
![]()
Transaction Processing in In-Memory OLTP
This chapter discusses transaction processing in In-Memory OLTP. It elucidates what isolation levels are supported with native compilation and cross-container transactions, provides an overview of concurrency phenomena encountered in the database systems, and explains how In-Memory OLTP addresses them. Finally, this chapter talks about the lifetime of In-Memory OLTP transactions in detail.
ACID, Transaction Isolation Levels, and Concurrency Phenomena Overview
Transactions are the unit of work that read and modify data in a database and help to enforce consistency and durability of the data in a system. Every transaction in a properly implemented transaction management system has four different characteristics known as atomicity, consistency, isolation, and durability, often referenced as ACID.
- Atomicity guarantees that each transaction executes as an “all or nothing” approach. All changes done within a transaction are either committed or rolled back in full. Consider the classic example of transferring money between checking and savings bank accounts. That action consists of two separate operations: decreasing the balance of the checking account and increasing the balance of the savings account. Transaction atomicity guarantees that both operations either succeed or fail together, and a system will never be in the situation when money was deducted from the checking account but never added to the savings account.
- Consistency ensures that any database transaction brings the database from one consistent state to another and none of defined database rules and constraints were violated.
- Isolation ensures that the changes done in the transaction are isolated and invisible to other transactions until the transaction is committed. By the book, transaction isolation should guarantee that concurrent execution of the multiple transactions should bring the system to the same state as if those transactions were executed serially. However, in most database systems, such a requirement is often relaxed and controlled by transaction isolation levels.
- Durability guarantees that after a transaction is committed, all changes done by the transaction stay permanent and will survive a system crash. SQL Server achieves durability by using Write-Ahead Logging hardening log records in transaction log synchronously with data modifications.
The isolation requirements are the most complex to implement in multi-user environments. Even though it is possible to completely isolate different transactions from each other, this could lead to a high level of blocking and other concurrency issues in systems with volatile data. SQL Server addresses this situation by introducing several transaction isolation levels that relax isolation requirements at the cost of possible concurrency phenomena related to read data consistency:
- Dirty Reads: A transaction reads uncommitted (dirty) data from other uncommitted transactions.
- Non-Repeatable Reads: Subsequent attempts to read the same data from within the same transaction return different results. This data inconsistency issue arises when the other transactions modified, or even deleted, data between the reads done by the affected transaction.
- Phantom Reads: This phenomenon occurs when subsequent reads within the same transaction return new rows (the ones that the transaction did not read before). This happens when another transaction inserted the new data in between the reads done by the affected transaction.
Table 7-1 shows the data inconsistency issues that are possible for different transaction isolation levels. It is worth mentioning that every isolation level resolves write/write conflicts, preventing multiple active transactions from updating the same rows simultaneously.
Table 7-1. Transaction Isolation Levels and Concurrency Phenomena

With the exception of the SNAPSHOT isolation level, SQL Server uses locking to address concurrency phenomena when dealing with on-disk tables. When a transaction modifies a row, it acquires exclusive (X) locks on the row and holds it until the end of the transaction. That exclusive (X) lock prevents other sessions from accessing uncommitted data until the transaction is completed and the locks are released. This behavior is also known as pessimistic concurrency.
Such behavior also means that, in the case of a write/write conflict, the last modification wins. For example, when two transactions are trying to modify the same row, SQL Server blocks one of them until another transaction is committed, allowing blocked transactions to modify the data afterwards. No errors or exceptions are raised; however, changes done by the first transaction are overwritten.
In the case of on-disk tables and pessimistic concurrency, transaction isolation levels control how a session acquires and releases shared (S) locks when reading the data. Table 7-2 demonstrates that behavior.
Table 7-2. Transaction Isolation Levels and Shared (S) Locks Behavior with On-disk Tables
Isolation Level | Shared (S) Locks Behavior | Comments |
|---|---|---|
READ UNCOMMITTED | (S) locks not acquired | Transaction can see uncommitted changes from the other sessions (dirty reads) |
READ COMMITTED | (S) locks acquired and released immediately | Transaction will be blocked when it tries to read uncommitted rows with exclusive (X) locks held by the other sessions (no dirty reads) |
REPEATABLE READ | (S) locks acquired and held till the end of transaction | Other sessions cannot modify a row after it was read (no non-repeatable reads). However, they can still insert phantom rows |
SERIALIZABLE | Range (S) locks acquired and held till end of transaction | Other sessions cannot modify a row after it was read nor insert new rows in between rows that were read (no non-repeatable or phantom reads) |
The SNAPSHOT isolation level uses a row-versioning model by creating the new version of the row after modification. In this model, all data modifications done by other transactions are invisible to the transaction after it starts.
Though it is implemented differently in the case of on-disk and memory-optimized tables, logically it behaves the same. A transaction will read a version of the row valid at the time when the transaction started, and sessions do not block each other. However, when two transactions try to update the same data, one of them will be aborted and rolled back to resolve the write/write conflict. This behavior is known as optimistic concurrency.
![]() Note While SERIALIZABLE and SNAPSHOT isolation levels provide the same level of protection against data inconsistency issues, there is a subtle difference in their behavior. A SNAPSHOT isolation level transaction sees data as of the beginning of a transaction. With the SERIALIZABLE isolation level, the transaction sees data as of the time when the data was accessed for the first time.
Note While SERIALIZABLE and SNAPSHOT isolation levels provide the same level of protection against data inconsistency issues, there is a subtle difference in their behavior. A SNAPSHOT isolation level transaction sees data as of the beginning of a transaction. With the SERIALIZABLE isolation level, the transaction sees data as of the time when the data was accessed for the first time.
Consider the situation when a session is reading data from a table in the middle of a transaction. If another session changed the data in that table after the transaction started but before data was read, the transaction in the SERIALIZABLE isolation level would see the changes while the SNAPSHOT transaction would not.
Transaction Isolation Levels in In-Memory OLTP
In-Memory OLTP supports three transaction isolation levels: SNAPSHOT, REPEATABLE READ, and SERIALIZABLE. However, In-Memory OLTP uses a completely different approach to enforce data consistency rules as compared to on-disk tables. Rather than block or being blocked by other sessions, In-Memory OLTP validates data consistency at the transaction COMMIT time and throws an exception and rolls back the transaction if rules were violated.
- In the SNAPSHOT isolation level, any changes done by other sessions are invisible to the transaction. A SNAPSHOT transaction always works with a snapshot of the data as of the time when transaction started. The only validation at the time of commit is checking for primary key violations, which is called snapshot validation.
- In the REPEATABLE READ isolation level, In-Memory OLTP validates that the rows that were read by the transaction have not been modified or deleted by the other transactions. A REPEATABLE READ transaction would not be able to commit if this was the case. That action is called repeatable read validation.
- In the SERIALIZABLE isolation level, SQL Server performs repeatable read validation and also checks for phantom rows that were possibly inserted by the other sessions. This process is called serializable validation.
Let’s look at a few examples that demonstrate this behavior. As a first step, shown in Listing 7-1, let’s create a memory-optimized table and insert a few rows there.
Table 7-3 shows how concurrency works in the REPEATABLE READ transaction isolation level.
Table 7-3. Concurrency in the REPEATABLE READ Transaction Isolation Level
Session 1 | Session 2 | Results |
|---|---|---|
begin tran | ||
update dbo.HKData | ||
select ID, Col | Return old version of a row (Col = 2) | |
commit | Msg 41305, Level 16, State 0, Line 0 The current transaction failed to commit due to a repeatable read validation failure. | |
begin tran | ||
insert into dbo.HKData | ||
select ID, Col | Does not return new row (10,10) | |
commit | Success |
As you can see, with memory-optimized tables, other sessions were able to modify data that was read by the active REPEATABLE READ transaction. This led to a transaction abort at the time of COMMIT when the repeatable read validation failed. This is a completely different behavior than that of on-disk tables, where other sessions are blocked,unable to modify data until the REPEATABLE READ transaction successfully commits and releases shared (S) locks it held.
It is also worth noting that in the case of memory-optimized tables, the REPEATABLE READ isolation level protects you from the Phantom Read phenomenon, which is not the case with on-disk tables.
As a next step, let’s repeat these tests in the SERIALIZABLE isolation level. You can see the code and the results of the execution in Table 7-4.
Table 7-4. Concurrency in the SERIALIZABLE Transaction Isolation Level
Session 1 | Session 2 | Results |
|---|---|---|
begin tran | ||
update dbo.HKData | ||
select ID, Col | Return old version of a row (Col = 2) | |
commit | Msg 41305, Level 16, State 0, Line 0 The current transaction failed to commit due to a repeatable read validation failure. | |
begin tran | ||
insert into dbo.HKData | ||
select ID, Col | Does not return new row (10,10) | |
commit | Msg 41325, Level 16, State 0, Line 0 The current transaction failed to commit due to a serializable validation failure. |
As you can see, the SERIALIZABLE isolation level prevents the session from committing a transaction when another session inserted a new row and violated the serializable validation. Like the REPEATABLE READ isolation level, this behavior is different from that of on-disk tables, where the SERIALIZABLE transaction successfully blocks other sessions until it is done.
Finally, let’s repeat the tests in the SNAPSHOT isolation level. The code and results are shown in Table 7-5.
Table 7-5. Concurrency in the SNAPSHOT Transaction Isolation Level
Session 1 | Session 2 | Results |
|---|---|---|
begin tran | ||
update dbo.HKData | ||
select ID, Col | Return old version of a row (Col = 2) | |
commit | Success | |
begin tran | ||
insert into dbo.HKData | ||
select ID, Col | Does not return new row (10,10) | |
commit | Success |
The SNAPSHOT isolation level behaves in a similar manner to on-disk tables, and it protects from the Non-Repeatable Reads and Phantom Reads phenomena. As you can guess, it does not need to perform repeatable read and serializable validations at the commit stage and, therefore, it reduces the load on SQL Server. However, there is still snapshot validation, which checks for primary key violations and is done in any transaction isolation level.
Table 7-6 shows the code that leads to the primary key violation condition. In contrast to on-disk tables, the exception is raised on the commit stage rather than at the time of the second INSERT operation.
Table 7-6. Snapshot Validation
Session 1 | Session 2 | Results |
|---|---|---|
begin tran | ||
begin tran | ||
commit | Successfully commit the first session | |
commit | Msg 41325, Level 16, State 1, Line 0 The current transaction failed to commit due to a serializable validation failure. |
It is worth mentioning that the error number and message are the same with the serializable validation failure even though SQL Server validated the different rule.
Write/write conflicts work the same way regardless of the transaction isolation level in In-Memory OLTP. SQL Server does not allow a transaction to modify a row that has been modified by other uncommitted transactions. Table 7-7 illustrates this behavior. The code uses the SNAPSHOT isolation level; however, the behavior does not change with different isolation levels.
Table 7-7. Write/Write Conflicts in In-Memory OLTP
Session 1 | Session 2 | Results |
|---|---|---|
begin tran | ||
begin tran | ||
update dbo.HKData | Msg 41302, Level 16, State 110, Line 1 The current transaction attempted to update a record that has been updated since this transaction started. The transaction was aborted. Msg 3998, Level 16, State 1, Line 1 Uncommittable transaction is detected at the end of the batch. The transaction is rolled back. The statement has been terminated. | |
begin tran | ||
begin tran | ||
update dbo.HKData | Msg 41302, Level 16, State 110, Line 1 The current transaction attempted to update a record that has been updated since this transaction started. The transaction was aborted. Msg 3998, Level 16, State 1, Line 1 Uncommittable transaction is detected at the end of the batch. The transaction is rolled back. The statement has been terminated. | |
commit | Successful commit of Session 2 transaction |
Cross-Container Transactions
Any access to memory-optimized tables from interpreted T-SQL is done through the Query Interop Engine and leads to cross-container transactions. You can use different transaction isolation levels for on-disk and memory-optimized tables. However, not all combinations are supported. Table 7-8 illustrates possible combinations for transaction isolation levels in cross-container transactions.
Table 7-8. Isolation Levels for Cross-Container Transactions
Isolation Levels for On-Disk Tables | Isolation Levels for Memory-Optimized Tables |
|---|---|
READ UNCOMMITTED, READ COMMITTED,READ COMMITTED SNAPSHOT | SNAPSHOT, REPEATABLE READ, SERIALIZABLE |
REPEATABLE READ, SERIALIZABLE | SNAPSHOT only |
SNAPSHOT | Not supported |
As you already know, internal implementations of REPEATABLE READ and SERIALIZABLE isolation levels are very different for on-disk and memory-optimized tables. Data consistency rules with on-disk tables rely on locking while In-Memory OLTP uses pre-commit validation. In cross-container transactions, SQL Server only supports SNAPSHOT isolation levels for memory-optimized tables when on-disk tables require REPEATABLE READ or SERIALIZABLE isolation.
Moreover, SQL Server does not allow access to memory-optimized tables when on-disk tables require SNAPSHOT isolation. Cross-container transactions, in a nutshell, consist of two internal transactions: one for on-disk and another one for memory-optimized tables. It is impossible to start both internal transactions at exactly the same time and guarantee the state of the data at the moment the transaction starts.
Listing 7-2 illustrates a transaction that tries to access data from memory-optimized and on-disk tables using incompatible transaction isolation levels.
As you already know, reading on-disk data in a REPEATABLE READ isolation level requires you to use SNAPSHOT isolation levels with memory-optimized tables and, therefore, the query from Listing 7-2 returns the error shown in Listing 7-3.
As the general guideline, it is recommended to use the READ COMMITTED/SNAPSHOT combination in cross-container transactions during the regular workload. This combination provides the minimal blocking and least pre-commit overhead and should be acceptable in a large number of use cases. Other combinations are more appropriate during data migrations when it is important to avoid non-repeatable and phantom reads phenomena.
As you may have already noticed, SQL Server requires you to specify the transaction isolation level with a table hint when you are accessing memory-optimized tables. This does not apply to individual statements that execute outside of the explicitly started (with BEGIN TRAN) transaction. Those statements are called autocommitted transactions, and each of them executes in a separate transaction that is active for the duration of the statement execution. Listing 7-4 illustrates code with three statements. Each of them will run in their own autocommitted transactions.
An isolation level hint is not required for statements running in autocommitted transactions. When the hint is omitted, the statement runs in the SNAPSHOT isolation level.
![]() Note SQL Server allows you to keep a NOLOCK hint while accessing memory-optimized tables from autocommitted transactions. That hint is ignored. A READUNCOMMITTED hint, however, is not supported and triggers an error.
Note SQL Server allows you to keep a NOLOCK hint while accessing memory-optimized tables from autocommitted transactions. That hint is ignored. A READUNCOMMITTED hint, however, is not supported and triggers an error.
There is the useful database option MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT, which is disabled by default. When this option is enabled, SQL Server allows you to omit the isolation level hint in non-autocommitted transactions promoting them to the SNAPSHOT isolation level as with autocommitted transactions. Consider enabling this option when you migrate an existing system to In-Memory OLTP and have T-SQL code that accesses tables that become memory-optimized.
Transaction Lifetime
Although I have already discussed a few key elements used by In-Memory OLTP to manage data access and the concurrency model, let’s review them here.
- The Global Transaction Timestamp is an auto-incremented value that uniquely identifies every transaction in the system. SQL Server increments and obtains this value at the transaction pre-commit stage.
- TransactionId is another identifier (timestamp) that also uniquely identifies a transaction. SQL Server obtains and increments its value at the moment when the transaction starts.
- Every row has BeginTs and EndTs timestamps, which correspond to the Global Transaction Timestamp of the transaction that inserted or deleted this version of a row.
Figure 7-1 shows the lifetime of a transaction that works with memory-optimized tables.

Figure 7-1. Transaction lifetime
At the time when a new transaction starts, it generates a new TransactionId and obtains the current Global Transaction Timestamp value. The Global Transaction Timestamp value dictates what rows are visible to the transaction, and it should be in between the BeginTs and EndTs for the rows to be visible. During data modifications, however, the transaction analyzes if there are any uncommitted versions of the rows, which prevents write/write conflicts when multiple sessions modify the same data.
When a transaction needs to delete a row, it updates the EndTs timestamp with the TransactionId value, which also has a flag that the timestamp contains the TransactionId rather than the Global Transaction Timestamp. The Insert operation creates a new row with the BeginTs of theTransactionId and the EndTs of Infinity. Finally, the update operation consists of delete and insert operations internally.
Figure 7-2 shows the data rows after we created and populated the dbo.HKData table in Listing 7-1, assuming that the rows were created by a transaction with the Global Transaction Timestamp of 5. (The hash index structure is omitted for simplicity’s sake.)

Figure 7-2. Data in the dbo.HKData table after insert
Let’s assume that you have a transaction that started at the time when the Global Transaction Timestamp value was 10 and the TransactionId generated as -8. (I am using a negative value for TransactionId to illustrate the difference between two types of timestamps in the figures.)
Let’s assume that the transaction performs the operations shown in Listing 7-5. The explicit transaction has already started, and the BEGIN TRAN statement is not included in the listing. All three statements are executing in the context of a single active transaction.
Figure 7-3 illustrates the state of the data after data modifications. An INSERT statement created a new row, a DELETE statement updated the EndTs value in the row with ID=4, and an UPDATE statement changed the EndTs value of the row with ID=2 and created a new version of the row with the same ID.
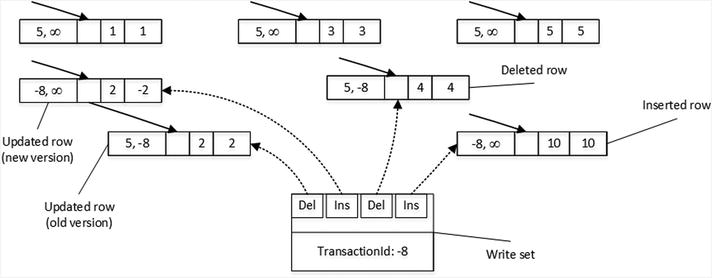
Figure 7-3. Data in the dbo.HKData table after modifications
It is important to note that the transaction maintains a write set, or pointers to rows that have been inserted and deleted by a transaction, which is used to generate transaction log records.
In addition to the write set, in the REPEATABLE READ and SERIALIZABLE isolation levels, transactions maintain a read set of the rows read by a transaction and use it for repeatable read validation. Finally, in the SERIALIZABLE isolation level, transactions maintain a scan set, which contains the information about predicates used by the queries in transaction. The scan set is used for serializable validation.
When a COMMIT request is issued, the transaction starts the validation phase. First, it generates a new Global Transaction Timestamp value and replaces the TransactionId with this value in all BeginTs and EndTs timestamps in the rows it modified. Figure 7-4 illustrates this action, assuming that the Global Transaction Timestamp value is 11.

Figure 7-4. Validation phase after BeginTs and EndTs values are replaced
At this moment, the rows modified by transactions become visible to other transactions in the system even though the transaction has yet to be committed. Other transactions can see uncommitted rows, which leads to a situation called commit dependency. These transactions are not blocked at the time when they access those rows; however, they do not return data to clients nor commit until the original transaction on which they have a commit dependency commits itself. I will talk about commit dependencies shortly.
As the next step, the transaction starts a validation phase. SQL Server performs several validations based on the isolation level of the transaction, as shown in Table 7-9.
Table 7-9. Validations Done in the Different Transaction Isolation Levels

![]() Important Repeatable read and serializable validations add an overhead to the system. Do not use REPEATABLE READ and SERIALIZABLE isolation levels unless you have a legitimate use case for such data consistency. We will discuss two of those use cases, such as supporting uniqueness and referential integrity, in Chapter 11.
Important Repeatable read and serializable validations add an overhead to the system. Do not use REPEATABLE READ and SERIALIZABLE isolation levels unless you have a legitimate use case for such data consistency. We will discuss two of those use cases, such as supporting uniqueness and referential integrity, in Chapter 11.
After the required rules have been validated, the transaction waits for the commit dependencies to clear and the transaction on which it depends to commit. If those transactions fail to commit for any reason, such as a validation rules violation, the dependent transaction is also be rolled back and an error 41301 is generated.
Figure 7-5 illustrates a commit dependency scenario. Transaction Tx2 can access uncommitted rows from transaction Tx1 during Tx1 validation and commit phases and, therefore, Tx2 has commit dependency on Tx1. After the Tx2 validation phase is completed, Tx2 has to wait for Tx1 to commit and the commit dependency to clear before entering the commit phase.
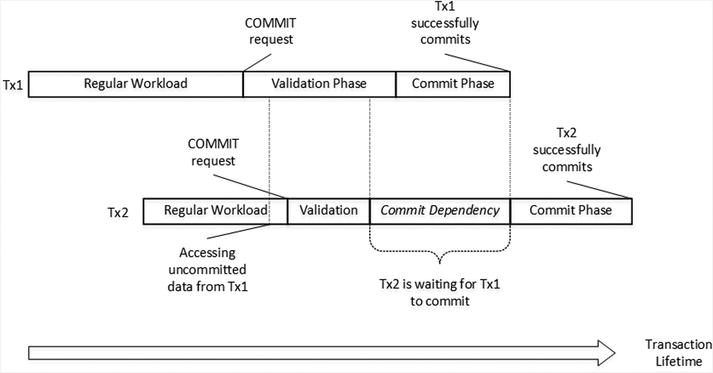
Figure 7-5. Commit Dependency: Successful Commit
If Tx1, for example, failed to commit due to serializable validation violation, Tx2 would be rolled back with Error 41301, as shown in Figure 7-6.

Figure 7-6. Commit Dependency: Validation Error
![]() Note You can track commit dependencies using the dependency_acquiredtx_event and waiting_for_dependenciestx_event extended events.
Note You can track commit dependencies using the dependency_acquiredtx_event and waiting_for_dependenciestx_event extended events.
Finally, when all commit dependencies are cleared, the transaction moves to the commit phase, generates one or more log records, saves them to the transaction log, and completes the transaction.
Commit dependency is technically the case of blocking in In-Memory OLTP. However, the validation and commit phases of the transactions are relatively short, and that blocking should not be excessive. It is also worth noting that transaction logging in In-Memory OLTP is more efficient compared to on-disk transactions. I will discuss it in more detail in Chapter 8.
![]() Note You can read more about the concurrency model in In-Memory OLTP at https://msdn.microsoft.com/en-us/library/dn479429.aspx.
Note You can read more about the concurrency model in In-Memory OLTP at https://msdn.microsoft.com/en-us/library/dn479429.aspx.
Summary
In-Memory OLTP supports three transaction isolation levels, SNAPSHOT, REPEATABLE READ, and SERIALIZABLE. In contrast to on-disk tables, where non-repeatable and phantom reads are addressed by acquiring and holding the locks, In-Memory OLTP validates data consistency rules on the transaction commit stage. An exception will be raised and the transaction will be rolled back if rules were violated.
Repeatable read and serializable validation adds an overhead to transaction processing. It is recommended to use the SNAPSHOT isolation level during a regular workload unless REPEATABLE READ or SERIALIZABLE data consistency is required.
You can use different transaction isolation levels for on-disk and memory-optimized tables in cross-container transactions; however, not all combinations are supported. The recommended practice is using the READ COMMITTED isolation level for on-disk and the SNAPSHOT isolation level for memory-optimized tables.
SQL Server does not require you to specify transaction isolation level when you access memory-optimized tables through the interop engine in autocommitted (single statement) transactions. SQL Server automatically promotes such transactions to the SNAPSHOT isolation level. However, you should specify an isolation level hint when a transaction is explicitly started with BEGIN TRAN statement. You can avoid this by enabling the MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT database option. This option is useful when you migrate existing system to use In-Memory OLTP.