
This class of algorithms aims to predict the unknown labels splitting the dataset, by generating a set of simple rules that are learnt from the features values. For example, consider a case of deciding whether to take an umbrella today or not based on the values of humidity, wind, temperature, and pressure. This is a classification problem, and an example of the decision tree can be like what is shown in the following figure based on data of 100 days. Here is a sample table:
|
Humidity (%) |
Pressure (mbar) |
Wind (Km/h) |
Temperature (C) |
Umbrella |
|---|---|---|---|---|
|
56 |
1,021 |
5 |
21 |
Yes |
|
65 |
1,018 |
3 |
18 |
No |
|
80 |
1,020 |
10 |
17 |
No |
|
81 |
1,015 |
11 |
20 |
Yes |

Decision tree for predicting whether to bring an umbrella or not based on a record of 100 days.
In the preceding figure the numbers in squares represent the days on which an umbrella has been brought, while the circled numbers indicate days in which an umbrella was not necessary.
The decision tree presents two types of nodes: decision nodes, which have two (or more) branches when a decision split is applied; and leaf nodes, when data is classified. The stopping criterion is usually a maximum number of decision nodes (depth of the tree) or a minimum of data points to continue to split (typically around 2 to 5). The problem of decision trees learning is to build the best tree out of all the possible node combinations, that is, estimate the hierarchy of the rules to be applied (in other words, whether the first decision node should be on humidity or on temperature, and so on). More formally, given a training set of ![]() with x(i) in Rm and corresponding labels yi, we need to find the best rule to partition the data S at node k. If the chosen feature, j, is continuous, each split rule is given by a feature j and a threshold tjk that splits S in
with x(i) in Rm and corresponding labels yi, we need to find the best rule to partition the data S at node k. If the chosen feature, j, is continuous, each split rule is given by a feature j and a threshold tjk that splits S in ![]() for
for ![]() and
and ![]() for
for ![]() ,
, ![]() . The best split rule
. The best split rule ![]() for the node k is associated with the minimum of the impurity I function that measures how much the rule is able to separate the data into partitions with different labels (that is, each branch will contain the minimum amount of label mixing):
for the node k is associated with the minimum of the impurity I function that measures how much the rule is able to separate the data into partitions with different labels (that is, each branch will contain the minimum amount of label mixing):

Here, ![]() are the numbers of data points on the left and right branches, respectively. Nk is the number of data points on node k, and H is a measure that can assume different expressions using the probability of each target value l at branch b (b can be left or right),
are the numbers of data points on the left and right branches, respectively. Nk is the number of data points on node k, and H is a measure that can assume different expressions using the probability of each target value l at branch b (b can be left or right),  :
:
- Entropy of the branch:

- Gini impurity of the branch:

-
Misclassification:

-
Mean squared error (variance):
 (where
(where 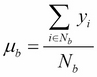 )
)
-
Mean squared error (variance):
Note that the latter is typically used in regression problems while the others are employed in classification. Note also that usually in literature, the information gain definition is introduced as the difference between H at node k and ![]()
![]() where
where 
If the feature j is discrete with d number of possible values, there is no binary threshold tjk to calculate and the data is split into d partitions. The measure H is calculated over d subsets.
For example, we can determine the rule for the first node (k=0) for the preceding example using the entropy as the impurity measure H.
All the features are continuous, so the values of tj0 are needed. Assuming that j=0 is the humidity and sorting in increasing order, the possible humidity values in the dataset we have are as follows:
|
h |
0 |
1 |
…. |
98 |
99 | |||||
|
umbrella |
yes |
no |
…. |
no |
no | |||||
|
humidity |
58 |
62 |
…. |
88 |
89 | |||||
|
< |
>= |
< |
>= |
< |
>= |
< |
>= |
< |
>= | |
|
yes |
0 |
11 |
14 |
32 |
7 |
20 |
29 |
12 |
78 |
0 |
|
no |
0 |
89 |
21 |
33 |
13 |
60 |
10 |
49 |
22 |
0 |
|
|
0.5 |
0.99 |
0.85 |
0.76 |
0.76 | |||||
So, the threshold value for the humidity feature is ![]() = 58; and in the same way, we can calculate the threshold values for temperature t10, wind t20, and pressure t30. Now we can record to determine the best rule for the first node, computing the impurity for each of the four features:
= 58; and in the same way, we can calculate the threshold values for temperature t10, wind t20, and pressure t30. Now we can record to determine the best rule for the first node, computing the impurity for each of the four features:
|
yes |
umbrella |
yes no |
umbrella | ||||
|
no | |||||||
|
Humidity j=0 |
|
0 |
0 |
Temperature j=1 |
|
21 |
32 |
|
|
11 |
89 |
|
11 |
36 | ||
|
Impurity: |
Impurity: | ||||||
|
yes |
umbrella |
yes no |
umbrella | ||||
|
no | |||||||
|
Wind j=2 |
|
48 |
5 |
Pressure j=3 |
|
39 |
3 |
|
|
1 |
46 |
|
45 |
13 | ||
|
Impurity: |
Impurity: | ||||||
Therefore, for node 0, the best rule is given by:
That is, the wind feature with threshold t20. We can repeat the same procedure to find the best rule for the following decision nodes until the end of the tree.
Decision trees learning is able to handle large datasets, though it tends not to generalize well, especially with a large set of features (N≈M). In such cases, it is advisable to set a small depth of the tree or use some dimensionality reduction techniques. Setting the minimum number of data points to split or the minimum number of data points in a leaf node will also help prevent overfitting. This algorithm may lead to over-complex trees; they can be pruned to reduce the branches that do not affect the quality of the prediction. Various pruning techniques are available, but they are beyond the scope of this book. Note also that a series of decision trees can be trained at the same time, composing of a so-called random forest. A random forest trains each tree with a random sample of the original data points, and a random subset of features is available for each decision node learning. The result is an average of the predictions in a regression problem or the majority in a classification problem.