
Chapter 3. Cache Optimization
There’s no question that the longer a web page takes to load, the less attention a user will give it. Curious minds might wonder what happens to users’ attention as a web page becomes faster. How fast can something get without users noticing that they had to wait for it? Research shows that, in general, people perceive load times of 100 milliseconds or less as seemingly instantaneous. This is the Holy Grail of web performance; if we could make a web page load faster than a user can notice, our work here would be done. Easy, right? Not quite.
Think about everything that could go wrong while a page loads. Before the server can even send the first bit of data, a few round-trips’ worth of negotiation take place just to open the lines for communication. Each phase in the connection chips away at the 100-millisecond budget for which we’ve aimed. It’s not long before the users notice that they’re waiting on us to load the page. Caching to the rescue.
What is a cache? A textbook definition might be that a cache is just a portion of computer memory temporarily set aside for data needed in the near future. Conceptually, caching allows an application to quickly access data. The canonical example of caching is saving the results of CPU computations in random-access memory (RAM) as opposed to disk space. The time required to read from and write to disk is much greater than it is with memory, so effective caching can have profound impacts on computation time. Even newer technology like solid state drives (SSDs) are slower to use than RAM due to hardware limitations.
Instead of a CPU, RAM, and persistent storage drives, we’re concerned with users, their browsers, and our web server. Analogously, a user needs to fetch information and instead of taking the long and slow route to our server, the user would simply be able to access a local copy minus the waiting. With the browser’s cache, we are able to save copies of resources like images, stylesheets, and scripts directly on the user’s machine. The next time one of these resources is needed, it can be served from cache instead of taking the slower journey across the Internet.
Of course, there are limitations to the cache. Most important, it has a finite size. Modern browsers’ caches are in the tens of megabytes, which may be enough to comfortably fit an average-sized website. But the browser cache is shared among all websites. There is bound to be a congestion issue. When this happens, the browser performs an eviction. One or more unlucky resources are removed from the cache to make room for new ones. Another consideration is that resources are not expected to be valid indefinitely; each resource is saved along with metadata about how long the browser can consider it to be fresh. Even if a resource is in the cache and the user makes a request for that same resource, it may be served over the network if the cached version is not fresh.
We’ll explore the concept of freshness later in this chapter and provide details of how to configure resources efficiently for caching. We will also look at the tools WebPageTest provides to measure how effectively a website uses browser caching.
Enabling Repeat View
Tests that run on WebPageTest default to a “cold” cache experience much like that of a user who has never been to a website before. This allows the tool to record the network activity of all resources needed to build the page. The test browser follows the instructions of the resources’ response headers and saves them to the cache. Other client-side caches are warmed up—for example, the DNS cache that saves a map of domain names to IP addresses for resources. Before each test run, however, these caches are flushed to provide a clean and consistent environment.
Throwing out the test client’s cache is a great way to simulate the “worst case” scenario in which no resources are locally available, but in reality we know that this is hardly always the case. Users revisit websites all the time and some sites even share resources. For example, the popular jQuery JavaScript library is often included in websites through a shared and public CDN. If a user visits two websites that both reference this resource, the second site will have the performance benefit of using the cached version. So if WebPageTest clears the cache before each test, how can we represent these use cases?
The Repeat View configuration setting is one way that WebPageTest is able to address this (Figure 3-1). To enable it, select the First View and Repeat View option. Each “view” is effectively another instance of the test run. The terminology may be getting confusing at this point, so think of it taxonomically as a single test containing multiple runs, each of which contains one or two views. First View refers to the cold cache setup in which nothing is served locally, whereas Repeat View refers to the warm cache containing everything instantiated by the first view. In addition to selecting the radio button UI on the page, you can also enable repeat views by setting the querystring parameter fvonly to 0. So, for example, the URL webpagetest.org?fvonly=0 would preset the radio button to the First View and Repeat View option.
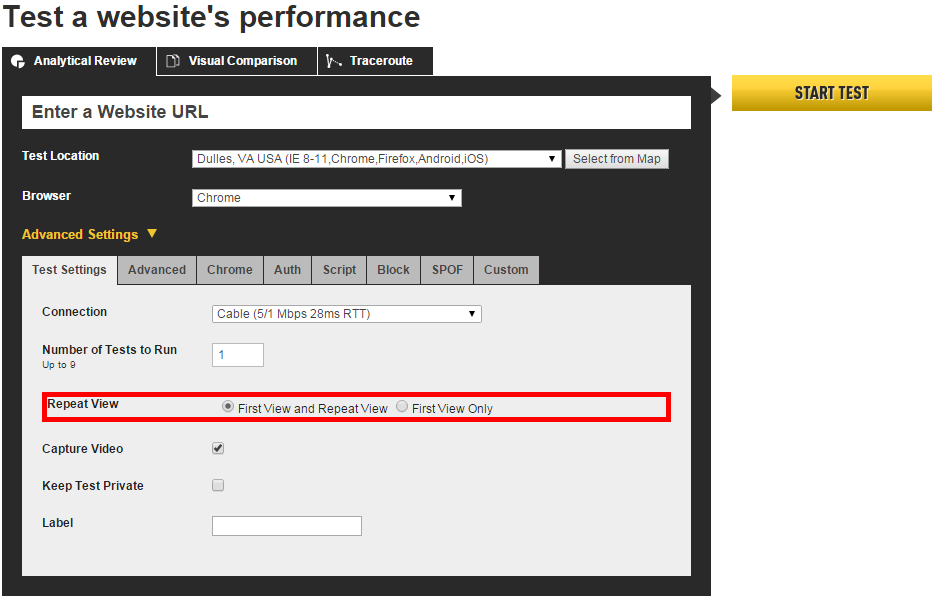
Figure 3-1. The option to enable repeat views for each test run is on the WebPageTest home page in the Advanced Settings section
You may be thinking that you might as well run all tests with this option set. After all, it shows a different perspective that may be useful for analysis. Despite the convenience of always having a repeat view available, keep in mind that someone has to pay for it—not necessarily monetarily but rather with time and resources. You pay for repeat views by waiting for your tests to complete. For all intents and purposes, enabling repeat view effectively doubles the test duration because it executes each test run in both cache states. When you are running many tests or a test with many runs, you can get your results sooner by ensuring that each test does less work. This is also important because WebPageTest is a public tool. It may be the case that there is someone else in the world waiting to run his own test behind yours. The longer your test takes to run, the longer that person has to wait (and the people behind him, too). And it should go without saying, but we will say anyway: WebPageTest itself has finite resources. It’s not in danger of running out of space any time soon, but if you could save a few megabytes of disk space by only enabling repeat view when you need it, why not? If you are running your own private instance of WebPageTest, this point may be especially critical. Simply put, use discretion with this and other configuration options that consume additional resources like the number of test runs (which are capped at nine for this reason) and the screenshot/video options.
There are also some limitations to the usefulness of repeat views. By definition, this view is an identical page load to the first view. For the purposes of synthetic testing, this is great for analyzing the cacheability of the resources of a single page. Inconveniently, real users tend to follow a flow of pages—starting at the home page and navigating through to secondary content, for example.
Repeat views are not necessarily able to demonstrate the warm-cache experience that real users experience throughout the website. If a user visits Page B via Page A and you run first and repeat view tests on Page B, you would not be accounting for the differences in resources between the two pages. You may misinterpret the repeat view results to mean that Page B’s warm cache state is better than it actually is. The reality is that you need a way to load both pages synthetically in order to represent the scenario of visiting a page with another page’s resources in cache. Repeat views are limited to loading a single page with its own resources in cache. To resolve this issue, we will need a more powerful tool that is flexible enough to handle multiple pages. That tool is reserved for a later chapter; see “Flow View” for more information.
Analyzing Cachability
After configuring a test to execute repeat views as described in the previous section, you must then analyze the results to determine how well resources are being cached. To do so, you need to know both what to look for and where to look.
How long a resource will be cached by the browser (if at all) is determined by two factors: age and time to live (TTL). Both of these values are configured by the server in the form of HTTP headers.
The age of a resource can be identified using one of two headers: entity tags (ETags) or the Last-Modified header. An entity tag is simply a unique identifier representing the content of a resource. As the content changes—for example, updating an image but retaining the same URL—the ETag would change respectively. Alternatively, the Last-Modified header is a date stamp of the time at which the resource most recently changed, as shown in Example 3-1. Either header can be used to identify the age, or state, of a resource at the time it is downloaded and cached.
Example 3-1. Sample resource age/state HTTP headers
Last-Modified: Fri, 19 Jan 2007 04:40:18 GMT ETag: W/"0a56eeb833bc71:2f7"
After the user’s browser has downloaded and cached the resource, it will stay in cache until it is evicted to make room for newer resources, or until it expires. To determine the expiration date, browsers rely on one of two TTL headers: Expires or the max-age property of Cache-Control. The Expires header provides a date stamp of the exact moment when the resource will expire. Similarly, the Cache-Control: max-age (sometimes referred to as CCMA) header specifies the number of seconds from the time of download until the resource expires. See Example 3-2 for example values for these headers.
Example 3-2. Sample resource TTL HTTP headers
Cache-Control: max-age=31536000 Expires: Fri, 20 Nov 2015 06:50:15 GMT
Now that you know what to look for, let’s talk about where to find this data. First, you’ll need to head over to the results (or details) page for a test run, which is where the waterfall diagrams are shown. Clicking on any request row in the waterfall will invoke a panel with summary information about the resource. The three other tabs in this panel let you drill down into the request headers, response headers, and the response body. From this panel, this chapter is only concerned with the Request and Response tabs.
The Response tab displays all of the headers sent back from the server to the browser, including the caching headers discussed earlier (ETag, Cache-Control, Expires, and Last-Modified).
Heuristic Caching
What you see in the repeat-view waterfall diagram is helpful toward understanding which resources must be downloaded across subsequent visits. However, what you don’t see may mislead you.
The omission of resources from the repeat-view waterfall suggests that they were served from cache. You would generally be right to assume that these resources were configured to persist across page views, but there are edge cases in which resources may only appear to be correctly configured.
The HTTP/1.1 specification permits user agents to estimate how long to keep a resource in cache using heuristics:
Since origin servers do not always provide explicit expiration times, HTTP caches typically assign heuristic expiration times, employing algorithms that use other header values (such as the Last-Modified time) to estimate a plausible expiration time. The HTTP/1.1 specification does not provide specific algorithms, but does impose worst-case constraints on their results.
13.2.2 Heuristic Expiration, http://www.w3.org/Protocols/rfc2616/rfc2616-sec13.html
According to the specification, if a browser downloads a resource with an unknown lifetime, it can assign an expected lifetime known as a heuristic expiration time. What this means for you is that the repeat view may not be entirely what it seems. You may incorrectly assume that a resource has been loaded from cache because it has been properly configured to do so. Under some circumstances, a browser may cache a resource even when not explicitly instructed by the server’s response headers. As a result, WebPageTest will not show this resource as having loaded over the network in the repeat view waterfall.
You may be wondering why you should even bother to set caching headers in the first place if browsers will do the work for you. The answer is that browsers only estimate how long one of these resources should be cached, and that control should always be in the developer’s hands. Despite granting the authority of heuristic expiration to browsers, the specification puts the onus on developers to maintain this control:
Since heuristic expiration times might compromise semantic transparency, they ought to be used cautiously, and we encourage origin servers to provide explicit expiration times as much as possible.
13.2.2 Heuristic Expiration, http://www.w3.org/Protocols/rfc2616/rfc2616-sec13.html
Furthermore, it’s not always clear how long implicitly cached resources should persist. The specification stops short of imposing an algorithm to determine the lifetime of these resources and leaves that up to the browser vendors. One way to get an exact answer is to go directly to the source. That is, check the browser’s source code.
Chrome’s source code is freely available, so we can see how it implements Section 13.2.2. Of interest is the file for evaluating resources’ HTTP response headers, aptly named http_response_headers.cc.
if((response_code_==200||response_code_==203||response_code_==206)&&!must_revalidate){// TODO(darin): Implement a smarter heuristic.Timelast_modified_value;if(GetLastModifiedValue(&last_modified_value)){// The last-modified value can be a date in the future!if(last_modified_value<=date_value){lifetimes.freshness=(date_value-last_modified_value)/10;returnlifetimes;}}}
As you can see, a resource can be implicitly cached for up to 10% of the difference between the time it was downloaded and the time it was last modified. In other words, if a user loads a resource only an hour old without any explicit cache headers, Chrome will cache it for six minutes. As the resource ages, its heuristic expiration time also increases. If you consider that the recommended cache lifetime for a static resource is 1 year, realize that you can only get this kind of performance for resources over 10 years old. This is exactly why you should take control of the HTTP response headers to include explicit cache instructions for browsers to ensure that the resource is handled exactly how you intend.