
The Splitter EIP provides you with a versatile mechanism for breaking a message down into smaller fragments and processing them individually.
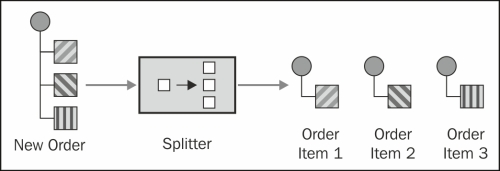
This recipe will show you how to use the Splitter EIP, along with Camel's built-in Expression Languages, to easily slice up your messages.
The Java code for this recipe is located in the org.camelcookbook.splitjoin.split package. The Spring XML files are located under src/main/resources/META-INF/spring and prefixed with split.
Inside your route, create a split statement, whose first line is the split expression. The following code splits a message naturally, meaning that any message that is an array, Collection, or Iterator will have each element processed individually through the statements in the block, as through a loop:
<from uri="direct:in"/>
<split>
<simple>${body}</simple>
<to uri="mock:split"/>
</split>Here, ${body} is a Simple Expression Language that identifies the node in the object graph to be split.
In Java, the corresponding block could be written as follows:
from("direct:in")
.split(body())
.to("mock:split")
.end();Here the body() expression is used for convenience instead of writing simple("${body}"). The end() method designates the end of the split() block.
The Splitter EIP evaluates the expression to obtain a collection of elements to process. Each element is processed individually through the statements within the split block, in the order evaluated by the expression.
The expression can be anything that uniquely identifies a collection of things that the EIP can split, or returns a collection of values. Consider the following class, which represents the body of an exchange flowing through the route:
public class ListWrapper {
// getters and setters omitted
private List<String> wrapped;
}In order to process each of the Strings individually, all we need to do is to modify the expression used within the Splitter to the following:
from("direct:in")
.split(simple("${body.wrapped}"))
.to("mock:out")
.end();The same thread that originally entered the block will process each of the split steps individually. When the thread exits the block, the body of the exchange will contain the original content. The reason behind this is that the Splitter has the option of aggregating the processed message fragments using AggregationStrategy (see the Splitting a message, and processing and gathering responses recipe). The default AggregationStrategy used always returns the original unsplit exchange.
When a message is split, a new exchange is created for each message fragment as it is processed through the route. This exchange contains a copy of the headers and properties of the original. In addition, the following message properties are set:
CamelSplitIndex: A 0-based index of the messageCamelSplitSize: The total number of fragments split from the original exchange bodyCamelSplitComplete: ABooleanthat indicates whether this exchange contains the last fragment
When an exception is thrown within your split() block, Camel will trigger the route's error handler for the exchange containing the split fragment. Beyond this, the default behavior is not what you would expect, in that the splitting process will not be interrupted like a traditional Java loop. Instead, the remainder of the split items will continue to be processed one by one. However, processing will be suspended at the completion of the split(), and then the exception will be thrown back to the consuming endpoint.
You can modify this behavior to what you might otherwise expect, by setting the stopOnException attribute to true:
In the XML DSL, this is written as:
<split stopOnException="true">
In the Java DSL, the same thing is expressed as:
.split(body()).stopOnException()
This will prevent the splitting process from processing any further fragments when an exception occurs.
- Splitter: http://camel.apache.org/splitter.html
- Simple Expression Language: http://camel.apache.org/simple.html