
The GMM algorithm assumes that clusters can be fit to some Gaussian (normal) distributions; it uses the EM approach for training. There is a CGMM class in the Shogun library that implements this algorithm, as illustrated in the following code snippet:
Some<CDenseFeatures<DataType>> features;
int num_clusters = 2;
...
auto gmm = some<CGMM>(num_clusters);
gmm->set_features(features);
gmm->train_em();
Notice that the constructor of the CGMM class takes the desired number of clusters as an argument. After CGMM object initialization, we pass training features and use the EM method for training. The following piece of code shows these steps and also plots the results of clustering:
Clusters clusters;
auto feature_matrix = features->get_feature_matrix();
for (index_t i = 0; i < features->get_num_vectors(); ++i) {
auto vector = feature_matrix.get_column(i);
auto log_likelihoods = gmm->cluster(vector);
auto max_el = std::max_element(log_likelihoods.begin(),
std::prev(log_likelihoods.end()));
auto label_idx = std::distance(log_likelihoods.begin(), max_el);
clusters[label_idx].first.push_back(vector[0]);
clusters[label_idx].second.push_back(vector[1]);
}
PlotClusters(clusters, "GMM", name + "-gmm.png");
We used the CGMM::cluster() method to identify which cluster our objects belong to. This method returns a vector of probabilities. Then, we searched for the vector's element with the maximum probability value and took its index as the number of the cluster.
The resulting cluster indices were used as an argument for the PlotClusters() function, which visualized the clustering result, as illustrated in the following screenshot:
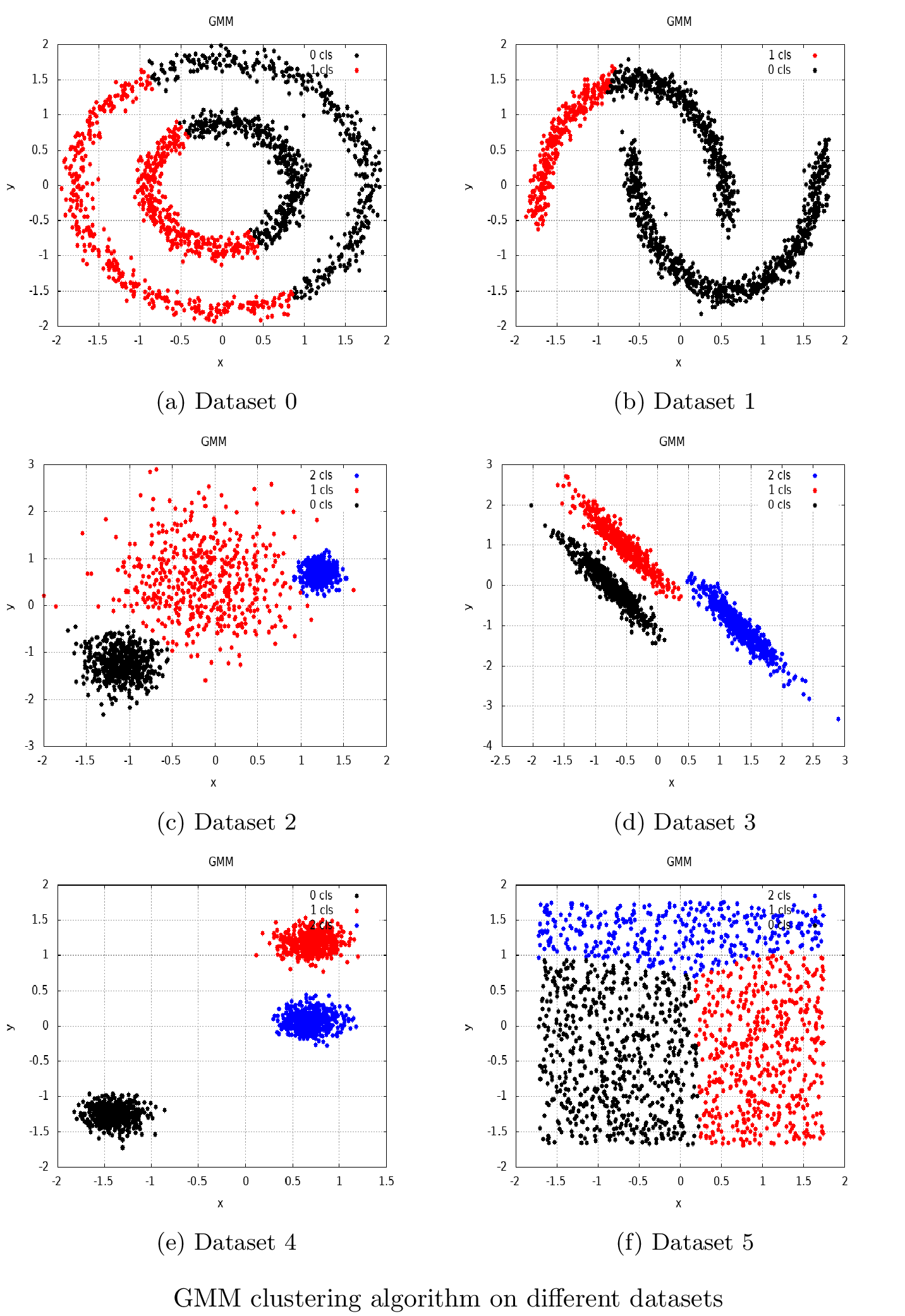
In the preceding screenshot, we can see how the GMM algorithm works on different artificial datasets.