
Web data mining techniques are used to explore the data available online and then extract the relevant information from the Internet. Searching on the web is a complex process that requires different algorithms, and they will be the main focus of this chapter. Given a search query, the relevant pages are obtained using the data available on each web page, which is usually divided in the page content and the page hyperlinks to other pages. Usually, a search engine has multiple components:
- A web crawler or spider for collecting web pages
- A parser that extracts content and preprocesses web pages
- An indexer to organize the web pages in data structures
- A retrieval information system to score the most important documents related to a query
- A ranking algorithm to order the web pages in a meaningful manner
These parts can be divided into web structure mining techniques and web content mining techniques.
The web crawler, indexer, and ranking procedures refer to the web structure (the network of hyperlinks). The other parts (parser and retrieval system) of a search engine are web content analysis methods because the text information on web pages is used to perform such operations.
Furthermore, the content of a collection of web pages can be further analyzed using some natural language processing techniques, such as latent Dirichlet allocation opinion mining or sentiment analysis tools. These techniques are especially important for extracting subjective information about web users, and so they are widely found in many commercial applications, from marketing to consultancy. These sentiment analysis techniques will be discussed at the end of the chapter. Now we will start discussing the web structure mining category.
This field of web mining focuses on the discovery of the relationships among web pages and how to use this link structure to find the relevance of web pages. For the first task, usually a spider is employed, and the links and the collected web pages are stored in a indexer. For the the last task, the web page ranking evaluates the importance of the web pages.
A spider starts from a set of URLs (seed pages) and then extracts the URL inside them to fetch more pages. New links are then extracted from the new pages and the process continues until some criteria are matched. The unvisited URLs are stored in a list called frontier, and depending on how the list is used, we can have different crawler algorithms, such as breadth-first and preferential spiders. In the breadth-first algorithm, the next URL to crawl comes from the head of the frontier while the new URLs are appended to the frontier tail. Preferential spider instead employs a certain importance estimate on the list of unvisited URLs to determine which page to crawl first. Note that the extraction of links from a page is performed using a parser, and this operation is discussed in more detail in the related paragraph of the web content mining section.
A web crawler is essentially a graph search algorithm in which the structure of the neighborhood of the starting pages is retrieved, following certain criteria such as the maximum number of links to follow (depth of the graph), maximum number of pages to crawl, or time limit. A spider can then extract a portion of the Web that has interesting structures, such as hubs and authorities. A hub is a web page that contains a large number of links, while an authority is defined as, a page, with a large number of times that its URL occurs on other web pages (it is a measure of the page's popularity). A popular Python implementation of the crawler is given by the Scrapy library, which also employs concurrency methods (asynchronous programming using Twisted) to speed up operations. A tutorial on this module is given in Chapter 7, Movie Recommendation System Web Application when the crawler will be used to extract information about movie reviews.
An indexer is a way to store web pages found by the crawler in a structured database to allow subsequent fast retrieval on a given search query. The simplest indexing approach is to directly store all the pages and, at query time, just scan for all the documents that contain the keywords in the query. However, this method is not feasible if the number of pages is large (which in practice, it is) due to high computational costs. The most common method to speed up the retrieval is called inverted index scheme, which is used by the most popular search engines.
Given a set of web pages p1, …, pk and a vocabulary V containing all the words ![]() in the pages, the inverted index database is obtained by storing lists such as
in the pages, the inverted index database is obtained by storing lists such as ![]() , …,
, …, ![]() ,
,
Here, ![]() is the ID of the web page j. Extra information can be stored for each word, for example, the frequency count of the word or its position on each page. The implementation of the indexer is beyond the scope of this book, but the general concepts have been described in this paragraph for completeness.
is the ID of the web page j. Extra information can be stored for each word, for example, the frequency count of the word or its position on each page. The implementation of the indexer is beyond the scope of this book, but the general concepts have been described in this paragraph for completeness.
Therefore, a search query with a list of words will retrieve all the inverted lists related to each word and then merge the lists. The order of the final lists will be chosen using the ranking algorithm together with an information retrieval system to measure the relevance of the documents to the query.
A ranking algorithm is important because the usual number of web pages that a single information retrieval query can return may be huge, so there is a problem of how to choose the most relevant pages. Furthermore, the information retrieval model can easily be spammed by just inserting many keywords into the page to make the page relevant to a large number of queries. So, the problem to evaluate the importance (that is, ranking score) of a web page on the Internet has been addressed considering the fact that the web has a graph in which the hyperlinks—links from a page to another—are the primary source of information to estimate the relevance of web pages. The hyperlinks can be divided as:
- in-links of page i: hyperlinks that point to page i
- out-links of page i: hyperlinks that point to other pages from page i
Intuitively, the more in-links a web page has, the more important the page should be. The study of this hyperlink structure is part of social network analysis, and many algorithms have been used and proposed. But for historical reasons, we will explain the most well known algorithm, called PageRank, which was presented by Sergey Brin and Larry Page (the founders of Google) in 1998. The whole idea is to calculate the prestige of a page as the sum of the prestiges of the pages that point to it. If the prestige of a page j is P(j) it is equally distributed to all the pages Nj that it points to so that each out-link receives a portion of prestige equal to P(j)|Nj. Formally, the prestige or page rank score of a page i can be defined as:
Here,  if page j points to page i; otherwise it is equal to 0. Aij is called adjacency matrix and it represents the portion of prestige that propagates from node j to node i. Considering N total nodes in the graph, the preceding equation can be rewritten in matrix form:
if page j points to page i; otherwise it is equal to 0. Aij is called adjacency matrix and it represents the portion of prestige that propagates from node j to node i. Considering N total nodes in the graph, the preceding equation can be rewritten in matrix form:
Note that this equation is equivalent to an eigensystem with eigenvalue ![]() if the adjacency matrix satisfies certain conditions. Another way to interpret the preceding equation is to use the Markov chain terminology—the entry Aij becomes the transition probability from node j to node i and the prestige of node i, p(i), is the probability to visit node i. In this scenario, it may happen that two nodes (or more) point to each other but do not point to other pages. Once one of these two nodes has been visited, a loop will occur and the user will be trapped in it. This situation is called
rank sink, (the matrix A is called
periodic) and the solution is to add a transition matrix term that allows jumping from each page to another page at random without following the Markov chain described by A:
if the adjacency matrix satisfies certain conditions. Another way to interpret the preceding equation is to use the Markov chain terminology—the entry Aij becomes the transition probability from node j to node i and the prestige of node i, p(i), is the probability to visit node i. In this scenario, it may happen that two nodes (or more) point to each other but do not point to other pages. Once one of these two nodes has been visited, a loop will occur and the user will be trapped in it. This situation is called
rank sink, (the matrix A is called
periodic) and the solution is to add a transition matrix term that allows jumping from each page to another page at random without following the Markov chain described by A:

Here, E=eeT is a matrix of one entry of dimensions N´N (e is a unit vector), and d (also called the damping factor) is the probability to follow the transition given by the transition matrix A. (1-d) is the probability to visit a page randomly. In this final form, all the nodes are linked to each other so that even if the adjacency matrix has a row with many 0 entries for a particular node s, Asj, there is always a small probability equal to ![]() that s is visited from all the N nodes in the graph. Note that A has to be stochastic, which means each row has to sum to 1;
that s is visited from all the N nodes in the graph. Note that A has to be stochastic, which means each row has to sum to 1; ![]() (at least one entry per row different from 0 or at least one out-link per page). The equation can be simplified by normalizing the P vector as eT P=N:
(at least one entry per row different from 0 or at least one out-link per page). The equation can be simplified by normalizing the P vector as eT P=N:
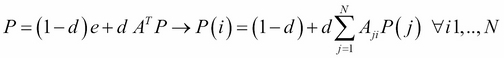
This can be solved using the power iteration method. This algorithm will be used in Chapter 8, Sentiment Analyser Application on Movie Reviews to implement an example of a movie review sentiment analysis system. The main advantages of this algorithm is that it does not depend on the query (so the PageRank scores can be computed offline and retrieved at query time), and it is very robust to spamming since it is not feasible for a spammer to insert in-links to their page on influential pages.