
The Shark-ML library implements the hierarchical clustering approach in the following way: first, we need to put our data into a space-partitioning tree. For example, we can use the object of the LCTree class, which implements binary space partitioning. Also, there is the KHCTree class, which implements kernel-induced feature space partitioning. The constructor of this class takes the data for partitioning and an object that implements some stopping criteria for the tree construction. We use the TreeConstruction object, which we configure with the maximal depth of the tree and the maximum number of objects in the tree node. The LCTree class assumes the existence of a Euclidean distance function for the feature type used in the dataset. The code can be seen in the following block:
UnlabeledData<RealVector>& features;
int num_clusters = 2;
...
LCTree<RealVector> tree(features,
TreeConstruction(0, features.numberOfElements() / num_clusters));
Having constructed the partitioning tree, we initialize an object of the HierarchicalClustering class with the tree object as an argument. The HierarchicalClustering class implements the actual clustering algorithm. There are two strategies to get clustering results—namely, hard and soft. In the hard clustering strategy, each object is assigned to one cluster. However, in the soft strategy, each object is assigned to all clusters, but with a specific probability or likelihood value. In the following example, we use the object of the HardClusteringModel class to assign objects to distinct clusters. Objects of the HardClusteringModel class override the function operator, so you can use them as functors for evaluation. The code can be seen in the following snippet:
HierarchicalClustering<RealVector> clustering(&tree);
HardClusteringModel<RealVector> model(&clustering);
Data<unsigned> clusters = model(features);
The clustering result is a container with cluster indices for each element in the dataset, as shown in the following code snippet:
for (std::size_t i = 0; i != features.numberOfElements(); i++) {
auto cluster_idx = clusters.element(i);
auto element = features.element(i);
...
}
We iterated over all items in the features container and got a cluster index for each item to visualize our clustering result. This index was used to assign a distinct color for every item, as illustrated in the following screenshot:
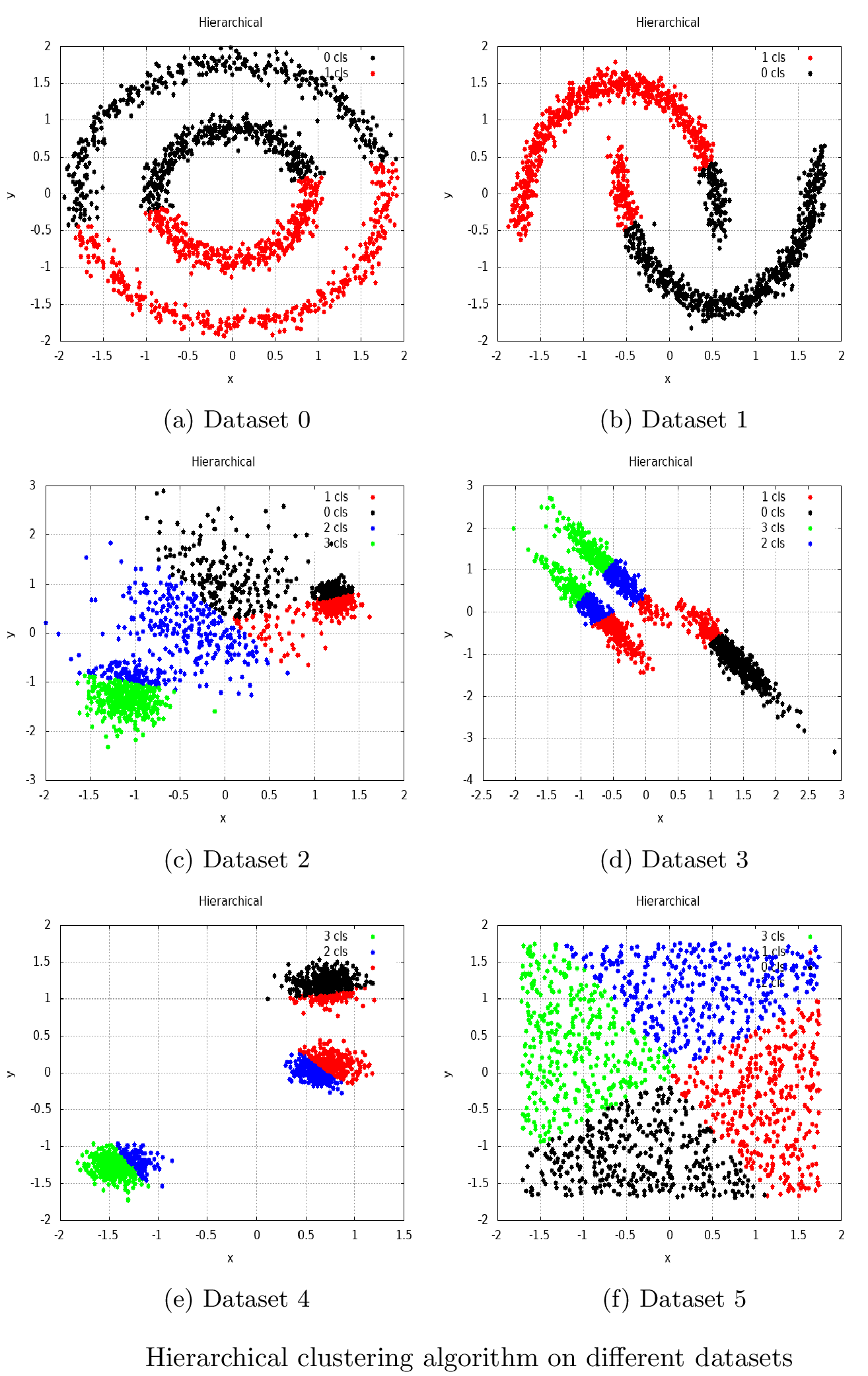
In the preceding screenshot, we can see how the hierarchical clustering algorithm implemented in the Shark-ML library works on different artificial datasets.