
![]()
Now you’ll begin your journey of using SQL in PL/SQL. You’ll start out slowly, inserting one row at a time, then updating one row at a time, then deleting one row at a time, and finally selecting one row at a time. I take this approach because you first have to insert data into a database before you can update, delete, or select it. I call these kinds of SQL statements singletons because they return one row of results. So let’s get started by putting some data into the database.
Inserts
The context here is inserting data into a relational database. To insert data into a relational database from PL/SQL, you simply write a SQL INSERT statement, where the values are PL/SQL literals, PL/SQL variables, or SQL columns.
I begin with examples that represent what is most commonly done, and then continually improve the architecture and design as you progress through the chapter. To start out, you’ll see what most PL/SQL programmers do, and then how to improve the code. Please keep in mind that there is a time and place for each of these solutions. In the end, you’re the one who will need to make the decision about which is the best solution based on the business problem you’re solving.
Rarely do you just perform a simple atomic INSERT statement in PL/SQL. You can do that using a SQL*Plus script, without using PL/SQL at all. More often, you’ll want to insert or update depending on whether the data you intend to insert already exists in the database. If it does, you’ll probably want to check if you need to update the values already in the database. So the process you decide to use to insert and/or update becomes a proverbial chicken vs. egg dilemma—which do you do first? Let’s start by looking at what can happen if a duplicate row already exists.
You’re going to see me use SELECT when I INSERT because, in a modern database design, you need to SELECT sequence and code ID values to use them in an INSERT statement. Let’s check it out. Listing 4-1 is an anonymous PL/SQL procedure that inserts values into the WORKERS table.
Listing 4-1. An Insert Example Using PL/SQL Literals and Variables, insert.sql
001 rem insert.sql
002 rem by Donald J. Bales on 2014-10-20
003 rem An anonymous PL/SQL procedure to insert
004 rem values using PL/SQL literals and variables
005
006 set serveroutput on size 1000000;
007
008 declare
009
010 -- I declared these variables so I can get
011 -- the required ID values before I insert.
012 n_id WORKERS.id%TYPE;
013 n_worker_type_id WORKERS.worker_type_id%TYPE;
014 v_external_id WORKERS.external_id%TYPE;
015 n_gender_type_id WORKERS.gender_type_id%TYPE;
016
017 -- I'll use this variable to hold the result
018 -- of the SQL insert statement.
019 n_count number;
020
021 begin
022
023 -- First, let's get the WORKER_TYPES id for a contractor
024 begin
025 select id
026 into n_worker_type_id
027 from WORKER_TYPES
028 where code = 'C';
029 exception
030 when OTHERS then
031 raise_application_error(-20002, SQLERRM||
032 ' on select WORKER_TYPES'||
033 ' in filename insert.sql'),
034 end;
035
036 -- Next, let's get the GENDER_TYPES id for a male
037 begin
038 select id
039 into n_gender_type_id
040 from GENDER_TYPES
041 where code = 'M';
042 exception
043 when OTHERS then
044 raise_application_error(-20004, SQLERRM||
045 ' on select GENDER_TYPES'||
046 ' in filename insert.sql'),
047 end;
048
049 -- Now, let's get the next WORKERS id sequence
050 begin
051 select WORKERS_ID.nextval
052 into n_id
053 from SYS.DUAL;
054 exception
055 when OTHERS then
056 raise_application_error(-20001, SQLERRM||
057 ' on select WORKERS_ID.nextval'||
058 ' in filename insert.sql'),
059 end;
060
061 -- And then, let's get the next external_id sequence
062 begin
063 select lpad(to_char(EXTERNAL_ID_SEQ.nextval), 9, '0')
064 into v_external_id
065 from SYS.DUAL;
066 exception
067 when OTHERS then
068 raise_application_error(-20003, SQLERRM||
069 ' on select EXTERNAL_ID_SEQ.nextval'||
070 ' in filename insert.sql'),
071 end;
072
073 -- Now that we have all the necessary ID values
074 -- we can finally insert a row!
075 begin
076 insert into WORKERS (
077 id,
078 worker_type_id,
079 external_id,
080 first_name,
081 middle_name,
082 last_name,
083 name,
084 birth_date,
085 gender_type_id )
086 values (
087 n_id, -- a variable
088 n_worker_type_id, -- a variable
089 v_external_id, -- a variable
090 'JOHN', -- a literal
091 'J.', -- a literal
092 'DOE', -- a literal
093 'DOE, JOHN J.', -- a literal
094 to_date('19800101', 'YYYYMMDD'), -- a function
095 n_gender_type_id ); -- a variable
096
097 n_count := sql%rowcount;
098 exception
099 when OTHERS then
100 raise_application_error(-20005, SQLERRM||
101 ' on insert WORKERS'||
102 ' in filename insert.sql'),
103 end;
104
105 pl(to_char(n_count)||' row(s) inserted.'),
106 end;
107 /
108
109 commit;
The SQL INSERT syntax used in Listing 4-1 is as follows:
INSERT INTO <table_name> (
<column_name_1>,
<column_name_2>,...
<column_name_N> )
VALUES (
<column_value_1>,
<column_value_2>,...
<column_value_N> );
where <table_name> is the name of the table to INSERT VALUES INTO, <column_name> is the name of a column in the table, and <column_value> is the value for a corresponding <column_name>. The column values can be PL/SQL literals, variables, qualifying function results, or SQL column values.
You should always use a list of columns in your INSERT statements in order to maintain the validity of your code, in case someone later adds a column to a table definition (and, in practice, that happens).
Let’s break down the code in Listing 4-1:
- Lines 12 through 15 declare four variables to hold the ID values from related sequence and code tables.
- Line 19 declares a number to hold the resulting row count from the INSERT statement.
- Lines 25 through 28 contain a SELECT statement to get the worker_type_id value for a contractor.
- On lines 24 through 34, I’ve blocked (put the code in a nested PL/SQL block) the SELECT statement so I can catch any catastrophic error, and report it to the presentation layer with an error number and message that are unique to the PL/SQL program. This practice greatly simplifies troubleshooting. You’ll know exactly what went wrong and where it went wrong, and that’s nice.
- On lines 37 through 47, I get the gender_type_id value for a male.
- On lines 50 through 59, I get the next id sequence value, storing that value in variable n_id.
- On lines 62 through 71, I get the next external_id value. I use the SQL function to_char() to do an explicit data type conversion from numeric to character. I wrap the character value with the SQL function lpad() in order to left-pad the number string with zeros so it’s nine characters long.
- Lines 76 through 95 contain an INSERT statement to insert John Doe’s data into the WORKERS table.
- Lines 77 through 85 list the names of the columns I’m going to insert values INTO. This is an important practice. If I didn’t list the columns, the procedure would become invalid any time someone modified the WORKERS table.
- Lines 87 through 95 specify the column values using a combination of PL/SQL literals, PL/SQL variables, and even the return value of the SQL function to_date() for the value of column birth_date.
- On line 97, I store the result value of the INSERT statement, which is the number of rows inserted. To accomplish this, I use the pseudo-cursor name sql% and its variable rowcount.
- On lines 75 through 103 collectively, I’ve blocked the INSERT statement so I can detect and report the exact type and location of an error in the PL/SQL procedure.
The following is the output from the first time the insert.sql script is executed:
SQL> @insert.sql
1 row(s) inserted.
PL/SQL procedure successfully completed.
If you examine the code in Listing 4-1 and its output, you’ll see that the procedure inserted one row into the database, as reported by the output from the INSERT statement through the sql%rowcount variable. But what happens if we run the script again? Here’s the output from the script’s second execution:
SQL> @insert.sql
declare
*
ERROR at line 1:
ORA-20005: ORA-00001: unique constraint (RPS.WORKERS_UK2) violated on insert WORKERS in filename insert.sql
ORA-06512: at line 93
No PL/SQL procedure successfully completed message this time! An unhandled unique constraint exception was raised as an application error, number 20005, along with a meaningful message.
Now if you want to handle this particular kind of exception, you can use one of three tactics:
- Catch exception DUP_VAL_ON_INDEX (good).
- Use additional PL/SQL code to predetect the duplicate’s presence (better).
- Use additional SQL code to predetect the duplicate’s presence (best).
Let’s take a look at these solutions, from good to best.
Catching a DUP_VAL_ON_INDEX Exception
When it comes to dealing with code that may raise a DUP_VAL_ON_INDEX exception (or any exception, for that matter), catching the exception is the laziest of solutions, yet perfectly legitimate. Actually, catching a DUP_VAL_ON_INDEX exception during an INSERT is the only way to determine that a duplicate row exists. So regardless of which process you use to insert a row, you always need to catch any possible exceptions during the execution of a SQL statement and handle them appropriately.
Figure 4-1 shows a simple process flow diagram for inserting a row and catching a DUP_VAL_ON_INDEX exception if a duplicate row already exists in the database. The process in Figure 4-1 starts out by executing a SQL INSERT statement. When you do this, Oracle will check for duplicate values in any existing unique index or unique key entries for the table in question. If a duplicate entry is found, PL/SQL will raise a DUP_VAL_ON_INDEX exception. So how do you handle that?
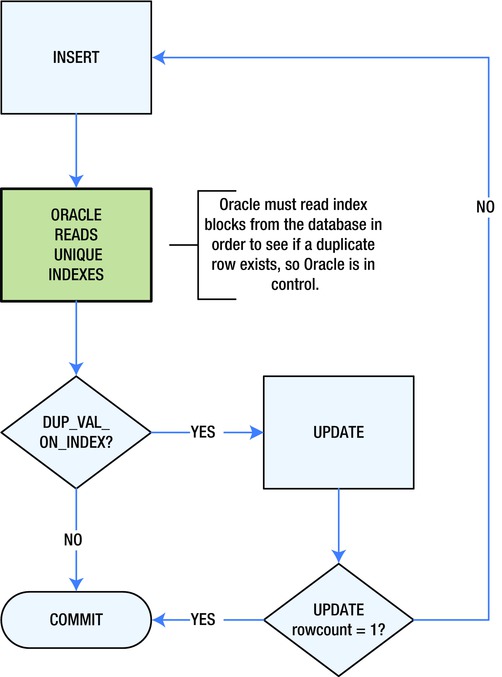
Figure 4-1. Updating after an insert fails
What you know at this point in your program is that a duplicate entry existed at the moment the SQL engine tried to insert your row. But that does not guarantee that the same duplicate row exists microseconds later in the exception handler. Someone or something else using the database could have deleted it in the meantime.
So perhaps you decide to try to UPDATE the supposedly existing entry. If you choose that tactic, you can be 100% sure that the entry was updated only if you examine sql%rowcount for the number of rows updated after your attempted update. If the row count isn’t equal to one, then you need to try to insert the row again.
This “classic” solution is perfectly legitimate and arguably the only correct way to insert values. Or is it? I don’t like this approach because it’s a reactive solution where you are not in complete control of the process. Is it better to gain control after an error or to maintain control all along? Let’s look at an example in order to get a better understanding of the problem, before you decide on a solution. Listing 4-2 shows a modified version of Listing 4-1, where the ORA-00001: unique constraint ... violated, or DUP_VAL_ON_INDEX exception, is handled.
Listing 4-2. An Insert Example, Modified to Catch DUP_VAL_ON_INDEX, insert_with_handled_exception.sql
073 -- Now that we have all the necessary ID values
074 -- we can finally insert a row!
075 begin
076 insert into WORKERS (
077 id,
078 worker_type_id,
079 external_id,
080 first_name,
081 middle_name,
082 last_name,
083 name,
084 birth_date,
085 gender_type_id )
086 values (
087 n_id, -- a variable
088 n_worker_type_id, -- a variable
089 v_external_id, -- a variable
090 'JOHN', -- a literal
091 'J.', -- a literal
092 'DOE', -- a literal
093 'DOE, JOHN J.', -- a literal
094 to_date('19800101', 'YYYYMMDD'), -- a function
095 n_gender_type_id ); -- a variable
096
097 n_count := sql%rowcount;
098 exception
099 when DUP_VAL_ON_INDEX then
100 n_count := 0;
101 pl('Caught a DUP_VAL_ON_INDEX exception'),
102 when OTHERS then
103 raise_application_error(-20005, SQLERRM||
104 ' on insert WORKERS'||
105 ' in filename insert_with_handled_exception.sql'),
106 end;
![]() Note Listing 4-2 is a partial code listing. I’ll use this technique whenever there’s a lot of repeated code from one listing to the next. Because of this, you didn’t have to pay as much for this book, nor did we have to kill as many trees; less paper, fewer dead trees, lower cost.
Note Listing 4-2 is a partial code listing. I’ll use this technique whenever there’s a lot of repeated code from one listing to the next. Because of this, you didn’t have to pay as much for this book, nor did we have to kill as many trees; less paper, fewer dead trees, lower cost.
So what changed?
- Line 99 now has a WHEN DUP_VAL_ON_INDEX clause, which catches a DUP_VAL_ON_INDEX exception. The scope of the clause extends until the next use of the keyword WHEN or the keyword END for the enclosing PL/SQL block.
- On line 100, I set the row count variable, n_count, to 0 because lines 96 and 97 are not executed when an exception occurs. Instead, the program’s execution jumps from line 95, where the error takes place, directly to line 98, in order to start handling exceptions.
- On line 101, I display a custom error message, but I don’t raise the exception, so the program executes successfully.
Here’s the output of the modified script, insert_with_handled_exception.sql:
SQL> @insert_with_handle_exception.sql
Caught a DUP_VAL_ON_INDEX exception
0 row(s) inserted.
PL/SQL procedure successfully completed.
But a nagging question remains. Is it better to gain control after an error or to maintain control all along? Let’s take a look at tactic number two.
Using PL/SQL to Predetect a Duplicate
Using additional PL/SQL code to predetect the presence of duplicate values is, in my opinion, better than catching a DUP_VAL_ON_INDEX exception, for these reasons:
- You maintain control of your PL/SQL program’s execution.
- You can conditionally decide how to handle duplicate values.
- You can use your detection scheme to acquire the primary key for the row that is a duplicate, and then update that row.
Figure 4-2 is a simple process flow diagram for predetecting a duplicate entry using PL/SQL, and then acting accordingly—that is, inserting or updating as needed. In this process, you start out by selecting the primary key value from the database for the table entry in question. If you find an existing entry, you can determine whether the entry needs to be updated, and then execute an UPDATE statement. Alternatively, you execute an INSERT statement if the SELECT statement raises a NO_DATA_FOUND exception.
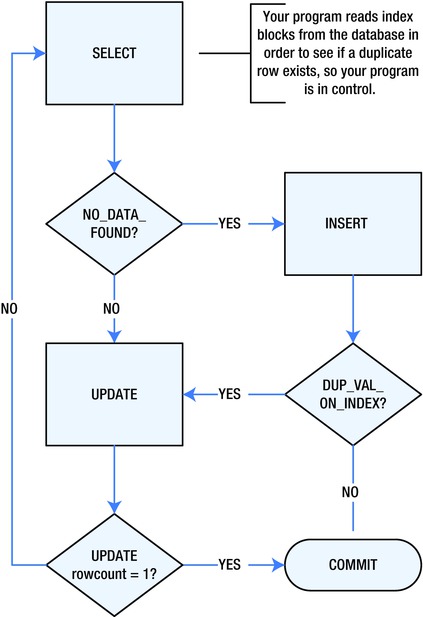
Figure 4-2. Select, then insert or update as needed
However, you cannot ignore the possibility that, even though a duplicate entry did not exist at the moment you executed a SELECT statement against the database, someone or something has since inserted a duplicate entry. This could happen in the microseconds between the raised exception and the execution of your INSERT statement, so you must still catch any possible exceptions on the execution of the INSERT statement and act accordingly.
This time, if the sql%rowcount variable is not equal to one, you need to try selecting the entry again.
So which solution is better? Once again, let’s look at an example before you decide. Listing 4-3 is another modification of Listing 4-1. This time, I’ve added a nested block of PL/SQL code to detect possible duplicate values.
Listing 4-3. An Insert Example, Modified to Detect Duplicates with PL/SQL, insert_with_plsql_detection.sql
015 v_first_name WORKERS.first_name%TYPE;
016 v_middle_name WORKERS.middle_name%TYPE;
017 v_last_name WORKERS.last_name%TYPE;
018 v_name WORKERS.name%TYPE;
019 d_birth_date WORKERS.birth_date%TYPE;
...
027 v_first_name := 'JOHN';
028 v_middle_name := 'J.';
029 v_last_name := 'DOE';
030 v_name :=
031 rtrim(v_last_name||', '||v_first_name||' '||v_middle_name);
032 d_birth_date :=
033 to_date('19800101', 'YYYYMMDD'), -- I'm guessing
...
061 -- Detect any existing entries with the unique
062 -- combination of columns as in this constraint:
063 -- constraint WORKERS_UK2
064 -- unique (
065 -- name,
066 -- birth_date,
067 -- gender_type_id )
068 begin
069 select count(1)
070 into n_count
071 from WORKERS
072 where name = v_name
073 and birth_date = d_birth_date
074 and gender_type_id = n_gender_type_id;
075 exception
076 when OTHERS then
077 raise_application_error(-20005, SQLERRM||
078 ' on select WORKERS'||
079 ' in filename insert_with_plsql_detection.sql'),
080 end;
081
082 -- Conditionally insert the row
083 if n_count = 0 then
084 -- Now, let's get the next id sequence
085 begin
086 select WORKERS_ID.nextval
087 into n_id
088 from SYS.DUAL;
089 exception
090 when OTHERS then
091 raise_application_error(-20001, SQLERRM||
092 ' on select WORKERS_ID.nextval'||
093 ' in filename insert_with_plsql_detection.sql'),
094 end;
095
096 -- And then, let's get the next external_id sequence
097 begin
098 select lpad(to_char(EXTERNAL_ID_SEQ.nextval), 9, '0')
099 into v_external_id
100 from SYS.DUAL;
101 exception
102 when OTHERS then
103 raise_application_error(-20003, SQLERRM||
104 ' on select EXTERNAL_ID_SEQ.nextval'||
105 ' in filename insert_with_plsql_detection.sql'),
106 end;
107
108 -- Now that we have all the necessary ID values
109 -- we can finally insert a row!
110 begin
111 insert into WORKERS (
112 id,
113 worker_type_id,
114 external_id,
115 first_name,
116 middle_name,
117 last_name,
118 name,
119 birth_date,
120 gender_type_id )
121 values (
122 n_id,
123 n_worker_type_id,
124 v_external_id,
125 v_first_name,
126 v_middle_name,
127 v_last_name,
128 v_name,
129 d_birth_date,
130 n_gender_type_id );
131
132 n_count := sql%rowcount;
133 exception
134 when OTHERS then
135 raise_application_error(-20006, SQLERRM||
136 ' on insert WORKERS'||
137 ' in filename insert_with_plsql_detection.sql'),
138 end;
139 else
140 n_count := 0;
141 end if;
Let’s review the modifications:
- On lines 15 through 19, I’ve added variables to hold column values. I’ve done this because I need to specify the column values more than once. This way, I can set their values once, and then know that I will consistently use the same values twice.
- Lines 27 through 33 initialize the variables I added on lines 15 through 19. A particularly troublesome issue is the variable v_name for column WORKERS.name. It’s a computed value that will be stored in the database in order to improve performance. This tactic will cause any relational database purist to have a hissy fit. But that’s not what I find troublesome. Since it’s a computed value, you must make sure it’s always computed the same way. Hmm, that sounds like a job for a function dedicated to the WORKERS table. You’ll create one to handle this issue in Chapter 5, so don’t sweat it yet.
- Lines 68 through 80 contain a new nested PL/SQL block that queries the WORKERS table against the columns that make up the unique constraint in question, to see if an entry with duplicate values already exists in the table. The SQL statement simply counts the number of rows with duplicate values, storing the count in variable n_count.
- Line 83 has a new IF statement, which determines whether to insert a row. If the value of the variable n_count is 0, I go ahead and insert the row. Otherwise, on line 140, I set n_count to 0 in order to correctly report the number of rows inserted.
In Listing 4-3, I was able to maintain control of the execution of my PL/SQL program. But what if I wanted to update the row that already existed? Then I would have coded the detection block as shown in Listing 4-4.
Listing 4-4. An Insert Example, Modified to Detect Duplicates with PL/SQL for Update, insert_with_plsql_detection_for_update.sql
069 begin
070 select id
071 into n_id
072 from WORKERS
073 where name = v_name
074 and birth_date = d_birth_date
075 and gender_type_id = n_gender_type_id;
076 exception
077 when NO_DATA_FOUND then
078 n_id := NULL; -- Is this really needed?
079 when OTHERS then
080 raise_application_error(-20003, SQLERRM||
081 ' on select WORKERS'||
082 ' in filename insert_with_plsql_detection_for_update.sql'),
083 end;
084
085 -- Conditionally insert the row
086 if n_id is NULL then
087 -- Now, let's get the next id sequence
088 begin
089 select WORKERS_ID.nextval
090 into n_id
091 from SYS.DUAL;
092 exception
093 when OTHERS then
094 raise_application_error(-20004, SQLERRM||
095 ' on select WORKERS_ID.nextval'||
096 ' in filename insert_with_plsql_detection_for_update.sql'),
097 end;
098
099 -- And then, let's get the next external_id sequence
100 begin
101 select lpad(to_char(EXTERNAL_ID_SEQ.nextval), 9, '0')
102 into v_external_id
103 from SYS.DUAL;
104 exception
105 when OTHERS then
106 raise_application_error(-20005, SQLERRM||
107 ' on select EXTERNAL_ID_SEQ.nextval'||
108 ' in filename insert_with_plsql_detection_for_update.sql'),
109 end;
110
111 -- Now that we have all the necessary ID values
112 -- we can finally insert a row!
113 begin
114 insert into WORKERS (
115 id,
116 worker_type_id,
117 external_id,
118 first_name,
119 middle_name,
120 last_name,
121 name,
122 birth_date,
123 gender_type_id )
124 values (
125 n_id,
126 n_worker_type_id,
127 v_external_id,
128 v_first_name,
129 v_middle_name,
130 v_last_name,
131 v_name,
132 d_birth_date,
133 n_gender_type_id );
134
135 n_inserted := sql%rowcount;
136 exception
137 when OTHERS then
138 raise_application_error(-20006, SQLERRM||
139 ' on insert WORKERS'||
140 ' in filename insert_with_plsql_detection_for_update.sql'),
141 end;
142 else
143 begin
144 update WORKERS
145 set worker_type_id = n_worker_type_id
146 where id = n_id;
147
148 n_updated := sql%rowcount;
149 exception
150 when OTHERS then
151 raise_application_error(-20007, SQLERRM||
152 ' on update WORKERS'||
153 ' in filename insert_with_plsql_detection_for_update.sql'),
154 end;
155 end if;
On lines 69 through 83, I’ve recoded the detection block to retrieve the primary key value for a row with duplicate values. If a duplicate row exists, variable n_id, initially NULL, will be set to the value of the primary key. Otherwise, if a duplicate row does not exist, a NO_DATA_FOUND exception will be raised. In turn, the exception will be handled by the WHEN NO_DATA_FOUND clause in the enclosing PL/SQL block’s exception-handling section. There, in the EXCEPTION clause, I set the value of variable n_id to NULL to flag that I did not find a duplicate. I actually don’t need to set it NULL because it remained NULL when the exception was raised. But the Oracle PL/SQL documentation does not explicitly guarantee this behavior, so I set it to NULL.
Also, on line 86, now I use the n_id variable to determine if I found a duplicate row. If n_id is NULL, I insert the row. Otherwise, on lines 143 through 154, I update the duplicate row with the worker_type_id value.
So if this was a better tactic, what’s best? Before I answer that question, let’s first digress a moment so I can finally explain the syntax of all those IF statements I’ve been using all along!
IF I Don’t Tell You Now, When ELSE Can I?
This seems a good a time as any to finally get around to defining just what an IF statement is. Let’s look at the IF statement syntax used in Listing 4-4:
IF <boolean_evaluation> THEN
-- do this if it's TRUE
[ELSE
-- do this if it's not TRUE]
END IF;
where <boolean_evaluation> is PL/SQL that evaluates to a Boolean value. If the <boolean_evaluation> is TRUE, then the lines of code between the THEN and ELSE keywords are executed. Otherwise, if the <boolean_evaluation> is not TRUE or NULL, then the lines of code between keywords ELSE and END IF are executed.
In Listing 4-4, on line 86, I evaluate id is NULL. If it’s TRUE, PL/SQL executes lines 87 through 141; otherwise (ELSE), it executes lines 143 through 154. You can also use the following syntaxes:
IF <boolean_evaluation> THEN
-- do this if it's TRUE
END IF;
or
IF <boolean_evaluation> THEN
-- do this if it's TRUE
[ELSIF <boolean_evaluation> THEN
-- do this if it's TRUE
ELSIF ...
ELSE
-- do this if it's not TRUE]
END IF;
Now, let’s get back to the subject of inserting.
Using SQL to Predetect a Duplicate
It’s almost always best to let SQL simply do its job! You can’t imagine how much PL/SQL code I’ve seen that can be replaced by one SQL statement—for example, all the code you’ve seen so far in this chapter in Listings 4-1 through 4-4.
Figure 4-3 is a simple process flow diagram for predetecting a duplicate entry using SQL. In this process, SQL performs the work of predetection using an EXISTS clause. If a duplicate entry does not exist at the moment the EXISTS clause is executed, the SQL engine immediately follows with an INSERT. Regardless, this does not mean you can’t get a DUP_VAL_ON_INDEX exception. In the microseconds between the evaluation of the EXISTS clause and the INSERT, it is possible that someone or something has inserted a duplicate value into the database. So you must still catch any exceptions from the SELECT...INTO statement and act accordingly.
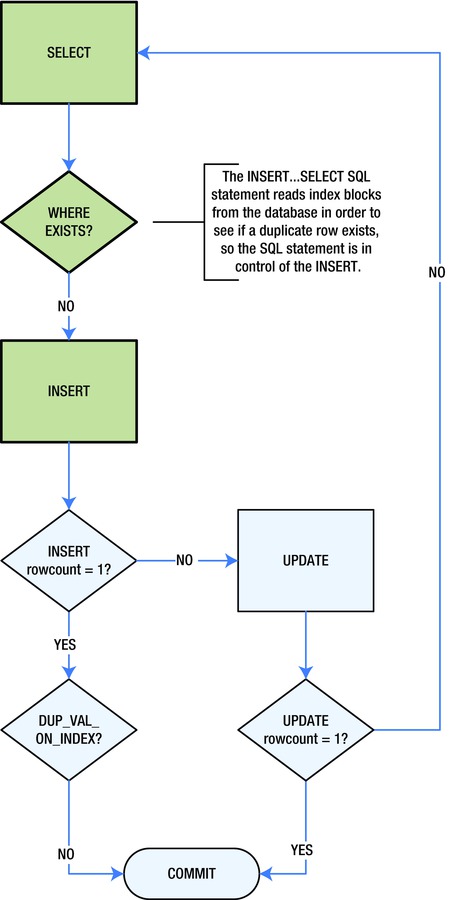
Figure 4-3. INSERT...SELECT, then update if needed
There appears to be no “perfect” solution, and indeed, that is the case. It’s always possible that someone or something has deleted or inserted an entry in the database between your duplicate row detection and corresponding action. Now let’s take a look at an example that uses SQL predetection.
Listing 4-5 is an example of letting SQL determine whether there’s a duplicate row, and then conditionally inserting values into the WORKERS table.
Listing 4-5. An Insert Example, Modified to Detect Duplicates with SQL, insert_with_sql_detection.sql
01 rem insert_with_sql_detection.sql
02 rem by Donald J. Bales on 2014-10-20
03 rem An anonymous PL/SQL procedure to insert
04 rem values using PL/SQL literals and variables
05
06 set serveroutput on size 1000000;
07
08 declare
09
10 v_first_name WORKERS.first_name%TYPE;
11 v_middle_name WORKERS.middle_name%TYPE;
12 v_last_name WORKERS.last_name%TYPE;
13 v_name WORKERS.name%TYPE;
14 d_birth_date WORKERS.birth_date%TYPE;
15
16 -- I'll use this variable to hold the result
17 -- of the SQL insert statement.
18 n_count number;
19
20 begin
21 -- Since I use these values more than once,
22 -- I set them here, and then use the variables
23 v_first_name := 'JOHN';
24 v_middle_name := 'J.';
25 v_last_name := 'DOE';
26 v_name :=
27 rtrim(v_last_name||', '||v_first_name||' '||v_middle_name);
28 d_birth_date :=
29 to_date('19800101', 'YYYYMMDD'), -- I'm guessing
30
31 -- Now I can just let SQL do all the work. Who needs PL/SQL!
32 begin
33 insert into WORKERS (
34 id,
35 worker_type_id,
36 external_id,
37 first_name,
38 middle_name,
39 last_name,
40 name,
41 birth_date,
42 gender_type_id )
43 select WORKERS_ID.nextval,
44 c1.id,
45 lpad(to_char(EXTERNAL_ID_SEQ.nextval), 9, '0'),
46 v_first_name,
47 v_middle_name,
48 v_last_name,
49 v_name,
50 d_birth_date,
51 c2.id
52 from WORKER_TYPES c1,
53 GENDER_TYPES c2
54 where c1.code = 'C'
55 and c2.code = 'M'
56 and not exists (
57 select 1
58 from WORKERS x
59 where x.name = v_name
60 and x.birth_date = d_birth_date
61 and x.gender_type_id = c2.id );
62
63 n_count := sql%rowcount;
64 exception
65 when OTHERS then
66 raise_application_error(-20006, SQLERRM||
67 ' on insert WORKERS'||
68 ' in filename insert_with_sql_detection.sql'),
69 end;
70
71 pl(to_char(n_count)||' row(s) inserted.'),
72 end;
73 /
74
75 commit;
Listing 4-5 isn’t a partial listing; it’s the whole program! Where did all the PL/SQL go? Well, let’s see. First, I’m using a different syntax for this program’s INSERT statement, as follows:
INSERT INTO <insert_table_name> (
<column_name_1>,
<column_name_2>,...
<column_name_N> )
SELECT <column_name_or_value_1>,
<column_name_or_value_2>,...
<column_name_or_value_N>
FROM <select_table_name_1> <select_table_alias_1>,
<select_table_name_2> <select_table_alias_2>,...
<select_table_name_N> <select_table_alias_N>
WHERE <where _clause>;
where <insert_table_name> is the name of the table to INSERT INTO, <column_name> is the name of a column in that table, <column_name_or_value> is the value for a corresponding <column_name> from one of the SELECT statement’s tables, <select_table_name> is one of the tables being queried by the SELECT statement, <select_table_alias> is a corresponding table name alias, and <where_clause> is the SELECT statement’s WHERE clause. The column values can be PL/SQL literals, variables, qualifying function results, or SQL column values.
I’ll say it again: you should always use a list of columns in your INSERT statements in order to maintain the validity of your code in the event that someone later adds a column to the table.
Back to the SQL statement:
- On lines 54 and 55, since the WHERE clause selects one row from the WORKER_TYPES and GENDER_TYPES tables, the SELECT statement will return only one row of values.
- On lines 56 through 61, the NOT EXISTS subquery performs the detection of a duplicate entry and, accordingly, the conditional insert of a row.
All the work that was done by five other SQL SELECT statements is now accomplished in one INSERT SELECT statement. What’s the moral of this story? Know thy SQL! Each solution presented here has its strengths and weaknesses. As I stated earlier, it’s up to you to decide which is the best tactic to apply to each situation.
I favor predetection instead of postdetection (reacting to the DUP_VAL_ON_INDEX exception) because I can maintain control of my program. And I have never found a situation where my PL/SQL batch programs were working on inserting and/or updating the exact same set of data at the same time. So, in 20 plus years of writing stored procedures, and after more than 40,000 stored procedures, I’ve never seen a DUP_VAL_ON_INDEX exception when using predetection. This means you must also consider the nature of the business environment in which you are going to run your stored procedures when deciding whether to use postdetection or predetection.
![]() Tip You should check out the functionality of the newer SQL DML statement MERGE. It can do a lot of what has already been covered in this chapter, using just SQL. However, it suffers from the same predetection issues I just covered.
Tip You should check out the functionality of the newer SQL DML statement MERGE. It can do a lot of what has already been covered in this chapter, using just SQL. However, it suffers from the same predetection issues I just covered.
It’s Your Turn to Insert
Are you just going to watch me do all the work? No way! Here’s what I need you to do, and you’ve got to do it, or the coming examples won’t work.
- Use whatever PL/SQL insert technique you want to code a script to insert rows into the WORKERS table for four workers: JANE J. DOE, her husband JOHN J. DOE, her daughter JANIE E. DOE, and her son JOHNNIE E. DOE.
- Save your script as insert_the_doe_family.sql.
- Execute your script.
- Test your script by executing it again. Make sure you don’t get any errors but still get the desired rows in the WORKERS table.
Listing 4-6 is my solution to this exercise.
Listing 4-6. An Anonymous Procedure to Insert the Doe Family into the Worker Table, insert_the_doe_family.sql
01 rem insert_the_doe_family.sql
02 rem by Donald J. Bales on 2014-10-20
03 rem An anonymous PL/SQL procedure to insert
04 rem values using PL/SQL literals and variables
05
06 set serveroutput on size 1000000;
07
08 declare
09
10 -- I'll use this variable to hold the result
11 -- of the SQL insert statement.
12 n_count number := 0;
13
14 -- I've declared this local (or embedded) function to
15 -- do the actual work of inserting values. It uses
16 -- SQL detection to prevent DUP_VAL_ON_INDEX exceptions.
17 FUNCTION add_worker(
18 aiv_first_name WORKERS.first_name%TYPE,
19 aiv_middle_name WORKERS.middle_name%TYPE,
20 aiv_last_name WORKERS.last_name%TYPE,
21 aid_birth_date WORKERS.birth_date%TYPE,
22 aiv_gender_code GENDER_TYPES.code%TYPE,
23 aiv_worker_type_code WORKER_TYPES.code%TYPE)
24 return number is
25
26 v_name WORKERS.name%TYPE;
27
28 begin
29 v_name :=
30 rtrim(aiv_last_name||', '||aiv_first_name||' '||aiv_middle_name);
31
32 -- Now I can just let SQL do all the work. Who needs PL/SQL!
33 begin
34 insert into WORKERS (
35 id,
36 worker_type_id,
37 external_id,
38 first_name,
39 middle_name,
40 last_name,
41 name,
42 birth_date,
43 gender_type_id )
44 select WORKERS_ID.nextval,
45 c1.id,
46 lpad(to_char(EXTERNAL_ID_SEQ.nextval), 9, '0'),
47 aiv_first_name,
48 aiv_middle_name,
49 aiv_last_name,
50 v_name,
51 aid_birth_date,
52 c2.id
53 from WORKER_TYPES c1,
54 GENDER_TYPES c2
55 where c1.code = aiv_worker_type_code
56 and c2.code = aiv_gender_code
57 and not exists (
58 select 1
59 from WORKERS x
60 where x.name = v_name
61 and x.birth_date = aid_birth_date
62 and x.gender_type_id = c2.id );
63
64 return sql%rowcount;
65 exception
66 when OTHERS then
67 raise_application_error(-20001, SQLERRM||
68 ' on insert WORKERS'||
69 ' in add_worker'),
70 end;
71 end add_worker;
72
73 begin
74 -- All I have to do now, is call the add_worker function
75 -- four times with each Doe family member's values.
76 n_count := n_count + add_worker(
77 'JOHN', 'J.', 'DOE', to_date('19800101', 'YYYYMMDD'), 'M', 'C'),
78 n_count := n_count + add_worker(
79 'JANE', 'J.', 'DOE', to_date('19800101', 'YYYYMMDD'), 'F', 'E'),
80 n_count := n_count + add_worker(
81 'JOHNNY', 'E.', 'DOE', to_date('19980101', 'YYYYMMDD'), 'M', 'E'),
82 n_count := n_count + add_worker(
83 'JANIE', 'E.', 'DOE', to_date('19980101', 'YYYYMMDD'), 'F', 'E'),
84
85 pl(to_char(n_count)||' row(s) inserted.'),
86 end;
87 /
88
89 commit;
In practice, you’ll find that you primarily use an INSERT statement in PL/SQL when you do the following:
- Move data from one application to another for data migration
- Transform data for data processing
Beyond those two applications, a program written in some other programming language like Java or a data-loading utility like SQL*Loader will be used to insert values into the database.
Now that you have four entries in the WORKERS table, let’s update a couple of them!
Updates
Here, I’m talking about updating a row or rows of data in a relational database from PL/SQL. Let’s start with a simple update.
Updating a Row
Listing 4-7 is an example of using a SQL UPDATE statement in PL/SQL. It’s just a good, old-fashioned UPDATE statement, where you can also use PL/SQL literals, PL/SQL variables, or SQL functions.
Listing 4-7. An Update Example Using Variables, insert_with_plsql_detection_for_update.sql
143 begin
144 update WORKERS
145 set worker_type_id = n_worker_type_id
146 where id = n_id;
147
148 n_updated := sql%rowcount;
149 exception
150 when OTHERS then
151 raise_application_error(-20007, SQLERRM||
152 ' on update WORKERS'||
153 ' in filename insert_with_plsql_detection_for_update.sql'),
154 end;
The syntax used for the SQL UPDATE statement in Listing 4-7 is as follows:
UPDATE <table_name>
SET <column_name_1> = <column_value_1>,
<column_name_2> = <column_value_2>,...
<column_name_N> = <column_value_N>
WHERE <where_clause>;
where <table_name> is the name of the table to be updated, <column_name> is the name of a column to update, <column_value> is the corresponding value to use for the column, and <where_clause> is a WHERE clause that appropriately selects the rows to be updated.
I said it earlier, and I’ll say it again: you should almost always have a WHERE clause with an UPDATE statement. I’ve seen some really catastrophic disasters in my day when someone has executed an UPDATE statement without a WHERE clause. I even go so far as to run a PL/SQL program against the database’s source table, SYS.DBA_SOURCE, to look for UPDATE statements without WHERE clauses.
As for the code in this listing, well, there’s nothing earth-shattering about it:
- Lines 144 through 146 contain a SQL UPDATE statement to update a worker’s type if a duplicate row already exists in the database.
- Line 148 gets the result of the UPDATE statement: the number of rows updated.
- On lines 143 through 154 collectively, I’ve blocked the UPDATE statement in order to capture and report the exact type and location of any unexpected error.
The number one abuse of PL/SQL when used for data processing is using it to update values in a table in a row-by-row fashion. Why is that an abuse of PL/SQL? Because that’s what SQL is for.
Using SQL to Perform Complex Updates
The SQL UPDATE statement is very powerful. It can update one or more columns for a predetermined set of rows in a single statement. Why am I spending so much time on this soapbox about knowing SQL? The whole purpose of PL/SQL is to control when to execute an appropriate SQL statement. It is not intended to replace SQL with a bunch of poorly performing PL/SQL statements.
You can update multiple columns at a time in a SQL UPDATE statement, as demonstrated in Listing 4-8.
Listing 4-8. Updating Multiple Columns with an UPDATE Statement, update_multiple.sql
1 update WORKERS u
2 set ( u.worker_type_id, u.gender_type_id ) = (
3 select c1.id, c2.id
4 from WORKER_TYPES c1,
5 GENDER_TYPES c2
6 where c1.code = decode(instr(u.first_name, 'JOHN'), 0, 'E', 'C')
7 and c2.code = decode(instr(u.first_name, 'JOHN'), 0, 'F', 'M') )
8 where u.last_name = 'DOE';
The syntax used in the UPDATE statement in Listing 4-8 is as follows:
UPDATE <update_table_name>
SET ( <update_column_name_1>, <update_column_name_2>,... <update_column_name_N> ) =
(SELECT <select_column_name_1>, <select_column_name_2>,... <select_column_name_N>
FROM <select_table_name_1>,
<select_table_name_2>,...
<select_table_name_N>
WHERE <select_column_name_3> = <update_column_name_3>
AND <select_column_name_4> = <update_column_name_4>
AND <select_column_name_N> = <update_column_name_N> )
WHERE <update_column_name_4> = ... ;
The UPDATE statement in Listing 4-8 will set the worker type and gender type to C (contractor) and M (male), respectively, for anyone with the first name John and the last name Doe. Yes, this is a silly example, but the point here is that the use of subqueries in the SET and WHERE clauses of a SQL UPDATE statement make it possible to update almost anything. All you should need PL/SQL for is deciding when to execute an appropriate SQL UPDATE statement.
Let’s take a close look at Listing 4-8:
- Line 1 specifies the name of the table to be updated.
- Line 2 specifies a list of columns in that table to be updated. The list is enclosed in parentheses followed by an equal sign, and then an opening parenthesis, which is the start of a subquery.
- Lines 3 through 7 contain a subquery that will conditionally select which values to update the columns with based on information in the table to be updated.
- Line 3 has a list of the same number of values (columns) in the SELECT statement’s column list as in the UPDATE statement’s SET list.
- Lines 4 and 5 specify two code tables from which to draw update values.
- On line 6, I conditionally specify the code value for C (contractor) or E (employee), based on whether or not the worker’s first_name contains the string 'JOHN'.
- On line 7, I conditionally specify the code value for F (female) or M (male), based on whether or not the worker’s first name contains the string 'JOHN'.
- On line 8, I constrain the rows that will be updated to those with the last_name equal to 'DOE'.
The lesson here: know thy SQL!
As I stated earlier, in practice, you’ll primarily use an UPDATE statement in PL/SQL in the following situations:
- The conditions for updating are too complex to be determined using a SQL WHERE clause; that is, you need a more procedural decision-making process.
- Deriving the values to use to update a table’s column values is too complex to be done by SQL; that is, you need a more procedural decision-making process.
- You need to use a PL/SQL program unit’s ability to formulate a larger and more complex multistatement transaction context.
Hence, the reason PL/SQL exists: to add procedure decision-making capabilities to the use of nonprocedural SQL statements!
Guess what? There’s even less to say about deleting rows.
Deletes
In practice, the SQL DELETE command is rarely used when compared to its siblings INSERT, UPDATE, and SELECT. However, for completeness, let’s look at how you use it in PL/SQL. Listing 4-9 is an example of using a DELETE statement in PL/SQL, where I use a PL/SQL literal, a SQL function, and a subquery that uses a PL/SQL variable.
Listing 4-9. A Delete Example Using a PL/SQL Literal and Variable, delete.sql
01 rem delete.sql
02 rem by Donald J. Bales on 2014-10-20
03 rem An anonymous PL/SQL procedure to delete
04 rem rows using PL/SQL literals and variables
05
06 set serveroutput on size 1000000;
07
08 declare
09
10 -- I'll use this variable to hold the result
11 -- of the SQL delete statement.
12 n_count number;
13
14 v_code GENDER_TYPES.code%TYPE := 'M';
15
16 begin
17
18 begin
19 delete from WORKERS d
20 where d.name = 'DOE, JOHN J.' -- a literal
21 and d.birth_date = to_date('19800101', 'YYYYMMDD') -- a function
22 and d.gender_type_id = ( -- a sub-query
23 select c.id
24 from GENDER_TYPES c
25 where c.code = v_code ); -- a variable
26
27 n_count := sql%rowcount;
28 exception
29 when OTHERS then
30 raise_application_error(-20001, SQLERRM||
31 ' on delete WORKERS'||
32 ' in filename delete.sql'),
33 end;
34
35 pl(to_char(n_count)||' row(s) deleted.'),
36 end;
37 /
38
39 commit;
The syntax for the SQL DELETE statement used in Listing 4-9 is as follows:
DELETE [FROM] <delete_table_name>
WHERE <where_clause> ;
where <delete_table_name> is the name of the table from which to delete rows, and <where_clause> is a SQL WHERE clause that appropriately specifies the rows within the table to delete.
On line 27, I capture the result of the SQL DELETE statement: the number of rows deleted. Just as with an UPDATE statement, every DELETE statement should have a WHERE clause.
Let’s discuss how you might apply a DELETE statement in PL/SQL. In practice, you’ll primarily use a DELETE statement in PL/SQL when the conditions for deleting are too complex to be determined by using a WHERE clause. So you’ll find that you rarely use DELETE at all!
Finally, let’s look at the SELECT statement.
Selects
The SQL SELECT statement is the most used SQL statement in PL/SQL, and for a good reason. PL/SQL is all about encompassing set-based operations with procedural logic. Yet a SQL SELECT statement is a nonprocedural construct, hence the need for the PL in PL/SQL. In this section, I’ll discuss the singleton SELECT statement—the one that is supposed to return one row.
You’ve seen me use SELECT statements over and over again at this point. As I’ve said, I assume you already know SQL. Regardless, I’ve tried to take some time to review what you know about SQL, so you’ll be ready for PL/SQL. Most PL/SQL stored procedures you write will have one or more SELECT statements in them. So what you can accomplish using PL/SQL—whether it’s object-oriented architecture, service-oriented architecture, data processing, data migration, or reporting—will be constrained by your competency in writing a SQL SELECT statement.
Let’s look back at the first source code listing in this chapter, Listing 4-3. For your convenience (and mine), I’m going to show part of it to you again in Listing 4-10.
Listing 4-10. An Example of Using Singleton SELECT Statements in PL/SQL, insert_with_plsql_detection.sql
048 -- Next, let's get the GENDER_TYPES id for a male
049 begin
050 select id
051 into n_gender_type_id
052 from GENDER_TYPES
053 where code = 'M';
054 exception
055 when OTHERS then
056 raise_application_error(-20004, SQLERRM||
057 ' on select GENDER_TYPES'||
058 ' in filename insert_with_plsql_detection.sql'),
059 end;
060
061 -- Detect any existing entries with the unique
062 -- combination of columns as in this constraint:
063 -- constraint WORKERS_UK2
064 -- unique (
065 -- name,
066 -- birth_date,
067 -- gender_type_id )
068 begin
069 select count(1)
070 into n_count
071 from WORKERS
072 where name = v_name
073 and birth_date = d_birth_date
074 and gender_type_id = n_gender_type_id;
075 exception
076 when OTHERS then
077 raise_application_error(-20005, SQLERRM||
078 ' on select WORKERS'||
079 ' in filename insert_with_plsql_detection.sql'),
080 end;
081
082 -- Conditionally insert the row
083 if n_count = 0 then
084 -- Now, let's get the next id sequence
085 begin
086 select WORKERS_ID.nextval
087 into n_id
088 from SYS.DUAL;
089 exception
090 when OTHERS then
091 raise_application_error(-20001, SQLERRM||
092 ' on select WORKERS_ID.nextval'||
093 ' in filename insert_with_plsql_detection.sql'),
094 end;
The syntax used for the SQL SELECT statements in Listing 4-10 is as follows:
SELECT <column_name_1>,
<column_name_2>,...
<column_name_N>
INTO <plsql_variable_1>,
<plsql_variable_2>,...
<plsql_variable_N>
FROM <table_name_1>,
<table_name_2>,...
<table_name_N>
WHERE <where_clause>... ;
where <column_name> is the name of a column in one of the tables in the FROM list, <plsql_variable> is the corresponding variable to copy the column value to, <table_name> is a table to query, and <where_clause> is an appropriate WHERE clause.
Let’s examine the three SQL SELECT INTO statements in Listing 4-10:
- Lines 50 through 53 get the corresponding gender_type_id value for the code 'M'.
- Line 50 selects the column name, GENDER_TYPES.id.
- Line 51 specifies the PL/SQL variable n_gender_type_id in the INTO clause.
- Line 52 specifies the code table’s name, GENDER_TYPES.
- Line 53 specifies a WHERE clause, where the code is equal to 'M'.
- On lines 49 through 59 collectively, I block the SQL SELECT statement in order to catch and report any catastrophic errors (WHEN OTHERS). This is a SELECT statement where I don’t expect any exceptions. I always expect the corresponding values to exist in the database.
- On lines 69 through 74, I use a SQL group operator, count(), to determine the number of rows in the table that match the criteria of the associated WHERE clause.
- On lines 68 through 80 collectively, I block the SQL SELECT statement for OTHERS. This is a safe SQL SELECT statement. It will always have a result, except in the case of some unforeseeable database error.
- Lines 86 through 88 get the next sequence value for the column id from sequence WORKERS_ID.
- On lines 85 through 94 collectively, I block the SQL SELECT statement for any unforeseeable errors, but I never expect this SQL SELECT statement to raise an exception.
But what do you do if you expect an error? For example, perhaps a row matching the WHERE clause criteria is not in the table! Or maybe too many rows match the WHERE clause criteria. What do you do then?
No Data Found
As I stated earlier when I first discussed exceptions in Chapter 2, there are two very commonly used exceptions. The most commonly used exception is NO_DATA_FOUND. When a singleton SELECT statement can’t find a row to match its WHERE clause’s criteria, it will raise a NO_DATA_FOUND exception. You saw an example of this earlier in Listing 4-4. Listing 4-11 highlights the SELECT statement in question.
Listing 4-11. An Example of a SELECT Statement That May Raise a NO_DATA_FOUND Exception, insert_with_plsql_detection_for_update.sql
069 begin
070 select id
071 into n_id
072 from WORKERS
073 where name = v_name
074 and birth_date = d_birth_date
075 and gender_type_id = n_gender_type_id;
076 exception
077 when NO_DATA_FOUND then
078 n_id := NULL; -- Is this really needed?
079 when OTHERS then
080 raise_application_error(-20003, SQLERRM||
081 ' on select WORKERS'||
082 ' in filename insert_with_plsql_detection_for_update.sql'),
083 end;
This SELECT statement may raise a NO_DATA_FOUND exception because the database might not contain a matching row. As a matter of fact, that’s just what I’m trying to determine here. If the SELECT statement returns an id value, then the program knows that an entry already exists, so it will update the existing entry. Otherwise, the program will insert a new entry. It’s the otherwise condition that will raise the exception.
When the NO_DATA_FOUND exception is raised, program execution jumps from the SELECT statement directly to the enclosing WHEN NO_DATA_FOUND clause. In this case, I set the n_id to NULL in that clause, and then later in the program, I use that fact to conditionally insert a new row.
Since the SELECT statement returns one set of columns—one row—from the database, there’s no way for it to report the number of rows found, right? No, you can still get the number of rows returned from sql%rowcount. Take a look at Listing 4-12.
Listing 4-12. An Example of a SELECT Statement That Captures the Selected Row Count, select_no_data_found.sql
40 begin
41 select id
42 into n_id
43 from WORKERS
44 where name = v_name
45 and birth_date = d_birth_date
46 and gender_type_id = n_gender_type_id;
47
48 n_selected := sql%rowcount;
49 exception
50 when NO_DATA_FOUND then
51 n_selected := sql%rowcount;
52 pl('Caught raised exception NO_DATA_FOUND'),
53 when OTHERS then
54 raise_application_error(-20002, SQLERRM||
55 ' on select WORKERS'||
56 ' in filename select_no_data_found.sql'),
57 end;
In Listing 4-12, I initially set the value of n_selected to –1 just so I can prove the value is changed later in the program. If the SELECT statement executes successfully, n_selected is equal to 1 because its value is set on line 48. However, if the SELECT statement raises the NO_DATA_FOUND exception, n_selected is equal to 0 because I set its value on line 51.
The number of rows returned from the SELECT statement is reported by the database, so why do I need a NO_DATA_FOUND exception? Why does it even exist? Quite frankly, I don’t know. I think the exception exists as a matter of programming convenience. It’s syntactic sugar. So even though it breaks my “You should always maintain control in your program” rule, it’s commonly used to detect that no matching row was found for a WHERE clause’s criteria. Even I use it.
I’ll show you another tactic for detecting no data found for a singleton in the next chapter when I cover cursors. If you’re going to rely on the NO_DATA_FOUND exception, you must keep in mind that any code that comes after your SELECT statement will not be executed if your SELECT statement raises NO_DATA_FOUND.
Next, let’s look at the other singleton SELECT issue: too many rows are returned.
Too Many Rows
In the context of a singleton SELECT, PL/SQL is always going to expect your SELECT statement to return one and only one row. I just finished discussing what happens when a SELECT statement doesn’t get at least one row. So what happens when a SELECT statement gets one (or more) too many? It raises the exception TOO_MANY_ROWS. Listing 4-13 is an example of a SELECT statement that will raise the exception TOO_MANY_ROWS.
Listing 4-13. An Example of a SELECT Statement That Raises a TOO_MANY_ROWS Exception, select_too_many_rows.sql
40 begin
41 select id
42 into n_id
43 from WORKERS;
44 -- Let's comment the WHERE clause so I get all the rows
45 -- where name = v_name
46 -- and birth_date = d_birth_date
47 -- and gender_type_id = n_gender_type_id;
48 n_selected := sql%rowcount;
49 exception
50 when NO_DATA_FOUND then
51 n_selected := sql%rowcount;
52 pl('Caught raised exception NO_DATA_FOUND'),
53 when TOO_MANY_ROWS then
54 n_selected := sql%rowcount;
55 pl('Caught raised exception TOO_MANY_ROWS'),
56 when OTHERS then
57 raise_application_error(-20002, SQLERRM||
58 ' on select WORKERS'||
59 ' in filename select_too_many_rows.sql'),
60 end;
In Listing 4-13, I’ve commented out the WHERE clause so the SELECT statement will see all four Doe family entries and will raise a TOO_MANY_ROWS exception. On lines 53 through 55, I’ve also added a WHEN TOO_MANY_ROWS clause to catch the raised exception and, in turn, capture the number of rows returned by the SELECT statement.
Guess what? On line 53, sql%rowcount reports that only one row was selected. So PL/SQL has no idea how many rows actually match the query. It only knows that more than one exists, and that’s a problem—where will PL/SQL put the data from rows 2 and on? There’s actually no place for the data, so PL/SQL appropriately throws an exception. After all, the query was supposed to be a singleton query!
You can add PL/SQL code to predetect too many rows, similar to the technique demonstrated in Listing 4-3, when I was trying to predetect a duplicate row.
If count() returns a value greater than one, the program will know that there’s more than one row. But once again, PL/SQL provides some syntactic sugar that allows me to use an exception to detect a condition. Yes, again that syntactic sugar—catching a TOO_MANY_ROWS exception—breaks my rule of “You should always maintain control over your program!” I’ll admit it, I use it. I catch the exception. I don’t like it. But as I’ll show you in the next chapter, you’ll need to write a lot of extra code to maintain control, so PL/SQL programmers commonly use the exception TOO_MANY_ROWS.
Once again, if you’re going to rely on the TOO_MANY_ROWS exception, you must keep in mind that any code that comes after your SELECT statement will not be executed if your SELECT statement raises TOO_MANY_ROWS!
That’s enough of that. Now let’s see you put what I just said to work.
It’s Your Turn to Select
Your assignment is to write an anonymous procedure that displays the first name of each of the Doe family members from the WORKERS table—remember, the ones you added in the previous exercise? To that end, follow these steps.
- Write you script using at least one singleton SELECT.
- Save your script as select_the_doe_family.sql.
- Execute your script.
- Test your script by executing it again. Make sure you don’t get any errors but still get the desired rows from the WORKERS table.
Listing 4-14 is my lousy solution. Why lousy? Because my solution involves repeatedly executing a singleton SELECT statement in order to read multiple rows from the WORKERS table. I really need a better way to handle this situation, and a better solution for this problem is just what I’ll cover in the next chapter.
Listing 4-14. A Really Bad Way to Select Multiple Rows from a Table, select_the_doe_family.sql
01 rem select_the_doe_family.sql
02 rem by Donald J. Bales on 2014-10-20
03 rem An anonymous PL/SQL procedure to select
04 rem the first names for the Doe family from
05 rem the Worker table.
06
07 set serveroutput on size 1000000;
08
09 declare
10
11 v_first_name WORKERS.first_name%TYPE;
12 n_id WORKERS.id%TYPE;
13
14 -- A local function that will be called over-and-over again
15 -- to find the next first_name for the specified id
16 -- and last_name.
17 FUNCTION get_first_name(
18 aion_id in out WORKERS.id%TYPE,
19 aiv_last_name in WORKERS.last_name%TYPE)
20 return WORKERS.first_name%TYPE is
21
22 v_first_name WORKERS.first_name%TYPE;
23
24 begin
25 -- Use SQL pseudo-column rownum in order
26 -- to limit the SELECT to the first row
27 select id,
28 first_name
29 into aion_id,
30 v_first_name
31 from WORKERS
32 where id > aion_id
33 and last_name like aiv_last_name||'%'
34 and rownum = 1;
35
36 return v_first_name;
37 exception
38 when NO_DATA_FOUND then
39 return v_first_name;
40 when OTHERS then
41 raise_application_error(-20001, SQLERRM||
42 ' on select WORKERS'||
43 ' in show_worker'),
44 end get_first_name;
45
46 begin
47 -- Keep track of the primary key so you
48 -- only retrieve the SELECTed row once
49 n_id := 0;
50 -- Loop until there's NO_DATA_FOUND
51 loop
52 -- get the first name from the local function
53 v_first_name := get_first_name(n_id, 'DOE'),
54 -- detect NO_DATA_FOUND
55 if v_first_name is NULL then
56 exit; -- Exit the loop
57 end if;
58 -- show the first_name
59 pl(v_first_name);
60 end loop;
61 end;
62 /
In practice, you’ll find that you primarily use a singleton SELECT statement in PL/SQL when you want to do the following:
- Select the IDs for some code values that you will reference repeatedly
- Allocate a sequence value for a new primary key value
- Predetect the presence of a matching row
Let’s review what you’ve learned.
Summary
At this point, it should be evident that a singleton is a SQL statement that returns one row of results. Table 4-1 is a side-by-side comparison of the results returned by each of the singletons I’ve covered: INSERT, UPDATE, DELETE, and SELECT.
Table 4-1. Singleton Results for INSERT, UPDATE, DELETE, and SELECT
Statement | Returns | Common Exceptions |
|---|---|---|
INSERT INTO | Row count | DUP_VAL_ON_INDEX |
UPDATE | Row count | |
DELETE FROM | Row count | |
SELECT...INTO | Row count and column values | NO_DATA_FOUND, TOO_MANY_ROWS |
When you’re working with the INSERT INTO and SELECT...INTO statements, you may as well expect an exception and write your PL/SQL accordingly. Of the four singletons, you’ll use the SELECT statement the most. After all, you are working with a database.
The last exercise left me looking for a better solution to selecting more than one row at a time. In the next chapter, I’ll look at the PL/SQL solution to this problem: a CURSOR.