
Once the feature sets get finalized in our last section, what follows is the estimation of parameters of the selected models, for which we will use MLlib. As earlier, we need to arrange distributed computing, especially for this case with various cars for various customer segments.
As MLlib is a built-in package for Apache Spark, the computation is a straightforward process for which the readers may consult Chapter 1, Spark for Machine Learning
One of the main reasons for our client utilizing Apache Spark is to take advantage of its computation speed and the ease of implementing parallel computing. For this project, as we need to build models for more than 40 products and many customer segments, we will perform machine learning only against segments by age.
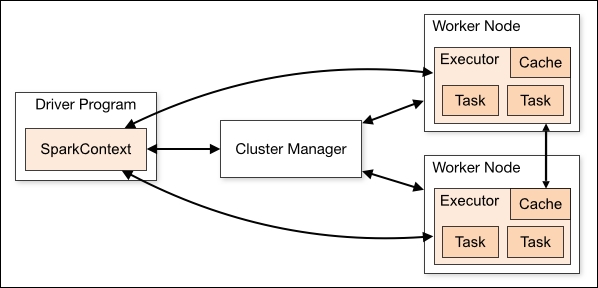
For updated information about implementing parallel computing with Spark and especially about submitting and monitoring application jobs, users should always consult Apache Spark's updated and detailed guidelines at http://spark.apache.org/docs/latest/cluster-overview.html.
With MLlib for random forest, we use the following code:
// Train a RandomForest model.
val treeStrategy = Strategy.defaultStrategy("Classification")
val numTrees = 300
val featureSubsetStrategy = "auto" // Let the algorithm choose.
val model = RandomForest.trainClassifier(trainingData,
treeStrategy, numTrees, featureSubsetStrategy, seed = 12345)For decision tree, we use the following code:
val categoricalFeaturesInfo = Map[Int, Int]() val impurity = "variance" val maxDepth = 5 val maxBins = 64 # larger = higher accuracy val model = DecisionTree.trainClassifier(trainingData, numClasses, categoricalFeaturesInfo, impurity, maxDepth, maxBins)
In MLlib for linear regression, we will use:
val numIterations = 90 val model = LinearRegressionWithSGD.train(TrainingData, numIterations)
For logistic regression, we will use:
val model = new LogisticRegressionWithSGD() .setNumClasses(2)