
Automated Deployments
Our goal in this chapter is to learn how we need to design our applications so that they’re easy to deploy. This section describes the deployment tools themselves to give us a baseline for understanding the design forces they impose. This overview won’t be enough for you to pick up Chef and start writing deployment recipes, but it will put Chef and tools like it into context so we know what to do with our ingredients.
The first tool of interest is the build pipeline. It picks up after someone commits a change to version control. (Some teams like to build every commit to master; others require a particular tag to trigger a build.) In some ways, the build pipeline is an overgrown continuous integration (CI) server. (In fact, build pipelines are often implemented with CI servers.) The pipeline spans both development and operations activities. It starts exactly like CI with steps that cover development concerns like unit tests, static code analysis, and compilation. See the figure that follows. Where CI would stop after publishing a test report and an archive, the build pipeline goes on to run a series of steps that culminate in a production deployment. This includes steps to deploy code into a trial environment (either real or virtual, maybe a brand-new virtual environment), run migration scripts, and perform integration tests.
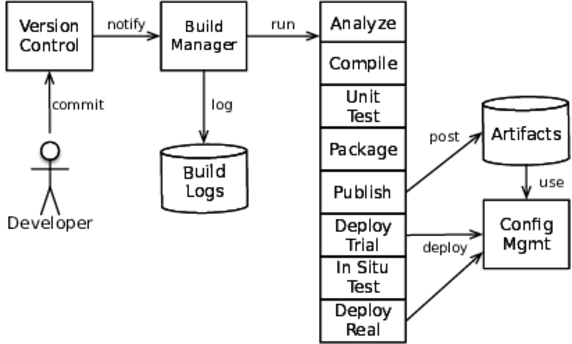
We call it a build pipeline, but it’s more like a build funnel. Each stage of a build pipeline is looking for reasons to reject the build. Tests failed? Reject it. Lint complains? Reject it. Build fails integration tests in staging? Reject it. Finished archive smells funny? Reject it.
This figure lumps steps together for clarity. In a real pipeline, you’ll probably have a larger number of smaller steps. For example, “deploy trial” will usually encompass the preparation, rollout, and cleanup phases that we’ll see later in this chapter.
There are some popular products for making build pipelines. Jenkins is probably the most commonly used today.[75] I also like Thoughtworks’ GoCD.[76] A number of new tools are vying for this space, including Netflix’s Spinnaker and Amazon’s AWS Code Pipeline.[77][78] And you always have the option to roll your own out-of-shell scripts and post-commit hooks. My advice is to dodge the analysis trap. Don’t try to find the best tool, but instead pick one that suffices and get good with it.
At the tail end of the build pipeline, we see the build server interacting with one of the configuration management tools that we first saw in Chapter 8, Processes on Machines. A plethora of open-source and commercial tools aim at deployments. They all share some attributes. For one thing, you declare your desired configuration in some description that the tool understands. These descriptions live in text files so they can be version-controlled. Instead of describing the specific actions to take, as a shell script would, these files describe a desired end state for the machine or service. The tool’s job is to figure out what actions are needed to make the machine match that end state.
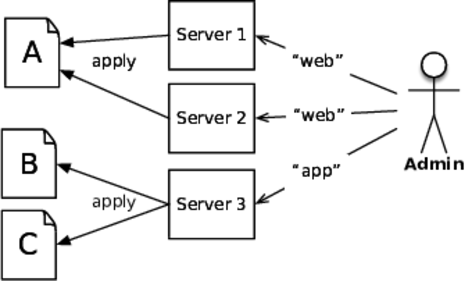
Configuration management also means mapping a specific configuration onto a host or virtual machine. This mapping can be done manually by an operator or automatically by the system itself. With manual assignment, the operator tells the tool what each host or virtual machine must do. The tool then lays down the configurations for that role on that host. Refer to the figure that follows.
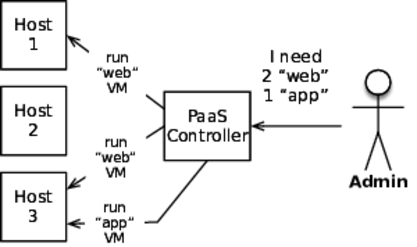
Automatic role assignment means that the operator doesn’t pick roles for specific machines. Instead, the operator supplies a configuration that says, “Service X should be running with Y replicas across these locations.” This style goes hand-in-hand with a platform-as-a-service infrastructure, as shown in the figure. It must then deliver on that promise by running the correct number of instances of the service, but the operator doesn’t care which machines handle which services. The platform combines the requested capacity with constraints. It finds hosts with enough CPU, RAM, and disk, but avoids co-locating instances on hosts. Because the services can be running on any number of different machines with different IP addresses, the platform must also configure the network for load balancing and traffic routing.
Along with role mapping, there are also different strategies for packaging and delivering the machines. One approach does all the installation after booting up a minimal image. A set of reusable, parameterizable scripts installs OS packages, creates users, makes directories, and writes files from templates. These scripts also install the designated application build. In this case, the scripts are a deliverable and the packaged application is a deliverable.
This “convergence” approach says the deployment tool must examine the current state of the machine and make a plan to match the desired state you declared. That plan can involve almost anything: copying files, substituting values into templates, creating users, tweaking the network settings, and more. Every tool also has a way to specify dependencies among the different steps. It is the tool’s job to run the steps in the right order. Directories must exist before copying files. User accounts must be created before files can be owned by them, and so on.
Under the immutable infrastructure approach that we first encountered in Immutable and Disposable Infrastructure, the unit of packaging is a virtual machine or container image. This is fully built by the build pipeline and registered with the platform. If the image requires any extra configuration, it must be injected by the environment at startup time. For example, Amazon Machine Images (AMIs) are packaged as virtual machines. A machine instance created from an AMI can interrogate its environment to find out the “user data” supplied at launch time.
People in the immutable infrastructure camp will argue that convergence never works. Suppose a machine has been around a while, a survivor of many deployments. Some resources may be in a state the configuration management tool just doesn’t know how to repair. There’s no way to get from the current state to the desired state. Another, more subtle issue is that parts of the machine state aren’t even included in your configuration recipes. These will be left untouched by the tool, but might be radically different than you expect. Think about things like kernel parameters and TCP timeouts.
Under immutable infrastructure, you always start with a basic OS image. Instead of trying to converge from an unknown state to the desired state, you always start from a known state: the master OS image. This should succeed every time. If not, at least testing and debugging the recipes is straightforward because you only have to account for one initial state rather than the stucco-like appearance of a long-lived machine. When changes are needed, you update the automation scripts and build a new machine. Then the outdated machine can simply be deleted.
Not surprisingly, immutable infrastructure is closely aligned with infrastructure-as-a-service (IaaS), platform-as-a-service (PaaS), and automatic mapping. Convergence is more common in physical deployments and on long-lived virtual machines and manual mapping. In other words, immutable infrastructure is for cattle, convergence is for pets.