
Unbalanced Capacities
Whether your resources take months, weeks, or seconds to provision, you can end up with mismatched ratios between different layers. That makes it possible for one tier or service to flood another with requests beyond its capacity. This especially holds when you deal with calls to rate-limited or throttled APIs!
In the illustration, the front-end service has 3,000 request-handling threads available. During peak usage, the majority of these will be serving product catalog pages or search results. Some smaller number will be in various corporate “telling” pages. A few will be involved in a checkout process.
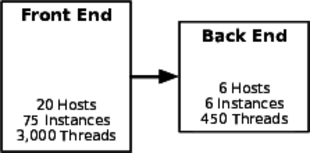
Of the threads serving a checkout-related page, a tiny fraction will be querying the scheduling service to see whether the item can be installed in the customer’s home by a local delivery team. You can do some math and science to predict how many threads could be making simultaneous calls to the scheduling system. The math is not hard, though it does rely on both statistics and assumptions—a combination notoriously easy to manipulate. But as long as the scheduling service can handle enough simultaneous requests to meet that demand prediction, you’d think that should be sufficient.
Not necessarily.
Suppose marketing executes a self-denial attack by offering the free installation of any big-ticket appliance for one day only. Suddenly, instead of a tiny fraction of a fraction of front-end threads involving scheduling queries, you could see two times, four times, or ten times as many. The fact is that the front end always has the ability to overwhelm the back end, because their capacities are not balanced.
It might be impractical to evenly match capacity in each system for a lot of reasons. In this example, it would be a gross misuse of capital to build up every service to the same size just on the off chance that traffic all heads to one service for some reason. The infrastructure would be 99 percent idle except for one day out of five years!
So if you can’t build every service large enough to meet the potentially overwhelming demand from the front end, then you must build both callers and providers to be resilient in the face of a tsunami of requests. For the caller, Circuit Breaker will help by relieving the pressure on downstream services when responses get slow or connections get refused. For service providers, use Handshaking and Backpressure to inform callers to throttle back on the requests. Also consider Bulkheads to reserve capacity for high-priority callers of critical services.
Drive Out Through Testing
Unbalanced capacities are another problem rarely observed during QA. The main reason is that QA for every system is usually scaled down to just two servers. So during integration testing, two servers represent the front-end system and two servers represent the back-end system, resulting in a one-to-one ratio. In production, where the big budget gets allocated, the ratio could be ten to one or worse.
Should you make QA an exact scale replica of the entire enterprise? It would be nice, wouldn’t it? Of course, you can’t do that. You can apply a test harness, though. (See Test Harnesses.) By mimicking a back-end system wilting under load, the test harness helps you verify that your front-end system degrades gracefully. (See Handle Others’ Versions, for more ideas for testing.)
On the flip side, if you provide a service, you probably expect a “normal” workload. That is, you reasonably expect that today’s distribution of demand and transaction types will closely match yesterday’s workload. If all else remains unchanged, then that’s a reasonable assumption. Many factors can change the workload coming at your system, though: marketing campaigns, publicity, new code releases in the front-end systems, and especially links on social media and link aggregators. As a service provider, you’re even further removed from the marketers who would deliberately cause these traffic changes. Surges in publicity are even less predictable.
So, what can you do if your service serves such unpredictable callers? Be ready for anything. First, use capacity modeling to make sure you’re at least in the ballpark. Three thousand threads calling into seventy-five threads is not in the ballpark. Second, don’t just test your system with your usual workloads. See what happens if you take the number of calls the front end could possibly make, double it, and direct it all against your most expensive transaction. If your system is resilient, it might slow down—even start to fail fast if it can’t process transactions within the allowed time (see Fail Fast)—but it should recover once the load goes down. Crashing, hung threads, empty responses, or nonsense replies indicate your system won’t survive and might just start a cascading failure. Third, if you can, use autoscaling to react to surging demand. It’s not a panacea, since it suffers from lag and can just pass the problem down the line to an overloaded platform service. Also, be sure to impose some kind of financial constraint on your autoscaling as a risk management measure.
Remember This
- Examine server and thread counts.
-
In development and QA, your system probably looks like one or two servers, and so do all the QA versions of the other systems you call. In production, the ratio might be more like ten to one instead of one to one. Check the ratio of front-end to back-end servers, along with the number of threads each side can handle in production compared to QA.
- Observe near Scaling Effects and users.
-
Unbalanced Capacities is a special case of Scaling Effects: one side of a relationship scales up much more than the other side. A change in traffic patterns—seasonal, market-driven, or publicity-driven—can cause a usually benign front-end system to suddenly flood a back-end system, in much the same way as a hot Reddit post or celebrity tweet causes traffic to suddenly flood websites.
- Virtualize QA and scale it up.
-
Even if your production environment is a fixed size, don’t let your QA languish at a measly pair of servers. Scale it up. Try test cases where you scale the caller and provider to different ratios. You should be able to automate this all through your data center automation tools.
- Stress both sides of the interface.
-
If you provide the back-end system, see what happens if it suddenly gets ten times the highest-ever demand, hitting the most expensive transaction. Does it fail completely? Does it slow down and recover? If you provide the front-end system, see what happens if calls to the back end stop responding or get very slow.