
Code Ownership and Diffusion of Responsibility
So far we’ve discussed coordination needs mainly in terms of quality: the more developers who touch a piece of code, the higher the risk for defects. But coordination also has a very real direct cost, which is what social psychologists call process loss.
Process loss is a concept that social psychologists borrowed from the field of mechanics. The idea is that just as a machine cannot operate at 100 percent efficiency all the time (due to physical factors like friction and heat loss), neither can a team. Part of a team’s potential productivity is simply lost. (See Group Process and Productivity [Ste72] for the original research.)
The kind of process loss that occurs depends on the task, but in a brain-intensive collaboration like software, most process loss is due to communication and coordination overhead. Process loss may also be driven by motivation losses and other social group factors. These are related to a psychological phenomenon called diffusion of responsibility. You notice the most extreme manifestation of diffusion of responsibility if you’re unfortunate enough to witness an accident or an emergency; the larger any group of bystanders, the less likely any individual will provide help. Scary.
One of the most important reasons behind diffusion of responsibility is that in larger groups we don’t feel a personal sense of responsibility, and we assume someone else should react and help.[79] The consequence is that the group setting makes us act in a way we wouldn’t if we were alone.
Diffusion of responsibility usually takes on less dramatic forms in software, but it’s still there and the same situational forces have serious implications for code quality and productivity. To counter these effects we must feel that our individual contributions make a difference. Good code has a sense of personal responsibility from everyone involved.
To counter the diffusion of responsibility we need to look for structural solutions. One way of producing personal responsibility is privatizing, which is an effective technique for managing shared resources in the real world. (See The commons dilemma: A simulation testing the effects of resource visibility and territorial division [CE78] for research on how groups benefit from privatization.) Since code is about knowledge rather than a physical resource, we need to explore the idea of privatizing and its consequences in terms of code ownership.
Immutable Design
Providing a clear ownership model also helps address hotspots. I analyze codebases as part of my day job, and quite often I come across major hotspots with low code quality that still attract 10 to 15 percent of all development efforts.
It’s quite clear that this code is a problem, and when we investigate its complexity trends we frequently see that those problems have been around for years, significantly adding to the cost and displeasure of the project. New code gets shoehorned into a seemingly immutable design, which has failed to evolve with the system.
At the same time, such code is often not very hard to refactor, so why hasn’t that happened? Why do projects allow their core components to deteriorate in quality, year after year? A look at the diffusion of responsibility provides part of the answer as the developer fragmentation of those hotspots tends to look like the figure.
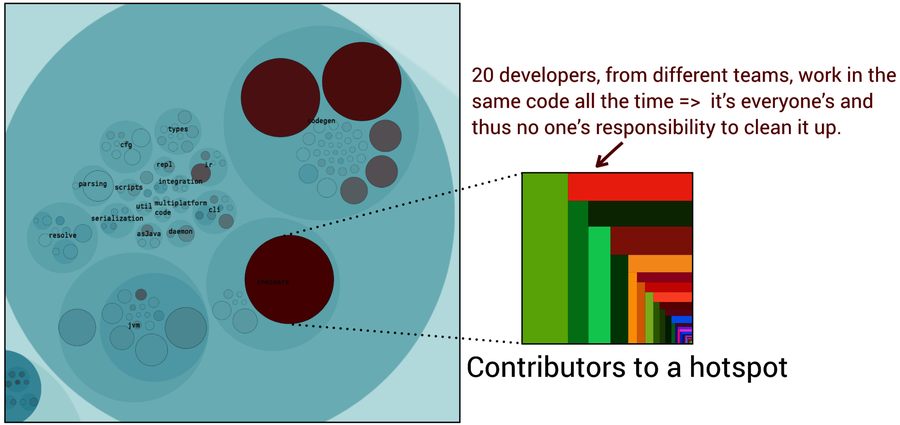
This is the software version of a crowd of people looking passively at an accident. Again, the main problem here isn’t technical but social, and it’s intimately tied to the organization building the code.
Code Ownership Means Responsibility
Code ownership can be a controversial topic as some organizations move to models where every developer is expected to work on all parts of the codebase. The idea of code ownership evokes the idea of development silos where knowledge is isolated in the head of a single individual. So let’s be clear about this: when we talk ownership, we don’t mean ownership in the sense of “This is my code—stay away.” Rather, ownership is a mechanism to counter the diffusion of responsibility, and it suggests that someone takes personal responsibility for the quality and future of a piece of code.
That “someone” can be an individual, a pair, or a small team in a larger organization. I’ve also seen organizations that successfully adopt an open source–inspired ownership model where a single team owns a piece of code, yet anyone can—and is encouraged to—contribute to that code. The owning team, however, still has the final say on whether to accept the contributions. The advantage of this model is that it allows teams to bridge gaps in the alignment between architecture and organization by implementing the functionality they need even when it happens to cross organizational boundaries.
Provide Broad Knowledge Boundaries
The effects we discuss are all supported by data, and whether we like it or not, software development doesn’t work well with lots of minor contributors to the same parts of the code. We’ve seen some prominent studies that support this claim, and there is further research in Code ownership and software quality: a replication study [GHC15], which shows that code ownership correlates with code quality. This research is particularly interesting since it replicates an earlier study, Don’t Touch My Code! Examining the Effects of Ownership on Software Quality [BNMG11], which claims that the risk for defects increases with the number of minor developers in a component.
Of course, these findings don’t mean you should stop sharing knowledge between people and teams—quite the contrary. It means that we need to distinguish between our operational boundaries (the parts where we’re responsible and write most of the code) from the knowledge boundaries of each team (the parts of the code we understand and are relatively familiar with). We want to keep the latter more broad, as illustrated in the following figure.
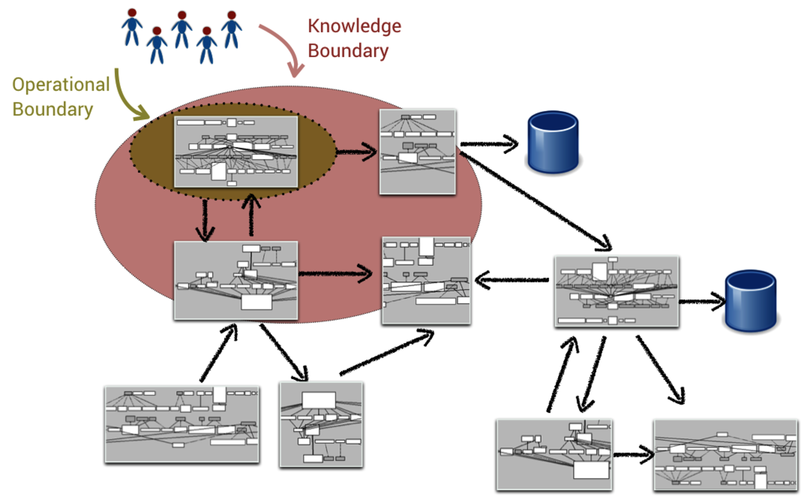
Whereas Conway’s law implies that our communication works best with well-defined operational boundaries, broader knowledge boundaries make interteam communication easier since we share parts of each other’s context. There’s also evidence that broader knowledge boundaries provide our organization with a competitive advantage, enabling us to see opportunities and benefit from innovations outside our area of the code. (See The Mirroring Hypothesis: Theory, Evidence, and Exceptions [CB16] for a summary of 142 empirical studies on the topic.)
There are several techniques for broadening your knowledge boundaries, such as inviting people from other teams to code reviews and scheduling recurring sessions where you present walkthroughs of a solution or design. You may also choose to encourage people to rotate teams. When combined, these techniques give your teams a fresh perspective on their work and help foster a culture of shared goals. In addition, few things provide a greater learning opportunity than explaining your code and design to someone else.
The key to finding the right boundaries is to make it a deliberate rather than an accidental designation. We can’t measure the precise knowledge boundaries, but we can get an accurate picture of the operational boundaries based on where each developer has contributed code, and use that information to streamline our architecture and organization. We’ll cover how to do that in a minute, but as a first step we need to agree on a cutoff date for our analysis.
Specify a Start Date with Organizational Significance
Development organizations aren’t static. People move between teams, new teams are formed, and old teams are abandoned. Each organizational change introduces a possible bias into the team-level metrics.
You can avoid these biases by selecting an analysis start date that represents the date of your last organizational change. For example, let’s say you changed the team structure in March 2017. In that case you want to limit your version-control data to changes since that date, which you do with the --after option to Git that we discussed earlier. Behavioral data in the shape of version-control commits accumulates quickly, and a few weeks of activity is usually enough to detect the patterns we discuss in this chapter.
Note that the technical analyses, like hotspots and change coupling, are different from social analyses because you want to detect long-term trends. In that case, use a start date that represents a significant event in your product’s life cycle, such as a major release or a fairly large redesign. With the analysis time span covered, we’re ready to start analyzing team work.