
![]()
XML Indexes
The past couple chapters focused on indexing what is commonly referred to as structured data, where there is a common schema and organization around the data and its storage. In this chapter, the indexing focus shifts to unstructured and semistructured data. With both structured and unstructured data, the task of indexing is to gain optimal efficiency for retrieving and manipulating data, but the data types that represent these types of data have differences in how they are stored in the database. These differences dictate how and why indexing is implemented as well as how the indexes are used by the query optimizer. SQL Server has a specialized data type for storing the most common type of unstructured and semistructured data, XML. This chapter explores the types of indexes offered by SQL Server for dealing with XML data. The chapter will also show the impact of those indexes on the types of queries that can be written against XML data using XQuery and the impact on the choices made by the optimizer.
XML Indexing
Extensible Markup Language (XML) was developed through the 1990s and introduced as a standard by the World Wide Web Consortium in February 1998. XML data had been stored in databases for years but was stored in SQL Server as text values since there wasn’t a specified data type. The XML data type, introduced in SQL Server 2005, was a long-awaited enhancement that extended the capabilities of SQL Server to appropriately manage this different data structure. With the acceptance of XML, the use and size of the total XML content within SQL Server databases grew. The growth was spurred by the advantages that XML offered application developers.
The introduction of the XML data type allowed for the full capability of XML storage inside a SQL Server database. This included the ability to retrieve XML contents based on queries written against the XML itself. The strongest support that XML offers developers is that it is both text-based and, nominally, self-documenting. Being text-based means that XML is easily passed from one application to another, regardless of underlying operating system or programming language. The self-documenting nature of XML means that you don’t need to actually have a structure defined in the same way as columns and tables are defined within a database. Instead, the elements and properties of the XML will tell you what they are. XML is referred to as semistructured because there is generally a template defining an expected structure in order to help validate that any given set of XML is considered to be well-formed.
Indexing XML can be a huge benefit if you are doing a lot XML processing on your system. The largest benefit for XML indexes will be in situations where you have large amounts of XML stored but you’re retrieving only small subsets of that XML. XML indexes benefit this situation greatly. If you have a lot of queries on your XML, you may also see improvements here when XML indexes are implemented.
Although the XML data type sounds like a perfect fit for every instance of XML, some considerations should be contemplated when designing a column in SQL Server that will be storing XML. One of the most critical is that the XML content should be well-formed. This ensures that the XML data type and features provided to utilize the data most efficiently are used to their full advantage. XML columns are stored as binary large objects, more commonly known as BLOBs. This storage means that runtime querying of the content is resource-intensive and slow in most cases. With any task that involves data retrieval, efficiency of that retrieval is of concern. In SQL Server, indexing is paramount to how efficient or nonefficient this can be. A complete lack of indexing or too many indexes will affect any data manipulation task. The XML data type also falls into this requirement. XML indexing is unique compared to the other indexing methods in SQL Server.
Categories
XML indexing consists of two categories: primary and secondary indexes. These two index types provide an indexing relationship within the XML documents similar to the relationship between clustered and nonclustered indexes. When implementing XML indexes, some basic rules apply to each.
- A secondary XML index cannot exist without a primary XML index.
- Primary XML indexes include paths, tags, and values of the XML content.
- Primary XML indexes cannot exist without a clustered index on the primary key of the table that the XML column is in. This clustered index is required for partitioning the table, and the XML index can use the same partitioning scheme and functioning.
- A secondary XML index extends the primary index including paths, values, and properties.
Creating an XML Index
As mentioned, the XML data type should be used with well-formed XML. To show this in more detail, let’s use a fictitious system that provides communications between cash registers and a database server. The checkout system uses XML that is built for each complete sale and then passed to SQL Server to be stored for later analysis of coupon usage trends. The XML information is received by SQL Server and is then processed and inserted into a database named AdventureWorks2014 and a table named PointOfSale. The PointOfSale definition will be shown later in this section. Before creating the table, a set of prerequisites that define and limit the XML must be created to properly administer the information being gathered. Listing 4-1 shows an example based on XML captured by this grocery checkout system.
As mentioned, well-formed XML is the preferred method of storage for taking advantage of SQL Server’s full abilities. To achieve well-formedness, the XML must follow a set of basic rules and standards involving consistency in opening and closing each tag, prevention of special characters that are utilized by XML processing (such as < and >), and consistency in creating XML data that follows a root-encapsulating tag with parent-child tags under the root tag.
As with well-formed XML, typed XML can take better advantage of the optimizer than untyped XML. To create typed XML, a schema collection must first be created. In Listing 4-2, a schema collection has been written for the XML data shown in Listing 4-1. The CREATE SCHEMA COLLECTION command is used to save the schema collection for use in validating the well-formed state of the XML data that is being processed. This must be run in the database where you’re going to store your XML data and create your XML indexes.
With the schema collection created in Listing 4-2, the table PointOfSale can now be created. The schema collection created in Listing 4-2 is assigned to the XML column in the new table. The schema collection will validate XML data that is inserted into the column. This combination of the schema collection and the XML data type on the column will allow only well-formed XML, or XML that follows the rules set by the schema collection, to be inserted into the column. Listing 4-3 shows the CREATE TABLE statement.
Listing 4-3 includes a primary key on PointOfSaleID. This primary key is the clustered index for PointOfSale. The importance of the existence of a clustered index and primary key will be shown later when creating other indexes on the XML data.
With the table and schema collection created, you can insert the XML information shown in Listing 4-1 into the table. The script in Listing 4-4 provides an example of inserting the XML value into PointOfSale.
To query this data, you can use distinct XML data type methods built into SQL Server. These include query(), value(), exist(), modify(), and nodes(). For example, Listing 4-5 is a query using the query() method to retrieve a full XML representation of the TotalSales.
Figure 4-1 shows the result from executing this query.

Figure 4-1. An XML query using query( ) and its result
This query approach is efficient with a small amount of data in the table. However, in real life, tables can become quite large, surpassing the point in which scanning through multiple XML documents is efficient. For instance, imagine if a point-of-sale system stored receipt information in XML documents for each sale. With this kind of data volume, performance would begin to suffer quickly. So, let’s look to indexing in order to retrieve the data as efficiently as possible.
At this point, you’ll look at the syntax for creating indexes, but I’m not going to run the scripts yet. I suggest you just follow along and create the following XML indexes. To create either a primary or secondary index on an XML column, you use the CREATE INDEX syntax. (You can find it in Chapter 1.) To create a secondary index, a primary index must first be created or be preexisting on the table. Listing 4-6 shows the basic syntax for creating a primary index.
Once you have a primary index, you can create a secondary index; the syntax for doing so is shown in Listing 4-7.
![]() Caution If you create and then drop a primary XML index, any secondary XML indexes will also be dropped because they are dependent on the primary. No warning will be shown for this action.
Caution If you create and then drop a primary XML index, any secondary XML indexes will also be dropped because they are dependent on the primary. No warning will be shown for this action.
The primary XML index essentially is a shredded version of the XML content that is stored in the XML column. As with all indexes, the data management view sys.dm_db_index_physical_stats can be used to review the index in detail. Reviewing the data returned by a query against the view shows a distinct difference in the size of the index versus the clustered index. This size difference is important to take into account because XML indexing will take approximately three to four times the space of the column itself. This is because of the nature of XML indexes and how the contents of the XML are shredded into a table format.
Listing 4-8 is a query against sys.dm_db_index_physical_stats. Figure 4-2 shows the results.

Figure 4-2. sys.dm_db_index_physical_stats query results showing space utilization of indexes
Although sys.dm_db_index_physical_stats is beneficial for finding information needed to maintain all indexes, including XML indexes, there is a system view specifically for XML indexing named sys.xml:indexes. This system view shows all the options that have been applied to an XML index. Information returned by the view can be useful in further maintaining an index, by knowing the type and other options set. This view is inherited from sys.indexes and returns the same columns and information as sys.indexes. The following additional columns also exist:
- using_xml:index_id: The parent index to a secondary index. As discussed, secondary indexes require a primary index to exist before creation. This column will be NULL for primary XML indexes and used only for secondary indexes.
- secondary_type: A flag specifying the type upon which a secondary index is based. Each secondary index is based on a specific type (V = VALUE, P = PATH, R = PROPERTY). For primary XML indexes, this column is NULL.
- secondary_type_desc: A description of the secondary index type. The values for the description map to those described in the secondary_type column.
Until now I have provided a basic overview of the primary and secondary XML indexes. Now let’s look at the effect XML indexes can have on the query optimizer as evidenced in execution plans. I’ll begin with an example.
In the previous example of the grocery store system, coupon data was collected for use in analyzing sales. This data may prove useful in a later query for the use of coupons that save customers money on a specific product. Let’s say that the sales team wants to look into Jif peanut butter coupon usage. To do this, the developer writing a query to retrieve this data could use the .value and .exist methods, as shown in Listing 4-9.
This query returns all the XML content for NetPrice and the coupon savings the customer had in CouponPrice. I'm assuming you have not created XML indexes on the table yet (and if you have, just drop the primary such index to remove it and any secondary indexes). As shown in Figure 4-3, extremely high-cost operations have to be used by the optimizer to satisfy this query. The first operation that is significant is the Table Valued function based on an XML Reader with an XPath Filter; there are then two more Table Valued functions using the XML Reader. The total estimated cost to the entire query for these operations, if there is no index in place, is 90 percent.

Figure 4-3. Execution plan results from query using no XML index
The execution plan in Figure 4-3 shows the XML content being shredded by Table Valued function operations, which are extremely slow and resource-intensive processes overall. Creating a primary XML index on XMLValue in PointOfSale will greatly benefit this query because it will provide the means for the optimizer to perform an index seek.
Effects from a Primary Index
You can create a primary XML index with the syntax shown in Listing 4-10.
Now rerun the query and capture the execution plan to see the changes made by the creation of the index. You can see that the execution plan takes on an extremely different pattern, as shown in Figure 4-4. This pattern revolves around the use of the primary XML index you created as an XML index. This indexing change will dramatically decrease the total duration of the query itself.

Figure 4-4. Execution plans generated after the creation of a primary index
You can now see that the optimizer is able to make choices that are more evenly balanced. The Clustered Index Scan of the PointOfSale table is actually as high an estimated cost as the Clustered Index Seeks against the XML index you created. This shift in where the work is occurring within the query engine will result in improved performance.
Effects from a Secondary Index
In the previous section, you used a primary XML index to improve a basic query. There will be times, though, when greater improvement is desired. In these cases, secondary XML indexes can be an option. In the next set of examples, you will look at how a secondary index will improve the performance of the queries on the sample table and XML column. As mentioned, a secondary index consists of a path, value, and property. The path is typically helpful for looking directly at the paths in the content without the use of wildcards. Let’s take a simple example (see Listing 4-11).
If you run this query and capture the execution plan, you can see that the primary index will be used to satisfy the query, as shown in Figure 4-5.
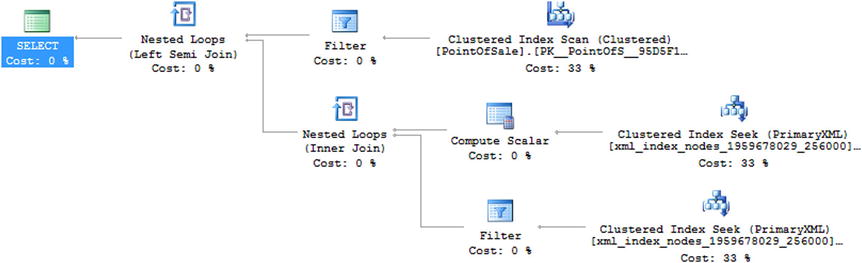
Figure 4-5. Execution plan looking for a date using primary XML index
Applying a secondary index to the XML that is focused on the PATH can add benefits to an exist() query of this type. To create a secondary XML index on PATH, use the statement in Listing 4-12.
The new execution plan, shown in Figure 4-6, shows the changes that have occurred because of the secondary index using the PATH.
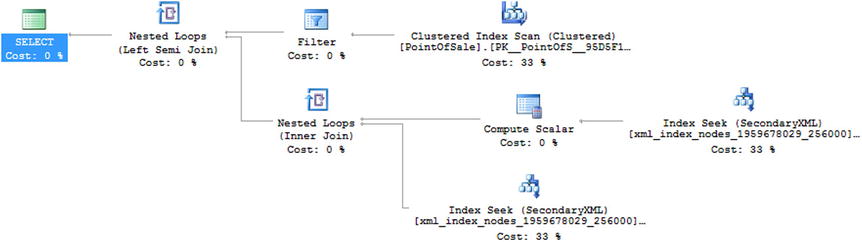
Figure 4-6. New execution plan using secondary index
If you compare the plans shown in Figures 4-5 and 4-6, you can see that a Filter operation has been removed and that the secondary XML index is being used instead of the primary. If you capture the query performance metrics (in this case I used Extended Events to capture sql_batch_completed), you can also compare them as shown in Figure 4-7.

Figure 4-7. Differences in execution time and resources caused by secondary XML index
Let’s take a closer look at the same query in terms of XML indexing. The query could benefit from a VALUE secondary index instead. This is because of the predicate searching for the date February 2, 2010. In this case, the optimizer won’t choose a value index over a path index, so you’ll need to drop the PATH index. Then, create another secondary index with type VALUE, as shown in Listing 4-13.
As shown in Figure 4-8, the IDX_SEC_VALUE index is taken over the IDX_SEC_PATH index for the same secondary XML operation. This choice is visible if you right-click the Index Seek operator and select properties.secondaryXML operation.

Figure 4-8. Properties of the Index Seek on a VALUE secondary index
The execution time was slightly improved, and all the other resources were approximately the same.
Let’s take things further now and show just how different an effect secondary index types can have on the same query based on the index type that is created. In all, this query would be optimized under a primary XML index and a secondary value-based index. However, if all three secondary indexes are created, the query optimizer may tend to utilize the property and path indexes over either the primary or VALUE secondary indexes. This may not be ideal given storage and overall execution times. For example, if a primary index alone can be used and optimal execution times can be met, then a secondary index may not be beneficial. The same situation exists if the correct secondary index is created and optimal execution times are achieved. Creating more secondary indexes would affect the overall performance of other operations on the table such as INSERT, UPDATE, and DELETE.
To illustrate, re-create the index from Listing 4-12 and create the third secondary index type of PROPERTY, as shown in Listing 4-14.
Running the query again from Listing 4-11 with all three secondary indexes produces the plan in Figure 4-9.

Figure 4-9. Execution plan results from the existence of a primary index and three secondary indexes
Both the secondary indexes IDX_SEC_VAL and IDX_SEC_PROP are used, contrary to the tendency within the optimizer. In this case, you could experiment with different combinations of secondary indexes to see which ones work the best. Now drop both the PATH and PROPERTY indexes (see Listing 4-15).
Then execute the query again. Figure 4-10 shows the resulting statistics, once more collected using Extended Events, from the primary index and secondary index used in the execution plan.

Figure 4-10. Differences in duration and reads caused by different secondary index choices
This is an example of a comparable execution utilizing different secondary indexes, with a slight advantage over the use of the primary XML index combined with secondary value index in the number of scans performed. The result from this one query and different utilization of the secondary indexes shows there is value in knowing how each will possibly benefit from querying the XML content. This, as well as the storage needs of each secondary index, will weigh on whether either is created.
Secondary indexes provide a lot of benefit when there are multiple unique values in the XML content. In many cases, though, a primary XML index will be sufficient. There are a number of other things to keep in mind when building secondary XML indexes. First, creating XML indexes takes a large amount of storage. Also, think about nodes and paths to indexes based on queries that will be encountered in the system. Strive to strike a balance between hardware resources, storage, index usefulness, number of indexes created, and number of times an index may actually be needed when building XML indexes.
Introduced in SQL Server 2012, selective XML indexes address a significant problem with XML indexes. XML documents can be extremely large. Applying an index to the entire document has major performance implications both for creating the index and for maintaining it over time. Also, these excessively large indexes can add to the storage woes that are a frequent problem within organizations. Also, when an index becomes excessively large, it may not function as well as it did when it was smaller. Because of all this, the selective XML index was introduced.
Selective XML indexes allow you to define a subset of the XML document that you want to index. This makes for smaller, more agile indexes that are targeted to specific paths within the XML. When the index gets created, the document is parsed, and the XML is shredded. The shredded values are then stored in standard relational storage within your database. In addition to the selective XML index, you can add secondary indexes based on the nodes within the path that defines the selective XML index.
Selective XML indexes can achieve large performance benefits over a standard XML index. However, if you have ad hoc queries that may go for all sorts of different elements within the XML document, the standard XML index may perform much better. Also, if you have a large number of node paths, you may see better performance from the standard XML index.
To create a selective XML index, you must meet the following criteria:
- The table must have a clustered primary key.
- The key size is limited to 128 bytes.
- The key columns are limited to 15.
The selective XML will not be used for query() or modify() methods within your XQuery statements. It will support exist(), value(), and nodes(). If you use query() and modify() together, it will assist a simple node lookup, but that’s all.
To see the selective XML index in action, you’ll need to create one. The script in Listing 4-16 creates a path within the selective XML index.
This will create the index using the same structures used throughout the rest of the chapter, without interfering with them. Again, creating more indexes than strictly satisfying the needs of your system will add additional overhead to the system and should be avoided. While you can have only a single selective XML index, you can specify more than one path within the index. Also exercise caution here because you don’t want to make this index overly large again and defeat the purpose of its use.
To see this query in action, you’ll need to drill down on one of the values on which you’ve created this selective XML index. The query in Listing 4-17 will look for the existence of any values above a certain point in the CouponPrice.
The query optimizer picks up on the fact that there is a new index in place and that this index can satisfy this query. Figure 4-11 shows the resulting execution plan.

Figure 4-11. Execution plan showing a selective XML index in use
You can see that the index that was created has been used and shows up as a Clustered Index Seek operation. You can see some interesting internals on how these indexes operate by looking at the properties of the operator, as shown in Figure 4-12.

Figure 4-12. Properties of the clustered index seek operation
Looking at the object properties, you can see the index in use, IDX_SEL_XML, and the type of index that it represents, SelectiveXML. But, you can also see the system table that has been generated for holding the XML data in its shredded form, xml:sxi_table_1959678029_256000. You can’t query that table directly, but you can see how SQL Server is managing this index. You can even see a column name in the Output List entry, CouponPrice_1_value. Finally, the Predicate value shows how the search against the index is performed.
While the selective XML index is a more complicated aspect of XML indexing, you can see that getting started with them is not that difficult. The selective XML index also supports more sophisticated XQuery than the examples in this chapter so that you can be extremely precise in exactly which segments of your XML document will be indexed.
Summary
This chapter covered the need to be able to search and index the unstructured and semistructured data that can now be stored within SQL Server. XML indexes provide developers and database administrators with the options to improve the performance of searches through XML documents. This benefits queries both by filtering data in XML documents and by retrieving the data for display. Selective XML indexes offer the opportunity to get a more granular and detailed approach to your XML indexing. Just remember that XML indexes require quite considerable additional disk space, so you should plan your systems accordingly.