
Load Balancing
Almost everything we build today uses horizontally scalable farms of instances that implement request/reply semantics. Horizontal scaling helps with overall capacity and resilience, but it introduces the need for load balancing. Load balancing is all about distributing requests across a pool of instances to serve all requests correctly in the shortest feasible time. In the previous section we looked at DNS round-robin as a means of load balancing. In this section we will consider active load balancing. This involves a piece of hardware or software inline between the caller and provider instances, as illustrated in the figure.
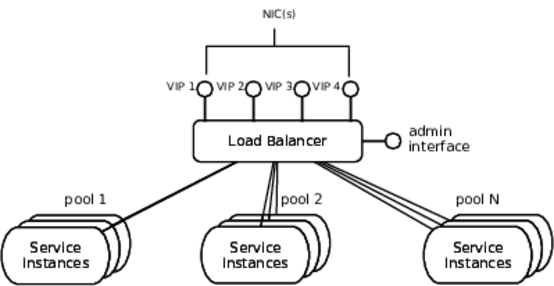
All types of active load balancers listen on one or more sockets across one or more IP addresses. These IP addresses are commonly called “virtual IPs” or “VIPs.” A single physical network port on a load balancer may have dozens of VIPs bound to it, as shown above. Each of these VIPs maps to one or more “pools.” A pool defines the IP addresses of the underlying instances along with a lot of policy information:
- The load-balancing algorithm to use
- What health checks to perform on the instances
- What kind of stickiness, if any, to apply to client sessions
- What to do with incoming requests when no pool members are available
To a calling application, the load balancer should be transparent. At least, that’s the case when it works. If the client can tell there’s a load balancer involved, it’s probably broken.
The service provider instances sitting behind the proxy server need to generate URLs with the DNS name of the VIP rather than their own hostnames. (They shouldn’t be using their own hostnames anyway!)
Load balancers can be implemented in software or with hardware. Each has its advantages and disadvantages. Let’s dig into the software load balancers first.
Software Load Balancing
Software load balancing is the low-cost approach. It uses an application to listen for requests and dole them out across the pool of instances. This application is basically a reverse proxy server, as shown in the figure.
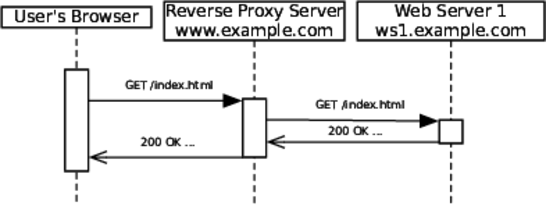
A normal proxy multiplexes many outgoing calls into a single source IP address. A reverse proxy server does the opposite: it demultiplexes calls coming into a single IP address and fans them out to multiple addresses. Squid,[22] HAProxy,[23] Apache httpd,[24] and nginx[25] all make great reverse proxy load balancers.
Like DNS round-robin, reverse proxy servers do their magic at the application layer. As such, they aren’t fully transparent, but adapting to them isn’t onerous. Logging the source address of the request is useless, because it will represent only the proxy server. Well-behaved proxies will add the “X-Forwarded-For” header to incoming HTTP requests, so services can use a custom log format to record that.
In addition to load balancing, you can configure reverse proxy servers to reduce the load on the service instances by caching responses. This provides some benefits in reducing the traffic on the internal network. If the service instances are the capacity constraint in the system, then offloading this traffic improves the system’s overall capacity. Of course, if the load balancer itself is the constraint, then this has no effect.
The biggest reverse proxy server “cluster” in the world is Akamai. Akamai’s basic service functions exactly like a caching proxy. Akamai has certain advantages over Squid and HAProxy, including a large number of servers located near the end users, but is otherwise logically equivalent.
Because the reverse proxy server is involved in every request, it can get burdened very quickly. Once you start contemplating a layer of load balancing in front of your reverse proxy servers, it’s time to look at other options.
Hardware Load Balancing
Hardware load balancers are specialized network devices that serve a similar role to the reverse proxy server. These devices, such as F5’s Big-IP products, provide the same kind of interception and redirection capabilities as the reverse proxy software. Because they operate closer to the network, hardware load balancers provide better capacity and throughput, as illustrated in the following figure.

Hardware load balancers are application-aware and can provide switching at layers 4 through 7 of the OSI stack. In practice, this means they can load-balance any connection-oriented protocol, not just HTTP or FTP. I’ve seen these successfully employed to load-balance a group of search servers that didn’t have their own load managers. They can also hand off traffic from one entire site to another, which is particularly useful for diverting traffic to a failover site for disaster recovery. This works well in conjunction with global server load balancing (see Global Server Load Balancing with DNS).
The big drawback to these machines is—of course—their price. Expect to pay in the five digits for a low-end configuration. High-end configurations easily run into six digits.
Health Checks
One of the most important services a load balancer can provide is service health checks. The load balancer will not send traffic to an instance that fails a certain number of health checks. Both the frequency and number of failed checks are configurable per pool. Refer back to Health Checks, for some details about good health checks.
Stickiness
Load balancers can also attempt to direct repeated requests to the same instance. This helps when you have stateful services, like user session state, in an application server. Directing the same requests to the same instances will provide better response time for the caller because necessary resources will already be in that instance’s memory.
A downside of sticky sessions is that they can prevent load from being distributed evenly across machines. You may find a machine running “hot” for a while if it happens to get several long-lived sessions.
Stickiness requires some way to determine how to group “repeated requests” into a logical session. One common approach has the load balancer attach a cookie to the outgoing response to the first request. Subsequent requests are hashed to an instance based on the value of that cookie. Another approach is to just assume that all incoming requests from a particular IP address are the same session. This approach will break badly if you have a reverse-proxy upstream of the load balancer. It also breaks when a large portion of your customer base reaches you through an outbound proxy in their network. (Looking at you, AOL!)
Partitioning Request Types
Another useful way to employ load balancers is “content-based routing.” This approach uses something in the URLs of incoming requests to route traffic to one pool or another. For example, search requests may go to one set of instances, while use-signup requests go elsewhere. A large-scale data provider may direct long-running queries to a subset of machines and cluster fast queries onto a different set. Of course, something in the requests must be evident to the load balancer.
Remember This
Load balancers are integral to the delivery of your service. We cannot treat them as just part of the network infrastructure any more.
Load balancing plays a part in availability, resilience, and scaling. Because so many application attributes depend on them, it pays to incorporate load-balancing design as you build services and plan deployment. If your organization treats load balancers as “those things over there” that some other team manages, then you might even think about implementing a layer of software load balancing under your control, entirely behind the hardware load balancers in the network.
-
Load balancing creates “virtual IPs” that map to pools of instances.
-
Software load balancers work at the application layer. They’re low cost and easy to operate.
-
Hardware load balancers reach much higher scale than software load balancers. They do require direct network access and specific engineering skills.
-
Health checks are a vital part of load balancer configuration. Good health checks ensure that requests can succeed, not just that the service is listening to a socket.
-
Session stickiness can help response time for stateful services.
-
Consider content-aware load balancing if your service can process workload more efficiently when it is partitioned.