
Chapter 3. Simple Linear Regression: Rushing Yards Over Expected
Football is a contextual sport. Consider whether a pass is completed. This depends on multiple factors: Was the quarterback under pressure (making it harder to complete)? Was the defense expecting a pass (which would make it harder to complete)? What was the depth of the pass (completion percentage goes down with the depth of the target)?
What turns people off to football analytics are conclusions that they feel lack a contextual understanding of the game. “Raw numbers” can be misleading. Sam Bradford once set the NFL record for completion percentage in a season as a member of the Minnesota Vikings in 2016. This was impressive, since he joined the team early in the season as a part of a trade and had to acclimate quickly to a new environment. While that was impressive, it did not necessarily mean he was the best quarterback in the NFL that year, or even the most accurate one. For one, he averaged just 6.6 yards average depth of target (aDOT) that year, which was 37th in the NFL according to PFF. That left his yards per pass attempt at a relatively average 7.0, tied for just 20th in football. Chapter 4 provides more context for that number and shows you how to adjust it yourself.
Luckily, given the great work of the people supporting nflfastR, you can provide your own context for metrics by applying the statistical tool known as regression. Through regression, you can normalize, or control for, variables (or features) that have been shown to affect a player’s production. Whether a feature predicts a player’s production is incredibly hard to prove in real life. Also, players emerge who come along and challenge our assumptions in this regard (such as Patrick Mahomes of the Kansas City Chiefs or Derrick Henry of the Tennessee Titans). Furthermore, data often fails to capture many factors that affect performance. As in life, you cannot account for everything, but hopefully you can capture the most important things. One of Richard’s professors at Texas Tech University, Katharine Long, likes to define this approach as the Mick Jagger theorem: “You can’t always get what you want, but if you try sometimes, you just might get what you need.”
The process of normalization in both the public and private football analytics space generally requires models that are more involved than a simple linear regression, the model covered in this chapter. But we have to start somewhere. And simple linear regression provides a nice start to modeling because it is both understandable and the foundation for many other types of analyses.
Note
Many fields use simple linear regression, which leads to the use of multiple terms. Mathematically, the predictor variable is usually x, and the response variable is usually y. Some synonyms for x include predictor variable, feature, explanatory variable, and independent variable. Some synonyms for y include response variable, target, and dependent variable. Likewise, medical studies often correct for exogenous or confounding data (variables to statisticians or features to data scientists) such as education level, age, or other socioeconomic data. You are learning the same concepts in this chapter and Chapter 4 with the terms normalize and control for.
Simple linear regression consists of a model with a single explanatory variable that is assumed to be linearly related to a single dependent variable, or feature. A simple linear regression fits the statistically “best” straight line by using one independent predictor variable to estimate a response variable as a function of the predictor. Simple refers to having only one predictor variable as well an intercept, an assumption Chapter 4 shows you how to relax. Linear refers to the straight line (compared to a curved line or polynomial line for those of you who remember high school algebra).
Regression originally referred to the idea that observations will return, or regress, to the average over time, as noted by Francis Galton in 1877. For example, if a running back has above-average rushing yards per carry one year, we would statistically expect them to revert, or regress, to the league average in future years, all else being equal. The linear assumption made in many models is often onerous but is generally fine as a first pass.
To start applying simple linear regression, you are going to work on a problem that has been solved already in the public space, during the 2020 Big Data Bowl. Participants in this event used tracking data (the positioning, direction, and orientation of all 22 on-field players every tenth of a second) to model the expected rushing yards gained on a play. This value was then subtracted from a player’s actual rushing yards on a play to determine their rushing yards over expected (RYOE). As we talked about in Chapter 1, this kind of residual analysis is a cornerstone exercise in all of sports analytics.
The RYOE metric has since made its way onto broadcasts of NFL games. Additional work has been done to improve the metric, including creating a version that uses scouting data instead of tracking data, as was done by Tej Seth at PFF, using an R Shiny app for RYOE. Regardless of the mechanics of the model, the broad idea is to adjust for the situation a rusher has to undergo to gain yards.
Note
The Big Data Bowl is the brainchild of Michael Lopez, the NFL’s director of data and analytics. Like Eric, Lopez was previously a professor, in Lopez’s case, at Skidmore College as a professor of statistics. Lopez’s home page contains useful tips, insight, and advice for sports as well as careers.
To mimic RYOE, but on a much smaller scale, you will use the yards to go on a given play. Recall that each football play has a down and distance, where down refers to the place in the four-down sequence a team is in to either pick up 10 yards or score either a touchdown or field goal. Distance, or yards to go, refers to the distance left to achieve that goal and is coded in the data as ydstogo.
A reasonable person would expect that the specific down and yards to go affect RYOE. This observation occurs because it is easier to run the ball when more yards to go exist because the defense will usually try to prevent longer plays. For example, when an offense faces third down and 10 yards to go, the defense is playing back in hopes of avoiding a big play. Conversely, while on second down and 1 yard to go, the defense is playing up to try to prevent a first down or touchdown.
For many years, teams deployed a short-yardage back, a (usually larger) running back who would be tasked with gaining the (small) number of yards on third or fourth down when only 1 or 2 yards were required for a first down or touchdown. These players were prized in fantasy football for their abilities to vulture (or take credit for) touchdowns that a team’s starting running back often did much of the work for, for their team to score. But the short-yardage backs’ yards-per-carry values were not impressive compared to the starting running back. This short-yardage back’s yards per carry lacked context compared to the starting running back’s. Hence, metrics like RYOE help normalize the context of a running back’s plays.
Many example players exist from the history of the NFL. Mike Alstott, the Tampa Bay Buccaneers second-round pick in 1996, often served as the short-yardage back on the upstart Bucs teams of the late-1990s/early-2000s. In contrast, his backfield mate, Warrick Dunn, the team’s first-round choice in 1997, served in the “early-down” role. As a result, their yards-per-carry numbers were different as members of the same team: 3.7 yards for Alstott and 4.0 yards for Dunn. Thus, regression can help you account for that and make better comparisons to create metrics such as RYOE.
Note
The wisdom of drafting a running back in the top two rounds once, let alone in consecutive years, is a whole other topic in football analytics. We talk about the draft in great detail in Chapter 7.
Understanding simple linear regression from this chapter also serves as a foundation for skills covered in other chapters, such as more complex RYOE models in Chapter 4, completion percentage over expected in the passing game in Chapter 5, touchdown passes per game in Chapter 6, and models used to evaluate draft data in Chapter 7. Many people, including the authors, call linear models both the workhorse and foundation for applied statistics and data science.
Exploratory Data Analysis
Prior to running a simple linear regression, it’s always good to plot the data as a part of the modeling process, using the exploratory data analysis (EDA) skills you learned about in Chapter 2. You will do this using seaborn in Python or ggplot2 in R. Before you calculate the RYOE, you need to load and wrangle the data. You will use the data from 2016 to 2022. First, load the packages and data.
Tip
Make sure you have installed the statsmodels package using
pip install statsmodels in the terminal.
If you’re using Python, use this code to load the data:
## Pythonimportpandasaspdimportnumpyasnpimportnfl_data_pyasnflimportstatsmodels.formula.apiassmfimportmatplotlib.pyplotaspltimportseabornassnsseasons=range(2016,2022+1)pbp_py=nfl.import_pbp_data(seasons)
If you’re using R, use this code to load the data:
## Rlibrary(tidyverse)library(nflfastR)pbp_r<-load_pbp(2016:2022)
After loading the data, select the running plays. Use the filtering criteria play_type == "run". Also, remove the plays without a rusher and replace the missing rushing yards with 0.
In Python, use rusher_id.notnull() as part of your query and then replace missing rushing_yards values with 0:
## Pythonpbp_py_run=pbp_py.query('play_type == "run" & rusher_id.notnull()').reset_index()pbp_py_run.loc[pbp_py_run.rushing_yards.isnull(),"rushing_yards"]=0
In R, use !is.na(rusher_id) as part of your filter() step and then mutate() with an ifelse() function to replace the missing values:
## Rpbp_r_run<-pbp_r|>filter(play_type=="run"&!is.na(rusher_id))|>mutate(rushing_yards=ifelse(is.na(rushing_yards),0,rushing_yards))
Next, plot the raw data prior to building a model. In Python, use displot() from seaborn to create Figure 3-1:
## Pythonsns.set_theme(style="whitegrid",palette="colorblind")sns.scatterplot(data=pbp_py_run,x="ydstogo",y="rushing_yards");plt.show();

Figure 3-1. Yards to go plotted against rushing yards, using seaborn
In R, use geom_point() from ggplot2 to create Figure 3-2:
ggplot(pbp_r_run,aes(x=ydstogo,y=rushing_yards))+geom_point()+theme_bw()

Figure 3-2. Yards to go plotted against rushing yards, using ggplot2
Figures 3-1 and 3-2 are dense graphs of points, and it’s hard to see whether a relation exists between the yards to go and the number of rushing yards gained on a play. You can do some things to make the plot easier to read. First, add a trend line to see if the data slopes upward, downward, or neither up nor down.
In Python, use regplot() to create Figure 3-3:
## Pythonsns.regplot(data=pbp_py_run,x="ydstogo",y="rushing_yards");plt.show();

Figure 3-3. Yards to go plotted against rushing yards with a trend line (seaborn)
In R, use stat_smooth(method = "lm") with your code from Figure 3-2 to create Figure 3-4:
ggplot(pbp_r_run,aes(x=ydstogo,y=rushing_yards))+geom_point()+theme_bw()+stat_smooth(method="lm")

Figure 3-4. Yards to go plotted against rushing yards with a trendline (ggplot2)
In Figures 3-3 and 3-4, you see a positive slope, albeit a very small one. This shows you that rushing gains increase slightly as yards to go increases. Another approach to try to examine the data is binning and averaging. This borrows from the ideas of a histogram (covered in “Histograms”), but rather than using the count for each bin, an average is used for each bin. In this case, the bins are easy to define: they are the ydstogo values, which are integers.
Now, average over each yards-per-carry value gained in each bin. In Python, aggregate the data and then plot it to create Figure 3-5:
## Pythonpbp_py_run_ave=pbp_py_run.groupby(["ydstogo"]).agg({"rushing_yards":["mean"]})pbp_py_run_ave.columns=list(map("_".join,pbp_py_run_ave.columns))pbp_py_run_ave.reset_index(inplace=True)sns.regplot(data=pbp_py_run_ave,x="ydstogo",y="rushing_yards_mean");plt.show();
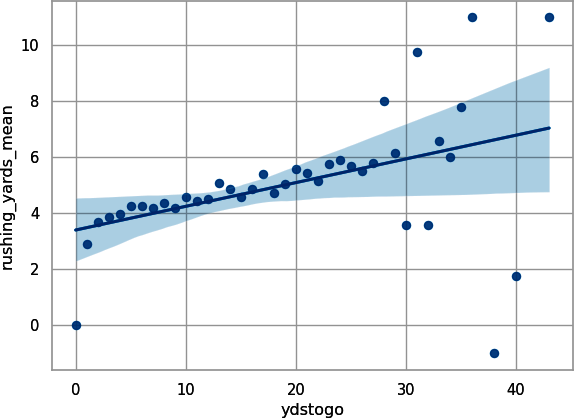
Figure 3-5. Average yards per carry plotted with seaborn
In R, create a new variable, yards per carry (ypc) and then plot the results in Figure 3-6:
## Rpbp_r_run_ave<-pbp_r_run|>group_by(ydstogo)|>summarize(ypc=mean(rushing_yards))ggplot(pbp_r_run_ave,aes(x=ydstogo,y=ypc))+geom_point()+theme_bw()+stat_smooth(method="lm")

Figure 3-6. Average yards per carry plotted with ggplot2
Tip
Figures 3-5 and 3-6 let you see a positive linear relationship between average yards gained and yards to go. While binning and averaging is not a substitute for regressing along the entire dataset, the approach can give you insight into whether such an endeavor is worth doing in the first place and helps you to better “see” the data.
Simple Linear Regression
Now that you’ve wrangled and interrogated the data, you’re ready to run a simple linear regression. Python and R use the same formula notation for the functions we show you in this book. For example, to build a simple linear regression where ydstogo predicts rushing_yards, you use the formula rushing_yards ~ 1 + ydstogo.
Tip
The left hand side of the formula contains the target, or response,
variable. The right hand side of the formula contains the response, or
predictor, variables. Chapter 4 shows how to use multiple
predictors that are separated by a +.
You can read this formula as rushing_yards are predicted by (indicated by the tilde, ~, which is located next to the 1 key on US keyboards and whose location varies on other keyboards) an intercept (1) and a slope parameter for yards to go (ydstogo). The 1 is an optional value to explicitly tell you where the model contains an intercept. Our code and most people’s code we read do not usually include an intercept in the formula, but we include it here to help you explicitly think about this term in the model.
Note
Formulas with statsmodels are usually similar or identical to R. This
is because computer languages often borrow from other computer
languages. Python’s statsmodels borrowed formulas from R, similar to
pandas borrowing dataframes from R. R also borrows ideas, and R is, in
fact, an open source re-creation of the S language. As another example,
both the tidyverse in R and pandas in Python borrow syntax and
ideas for cleaning data from SQL-type languages.
We are using the statsmodels package because it is better for statistical inference compared to the more popular Python package scikit-learn that is better for machine learning. Additionally, statsmodels uses similar syntax as R, which allows you to more readily compare the two languages.
In Python, use the statsmodels package’s formula.api imported as smf, to run an ordinary least-squares regression, ols(). To build the model, you will need to tell Python how to fit the regression. For this, model that the number of rushing yards for a play (rushing_yards) is predicted by an intercept (1) and the number of yards to go for the play (ydstogo), which is written as a formula: rushing_yards ~ 1 + ydstogo.
Using Python, build the model, fit the model, and then look at the model’s summary:
## Pythonimportstatsmodels.formula.apiassmfyard_to_go_py=smf.ols(formula='rushing_yards ~ 1 + ydstogo',data=pbp_py_run)(yard_to_go_py.fit().summary())
Resulting in:
OLS Regression Results
==============================================================================
Dep. Variable: rushing_yards R-squared: 0.007
Model: OLS Adj. R-squared: 0.007
Method: Least Squares F-statistic: 623.7
Date: Sun, 04 Jun 2023 Prob (F-statistic): 3.34e-137
Time: 09:35:30 Log-Likelihood: -3.0107e+05
No. Observations: 92425 AIC: 6.021e+05
Df Residuals: 92423 BIC: 6.022e+05
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 3.2188 0.047 68.142 0.000 3.126 3.311
ydstogo 0.1329 0.005 24.974 0.000 0.122 0.143
==============================================================================
Omnibus: 81985.726 Durbin-Watson: 1.994
Prob(Omnibus): 0.000 Jarque-Bera (JB): 4086040.920
Skew: 4.126 Prob(JB): 0.00
Kurtosis: 34.511 Cond. No. 20.5
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is
correctly specified.This summary output includes a description of the model. Many of the summary items should be straightforward, such as the dependent variable (Dep. Variable), Date, and Time. The number of observations (No. Observations) relates to the degrees of freedom. The degrees of freedom indicate the number of “extra” observations that exist compared to the number of parameters fit.
With this model, two parameters were fit: a slope for rushing_yards and an intercept, Intercept. Hence, the Df Residuals equals the No. Observations–2. The
Other outputs of interest include the coefficient estimates for the Intercept and ydstogo. The Intercept is the number of rushing yards expected to be gained if there are 0 yards to go for a first down or a touchdown (which never actually occurs in real life). The slope for ydstogo corresponds to the expected number of additional rushing yards expected to be gained for each additional yard to go. For example, a rushing play with 2 yards to go would be expected to produce 3.2(intercept) + 0.1(slope) × 2(number of yards to go) = 3.4 yards on average.
With the coefficients, a point estimate exists (coef) as well as the standard error (std err). The standard error (SE) captures the uncertainty around the estimate for the coefficient, something Appendix B describes in greater detail. The t-value comes from a statistical distribution (specifically, the t-distribution) and is used to generate the SE and confidence interval (CI). The p-value provides the probability of obtaining the observed t-value, assuming the null hypothesis of the coefficient being 0 is true.
The p-value ties into null hypothesis significance testing (NHST), something that most introductory statistics courses cover, but is increasingly falling out of use by practicing statisticians. Lastly, the summary includes the 95% CI for the coefficients. The lower CI is the [0.025 column, and the upper CI is the 0.975] column (97.5 – 2.5 = 95%). The 95% CI should contain the true estimate for the coefficient 95% of the time, assuming the observation process is repeated many times. However, you never know which 5% of the time you are wrong.
You can fit a similar, linear model (lm()) by using R and then print the summary results:
## Ryard_to_go_r<-lm(rushing_yards~1+ydstogo,data=pbp_r_run)summary(yard_to_go_r)
Resulting in:
Call:
lm(formula = rushing_yards ~ 1 + ydstogo, data = pbp_r_run)
Residuals:
Min 1Q Median 3Q Max
-33.079 -3.352 -1.415 1.453 94.453
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.21876 0.04724 68.14 <2e-16 ***
ydstogo 0.13287 0.00532 24.97 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 6.287 on 92423 degrees of freedom
Multiple R-squared: 0.006703, Adjusted R-squared: 0.006692
F-statistic: 623.7 on 1 and 92423 DF, p-value: < 2.2e-16The general structure of the regression output differs in R compared to Python. However, the items provided are similar, with the main difference occurring in formatting. R provides the model formula, or Call, followed by a summary of the residuals. Residuals indicate how well data compares to the model’s fit. For RYOE, you actually will use the residuals later. Then the summary provides the Coefficients and their uncertainty. Last, model details are printed, which are similar to the Python details.
Warning
Checking degrees of freedom may seem strange to people starting out
modeling. However, this can be a great check for your data to make sure
the model is using all your inputs correctly and that values are not being lost. One of our friends, Barb Bennie, spends most of a semester teaching her graduate students in statistics how to compare degrees of freedom across models. When writing this book, the Python and R versions of the nflfastR data were giving different values for model estimates, and the degrees of freedom helped us figure out the packages needed to be updated on our machines. Do not underestimate the utility and power of understanding degrees of freedom.
Lastly, before moving on to look at RYOE, we need to save the residuals to create an RYOE column in the data. Residuals are the difference between a model’s expected (or predicted) output and the observed data. With pandas in Python, create a new RYOE column in the pbp_py_run dataframe from the model’s residuals:
## Pythonpbp_py_run["ryoe"]=yard_to_go_py.fit().resid
Tip
Linear models in Python and R have capabilities and tools that we only scratch the surface of in this book. Learning the details of these tools, using resources such as those listed in “Suggested Readings” will help you better unlock the power of linear models.
Likewise, in R mutate the pbp_r_run data to create a new column, ryoe:
## Rpbp_r_run<-pbp_r_run|>mutate(ryoe=resid(yard_to_go_r))
Note
R, which was created for teaching statistics, is based on the S language. Given this history and the state of statistics in the early 1990s, R has linear models well integrated into the language. In contrast, Python has a clone of R for linear models for statistical inference—specifically, the statsmodels package. The main package for models in Python, scikit-learn (sklearn) focuses on machine learning rather than statistical inference. Understanding the history of R and Python can provide insight into why the languages exist as they do as well as enable you to leverage their respective strengths. We would also argue that if all you need and want to do is fit regression models for statistical inference, R would be the better software choice.
Who Was the Best in RYOE?
Now, look at the leaderboard for RYOE from 2016 to 2022, first in total yards over expected and average yards over expected per carry. As with the passer data in Chapter 2, you will need to group by both the rusher and rusher_id because some players have the same last name and first initial.
With pandas, group by seasons, rusher_id, and rusher. Then, aggregate ryoe with the count, sum, and mean, and aggregate rushing_yards with the mean. This gives the following columns:
-
The
countof RYOE is the number of carries a rusher has. -
The
sumof RYOE is the total RYOE. -
The
meanof RYOE is the RYOE per carry. -
The
meanof rushing yards is the yards per carry.
Flatten the columns and reset the index to make the dataframe easier to work with. Next, rename the columns to give them football-specific names. Lastly, query the result to print only players with more than 50 carries:
## Pythonryoe_py=pbp_py_run.groupby(["season","rusher_id","rusher"]).agg({"ryoe":["count","sum","mean"],"rushing_yards":"mean"})ryoe_py.columns=list(map("_".join,ryoe_py.columns))ryoe_py.reset_index(inplace=True)ryoe_py=ryoe_py.rename(columns={"ryoe_count":"n","ryoe_sum":"ryoe_total","ryoe_mean":"ryoe_per","rushing_yards_mean":"yards_per_carry",}).query("n > 50")(ryoe_py.sort_values("ryoe_total",ascending=False))
Resulting in:
season rusher_id rusher n ryoe_total ryoe_per yards_per_carry 1989 2021 00-0036223 J.Taylor 332 417.501295 1.257534 5.454819 1440 2020 00-0032764 D.Henry 397 362.768406 0.913774 5.206549 1258 2019 00-0034796 L.Jackson 135 353.652105 2.619645 6.800000 1143 2019 00-0032764 D.Henry 387 323.921354 0.837006 5.131783 1474 2020 00-0033293 A.Jones 222 288.358241 1.298911 5.540541 ... ... ... ... ... ... ... ... 419 2017 00-0029613 D.Martin 139 -198.461432 -1.427780 2.920863 122 2016 00-0029613 D.Martin 144 -199.156646 -1.383032 2.923611 675 2018 00-0027325 L.Blount 155 -247.528360 -1.596957 2.696774 1058 2019 00-0030496 L.Bell 245 -286.996618 -1.171415 3.220408 267 2016 00-0032241 T.Gurley 278 -319.803875 -1.150374 3.183453 [534 rows x 7 columns]
To print the entire table in Python once, run print(ryoe_py.query("n > 50").to_string()), something we did not do in order to save space. Alternatively, you can change the printing in your entire session by using the pandas set_option() function. For example, pd.set_option("display.min_rows", 10) would always print 10 rows.
With R, use the pbp_r_run data and group by season, rusher_id, and rusher. Then summarize() to get the number per group, total RYOE, average RYOE, and yards per carry. Lastly, filter to include only players with more than 50 carries:
## Rryoe_r<-pbp_r_run|>group_by(season,rusher_id,rusher)|>summarize(n=n(),ryoe_total=sum(ryoe),ryoe_per=mean(ryoe),yards_per_carry=mean(rushing_yards))|>arrange(-ryoe_total)|>filter(n>50)(ryoe_r)
Resulting in:
# A tibble: 534 × 7
# Groups: season, rusher_id [534]
season rusher_id rusher n ryoe_total ryoe_per yards_per_carry
<dbl> <chr> <chr> <int> <dbl> <dbl> <dbl>
1 2021 00-0036223 J.Taylor 332 418. 1.26 5.45
2 2020 00-0032764 D.Henry 397 363. 0.914 5.21
3 2019 00-0034796 L.Jackson 135 354. 2.62 6.8
4 2019 00-0032764 D.Henry 387 324. 0.837 5.13
5 2020 00-0033293 A.Jones 222 288. 1.30 5.54
6 2019 00-0031687 R.Mostert 190 282. 1.48 5.83
7 2016 00-0033045 E.Elliott 344 279. 0.810 5.10
8 2021 00-0034791 N.Chubb 228 276. 1.21 5.52
9 2022 00-0034796 L.Jackson 73 276. 3.78 7.82
10 2020 00-0034791 N.Chubb 221 254. 1.15 5.48
# ℹ 524 more rowsWe did not have you print out all the tables, to save space. However, using |> print(n = Inf) at the end would allow you to see the entire table in R. Alternatively, you could change all printing for an R session by running options(pillar.print_min = n).
For the filtered lists, we had you print only the lists with players who carried the ball 50 or more times to leave out outliers as well as to save page space. We don’t have to do that for total yards, since players with so few carries will not accumulate that many RYOE, anyway.
By total RYOE, 2021 Jonathan Taylor was the best running back in football since 2016, generating over 400 RYOE, follow by the aforementioned Henry, who generated 374 RYOE during his 2,000-yard 2020 season. The third player on the list, Lamar Jackson, is a quarterback, who in 2019 earned the NFL’s MVP award for both rushing for over 1,200 yards (an NFL record for a quarterback) and leading the league in touchdown passes. In April of 2022, Jackson signed the richest contract in NFL history for his efforts.
One interesting quirk of the NFL data is that only designed runs for quarterbacks (plays that are actually running plays and not broken-down passing plays, where the quarterback pulls the ball down and runs with it) are counted in this dataset. So Jackson generating this much RYOE on just a subset of his runs is incredibly impressive.
Next, sort the data by RYOE per carry. We include only code for R, but the previous Python code is readily adaptable:
## Rryoe_r|>arrange(-ryoe_per)
Resulting in:
# A tibble: 534 × 7
# Groups: season, rusher_id [534]
season rusher_id rusher n ryoe_total ryoe_per yards_per_carry
<dbl> <chr> <chr> <int> <dbl> <dbl> <dbl>
1 2022 00-0034796 L.Jackson 73 276. 3.78 7.82
2 2019 00-0034796 L.Jackson 135 354. 2.62 6.8
3 2019 00-0035228 K.Murray 56 122. 2.17 6.5
4 2020 00-0034796 L.Jackson 121 249. 2.06 6.26
5 2021 00-0034750 R.Penny 119 229. 1.93 6.29
6 2022 00-0036945 J.Fields 85 160. 1.88 6
7 2022 00-0033357 T.Hill 96 178. 1.86 5.99
8 2021 00-0034253 D.Hilliard 56 101. 1.80 6.25
9 2022 00-0034750 R.Penny 57 99.2 1.74 6.07
10 2019 00-0034400 J.Wilkins 51 87.8 1.72 6.02
# ℹ 524 more rowsLooking at RYOE per carry yields three Jackson years in the top four, sandwiching a year by Kyler Murray, who is also a quarterback. Murray was the first-overall pick in the 2019 NFL Draft and elevated an Arizona Cardinals offense from the worst in football in 2018 to a much more respectable standing in 2019, through a combination of running and passing. Rashaad Penny, the Seattle Seahawks’ first-round pick in 2018, finally emerged in 2021 to earn almost 2 yards over expected per carry while leading the NFL in yards per carry overall (6.3). This earned Penny a second contract with Seattle the following offseason.
A reasonable question we should ask is whether total yards or yards per carry is a better measure of a player’s ability. Fantasy football analysts and draft analysts both carry a general consensus that “volume is earned.” The idea is that a hidden signal is in the data when a player plays enough to generate a lot of carries.
Data is an incomplete representation of reality, and players do things that aren’t captured. If a coach plays a player a lot, it’s a good indication that that player is good. Furthermore, a negative relationship generally exists between volume and efficiency for that same reason. If a player is good enough to play a lot, the defense is able to key on him more easily and reduce his efficiency. This is why we often see backup running backs with high yards-per-carry values relative to the starter in front of them (for example, look at Tony Pollard and Ezekiel Elliott for the Dallas Cowboys in 2019–2022). Other factors are at play as well (such as Zeke’s draft status and contract) that don’t necessarily make volume the be-all and end-all, but it’s important to inspect.
Is RYOE a Better Metric?
Anytime you create a new metric for player or team evaluation in football, you have to test its predictive power. You can put as much thought into your new metric as the next person, and the adjustments, as in this chapter, can be well-founded. But if the metric is not more stable than previous iterations of the evaluation, you either have to conclude that the work was in vain or that the underlying context that surrounds a player’s performance is actually the entity that carries the signal. Thus, you’re attributing too much of what is happening in terms of production on the individual player.
In Chapter 2, you conducted stability analysis on passing data. Now, you will look at RYOE per carry for players with 50 or more carries versus traditional yards-per-carry values. We don’t have you look at total RYOE or rushing yards since that embeds two measures of performance (volume and efficiency). Volume is in both measures, which muddies things.
This code is similar to that from “Deep Passes Versus Short Passes”, and we do not provide a walk-through here, simply the code with comments. Hence, we refer you to that section for details.
In Python, use this code:
## Python# keep only columns neededcols_keep=["season","rusher_id","rusher","ryoe_per","yards_per_carry"]# create current dataframeryoe_now_py=ryoe_py[cols_keep].copy()# create last-year's dataframeryoe_last_py=ryoe_py[cols_keep].copy()# rename columnsryoe_last_py.rename(columns={'ryoe_per':'ryoe_per_last','yards_per_carry':'yards_per_carry_last'},inplace=True)# add 1 to seasonryoe_last_py["season"]+=1# merge togetherryoe_lag_py=ryoe_now_py.merge(ryoe_last_py,how='inner',on=['rusher_id','rusher','season'])
Lastly, examine the correlation for yards per carry:
## Pythonryoe_lag_py[["yards_per_carry_last","yards_per_carry"]].corr()
Resulting in:
yards_per_carry_last yards_per_carry yards_per_carry_last 1.00000 0.32261 yards_per_carry 0.32261 1.00000
Repeat with RYOE:
## Pythonryoe_lag_py[["ryoe_per_last","ryoe_per"]].corr()
Which results in:
ryoe_per_last ryoe_per ryoe_per_last 1.000000 0.348923 ryoe_per 0.348923 1.000000
With R, use this code:
## R# create current dataframeryoe_now_r<-ryoe_r|>select(-n,-ryoe_total)# create last-year's dataframe# and add 1 to seasonryoe_last_r<-ryoe_r|>select(-n,-ryoe_total)|>mutate(season=season+1)|>rename(ryoe_per_last=ryoe_per,yards_per_carry_last=yards_per_carry)# merge togetherryoe_lag_r<-ryoe_now_r|>inner_join(ryoe_last_r,by=c("rusher_id","rusher","season"))|>ungroup()
Then select the two yards-per-carry columns and examine the correlation:
## Rryoe_lag_r|>select(yards_per_carry,yards_per_carry_last)|>cor(use="complete.obs")
Resulting in:
yards_per_carry yards_per_carry_last yards_per_carry 1.0000000 0.3226097 yards_per_carry_last 0.3226097 1.0000000
Repeat the correlation with the RYOE columns:
## Rryoe_lag_r|>select(ryoe_per,ryoe_per_last)|>cor(use="complete.obs")
Resulting in:
ryoe_per ryoe_per_last ryoe_per 1.0000000 0.3489235 ryoe_per_last 0.3489235 1.0000000
These results show that, for players with more than 50 rushing attempts in back-to-back seasons, this version of RYOE per carry is slightly more stable year to year than yards per carry (because the correlation coefficient is larger). Therefore, yards per carry includes information inherent to the specific play in which a running back carries the ball. Furthermore, this information can vary from year to year. After extracted out, our new metric for running back performance is slightly more predictive year to year.
As far as the question of whether (or, more accurately, how much) running backs matter, the difference between our correlation coefficients suggest that we don’t have much in the way of a conclusion to be drawn so far. Prior to this chapter, you’ve really looked at statistics for only one position (quarterback), and the more stable metric in the profile for that position (yards per pass attempt on short passes, with r values nearing 0.5) is much more stable than yards per carry and RYOE. Furthermore, you haven’t done a thorough analysis of the running game relative to the passing game, which is essential to round out any argument that running backs are or are not important.
The key questions for football analysts about running backs are as follows:
-
Are running back contributions valuable?
-
Are their contributions repeatable across years?
In Chapter 4, you will add variables to control for other factors affecting the running game. For example, the down part of down and distance is surely important, because a defense will play even tighter on fourth down and 1 yard to go than it will on third down and that same 1 yard to go. A team trailing (or losing) by 14 points will have an easier time of running the ball than a team up by 14 points (all else being equal) because a team that is ahead might be playing “prevent” defense, a defense that is willing to allow yards to their opponent, just not too many yards.
Data Science Tools Used in This Chapter
This chapter covered the following topics:
-
Fitting a simple linear regression by using
OLS()in Python or by usinglm()in R -
Understanding and reading the coefficients from a simple linear regression
-
Plotting a simple linear regression by using
regplot()fromseabornin Python or by usinggeom_smooth()in R -
Using correlations with the
corr()function in Python and R to conduct stability analysis
Exercises
-
What happens if you repeat the correlation analysis with 100 carries as the threshold? What happens to the differences in r values?
-
Assume all of Alstott’s carries were on third down and 1 yard to go, while all of Dunn’s carries came on first down and 10 yards to go. Is that enough to explain the discrepancy in their yards-per-carry values (3.7 versus 4.0)? Use the coefficient from the simple linear model in this chapter to understand this question.
-
What happens if you repeat the analyses in this chapter with yards to go to the endzone (
yardline_100) as your feature? -
Repeat the processes within this chapter with receivers and the passing game. To do this, you have to filter by
play_type == "pass"andreceiver_idnot beingNAorNULL.
Suggested Readings
Eric wrote several articles on running backs and running back value while at PFF. Examples include the following:
-
“The NFL’s Best Running Backs on Perfectly and Non-perfectly Blocked Runs in 2021”
-
“Are NFL Running Backs Easily Replaceable: The Story of the 2018 NFL Season”
-
“Explaining Dallas Cowboys RB Ezekiel Elliott’s 2018 PFF Grade”
Additionally, many books exist on regression and introductory statistics and “Suggested Readings” lists several introductory statistics books. For regression, here are some books we found useful:
-
Regression and Other Stories by Andrew Gelman et al. (Cambridge University Press, 2020). This book shows how to apply regression analysis to real-world problems. For those of you looking for more worked case studies, we recommend this book to help you learn how to think about applying regression.
-
Regression Modeling Strategies: With Applications to Linear Models, Logistic and Ordinal Regression, and Survival Analysis, 2nd edition, by Frank E. Harrell Jr. (Springer, 2015). This book helped one of the authors think through the world of regression modeling. It is advanced but provides a good oversight into regression analysis. The book is written at an advanced undergraduate or introductory graduate level. Although hard, working through this book provides mastery of regression analysis.