNode(), getRelationshipsBetween(), etc.).
Most of the other mechanisms deal with more advanced ways to look up
interesting things in the graph—by issuing index queries with
lookup, executing Cypher statements with query(), or running a traversal with traverse(). The
Neo4jTemplate offers methods to convert nodes into entities
with load(), or one entity into a different type with projectTo() (see Multiple Roles for a Single Node). Lazily loaded entities can be loaded
fully via fetch().
You can achieve most of what you want to do with Spring Data Neo4j
with the Neo4jTemplate alone, but the repository support
adds a much more convenient way to perform many operations.
With all that set up, we can now look into how repositories integrate with Spring Data Neo4j and how they are used in a “graphy” way.
Spring Data Commons repositories (see Chapter 2) make it easy to keep persistence access related
code (or rather noncode) in one place and allow us to write as little of
it as possible to satisfy the specific use cases. In Spring Data Neo4j,
repositories are derived from the GraphRepository<T>
base interface, which already combines some of the usually needed
functionality: CRUD operations, and index and traversal functions. The basic setup for
repositories is just another line of the namespace configuration, as shown
in Example 7-16. Each domain class will be bound
to an individual, concrete repository interface (see Example 7-17).
Spring Data Neo4j repositories provide
support for @Query-annotated and derived finder methods, which are projected to Cypher
statements. To understand how this mapping works, you need to be aware of
the expressive syntax of Cypher, which is explained in the next sidebar,
.
The basic operations provided by the repositories mimic those
offered by the Neo4jTemplate, only bound to the
declared repository domain class. So findOne(…), save(…),
delete(…), findAll(…), and so on, take and
return instances of the domain class.
Spring Data Neo4j stores the type (hierarchy) information of the mapped entities in the graph. It uses one of several strategies for this purpose, defaulting to an index-based storage. This type information is used for all repository and template methods that operate on all instances of a type and for verification of requested types versus stored types.
The updating repository methods are
transactional by default, so there is no need to declare a transaction
around them. For domain use cases, however, it is sensible to do so
anyway, as usually more than one database operation is encapsulated by a
business transaction. (This uses the Neo4j supplied support for JtaTransactionManager)
For index operations, specific methods like
findAllByPropertyValue(), findAllByQuery(),
and findAllByRange() exist in the
IndexRepository and are mapped directly to the underlying
index infrastructure of Neo4j, but take the repository domain class and
existing index-related annotations into account. Similar methods are
exposed in the TraversalRepository whose
findAllByTraversal() method allows direct access to the
powerful graph traversal mechanisms of Neo4j. Other provided repository
interfaces offer methods for spatial queries or the Cypher-DSL
integration.
Besides the previously discussed basic operations, Spring Data Neo4j repositories
support custom finder methods by leveraging the Cypher query language.
For both annotated and derived finder methods, additional
Pageable and Sort method parameters are taken
into account during query execution. They are converted into appropriate
ORDER BY, SKIP, and LIMIT
declarations.
Finders can use Cypher directly if we add a @Query annotation
that contains the query string, as shown in Example 7-18. The method arguments are passed as
parameters to the Cypher query, either via their parameter position or
named according to their @Parameter annotation, so you can use {index} or
{name} in the query string.
Example 7-18. An annotated cypher query on a repository query method
publicinterfaceOrderRepositoryextendsGraphRepository<Order>{@Query(" START c=node({0}) "+" MATCH c-[:ORDERED]->order-[item:LINE_ITEM]->product "+" WITH order, SUM (product.price * item.amount) AS value "+" WHERE value > {orderValue} "+"RETURN order")Collection<Order>findOrdersWithMinimumValue(Customercustomer,@Parameter("orderValue")intvalue);}
The return types of finder methods can be either an Iterable<T>,
in which case the evaluation of the query happens lazily,
or any of these interfaces:
Collection<T>,
List<T>,
Set<T>,
Page<T>. T is the
result type of the query, which can be either a mapped domain entity
(when returning nodes or relationships) or a primitive type. There is
support for an interface-based simple mapping of query results. For
mapping the results, we have to create an interface annotated with
@MapResult. In the interface we declare methods for
retrieving each column-value. We annotate the methods individually
with
@ResultColumn("columnName").
See Example 7-19.
Example 7-19. Defining a MapResult and using it in an interface method
@MapResultinterfaceRatedProduct{@ResultColumn("product")ProductgetProduct();@ResultColumn("rating")FloatgetRating();@ResultColumn("count")intgetCount();}
publicinterfaceProductRepositoryextendsGraphRepository<Product>{@Query(" START tag=node({0}) "+" MATCH tag-[:TAG]->product<-[rating:RATED]-() "+"RETURN product, avg(rating.stars) AS rating, count(*) as count "+" ORDER BY rating DESC")Page<RatedProduct>getTopRatedProductsForTag(Tagtag,Pageablepage);}
To avoid the proliferation of query methods for different
granularities, result types, and container classes, Spring Data Neo4j
provides a small fluent API for result handling. The API covers
automatic and programmatic value conversion. The core of the result
handling API centers on converting an iterable result into different
types using a configured or given ResultConverter,
deciding on the granularity of the result size and optionally on the
type of the target container. See Example 7-20.
Example 7-20. Result handling API
publicinterfaceProductRepositoryextendsGraphRepository<Product>{Result<Map<String,Object>>findByName(Stringname);}
Result<Map<String,Object>>result=repository.findByName("mac");// return a single node (or null if nothing found)Noden=result.to(Node.class).singleOrNull();Page<Product>page=result.to(Product.class).as(Page.class);Iterable<String>names=result.to(String.class,newResultConverter<Map<String,Object>,String>>(){publicStringconvert(Map<String,Object>row){return(String)((Node)row.get("name")).getProperty("name");}});
As described in Chapter 2, the derived finder methods (see Property expressions) are a real differentiator. They leverage the existing mapping information about the targeted domain entity and an intelligent parsing of the finder method name to generate a query that fetches the information needed.
Derived
finder methods—like
ProductRepository.findByNameAndColorAndTagName(name, color, tagName)—start with
find(By) or get(By) and then contain a
succession of property expressions. Each of the property expressions
either points to a property name of the current type or to another,
related domain entity type and one of its properties. These properties
must exist on the entity. If that is not the case, the repository creation fails early during
ApplicationContext startup.
For all valid finder methods, the repository constructs an appropriate query by using the mapping information about domain entities. Many aspects—like in-graph type representation, indexing information, field types, relationship types, and directions—are taken into account during the query construction. This is also the point at which appropriate escaping takes place.
Thus, Example 7-20 would be converted to the query shown in Example 7-21.
Example 7-21. Derived query generation
@NodeEntityclassProduct{@IndexedStringname;intprice;@RelatedTo(type="TAG")Set<Tag>tags;}@NodeEntityclassTag{@IndexedStringname;}publicinterfaceProductRepositoryextendsGraphRepository<Product>{List<Product>findByNameAndPriceGreaterThanAndTagsName(Stringname,intprice,StringtagName);}// Generated querySTARTproduct=node:Product(name={0}),productTags=node:Tag(name={3})MATCHproduct-[:TAG]->productTagsWHEREproduct.price>{1}RETURNproduct
This example demonstrates the use of index lookups for indexed attributes and the simple property comparison. If the method name refers to properties on other, related entities, then the query builder examines those entities for inclusion in the generated query. The builder also adds the direction and type of the relationship to that entity. If there are more properties further along the path, the same action is repeated.
Supported keywords for the property comparison are:
For many of the typical query use cases, it is easy enough to just code a derived finder declaration in the repository interface and use it. Only for more involved queries is an annotated query, traversal description, or manual traversing by following relationships necessary.
Besides the ease of mapping real-world, connected data into the graph, using the graph data model allows you to work with your data in interesting ways. By focusing on the value of relationships in your domain, you can find new insights and answers that are waiting to be revealed in the connections.
Due to the schema-free nature of Neo4j, a single node or relationship is not limited to be mapped to a single domain class. Sometimes it is sensible to structure your domain classes into smaller concepts/roles that are valid for a limited scope/context.
For example, an Order is used differently in
different stages of its life cycle. Depending on the current state, it
is either a shopping cart, a customer order, a dispatch note, or a
return order. Each of those states is associated with different
attributes, constraints, and operations. Usually, this would have been
modeled either in different entities stored in separate tables or in a
single Order class stored in a very large and sparse table
row. With the schemaless nature of the graph database, the order will be
stored in a node but only contains the state (and relationships) that
are needed in the current state (and those still needed from past
states). Usually, it gains attributes and relationships during its life,
and gets simplified and locked down only when being retired.
Spring Data Neo4j allows us to model such
entities with different classes, each of which covers one period of the
life cycle. Those entities share a few attributes; each has some unique
ones. All entities are mapped to the same node, and depending on the
type provided at load time with template.findOne(id,type),
or at runtime with template.projectTo(object, type), it can
be used differently in different contexts. When the projected entity is
stored, only its current attributes (and relationships) are updated; the
other existing ones are left alone.
For handling larger product catalogs and ease of exploration, it is important to be able to put products into categories. A naive approach that uses a single category attribute with just one value per product falls short in terms of long-term usability. In a graph, multiple connections to category nodes per entity are quite natural. Adding a tree of categories, where each has relationships to its children and each product has relationships to the categories it belongs to, is really simple. Typical use cases are:
The same goes for tags, which are less restrictive than categories and often form a natural graph, with all the entities related to tags instead of a hierarchical tree like categories. In a graph database, both multiple categories as well as tags form implicit secondary indexing structures that allow navigational access to the stored entities in many different ways. There can be other secondary indexes (e.g., geoinformation, time-related indices, or other interesting dimensions). See Example 7-22.
Example 7-22. Product categories and tags
@NodeEntitypublicclassCategoryextendsAbstractEntity{@Indexed(unique=true)Stringname;@Fetch// loads all children eagerly (cascading!)@RelatedTo(type="SUB_CAT")Set<Category>children=newHashSet<Category>();publicvoidaddChild(Categorycat){this.children.add(cat);}}@NodeEntitypublicclassProductextendsAbstractEntity{@RelatedTo(type="CATEGORY")Set<Category>categories=newHashSet<Category>();publicvoidaddCategory(Categorycat){this.categories.add(cat);}}publicinterfaceProductRepositoryextendsGraphRepository<Product>{@Query("START cat=node:Category(name={0}) "+"MATCH cat-[SUB_CAT*0..5]-leaf<-[:CATEGORY]-product "+"RETURN distinct product")List<Product>findByCategory(Stringcategory);}
The Category forms a nested composite structure
with parent-child relationships. Each category has a unique name and a
set of children. The category objects are used for creating the
structure and relating products to categories. For leveraging the
connectedness of the products, a custom (annotated) query navigates from
a start (or root) category, via the next zero through five
relationships, to the products connected to this subtree. All attached
products are returned in a list.
Collaborative
filtering, demonstrated in Example 7-23, relies on the assumption that we can find other “people”
who are very similar/comparable to the current user in their interests
or behavior. Which criteria are actually used for
similarity—search/buying history, reviews, or others—is domain-specific.
The more information the algorithm gets, the better the results.
In the next step, the products that those similar people also bought or liked are taken into consideration (measured by the number of their mentions and/or their rating scores) optionally excluding the items that the user has already bought, owns, or is not interested in.
Example 7-23. Collaborative filtering
publicinterfaceProductRepositoryextendsGraphRepository<Product>{@Query("START cust=node({0}) "+" MATCH cust-[r1:RATED]->product<-[r2:RATED]-people "+" -[:ORDERED]->order-[:ITEMS]->suggestion "+" WHERE abs(r1.stars - r2.stars) <= 2 "+" RETURN suggestion, count(*) as score"+" ORDER BY score DESC")List<Suggestion>recommendItems(Customercustomer);@MapResultinterfaceSuggestion{@ResultColumn("suggestion")ProductgetProduct();@ResultColumn("score")IntegergetScore();}}
Generally in all domains, but particularly in the ecommerce domain, making recommendations of interesting products for customers is key to leveraging the collected information on product reviews and buying behavior. Obviously, we can derive recommendations from explicit customer reviews, especially if there is too little actual buying history or no connected user account. For the initial suggestion, a simple ordering of listed products by number and review rating (or more advanced scoring mechanisms) is often sufficient.
For more advanced recommendations, we use algorithms that take multiple input data vectors into account (e.g., ratings, buying history, demographics, ad exposure, and geo-information).
The query in Example 7-24 looks up a product and all the ratings by any customer and returns a single page of top-rated products (depending on the average rating).
With Neo4j being a fully transactional database, Spring Data Neo4j participates in
(declarative) Spring transaction management, and builds upon transaction managers provided by Neo4j that are compatible
with the Spring JtaTransactionManager. The
transaction-manager bean named
neo4jTransactionManager (aliased to
transactionManager) is created in the <neo4j:config
/> element. As transaction management is configured by default,
@Transactional annotations are all that’s needed to define transactional scopes.
Transactions are needed for all write operations to the graph database,
but reads don’t need transactions. It is possible to nest transactions,
but nested transactions will just participate in the running parent
transaction (like REQUIRED).
Spring Data Neo4j, as well as Neo4j itself, can integrate with external XA transaction managers; the Neo4j manual describes the details.
For the simple mapping mode, the life cycle is straightforward: a new
entity is just a POJO instance until it has been stored to the graph, in
which case it will keep the internal id of the element (node
or relationship) in the @GraphId annotated field for later
reattachment or merging. Without the id set, it will be
handled as a new entity and trigger the creation of a new graph element
when saved.
Whenever entities are fetched in simple
mapping mode from the graph, they are automatically detached. The data is
copied out of the graph and stored in the domain object instances. An
important aspect of using the simple mapping mode is the fetch
depth. As a precaution, the transaction fetches only the direct
properties of an entity and doesn’t follow relationships by default when
loading data.
To achieve a deeper fetch graph, we need to
supply a @Fetch annotation on the fields that should be eagerly fetched. For entities
and fields not already fetched, the template.fetch(…) method
will load the data from the graph and update them in place.
Spring Data Neo4j also offers a more advanced mapping mode. Its main difference
from the simple mapping mode is that it offers a live view of the graph
projected into the domain objects. So each field access will be
intercepted and routed to the appropriate properties or relationships
(for @RelatedTo[Via] fields). This interception
uses AspectJ under the hood to work its magic.
We can enable the advanced mapping mode by
adding the org.springframework.data:spring-data-neo4j-aspects
dependency and configuring either a AspectJ build plug-in or load-time-weaving activation (Example 7-25).
Example 7-25. Spring Data Neo4j advanced mapping setup
<properties><aspectj.version>1.6.12</aspectj.version></properties><dependency><groupId>org.springframework.data</groupId><artifactId>spring-data-neo4j-aspects</artifactId><version>${spring-data-neo4j.version}</version></dependency><dependency><groupId>org.aspectj</groupId><artifactId>aspectjrt</artifactId><version>${aspectj.version}</version></dependency>....<plugin><groupId>org.codehaus.mojo</groupId><artifactId>aspectj-maven-plugin</artifactId><version>1.2</version><dependencies><dependency><groupId>org.aspectj</groupId><artifactId>aspectjrt</artifactId><version>${aspectj.version}</version></dependency><dependency><groupId>org.aspectj</groupId><artifactId>aspectjtools</artifactId><version>${aspectj.version}</version></dependency></dependencies><executions><execution><goals><goal>compile</goal><goal>test-compile</goal></goals></execution></executions><configuration><outxml>true</outxml><aspectLibraries><aspectLibrary><groupId>org.springframework</groupId><artifactId>spring-aspects</artifactId></aspectLibrary><aspectLibrary><groupId>org.springframework.data</groupId><artifactId>spring-data-neo4j-aspects</artifactId></aspectLibrary></aspectLibraries><source>1.6</source><target>1.6</target></configuration></plugin>
Fields are automatically read from the graph
at any time, but for immediate writethrough the operation must happen
inside of a transaction. Because objects can be modified outside of a
transaction, a life cycle of attached/detached objects has been
established. Objects loaded from the graph or just saved
inside a transaction are attached; if an object is
modified outside of a transaction or newly created, it is
detached. Changes to detached objects are stored in the
object itself, and will only be reflected in the graph with the next
save operation, causing the entity to become attached
again.
This live view of the graph database allows
for faster operation as well as “direct” manipulation of the graph.
Changes will be immediately visible to other graph operations like
traversals, Cypher queries, or Neo4j Core API methods. Because reads
always happen
against the live graph, all changes by other committed transactions are
immediately visible. Due to the immediate live reads from the graph
database, the advanced mapping mode has no need of fetch handling and the @Fetch annotation.
We’ve already mentioned that Neo4j comes in two flavors. You can easily use the high-performance, embeddable Java database with any JVM language, preferably with that language's individual idiomatic APIs/drivers. Integrating the embedded database is as simple as adding the Neo4j libraries to your dependencies.
The other deployment option is Neo4j server. The Neo4j server module is a simple download or operating system package that is intended to be run as an independent service. Access to the server is provided via a web interface for monitoring, operations, and visualizations (refer back to Example 7-1). A comprehensive REST API offers programmatic access to the database functionality. This REST API exposes a Cypher endpoint. Using the Neo4j-Java-Rest-Binding (which wraps the Neo4j Java API around the REST calls) to interact transparently with the server, Spring Data Neo4j can work easily with the server.
By depending on
org.springframework.data:spring-data-neo4j-rest and changing
the setup to point to the remote URL of the server, we can use Spring Data
Neo4j with a server installation (Example 7-26).
Please note that with the current implementation, not all calls are
optimally transferred over the network API, so the server interaction for
individual operations will be affected by network latency and bandwidth.
It is recommended to use remotely executed queries as much as possible to
reduce that impact.
Example 7-26. Server connection configuration setup
<?xml version="1.0" encoding="UTF-8"?><beansxmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:neo4j="http://www.springframework.org/schema/data/neo4j"xsi:schemaLocation="http://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans.xsdhttp://www.springframework.org/schema/data/neo4jhttp://www.springframework.org/schema/data/neo4j/spring-neo4j.xsd"><neo4j:configgraphDatabaseService="graphDatabaseService"/><beanid="graphDatabaseService"class="org.springframework.data.neo4j.rest.SpringRestGraphDatabase"><constructor-argindex="0"value="http://localhost:7474/db/data"/></bean></beans>
The SpringRestGraphDatabase
connects via a RestAPI instance, which you can get to
execute individual or batched REST operations more efficiently. For
instance, creating entities with immediate property population, both for
conventional or unique entities, is more efficient with the
RestAPI.
This chapter presented some of the possibilities that graph databases—in particular Neo4j—offer and how Spring Data Neo4j gives you convenient access to them while keeping the doors open for raw, low-level graph processing.
The next thing you should do is consider the data you are working with (or want to work with) and see how connected the entities are. Look closely—you’ll see they’re often much more connected than you’d think at first glance. Taking one of these domains, and putting it first on a whiteboard and then into a graph database, is your first step toward realizing the power behind these concepts. For writing an application that uses the connected data, Spring Data Neo4j is an easy way to get started. It enables you to easily create graph data and expose results of graph queries as your well-known POJOs, which eases the integration with other libraries and (UI) frameworks.
To learn how that process works for a complete web application, see [Hunger12] in the Bibliography, which is part of the reference documentation and the GitHub repository. The tutorial is a comprehensive walkthrough of creating the social movie database cineasts.net, and explains data modeling, integration with external services, and the web layer.
Feel free to reach out at any time to the Springsource Forums, Stackoverflow, or the Neo4j Google Group for answers to your questions. Enjoy!