
Chapter 10. Commands and Command Handler
In the previous chapter we talked about using events as a way of representing the inputs to our system, and turned our application into a message processing machine.
To achieve that, we converted all our use-case functions to event handlers.
When the API receives a POST to create a new batch, it builds a new BatchCreated
event and handles it as if it were an internal event.
This might have felt counter-intuitive. After all, the batch hasn’t been
created yet, that’s why we called the API. We’re going to fix that conceptual
wart by introducing Commands, and show how they can be handled by the same
message bus, but with slightly different rules.
Tip
You can find our code for this chapter at github.com/cosmicpython/code/tree/chapter_10_commands.
git clone https://github.com/cosmicpython/code.git && cd code git checkout chapter_10_commands # or, if you want to code along, checkout the previous chapter: git checkout chapter_09_all_messagebus
Commands and Events
Like events, commands are a type of message—instructions sent by one part of a system to another. Like events, we usually represent commands with dumb data structures and we can handle them in much the same way.
The differences between them, though, are important.
Commands are sent by one actor to another specific actor with the expectation that a particular thing will happen as a result. When I post a form to an API handler, I am sending a command. We name commands with imperative tense verb phrases like “allocate stock,” or “delay shipment.”
Commands capture intent. They express our wish for the system to do something. As a result, when they fail, the sender needs to receive error information.
Events are broadcast by an actor to all interested listeners. When we publish the
BatchQuantityChanged we don’t know who’s going to pick it up. We name events
with past-tense verb phrases like “order allocated to stock,” or “shipment delayed.”
We often use events to spread the knowledge about successful commands.
Events capture facts about things that happened in the past. Since we don’t know who’s handling an event, senders should not care whether the receivers succeeded or failed.
Event |
Command |
|
Named |
Past-Tense |
Imperative Tense |
Error Handling |
Fail independently |
Fail noisily |
Sent to |
All listeners |
One recipient |
What kinds of commands do we have in our system right now?
Pulling out some commands (src/allocation/domain/commands.py)
classCommand:pass@dataclassclassAllocate(Command):orderid:strsku:strqty:int@dataclassclassCreateBatch(Command):ref:strsku:strqty:inteta:Optional[date]=None@dataclassclassChangeBatchQuantity(Command):ref:strqty:int

commands.Allocatewill replaceevents.AllocationRequired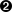
commands.CreateBatchwill replaceevents.BatchCreated
commands.ChangeBatchQuantitywill replaceevents.BatchQuantityChanged
Differences in Exception-handling
Just changing the names and verb tenses is all very well, but it won’t actually change the behavior of our system. We want to treat events and commands similarly, but not exactly the same. Let’s see how our message bus changes.
Dispatch events and commands differently (src/allocation/service_layer/messagebus.py)
Message=Union[commands.Command,events.Event]defhandle(message:Message,uow:unit_of_work.AbstractUnitOfWork):results=[]queue=[message]whilequeue:message=queue.pop(0)ifisinstance(message,events.Event):handle_event(message,queue,uow)elifisinstance(message,commands.Command):cmd_result=handle_command(message,queue,uow)results.append(cmd_result)else:raiseException(f'{message} was not an Event or Command')returnresults
It still has a main
handle()entrypoint, that takes amessage, which may be a command or an event.We dispatches events and commands to two different helper functions, shown next.
Events cannot interrupt the flow (src/allocation/service_layer/messagebus.py)
defhandle_event(event:events.Event,queue:List[Message],uow:unit_of_work.AbstractUnitOfWork):forhandlerinEVENT_HANDLERS[type(event)]:try:logger.debug('handling event%swith handler%s',event,handler)handler(event,uow=uow)queue.extend(uow.collect_new_events())exceptException:logger.exception('Exception handling event%s',event)continue
Events go to a dispatcher that can delegate to multiple handlers per event.
It catches and logs any errors, but does not let them interrupt message processing.
Commands reraise exceptions (src/allocation/service_layer/messagebus.py)
defhandle_command(command:commands.Command,queue:List[Message],uow:unit_of_work.AbstractUnitOfWork):logger.debug('handling command%s',command)try:handler=COMMAND_HANDLERS[type(command)]result=handler(command,uow=uow)queue.extend(uow.collect_new_events())returnresultexceptException:logger.exception('Exception handling command%s',command)raise
The command dispatcher expects just one handler per command.
If any errors are raised, they fail-fast and will bubble up.
return resultis only temporary; as mentioned in “A Temporary Ugly Hack: The Messagebus Has to Return Results”, it’s a temporary hack to allow the message bus to return the batch reference for the API to use. We’ll fix this in Chapter 12.
We also change the single HANDLERS dict into different ones for
commands and events. Commands can only have one handler, according
to our convention.
New handlers dicts (src/allocation/service_layer/messagebus.py)
EVENT_HANDLERS={events.OutOfStock:[handlers.send_out_of_stock_notification],}# type: Dict[Type[events.Event], List[Callable]]COMMAND_HANDLERS={commands.Allocate:handlers.allocate,commands.CreateBatch:handlers.add_batch,commands.ChangeBatchQuantity:handlers.change_batch_quantity,}# type: Dict[Type[commands.Command], Callable]
Discussion: Events, Commands, and Error Handling
Many developers get uncomfortable at this point, and ask “what happens when an event fails to process. How am I supposed to make sure the system is in a consistent state?”
If we manage to process half of the events during messagebus.handle before an
out-of-memory error kills our process, how do we mitigate problems caused by the
lost messages?
Let’s start with the worst case: we fail to handle an event, and the system is left in an inconsistent state. What kind of error would cause this? Often in our systems we can end up in an inconsistent state when only half an operation is completed.
For example, we could allocate 3 units of DESIRABLE_BEANBAG to a customer’s order but somehow fail to reduce the amount of remaining stock. This would cause an inconsistent state: the 3 units of stock are both allocated and available depending on how you look at it. Later on, we might allocate those same beanbags to another customer, causing a headache for customer support.
In our allocation service, though, we’ve already taken steps to prevent that happening. We’ve carefully identified Aggregates which act as consistency boundaries, and we’ve introduced a Unit of Work that manages the atomic success or failure of an update to an aggregate.
For example, when we allocate stock to an order, our consistency boundary is the Product aggregate. This means that we can’t accidentally over-allocate: either a particular order line is allocated to the product, or it is not—there’s no room for inconsistent states.
By definition, we don’t require two aggregates to be immediately consistent, so if we fail to process an event, and only update a single aggregate, our system can still be made eventually consistent. We shouldn’t violate any constraints of the system.
With this example in mind, we can better understand the reason for splitting messages into Commands and Events: When a user wants to make the system do something, we represent their request as a Command. That command should modify a single Aggregate and either succeed or fail in totality. Any other book keeping, clean up, and notification we need to do can happen via an Event. We don’t require the event handlers to succeed in order for the command to be successful.
Let’s take another example to see why not.
Imagine we are building an e-commerce website that sells expensive luxury goods. Our marketing department wants to reward customers for repeat visits. We will flag customers as VIPs once they make their third purchase, and this will entitle them to priority treatment and special offers. Our acceptance criteria for this story read as follows:
Givena customer with two orders in their history,Whenthe customer places a third order,Thenthey should be flagged as a VIP.Whena customer first becomes a VIPThenwe should send them an email to congratulate them
Using the techniques we’ve already discussed in this book, we decide that we
want to build a new History aggregate that records orders and can raise domain
events when rules are met. We will structure the code like this:
VIP Customer (example code for a different project)
classHistory(Aggregate):def__init__(self,customer_id:int):self.orders=set()# Set[HistoryEntry]self.customer_id=customer_iddefrecord_order(self,order_id:str,order_amount:int):entry=HistoryEntry(order_id,order_amount)ifentryinself.orders:returnself.orders.add(entry)iflen(self.orders)==3:self.events.append(CustomerBecameVIP(self.customer_id))defcreate_order_from_basket(uow,cmd:CreateOrder):withuow:order=Order.from_basket(cmd.customer_id,cmd.basket_items)uow.orders.add(order)uow.commit()# raises OrderCreateddefupdate_customer_history(uow,event:OrderCreated):withuow:history=uow.order_history.get(event.customer_id)history.record_order(event.order_id,event.order_amount)uow.commit()# raises CustomerBecameVIPdefcongratulate_vip_customer(uow,event:CustomerBecameVip):withuow:customer=uow.customers.get(event.customer_id).send(customer.email_address,f'Congratulations {customer.first_name}!')
The History aggregate captures the rules for when a customer becomes a VIP. This puts us in a good place to handle changes when the rules become more cmnplex in the future.
Our first handler creates an order for the customer and raises a domain event OrderCreated.
Our second handler updates the History object to record that an order was created.

Finally we send an email to the customer when they become a VIP.
Using this code we can gain some intuition about error handling in an event-driven system.
In our current implementation, we raise events about an aggregate after we persist our state to the database. What if we raised those events before we persisted, and committed all our changes at the same time? That way we could be sure that all the work was complete. Wouldn’t that be safer?
What happens, though if the email server is slightly overloaded? If all the work has to complete at the same time, a busy email server can stop us taking money for orders.
What happens if there is a bug in the implementation of the History aggregate? Should we fail to take your money just because we can’t recognise you as a VIP?
By separating these concerns out, we have made it possible for things to fail in isolation, which improves the overall reliability of the system. The only part of this code that has to complete is the Command Handler that creates an order. This is the only part that a customer cares about, and it’s the part that our business stakeholders should prioritise.
Notice how we’ve deliberately aligned our transactional boundaries to the start and end of the business processes. The names that we use in the code match the jargon used by our business stake-holders, and the handlers we’ve written match the steps of our natural language acceptance criteria. This concordance of names and structure helps us to reason about our systems as they grow larger and more complex.
Recovering From Errors Synchronously
Hopefully we’ve convinced you that it’s okay for events to fail independently from the commands that raised them. What should we do, then, to make sure we can recover from errors when they inevitably occur?
The first thing we need is to know when an error has occurred, and for that we usually rely on logs.
Let’s look again at the handle_event method from our message bus.
Current handle function (src/allocation/service_layer/messagebus.py)
defhandle_event(event:events.Event,queue:List[Message],uow:unit_of_work.AbstractUnitOfWork):forhandlerinEVENT_HANDLERS[type(event)]:try:logger.debug('handling event%swith handler%s',event,handler)handler(event,uow=uow)queue.extend(uow.collect_new_events())exceptException:logger.exception('Exception handling event%s',event)continue
When we handle a message in our system, the first thing we do is write a log line to record what we’re about to do. For our CustomerBecameVIP use case, the logs might read:
Handling event CustomerBecameVIP(customer_id=12345) with handler <function congratulate_vip_customer at 0x10ebc9a60>
Because we’ve chosen to use dataclasses for our message types we get a neatly printed summary of the incoming data that we can copy and paste into a Python shell to recreate the object.
When an error occurs, we can use the logged data to either reproduce the problem in a unit test, or replay the message into the system.
Manual replay works well for cases where we need to fix a bug before we can re-process an event, but our systems will always experience some background level of transient failure. This includes things like network hiccups, table deadlocks, and brief downtime caused by deployments.
For most of those cases, we can recover elegantly by trying again. As the proverb says, “if at first you don’t succeed, retry the operation with an exponentially increasing back-off period”.
Handle with Retry (src/allocation/service_layer/messagebus.py)
fromtenacityimportRetrying,RetryError,stop_after_attempt,wait_exponential...defhandle_event(event:events.Event,queue:List[Message],uow:unit_of_work.AbstractUnitOfWork):forhandlerinEVENT_HANDLERS[type(event)]:try:forattemptinRetrying(stop=stop_after_attempt(3),wait=wait_exponential()):withattempt:logger.debug('handling event%swith handler%s',event,handler)handler(event,uow=uow)queue.extend(uow.collect_new_events())exceptRetryErrorasretry_failure:logger.error('Failed to handle event%stimes, giving up!,retry_failure.last_attempt.attempt_number)continue
Tenacity is a Python library that implements common patterns for retrying.
Here we configure our message bus to retry operations up to three times, with an exponentially increasing wait between attempts.
Retrying operations that might fail is probably the single best way to improve the resilience of our software. Again, the unit of work and command handler patterns mean that each attempt starts from a consistent state, and won’t leave things half-finished.
Warning
At some point, regardless of tenacity, we’ll have to give up trying to process the message. Building reliable systems with distributed messages is hard and we have to skim over some tricky bits. There’s pointers to more reference materials in Chapter 10 and the epilogue.
| Pros | Cons |
|---|---|
|
|