
There are different ways of selecting models with the right complexity so that the prediction error on unseen data is less. Let's discuss each of these approaches in the context of the linear regression model.
In the subset selection approach, one selects only a subset of the whole set of variables, which are significant, for the model. This not only increases the prediction accuracy of the model by decreasing model variance, but it is also useful from the interpretation point of view. There are different ways of doing subset selection, but the following two are the most commonly used approaches:
- Forward selection: In forward selection, one starts with no variables (intercept alone), and by using a greedy algorithm, adds other variables one by one. For each step, the variable that most improves the fit is chosen to add to the model.
- Backward selection: In backward selection, one starts with the full model and sequentially deletes the variable that has the least impact on the fit. At each step, the variable with the least Z-score is selected for elimination. In statistics, the Z-score of a random variable is a measure of the standard deviation between an element and its mean. A small value of Z-score (typically < 2) indicates that the effect of the variable is more likely by chance and is not statistically significant.
In this approach, one adds a penalty term to the loss function that does not allow the size of the parameter to become very large during minimization. There are two main ways of doing this:
- Ridge regression: This simple type of regularization is where the additional term is proportional to the magnitude of the parameter vector given by
 . The loss function for linear regression with the regularization term can be written as follows:
Parameters
. The loss function for linear regression with the regularization term can be written as follows:
Parameters
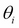 having a large magnitude will contribute more to the loss. Hence, minimization of the preceding loss function will typically produce parameters having small values and reduce the overfit. The optimum value of
having a large magnitude will contribute more to the loss. Hence, minimization of the preceding loss function will typically produce parameters having small values and reduce the overfit. The optimum value of 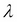 is found from the validation set.
is found from the validation set.
- Lasso: In Lasso also, one adds a penalty term similar to ridge regression, but the term is proportional to the sum of modulus of each parameter and not its square:

Though this looks like a simple change, Lasso has some very important differences with respect to ridge regression. First of all, the presence of the
 term makes the loss function nonlinear in parameters
term makes the loss function nonlinear in parameters  . The corresponding minimization problem is called the quadratic programming problem compared to the linear programming problem in ridge regression, for which a closed form solution is available. Due to the particular form of the penalty, when the coefficients shrink as a result of minimization, some of them eventually become zero. So, Lasso is also in some sense a subset selection problem.
. The corresponding minimization problem is called the quadratic programming problem compared to the linear programming problem in ridge regression, for which a closed form solution is available. Due to the particular form of the penalty, when the coefficients shrink as a result of minimization, some of them eventually become zero. So, Lasso is also in some sense a subset selection problem.
A detailed discussion of various subset selection and model regularization approaches can be found in the book by Trevor Hastie et.al (reference 1 in the References section of this chapter).