
The Three Generations of Code
The code age analysis was inspired by the work of Dan North, who introduced the idea of short software half-life as a way to simplify code. North claims that we want our code to be either very recent or old, and the kind of code that’s hard to understand lies in between these two extremes.[53] North’s observation ties in with how human memory works, so let’s take a brief detour into the science of forgetting before we return to code age and see how it impacts our ability to understand systems.
In Your Mental Models of Code, we saw how our brain makes sense of code by building cognitive schemas. Unfortunately, those mental models aren’t fixed. That’s why we may find ourselves cursing a particular design choice only to realize it’s code written by our younger selves in a more ignorant time. We humans forget, and at a rapid pace.
Back in 1885 the psychologist Hermann Ebbinghaus published his pioneering work on how human memory functions. (See Über das Gedächtnis. Untersuchungen zur experimentellen Psychologie. [Ebb85].) In this research, Ebbinghaus studied his own memory performance by trying to remember as many made-up nonsense syllables as possible (kind of like learning to code in Perl). Ebbinghaus then retested his memorization after various periods of time, and discovered that we tend to forget at an exponential rate. This is bad news for a software maintainer.
The next figure shows the Ebbinghaus forgetting curve, where we quickly forget information learned at day one. To retain the information we need to repeat it, and with each repetition we’re able to improve our performance by remembering more.
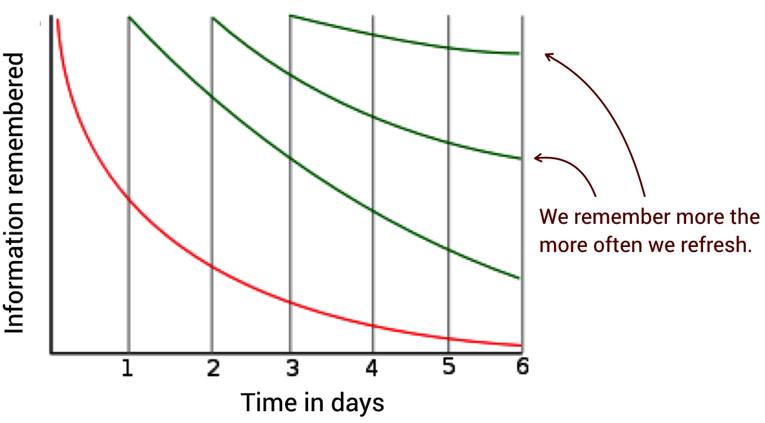
Now, think back to North’s claim that code should be either recent or old. This works as a design principle because it aligns with the nature of the Ebbinghaus forgetting curve. Recent code is what we extend and modify right now, which means we have a fresh mental model of the code and we know how it achieves its magic. In contrast, old code is by definition stable, which means we don’t have to modify it, nor do we have to maintain any detailed information about its inner workings. It’s a black box.
The Ebbinghaus forgetting curve also explains why code that’s neither old nor recent is troublesome; such code is where we’ve forgotten much detail, yet we need to revisit the code at times. Each time we revisit mid-aged code we need to relearn its inner workings, which comes at a cost of both time and effort.
There’s also a social side to the age of code in the sense that the older the code, the more likely the original programmer has left the organization. This is particularly troublesome for the code in between—the code we fail to stabilize—because it means that we, as an organization, have to modify code we no longer know. David Parnas labeled such modifications “ignorant surgery” as a reference to changing code whose original design concept we fail to understand. (See Software Aging [Par94].)
The first ignorant surgery is an invitation for others to follow. Over time the code gets harder and harder to understand, which leaves us with a technical debt that’s largely due to the organizational factor of failing to maintain mastery of the system. Such code also becomes brittle, which means it’s important to stabilize code from a quality perspective too.
Your Best Bug Fix Is Time
Back in my days as a consultant I was hired to do a code review of a database framework. The code, which had been around for years, was a monument to accidental complexity and the basis of many war stories among the senior staff. The code review soon confirmed that the design was seriously flawed. However, as we followed up with a code age analysis, we noted that the code had barely been touched over the past year. So what was all the fuss about? Why spend time reviewing that code?
Well, this organization faced lots of technical debt—both reckless and strategic—and now was the time to pay it off. The database framework was the starting point since that’s what everyone complained the most about and had the urge to rewrite. However, those complaints were rooted in folklore rather than data. Sure, the code was messy to work with, so the few people brave enough to dive into it did raise valid complaints, but it had cooled down significantly and was no longer a hotspot. And to our surprise the code wasn’t defect-dense either.
Software bugs always occur in a context, which means that a coding error doesn’t necessarily lead to a failure. Historically, that database framework had its fair share of critical defects, but it had since been patched into correctness by layers of workarounds delivered by generations of programmers. Now it just did its job and it did it fairly well.
The risk of a new bug decreases with every day that passes. That’s due to the interesting fact that the risk of software faults declines with the age of the code. A team of researchers noted that a module that is a year older than a similar module has roughly one-third fewer faults. (See Predicting fault incidence using software change history [GKMS00].) The passage of time is like a quality verdict, as it exposes modules to an increasing number of use cases and variations. Defective modules have to be corrected. And since bug fixes themselves, ironically, pose a major risk of introducing new defects, the code has to be patched again and again. Thus, bugs breed bugs and it all gets reflected as code that refuses to stabilize and age.
Test Cases Don’t Age Well | |
|---|---|
|
|
While old code is likely to be good code in the sense that it has low maintenance costs and low defect risk, the same reasoning doesn’t apply to test cases. Test cases tend to grow old in the sense that they become less likely to identify failures. (See Do System Test Cases Grow Old? [Fel14].) Tests are designed in a context and, as the system changes, the tests have to evolve together with it to stay relevant. |
Even when a module is old and stable, bad code may be a time bomb and we might defuse it by isolating that code in its own library. The higher-level interface of a library serves as a barrier to fend off ignorant surgeries. Let’s see how we get there by embarking on our first code age analysis.
Refactor Toward Code of Similar Age
We’ve already learned to calculate code age, so let’s import the raw numbers into a spreadsheet application and generate a histogram like the one in the next figure.
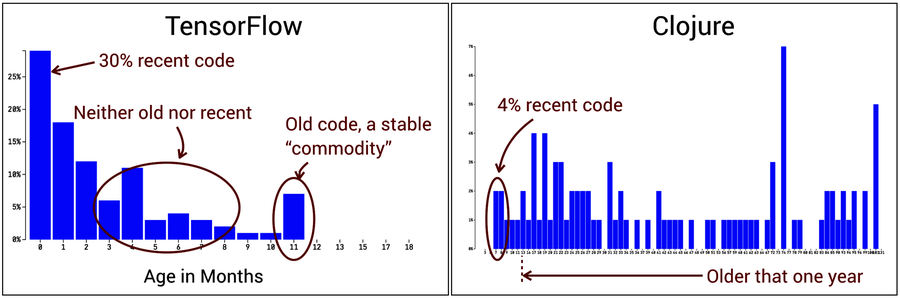
The preceding figure shows the code age distribution of two codebases in radically different states of development: Google’s machine-learning service TensorFlow and the programming language Clojure.[54] [55]
At this time of writing, TensorFlow is under heavy development and that’s reflected in its age profile; much of the code shows up as recent. This is in contrast to the age profile of the Clojure code, where most of it hasn’t been touched in years. The age distribution of Clojure shows a stable codebase that has found its form.
Code age, like many of the techniques in this book, is a heuristic. That means the analysis results won’t make any decisions for us, but rather will guide us by helping us ask the right questions. One such question is if we can identify any high-level refactoring opportunities that allow us to turn a collection of files into a stable package—that is, a mental chunk.
The preceding age distribution of TensorFlow showed that most code was recent, but we also identified a fair share of old, stable code. If we can get that stable code to serve as a chunk, we’ll reap the benefits of an age-oriented code organization that we discussed earlier. So let’s project TensorFlow’s age information onto the static structure of our code.
The next figure shows CodeScene’s age map zoomed in on TensorFlow’s core/lib package. As usual, you can follow along interactively in the pregenerated analysis results.[56]
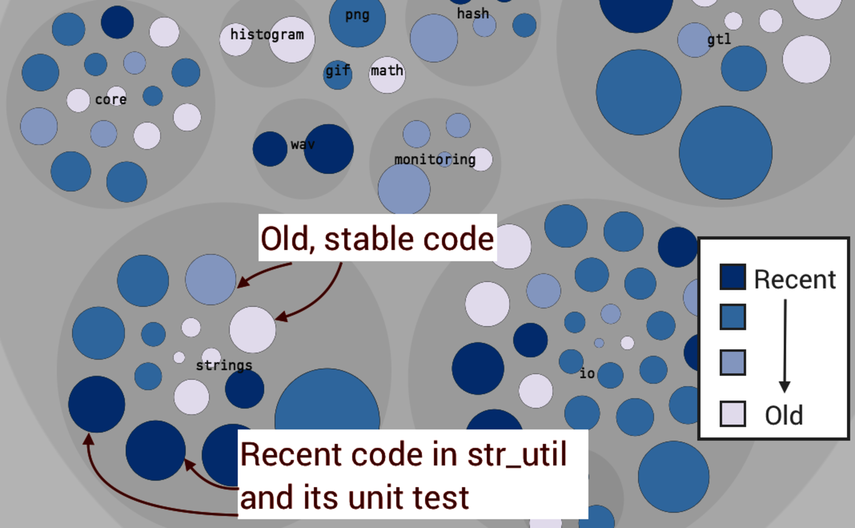
You may recognize the visualization style as an enclosure diagram, just like the one we used in Prioritize Technical Debt with Hotspots. The difference here is that the color signals the age of the files rather than change frequencies—everything else is the same. The dark blue circles represent recent code and the lighter blue shades indicate code of increasing age.
We start our investigation at the strings package in the lower-right corner. The reason we start there is because the visualization indicates that the package contains code of mixed age. There are no precise rules, so we rely on this visual heuristic instead. If you inspect the actual age of each file, you find that most code is between eight and eleven months old. That’s close to ancient, given the rapid development of TensorFlow. However, we also note that the module str_util.cc and its corresponding unit test are recent and thus prevent us from stabilizing the whole package.
Domain Knowledge Drives Refactorings | |
|---|---|
|
|
The strings package refactoring in this TensorFlow example is chosen as a simple example because we don’t want to get sidetracked by domain details; strings are a universal programming construct. A code age analysis on your own code may point you toward more complex refactorings. Should the refactoring turn out to be too hard, take a step back—which is easy with version control—and restart it using the splinter pattern. (See Refactor Congested Code with the Splinter Pattern.) |
Back in Signal Incompleteness with Names, we saw that generic module names like str_util.cc signal low cohesion. Given the power of names—they guide usage and influence our thought processes—such modules are quite likely to become a dumping ground for a mixture of unrelated functions. This is a problem even when most of the existing functions in such utility-style files are stable, as the module acts like a magnet that attracts more code. This means we won’t be able to stabilize the strings package unless we introduce new modular boundaries.
A quick code inspection of str_util.cc confirms our suspicions as we notice functions with several unrelated responsibilities:[57] some escape control characters, others strip whitespace or convert to uppercase, and much more. To stabilize the code we extract those functions into separate modules based on the different responsibilities. We also take the opportunity to clarify the intent of some functions by renaming them, as the figure illustrates.
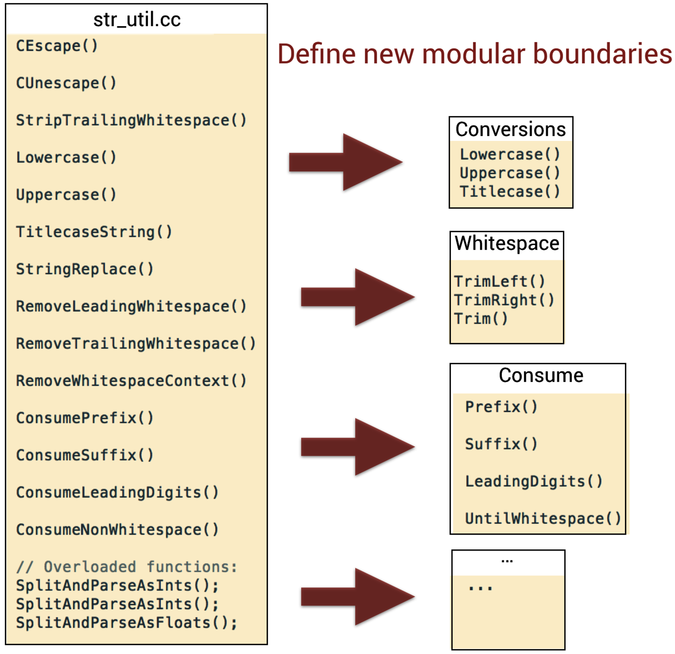
If this were our own code we would continue to split the corresponding unit test str_util_test.cc too. But let’s leave that for now and reflect on where our refactoring would take us:
- Each new module is more cohesive, with a clear responsibility.
- The name of each module suggests a usage related to the solution domain.
- As string objects represent a largely fixed problem space, it’s likely that several of our new modules won’t be touched again. Stable code!
This single refactoring won’t be enough to turn the whole strings package into a stable chunk that we can extract into a library. However, we’ve taken the first step. From here we identify the next young file inside strings, explore why it fails to stabilize, and refactor when needed. Such refactorings have to be an iterative process that stretches over time, and as we move along we can expect to stabilize larger and larger chunks of our code.