
- Using the full gamut of input variables, local values, and output values
- Making Terraform more expressive with functions and for expressions
- Incorporating two new providers: Random and Archive
- Templating with
templatefile() - Scaling resources with
count
Functional programming is a declarative programming paradigm that allows you to do many things in a single line of code. By composing small modular functions, you can tell a computer what you want it to do instead of how to do it. Functional programming is called that because, as the name implies, programs consist almost entirely of functions. The core principles of functional programming are as follows:
-
Pure functions—Functions return the same value for the same arguments, never having any side effects.
-
First-class and higher-order functions—Functions are treated like any other variables and can be saved, passed around, and used to create higher-order functions.
-
Immutability—Data is never directly modified. Instead, new data structures are created each time data would change.
To give you an idea of the difference between procedural and functional programming, here is some procedural JavaScript code that multiples all even numbers in an array by 10 and adds the results together:
const numList = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
let result = 0;
for (let i = 0; i < numList.length; i++) {
if (numList[i] % 2 === 0) {
result += (numList[i] * 10)
}
}
And here is the same problem solved with functional programming (JavaScript)
const numList = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
const result = numList
.filter(n => n % 2 === 0)
.map(a => a * 10)
.reduce((a, b) => a + b)
locals {
numList = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
result = sum([for x in local.numList : 10 * x if x % 2 == 0])
}
Although you may not consider yourself a programmer, it’s still important to grasp the basics of functional programming. Terraform does not directly support procedural programming, so any logic you want to express needs to be declarative and functional. In this chapter, we take a deep dive into functions, expressions, templates, and other dynamics features that make up the Terraform language.
3.1 Fun with Mad Libs
The specific scenario we will look at builds a program that generates Mad Libs paragraphs from template files. Mad Libs, in case you aren’t aware, is a phrasal templating word game in which one player prompts another for words to fill in the blanks of a story. An example input is shown here:
To make a pizza, you need to take a lump of <noun> and make a thin, round, <adjective> <noun>.
For the given template string, a random noun, an adjective, and another noun will be selected to fill in the placeholders. An example output would therefore be as follows:
To make a pizza, you need to take a lump of roses and make a thin, round, colorful jewelry.
Let’s start by generating a single Mad Libs story. To do that, we need a randomized pool of words to select from, and a template file. The rendered content will then be printed to the CLI. An architecture diagram for what we’re about to do is shown in figure 3.1.
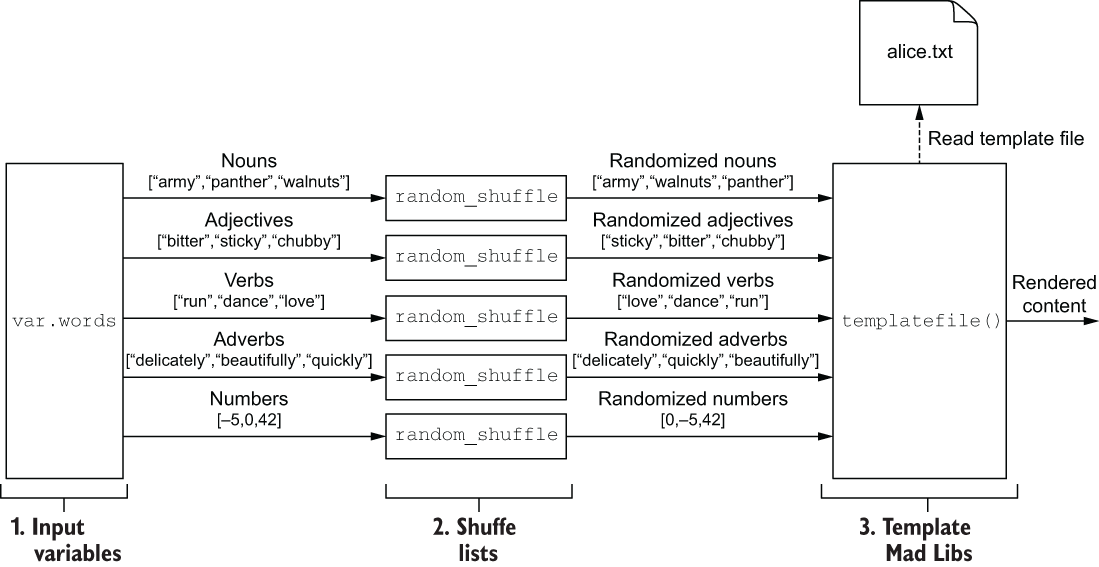
Figure 3.1 Architecture diagram of the Mad Libs template engine
3.1.1 Input variables
First, we need to create the word pool. That means we need to talk about input variables—what they are, how they are declared, and how they can be set and validated.
Input variables (or Terraform variables, or just variables) are user-supplied values that parametrize Terraform modules without altering the source code. Variables are
declared with a variable block, which is an HCL object with two labels. The first label indicates the object type, which is variable, and the second is the variable’s name. A variable’s name can be almost anything, as long as it is unique within a given module and not a reserved identifier. Figure 3.2 shows the syntax of a variable block.
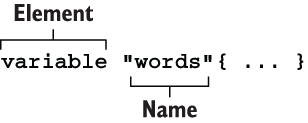
Figure 3.2 Syntax of a variable
Variable blocks accept four input arguments:
-
default—A preselected option to use when no alternative is available. Leaving this argument blank means a variable is mandatory and must be explicitly set. -
description—A string value providing helpful documentation to the user. -
type—A type constraint to set for the variable. Types can be either primitive (e.g. string, integer, bool) or complex (e.g. list, set, map, object, tuple). -
validation—A nested block that can enforce custom validation rules.
Note Variable values can be accessed within a given module by using the expression var.<VARIABLE_NAME>.
For this scenario, we could define a separate variable for each particle of speech, such as nouns, adjectives, verbs, etc. If we did that, our code would look like this:
variable "nouns" {
description = "A list of nouns"
type = list(string)
}
variable "adjectives" {
description = "A list of adjectives"
type = list(string)
}
variable "verbs" {
description = "A list of verbs"
type = list(string)
}
variable "adverbs" {
description = "A list of adverbs"
type = list(string)
}
variable "numbers" {
description = "A list of numbers"
type = list(number)
}
Although this code is clear, we’ll instead group the variables into a single complex variable because then later we can iterate over the words using a for expression.
Create a new project workspace for your Terraform configuration, and make a new file called madlibs.tf. Add in the following code.
terraform { ❶
required_version = ">= 0.15"
}
variable "words" {
description = "A word pool to use for Mad Libs"
type = object({ ❷
nouns = list(string),
adjectives = list(string),
verbs = list(string),
adverbs = list(string),
numbers = list(number),
})
}
❷ Any set value must be coercible into this complex type.
3.1.2 Assigning values with a variable definition file
Assigning variable values with the default argument is not a good idea because doing so does not facilitate code reuse. A better way to set variable values is with a variables definition file, which is any file ending in either .tfvars or .tfvars.json. A variables definition file uses the same syntax as Terraform configuration code but consists exclusively of variable assignments.
Create a new file in the workspace called terraform.tfvars, and add the following code.
words = {
nouns = ["army", "panther", "walnuts", "sandwich", "Zeus", "banana",
➥ "cat", "jellyfish", "jigsaw", "violin", "milk", "sun"]
adjectives = ["bitter", "sticky", "thundering", "abundant", "chubby",
➥ "grumpy"]
verbs = ["run", "dance", "love", "respect", "kicked", "baked"]
adverbs = ["delicately", "beautifully", "quickly", "truthfully",
➥ "wearily"]
numbers = [42, 27, 101, 73, -5, 0]
}
3.1.3 Validating variables
Input variables can be validated with custom rules by declaring a nested validation block. To validate that at least 20 nouns are passed into var.words, you can write a validation block:
variable "words" {
description = "A word pool to use for Mad Libs"
type = object({
nouns = list(string),
adjectives = list(string),
verbs = list(string),
adverbs = list(string),
numbers = list(number),
})
validation {
condition = length(var.words["nouns"]) >= 20
error_message = "At least 20 nouns must be supplied."
}
}
The condition argument in validation is an expression that determines whether a variable is valid. true means it’s valid, while false means invalid. Invalid expressions will exit with an error, and the error message error_message will be displayed to the user. Here is an example from the user’s perspective:
│ │ Error: Invalid value for variable │ │ on madlibs.tf line 5: │ 5: variable "words" { │ │ At least 20 nouns must be supplied. │ │ This was checked by the validation rule at madlibs.tf:14,1-11.
tip There is no limit to the number of validation blocks you can have on a variable, allowing you to be as fine-grained with validation as you like.
3.1.4 Shuffling lists
Now that we have words in our word pool, the next step is to shuffle them. If we don’t shuffle the lists, the order will be fixed, which means exactly the same Mad Libs paragraph would be generated on each execution. Nobody wants to read the same Mad Libs story over and over again, because where is the fun in that? You might expect there to be a function called shuffle() that would shuffle a generic list, but there isn’t. It’s lacking because Terraform strives to be a functional programming language, which means all functions (with the exception of two) are pure functions. Pure functions return the same result for a given set of input arguments and do not cause any additional side effects. shuffle() cannot be allowed because generated execution plans would be unstable, never converging on a fixed configuration.
Note uuid() and timestamp() are the only two impure Terraform functions. These are legacy functions that should be avoided whenever possible because of their potential for introducing subtle bugs and because they are likely to be deprecated at some point.
The Random provider for Terraform introduces a random_shuffle resource for safely shuffling lists, so that’s what we’ll use. Since we have five lists, we need five random_shuffles. This is illustrated in figure 3.3.
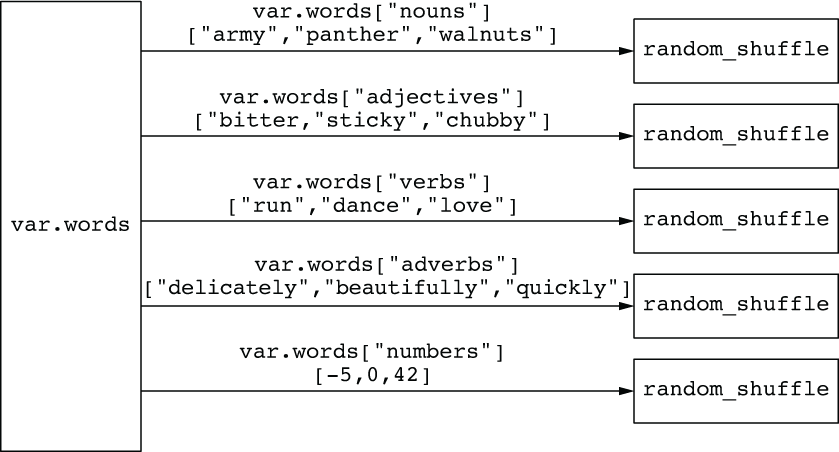
Figure 3.3 Shuffling lists of strings from var.words
Paste the code from the next listing into madlibs.tf to shuffle the words.
terraform {
required_version = ">= 0.15"
required_providers {
random = {
source = "hashicorp/random"
version = "~> 3.0"
}
}
}
variable "words" {
description = "A word pool to use for Mad Libs"
type = object({
nouns = list(string),
adjectives = list(string),
verbs = list(string),
adverbs = list(string),
numbers = list(number),
})
}
resource "random_shuffle" "random_nouns" {
input = var.words["nouns"] ❶
}
resource "random_shuffle" "random_adjectives" {
input = var.words["adjectives"]
}
resource "random_shuffle" "random_verbs" {
input = var.words["verbs"]
}
resource "random_shuffle" "random_adverbs" {
input = var.words["adverbs"]
}
resource "random_shuffle" "random_numbers" {
input = var.words["numbers"]
}
❶ A new shuffled list is generated from the input list.
3.1.5 Functions
We’ll use the randomized list of words to replace placeholder values in a template file, rendering content for a new Mad Libs story. The built-in templatefile() functions allows us to do this easily. Terraform functions are expressions that transform inputs into outputs. Unlike other programming languages, Terraform does not have support for user-defined functions, nor is there a way to import functions from external libraries. Instead, you are restricted to the roughly 100 functions built in to the Terraform language. That’s a lot for a declarative programming language but almost nothing compared to traditional programming languages.
Note You extend Terraform by writing your own provider, not by writing new functions.
Returning to the problem at hand, figure 3.4 shows the templatefile() syntax more closely.

Figure 3.4 Syntax of templatefile()
As you can see, templatefile() accepts two arguments: a path to the template file and a map of template variables to be rendered. We’ll construct the map of template variables by aggregating together the lists of shuffled words (see figure 3.5).
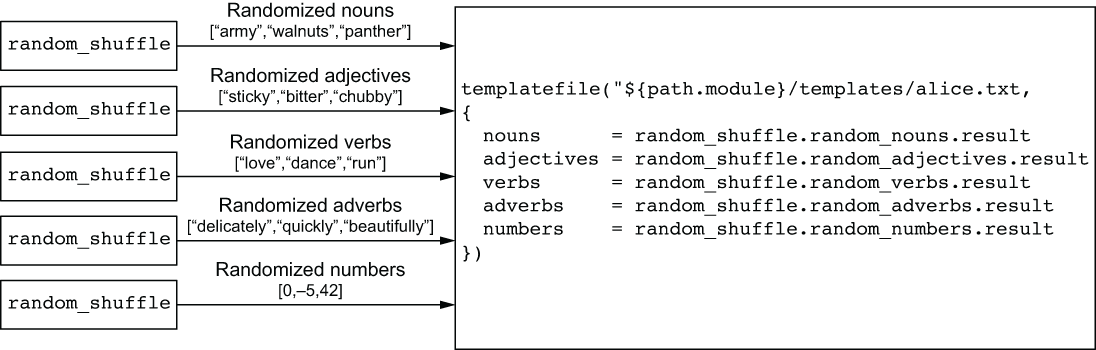
Figure 3.5 Aggregating the lists of shuffled words into a map of template variables
Here’s the templatefile() code:
templatefile("${path.module}/templates/alice.txt",
{
nouns=random_shuffle.random_nouns.result
adjectives=random_shuffle.random_adjectives.result
verbs=random_shuffle.random_verbs.result
adverbs=random_shuffle.random_adverbs.result
numbers=random_shuffle.random_numbers.result
})
3.1.6 Output values
We can return the result of templatefile() to the user with an output value. Output values are used to do two things:
We talk more about passing values between modules in chapter 4; for now, we are interested in printing values to the CLI. The syntax for an output block is shown in figure 3.6.
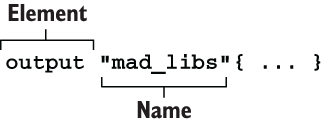
Figure 3.6 Syntax of an output value
Add the output block to madlibs.tf. Your configuration is now as shown in the following listing.
terraform {
required_version = ">= 0.15"
required_providers {
random = {
source = "hashicorp/random"
version = "~> 3.0"
}
}
}
variable "words" {
description = "A word pool to use for Mad Libs"
type = object({
nouns = list(string),
adjectives = list(string),
verbs = list(string),
adverbs = list(string),
numbers = list(number),
})
}
resource "random_shuffle" "random_nouns" {
input = var.words["nouns"]
}
resource "random_shuffle" "random_adjectives" {
input = var.words["adjectives"]
}
resource "random_shuffle" "random_verbs" {
input = var.words["verbs"]
}
resource "random_shuffle" "random_adverbs" {
input = var.words["adverbs"]
}
resource "random_shuffle" "random_numbers" {
input = var.words["numbers"]
}
output "mad_libs" {
value = templatefile("${path.module}/templates/alice.txt",
{
nouns = random_shuffle.random_nouns.result
adjectives = random_shuffle.random_adjectives.result
verbs = random_shuffle.random_verbs.result
adverbs = random_shuffle.random_adverbs.result
numbers = random_shuffle.random_numbers.result
})
}
Note path.module is a reference to the filesystem path of the containing module.
3.1.7 Templates
The last thing to do is create an alice.txt template file. Template syntax is the same as for interpolation values in the main Terraform language, which is anything enclosed in ${ ... } markers. String templates allow you to evaluate expressions and coerce the result to a string.
Any expression can be evaluated with template syntax; however, you are restricted by variable scope. Only passed-in template variables are in scope; all other variables and resources—even within the same module—are not.
Let’s create the template file now. First, create a new directory called templates to contain template files; in this directory, create an alice.txt file.
TIP Some people like to give template files a .tpl extension to indicate their purpose, but I find this unhelpful and confusing. I recommend giving template files the proper extension for what they actually are.
The next listing shows the contents of alice.txt.
ALICE'S UPSIDE-DOWN WORLD
Lewis Carroll's classic, "Alice's Adventures in Wonderland", as well
as its ${adjectives[0]} sequel, "Through the Looking ${nouns[0]}",
have enchanted both the young and old ${nouns[1]}s for the last
${numbers[0]} years, Alice's ${adjectives[1]} adventures begin
when she ${verbs[0]}s down a/an ${adjectives[2]} hole and lands
in a strange and topsy-turvy ${nouns[2]}. There she discovers she
can become a tall ${nouns[3]} or a small ${nouns[4]} simply by
nibbling on alternate sides of a magic ${nouns[5]}. In her travels
through Wonderland, Alice ${verbs[1]}s such remarkable
characters as the White ${nouns[6]}, the ${adjectives[3]} Hatter,
the Cheshire ${nouns[7]}, and even the Queen of ${nouns[8]}s.
Unfortunately, Alice's adventures come to a/an ${adjectives[4]}
end when Alice awakens from her ${nouns[8]}.
3.1.8 Printing output
We’re finally ready to generate our first Mad Libs paragraph. Initialize Terraform by performing a terraform init, and then apply these changes:
$ terraform init && terraform apply -auto-approve ... random_shuffle.random_adjectives: Creation complete after 0s [id=-] random_shuffle.random_numbers: Creation complete after 0s [id=-] random_shuffle.random_nouns: Creation complete after 0s [id=-] Apply complete! Resources: 5 added, 0 changed, 0 destroyed. Outputs: mad_libs = <<EOT ALICE'S UPSIDE-DOWN WORLD Lewis Carroll's classic, "Alice's Adventures in Wonderland", as well as its chubby sequel, "Through the Looking sun", have enchanted both the young and old panthers for the last 0 years, Alice's bitter adventures begin when she kickeds down a/an thundering hole and lands in a strange and topsy-turvy army. There she discovers she can become a tall banana or a small jigsaw simply by nibbling on alternate sides of a magic Zeus. In her travels through Wonderland, Alice respects such remarkable characters as the White walnuts, the sticky Hatter, the Cheshire milk, and even the Queen of violins. Unfortunately, Alice's adventures come to a/an abundant end when Alice awakens from her violin. EOT
Note This would be a good place to use terraform plan before applying changes.
3.2 Generating many Mad Libs stories
We can generate a single Mad Libs story from a randomized pool of words and output the result to the CLI. But what if we wanted to generate more than one Mad Libs at a time? It’s easy to do using expressions and the count meta argument.
To accomplish this, we need to make some changes to the original architecture. Here is the list of design changes:
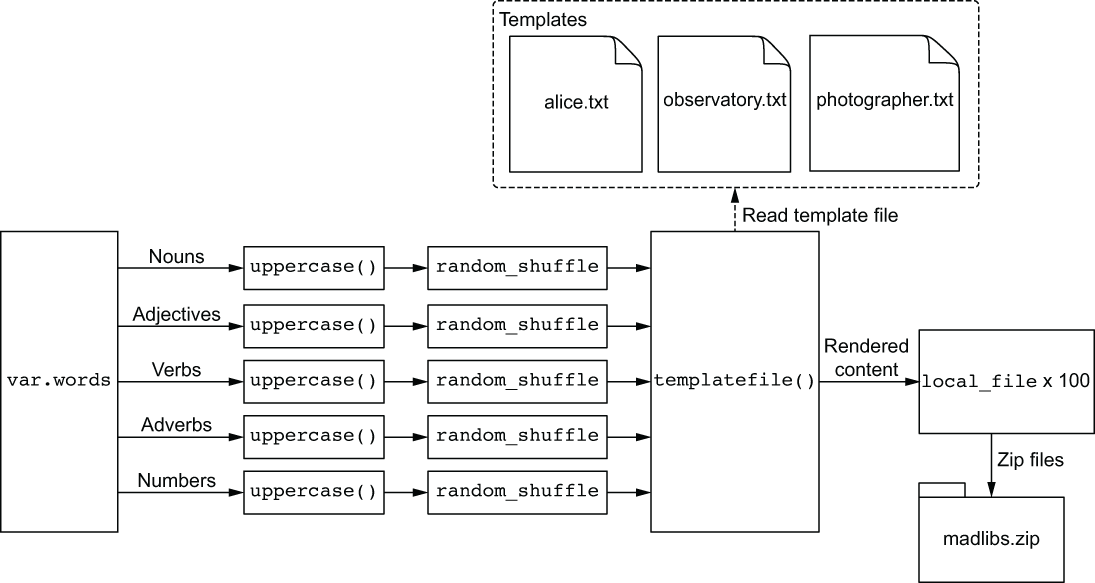
Figure 3.7 Revised architecture for the Mad Libs templating engine
Our revised architecture is shown in figure 3.7.
3.2.1 for expressions
We added a step to uppercase all strings in var.words prior to shuffling. This isn’t strictly necessary, but it does make it easier to see templated words. The result of the uppercase function is saved into a local value, which is then fed into random_ shuffle.
To uppercase all the strings in var.words, we need to employ a for expression. for expressions are anonymous functions that can transform one complex type into another. They use lambda-like syntax and are comparable to lambda expressions and streams in conventional programming languages. Figure 3.8 shows the syntax of a for expression that uppercases each element in an array of strings and outputs the result as a new list. Figure 3.9 illustrates the processed stream.

Figure 3.8 Syntax of a for expression that uppercases each word in a list

Figure 3.9 Visualization of the for expression from figure 3.8
The brackets around a for expression determine the output type. The previous code uses [], which means the output will be a list. If instead we used {}, then the result would be an object. For example, if we wanted to loop through var.words and output a new map with the same key as the original map and a value that is the length of the original value, we could do that with the expression illustrated in figures 3.10 and 3.11.

Figure 3.10 Syntax of a for expression that iterates over var.words and outputs a map

Figure 3.11 Visualization of the for expression from figure 3.10
for expressions are useful because they can convert one type to another and because simple expressions can be combined to construct higher-order functions. To make a for expression that uppercases each word in var.words, we will combine two smaller for expressions into one mega for expression.
TIP Composed for expressions hurt readability and increases cyclomatic complexity, so try not to overuse them.
The general logic is as follows:
Looping through each key-value pair in var.words and outputting a new map can be done with the following expression:
{for k,v in var.words : k => v }
The next expression uppercases each word in a list and outputs to a new list:
[for s in v : upper(s)]
By combining these two expressions, we get
{for k,v in var.words : k => [for s in v : upper(s)]}
Optionally, if you want to filter out a particular key, you can do so with the if clause. For example, to skip any key that matches "numbers", you could do so with the following expression:
{for k,v in var.words : k => [for s in v : upper(s)] if k != "numbers"}
note We do not need to skip the "numbers" key (even if it makes sense to do so) because uppercase("1") is equal to "1", so it’s effectively an identity function.
3.2.2 Local values
We can save the result of an expression by assigning to a local value. Local values assign a name to an expression, allowing it to be used multiple times without repetition. In making the comparison with traditional programing languages, if input variables are analogous to a function’s arguments and output values are analogous to a function’s return values, then local values are analogous to a function’s local temporary symbols.
Local values are declared by creating a code block with the label locals. The syntax for a locals block is shown in figure 3.12.
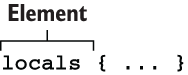
Figure 3.12 Syntax of a local value
Add the new local value to madlibs.tf, and update the reference of all random_shuffle resources to point to local .uppercase_words instead of var.words. The next listing shows how your code should now look.
terraform {
required_version = ">= 0.15"
required_providers {
random = {
source = "hashicorp/random"
version = "~> 3.0"
}
}
}
variable "words" {
description = "A word pool to use for Mad Libs"
type = object({
nouns = list(string),
adjectives = list(string),
verbs = list(string),
adverbs = list(string),
numbers = list(number),
})
}
locals { ❶
uppercase_words = {for k, v in var.words : k => [for s in v : upper(s)]}
}
resource "random_shuffle" "random_nouns" {
input = local.uppercase_words["nouns"]
}
resource "random_shuffle" "random_adjectives" {
input = local.uppercase_words["adjectives"]
}
resource "random_shuffle" "random_verbs" {
input = local.uppercase_words["verbs"]
}
resource "random_shuffle" "random_adverbs" {
input = local.uppercase_words["adverbs"]
}
resource "random_shuffle" "random_numbers" {
input = local.uppercase_words["numbers"]
}
❶ for expression to uppercase strings and save to a local value
3.2.3 Implicit dependencies
At this point, it’s important to point out that because we’re using an interpolated value to set the input attribute of random_shuffle, an implicit dependency is created between the two resources. An expression or resource with an implicit dependency won’t be evaluated until after the dependency is resolved. In the current workspace, the dependency diagram looks like figure 3.13.
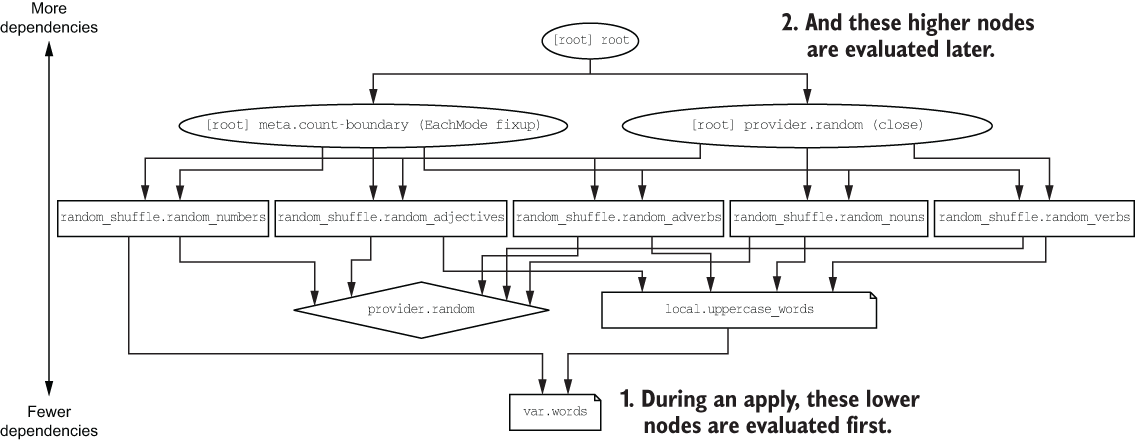
Figure 3.13 Visualizing the dependency graph and execution order
Nodes toward the bottom of the dependency graph have fewer dependencies, while nodes toward the top have more dependencies. At the very top is the root node, which is dependent on all other nodes.
You need to know the following about dependency graphs:
-
Nodes with zero dependencies are created first and destroyed last.
-
You cannot guarantee any ordering between nodes at the same dependency level.
Note dependency graphs quickly become confusing when developing non-trivial projects. I do not find them useful except in the academic sense.
3.2.4 count parameter
To make 100 Mad Libs stories, the brute-force way would be to copy our existing code 100 times and call it a day. I wouldn’t recommend doing this because it’s messy and doesn’t scale well. Fortunately, we have better options. For this particular scenario, we’ll use the count meta argument to dynamically provision resources.
Note In chapter 7, we cover for_each, which is an alternative to count.
Count is a meta argument, which means all resources intrinsically support it by virtue of being a Terraform resource. The address of a managed resource uses the format <RESOURCE TYPE>.<NAME>. If count is set, the value of this expression becomes a list of objects representing all possible resource instances. Therefore, we could access the Nth instance in the list with bracket notation: <RESOURCE TYPE>.<NAME>[N] (see figure 3.14).
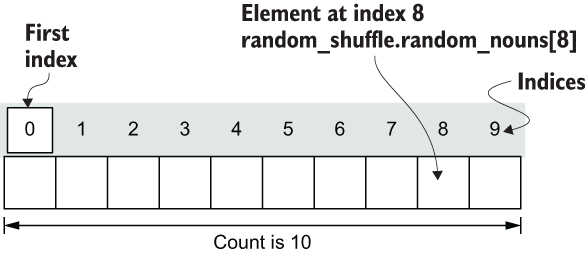
Figure 3.14 Count creates a list of resources that can be referenced using bracket notation.
Let’s update our code to support producing an arbitrary number of Mad Libs stories. First, add a new variable named var.num_files having type number and a default value of 100. Next, reference this variable to dynamically set the count meta argument on each of the shuffle_resources. Your code will look like the next listing.
variable "words" {
description = "A word pool to use for Mad Libs"
type = object({
nouns = list(string),
adjectives = list(string),
verbs = list(string),
adverbs = list(string),
numbers = list(number),
})
}
variable "num_files" {❶
default = 100
type = number
}
locals {
uppercase_words = {for k,v in var.words : k => [for s in v : upper(s)]}
}
resource "random_shuffle" "random_nouns" {
count = var.num_files ❷
input = local.uppercase_words["nouns"]
}
resource "random_shuffle" "random_adjectives" {
count = var.num_files ❷
input = local.uppercase_words["adjectives"]
}
resource "random_shuffle" "random_verbs" {
count = var.num_files ❷
input = local.uppercase_words["verbs"]
}
resource "random_shuffle" "random_adverbs" {
count = var.num_files ❷
input = local.uppercase_words["adverbs"]
}
resource "random_shuffle" "random_numbers" {
count = var.num_files ❷
input = local.uppercase_words["numbers"]
}
❶ Declares an input variable for setting count on the random_shuffle resources
❷ References the num_files variable to dynamically set the count meta argument
3.2.5 Conditional expressions
Conditional expressions are ternary operators that alter control flow based on the results of a boolean condition. They can be used to selectively evaluate one of two expressions: the first for when the condition is true and the second for when it’s false. Before variables had validation blocks, conditional expressions were used to validate input variables. Nowadays, they serve a niche role. The syntax of a conditional expression is shown in figure 3.15.
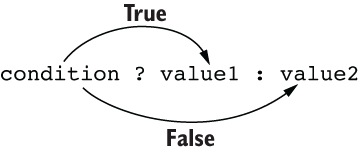
Figure 3.15 Syntax of a conditional expression
The following conditional expression validates that at least one noun is supplied to the nouns word list. If the condition fails, then an error will be thrown (because it is preferable to throw an error than proceed with invalid input):
locals {
v = length(var.words["nouns"])>=1 ? var.words["nouns"] : [][0] ❶
}
❶ var.words["nouns"] must contain at least one word.
If var.words["nouns"] contains at least one word, then application flow continues as normal. Otherwise, an error is thrown:
Error: Invalid index on main.tf line 8, in locals: 8: v = length(var.words["nouns"])>=1 ? var.words["nouns"] : [][0]
Lazy evaluation is why this validation trick works. Only the expression that needs to be evaluated is evaluated—the other control path is ignored. The expression [][0] always throws an error if it’s evaluated (since it attempts to access the first element of an empty list), but it’s not evaluated unless the boolean condition is false.
Conditional expressions are most commonly used to toggle whether a resource will be created. For example, if you had a boolean input variable called shuffle_enabled, you could conditionally create a resource with the following expression:
count = var.shuffle_enabled ? 1 : 0
WARNING Conditional expressions hurt readability a lot, so avoid using them if you can.
3.2.6 More templates
Let’s add two more template files to spice things up a bit. We’ll cycle between them so we have equal number of Mad Libs stories using each template. Make a new template file called observatory.txt in the templates directory, and set the contents as follows.
THE OBSERVATORY
Out class when on a field trip to a ${adjectives[0]} observatory. It
was located on top of a ${nouns[0]}, and it looked like a giant
${nouns[1]} with a slit down its ${nouns[2]}. We went inside and
looked through a ${nouns[3]} and were able to see ${nouns[4]}s in
the sky that were millions of ${nouns[5]}s away. The men and
women who ${verbs[0]} in the observatory are called
${nouns[6]}s, and they are always watching for comets, eclipses,
and shooting ${nouns[7]}s. An eclipse occurs when a ${nouns[8]}
comes between the earth and the ${nouns[9]} and everything
gets ${adjectives[1]}. Next week, we place to ${verbs[1]} the
Museum of Modern ${nouns[10]}.
Next, make another template file called photographer.txt and set the contents as follows.
HOW TO BE A PHOTOGRAPHER
Many ${adjectives[0]} photographers make big money
photographing ${nouns[0]}s and beautiful ${nouns[1]}s. They sell
the prints to ${adjectives[1]} magazines or to agencies who use
them in ${nouns[2]} advertisements. To be a photographer, you
have to have a ${nouns[3]} camera. You also need an
${adjectives[2]} meter and filters and a special close-up
${nouns[4]}. Then you either hire professional ${nouns[1]}s or go
out and snap candid pictures of ordinary ${nouns[5]}s. But if you
want to have a career, you must study very ${adverbs[0]} for at
least ${numbers[0]} years.
3.2.7 Local file
Instead of outputting to the CLI, we’ll save the results to disk with a local_file resource. First, though, we need to read all the text files from the templates folder into a list. This is possible with the built-in fileset() function:
locals {
templates = tolist(fileset(path.module, "templates/*.txt"))
}
Note Sets and lists look the same but are treated as different types, so an explicit cast must be made to convert from one type to another.
Once we have the list of template files in place, we can feed the result into local_ file. This resource generates var.num_files (i.e. 100) text files:
resource "local_file" "mad_libs" {
count = var.num_files
filename = "madlibs/madlibs-${count.index}.txt"
content = templatefile(element(local.templates, count.index),
{
nouns = random_shuffle.random_nouns[count.index].result
adjectives = random_shuffle.random_adjectives[count.index].result
verbs = random_shuffle.random_verbs[count.index].result
adverbs = random_shuffle.random_adverbs[count.index].result
numbers = random_shuffle.random_numbers[count.index].result
})
}
Two things worth pointing out are element() and count.index. The element() function operates on a list as if it were circular, retrieving elements at a given index without throwing an out-of-bounds exception. This means element() will evenly divide the 100 Mad Libs stories between the two template files.
The count.index expression references the current index of a resource (see figure 3.16). We use it to parameterize filenames and ensure that templatefile() receives template variables from corresponding random_shuffle resources.
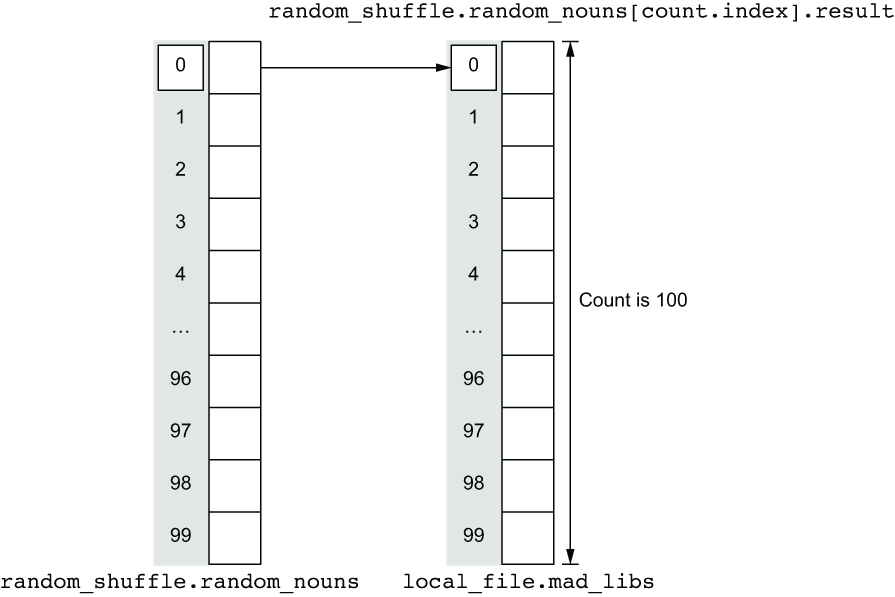
Figure 3.16 random_nouns and mad_libs are lists of resources and must be kept in sync.
3.2.8 Zipping files
We can create arbitrary numbers of Mad Libs stories and output them in a madlibs directory, but wouldn’t it be great to zip the files together as well? The archive_file data source can do just this. It outputs all the files in a source directory to a new zip file. Add the following code to madlibs.tf:
data "archive_file" "mad_libs" {
depends_on = [local_file.mad_libs]
type = "zip"
source_dir = "${path.module}/madlibs"
output_path = "${path.cwd}/madlibs.zip"
}
The depends_on meta argument specifies explicit dependencies between resources. Explicit dependencies describe relationships between resources that are not visible to Terraform. depends_on is included here because archive_file must be evaluated after all the Mad Libs paragraphs have been created; otherwise, it would zip up files in an empty directory. Normally we would express this relationship through an implicit dependency by using an interpolated input argument, but archive_file does not accept any input arguments that it would make sense to set from the output of local_file, so we are forced to use an explicit dependency, instead.
TIP Prefer implicit dependencies over explicit dependencies because they are clearer to someone reading your code. If you must use an explicit dependency, at least document the reason you are using it and what the hidden dependency is.
For reference, the complete code for madlibs.tf is shown in the following listing.
terraform {
required_version = ">= 0.15"
required_providers {
random = {
source = "hashicorp/random"
version = "~> 3.0"
}
local = {
source = "hashicorp/local"
version = "~> 2.0"
}
archive = {
source = "hashicorp/archive"
version = "~> 2.0"
}
}
}
variable "words" {
description = "A word pool to use for Mad Libs"
type = object({
nouns = list(string),
adjectives = list(string),
verbs = list(string),
adverbs = list(string),
numbers = list(number),
})
}
variable "num_files" {
default = 100
type = number
}
locals {
uppercase_words = { for k, v in var.words : k => [for s in v : upper(s)] }
}
resource "random_shuffle" "random_nouns" {
count = var.num_files
input = local.uppercase_words["nouns"]
}
resource "random_shuffle" "random_adjectives" {
count = var.num_files
input = local.uppercase_words["adjectives"]
}
resource "random_shuffle" "random_verbs" {
count = var.num_files
input = local.uppercase_words["verbs"]
}
resource "random_shuffle" "random_adverbs" {
count = var.num_files
input = local.uppercase_words["adverbs"]
}
resource "random_shuffle" "random_numbers" {
count = var.num_files
input = local.uppercase_words["numbers"]
}
locals {
templates = tolist(fileset(path.module, "templates/*.txt"))
}
resource "local_file" "mad_libs" {
count = var.num_files
filename = "madlibs/madlibs-${count.index}.txt"
content = templatefile(element(local.templates, count.index),
{
nouns = random_shuffle.random_nouns[count.index].result
adjectives = random_shuffle.random_adjectives[count.index].result
verbs = random_shuffle.random_verbs[count.index].result
adverbs = random_shuffle.random_adverbs[count.index].result
numbers = random_shuffle.random_numbers[count.index].result
})
}
data "archive_file" "mad_libs" {
depends_on = [local_file.mad_libs]
type = "zip"
source_dir = "${path.module}/madlibs"
output_path = "${path.cwd}/madlibs.zip"
}
3.2.9 Applying changes
We’re ready to apply changes. Run terraform init to download the new providers, and follow it with terraform apply:
$ terraform init && terraform apply -auto-approve ... local_file.mad_libs[71]: Creation complete after 0s [id=382048cc1c505b6f7c2ecd8d430fa2bcd787cec0] local_file.mad_libs[54]: Creation complete after 0s [id=8b6d5cc53faf1d20f913ee715bf73dda8b635b5d] data.archive_file.mad_libs: Reading... data.archive_file.mad_libs: Read complete after 0s [id=4a151807e60200bff2c01fdcabeab072901d2b81] Apply complete! Resources: 600 added, 0 changed, 0 destroyed.
Note If you previously ran an apply before adding archive_file, it will say that zero resources were added, changed, and destroyed. This is somewhat surprising, but it happens because data sources are not considered resources for the purposes of an apply.
The files in the current directory are now as follows:
. ├── madlibs │ ├── madlibs-0.txt │ ├── madlibs-1.txt ... │ ├── madlibs-98.txt │ └── madlibs-99.txt ├── madlibs.zip ├── madlibs.tf ├── templates │ ├── alice.txt │ ├── observatory.txt │ └── photographer.txt ├── terraform.tfstate ├── terraform.tfstate.backup └── terraform.tfvars
Here is an example of a generated Mad Libs story for your amusement:
$ cat madlibs/madlibs-2.txt
HOW TO BE A PHOTOGRAPHER
Many CHUBBY photographers make big money
photographing BANANAs and beautiful JELLYFISHs. They sell
the prints to BITTER magazines or to agencies who use
them in SANDWICH advertisements. To be a photographer, you
have to have a CAT camera. You also need an
ABUNDANT meter and filters and a special close-up
WALNUTS. Then you either hire professional JELLYFISHs or go
out and snap candid pictures of ordinary PANTHERs. But if you
want to have a career, you must study very DELICATELY for at
least 27 years.
This is an improvement because the capitalized words stand out from the surrounding text and, of course, because we have a lot more Mad Libs. To clean up, perform terraform destroy.
Note terraform destroy will not delete madlibs.zip because this file isn’t a managed resource. Recall that madlibs.zip was created with a data source, and data sources do not implement Delete().
3.3 Fireside chat
Terraform is a highly expressive programming language. Anything you want to do is possible, and the language itself is rarely an impediment. Complex logic that takes dozens of lines of procedural code can be easily expressed in one or two functional lines of Terraform code.
The focus of this chapter was on functions, expressions, and templates. We started by comparing input variables, local values, and output values to the arguments, temporary symbols, and return values of a function. We then saw how we can template files using templatefile().
Next, we saw how to scale up to an arbitrary number of Mad Libs stories by using for expressions and count. for expressions allow you to create higher-order functions with lambda-like syntax. This is especially useful for transforming complex data before configuring resource attributes.
The final thing we did was zip up all the Mad Libs paragraphs with an archive_ file data source. We ensured that the zipping was done at the right time by putting in an explicit depends_on.
Terraform includes many kinds of expressions, some of which we have not had the opportunity to cover. Table 3.1 is a reference of all expressions that currently exist in Terraform.
Table 3.1 Expression reference
Summary
-
Input variables parameterize Terraform configurations. Local values save the results of an expression. Output values pass data around, either back to the user or to other modules.
-
forexpressions allow you to transform one complex type into another. They can be combined with otherforexpressions to create higher-order functions. -
Randomness must be constrained. Avoid using legacy functions such as
uuid()andtimestamp(), as these will introduce subtle bugs in Terraform due to a non-convergent state. -
Zip files with the Archive provider. You may need to specify an explicit dependency to ensure that the data source runs at the right time.
-
templatefile()can template files with the same syntax used by interpolation variables. Only variables passed to this function are in scope for templating. -
The
countmeta argument can dynamically provision multiple instances of a resource. To access an instance of a resource created withcount, use bracket notation[].