
Chapter 16. Privacy and Security
This chapter considers privacy and security issues that should be evaluated while writing a RESTful application or service. Our discussion will go beyond the usual Rails recommendations and security best practices; we will also explore the implications of handling and collecting data about users’ behavior and preferences.
How to Protect User Privacy
Privacy is currently one of those hot topics in information technology. This is probably because there are two primary opposing views on the subject:
- Users do not care about privacy.
- Users wouldn’t want to be “social” if they knew what it really meant for their privacy.
Both views are utterly right and utterly wrong at the same time. The truth in fact is that users do see a benefit in disclosing their preferences and in having websites collect their data. They receive value back in terms of utility, or in other words a better service already filtered and tailored for their needs and tastes. Still, by collecting user data, over time you will end up with a history of your users’ behavior on your platform, and some information about their activity on other platforms as well. This can be a potential source of a whole class of issues.
The first important step when it comes to security is understanding what kinds of sensitive data your service is storing. This may include anything from credit card and banking information, to physical addresses or personal preferences that the users would like to keep private.
Once you know what kind of data you are storing about your users, you should try to understand how this data can be shared by the users (if that’s possible) and who could have access to it.
This question might seem trivial, but it is actually crucial when you are dealing with user data. To understand why, I will introduce the notion of a quasi-identifier. We are all familiar with the concept of a unique identifier; we use it constantly. A unique identifier is “any identifier which is guaranteed to be unique among all the identifiers used for [a class of] objects and for a specific purpose.” This could be for example a social security number, a serial number, a credit card number—something that is never repeated.
A quasi-identifier instead is not unique in itself, but combined with other quasi-identifiers can be sufficiently well correlated with an entity as to create a unique identifier.
To understand this notion, imagine that you are in a remote location and you are using Twitter with the location sharing services enabled. Nobody knows your username, yet some people might know your location and use that information to find your identity on Twitter, since very few people might be tweeting from that location.
This is certainly an extreme case, considering how many people use Twitter worldwide. But you might be working on an application for which the number of users at a certain time or in a specific location is very low, and a simple action by an individual could become a quasi-identifier for a possible attacker.
For example, think of a smart transportation service that is sharing online the number of people getting on and off of certain buses at a certain time. Imagine that someone always catches the bus at the beginning of the run and gets off only toward the end. More often than not, only a few users get on at the beginning of the route and off at the end.
Therefore, with some other information that could be used as quasi-identifiers in correlation with the relative frequency of people hopping on and off the bus, it would be relatively easy to make assumptions regarding who those few users are.
When you think of private information, think of it like puzzle pieces. Each piece of information, or in other words each quasi-identifier, can be used to assume other information and eventually create a complete picture of a user and her activities.
This can particularly be an issue when data from different services is combined. Each activity, each data point, each preference expressed probably corresponds to a little piece of the puzzle, and before you realize it the user’s identity has been leaked to third parties.
Reasoning about user privacy implies understanding the trade-off between providing a tailored and useful service and protecting users’ private data from involuntary leaks.
Up to now, in an online context, the right to privacy has commonly been interpreted as a right to “information self-determination.” Acts typically claimed to breach online privacy concern the collection of personal information without consent, the selling of personal information, and the further processing of that information.
This definition of privacy breach can be considered valid as long as the users have direct control over the data they have created and who they are sharing it with. The problem with this approach is that users have practically lost direct control over their data, considering the amount of user information that is constantly created, shared, and consumed online by a complicated network of applications and services.
As application developers, we should always give users an intuitive way of controlling who has access to their data and how that data is shared on our platforms and with third parties.
Furthermore, you might consider anonymizing the data before third parties can access it through your APIs, in a way that reduces the possibility that some user activity might be used as a quasi-identifier.
In such a situation, your API will only request data from an anonymized database that will contain only data that is considered safe to be accessed by third parties (i.e., some features of the original dataset will have been removed to avoid leakage of sensitive information).
There are different techniques here that might seem a bit academic, but in my opinion they are worth considering if you are dealing with potentially sensitive user data.
Two very common strategies of anonymization are k-anonymity and differential privacy. We are going to briefly introduce both of them.
k-anonymity
k-anonymity is a concept that was first formulated by Latanya Sweeney in a paper published in 2002. K-anonymity is concerned with reducing the possibility that a quasi-identifier can be used to infer unique properties about a user. More specifically, the problem that k-anonymity tries to solve can be formulated in the following terms: “Given user-specific field-structured data, is it possible to produce a release of the data with scientific guarantees that the individuals who are the subjects of the data cannot be re-identified while the data remain practically useful?” Therefore, a release of some data is said to have the k-anonymity property “if the information for each person contained in the release cannot be distinguished from at least k-1 individuals whose information also appear in the release.”
K-anonymity algorithms are usually intended to be used when complete databases of sensitive information are disclosed to the public. As a concept, it can also be used to assess the possibility that information contained in a certain set of data could be used for a privacy attack.
Differential Privacy
Differential privacy is a concept rooted in the notion of statistical disclosure control (SDC). In 1977, Tore Dalenius wrote what is now considered a classic paper on SDC,1 providing a formal definition of the topic and theory of statistical disclosure and finally proposing a methodology for SDC. The objective of SDC is summarized in the question: “How is it possible to publish some useful information regarding a group of individuals?” That is, how can we disclose a statistic about a population, without violating the privacy of individuals?
SDC is connected to the notion of semantic security for cryptographic systems. Given a clear text and a ciphertext, the definition of semantic security formulates that: “Whatever is efficiently computable about the cleartext given the ciphertext, is also efficiently computable without the ciphertext.” Alternatively, it could be said that no information can be learned regarding a given plain text by seeing the ciphertext, which could not be learned without seeing the ciphertext.
Per Dalenius, in the database field, the notion of semantic security could be translated into: “Having access to a statistical database should not enable one to learn anything about an individual that could not be learned without access.” Cynthia Dwork in her work on differential privacy states that this kind of privacy cannot be achieved, since possible attackers might possess some auxiliary information that could help them isolate key features regarding a specific individual.
This concept is translated into practical terms by Dwork’s definition of differential privacy: “the risk to one’s privacy, or in general, any type of risk, such as the risk of being denied automobile insurance, should not substantially increase as a result of participating in a statistical database.” Differential privacy is, therefore, a mechanism designed to provide strong privacy guarantees for an individual’s input to a (randomized) function, regardless of whether any individual opts into or out of a database.
Privacy-Enhancing Technologies
While the notions of k-anonymity and differential privacy might seem like academic, abstract mathematical concepts, they are often the theoretical foundation for safely disclosing user data or sharing information on the Internet or in a network of distributed services and applications.
Privacy-enhancing technologies (PETs) are therefore a set of measures that can be adopted to protect information privacy by eliminating or minimizing personal user data and preventing unwanted leaks, without a considerable loss of system functionality. One or several PETs can be adopted with different objectives in mind, including:
- Increase user control over their personal data
- Minimize the personal data collected and used by third-party service providers and merchants
- Allow for a degree of anonymity and unlinkability, i.e., the possibility that profiles from different service or virtual identities can be linked to a unique identifier or physical persona
- Facilitate the exercise the user legal rights
- Achieve informed consent regarding data usage and dissemination policies
- Allow users to safely log and track their activity on your platform
- Technically enforce terms of service and conditions over the use of data and your privacy policy
Is My Data Safe?
Data security means protecting your data from any possible destructive agents and the unwanted actions of unauthorized parties. Whether you are deploying your own infrastructure or using a cloud-based service, there are different issues in data security that need to be considered:
- Where is your data stored? Are you infringing any law in the country where your data is stored?
- Is your data encrypted?
- Who could potentially access your data?
- Is your data backed up?
These are the questions that will need to be answered to secure your data—and these are all questions related to system security.
Generally speaking, system security is a wide topic, covering several layers and influencing the application and service design at many different levels.
Since you have reached the last chapter of this book on RESTful Rails development, by now you might have noticed that the approach that we have followed is to break down complex problems into smaller ones. Each small problem was solved with a new API, and the APIs were consumed by a set of different services and applications.
This approach certainly has various benefits, while also carrying with it various intrinsic issues. Some of these issues can be dealt with at the microservice level, while some others need to be identified and resolved at the macro application level.
We will try to follow the same approach when it comes to security. Some security concerns can be analyzed at the service level, but others will need to be evaluated at the distributed application level.
There are a number of common sources of insecurity when reasoning about data. Some can be dealt with at the framework level (Rails), and others need to be addressed with design choices.
There are different ways and techniques to address the security of an application or system. If you are familiar with software testing strategies, you have probably heard of white box testing and black box testing. These are two opposite testing strategies: in white box testing you consider the system design and its functionality, and you test different cases that are considered appropriate; in black box testing instead you basically try to break the system and see what happens.
White box testing in the security development lifecycle (SDL) attempts to highlight possible vulnerabilities within the architectural design of the application and/or the actual code implementation of a single service.
White box analysis often implies the use of formal mathematical methods to prove that some function(s) or a certain routine can or cannot contain runtime errors. These methods are often approximate, as it was proven by Alan Turing in 1936 that a general algorithm to solve the halting problem (i.e., “the problem of determining, from a description of an arbitrary computer program and an input, whether the program will finish running or continue to run forever”) for all possible program-input pairs cannot exist.
Static analysis often uses data-flow analysis, “a technique for gathering information about the possible set of values calculated at various points in a computer program.” With this technique, a program’s control flow graph (CFG) is used to determine how a particular value is propagated when assigned to a variable. The information gathered is often used to understand if the program or the unit examined is functioning according to the specification.
Another analytical procedure used in static analysis is taint analysis, which “attempts to identify variables that have been ‘tainted’ with user controllable input and traces them to possible vulnerable functions also known as a ‘sink.’” Tainted variables that slip through and are passed to a sink without first being sanitized are flagged as vulnerabilities.
Static analysis can be performed at different levels of an application (or sometimes, organization). The lowest level is the unit level. Here, a specific portion of the application is considered in isolation. At the next level, the technological level, interactions between different units are taken into consideration. Then we consider interactions at the system level, taking into account different units, programs, and services. At the last level we consider interactions at the business level.
Common Sources of Insecurity
A common source of insecurity in web application is just about anywhere the user can input data.
Data inputs can be used by a possible attacker in many different ways. We’ll look at a few of them here.
Command-line injection
Command-line injection might also be possible if your application executes commands in the underlying operating system. In this situation you have to be especially careful if the user is allowed to enter the whole command, or even just a part of it. This can be particularly dangerous since in most cases you can theoretically execute another command at the end of the first one, by concatenating them with a semicolon (;) or a vertical bar (|).
To prevent this type of attack, consider using a method that passes command-line parameters safely, like the system command:
system([env,]command...[,options])->true,falseornilExecutescommand...inasubshell.command...isoneoffollowingforms.commandline:commandlinestringwhichispassedtothestandardshellcmdname,arg1,...:commandnameandoneormorearguments(noshell)[cmdname,argv0],arg1,...:commandname,argv[0]andzeroormorearguments(noshell)systemreturnstrueifthecommandgiveszeroexitstatus,falsefornonzeroexitstatus.Returnsnilifcommandexecutionfails.Anerrorstatusisavailablein$?.
HTTP header injection
Another possible attack is HTTP header injection. HTTP header injection attacks work by the attacker injecting certain fields, or text, into the header of a request to the server. Header fields should always be escaped when used in your application, especially if any of these fields are based on user input (even partly).
HTTP response splitting
An attack related to HTTP header injection is HTTP response splitting. The Security Guide gives the following example:
In HTTP, the header block is followed by two CRLFs and the actual data (usually HTML). The idea of Response Splitting is to inject two CRLFs into a header field, followed by another response with malicious HTML. The response will be:
HTTP/1.1302Found[Firststandard302response]Date:Tue,12Apr200522:09:07GMTLocation:Content-Type:text/htmlHTTP/1.1200OK[SecondNewresponsecreatedbyattackerbegins]Content-Type:text/html<html><fontcolor=red>hey</font></html>[Arbitarymaliciousinputisshownastheredirectedpage]Keep-Alive:timeout=15,max=100Connection:Keep-AliveTransfer-Encoding:chunkedContent-Type:text/html
SQL injection
SQL injection attacks are carried out with the goal of influencing database queries and actions by manipulating web application parameters. A popular goal of these attacks is to bypass authorization and hence gain access to data in the database.
Ruby on Rails already contains a number of measures to prevent SQL injection attacks. A good source to learn more about possible attacks, how they are implemented, and how to prevent them is Rails SQL Injection Examples. The web app contains a list of possible situations where it is actually possible to perform a SQL injection attack in Rails. It also lists all query methods and options in Active Record that should be treated with extra attention since they do not sanitize raw SQL arguments.
Is Rails Secure?
To answer the question “Is Rails secure?” we should start by considering why Rails was developed and how it is actually used.
Generally speaking the purpose of a web application framework is to help developers create web applications. As part of the framework, some security mechanisms to help you in securing your app are also included.
Having said this, no framework is particularly more secure than any other. In general, if they’re used correctly it is possible to build secure applications with many different frameworks. Each of them will offer its own features to solve issues that you might encounter when developing an app, security issues included.
The Rails team handles support by categorizing changes made to the framework into four groups: new features, bug fixes, security issues, and severe security issues. They are handled as follows:
1 New Features
New features are only added to the master branch and will not be made available in point releases.
2 Bug Fixes
Only the latest release series will receive bug fixes. When enough bugs are fixed and [it’s] deemed worthy to release a new gem, this is the branch it happens from.
In special situations, where someone from the Core Team agrees to support more series, they are included in the list of supported series.
Currently included series: 4.2.Z, 4.1.Z (Supported by Rafael França).
3 Security Issues
The current release series and the next most recent one will receive patches and new versions in case of a security issue.
These releases are created by taking the last released version, applying the security patches, and releasing. Those patches are then applied to the end of the x-y-stable branch. For example, a theoretical 1.2.3 security release would be built from 1.2.2, and then added to the end of 1-2-stable. This means that security releases are easy to upgrade to if you’re running the latest version of Rails.
Currently included series: 4.2.Z, 4.1.Z.
4 Severe Security Issues
For severe security issues we will provide new versions as above, and also the last major release series will receive patches and new versions. The classification of the security issue is judged by the core team.
Currently included series: 4.2.Z, 4.1.Z, 3.2.Z.
5 Unsupported Release Series
When a release series is no longer supported, it’s your own responsibility to deal with bugs and security issues. We may provide backports of the fixes and publish them to git, however there will be no new versions released. If you are not comfortable maintaining your own versions, you should upgrade to a supported version.
It is important to understand that there is no library or tool or gem that will give you security out of the box. It is often said that the only secure system is the isolated system, meaning that as soon as something is able to communicate with the outside world, it will have to face some risks.
Security in a web app, as we saw in the previous section, depends on different layers of the web application environment, and possibly also on other services as well. Therefore, in order to keep your web application secure you have to think about security issues at all layers, keep up-to-date with current issues, read security blogs, update your libraries, and try to identify possible malicious activity on your platform.
Sessions
HTTP is a stateless protocol, yet both server and client in certain situations need to keep track of the state of the user or the application itself. This is accomplished using sessions.
A session in Rails consists of a hash object, with some key/value pairs and a session ID. The session ID is usually a 32-character string; it identifies the hash.
The session ID is included both in information saved on the browser side, like cookies or local-storage data, and in the requests from the client to the server. This way the client doesn’t have to authenticate at each request.
Rails creates a new session automatically whenever a new user accesses the application, and if the user has already used the application it will load the existing session. You can save and retrieve values using the session method:
session[:user_id]=@current_user.idUser.find(session[:user_id])
In Rails the session ID is built as a 32-byte MD5 hash value of a random string. The random string is generated from the current timestamp, a random number between 0 and 1, the process ID number of the server’s Ruby interpreter, and a constant string. The Rails session ID is very difficult to compromise and can be considered secure in its default implementation. MD5 remains uncompromised, but collisions in MD5 hashes are in fact possible. So, theoretically, an attacker could create an input text with the same hash value.
If an attacker steals the user’s session ID, he could impersonate the victim and use the web application on his own behalf.
There are different ways a session ID could be stolen. To understand how this could be accomplished, let’s take a step back and look at how authentication systems work in general.
When a user authenticates to a web app, she provides a username and password. The web application checks them and stores the corresponding user ID in the session hash (Figure 16-1). From now on, the session is valid. On every request the application will query the database and use the profile of the user identified by the ID in the session, without the need to authenticate again. The session ID in the cookie identifies the session.

Figure 16-1. Simple authentication system where login credentials are posted to the server and, once verified, a cookie is set with the session ID
The cookie serves as a temporary authentication for the web app, which means anyone in possession of the cookie could act on behalf of the user. Possible ways to hijack the session include:
- Cookie sniffing in an insecure network, such as an unencrypted wireless LAN, where it is trivial to listen to the traffic of connected clients. A countermeasure in this case would be to force SSL connections in your application via
config.force_ssl = true. Yet, since most people do not clear out their cookies even when they are using a public terminal, session IDs could remain stored there and be easily stolen. To avoid this, always provide an easy-to-access logout button in the user interface. - XSS exploits aimed at obtaining the user’s cookie.
- Session fixation, where the attacker obtains a session ID and forces the victim’s browser to use this ID.
Session storage
Different storage mechanisms are provided in Rails for safekeeping session hashes, including ActionDispatch::Session::CookieStore.
CookieStore has been used in Rails since version 2 to save session hashes directly in a cookie on the client side. With CookieStore the server retrieves the session hash from the cookie. This mechanism eliminates the need to use a session ID.
CookieStore represents a great improvement for application speed. However, storing the session hash in the cookie is not ideal for security purposes. Drawbacks of this approach include:
- The maximum size of a cookie is 4 KB. (This is fine for most applications and for the functionality supported by CookieStore.)
- Everything you store in a cookie can be accessed and read by the client. The information stored is Base64-encoded, but not encrypted. Please be aware that storing secrets in a cookie is inherently insecure.
The security of the CookieStore option depends on the application secret that is used to calculate the digest.
Replay attacks for CookieStore
Imagine an online game of some sort. The user has been playing the game and the application has stored the score in the session (this is bad practice anyway since it should be stored in the server, but let’s pretend this doesn’t matter at this point).
The user plays the game a bit more and his score decreases for some reason. The application will update the new score in the session.
Now, for some other reason, imagine that the user has saved the cookie with the previous score value. He can use the old cookie to replace the new cookie and get back his higher score. This is illustrated in Figure 16-2.

Figure 16-2. In a replay attack, the cookie is replaced and the server reads an older amount stored in the session
To avoid this type of replay attack, you could store some random value that is valid only once (a nonce) in the session so that a possible attacker cannot tamper with the cookie. This strategy can get complicated if the server needs to keep track of large series of nonces that will have to be stored in the database, though, and since the purpose of using CookieStore is not having to access the database, using this technique would nullify its benefits.
The best solution to avoid this type of attack is not to store sensitive information in the session. Store only the logged-in user’s ID in the session, and all other information in the database.
Session fixation attacks
The idea of a session fixation attack is that both the attacker and the victim (user) share the same session ID. To accomplish this, the attacker creates a valid session ID by loading the login page of the web application where she wants to fix the session, and notes the session ID stored in the cookie sent with the response.
The attacker will try to maintain the session for as long as possible, accessing the web application at regular intervals in order to keep the session alive. Therefore, expiring sessions greatly reduces the chances of such attacks succeeding.
Once the attacker has obtained a valid session ID, she will need to force the same ID into the user’s browser. This may be done by injecting JavaScript code like the following (an XSS attack) into the application that the user will execute when visiting the page: <script>document.cookie="_session_id=1234";</script>.
Then, when the user visits the login page himself, his browser will replace the session ID that’s assigned by the app with the trapped session ID. The user will be asked to authenticate (as the attacker trapped the session ID but didn’t actually provide credentials to log in to the web app), and from now on the victim and the attacker will both be able to use the application with the same session. Figure 16-3 illustrates how this attack works.
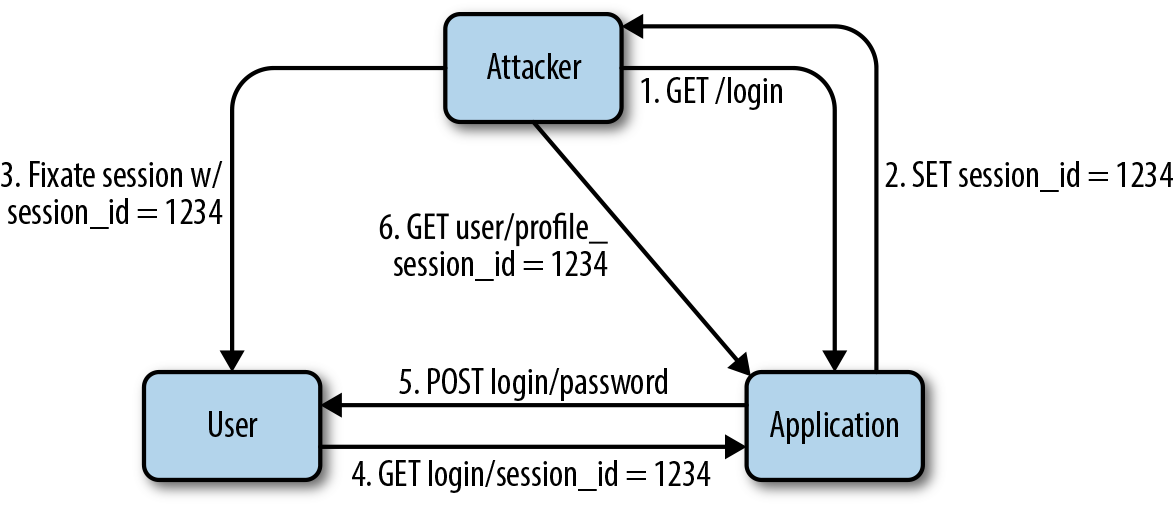
Figure 16-3. A session fixation attack where the attacker forces the victim’s browser to use a specific session ID
Different countermeasures are possible for session fixation attacks. The most effective is to issue a new session ID after a successful login while also declaring the old one invalid. This way, an attacker cannot tie the session to the victim. This is a good countermeasure for session hijacking as well.
The Rails method to tell your application to reset the session is reset_session. Note that this method removes all values from the session, so any values you want to maintain must be transferred to the new session.
It is also important to stress that session expiration information cannot be stored in the cookie. The cookie is always stored on the client side and therefore can be edited. It is better to set the expiration on the server side to avoid tampering.
Another possible countermeasure is to save user-specific properties into the session that can be verified by the application. This is sometimes referred to as “user fingerprinting”; it takes into consideration a variety of characteristics from the user’s machine, such as browser settings that can uniquely identify a user online.
Cross-Site Request Forgery
A cross-site request forgery (CSRF) is a security attack that either uses malicious code stored in the database or loads it through external links. If a user is logged in, an attacker might try to use this technique to steal user data or execute unauthorized commands.
Imagine that a user is logged into a certain application and accesses a page where the src attribute of an image has been modified in such a way as to make it possible to destroy some of the user’s data. The user will not notice that a command was executed when an attempt was made to load the image; she will just see a broken image link.
It is important to notice that the actual engineered image or link doesn’t necessarily have to be situated in the web application’s domain—it can be anywhere, such as in a forum or blog post or an email.
CSRF attacks can be easily avoided by using HTTP verbs correctly. For example, fetching a particular URL should not be able to trigger a dangerous action (a POST or PUT request should be used instead when deleting a database record).
Rails includes a required security token to protect applications against forged requests. This one-liner in your application controller (included by default in all newly created Rails apps):
protect_from_forgery
will cause a security token to be included in all forms and Ajax requests generated by Rails. If the security token in a request doesn’t match what is expected, the session will be reset.
Redirection
Redirection is a simple attack to construct. The most obvious situation would be a redirect to a fake web application that looks and feels like the original one.
The link that the attacker uses starts with the URL to the web application, and the URL to the malicious site is hidden in the redirection parameter: e.g., http://www.example.com/site/redirect?to=www.attacker.com.
Generally speaking, whenever the user is allowed to pass (parts of) the URL for redirection, it is possibly vulnerable.
Possible countermeasures to this common attack include using a whitelist or regular expression to check that the URL or domain being redirected to is an approved one and, for self-contained XSS attacks, not allowing the user to supply the URL to be redirected to (or any parts of it).
File Upload
There are many possible security issues that can come with allowing users to upload their own files. For example, files can include viruses or malicious programs that could compromise your server. Often it is beneficial to use a whitelist approach to filter filenames that the user can upload. Also, it is better not to process uploaded files synchronously. An attacker might take advantage of this to start several file uploads at the same time and take your service offline (a denial of service attack). Also, always check for executable code in file uploads.
File Download
Although it might seem counterintuitive, there are also a set of security issues around file downloads. Here are a few tips:
- When sending files to the user, again use a whitelist approach to filter filenames that the user may choose. Although this might seem counterintuitive, it is important to take all possible security precautions.
- Store the allowed filename patterns in the database and name the files on disk after the IDs or patterns stored. This is also a good approach to avoid possible code in an uploaded file from being executed.
Logs
A commonly overlooked mistake in application development is that of copying passwords to log files. Remember to tell Rails not to put passwords in the logs!
Rails logs all requests being made to a web application by default, but you don’t need log files to contain login credentials, credit card numbers, and other private user data.
The Ruby on Rails Security Guide offers this tip: “You can filter certain request parameters from your log files by appending them to config.filter_parameters in the application configuration. These parameters will be marked [FILTERED] in the log.”
Conclusions
This was the last chapter of this book. I hope that you have had fun building different applications, and that you have also learned a lot.
This chapter was about security and privacy, and it is no coincidence that it was the final chapter of the book. Sometimes developers and startups in general do not consider user privacy or API security early enough in their ventures. I can only recommend that you do not commit this mistake and overlook the importance of designing a secure product from the beginning. Building an insecure application can destroy your users’ and partners’ trust in your product. Not protecting your users’ privacy or respecting their personal information shows that you do not really care about them. This is something that cannot easily be patched later on.
1 Dalenius, T. “Towards a methodology for statistical disclosure control.” Statistik Tidskrift 15 (1977): 429–444.