
6
Code smells
In this chapter
- Handling Constructor Over-injection code smells
- Detecting and preventing overuse of Abstract Factories
- Fixing cyclic Dependency code smells
You may have noticed that I (Mark) have a fascination with sauce béarnaise — or sauce hollandaise. One reason is that it tastes so good; another is that it’s a bit tricky to make. In addition to the challenges of production, it presents an entirely different problem: it must be served immediately (or so I thought).
This used to be less than ideal when guests arrived. Instead of being able to casually greet my guests and make them feel welcome and relaxed, I was frantically whipping the sauce in the kitchen, leaving them to entertain themselves. After a couple of repeat performances, my sociable wife decided to take matters into her own hands. We live across the street from a restaurant, so one day she chatted with the cooks to find out whether there’s a trick that would enable me to prepare a genuine hollandaise well in advance. It turns out there is. Now I can serve a delicious sauce for my guests without first subjecting them to an atmosphere of stress and frenzy.
Each craft has its own tricks of the trade. This is also true for software development, in general, and for DI, in particular. Challenges keep popping up. In many cases, there are well-known ways to deal with them. Over the years, we’ve seen people struggle when learning DI, and many of the issues were similar in nature. In this chapter, we’ll look at the most common code smells that appear when you apply DI to a code base and how you can resolve them. When we’re finished, you should be able to better recognize and handle these situations when they occur.
Similar to the two previous chapters in this part of the book, this chapter is organized as a catalog — this time, a catalog of problems and solutions (or, if you will, refactorings). You can read each section independently or in sequence, as you prefer. The purpose of each section is to familiarize you with a solution to a commonly occurring problem so that you’ll be better equipped to deal with it if it occurs. But first, let’s define code smells.
Where an anti-pattern is a description of a commonly occurring solution to a problem that generates decidedly negative consequences, a code smell, on the other hand, is a code construct that might cause problems. Code smells simply warrant further investigation.
6.1 Dealing with the Constructor Over-injection code smell
Unless you have special requirements, Constructor Injection (we covered this in chapter 4) should be your preferred injection pattern. Although Constructor Injection is easy to implement and use, it makes developers uncomfortable when their constructors start looking something like that shown next.

Listing 6.1 Constructor with many Dependencies
public OrderService(
IOrderRepository orderRepository, ①
IMessageService messageService, ①
IBillingSystem billingSystem, ①
ILocationService locationService, ①
IInventoryManagement inventoryManagement) ①
{
if (orderRepository == null)
throw new ArgumentNullException("orderRepository");
if (messageService == null)
throw new ArgumentNullException("messageService");
if (billingSystem == null)
throw new ArgumentNullException("billingSystem");
if (locationService == null)
throw new ArgumentNullException("locationService");
if (inventoryManagement == null)
throw new ArgumentNullException("inventoryManagement");
this.orderRepository = orderRepository;
this.messageService = messageService;
this.billingSystem = billingSystem;
this.locationService = locationService;
this.inventoryManagement = inventoryManagement;
}
Having many Dependencies is an indication of a Single Responsibility Principle (SRP) violation. SRP violations lead to code that’s hard to maintain.
In this section, we’ll look at the apparent problem of a growing number of constructor parameters and why Constructor Injection is a good thing rather than a bad thing. As you’ll see, it doesn’t mean you should accept long parameter lists in constructors, so we’ll also review what you can do about those. You can refactor away from Constructor Over-injection in many ways, so we’ll also discuss two common approaches you can take to refactor those occurrences, namely, Facade Services and domain events:
- Facade Services are abstract Facades1 that are related to Parameter Objects.2 Instead of combining components and exposing them as parameters, however, a Facade Service exposes only the encapsulated behavior, while hiding the constituents.
- With domain events, you capture actions that can trigger a change to the state of the application you’re developing.
6.1.1 Recognizing Constructor Over-injection
When a constructor’s parameter list grows too large, we call the phenomenon Constructor Over-injection and consider it a code smell.3 It’s a general issue unrelated to, but magnified by, DI. Although your initial reaction might be to dismiss Constructor Injection because of Constructor Over-injection, we should be thankful that a general design issue is revealed to us.
We can’t say we blame anyone for disliking a constructor as shown in listing 6.1, but don’t blame Constructor Injection. We can agree that a constructor with five parameters is a code smell, but it indicates a violation of the SRP rather than a problem related to DI.
Our personal threshold lies at four constructor arguments. When we add a third argument, we already begin considering whether we could design things differently, but we can live with four arguments for a few classes. Your limit may be different, but when you cross it, it’s time to investigate.
How you refactor a particular class that has grown too big depends on the particular circumstances: the object model already in place, the domain, business logic, and so on. Splitting up a budding God Class into smaller, more focused classes according to well-known design patterns is always a good move.4 Still, there are cases where business requirements oblige you to do many different things at the same time. This is often the case at the boundary of an application. Think about a coarse-grained web service operation that triggers many business events.
You can design and implement collaborators so that they don’t violate the SRP. In chapter 9, we’ll discuss how the Decorator5 design pattern can help you stack Cross-Cutting Concerns instead of injecting them into consumers as services. This can eliminate many constructor arguments. In some scenarios, a single entry point needs to orchestrate many Dependencies. One example is a web service operation that triggers a complex interaction of many different services. The entry point of a scheduled batch job can face the same issue.
The sample e-commerce application that we look at from time to time needs to be able to receive orders. This is often best done by a separate application or subsystem because, at that point, the semantics of the transaction change. As long as you’re looking at a shopping basket, you can dynamically calculate unit prices, exchange rates, and discounts. But when a customer places an order, all of those values must be captured and frozen as they were presented when the customer approved the order. Table 6.1 provides an overview of the order process.
Five different Dependencies are required just to approve an order. Imagine the other Dependencies you’d need to handle other order-related operations!
Let’s review how this would look if the consuming OrderService class directly imported all of these Dependencies. The following listing gives a quick overview of the internals of this class.
Listing 6.2 Original OrderService class with many Dependencies
public class OrderService : IOrderService
{
private readonly IOrderRepository orderRepository;
private readonly IMessageService messageService;
private readonly IBillingSystem billingSystem;
private readonly ILocationService locationService;
private readonly IInventoryManagement inventoryManagement;
public OrderService(
IOrderRepository orderRepository,
IMessageService messageService,
IBillingSystem billingSystem,
ILocationService locationService,
IInventoryManagement inventoryManagement)
{
this.orderRepository = orderRepository;
this.messageService = messageService;
this.billingSystem = billingSystem;
this.locationService = locationService;
this.inventoryManagement = inventoryManagement;
}
public void ApproveOrder(Order order)
{
this.UpdateOrder(order); ①
this.Notify(order); ②
}
private void UpdateOrder(Order order)
{
order.Approve();
this.orderRepository.Save(order);
}
private void Notify(Order order)
{
this.messageService.SendReceipt(new OrderReceipt { ... });
this.billingSystem.NotifyAccounting(...);
this.Fulfill(order);
}
private void Fulfill(Order order)
{
this.locationService.FindWarehouses(...); ③
this.inventoryManagement.NotifyWarehouses(...); ④
}
}
To keep the example manageable, we omitted most of the details of the class. But it’s not hard to imagine such a class to be rather large and complex. If you let OrderService directly consume all five Dependencies, you get many fine-grained Dependencies. The structure is shown in figure 6.1.

Figure 6.1 OrderService has five direct Dependencies, which suggests an SRP violation.
If you use Constructor Injection for the OrderService class (which you should), you have a constructor with five parameters. This is too many and indicates that OrderService has too many responsibilities. On the other hand, all of these Dependencies are required because the OrderService class must implement all of the desired functionality when it receives a new order. You can address this issue by redesigning OrderService using Facade Services refactoring. We’ll show you how to do that in the next section.
6.1.2 Refactoring from Constructor Over-injection to Facade Services
When redesigning OrderService, the first thing you need to do is to look for natural clusters of interaction. The interaction between ILocationService and IInventoryManagement should immediately draw your attention, because you use them to find the closest warehouses that can fulfill the order. This could potentially be a complex algorithm.
After you’ve selected the warehouses, you need to notify them about the order. If you think about this a little further, ILocationService is an implementation detail of notifying the appropriate warehouses about the order. The entire interaction can be hidden behind an IOrderFulfillment interface, like this:
public interface IOrderFulfillment
{
void Fulfill(Order order);
}
The next listing shows the implementation of the new IOrderFulfillment interface.

Listing 6.3 OrderFulfillment class
public class OrderFulfillment : IOrderFulfillment
{
private readonly ILocationService locationService;
private readonly IInventoryManagement inventoryManagement;
public OrderFulfillment(
ILocationService locationService,
IInventoryManagement inventoryManagement)
{
this.locationService = locationService;
this.inventoryManagement = inventoryManagement;
}
public void Fulfill(Order order)
{
this.locationService.FindWarehouses(...);
this.inventoryManagement.NotifyWarehouses(...);
}
}
Interestingly, order fulfillment sounds a lot like a domain concept in its own right. Chances are that you discovered an implicit domain concept and made it explicit.
The default implementation of IOrderFulfillment consumes the two original Dependencies, so it has a constructor with two parameters, which is fine. As a further benefit, you’ve encapsulated the algorithm for finding the best warehouse for a given order into a reusable component. The new IOrderFulfillment Abstraction is a Facade Service because it hides the two interacting Dependencies with their behavior.
This refactoring merges two Dependencies into one but leaves you with four Dependencies on the OrderService class, as shown in figure 6.2. You also need to look for other opportunities to aggregate Dependencies into a Facade.
The OrderService class only has four Dependencies, and the OrderFulfillment class contains two. That’s not a bad start, but you can simplify OrderService even more. The next thing you may notice is that all the requirements involve notifying other systems about the order. This suggests that you can define a common Abstraction that models notifications, perhaps something like this:
public interface INotificationService
{
void OrderApproved(Order order);
}

Figure 6.2 Two Dependencies of OrderService aggregated behind a Facade Service
Each notification to an external system can be implemented using this interface. But you may wonder how this helps, because you’ve wrapped each Dependency in a new interface. The number of Dependencies didn’t decrease, so did you gain anything?
Yes, you did. Because all three notifications implement the same interface, you can wrap them in a Composite6 pattern as can be seen in listing 6.4. This shows another implementation of INotificationService that wraps a collection of INotificationService instances and invokes the OrderAccepted method on all of those.
Listing 6.4 Composite wrapping INotificationService instances
public class CompositeNotificationService
: INotificationService ①
{
IEnumerable<INotificationService> services;
public CompositeNotificationService(
IEnumerable<INotificationService> services) ②
{
this.services = services;
}
public void OrderApproved(Order order)
{
foreach (var service in this.services)
{
service.OrderApproved(order); ③
}
}
}
CompositeNotificationService implements INotificationService and forwards an incoming call to its wrapped implementations. This prevents the consumer from having to deal with multiple implementations, which is an implementation detail. This means that you can let OrderService depend on a single INotificationService, which leaves just two Dependencies, as shown next.
Listing 6.5 Refactored OrderService with two Dependencies
public class OrderService : IOrderService
{
private readonly IOrderRepository orderRepository;
private readonly INotificationService notificationService;
public OrderService(
IOrderRepository orderRepository,
INotificationService notificationService)
{
this.orderRepository = orderRepository;
this.notificationService = notificationService;
}
public void ApproveOrder(Order order)
{
this.UpdateOrder(order);
this.notificationService.OrderApproved(order);
}
private void UpdateOrder(Order order)
{
order.Approve();
this.orderRepository.Save(order);
}
}
From a conceptual perspective, this also makes sense. At a high level, you don’t need to care about the details of how OrderService notifies other systems, but you do care that it does. This reduces OrderService to only two Dependencies, which is a more reasonable number.
From the consumer’s perspective, OrderService is functionally unchanged, making this a true refactoring. On the other hand, on the conceptual level, OrderService is changed. Its responsibility is now to receive an order, save it, and notify other systems. The details of which systems are notified and how this is implemented have been pushed down to a more detailed level. Figure 6.3 shows the final Dependencies of OrderService.
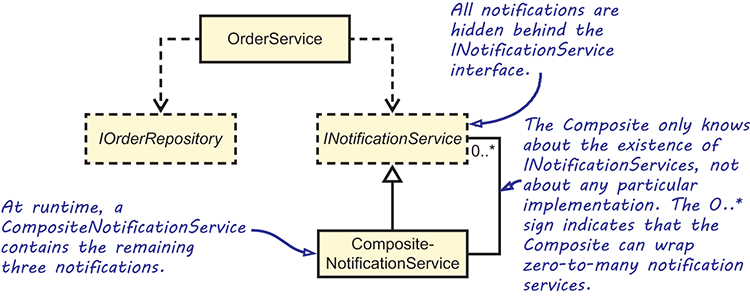
Figure 6.3 The final OrderService with refactored Dependencies
Using the CompositeNotificationService, you can now create the OrderService with its Dependencies.
Listing 6.6 Composition Root refactored using Facade Services
var repository = new SqlOrderRepository(connectionString);
var notificationService = new CompositeNotificationService(
new INotificationService[]
{
new OrderApprovedReceiptSender(messageService),
new AccountingNotifier(billingSystem),
new OrderFulfillment(locationService, inventoryManagement)
});
var orderServive = new OrderService(repository, notificationService);
Even though you consistently use Constructor Injection throughout, no single class’s constructor ends up requiring more than two parameters. CompositeNotificationService takes an IEnumerable<INotificationService> as a single argument.
A beneficial side effect is that discovering these natural clusters draws previously undiscovered relationships and domain concepts out into the open. In the process, you turn implicit concepts into explicit concepts.7 Each aggregate becomes a service that captures this interaction at a higher level, and the consumer’s single responsibility becomes to orchestrate these higher-level services. You can repeat this refactoring if you have a complex application where the consumer ends up with too many Dependencies on Facade Services. Creating a Facade Service of Facade Services is a perfectly sensible thing to do.
The Facade Services refactoring is a great way to handle complexity in a system. But with regard to the OrderService example, we might even take this one step further, bringing us to domain events.
6.1.3 Refactoring from Constructor Over-injection to domain events
Listing 6.5 shows that all notifications are actions triggered when an order is approved. The following code shows this relevant part again:
this.notificationService.OrderApproved(order);
We can say that the act of an order being approved is of importance to the business. These kinds of events are called domain events, and it might be valuable to model them more explicitly in your applications.
Although the introduction of INotificationService is a great improvement to OrderService, it only solves the problem at the level of OrderService and its direct Dependencies. When applying the same refactoring technique to other classes in the system, one could easily imagine how INotificationService evolves toward something similar to the following listing.

Listing 6.7 INotificationService with a growing number of methods
public interface INotificationService
{
void OrderApproved(Order order); ①
void OrderCancelled(Order order); ①
void OrderShipped(Order order); ①
void OrderDelivered(Order order); ①
void CustomerCreated(Customer customer); ①
void CustomerMadePreferred(Customer customer); ①
}
Within any system of reasonable size and complexity, you’d easily get dozens of these domain events, which would lead to an ever-changing INotificationService interface. With each change to this interface, all implementations of that interface must be updated too. Additionally, ever-growing interfaces also causes ever-growing implementations. If, however, you promote the domain events to actual types and make them part of the domain, as shown in figure 6.4, an interesting opportunity to generalize even further arises.

Figure 6.4 Domain events promoted to actual types. These types contain only data and no behavior.
The following listing shows the domain event code illustrated in figure 6.4.
Listing 6.8 OrderApproved and OrderCancelled domain event classes
public class OrderApproved
{
public readonly Guid OrderId;
public OrderApproved(Guid orderId)
{
this.OrderId = orderId;
}
}
public class OrderCancelled
{
public readonly Guid OrderId;
public OrderCancelled(Guid orderId)
{
this.OrderId = orderId;
}
}
Although both the OrderApproved and OrderCancelled classes have the same structure and are related to the same Entity, modelling them around their own class makes it easier to create code that responds to such a specific event. When each domain event in your system gets its own type, it lets you change INotificationService to a generic interface with a single method, as the following listing shows.
Listing 6.9 Generic IEventHandler<TEvent> with just a single method
public interface IEventHandler<TEvent> ①
{
void Handle(TEvent e);
}
In the case of IEventHandler<TEvent>, a class deriving from the interface must specify a TEvent type — for the instance OrderCancelled — in the class declaration. This type will then be used as the parameter type for that class’s Handle method. This allows one interface to unify several classes, despite differences in their types. In addition, it allows each of those implementations to be strongly typed, working exclusively off whatever type was specified as TEvent.
Based on this interface, you can now build the classes that respond to a domain event, like the OrderFulfillment class you saw previously. Based on the new IEventHandler<TEvent> interface, the original OrderFulfillment class, as shown in listing 6.3, changes to that displayed in the following listing.
Listing 6.10 OrderFulfillment class implementing IEventHandler<TEvent>
public class OrderFulfillment
: IEventHandler<OrderApproved> ①
{
private readonly ILocationService locationService;
private readonly IInventoryManagement inventoryManagement;
public OrderFulfillment(
ILocationService locationService,
IInventoryManagement inventoryManagement)
{
this.locationService = locationService;
this.inventoryManagement = inventoryManagement;
}
public void Handle(OrderApproved e) ②
{
this.locationService.FindWarehouses(...);
this.inventoryManagement.NotifyWarehouses(...);
}
}
The OrderFulfillment class implements IEventHandler<OrderApproved>, meaning that it acts on OrderApproved events. OrderService then uses the new IEventHandler<TEvent> interface, as figure 6.5 shows.
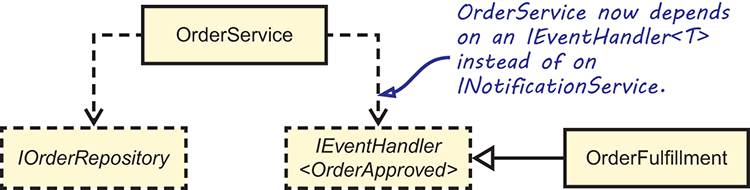
Figure 6.5 The OrderService class depends on an IEventHandler<OrderApproved> interface, instead of INotificationService.
Listing 6.11 shows an OrderService depending on IEventHandler<OrderApproved>. Compared to listing 6.5, the OrderService logic will stay almost unchanged.
Listing 6.11 OrderService depending on IEventHandler<OrderApproved>
public class OrderService : IOrderService
{
private readonly IOrderRepository orderRepository;
private readonly IEventHandler<OrderApproved> handler;
public OrderService(
IOrderRepository orderRepository,
IEventHandler<OrderApproved> handler) ①
{
this.orderRepository = orderRepository;
this.handler = handler;
}
public void ApproveOrder(Order order)
{
this.UpdateOrder(order);
this.handler.Handle(
new OrderApproved(order.Id)); ②
}
...
}
Just as with the non-generic INotificationService, you still need a Composite that takes care of dispatching the information to the list of available handlers. This enables you to add new handlers to the application, without the need to change OrderService. Listing 6.12 shows this Composite. As you can see, it’s similar to the CompositeNotificationService from listing 6.4.
Listing 6.12 Composite wrapping IEventHandler<TEvent> instances
public class CompositeEventHandler<TEvent> : IEventHandler<TEvent>
{
private readonly IEnumerable<IEventHandler<TEvent>> handlers;
public CompositeEventHandler(
IEnumerable<IEventHandler<TEvent>> handlers) ①
{
this.handlers = handlers;
}
public void Handle(TEvent e)
{
foreach (var handler in this.handlers)
{
handler.Handle(e);
}
}
}
Wrapping a collection of IEventHandler<TEvent> instances, as does CompositeEventHandler<TEvent>, lets you add arbitrary event handler implementations to the system without having to make any changes to consumers of IEventHandler<TEvent>. Using the new CompositeEventHandler<TEvent>, you can create the OrderService with its Dependencies.
Listing 6.13 Composition Root for the OrderService refactored using events
var orderRepository = new SqlOrderRepository(connectionString);
var orderApprovedHandler = new CompositeEventHandler<OrderApproved>(
new IEventHandler<OrderApproved>[]
{
new OrderApprovedReceiptSender(messageService),
new AccountingNotifier(billingSystem),
new OrderFulfillment(locationService, inventoryManagement)
});
var orderService = new OrderService(orderRepository, orderApprovedHandler);
Likewise, the Composition Root will contain the configuration for the handlers of other domain events. The following code shows a few more event handlers for OrderCancelled and CustomerCreated. We leave it up to the reader to extrapolate from this.
var orderCancelledHandler = new CompositeEventHandler<OrderCancelled>(
new IEventHandler<OrderCancelled>[]
{
new AccountingNotifier(billingSystem),
new RefundSender(orderRepository),
});
var customerCreatedHandler = new CompositeEventHandler<CustomerCreated>(
new IEventHandler<CustomerCreated>[]
{
new CrmNotifier(crmSystem),
new TermsAndConditionsSender(messageService, termsRepository),
});
var orderService = new OrderService(
orderRepository, orderApprovedHandler, orderCancelledHandler);
var customerService = new CustomerService(
customerRepository, customerCreatedHandler);
The beauty of a generic interface like IEventHandler<TEvent> is that the addition of new features won’t cause any changes to either the interface nor any of the already existing implementations. In case you need to generate an invoice for your approved order, you only have to add a new implementation that implements IEventHandler<OrderApproved>. When a new domain event is created, no changes to CompositeEventHandler<TEvent> are required.
In a sense, IEventHandler<TEvent> becomes a template for common building blocks that the application relies on. Each building block responds to a particular event. As you saw, you can have multiple building blocks that respond to the same event. New building blocks can be plugged in without the need to change any existing business logic.
Although the introduction of IEventHandler<TEvent> prevented the problem of an ever-growing INotificationService, it doesn’t prevent the problem of an ever-growing OrderService class. This is something we’ll address in great detail in chapter 10.
We’ve found the use of domain events to be an effective model. It allows code to be defined on a more conceptual level, while letting you build more-robust software, especially where you have to communicate with external systems that aren’t part of your database transaction. But no matter which refactoring approach you choose, be it Decorators, Facade Services, domain events, or perhaps another, the important takeaway here is that Constructor Over-injection is a clear sign that code smells. Don’t ignore such a sign, but act accordingly.
Because Constructor Over-injection is a commonly recurring code smell, the next section discusses a more subtle problem that, at first sight, might look like a good solution to a set of recurring problems. But is it?
6.2 Abuse of Abstract Factories
When you start applying DI, one of the first difficulties you’re likely to encounter is when Abstractions depend on runtime values. For example, an online mapping site may offer to calculate a route between two locations, giving you a choice of how you want the route computed. Do you want the shortest route? The fastest route based on known traffic patterns? The most scenic route?
The first response from many developers in such cases would be to use an Abstract Factory. Although Abstract Factories do have their place in software, when it comes to DI — when factories are used as DEPENDENCIES in application components — they're often overused. In many cases, better alternatives exist.
In this section, we’ll discuss two cases where better alternatives to Abstract Factories exist. In the first case, we’ll discuss why Abstract Factories shouldn’t be used to create stateful Dependencies with a short lifetime. After that, we’ll discuss why it’s generally better not to use Abstract Factories to select Dependencies based on runtime data.
6.2.1 Abusing Abstract Factories to overcome lifetime problems
When it comes to the abuse of Abstract Factories, a common code smell is to see parameterless factory methods that have a Dependency as the return type, as the next listing shows.
Listing 6.14 Abstract Factory with parameterless Create method
public interface IProductRepositoryFactory
{
IProductRepository Create(); ①
}
Abstract Factories with parameterless Create methods are often used to allow consumers to control the lifetime of their Dependencies. In the following listing, HomeController controls the lifetime of IProductRepository by requesting it from the factory, and disposing of it when it finishes using it.
Listing 6.15 A HomeController explicitly managing its Dependency’s lifetime
public class HomeController : Controller
{
private readonly IProductRepositoryFactory factory;
public HomeController(
IProductRepositoryFactory factory) ①
{
this.factory = factory;
}
public ViewResult Index()
{
using (IProductRepository repository =
this.factory.Create()) ②
{
var products =
repository.GetFeaturedProducts(); ③
return this.View(products);
} ④
}
}
Figure 6.6 shows the sequence of communication between HomeController and its Dependencies.

Figure 6.6 The consuming class HomeController controls the lifetime of its IProductRepositoryDependency. It does so by requesting a Repository instance from the IProductRepositoryFactoryDependency and calling Dispose on the IProductRepository instance when it’s done with it.
Disposing the Repository is required when the used implementation holds on to resources, such as database connections, that should be closed in a deterministic fashion. Although an implementation might require deterministic cleanup, that doesn’t imply that it should be the responsibility of the consumer to ensure proper cleanup. This brings us to the concept of Leaky Abstractions.
The Leaky Abstraction code smell
Just as Test-Driven Development (TDD) ensures Testability, it’s safest to define interfaces first and then subsequently program against them. Even so, there are cases where you already have a concrete type and now want to extract an interface. When you do this, you must take care that the underlying implementation doesn’t leak through. One way this can happen is if you only extract an interface from a given concrete type, but some of the parameter or return types are still concrete types defined in the library you want to abstract from. The following interface definition offers an example:
public interface IRequestContext ①
{
HttpContext Context { get; } ②
}
If you need to extract an interface, you need to do it in a recursive manner, ensuring that all types exposed by the root interface are themselves interfaces. We call this Deep Extraction, and the result is Deep Interfaces.
This doesn’t mean that interfaces can’t expose any concrete classes. It’s typically fine to expose behaviorless data objects, such as Parameter Objects, view models, and Data Transfer Objects (DTOs). They’re defined in the same library as the interface instead of the library you want to abstract from. Those data objects are part of the Abstraction.
Be careful with Deep Extraction: it doesn’t always lead to the best solution. Take the previous example. Consider the following suspicious-looking implementation of a Deep Extracted IHttpContext interface:
public interface IHttpContext ①
{
IHttpRequest Request { get; } ②
IHttpResponse Response { get; } ②
IHttpSession Session { get; } ②
IPrincipal User { get; } ②
}
Although you might be using interfaces all the way down, it’s still glaringly obvious that the HTTP model is leaking through. In other words, IHttpContext is still a Leaky Abstraction — and so are its sub-interfaces.
How should you model IRequestContext instead? To figure this out, you have to look at what its consumers want to achieve. For instance, if a consumer needs to find out the role of the user who sent the current web request, you might end up instead with the IUserContext we discussed in chapter 3:
public interface IUserContext
{
bool IsInRole(Role role);
}
This IUserContext interface doesn’t reveal to the consumer that it’s running as part of an ASP.NET web application. As a matter of fact, this Abstraction lets you run the same consumer as part of a Windows service or desktop application. It’ll likely require the creation of a different IUserContext implementation, but its consumers are oblivious to this.
Always consider whether a given Abstraction makes sense for implementations other than the one you have in mind. If it doesn’t, you should reconsider your design. That brings us back to our parameterless factory methods.
Parameterless factory methods are Leaky Abstractions
As useful as the Abstract Factory pattern can be, you must take care to apply it with discrimination. The Dependencies created by an Abstract Factory should conceptually require a runtime value, and the translation from a runtime value into an Abstraction should make sense. If you feel the urge to introduce an Abstract Factory because you have a specific implementation in mind, you may have a Leaky Abstraction at hand.
Consumers that depend on IProductRepository, such as the HomeController from listing 6.15, shouldn’t care about which instance they get. At runtime, you might need to create multiple instances, but as far as the consumer is concerned, there’s only one.
By specifying an IProductRepositoryFactory Abstraction with a parameterless Create method, you let the consumer know that there are more instances of the given service, and that it has to deal with this. Because another implementation of IProductRepository might not require multiple instances or deterministic disposal at all, you’re therefore leaking implementation details through the Abstract Factory with its parameterless Create method. In other words, you’ve created a Leaky Abstraction.
Next, we’ll discuss how to prevent this Leaky Abstraction code smell.
Refactoring toward a better solution
Consuming code shouldn’t be concerned with the possibility of there being more than one IProductRepository instance. You should therefore get rid of the IProductRepositoryFactory completely and instead let consumers depend solely on IProductRepository, which they should have injected using Constructor Injection. This advice is reflected in the following listing.
Listing 6.16 HomeController without managing its Dependency’s lifetime
public class HomeController : Controller
{
private readonly IProductRepository repository;
public HomeController(
IProductRepository repository) ①
{
this.repository = repository;
}
public ViewResult Index()
{
var products = ②
this.repository.GetFeaturedProducts(); ②
②
return this.View(products); ②
}
}
This code results in a simplified sequence of interactions between HomeController and its sole IProductRepository Dependency, as shown in figure 6.7.
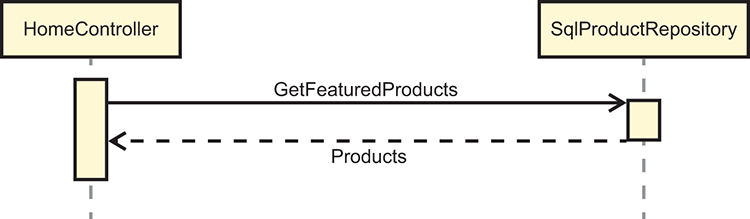
Figure 6.7 Compared to figure 6.6, removing the responsibility of managing IProductRepository’s lifetime together with removing the IProductRepositoryFactoryDependency considerably simplifies interaction with HomeController’s Dependencies.
Although removing Lifetime Management simplifies the HomeController, you’ll have to manage the Repository’s lifetime somewhere in the application. A common pattern to address this problem is the Proxy pattern, an example of which is given in the next listing.
Listing 6.17 Delaying creation of SqlProductRepository using a Proxy
public class SqlProductRepositoryProxy : IProductRepository
{
private readonly string connectionString;
public SqlProductRepositoryProxy(string connectionString)
{
this.connectionString = connectionString;
}
public IEnumerable<Product> GetFeaturedProducts()
{
using (var repository = this.Create()) ①
{
return repository.GetFeaturedProducts(); ②
}
}
private SqlProductRepository Create()
{
return new SqlProductRepository( ③
this.connectionString);
}
}
Notice how SqlProductRepositoryProxy internally contains factory-like behavior with its private Create method. This behavior, however, is encapsulated within the Proxy and doesn’t leak out, compared to the IProductRepositoryFactory Abstract Factory that exposes IProductRepository from its definition.
SqlProductRepositoryProxy is tightly coupled to SqlProductRepository. This would be an implementation of the Control Freak anti-pattern (section 5.1) if the SqlProductRepositoryProxy was defined in your domain layer. Instead, you should either define this Proxy in your data access layer that contains SqlProductRepository or, more likely, the Composition Root.
Because the Create method composes part of the object graph, the Composition Root is a well-suited location to place this Proxy class. The next listing shows the structure of the Composition Root using the SqlProductRepositoryProxy.
Listing 6.18 Object graph with the new SqlProductRepositoryProxy
new HomeController(
new SqlProductRepositoryProxy( ①
connectionString));
In the case that an Abstraction has many members, it becomes quite cumbersome to create Proxy implementations. Abstractions with many members, however, typically violate the Interface Segregation Principle. Making Abstractions more focused solves many problems, such as the complexity of creating Proxies, Decorators, and Test Doubles. We’ll discuss this in more detail in section 6.3 and again come back to this subject in chapter 10.
The next section deals with the abuse of Abstract Factories to select the Dependency to return, based on the supplied runtime data.
6.2.2 Abusing Abstract Factories to select Dependencies based on runtime data
In the previous section, you learned that Abstract Factories should typically accept runtime values as input. Without them, you’re leaking implementation details about the implementation to the consumer. This doesn’t mean that an Abstract Factory that accepts runtime data is the correct solution to every situation. More often than not, it isn’t.
In this section, we’ll look at Abstract Factories that accept runtime data specifically to decide which Dependency to return. The example we’ll look at is the online mapping site that offers to calculate a route between two locations, which we introduced at the start of section 6.2.
To calculate a route, the application needs a routing algorithm, but it doesn’t care which one. Each option represents a different algorithm, and the application can handle each routing algorithm as an Abstraction to treat them all equally. You must tell the application which algorithm to use, but you won’t know this until runtime because it’s based on the user’s choice.
In a web application, you can only transfer primitive types from the browser to the server. When the user selects a routing algorithm from a drop-down box, you must represent this by a number or a string.15 An enum is a number, so on the server you can represent the selection using this RouteType:
public enum RouteType { Shortest, Fastest, Scenic }
What you need is an instance of IRouteAlgorithm that can calculate the route for you:
public interface IRouteAlgorithm
{
RouteResult CalculateRoute(RouteSpecification specification);
}
Now you’re presented with a problem. The RouteType is runtime data based on the user’s choice. It’s sent to the server with the request.
Listing 6.19 RouteController with its GetRoute method
public class RouteController : Controller
{
public ViewResult GetRoute(
RouteSpecification spec, RouteType routeType)
{
IRouteAlgorithm algorithm = ... ①
var route = algorithm.CalculateRoute(spec); ②
var vm = new RouteViewModel ③
{ ③
... ③
}; ③
return this.View(vm); ④
}
}
The question now becomes, how do you get the appropriate algorithm? If you hadn’t been reading this chapter, your knee-jerk reaction to this challenge would probably be to introduce an Abstract Factory, like this:
public interface IRouteAlgorithmFactory
{
IRouteAlgorithm CreateAlgorithm(RouteType routeType);
}
This enables you to implement a GetRoute method for RouteController by injecting IRouteAlgorithmFactory and using it to translate the runtime value to the IRouteAlgorithm Dependency you need. The following listing demonstrates the interaction.
Listing 6.20 Using an IRouteAlgorithmFactory in RouteController
public class RouteController : Controller
{
private readonly IRouteAlgorithmFactory factory;
public RouteController(IRouteAlgorithmFactory factory)
{
this.factory = factory;
}
public ViewResult GetRoute(
RouteSpecification spec, RouteType routeType)
{
IRouteAlgorithm algorithm = ①
this.factory.CreateAlgorithm(routeType); ①
var route = algorithm.CalculateRoute(spec); ②
var vm = new RouteViewModel
{
...
};
return this.View(vm);
}
}
The RouteController class’s responsibility is to handle web requests. The GetRoute method receives the user’s specification of origin and destination, as well as a selected RouteType. With an Abstract Factory, you map the runtime RouteType value to an IRouteAlgorithm instance, so you request an instance of IRouteAlgorithmFactory using Constructor Injection. This sequence of interactions between RouteController and its Dependencies is shown in figure 6.8.
The most simple implementation of IRouteAlgorithmFactory would involve a switch statement and return three different implementations of IRouteAlgorithm based on the input. But we’ll leave this as an exercise for the reader.
Up until this point you might be wondering, “What’s the catch? Why is this a code smell?” To be able to see the problem, we need to go back to the Dependency Inversion Principle.

Figure 6.8 RouteController supplies the routeType runtime value to IRouteAlgorithmFactory. The factory returns an IRouteAlgorithm implementation, and RouteController requests a route by calling CalculateRoute. The interaction is similar to that of figure 6.6.
Analysis of the code smell
In chapter 3 (section 3.1.2), we talked about the Dependency Inversion Principle. We discussed how it states that Abstractions should be owned by the layer using the Abstraction. We explained that it’s the consumer of the Abstraction that should dictate its shape and define the Abstraction in a way that suits its needs the most. When we go back to our RouteController and ask ourselves whether this is the design that suits RouteController the best, we’d argue that this design doesn’t suit RouteController.
One way of looking at this is by evaluating the number of Dependencies RouteController has, which tells you something about the complexity of the class. As you saw in section 6.1, having a large number of Dependencies is a code smell, and a typical solution is to apply Facade Services refactoring.
When you introduce an Abstract Factory, you always increase the number of Dependencies a consumer has. If you only look at the constructor of RouteController, you may be led to believe that the controller only has one Dependency. But IRouteAlgorithm is also a Dependency of RouteController, even if it isn’t injected into its constructor.
This increased complexity might not be obvious at first, but it can be felt instantly when you start unit testing RouteController. Not only does this force you to test the interaction RouteController has with IRouteAlgorithm, you also have to test the interaction with IRouteAlgorithmFactory.
Refactoring toward a better solution
You can reduce the number of Dependencies by merging both IRouteAlgorithmFactory and IRouteAlgorithm together, much like you saw with the Facade Services refactoring of section 6.1. Ideally, you’d want to use the Proxy pattern the same way you applied it in section 6.2.1. A Proxy, however, is only applicable in case the Abstraction is supplied with all the data required to select the appropriate Dependency. Unfortunately, this prerequisite doesn’t hold for IRouteAlgorithm because it’s only supplied with a RouteSpecification, but not a RouteType.
Before you discard the Proxy pattern, it’s important to verify whether it makes sense from a conceptual level to pass RouteType on to IRouteAlgorithm. If it does, it means that a CalculateRoute implementation contains all the information required to select both the proper algorithm and the runtime values the algorithm will need to calculate the route. In this case, however, passing RouteType on to IRouteAlgorithm is conceptually weird. An algorithm implementation will never need to use RouteType. Instead, to reduce the controller’s complexity, you define an Adapter that internally dispatches to the appropriate route algorithm:
public interface IRouteCalculator
{
RouteResult Calculate(RouteSpecification spec, RouteType routeType);
}
The following listing shows how RouteController gets simplified when it depends on IRouteCalculator instead of IRouteAlgorithmFactory.
Listing 6.21 Using an IRouteCalculator in RouteController
public class RouteController : Controller
{
private readonly IRouteCalculator calculator;
public RouteController(IRouteCalculator calculator) ①
{
this.calculator = calculator;
}
public ViewResult GetRoute(RouteSpecification spec, RouteType routeType)
{
var route = this.calculator.Calculate(spec, routeType);
var vm = new RouteViewModel { ... };
return this.View(vm);
}
}
Figure 6.9 shows the simplified interaction between RouteController and its sole Dependency. As you saw in figure 6.7, the interaction is reduced to a single method call.

Figure 6.9 Compared to figure 6.8, by hiding IRouteAlgorithmFactory and IRouteAlgorithm behind a single IRouteCalculatorAbstraction, the interaction between RouteController and its (now single) Dependency is simplified.
You can implement an IRouteCalculator in many ways. One way is to inject IRouteAlgorithmFactory into this RouteCalculator. This isn’t our preference, though, because IRouteAlgorithmFactory would be a useless extra layer of indirection you could easily do without. Instead, you’ll inject IRouteAlgorithm implementations into the RouteCalculator constructor.
Listing 6.22 IRouteCalculator wrapping a dictionary of IRouteAlgorithms
public class RouteCalculator : IRouteCalculator
{
private readonly IDictionary<RouteType, IRouteAlgorithm> algorithms;
public RouteCalculator(
IDictionary<RouteType, IRouteAlgorithm> algorithms)
{
this.algorithms = algorithms;
}
public RouteResult Calculate(RouteSpecification spec, RouteType type)
{
return this.algorithms[type].CalculateRoute(spec);
}
}
Using the newly defined RouteCalculator, RouteController can now be constructed like this:
var algorithms = new Dictionary<RouteType, IRouteAlgorithm>
{
{ RouteType.Shortest, new ShortestRouteAlgorithm() },
{ RouteType.Fastest, new FastestRouteAlgorithm() },
{ RouteType.Scenic, new ScenicRouteAlgorithm() }
};
new RouteController(
new RouteCalculator(algorithms));
By refactoring from Abstract Factory to an Adapter, you effectively reduce the number of Dependencies between your components. Figure 6.10 shows the Dependency graph of the initial solution using the Factory, while figure 6.11 shows the object graph after refactoring.

Figure 6.10 The initial Dependency graph for RouteController with IRouteAlgorithmFactory
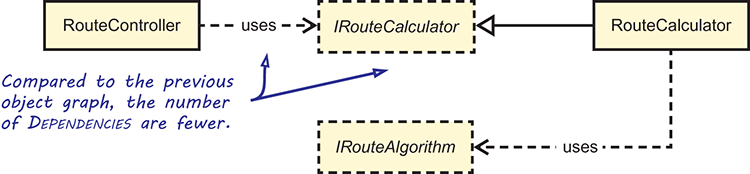
Figure 6.11 The Dependency graph for RouteController when depending on IRouteCalculator instead
When you use Abstract Factories to select Dependencies based on supplied runtime data, more often than not, you can reduce complexity by refactoring toward Adapters that don’t expose the underlying Dependency like the Abstract Factory does. This, however, doesn’t hold only when dealing with Abstract Factories. We’d like to generalize this point.
Typically, service Abstractions shouldn’t expose other service Abstractions in their definition.16 This means that a service Abstraction shouldn’t accept another service Abstraction as input, nor should it have service Abstractions as output parameters or as a return type. Application services that depend on other application services force their clients to know about both Dependencies.
The next code smell is a more exotic one, so you might not encounter it that often. Although the previously discussed code smells can go unnoticed, the next smell is hard to miss — your code either stops compiling or breaks at runtime.
6.3 Fixing cyclic Dependencies
Occasionally, Dependency implementations turn out to be cyclic. An implementation requires another Dependency whose implementation requires the first Abstraction. Such a Dependency graph can’t be satisfied. Figure 6.12 shows this problem.

Figure 6.12 Dependency cycle between Chicken and Egg
The following shows a simplistic example containing the cyclic Dependency of figure 6.12:
public class Chicken : IChicken
{
public Chicken(IEgg egg) { ... } ①
public void HatchEgg() { ... }
}
public class Egg : IEgg ②
{
public Egg(IChicken chicken) { ... } ③
}
With the previous example in mind, how can you construct an object graph consisting of these classes?
new Chicken( ①
new Egg(
??? ②
)
);
What we’ve got here is your typical the chicken or the egg causality dilemma. The short answer is that you can’t construct an object graph like this because both classes require the other object to exist before they’re constructed. As long as the cycle remains, you can’t possibly satisfy all Dependencies, and your applications won’t be able to run. Clearly, something must be done, but what?
In this section, we’ll look into the issue concerning cyclic Dependencies, including an example. When we’re finished, your first reaction should be to try to redesign your Dependencies, because the problem is typically caused by your application’s design. The main takeaway from this section, therefore, is this: Dependency cycles are typically caused by an SRP violation.
If redesigning your Dependencies isn’t possible, you can break the cycle by refactoring from Constructor Injection to Property Injection. This represents a loosening of a class’s invariants, so it isn’t something you should do lightly.
6.3.1 Example: Dependency cycle caused by an SRP violation
Mary Rowan (our developer from chapter 2) has been developing her e-commerce application for some time now, and it’s been quite successful in production. One day, however, Mary’s boss pops around the door to request a new feature. The complaint is that when problems arise in production, it’s hard to pinpoint who’s been working on a certain piece of data in the system. One solution would be to store changes in an auditing table that records every change that every user in the system makes.
After thinking about this for some time, Mary comes up with the definition for an IAuditTrailAppender Abstraction, as shown in listing 6.23. (Note that to demonstrate this code smell in a realistic setting, we need a somewhat complex example. The following example consists of three classes, and we’ll spend a few pages explaining the code, before we get to its analysis.)
Listing 6.23 An IAuditTrailAppenderAbstraction
public interface IAuditTrailAppender ①
{
void Append(Entity changedEntity); ②
}
Mary uses SQL Server Management Studio to create an AuditEntries table that she can use to store the audit entries. The table definition is shown in table 6.2.
| Column Name | Data Type | Allow Nulls | Primary Key |
| Id | uniqueidentifier | No | Yes |
| UserId | uniqueidentifier | No | No |
| TimeOfChange | DateTime | No | No |
| EntityId | uniqueidentifier | No | No |
| EntityType | varchar(100) | No | No |
After creating her database table, Mary continues with the IAuditTrailAppender implementation, shown in the next listing.
Listing 6.24 SqlAuditTrailAppender appends entries to a SQL database table
public class SqlAuditTrailAppender : IAuditTrailAppender
{
private readonly IUserContext userContext;
private readonly CommerceContext context;
private readonly ITimeProvider timeProvider; ①
public SqlAuditTrailAppender(
IUserContext userContext,
CommerceContext context,
ITimeProvider timeProvider)
{
this.userContext = userContext;
this.context = context;
this.timeProvider = timeProvider;
}
public void Append(Entity changedEntity)
{
AuditEntry entry = new AuditEntry
{
UserId = this.userContext.CurrentUser.Id, ②
TimeOfChange = this.timeProvider.Now, ②
EntityId = entity.Id, ②
EntityType = entity.GetType().Name ②
};
this.context.AuditEntries.Add(entry);
}
}
An important part of an audit trail is relating a change to a user. To accomplish this, SqlAuditTrailAppender requires an IUserContext Dependency. This allows SqlAuditTrailAppender to construct the entry using the CurrentUser property on IUserContext. This is a property that Mary added some time ago for another feature.
Listing 6.25 shows Mary’s current version of the AspNetUserContextAdapter (see listing 3.12 for the initial version).
Listing 6.25 AspNetUserContextAdapter with added CurrentUser property
public class AspNetUserContextAdapter : IUserContext
{
private static HttpContextAccessor Accessor = new HttpContextAccessor();
private readonly IUserRepository repository; ①
public AspNetUserContextAdapter(
IUserRepository repository)
{
this.repository = repository;
}
public User CurrentUser ②
{
get
{
var user = Accessor.HttpContext.User; ③
string userName = user.Identity.Name; ③
return this.repository.GetByName(userName); ③
}
}
...
}
While you were busy reading about DI patterns and anti-patterns, Mary’s been busy too. IUserRepository is one of the Abstractions she added in the meantime. We’ll discuss her IUserRepository implementation shortly.
Mary’s next step is to update the classes that need to be appended to the audit trail. One of the classes that needs to be updated is SqlUserRepository. It implements IUserRepository, so this is a good moment to take a peek at it. The following listing shows the relevant parts of this class.
Listing 6.26 SqlUserRepository that needs to append to the audit trail
public class SqlUserRepository : IUserRepository
{
public SqlUserRepository(
CommerceContext context,
IAuditTrailAppender appender) ①
{
this.appender = appender;
this.context = context;
}
public void Update(User user)
{
this.appender.Append(user); ②
... ③
}
public User GetById(Guid id) { ... } ③
public User GetByName(string name) { ... } ④
}
Mary is almost finished with her feature. Because she added a constructor argument to the SqlUserRepository method, she’s left with updating the Composition Root. Currently, the part of the Composition Root that creates AspNetUserContextAdapter looks like this:
var userRepository = new SqlUserRepository(context);
IUserContext userContext = new AspNetUserContextAdapter(userRepository);
Because IAuditTrailAppender was added as Dependency to the SqlUserRepository constructor, Mary tries to add it to the Composition Root:
var appender = new SqlAuditTrailAppender(
userContext, ①
context,
timeProvider);
var userRepository = new SqlUserRepository(context, appender);
IUserContext userContext = new AspNetUserContextAdapter(userRepository);
Unfortunately, Mary’s changes don’t compile. The C# compiler complains: “Cannot use local variable 'userContext' before it’s declared.”
Because SqlAuditTrailAppender depends on IUserContext, Mary tries to supply the SqlAuditTrailAppender with the userContext variable that she defined. The C# compiler doesn’t accept this because such a variable must be defined before it’s used. Mary tries to fix the problem by moving the definition and assignment of the userContext variable up, but this immediately causes the C# compiler to complain about the userRepository variable. But when she moves the userRepository variable up, the compiler complaints about the appender variable, which is used before it’s declared.
Mary starts to realize she’s in serious trouble — there’s a cycle in her Dependency graph. Let’s analyze what went wrong.
6.3.2 Analysis of Mary’s Dependency cycle
The cycle in Mary’s object graph appeared once she added the IAuditTrailAppender Dependency to the SqlUserRepository class. Figure 6.13 shows this Dependency cycle.

Figure 6.13 The Dependency cycle involving AspNetUserContextAdapter, SqlUserRepository, and SqlAuditTrailAppender
The figure shows the cycle in the object graph. The object graph, however, is part of the story. Another view we can use to analyze the problem is the method call graph as shown here:
UserService.UpdateMailAddress(Guid userId, string newMailAddress)
➥ SqlUserRepository.Update(User user)
➥ SqlAuditTrailAppender.Append(Entity changedEntity)
➥ AspNetUserContextAdapter.CurrentUser
➥ SqlUserRepository.GetByName(string name)
This call graph shows how the call would start with the UpdateMailAddress method of UserService, which would call into the Update method of the SqlUserRepository class. From there it goes into SqlAuditTrailAppender, then into AspNetUserContextAdapter and, finally, it ends up in the SqlUserRepository’s GetByName method.
What this method call graph shows is that although the object graph is cyclic, the method call graph isn’t recursive. It would become recursive if GetByName again called SqlAuditTrailAppender.Append, for instance. That would cause the endless calling of other methods until the process ran out of stack space, causing a StackOverflowException. Fortunately for Mary, the call graph isn’t recursive, as that would require her to rewrite the methods. The cause of the problem lies somewhere else — there’s an SRP violation.
When we take a look at the previously declared classes AspNetUserContextAdapter, SqlUserRepository, and SqlAuditTrailAppender, you might find it difficult to spot a possible SRP violation. All three classes seem to be focused on one particular area, as table 6.3 lists.
If you look more closely at IUserRepository, you can see that the functionality in the class is primarily grouped around the concept of a user. This is a quite broad concept. If you stick with this approach of grouping user-related methods in a single class, you’ll see both IUserRepository and SqlUserRepository being changed quite frequently.
When we look at the SRP from the perspective of cohesion, we can ask ourselves whether the methods in IUserRepository are really that highly cohesive. How easy would it be to split the class up into multiple narrower interfaces and classes?
6.3.3 Refactoring from SRP violations to resolve the Dependency cycle
It might not always be easy to fix SRP violations, because that might cause rippling changes through the consumers of the Abstraction. In the case of our little commerce application, however, it’s quite easy to make the change, as the following listing shows.
Listing 6.27 GetByName moved into IUserByNameRetriever
public interface IUserByNameRetriever
{
User GetByName(string name); ①
}
public class SqlUserByNameRetriever : IUserByNameRetriever
{
public SqlUserByNameRetriever(CommerceContext context)
{
this.context = context;
}
public User GetByName(string name) { ... }
}
In the listing, the GetByName method is extracted from IUserRepository and SqlUserRepository into a new Abstraction implementation pair named IUserByNameRetriever and SqlUserByNameRetriever. The new SqlUserByNameRetriever implementation doesn’t depend on IAuditTrailAppender. The remaining part of SqlUserRepository is shown next.
Listing 6.28 The remaining part of IUserRepository and its implementation
public interface IUserRepository ①
{
void Update(User user);
User GetById(Guid id);
}
public class SqlUserRepository : IUserRepository
{
public SqlUserRepository( ②
CommerceContext context,
IAuditTrailAppender appender
{
this.context = context;
this.appender = appender;
}
public void Update(User user) { ... }
public User GetById(Guid id) { ... }
}
Mary gained a couple of things from this division. First of all, the new classes are smaller and easier to comprehend. Next, it lowers the chance of getting into the situation where Mary will be constantly updating existing code. And last, but not least, splitting the SqlUserRepository class breaks the Dependency cycle, because the new SqlUserByNameRetriever doesn’t depend on IAuditTrailAppender. Figure 6.14 shows how the Dependency cycle was broken.

Figure 6.14 The separation of IUserRepository into two interfaces breaks the Dependency cycle.
The following code shows the new Composition Root that ties everything together:
var userContext = new AspNetUserContextAdapter(
new SqlUserByNameRetriever(context)); ①
var appender = new
SqlAuditTrailAppender(
userContext,
context,
timeProvider);
var repository = new SqlUserRepository(context, appender);
The most common cause of Dependency cycles is an SRP violation. Fixing the violation by breaking classes into smaller, more focused classes is typically a good solution, but there are also other strategies for breaking Dependency cycles.
6.3.4 Common strategies for breaking Dependency cycles
When we encounter a Dependency cycle, our first question is, “Where did I fail?” A Dependency cycle should immediately trigger a thorough evaluation of the root cause. Any cycle is a design smell, so your first reaction should be to redesign the involved part to prevent the cycle from happening in the first place. Table 6.4 shows some general directions you can take.
Make no mistake: a Dependency cycle is a design smell. Your first priority should be to analyze the code to understand why the cycle appears. Still, sometimes you can’t change the design, even if you understand the root cause of the cycle.
6.3.5 Last resort: Breaking the cycle with Property Injection
In some cases, the design error is out of your control, but you still need to break the cycle. In such cases, you can do this by using Property Injection, even if it’s a temporary solution.
To break the cycle, you must analyze it to figure out where you can make a cut. Because using Property Injection suggests an optional rather than a required Dependency, it’s important that you closely inspect all Dependencies to determine where cutting hurts the least.
In our audit trail example, you can resolve the cycle by changing the Dependency of SqlAuditTrailAppender from Constructor Injection to Property Injection. This means that you can create SqlAuditTrailAppender first, inject it into SqlUserRepository, and then subsequently assign AspNetUserContextAdapter to SqlAuditTrailAppender, as this listing shows.
Listing 6.29 Breaking a Dependency cycle with Property Injection
var appender =
new SqlAuditTrailAppender(context, timeProvider); ①
var repository =
new SqlUserRepository(context, appender); ②
var userContext = new
AspNetUserContextAdapter(
new SqlUserByNameRetriever(context));
appender.UserContext = userContext; ③
Using Property Injection this way adds extra complexity to SqlAuditTrailAppender, because it must now be able to deal with a Dependency that isn’t yet available. This leads to Temporal Coupling, as discussed in section 4.3.2.
If you don’t want to relax any of the original classes in this way, a closely related approach is to introduce a Virtual Proxy, which leaves SqlAuditTrailAppender intact:17
Listing 6.30 Breaking a Dependency cycle with a Virtual Proxy
var lazyAppender = new LazyAuditTrailAppender(); ①
var repository =
new SqlUserRepository(context, lazyAppender);
var userContext = new
AspNetUserContextAdapter(
new SqlUserByNameRetriever(context));
lazyAppender.Appender = ②
new SqlAuditTrailAppender(
userContext, context, timeProvider);
LazyAuditTrailAppender implements IAuditTrailAppender like SqlAuditTrailAppender does. But it takes its IAuditTrailAppender Dependency through Property Injection instead of Constructor Injection, allowing you to break the cycle without violating the invariants of the original classes. The next listing shows the LazyAuditTrailAppender Virtual Proxy.
Listing 6.31 A LazyAuditTrailAppender Virtual Proxy implementation
public class LazyAuditTrailAppender : IAuditTrailAppender
{
public IAuditTrailAppender Appender { get; set; } ①
public void Append(Entity changedEntity)
{
if (this.Appender == null) ②
{
throw new InvalidOperationException("Appender was not set.");
}
this.Appender.Append(changedEntity); ③
}
}
Always keep in mind that the best way to address a cycle is to redesign the API so that the cycle disappears. But in the rare cases where this is impossible or highly undesirable, you must break the cycle by using Property Injection in at least one place. This enables you to compose the rest of the object graph apart from the Dependency associated with the property. When the rest of the object graph is fully populated, you can inject the appropriate instance via the property. Property Injection signals that a Dependency is optional, so you shouldn’t make the change lightly.
DI isn’t particularly difficult when you understand a few basic principles. As you learn, however, you’re guaranteed to run into issues that may leave you stumped for a while. This chapter addressed some of the most common issues people encounter. Together with the two preceding chapters, it forms a catalog of patterns, anti-patterns, and code smells. This catalog constitutes part 2 of the book. In part 3, we’ll turn toward the three dimensions of DI: Object Composition, Lifetime Management, and Interception.
Summary
- Ever-changing Abstractions are a clear sign of Single Responsibility Principle (SRP) violations. This also relates to the Open/Closed Principle that states that you should be able to add features without having to change existing classes.
- The more methods a class has, the higher the chance it violates the SRP. This is also related to the Interface Segregation Principle, which states that no client should be forced to depend on methods it doesn’t use.
- Making Abstractions thinner solves many problems, such as the complexity of creating Proxies, Decorators, and Test Doubles.
- A benefit of Constructor Injection is that it becomes more obvious when you violate the SRP. When a single class has too many Dependencies, it’s a signal that you should redesign it.
- When a constructor’s parameter list grows too large, we call the phenomenon Constructor Over-injection and consider it a code smell. It’s a general code smell unrelated to, but magnified by, DI.
- You can redesign from Constructor Over-injection in many ways, but splitting up a large class into smaller, more focused classes according to well-known design patterns is always a good move.
- You can refactor away from Constructor Over-injection by applying Facade Services refactoring. A Facade Service hides a natural cluster of interacting Dependencies with their behavior behind a single Abstraction.
- Facade Service refactoring allows discovering these natural clusters and draws previously undiscovered relationships and domain concepts out in the open. Facade Service is related to Parameter Objects but, instead of combining and exposing components, it exposes only the encapsulated behavior while hiding the constituents.
- You can refactor away from Constructor Over-injection by introducing domain events into your application. With domain events, you capture actions that can trigger a change to the state of the application you’re developing.
- A Leaky Abstraction is an Abstraction, such as an interface, that leaks implementation details, such as layer-specific types or implementation-specific behavior.
- Abstractions that implement
IDisposableare Leaky Abstractions.IDisposableshould be put into effect within the implementation instead. - Conceptually, there’s only one instance of a service Abstraction. Abstractions that leak this knowledge to their consumers aren’t designed with those consumers in mind.
- Service Abstractions should typically not expose other service Abstractions in their definition. Abstractions that depend on other Abstractions force their clients to know about both Abstractions.
- When it comes to applying DI, Abstract Factories are often overused. In many cases, better alternatives exist.
- The Dependencies created by an Abstract Factory should conceptually require a runtime value. The translation from a runtime value into an Abstraction should make sense on the conceptual level. If you feel the urge to introduce an Abstract Factory to be able to create instances of a concrete implementation, you may have a Leaky Abstraction on hand. Instead, the Proxy pattern provides you with a better solution.
- Having factory-like behavior inside some classes is typically unavoidable. Application-wide Factory Abstractions, however, should be reviewed with suspicion.
- An Abstract Factory always increases the number of Dependencies a consumer has, along with its complexity.
- When you use Abstract Factories to select Dependencies based on supplied runtime data, more often than not, you can reduce complexity by refactoring towards Facades that don’t expose the underlying Dependency.
- Dependency cycles are typically caused by SRP violations.
- Improving the design of the part of the application that contains the Dependency cycle should be your preferred option. In the majority of cases, this means splitting up classes into smaller, more focused classes.
- Dependency cycles can be broken using Property Injection. You should only resort to solving cycles by using Property Injection as a last-ditch effort. It only treats the symptoms instead of curing the illness.
- Classes should never perform work involving Dependencies in their constructors because the injected Dependency may not yet be fully initialized.