
This chapter continues the work of the previous one in creating a DSL for expressing offers for the Time Machine Store. As you may remember, deep embedding was chosen as the way to model the offers language in Haskell. A deeply embedded language is divided between its syntax, expressed as a set of Haskell data types, and its interpretation, which is responsible for assigning a meaning to each value in the language. In this example, the interpretation of an offer could be a function that, given a list of products and prices, applies the offers and discounts and returns the new price.
In principle, the interpretations could be defined as plain Haskell functions over the DSL values. However, almost every interpretation you can give follows a set of patterns. Thus, it’s interesting to consider those patterns and build a conceptual model that better defines the interpretations. This is what attribute grammars do for you. Then, you can use a tool to generate the Haskell code that corresponds to an attribute grammar, saving you from having to write a lot of boilerplate code. In particular, this chapter will devote most of its time to the topic of programming with the Utrecht University Attribute Grammar Compiler (UUAGC).
In addition to plain programming, in this chapter you will also consider the relations between attribute grammars and other Haskell concepts, such as monads. You will revisit the ideas of origami programming from Chapter 3 and will apply them to general data types (not only lists). Finally, I shall introduce the idea of data type-generic programming, which allows us to create algorithms which work on many different data types in a uniform manner.
Interpretations and Attribute Grammars
In this section, you’ll learn about attribute grammars. To help, a simple language is given an interpretation in Haskell. That language is then reworked using attributes.
A Simple Interpretation
Introducing Attribute Grammars
The previous section’s interpretation is quite simple. Still, it contains a lot of boilerplate code. The recursive nature of this definition is explicit by calling meaning on the subexpressions, and the p list must be explicitly threaded throughout the entire function. Attribute grammars provide a higher-level model for writing interpretations (and, as you will see later, many other kinds of functions), focusing on the data being used and produced, saving you from thinking about all the small details related to information flow. As a result, your code becomes much more maintainable.
In addition, attribute grammars contribute to the modularity of the code. You can separate your interpretation into several parts (and even in several files) and then ask the attribute grammar system to join them together to compute all the information you need from your data type in the smallest number of passes.
The main disadvantage of attribute grammars is that they have a different computational model than plain Haskell, even though the integration is tight. As you will see in this chapter, it’s easy to understand attribute grammars in Haskell terms, so this disadvantage shouldn’t block you from using them.
Let’s return to the expression example. If instead of plain Haskell you were using attribute grammars, you would be thinking about this interpretation in different terms. From the attribute grammar point of view, your data type is a tree whose nodes keep some attributes within them. In this example, the attributes would be the string that you’re exploring and the result of the interpretation.
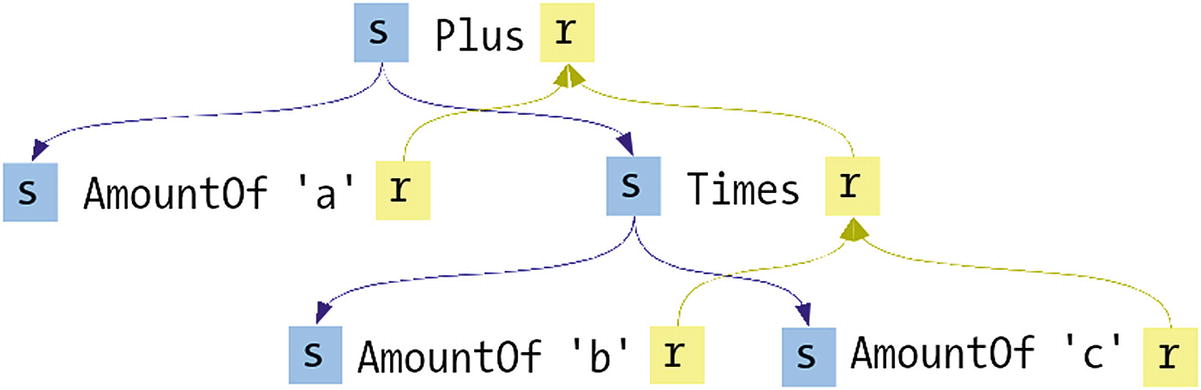
Tree and attributes for AmountOf 'a' `Plus` (AmountOf 'b' `Times` AmountOf 'c')
- 1.
Which are the possible nodes in your tree. This is done via the definition of a set of data types in which every constructor represents a kind of node.
- 2.
The attributes to be computed and whether they are inherited or synthesized.
- 3.
How to pass the information from parent to children nodes in the case of the inherited attributes and how to compute the value of a synthesized attributes from their children.
When an attribute needs to be transported in a more complex fashion than just top-down or bottom-up (e.g., between sibling nodes), the Haskell code can become quite complex. But with an attribute grammar, this behavior is expressed declaratively, and the system takes care of keeping track of it.
Sometimes the value of an attribute depends on another one. This means attributes must be ordered in some way for the whole computation to proceed, maybe doing more than one traversal of the same tree. Attribute grammar systems perform this ordering automatically (and in many cases, in an optimal way), so you don’t need to think about it.
Hackage includes several implementations of attribute grammars in its package repository. One option is to use Happy, the parser generator included in the Haskell Platform and that has support for attributes in its grammars. Happy is an external tool that preprocesses a grammar description and generates the Haskell code needed for parsing it.
AspectAG is a library for embedding attribute grammars inside Haskell. So, you don’t need an extra step of building prior to compilation. It’s an interesting option for working with attribute grammars inside Haskell but has the downside of needing a lot of type-level programming to make it work.
The tool that will be presented in this chapter is the Utrecht University Attribute Grammar Compiler (UUAGC). Like with Happy, it’s a preprocessor that generates Haskell code from the description of the grammar. In contrast to Happy, UUAGC is focused specifically on defining attribute grammars. Thus, the connection between the attribute grammar formalism and UUAGC code is much more explicit in this case, making it a better choice for learning about these grammars.
Installing UUAGC
By following these instructions, you also install integration with Cabal, which is found in the uuagc-cabal package. You’ll be using uuagc-cabal to build the attribute grammars in the upcoming sections.
Your First Attribute Grammar
Now let’s create the attribute grammar corresponding to the simple numeric expressions introduced in the previous section. For the source file, you have two conventions to follow: UUAGC source files end with .ag, and files must be found inside a folder structure that follows the module name. The conventions follow Haskell’s. In this case, the module will be Chapter14.Simple, so the file should be found in src/Chapter14/Simple.ag.
Synthesizing the Result
- 1.
No equal sign should appear after the name of the data type. Instead, each constructor declaration must begin with a vertical bar: |.
- 2.
All the arguments to a constructor must be named, as happens with records in Haskell. However, no brackets should be used around the fields.
Note
UUAGC supports two kinds of syntax. The one used in the examples of this chapter is dubbed “Haskell syntax” because of its resemblance to that language. The “classical syntax” is quite different from Haskell’s; you can spot it in UUAGC code because all the keywords are written in capitals.
- 1.
The value of an attribute at a child node is accessed via the syntax node.attribute. The special name lhs is reserved for referring to the parent of the current node. The idea of a parent is not found in Haskell code, so let’s clarify it using an example. Say you have a value of the following form Plus (AmountOf 'a') (AmountOf 'b') , that is, a parent Plus node with two AmountOf children nodes. At each node both a string and a result attribute will be handled. From the point of view of AmountOf 'a', lhs.string refers to the attribute in the parent node, that is, the value of the string attribute in the Plus node.
- 2.
At the right side of the declaration of each attribute, the references to other attributes or parameters of the constructor must be preceded by the @ sign.
- 3.
UUAGC uses indentation to delimit blocks. However, you can ask the preprocessor to keep a piece of code exactly as it appears in the source file, wrapping it between { and }.
Executing the Attribute Grammar
The data declaration in a grammar is transformed to a data declaration in Haskell, but with the constructors prefixed with the name of the data type, in this case Expr. If you want constructors to appear as written in the grammar, don’t use the rename option in UUAGC. However, in that case, you have to take care that constructor names do not collide.
The data types Inh_Expr and Syn_Expr represent the inherited and synthesized attributes at each node of the Expr data type. Both are declared as records, with the field names including also the names of the attributes and the type of record they are in. In this example, the names boil down to string_Inh_Expr and result_Syn_Expr.
A function sem_Expr converts a value of the data type into a function that takes as parameters the initial inherited attributes and returns a tuple of synthesized attributes. However, the function that you get may have the attributes in any order, so it’s customary to use the wrap_Expr function , which takes attribute records as parameters.
Integrating UUAGC in Your Package
As mentioned earlier, UUAGC is not a library but a preprocessor for Haskell code. This means the attribute grammars you write cannot be directly compiled by GHC or any other Haskell compiler; rather, they need to be converted into Haskell source by UUAGC. You can do the translation yourself each time your attribute grammar changes, but it’s better to tell Cabal that you’re using UUAGC and let the tool take care of preprocessing files that have changes while it takes care of which files need to be recompiled.
Caution
Cabal does not support build dependencies, only package dependencies. In other words, Cabal is not aware that you need UUAGC to build the package; you need to ensure it beforehand. If you get an error about UU.UUAGC in Setup, double check that the tool has been correctly installed.
Notice that you need to include both the path to the attribute grammar (in the file field) and the name of the module that will be created (in this case Chapter14.Simple). Furthermore, if you want to use “Haskell syntax” as presented in the examples of this chapter, you should remember to always include the haskellsyntax option.
For each new attribute grammar that you need to compile, you must include a new pair of lines defining it in the uuagc_options file. The advantage of this methodology is that Cabal takes care of rebuilding only the parts that have changed and doesn’t call the preprocessor if it’s not strictly needed.
UUAGC Code Generation
By default, UUAGC takes advantage of lazy evaluation for executing attribute grammars. But you can also instruct it to optimize the code. In that case, a specific sequence of visits through the tree will be scheduled, resulting in stricter code.
This chapter focuses on the use of UUAGC with Haskell. But the preprocessor can generate code for other functional languages, including OCaml and Clean. In those cases, the right sides should be written in the corresponding back-end language instead of in Haskell.
Expressions Interpretation
Let’s move now to a larger attribute grammar. In this case, the focus would be conditional expressions inside an offer. The aim is to obtain a function that, given an expression and a list of products, returns the result of applying the expression to that list.
Using an Attribute Grammar
Note
To compile this attribute grammar, you need to enable the ScopedTypeVariables extension for GHC. The easiest way to do this is to add a line similar to extensions: ScopedTypeVariables to the Cabal stanza.
In this case, I’ll return to the simple modeling of expressions results. Three different attributes will hold the result of the expression as integer, float, or Boolean. At any point, only one of the components will hold a Just value, whereas the others will be Nothing. As you know from the previous chapter, you could refine the definition of Expr using GADTs to make this tupling unnecessary. However, the focus in this chapter is on attribute grammars, so let’s try to keep the types as simple as possible. The result of an expression depends on the subexpressions, so this attribute should be a synthesized one.
Note
Remember that compound types such as [(a, Float)] or Maybe Bool must be written inside brackets to stop UUAGC from parsing them as special attribute grammar syntax.
Given these examples, the rest of the cases should be easy to write. Exercise 14-1 asks you to do so.
Exercise 14-1. Full Expression Attribute Grammar
Complete the remaining cases of the sem block of Expr. Hint: use the previous examples as templates, either performing some computation over the products list or combining the value of subexpressions using Applicative syntax.
Precomputing Some Values
The attribute grammar for Expr works fine but could be enhanced in terms of performance. In the code above, each time a TotalNumberOfProducts or TotalPrice constructor is found, the full product list has to be traversed. Since it’s quite common to find those basic combinators in the expressions, it’s useful to cache the results to be reused each time they are needed. Let’s see how to implement that caching in the attribute grammar.
Note
Adding an extra Root data type is merely a convention used for initializing inherited attributes. In many cases it’s not needed, and of course, you can use a name different from Root.
Notice how UUAGC allows you to include in the same declaration several data types that share attributes. To use that functionality, just include all the data types after the attr keyword. In this example, the products, intValue, fltValue, and boolValue attributes are declared for both the Root and Expr data types.
Now you might expect extra declarations for threading the new inherited attributes inside Expr and taking the synthesized attributes from Expr to save it into Root. The good news is that they are not needed at all. UUAGC has some built-in rules that fire in case you haven’t specified how to compute some attribute. For inherited attributes, the computation proceeds by copying the value from the parent to its children. For synthesized attributes, the result is taken from a child. (If you need to combine information from several children, there are other kinds of rules; you’ll get in touch with them in the next section.) These rules are collectively known as copy rules because they take care of the simple case of attributes being copied. The flow of the inherited products attribute in the previous grammar didn’t have to be specified; this rule would take care of it.
The core of the idea is that each time you need to initialize some values for the rest of the computation of the attributes, it’s useful to wrap the entire tree inside a data type with only one constructor, which includes that initialization in its sem block.
A Different (Monadic) View
When learning about a new concept, it’s useful to relate it to concepts you’re already familiar with. You’ve already seen how attribute grammars come into existence when trying to declaratively define the flow of information. In the first simple interpretation, the parameters to functions became inherited attributes, and the tuple of results correspond to the synthesized attributes. In Chapters 6 and 7, another different concept was used to thread information in that way: the Reader and Writer monads. Indeed, you can express the attribute grammar developed in this section using the monadic setting. I’ll show how to do that. Note that the code from this section is independent of the attribute grammar and should be written in a different file, which should contain the definition of the Expr data type from the previous chapter.
The Semigroup instance is only required in GHC version 8.4 or newer. The reason is that from that version on, Semigroup is a superclass of Monoid , and thus any instance of the latter must also be an instance of the former.
Caution
Although type correct, this instance doesn’t express a true monoid. The problem is that x `mappend` mempty = mempty, which is not what is necessary. A correct solution for this problem would be to save a list of output results and get the last one at the end of the attribute computation.
As you can see, attribute grammars express the concepts behind the Reader and Writer monads in a new setting. The main advantage is that you can refer to attributes by name, instead of stacking several monad transformers and having to access each of them by a different amount of lift. The intuitive idea that Reader and Writer monads can be combined easily and in any order to yield a new monad is made explicit by the fact that you can combine attribute grammars just by merging their attributes.
Offer Interpretations
It’s time to move forward from conditional expressions to full values of type Offer, which represent the possible discounts in the Time Machine Store. As in the previous section, the examples will revolve around the initial definition of this data type, prior to adding extra type safety, in order to keep the code clean and concise.
Checking the Presents Rule
You’ve already seen several ways in which the Presents Rule of the offers (remember, the number of free presents in an offer may be limited) can be checked. Using strong typing, you looked at a way to count the maximum number of presents, but the implementation gives no clue about what presents are inside. The task in this section is to create a small attribute grammar that computes the largest possible set of presents that a single customer can get for free.
- 1.
When you find a Present constructor , you know that the number of presents returned by that offer is a singleton list including the value in its parameter.
- 2.
When a Restrict constructor is found, you must delete from the present list all those products that are not inside the restriction list.
If you don’t specify how to compute the value of the presents attribute, the rule that just copies it will no longer be applied. Instead, the preprocessor will use the operations in the use declaration.
If you look a bit closer at the operations specified, you’ll notice that they are indeed the Monoid instance for lists. Remember the previous discussion about the relation between attribute grammars and monads? When using a synthesized attribute with use, you can see it being a Writer, where the Monoid instance of the attribute type is exactly defined by the operations in use (instead of the operation that just forgets about the first argument of mappend).
The Duration Rule could also be checked using an attribute grammar. Exercise 14-2 asks you to do so.
Exercise 14-2. The Duration Rule
Compute the maximum duration of an offer using an attribute grammar. The rules for doing so should be the same as in Chapter 13. Decorate your attributes with use, as shown in this section, to specify the common behavior of joining offers.
Showing an HTML Description
The last example for attribute grammars will show a description of an offer as HTML. This is an interesting example of how a grammar can be used not only to consume information but also to show that information in a new way. Furthermore, this grammar will show some subtleties related to attribute handling.
- 1.
A list of all the presents that you may get via the offer. This is done by reusing the presents attribute from the previous section.
- 2.
A small table of contents that should show a small description of the first and second levels of the offer tree, in which item is a link to the full description.
- 3.
Finally, the full description of the offer as a series of nested lists.

Attribute c threaded through siblings of an And node
These kinds of attributes that are both inherited and synthesized are known in the field of attribute grammars as chained . If you want to relate the behavior of chained attributes to a monad, it would be the State one in this case. The attribute can be seen as a value that changes throughout the exploration of the whole tree.
Since counter is both an inherited attribute and a synthesized attribute, lhs.counter is referring to different attributes on each side. On the right side, @lhs.counter is the value that comes from the parent. On the left side, lhs.counter is the value that will be given back as an identifier for this node.
Think carefully about the rest of the threading for Exercise 14-3.
Exercise 14-3. Threading the Counter
Complete the computation of the counter and ident attributes for the Restrict, From, Until, Extend, and If constructors.
Note
You can write all the rules as they are shown, one below the other. UUAGC will take care of merging all the attribute computations for each constructor.
The rest of the constructors are left as an exercise to the reader, specifically as Exercise 14-4.
Exercise 14-4. Building Descriptions
Complete the computation of the htmlText, htmlChild, title, and subtitle attributes for the Present, AbsoluteDiscount, Restrict, From, Until, Extend, Both, and If constructors.
One important advantage of describing the generation of the markup as an attribute grammar is that you didn’t have to take care of ordering the computation. UUAGC is able to find a sorting of the attributes, in the way that each of them needs only the previous ones to be computed. If this cannot be done, the preprocessor will emit a warning telling you that your attribute grammar is circular.
Programming with Data Types
Attribute grammars provide us a common language to describe operations performed over any data type. Any Haskell value can be seen as a tree and can be decorated using attributes which flow either top-down or bottom-up. But this is not the only way to look at data types in a uniform manner: folds provide a similar generalization. In fact, Haskell has powerful features to describe operations based on the shape of a data type; this is what we call data type-generic programming.
Origami Programming Over Any Data Type
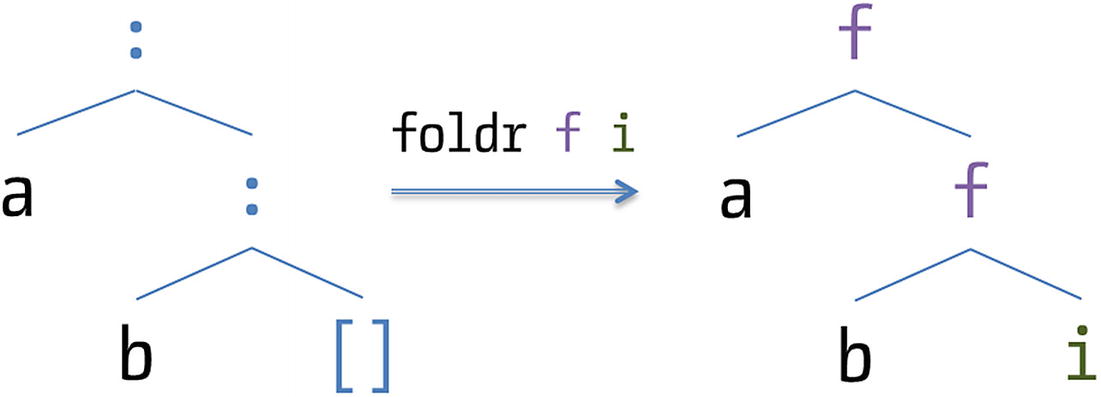
Reminder of the behavior of foldr
Interestingly, the notion of a fold can be defined for every Haskell data type. For each constructor you supply a function that will “replace” it and then evaluate the resulting tree. In addition, the fold should call itself recursively in those places where the definition of the data type is also recursive. These generalized folds are also called catamorphisms .
You can practice those ideas by adding new constructors in Exercise 14-5.
Exercise 14-5. Larger Expressions
Extend the Expr data type with the constructors Minus and DividedBy and complete the corresponding fold functions for those new constructors.
Folds are closely related to attribute grammars. What you’re doing with an attribute grammar is defining a specific algebra for your data type, an algebra that computes the value of the attributes. If you look at the generated Haskell code by UUAGC, you’ll notice that there are some parts labeled as cata. These are the functions starting with sem_ that you used previously. What this function does is fold over the structure while expecting the initial inherited values you give with the function starting with wrap_.
Once you feel comfortable with these ideas, you can dive into other ways data types can be constructed and consumed in a generic fashion. For example, the notion of unfold (also called anamorphism ) can also be generalized, and combinations of folds and unfold give rise to other interesting functions. A good library to look at is recursion-schemes by Edward A. Kmett. Knowing these patterns will help you when reusing a lot of code that is already written and that follows the same structure on different data types.
In addition to libraries, there’s also a lot of information about how you can use this idea of folding over any data type to create more elegant code. “Origami programming” by Jeremy Gibbons was already mentioned in Chapter 3. “Functional Programming with Bananas, Lenses, Envelopes and Barbed Wire” by Erik Meijer, Maarten Fokkinga, and Ross Paterson discusses all these generalizations of folds and unfolds and shows how to use equational reasoning as you saw in Chapter 3 for lists, but over any data type.
Data Type-Generic Programming
You’ve already seen two kinds of polymorphism in Haskell. Parametric polymorphism treats values as black boxes, with no inspection of the content. Ad hoc polymorphism, on the other hand, allows you to treat each case separately.
But there’s a third kind of polymorphism available in GHC, namely, data type- generic programming (or simply generics). In this setting, your functions must work for any data type, but you may depend on the structure of your data declaration. There are several libraries of doing this kind of programming available in Hackage. GHC integrates its own in the compiler in the GHC.Generics module, and this is the one I am going to discuss.
Fields , which contain one value of a certain type.
Products , which put together several fields into a constructor. We use the symbol (:*:) to express products.
Choice of constructors, for those data types which have more than one. In this case, we use the symbol (:+:).
You should read this as “you have two constructors, one with no fields, and one with two fields, the first one of type Bool and the second one of type [Bool]”. For most data type-generic programming tasks, the name of the data type and the constructors is not used at all.
Note that the appearance of a choice of constructors results in the use of L1 and R1 to choose which constructor to take. The rest of the building blocks, (:*:), U1, and Rec0, have only one constructor, whose name coincides with that of the type, except for Rec0 which uses K1.
The question is: how can we define a generic operation by taking advantage of this uniform description of data types? The procedure is always similar: we have to define two type classes. The first one represents the operation itself, whereas the second one is used to disassemble the building blocks and derive the implementation. Furthermore, in the first type class we specify how to derive a function automatically using the second one.
Note
A proxy is a dummy value whose only purpose is to fix a type for the compiler. They are defined in the Data.Proxy module.
As you can see, they look fairly similar, except for the kind of the second argument. In the GHC.Generics module all the building blocks have a kind * -> *. As a result, the second argument to ggetall must be given an additional type argument, so it reads f x instead of simply f.
This was a very fast-paced introduction to data type-generic programming, with the aim for you to taste its flavor. If you want to dive into it, I recommend looking at the lecture notes called “Applying Type-Level andGeneric Programming in Haskell” by Andres Löh.
Summary
You delved into the general idea of attributing a tree whose nodes are the constructors of a specific Haskell data type.
Three kinds of attributes were distinguished: synthesized (bottom-up), inherited (top-down), and chained (threaded among siblings).
Monads are related to attribute grammars: Reader corresponds to inherited attributes, Writer to synthesized attributes, and State to chained attributes.
You learned how to configure and use the Utrecht University Attribute Grammar Compiler to preprocess your attribute grammars into Haskell code.
UUAGC provides many facilities for writing concise attribute grammars. In this chapter, you became familiar with use declarations and local attributes.
The idea of fold (or catamorphism) was generalized from lists to any possible Haskell data type.
Finally, you have seen how to define operations which depend on the structure of the data type using GHC.Generics.