
Chapter 6 provided us with the first three outlier detection tests. In this chapter, we will build upon the prior work and include several additional tests. We will also refactor existing code, rethink a few design choices, and wrap up the core elements of univariate statistical analysis.
Adding New Tests
The three tests we added in the prior chapter are quite useful and might even be enough on their own to solve many common univariate outlier detection problems. If your input data follows a specific shape, however, there are other that can be quite useful in tracking outliers. Specifically, there are several tests we can perform if the data fits closely enough to a normal distribution.
In Chapter 3, we described various distributions, including the normal distribution. As a brief summary, the normal distribution has a mean of 0 and a variance of 1. A normal distribution is one in which we can, using only addition and multiplication, translate our data to the normal distribution without distorting the relationships between data points. For the rest of this chapter, any reference to normal distributions (even mentions of “the” normal distribution) will be the more generic concept, not the singular normal distribution with a mean of 0 and variance of 1.
Checking for Normality
There are several tests that can inform us as to whether a particular dataset appears to follow a normal distribution. The first test we will look at is called the Shapiro-Wilk test. This test, named after Samuel Shapiro and Martin Wilk, tends to be the most accurate at determining whether a given sample of data approximates a normal distribution. In Python, the Shapiro-Wilk test is a function within the scipy.stats library.

A graph plots density versus value. Log normal is a right-skewed curve and normal is a normal curve.
The normal distribution exhibits no skewness. By contrast, the log-normal distribution has a positive skew
The kurtosis of a dataset indicates the amount of a distribution contained in the tails. The kurtosis of a normal distribution is 3, and as the kurtosis increases, the likelihood of seeing outlier data points increases. Using the datasets from Figure 7-1, the skewness of our normal distribution is 0, and its kurtosis is 2.99. The log-normal dataset has a skewness of 5.34 and a kurtosis of 58.34.
D’Agostino’s K-squared test, which is the normaltest() function in scipy.stats, uses these measures to estimate whether the dataset’s distribution is markedly different from the normal distribution.
The third test we will use is the Anderson-Darling test, named after Theodore Anderson and Donald Darling. This test is similar to the Shapiro-Wilk test. It tends not to be quite as accurate as the Shapiro-Wilk test, but in Python, the anderson() function performs the test at a variety of significance levels, meaning that you can test at several levels of significance in one go.
Run two basic tests for normality
Both of these tests take a similar shape, and so we centralize the code in check_basic_normal_test(), which takes four parameters: the values in our DataFrame (col), an indicator of just how unlike a normal distribution our result should be before we flag it as non-normal (alpha), the name of the function that we want to use for labeling (name), and the actual function name (f). In Python, we can use a function as an input to another function. When doing so, note that we do not put parentheses around the function name, either in the parameter to check_basic_normal_test() or in the calls in check_shapiro() or check_dagostino(). We save the function call f(col) for the body of check_basic_normal_test(), in which we call shapiro() or normaltest() and pass in col as the parameter. These tests calculate a p-value and compare that against our provided alpha parameter. If the p-value is greater than alpha, then we assume that the sample could have come from a normal distribution. If the p-value is at or below alpha, we believe that the data is not normal.
The Anderson-Darling check for normality

A pseudocode of the Shapiro-Wilk, D Agostino, and Anderson-Darling tests against a dataset that passes the normality test.
The results of three normality checks. Note that the Anderson-Darling significance level scale runs from 0 to 100 rather than 0-1

A pseudocode of the Shapiro-Wilk, D Agostino, and Anderson-Darling tests of the input dataset that does not appear to come from a normal distribution.
A sample that is decidedly not normal
In this case, the Shapiro-Wilk and D’Agostino p-values are well below 0.05, meaning that both tests indicate that this dataset does not appear to have come from a normal distribution. The Anderson-Darling result statistic has a value greater than 5.0, well above the 0.501 at the 15% significance level and even the 0.951 of the 1% significance level.
A function that determines whether an input dataset follows from a normal distribution
The function begins by setting an alpha value of 0.05, following our general principle of not having users make choices that require detailed statistical knowledge. Then, if the dataset has fewer than 5000 observations, we run the Shapiro-Wilk test; otherwise, we skip the test. If we have at least eight observations, we can run D’Agostino’s K-squared test. Finally, no matter the sample size, we may run the Anderson-Darling test.
When it comes to making a determination based on these three tests, we have to make a decision similar to how we weight our ensembles. We can perform simple voting or weigh some tests greater than others. In this case, we will stick with a simple unanimity rule: if all three tests agree that the dataset is normally distributed, then we will assume that it is; otherwise, we will assume that it is not normally distributed. The diagnostics generate the JSON snippets that we saw in Figures 7-2 and 7-3.
Approaching Normality
Now that we have a check for normality, we can then ask the natural follow-up question: If we need normally distributed data and our dataset is not already normally distributed, is there anything we can do about that? The answer to that question is an emphatic “Probably!”
There are a few techniques for transforming data to look more like it would if it followed from a normal distribution. Perhaps the most popular among these techniques is the Box-Cox transformation, named after George Box and David Cox. Box-Cox transformation takes a variable and transforms it based on the formula in Listing 7-4.
Listing 7-4. The equation behind Box-Cox transformation
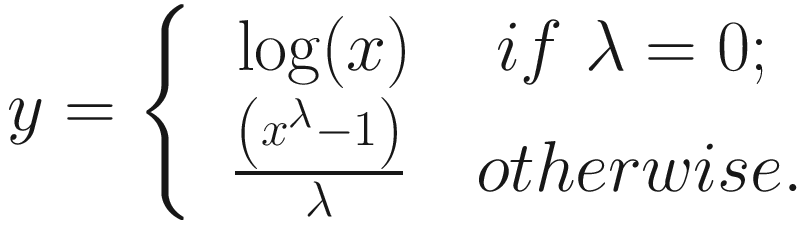
Suppose we have some target variable x. This represents the single feature of our univariate dataset. We want to transform the values of x into a variable that follows from a normal distribution, which we’ll call y. Given some value of lambda (λ), we can do this by performing one of two operations. If lambda is 0, then we take the log of x, and that becomes y. This works well for log-normally distributed data like we saw in Chapter 3. Otherwise, we have some lambda and raise x to that power, subtract 1 from the value, and divide it by lambda. Lambda can be any value, positive or negative, although common values in Box-Cox transformations range between -5 and 5.
This leads to the next question: How do we know what the correct value of lambda is? Well, the SciPy library has a solution for us: scipy.stats.boxcox() takes an optional lambda parameter. If you pass in a value for lambda, the function will use that value to perform Box-Cox transformation. Otherwise, if you do not specify a value for the lambda parameter, the function will determine the optimal value for lambda and return that to you. Even though we get back an optimal value for lambda, there is no guarantee that the transformed data actually follows from a normal distribution, and therefore, we should check the results afterward to see how our transformation fares.
The function to normalize our input data using the Box-Cox technique
The first thing we do is find the middle 80% of our input data. The rationale behind this is that Box-Cox transformation is quite effective at transforming data. So effective, in fact, that it can smother outliers in the data and make the subsequent tests lose a lot of their value in identifying outlier values. Therefore, we will focus on the central 80% of data, which we typically do not expect to contain many outliers. Running boxcox() on the central 80% of data, we get back a fitted lambda value. We can then pass that value in as a parameter to perform the transformation against our entire dataset, returning the entirety of fitted data as well as the fitted lambda we built from the central 80%.
The function to perform normalization on a dataset
Listing 7-6 starts by checking to see if the data is already normally distributed. If so, we do not need to perform any sort of transformation and can use the resulting data as is. Otherwise, we perform a Box-Cox transformation if we meet all of the following results: first, the data must not follow from a normal distribution; second, there must be some variance in the data; third, all values in the data must be greater than 0, as we cannot take the logarithm of 0 or a negative number; and fourth, we need at least eight observations before Box-Cox transformation will work.
If we meet all of these criteria, then we call the normalize() function and retrieve the fitted data and lambda. Then, we call is_normally_distributed() a second time on the resulting dataset. Note that we may still end up with non-normalized data as a result of this operation due to the fact that we configured the value of lambda based on the central 80% of our dataset and so extreme outliers may still be present in the data after transformation. Therefore, we log the result but do not allow is_normally_distributed() to prohibit us from moving forward.
In the event that we do not meet all of the relevant criteria, we figure out which criteria are not correct and write that to the diagnostics dictionary. Finally, we return all results to the end user. Now that we have a function to normalize our data should we need it, we can update the run_tests() function to incorporate this, as well as a slew of new tests.
A Framework for New Tests
An updated test runner. For the sake of parsimony, most mentions of the diagnostics dictionary have been removed.
The first thing we do in the function is to perform statistical calculations, retrieving data such as mean, standard deviation, median, and MAD. We have also added the minimum (min), maximum (max), and count of observations (len) to the dictionary, as they will be useful for the upcoming tests. After this, we perform a normalization check and get a response indicating whether we should use the fitted results. Regardless of whether we decide to use the fitted results, we first want to use the original data to perform our checks from Chapter 6. The pragmatic reason is that doing so means we don’t need to change as many unit tests in this chapter—transformed data will, by nature of the transformation, not necessarily share the same outlier points as untransformed data.
After running these initial tests, we mark them as having run and add our new tests as not having run. We also create columns in our DataFrame for the new tests. This way, any references to the columns later on are guaranteed to work. Finally, if the use_fitted_results flag is True, we will set the fitted value to our (potentially) transformed dataset and perform a new set of statistical calculations on the fitted data. Then, we ready ourselves to run any new tests. The following sections cover the three new tests we will introduce, why they are important, and how we will implement them.
Grubbs’ Test for Outliers
Grubbs’ test for outliers is based on Frank Grubbs’ 1969 article, Procedures for Detecting Outlying Observations in Samples (Grubbs, 1969). This test outlines a strategy to determine if a given dataset has an outlier. The assumption with this test is that there are no outliers in the dataset, with the alternative being that there is exactly one outlier in the dataset. There is no capacity to detect more than one outlier.
Although this test is quite limited in the number of outliers it produces, it does a good job at finding the value with the largest spread from the mean and checking whether the value is far enough away to matter.
Finding differences between sets to determine if there are outliers
The find_differences() function takes in two datasets: our fitted values (col) and the output from the call to Grubbs’ test (out). We convert each of these to a set and then find the set difference—that is, any elements in the fitted values set that do not appear in the results set. Note that duplicate values are not allowed in a set and so all references to a particular outlier value will become outliers. For example, if we have a fitted values dataset of [ 0, 1, 1, 2, 3, 9000, 9000 ], the fitted values set becomes { 0, 1, 2, 3, 9000 }. If our output dataset is [ 0, 1, 1, 2, 3 ], we convert it to a set as well, making it { 0, 1, 2, 3 }. The set difference between these two is { 9000 }, so every value of 9000 will become an outlier. We do this by creating a new result column that has as many data points as we have elements in the fitted values dataset. Then, for each value in the set difference, we find all references in the fitted values dataset matching that value and mark the matching value in our results dataset to 1.0 to indicate that the data point represents an outlier. We then return the results list to the caller.
The reasons we loop through sdiff, despite there being only one possible element in the set, are twofold. First, this handles cleanly the scenario in which sdiff is an empty set, as then it will not loop at all. Second, we’re going to need this function again for the next test, the generalized ESD (or GESD) test.
Generalized ESD Test for Outliers
The generalized extreme Studentized deviate test, otherwise known as GESD or generalized ESD, is the general form of Grubbs’ test. Whereas Grubbs’ test requires that we have either no outliers or one outlier, generalized ESD only requires that we specify the upper bound of outliers. At this point, you may note that we already keep track of a max_fraction_anomalies user input, so we could multiply this fraction by the number of input items and use that to determine the maximum upper bound. This idea makes a lot of sense in principle, but it does not always work out in practice. The reason for this is a concept known as degrees of freedom.
Degrees of freedom is a concept in statistics that relates to how many independent values we have in our dataset and therefore how much flexibility we have in finding missing information (in our case, whether a particular data point is an outlier) by varying those values. If we have a dataset containing 100 data points and we estimate that we could have up to five outliers, that leaves us with 95 “known” inliers. Generalized ESD is built off of a distribution called the t (or student-t) distribution, whose calculation for degrees of freedom is the number of data points minus one. For this calculation, we take the 95 expected inliers, subtract 1, and end up with 94 degrees of freedom. Ninety-four degrees of freedom to find up to five outliers is certainly sufficient for the job. By contrast, if we allow 100% of data points to be outliers, we have no degrees of freedom and could get an error. Given that our default fraction of outliers is 1.0, using this as the input for generalized ESD is likely going to leave us in trouble.
Instead, let us fall back to a previous rule around outliers and anomalies: something is anomalous in part because it is rare. Ninety percent of our data points cannot be outliers; otherwise, the sheer number of data points would end up making these “outliers” become inliers! Still, we do not know the exact number of outliers in a given dataset, and so we need to make some estimation. The estimation we will make is that we have no more than 1/3 of data points as potential outliers. Along with a minimum requirement of 15 observations, this ensures that we have no fewer than 5 potential outliers for a given dataset and also that we have a minimum of 9 degrees of freedom. As the number of data points in our dataset increases, the degrees of freedom increases correspondingly, and our solution becomes better at spotting outliers.
The code to check for outliers using generalized ESD
Dixon’s Q Test
The final test we will implement in this chapter is Dixon’s Q test, named after Wilfrid Dixon. Dixon’s Q test is intended to identify outliers in small datasets, with a minimum of three observations and a small maximum. The original equation for Dixon’s Q test specified a maximum of ten observations, although Dixon later came up with a variety of tests for different small datasets. We will use the original specification, the one commonly known as the Q test, with a maximum of 25 observations as later research showed that the Q test would hold with datasets of this size. The formula for the Q test is specified in Listing 7-10. We first sort all of the data in x in ascending order, such that x1 is the smallest value and xn is the largest.
Listing 7-10. The calculation for Q
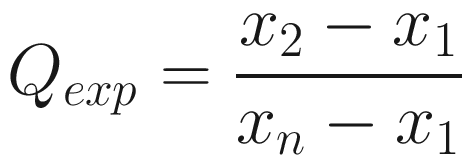
Once we have calculated the value of Q, we compare it against a table of known critical values for a given confidence level. In our case, we will use the 95% confidence level. Doing so, we check if our expected Q value is greater than or equal to the critical value. If so, the largest data point is an outlier. We can perform a similar test to see if the minimum data point is an outlier. This means that in practice, we can spot up to two outliers with Dixon’s Q test: the maximum value and the minimum value.
The code for Dixon’s Q test
We first create a list of critical values for a given number of observations at a 95% confidence level. We turn this into a dictionary whose key is the number of observations and whose value is the critical value for that many observations. After sorting the data, we calculate the minimum value’s Q, following the formula in Listing 7-10. Note that the division is in a try-catch block so that if there is no variance, we do not get an error. Instead, the numerator is guaranteed to be 0. After calculating Q_min, we compare its value to the appropriate critical value and call that Q_mindiff. We can perform a very similar test with the maximum data point, comparing it to the second largest and dividing by the total range of the dataset.
After calculating Q_mindiff and Q_maxdiff, we check to see if either is greater than or equal to zero. A value less than zero means that the data point is an inlier, whereas a value greater than or equal to zero indicates an outlier. Finally, as with the other tests in this chapter, in the event that there are multiple data points with the same value, we mark all such ties as outliers.
Now that we have three tests available to us, we will need to update our calling code to reference these tests.
Calling the Tests
Add the three new tests.
In order to run Grubbs’ test, we need at least 7 observations; running Dixon’s Q test requires between 3 and 25 observations; and generalized ESD requires a minimum of 15 observations. If we run a given test, we set the appropriate column in our DataFrame to indicate the results of the test; otherwise, the score will be -1 for a test that did not run.
Because we have new tests, we need updated weights. Keeping the initial tests’ weights the same, we will add three new weights: Grubbs’ test will have a weight of 0.05, Dixon’s Q test a weight of 0.15, and generalized ESD a weight of 0.30. These may seem low considering how much work we put into the chapter, but it is for good reason: Grubbs’ test and Dixon’s Q test will mark a maximum of one and two outliers, respectively. If there are more anomalies in our data, then they will incorrectly label those data points as inliers. In practice, this provides a good signal for an extreme outlier but a much weaker signal for non-extremes. Generalized ESD has less of a problem with this, as we specify that up to 20% of the data points may be outliers and so its weight is commensurate with the other statistical tests.
A new way to score results
The function first creates a dictionary called tested_weights, which includes weights for all of the statistical tests we successfully ran, using the value of the weight if we did run the test or 0 otherwise. Then, we sum up the total weight of all tests. Finally, we calculate a new anomaly score as the sum of our individual scored results multiplied by the test weight and divide that by 95% of the maximum weight. The 0.95 multiplier on maximum weight serves a similar purpose to the way we oversubscribed on weights in Chapter 6. The idea here is that even if we have a low sensitivity score, we still want some of the extreme outliers to show up. As a result, our anomaly score for a given data point may go above 1.0, ensuring that the data point always appears as an outlier regardless of the sensitivity level.
With these code changes in place, we are almost complete. Now we need to make a few updates to tests, and we will have our outlier detection process in place.
Updating Tests
A natural result of adding new statistical tests to our ensemble is that some of the expected results in our unit and integration tests will necessarily change. We are adding these new statistical tests precisely because they give us added nuance, so there may be cases in which we had four outliers based on the results of Chapter 6, but now we have five or three outliers with these new tests. As such, we will want to observe the changes that these new statistical tests bring, ensure that the changes are fairly reasonable, and update the unit and integration tests to correspond with our new observations. In addition, we will want to add new tests to cover additional functionality we have added throughout this chapter.
Updating Unit Tests
Some of the tests we created in Chapter 6 will need to change as a result of our work throughout this chapter. The test case with the greatest number of changes is the test that ensures that sensitivity level changes affect the number of anomalies reported. There are several instances in which the number of outliers we saw in Chapter 6 will differ from the number we see in Chapter 7. For example, when we set the sensitivity level to 95 in Chapter 6, we got back 15 outliers. With these new tests in place, we are down to 12 outliers. With the sensitivity level at 85, we went from eight down to five outliers, 75 moves from five to two, and a sensitivity level of 1 goes from one outlier to zero outliers.
This turns out to be a positive outcome, as a human looking at the stream { 1, 1, 2, 2, 3, 3, 4, 4, 5, 5, 6, 7, 8, 9, 10, 2550, 9000 } sees two anomalies: 2550 and 9000. Ideally, our outlier detection engine would only return those two values as outliers. We can see that at least in the range 25–75 (which includes our default of 50), we do in fact get two outliers. There are a few other tests that need minor changes as well for similar reasons.
A test to ensure that our normalization tests execute as expected on various types of datasets
In this test, we do not need to perform any special preparation work, and so the Arrange section of our test is empty. We can also see that for the most part, there is agreement between these tests, at least for the five extreme cases I chose. We could find other situations in which the tests disagree with one another, but this should prove sufficient for the main purpose of our test.
Combining the three normalization tests provides the expected result
Because there is disagreement on the larger uniform dataset case, we expect this function to return False. In order for the test to return True, all three statistical tests must be in agreement.
Ensure that we only perform normalization on valid datasets
The code to determine if we run a specific statistical test
We can confirm whether a test ran by reading through the diagnostics dictionary, looking inside the Tests Run object for a particular test name.
After creating all of the relevant tests, we now have 80 test cases covering a variety of scenarios. We will add more test cases and tests as we expand the product, but this will do for now. Instead, we shall update some existing integration tests and then add new ones for Chapter 7.
Updating Integration Tests
Just like with the unit tests, we will need to perform some minor alterations to integration tests. For example, the integration test named Ch06 – Univariate – All Inputs – No Constraint returned 14 outliers in Chapter 6, but with the new tests, that number drops to 8.
We expect normalization to take place for this call.
The final test, in which we check for the existence of a fitted lambda (indicating that we performed Box-Cox transformation), is the way in which we indicate that normalization did occur as we expected. We have similar checks in the other tests as well.
Multi-peaked Data
Now that our univariate anomaly detection engine is in place, we are nearly ready to wrap up this chapter. Before we do so, however, I want to cover one more topic: multi-peaked data.
A Hidden Assumption

A graph plots density versus value. Log normal is a right-skewed curve and normal is a normal curve.
Two distributions of data, each of which has a single peak

A sinusoidal curve plots density versus value. Values are estimated. Multi-peaked (negative 4, 0.00), (0, 0.17), (5, 0.00), (12, 0.11), and (16, 0.00).
A dataset with two clear peaks
The results of a test with multi-peaked data
Value | Anomaly Score |
|---|---|
1 | 0.169 |
2 | 0.164 |
3 | 0.158 |
4 | 0.153 |
5 | 0.149 |
6 | 0.146 |
50 | 0.001 |
95 | 0.148 |
96 | 0.151 |
97 | 0.155 |
98 | 0.160 |
99 | 0.165 |
100 | 0.171 |
Not only does 50 not get marked as an outlier, it’s supposedly the least likely data point to be an outlier! The reason for this is that our statistical tests are focused around the mean and median, both of which are (approximately) 50 in this case.
The Solution: A Sneak Peek
Now that we see what the problem is, we can come up with a way to solve this issue. The kernel of understanding we need for a solution is that we should not necessarily think of the data as a single-peaked set of values following from an approximately normal distribution. Instead, we may end up with cases in which we have groups of data, which we will call clusters. Here, we have two clusters of values: one from 1 to 6 and the other from 95 to 100. We will have much more to say about clustering in Part III of the book.
Conclusion
In this chapter, we extended our capability to perform univariate anomaly detection. We learned how to check if an input dataset appears to follow from a normal distribution and how to perform Box-Cox transformation on the data if it does not follow a normal distribution, and incorporated additional tests that expect normalized data in order to work. Our univariate anomaly detector has grown to nearly 400 lines of code and has become better at picking out outliers, returning fewer spurious outliers as we increase the sensitivity level.
In the next chapter, we will take a step back from this code base. We will build a small companion project to visualize our results, giving us an easier method to see outputs than reading through hundreds of lines of JSON output.