
We saw how to install Beautiful Soup in Linux, Windows, and Mac OS X machines in Chapter 1, Installing Beautiful Soup.
Beautiful Soup is widely used for getting data from web pages. We can use Beautiful Soup to extract any data in an HTML/XML document, for example, to get all links in a page or to get text inside tags on the page. In order to achieve this, Beautiful Soup offers us different objects, and simple searching and navigation methods.
Any input HTML/XML document is converted to different Beautiful Soup objects, and based on the different properties and methods of these objects, we can extract the required data. The list of objects in Beautiful Soup includes the following:
BeautifulSoupTagNavigableString
Creating a BeautifulSoup object is the starting point of any Beautiful Soup project. A BeautifulSoup object represents the input HTML/XML document used for its creation.
BeautifulSoup is created by passing a string or a file-like object (this can be an open handle to the files stored locally in our machine or a web page).
A string can be passed to the BeautifulSoup constructor to create an object as follows:
helloworld = "<p>Hello World</p>" soup_string = BeautifulSoup(helloworld)
Tip
Downloading the example code
You can download the example code files for all Packt books you have purchased from your account at http://www.packtpub.com. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
The previous code will create the BeautifulSoup object based on the input string helloworld. We can see that the input has been treated as HTML and the content of the object can be verified by print(soup_string).
<html><body><p>Helloworld</p></body></html>
During the creation of the object, Beautiful Soup converts the input markup (HTML/XML) to a tree structure using the supported parsers. While doing so, the markup will be represented as different Beautiful Soup objects such as BeautifulSoup, Tag, and NavigableString.
A file-like object can also be passed to the BeautifulSoup constructor to create the object. This is useful in parsing an online web page, which is the most common use of Beautiful Soup.
For example, consider the case where we need to get a list of all the books published by Packt Publishing, which is available at http://www.packtpub.com/books. In order to reduce the overhead of visiting this URL from our browser to get the page content as String, it is appropriate to create the BeautifulSoup object by providing the file-like object of the URL.
import urllib2 from bs4 import BeautifulSoup url = "http://www.packtpub.com/books" page = urllib2.urlopen(url) soup_packtpage = BeautifulSoup(page)
In the previous Python script, we have used the urllib2 module, which is a native Python module, to open the http://www.packtpub.com/books page. The urllib2.urlopen() method returns a file-like object for the input URL. Then we create the BeautifulSoup object, soup_packtpage, by passing the file-like object.
We learned how to create a BeautifulSoup object by passing a file-like object for a URL in the previous example. Similarly, we can pass the file object for a local file to the BeautifulSoup constructor.
For this, create a local folder in your machine by executing the command mkdir Soup from a terminal. Create an HTML file, foo.html, in this folder using touch Soup/foo.html. From the same terminal, change to the directory just created using cd Soup.
Now let us see the creation of BeautifulSoup using the file foo.html.
with open("foo.html","r") as foo_file:
soup_foo = BeautifulSoup(foo_file)The previous lines of code create a BeautifulSoup object based on the contents of the local file, foo.html.
Beautiful Soup has a basic warning mechanism to notify whether we have passed a filename instead of the file object.
Let us look at the next code line:
soup_foo = BeautifulSoup("foo.html")This will produce the following warning:
UserWarning: "foo.html" looks like a filename, not markup. You should probably open this file and pass the filehandle into Beautiful Soup.
But still a BeautifulSoup object is created assuming the string ("foo.html") that we passed as HTML.
The print(soup_foo) code line will give the following output:
<html><body><p>foo.html</p></body></html>
The same warning mechanism also notifies us if we tried to pass in a URL instead of the URL file object.
soup_url = BeautifulSoup("http://www.packtpub.com/books")The previous line of code will produce the following warning:
UserWarning: "http://www.packtpub.com/books" looks like a URL. Beautiful Soup is not an HTTP client. You should probably use an HTTP client to get the document behind the URL, and feed that document to Beautiful Soup
Here also the BeautifulSoup object is created by considering the string (URL) as HTML.
print(soup_url)
The previous code will give the following output:
<html><body><p>http://www.packtpub.com/books</p></body></html>
So we should pass either the file handle or string to the BeautifulSoup constructor.
Beautiful Soup can also be used for XML parsing. While creating a BeautifulSoup object, the TreeBuilder class is selected by Beautiful Soup for the creation of HTML/XML tree. The TreeBuilder class is used for creating the HTML/XML tree from the input document. The default behavior is to select any of the HTML TreeBuilder objects, which use the default HTML parser, leading to the creation of the HTML tree. In the previous example, using the string helloworld, we can verify the content of the soup_string object, which shows that the input is treated as HTML by default.
soup_string = BeautifulSoup(helloworld) print(soup_string)
The output for the previous code snippet is as follows:
<html><body><p>Hello World</p></body></html>
If we want Beautiful Soup to consider the input to be parsed as XML instead, we need to explicitly specify this using the features argument in the BeautifulSoup constructor. By specifying the features argument, BeautifulSoup will be able to pick up the best suitable TreeBuilder that satisfies the features we requested.
The TreeBuilders class use an underlying parser for input processing. Each TreeBuilder will have a different set of features based on the parser it uses. So the input is treated differently based on the features argument being passed to the constructor. The parsers currently used by different TreeBuilders in Beautiful Soup are as follows:
lxmlhtml5libhtml.parser
The
features argument of the BeautifulSoup constructor can accept either a list of strings or a string value. The currently supported features by each TreeBuilder and the underlying parsers are described in the following table:
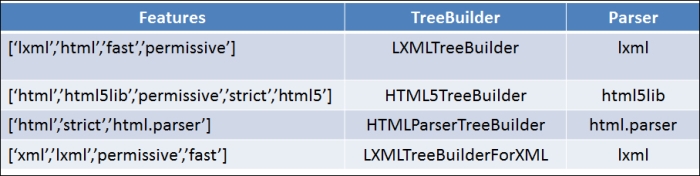
The features argument can be specified as a list of strings or a string value. Beautiful Soup picks the best suitable TreeBuilder, which has the feature(s) specified. The order of picking a Treebuilder in the case of an HTML document is based on the priority of the parsers upon which they are built. The first being lxml, followed by html5lib, and at last html.parser. For example, if we provide html as the feature, Beautiful Soup will pick lXmlTreeBuilder, if the lxml parser is available. If the lxml parser is not available, it picks HTML5TreeBuilder based on the html5lib parser, and if the html5lib parser is also not available, then HTMLPraserTreeBuilder is picked based on the html.parser. For XML, since lxml is the only available parser, LXMLTreeBuilderForXML is always selected.
We can specify the features argument in the BeautifulSoup constructor for considering the input for XML processing as follows:
soup_xml = BeautifulSoup(helloworld,features= "xml")
Another alternative is by using the following code line:
soup_xml = BeautifulSoup(helloworld,"xml")
In the previous code, we passed xml as the value for the features argument and created the soup_xml object. We can see that the same content ("<p>Helloworld</p>") is now being treated as XML instead of HTML.
print(soup_xml) #output <?xml version="1.0" encoding="utf-8"?> <p>Hello World</p>
In the previous example, Beautiful Soup has picked LXMLTreeBuilderForXML based on the lxml parser and parsed the input as XML.
By providing the features argument we are specifying the features that a TreeBuilder should have. In case Beautiful Soup is unable to find a TreeBuilder with the given features, an error is thrown. For example, assume that lxml, which is the only parser currently used by Beautiful Soup for XML processing, is not present in the system. In this case, if we use the following line of code:
soup_xml = BeautifulSoup(helloworld,features= "xml")
The previous code will fail and throw the following error (since lxml is not installed in the system):
bs4.FeatureNotFound: Couldn't find a tree builder with the features you requested: xml. Do you need to install a parser library?
In this case, we should install the required parsers using easy_install, pip, or setup.py install.
It is always a better practice to specify the parser to be used while creating a BeautifulSoup object. This is due to the fact that different parsers parse the content differently. This is more evident in cases where we give invalid HTML content to parse. The three parsers discussed previously produce three types of HTML trees in the case of an invalid HTML. For example:
invalid_html = '<a invalid content'
Here the HTML is invalid since there is no closing </a> tag. The processing of this invalid HTML using the previously mentioned parsers is given as follows:
- By using the
lxmlparser, which is shown as follows:soup_invalid_html = BeautifulSoup(invalid_html,'lxml')
The
print(soup_invalid_html)code line will give the HTML tree produced using thelxmlparser.<html><body><a invalid content=""></a></body></html>
From the output, it is clear that the
lxmlparser has processed the invalid HTML. It added the closing</a>tag and also considered the invalid content as an attribute of the<a>tag. Apart from this, it has also added the<html>and<body>tags, which was not present in the input. Addition of the<html>and<body>tags will be done by default if we uselxml. - By using the
html5libparser, which is shown as follows:soup_invalid_html = BeautifulSoup(invalid_html,'html5lib')
The
print(soup_invalid_html)code line will show us the HTML tree produced using thehtml5libparser.<html><head></head><body></body></html>
From the output, it is clear that the
html5libparser has added the<html>,<head>, and<body>tags, which was not present in the input. For example, thelxmlparser and thehtml5libparser will also add these tags for any input. But at the same time, it has discarded the invalid<a>tag to produce a different representation of the input. - By using the
html.parser, which is shown as follows:soup_invalid_html = BeautifulSoup(invalid_html,'html.parser')
The
print(soup_invalid_html)code line will show us the HTML tree produced using thehtml.parser.The
html.parserhas discarded the invalid HTML and produced an empty tree. Unlike the other parsers, it doesn't add any of the<html>,<head>, or<body>tags.
So, it is good to specify the parser by giving the features argument because this helps to ensure that the input is processed in the same manner across different machines. Otherwise, there is a possibility that the same code will break in one of the machines if some invalid HTML is present, as the default parser that is picked up by Beautiful Soup will produce a different tree. Specifying the features argument helps to ensure that the tree generated is identical across all machines.
While creating the BeautifulSoup object, other objects are also created, which include the following:
TagNavigableString