
The Shark-ML library implements the k-means algorithm in the kMeans() function, which takes three parameters: the training dataset, the desired number of clusters, and the output parameter for cluster centroids. The following code sample shows how to use this function:
UnlabeledData<RealVector> features;
int num_clusters = 2;
...
Centroids centroids;
kMeans(features, num_clusters, centroids);
After we get the centroids, we can initialize an object of the HardClusteringModel class. As in the previous example, we can use this object for the evaluation of the trained model on new data or the training data, as follows:
HardClusteringModel<RealVector> model(¢roids);
Data<unsigned> clusters = model(features);
for (std::size_t i = 0; i != features.numberOfElements(); i++) {
auto cluster_idx = clusters.element(i);
auto element = features.element(i);
...
}
After, we used the model object as a functor to perform clustering. The result was a container with cluster indices for each element of the input dataset. Then, we used these cluster indices to visualize the final result, as illustrated in the following screenshot:
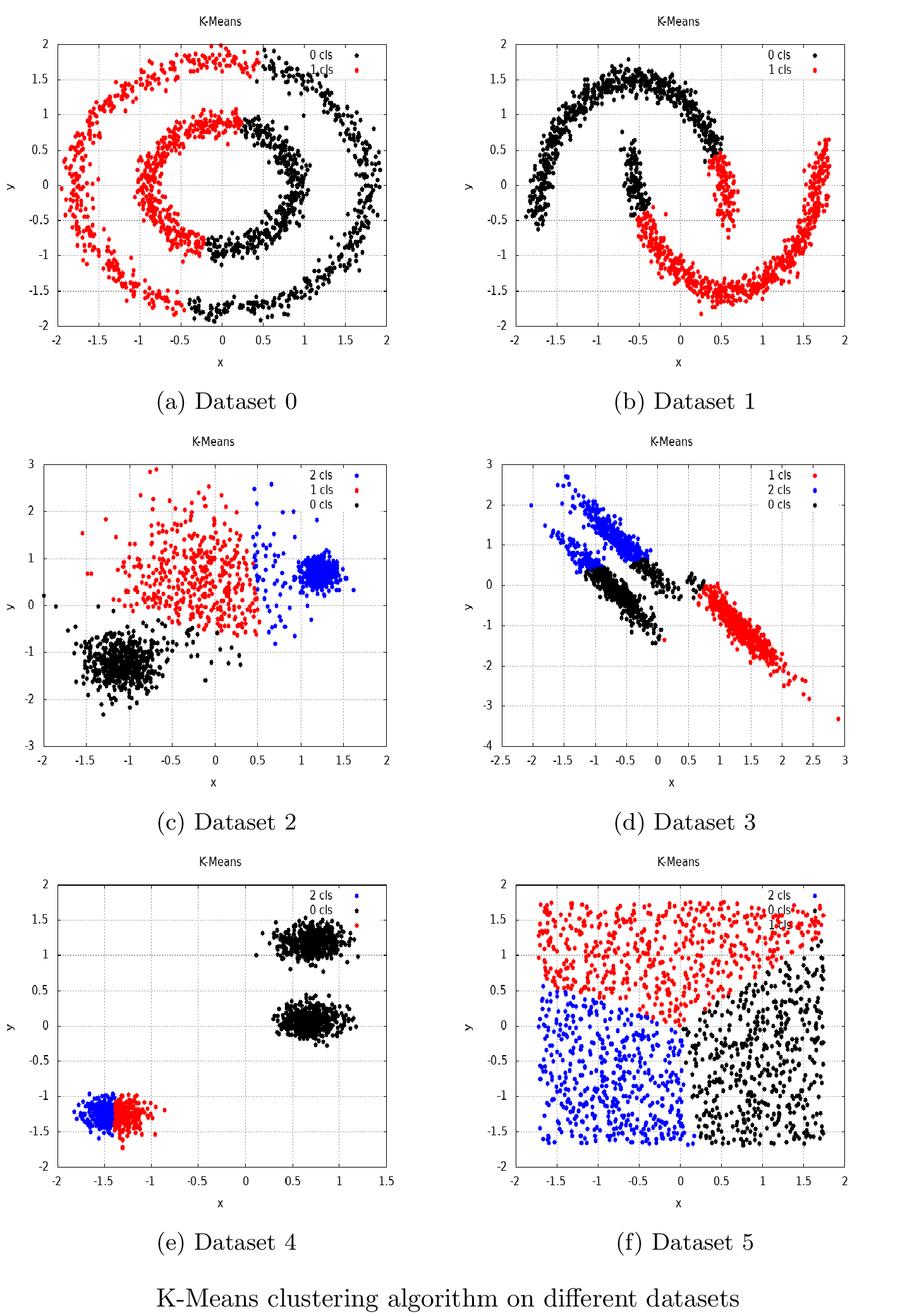
In the preceding screenshot, we can see how the k-means clustering algorithm implemented in the Shark-ML library works on different artificial datasets.