
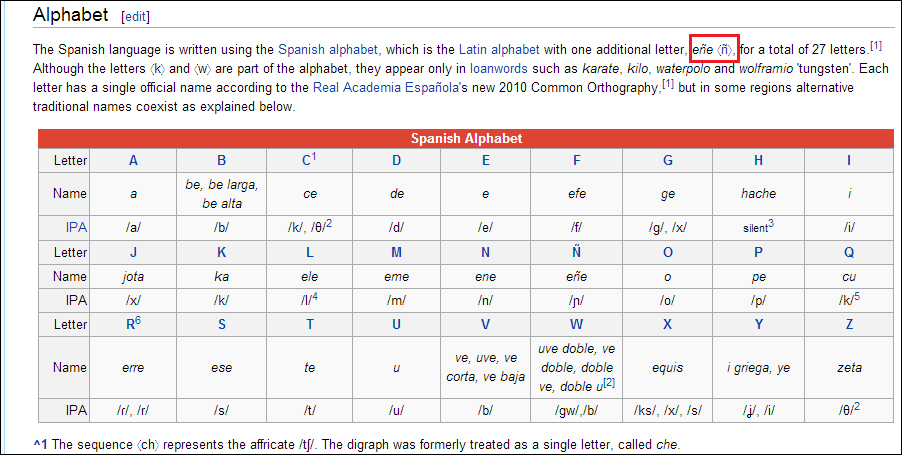
All web pages will have an encoding associated with it. Modern websites have different encodings such as UTF-8, and Latin-1. Nowadays, UTF-8 is the encoding standard used in websites. So, while dealing with the scraping of such pages, it is important that the scraper should also be capable of understanding those encodings. Otherwise, the user will see certain characters in the web browser whereas the result you would get after using a scraper would be gibberish characters. For example, consider a sample web content from Wikipedia where we are able to see the Spanish character ñ.
If we run the same content through a scraper with no support for the previous encoding used by the website, we might end up with the following content:
The Spanish language is written using the Spanish alphabet, which is the Latin alphabet with one additional letter, e単e (単), for a total of 27 letters.We see the Spanish character ñ is replaced with gibberish characters. So it is important that a scraper should support different encodings. Beautiful Soup handles these encodings pretty neatly. In this chapter, we will see the encoding support in Beautiful Soup.
As already explained, every HTML/XML document will be written in a specific character set encoding, for example, UTF-8, and Latin-1. In an HTML page, this is represented using the meta tag as shown in the following example:
<meta http-equiv="Content-Type" content="text/html;charset=UTF-8">
Beautiful Soup uses the UnicodeDammit library to automatically detect the encoding of the document. Beautiful Soup converts the content to Unicode while creating soup objects from the document.
In the previous example, Beautiful Soup converts the document to Unicode.
html_markup = """<p> The Spanish language is written using the Spanish alphabet, which is the Latin alphabet with one additional letter, eñe ⟨ñ⟩, for a total of 27 letters.</p> """ soup = BeautifulSoup(html_markup,"lxml") print(soup.p.string) #output ' The Spanish language is written using the Spanish alphabet, which is the Latin alphabet with one additional letter, e単e (単), for a total of 27 letters.
From the previous output, we can see that there is a difference in the additional letter part (e
単
e (
単
)) because there is a gibberish character instead of the actual representation. This is due to the wrong interpretation of the original encoding in the document by UnicodeDammit.
The previous HTML content was originally of UTF-8 encoding. But Beautiful Soup, while generating the soup object, detects encoding using the UnicodeDammit library and we can get hold of this original encoding using the attribute original_encoding.
The soup.original_encoding will give us the original encoding, which is euc-jp in the previous case. This is wrong because UnicodeDammit detected the encoding as euc-jp instead of utf-8.
The UnicodeDammit library detects the encoding after a careful search of the entire document. This is time consuming and there are cases where the UnicodeDammit library detects the encoding as wrong, as observed previously. This wrong guess happens mostly when the content is very short and there are similarities between the encodings. We can avoid these if we know the encoding of the HTML document upfront. We can pass the encoding to the BeautifulSoup constructor so that the excess time consumption and wrong guesses can be avoided. The encoding is specified as a part of the constructor in the from_encoding parameter. So in the previous case, we can specify the encoding as utf-8.
soup = BeautifulSoup(html_markup,"lxml",from_encoding="utf-8")
print(soup.prettify())
#output '
<html>
<body>
<p>
The Spanish language is written using the Spanish alphabet, which is the Latin alphabet with one additional letter, eñe ⟨ñ⟩, for a total of 27 letters.
</p>
</body>
</html>There are no longer gibberish characters because we have specified the correct encoding and we can verify this from the output.
The encoding that we pass should be correct, otherwise the character encoding will be wrong; for example, if we pass the encoding as latin-1 in the preceding HTML fragment, the result will be different.
soup = BeautifulSoup(html_markup,"lxml",from_encoding="latin-1") print(soup.prettify()) #output 'The Spanish language is written using the Spanish alphabet, which is the Latin alphabet with one additional letter, e単e (単), for a total of 27 letters.
So it is better to pass the encoding only if we are sure about the encoding used in the document.