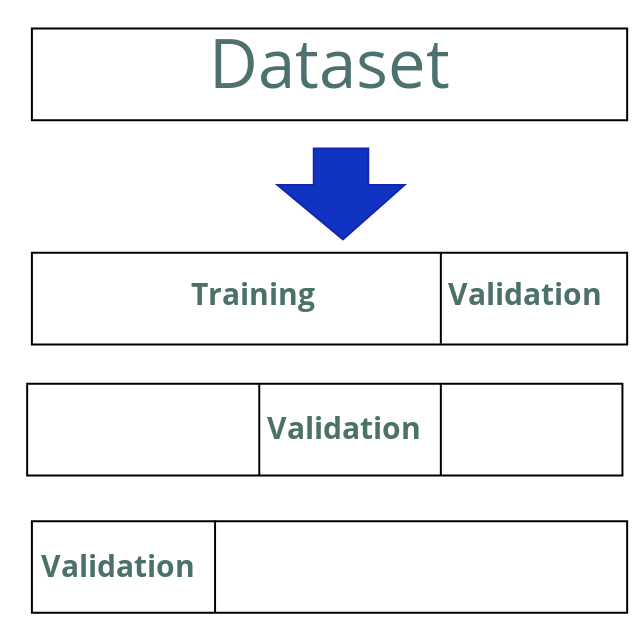
The most well-known method of cross-validation is K-fold cross-validation. The idea is to divide the dataset into K blocks of the same size. Then, we use one of the blocks for validation and the others for training. We repeat this process K times, each time choosing a different block for validation, and in the end, we average all the results. The data splitting scheme during the whole cross-validation cycle looks like this:
- Divide the dataset into K blocks of the same size.
- Select one of the blocks for validation and the remaining ones for training.
- Repeat this process, making sure that each block is used for validation and the rest are used for training.
- Average the results of the performance metrics that were calculated for the validation sets on each iteration.
The following diagram shows the cross-validation cycle: