
![]()
This chapter discusses memory-optimized tables in detail. It shows how memory-optimized tables store their data and how SQL Server accesses them. It covers the format of the data rows in memory-optimized tables and talks about the process of native compilation.
Finally, the chapter provides an overview of the memory-optimized tables limitations that exist in the first release of the In-Memory OLTP Engine.
On-Disk vs. Memory-Optimized Tables
Data and index structures in memory-optimized tables are different from those in on-disk tables. In on-disk tables, the data is stored in the 8KB data pages grouped together in eight-page extents on per-index or per-heap basis. Every page stores the data from one or multiple data rows. Moreover, the data from variable-length or LOB columns can be stored off-row on ROW_OVERFLOW and LOB data pages when it does not fit on one in-row page.
All pages and rows in on-disk tables are referenced by in-file offsets, which is the combination of file_id, data page offset/position in the file and, in case of a data row, row offset/position on the data page.
Finally, every nonclustered index stores its own copy of the data from the index key columns referencing the main row by row-id, which is either the clustered index key value or a physical address (offset) of the row in the heap table.
Figures 3-1 and 3-2 illustrate these concepts. They show clustered and nonclustered index B-Trees defined on a table. As you see, pages are linked through in-file offsets. The nonclustered index persists the separate copy of the data and references the clustered index through clustered index key values.

Figure 3-1. Clustered index on on-disk tables
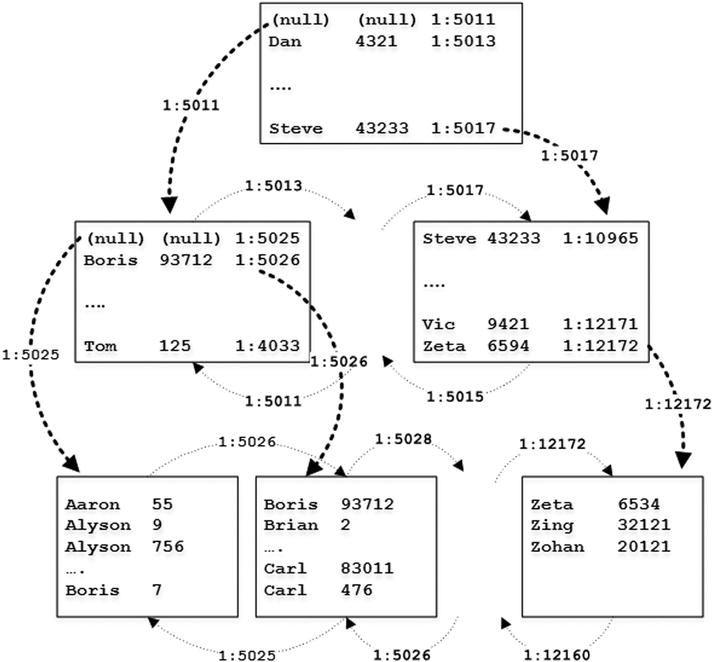
Figure 3-2. Nonclustered index on on-disk tables
Every time you need to access the data from the page, SQL Server loads the copy of the page to the memory, caching it in the buffer pool. However, the format and structure of the data page in the buffer pool does not change, and pages there still use in-file offsets to reference each other. The SQL Server component called the Buffer Manager manages the buffer pool, and it tracks the data page’s in-memory locations, translating in-file offsets to the corresponding memory addresses of the page structures.
Consider the situation when SQL Server needs to scan several data pages in the index. The Scheduler requests the page from the Buffer Manager, using file_id and page_id to identify it. The Buffer Manager, in turn, checks if the page is already cached, reading it from disk when necessary. When the page is read and processed, SQL Server obtains the address of the next page in the index and repeats the process.
It is also entirely possible that SQL Server needs to access multiple pages in order to read a single row. This happens in case of off-row storage and/or when the execution plan uses nonclustered indexes and issues Key or RID Lookup operations, obtaining the data from the clustered index or heap.
The process of locating a page in the buffer pool is very fast; however, it still introduces overhead that affects performance of the queries. The performance hit is much worse when the data page is not in memory and a physical I/O operation is required.
The In-Memory OLTP Engine uses a completely different approach with memory-optimized tables. With the exception of Bw-Trees in nonclustered indexes, which I will discuss in Chapter 5, in-memory objects do not use data pages. Data rows reference each other through the memory pointers. Every row knows the memory address of a next row in the chain, and SQL Server does not need to do any extra steps to locate it.
Every memory-optimized table has at least one index row chain to link rows together and, therefore, every table must have at least one index defined. In the case of durable memory-optimized tables, there is the requirement of creating a primary key constraint, which can serve for such a purpose.
To illustrate the concepts of row chains, let’s create the memory-optimized table as shown in Listing 3-1.
This table has two hash indexes defined on the Name and City columns. I am not going to discuss hash indexes in depth here but as a general overview, they consist of a hash table (an array of hash buckets), each of which contains a memory pointer to the data row. SQL Server applies a hash function to the index key columns, and the result of the function determines to which bucket a row belongs. All rows that have the same hash value and belong to the same bucket are linked together in a row chain; every row has a pointer to the next row in a chain.
![]() Note I will discuss hash indexes in detail in Chapter 4.
Note I will discuss hash indexes in detail in Chapter 4.
Figure 3-3 illustrates this. Solid arrows represent pointers in the index on the Name column. Dotted arrows represent pointers in the index on the City column. For simplicity sake, let’s assume that the hash function generates a hash value based on the first letter of the string. Two numbers, displayed in each row, indicate row lifetime, which I will explain in the next section of this chapter.

Figure 3-3. Memory-optimized table with two hash indexes
In contrast to on-disk tables, indexes on memory-optimized tables are not created as separate data structures but rather embedded as pointers in the data rows, which, in a nutshell, makes every index covering.
![]() Note To be precise, nonclustered indexes on memory-optimized tables introduce additional data structures in memory. However, they are much more efficient compared to nonclustered indexes on on-disk tables and do not require Key or RID Lookup operations to access the data. I will discuss nonclustered indexes in details in Chapter 5.
Note To be precise, nonclustered indexes on memory-optimized tables introduce additional data structures in memory. However, they are much more efficient compared to nonclustered indexes on on-disk tables and do not require Key or RID Lookup operations to access the data. I will discuss nonclustered indexes in details in Chapter 5.
Introduction to the Multiversion Concurrency Control
As you already noticed in Figure 3-3, every row in a memory-optimized table has two values, called BeginTs and EndTs, which define the lifetime of the row. A SQL Server instance maintains the Global Transaction Timestamp value, which is auto-incremented when the transaction commits and is unique for every committed transaction. BeginTs stores the Global Transaction Timestamp of the transaction that is inserted a row, and EndTs stores the timestamp of the transaction that deleted a row. A special value called Infinity is used as EndTs for the rows that have not been deleted.
The rows in memory-optimized tables are never updated. The update operation creates the new version of the row with the new Global Transaction Timestamp set as BeginTs and marks the old version of the row as deleted by populating the EndTs timestamp with the same value.
Every transaction has a transaction timestamp, which is the Global Transaction Timestamp value at the moment the transaction starts. BeginTs and EndTs control the visibility of a row for the transactions. A transaction can see a row only when its transaction timestamp is between the BeginTs and EndTs timestamps of the row.
To illustrate that, let’s assume that we ran the statement shown in Listing 3-2 and committed the transaction when the Global Transaction Timestamp value was 100.
Figure 3-4 illustrates the data in the table after an update transaction has been committed. As you see, we now have two rows with Name=’Ann’ and different lifetime. The new row has been appended to the row chain referenced by the hash backet for the value of ’A’ in the index on the Name column. The hash index on City column did not have any rows referenced by the ’C’ bucket, therefore the new row becomes the first in the row chain referenced from that bucket.

Figure 3-4. Data in the table after update
Let’s assume that you need to run a query that selects all rows with Name=’Ann’ in the transaction, which started when the Global Transaction Timestamp was 110. SQL Server calculates the hash value for Ann, which is ’A’, and finds the corresponding bucket in the hash index on the Name column. It follows the pointer from that bucket, which references a row with Name=’Adam’. This row has BeginTs of 10 and EndTs of Infinity; therefore, it is visible to the transaction. However, the Name value does not match the predicate and the row is ignored.
In the next step, SQL Server follows the pointer from the Adam index pointer array, which references the first Ann row. This row has BeginTs of 100 and EndTs of Infinity; therefore, it is visible to the transaction and needs to be selected.
As a final step, SQL Server follows the next pointer in the index. Even though the last row also has Name=’Ann’, it has EndTs of 100 and is invisible to the transaction.
As you should have already noticed, this concurrency behavior and data consistency corresponds to the SNAPSHOT transaction isolation level when every transaction sees the data as of the time transaction started. SNAPSHOT is default transaction isolation level in the In-Memory OLTP Engine, which also supports REPEATABLE READ and SERIALIZABLE isolation levels. However, REPEATABLE READ and SERIALIZABLE transactions in In-Memory OLTP behave differently than with on-disk tables. In-Memory OLTP raises an exception and rolls back a transaction if REPEATABLE READ or SERIALIZABLE data consistency rules were violated rather than blocks a transacton as with on-disk tables.
In-Memory OLTP documentation also indicates that autocommitted (single statement) transactions can run in READ COMMITTED isolation level. However, this is a bit misleading. SQL Server promotes and executes such transactions in the SNAPSHOT isolation level and does not require you to explicitly specify the isolation level in your code. The Autocommitted READ COMMITTED transaction would not see the changes committed after the transaction started, which is a different behavior compared to the READ COMMITTED transactions against on-disk tables.
![]() Note I will discuss concurrency model in In-Memory OLTP in Chapter 7.
Note I will discuss concurrency model in In-Memory OLTP in Chapter 7.
SQL Server keeps track of the active transactions in the system and detects stale rows with the EndTs timestamp older than the Global Transaction Timestamp of the oldest active transaction in the system. Stale rows are invisible for active transactions in the system, and eventually they are removed from the index row chains and deallocated by the garbage collection process.
![]() Note The garbage collection process is covered in more detail in Chapter 9.
Note The garbage collection process is covered in more detail in Chapter 9.
Data Row Format
As you can guess, the format of the data rows in memory-optimized tables is entirely different from on-disk tables and consists of two different sections, Row Header and Payload, as shown in Figure 3-5.

Figure 3-5. The structure of a data row in a memory-optimized table
You are already familiar with the BeginTs and EndTs timestamps in the row header. The next element there is StmtId, which references the statement that is inserted that row. Every statement in a transaction has a unique 4-byte StmtId value, which works as a Halloween protection technique and allows the statement to skip rows it just inserted.
HALLOWEEN PROTECTION
The Halloween effect is a known problem in the relation databases world. It was discovered by IBM researchers almost 40 years ago. In a nutshell, it refers to the situation when the execution of a data modification query is affected by the previous modifications it performed.
You can think of the following statement as a classic example of the Halloween problem:
insert into T
select * from T
Without Halloween protection, this query would fall into an infinitive loop, reading the data it just inserted, and inserting it over and over again.
With on-disk tables, SQL Server implements Halloween protection by adding spool operators to the execution plan. These operators create a temporary copy of the data before processing it. In our example, all data from the table is cached in the Table Spool first, which will work as the source of the data for the insert.
StmtId helps to avoid the Halloween problem in memory-optimized tables. Statements check the StmtId of the rows, and skip those they just inserted.
The next element in the header, the 2-byte IdxLinkCount, indicates how many indexes (pointers) reference the row (or, in the other words, in how many index chains this row is participating). SQL Server uses it to detect rows that can be deallocated by the garbage collection process.
An array of 8-byte index pointers is the last element of the row header. As you already know, every memory-optimized table should have at least one index to link data rows together. At most, you can define eight indexes per memory-optimized table, including the primary key constraint.
The actual row data is stored in the Payload section of the row. The Payload format may vary depending on the table schema. SQL Server works with the Payload through a DLL that is generated and compiled for the table (more on that in the next section of this chapter).
I would like to reiterate that a key principle of In-Memory OLTP is that Payload data is never updated. When a table row needs to be updated, In-Memory OLTP deletes the version of the row by setting the EndTs attribute of the original row and inserts the new data row version with the new BeginTs value and an EndTs value of Infinity.
Native Compilation of Memory-Optimized Tables
One of the key differences between the Storage and In-Memory OLTP Engines resides in how engines work with row data. The data in on-disk tables is always stored using the same and pre-defined data row format. Strictly speaking, there are several different storage formats based on data compression settings and type of rows; however, the number of possible formats are very small and they do not depend on the table schema. For example, clustered indexes from the multiple tables defined with the same data compression option would store the data in the same way regardless of the tables’ schemas.
As usual, that approach comes with benefits and downsides. It is extremely flexible and allows us to alter a table and mix per- and post-altered versions of the rows together. For example, adding a new nullable column to the table is the metadata-level operation, which does not change existing rows. The Storage Engine analyzes table metadata and different row attributes, and handles multiple versions of the rows correctly.
However, such flexibility comes at cost. Consider the situation when the query needs to access the data from the variable-length column in the row. In this scenario, SQL Server needs to find the offset of the variable-length array section in the row, calculate an offset and length of the column data from that array, and analyze if the column data is stored in-row or off-row before getting the required data. All of that can lead to thousands of CPU instructions to execute.
The In-Memory OLTP Engine uses a completely opposite approach. SQL Server creates and compiles the separate DLLs for every memory-optimized table in the system. Those DLLs are loaded into the SQL Server process, and they are responsible for accessing and manipulating the data in Payload section of the row. The In-Memory OLTP Engine is generic and it does not know anything about underlying row structures; all data access is done through those DLLs.
As you can guess, this approach significantly reduces processing overhead; however, it comes at the cost of reduced flexibility. In the first release of In-Memory OLTP, generated DLLs require all rows to have the same structure and, therefore, it is impossible to alter the table after it is created.
This restriction can lead to supportability and performance issues when tables and indexes are defined incorrectly. One such example is the wrong hash index bucket count estimation, which can lead to an excessive number of rows in the row chains, which reduces index seek performance. I will discuss this problem in detail in Chapter 4.
![]() Note SQL Server places the source code and compiled dlls in the XTP subfolder of the SQL Server DATA directory. I will talk about those files and the native compilation process in more detail in Chapter 6.
Note SQL Server places the source code and compiled dlls in the XTP subfolder of the SQL Server DATA directory. I will talk about those files and the native compilation process in more detail in Chapter 6.
Memory-Optimized Tables: Surface Area and Limitations
The first release of the In-Memory OLTP Engine has an extensive list of limitations. Let’s look at those limitations in detail.
Supported Data Types
As mentioned, memory-optimized tables do not support off-row storage and do restrict the maximum data row size to 8,060 bytes. Therefore, only a subset of the data types is supported. The supported list includes:
- bit
- Integer types: tinyint, smallint, int, bigint
- Floating and fixed point types: float, real
- numeric, and decimal. The In-Memory OLTP Engine uses either 8 or 16 bytes to store such data types, which is different from on-disk tables where storage size can be 5, 9, 13, or 17 bytes, depending on precision.
- Money types: money and smallmoney
- Date/time types: smalldatetime, datetime, datetime2, date, and time. The In-Memory OLTP Engine uses 4 bytes to store values of date data type and 8 bytes for the other data types, which is different from on-disk tables where storage size is based on precision.
- uniqueidentifiers
- Non-LOB string types: (n)char(N), (n)varchar(N), and sysname
- Non-LOB binary types: binary(N) and varbinary(N)
Unfortunately, you cannot use any data types that use LOB storage. None of the following data types are supported: (n)varchar(max), xml, clr data types, (n)text, and image.
It is also worth remembering that the maximum row size limitation of 8,060 bytes applies to the size of the columns in table definition rather than to the actual row size. For example, it is impossible to define memory-optimized tables with two varchar(4100) columns even if you plan to keep data row sizes below the 8,060 bytes threshold.
Constraints and Table Features
In addition to the limited set of supported data types and inability to alter the table, memory-optimized tables have other requirements and limitations. None of the following objects are supported:
- FOREIGN KEY constraints
- CHECK constraints
- UNIQUE constraints or indexes with exception of the PRIMARY KEY
- DML triggers
- IDENTITY columns with SEED and INCREMENT different than (1,1)
- Computed and sparse columns
- Non-binary collations for the text columns participating in the indexes
- Nullable indexed columns. A column can be defined as nullable when it does not participate in the indexes.
Every memory-optimized table, durable or non-durable, should have at least one and at most eight indexes. Moreover, the durable memory-optimized table should have a unique primary key constraint defined. This constraint is counted as one of the indexes towards the eight-index limit.
If is also worth noting that columns participating in the primary key constraint are non-updatable. You can delete the old and insert the new row as the workaround.
Database-Level Limitations
In-Memory OLTP has several limitations that affect some of the database settings and operations. They include the following:
- You cannot create a Database Snapshot on databases that use In-Memory OLTP.
- The AUTO_CLOSE database option must be set to OFF.
- CREATE DATABASE FOR ATTACH_REBUILD_LOG is not supported.
- DBCC CHECKDB skips the memory-optimized tables.
- DBCC CHECKTABLE fails if called to check memory-optimized table.
![]() Note You can see the full list of limitations in the first release of the In-Memory OLTP at http://msdn.microsoft.com/en-us/library/dn246937.aspx.
Note You can see the full list of limitations in the first release of the In-Memory OLTP at http://msdn.microsoft.com/en-us/library/dn246937.aspx.
High Availability Technologies Support
Memory-optimized tables are fully supported in an AlwaysOn Failover Cluster and Availability Groups, and with Log Shipping. However, in the case of a Failover Cluster, data from durable memory-optimized tables must be loaded into memory in case of a failover, which could increase failover time.
In the case of AlwaysOn Availability Groups, only durable memory-optimized tables are replicated to secondary nodes. You can access and query those tables on the readable secondary nodes if needed. Data from non-durable memory-optimized tables, on the other hand, is not replicated and will be lost in the case of a failover.
You can set up transactional replication on databases with memory-optimized tables; however, those tables cannot be used as articles in publications.
In-Memory OLTP is not supported in database mirroring sessions. This does not appear to be a big limitation, however. In-Memory OLTP is an Enterprise Edition feature, which allows you to replace database mirroring with AlwaysOn Availability Groups.
Summary
As the opposite to on-disk tables, where data is stored in 8KB data pages, memory-optimized tables link data rows into the index row chains using regular memory pointers. Every row has multiple pointers, one per index row chain. Every table must have at least one and at most eight indexes defined.
A SQL Server instance maintains the Global Transaction Timestamp value, which is auto-incremented when the transaction commits and is unique for every committed transaction. Every data row has BeginTs and EndTs timestamps that define row lifetimes. A transaction can see a row only when its transaction timestamp (timestamp at time when transaction starts) is between the BeginTs and EndTs timestamps of the row.
Row data in memory-optimized tables are never updated. When a table row needs to be updated, In-Memory OLTP creates the new version of the row with new BeginTs value and deletes the old version of the row by populating its EndTs timestamp.
SQL Server generates and compiles native DLLs for every memory-optimized table in the system. Those DLLs are loaded into the SQL Server process, and they are responsible for accessing and manipulating the row data.
The first release of In-Memory OLTP has an extensive list of limitations. Those limitations include the inability to alter the table after it is created; a 8,060 byte maximum data row size limit without any off-row storage support; the inability to define triggers, foreign key, check, and unique constraints on tables; and quite a few others.
The In-Memory OLTP Engine is fully supported in AlwaysOn Failover Clusters, Availability Groups, and Log Shipping. Databases with memory-optimized tables can participate in transactional replication; however, you cannot replicate memory-optimized tables.