Part 4
Working with a Team
Everything we’ve covered up to this point is about working with Git on your own. You can use Git like this to track your own projects, but that doesn’t take full advantage of Git’s power. You need to be able to collaborate with other developers on your team using Git.
You share code with other developers using remote repositories. Remote repositories are given names to make them easier to remember. For example, the conventional name for your default remote repository is origin.
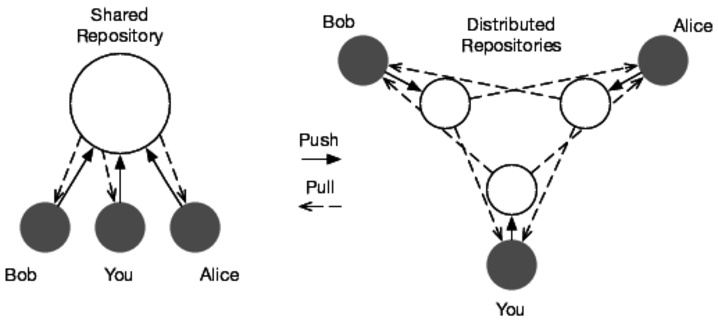
There are two different ways to share code through a remote repository in Git: with a shared repository model or a distributed repository model. For a visual of these two models, see the following image of a shared and distributed repository layout with three developers. (Gray circles are the private repositories; outlined circles are public repositories.)
The one most familiar to those coming from another VCS is the shared repository model.
A shared repository means that all members of your team can push and pull from the same repository. Team members keep their changes locally until they’re ready; then they push those changes back upstream when they’re complete for the rest of the team to use.
This model is very familiar to anyone used to working with a traditional version control system. There’s very little overhead in determining where the code is and what state everything is in.
You can also use a distributed repository model for handling your repositories. Each member of your team has their own private repositories on their computers plus a public repository that they push their code to. Each team member needs to pull changes from the other team members to make sure they have the latest code.
Most teams using a distributed model designate someone as the release manager. It becomes their job to make sure that everything is merged together, and that member’s public repository becomes the repository of record. This is also common in open source projects using Git.
Many teams see the most benefit from a hybrid of these two approaches. One repository is considered the repository of record that everyone syncs against, and then developers share their changes through their public repositories. Once changes are ready to become part of the official version, they get pushed to the official repository.
In addition to the concept of remotes, these tasks introduce two new concepts you use to retrieve and send changes to remote repositories:
Fetching, or retrieving changes from a remote repository, covered in Task 20, Retrieving Remote Changes
Pushing, or sending changes to a remote repository, discussed in Task 22, Sending Changes to Remotes
You might wonder where pulling fits into this. The only difference between a pull (see Task 21, Retrieving Remote Changes, Part II) and a fetch (see Task 20, Retrieving Remote Changes) is that pulling merges changes after Git fetches them. It’s a shorthand way to combine fetching and merging into one command.
All of these changes being retrieved from remote repositories are stored inside your local repository in remote branches. Git treats remote repositories—often called just remotes—as branches. All of the commits from the remotes are stored alongside your commits in the repository, and special remote branches track which commits have branches pointing to them.
You can treat remote branches like normal branches with one exception: you can’t commit to them. That means you can merge or cherry-pick commits from them into your local branches or rebase your local branches on top of remote branches. The only way to get commits into a remote branch is to push those changes to the remote.
Covered in this part:
First you need to know how to handle remote repositories. You learn that in Task 19, Adding and Removing Remotes.
Next up is fetching changes from remote repositories, which you learn about in Task 20, Retrieving Remote Changes.
After you know how to fetch changes, we go over the shorthand command for fetching and merging changes at the same time in Task 21, Retrieving Remote Changes, Part II.
Grabbing changes from other developers is only half the process. You need to be able to send your changes back out into the world. Task 22, Sending Changes to Remotes shows you how.
We’ve already talked about tags and branches locally. You learn about remote tags in Task 23, Handling Remote Tags and Branches.
Before you start concerning yourself with pushing and pulling, however, you need to add a remote repository to communicate with. Let’s cover that next.