
Notice that the Word2Vec algorithm only takes the local context of words into account. It doesn't use global statistics throughout the training corpus. For example, the words the and cat will often be used together, but Word2Vec is unable to determine whether the word the is a standard article or whether the words the and cat have a strong implicit connection. This problem leads to the idea of using global statistics.
For example, latent semantic analysis (LSA) calculates the embeddings for words by factorizing the term-document matrix using singular decomposition. However, even though this method takes advantage of global information, the obtained vectors do not show the same generalization properties as those obtained using Word2Vec. For example, vectors obtained using Word2Vec have such a generalizing property that, by using arithmetic operations, you can generate the following kind of result: king - man + woman = queen.
There is also another popular algorithm called GloVe. GloVe aims to achieve two goals:
- Create word vectors that capture meaning in the vector space
- Take advantage of global statistics, not just use local information
Unlike Word2Vec, which is trained using a sentence's flow, GloVe is trained based on a co-occurrence matrix and trains word vectors so that their difference predicts co-occurrence ratios.
First, we need to build a co-occurrence matrix. It is possible to calculate the co-occurrence matrix using a fixed-size window to make GloVe also take into account the local context. For example, the sentence The cat sat on the mat, with a window size of 2, can be converted into the following co-occurrence matrix:
|
the |
cat |
sat |
on |
mat |
|
the |
2 |
1 |
1 |
1 |
|
cat |
1 |
1 |
1 |
0 |
|
sat |
2 |
1 |
1 |
0 |
|
on |
1 |
1 |
1 |
1 |
|
mat |
1 |
0 |
1 |
1 |
Notice that the matrix is symmetrical because when the word cat appears in the context of the word sat, the opposite happens too.
To connect the vectors with the statistics we calculated previously, we can formulate the following principle: the coincidental relationship between two words, in terms of context, are closely related to their meaning. For example, consider the words ice and steam. Ice and steam differ in their state but are similar in that they are forms of water. Therefore, we can expect that water-related words (such as moisture and wet) will be displayed equally in the context of the words ice and steam. In contrast, words such as cold and solid are likely to appear next to the word ice, but not the word steam.
Let's denote the co-occurrence matrix as X. In this case 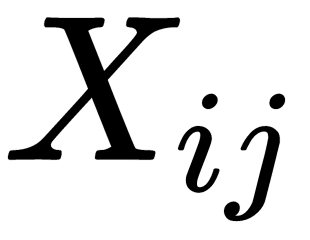 refers to the elements i and j, in X, which is equal to the number of times the word j appears in the context of the word
refers to the elements i and j, in X, which is equal to the number of times the word j appears in the context of the word 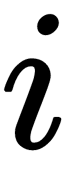 . We can also define
. We can also define 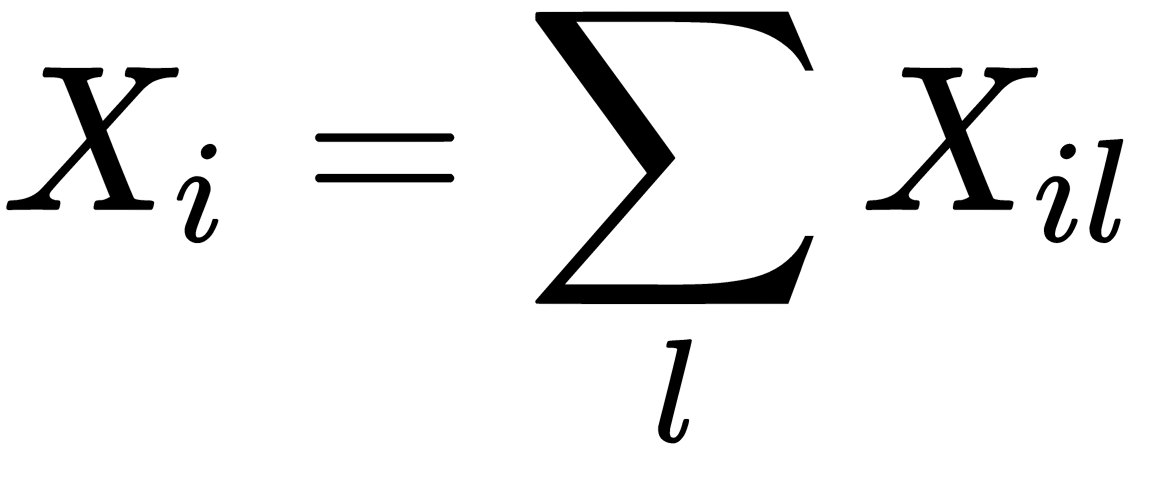 as the total number of words that appeared in the context of the word i.
as the total number of words that appeared in the context of the word i.
Next, we need to generate an expression to estimate co-occurrence ratios using word vectors. To do this, we start with the following relationship:
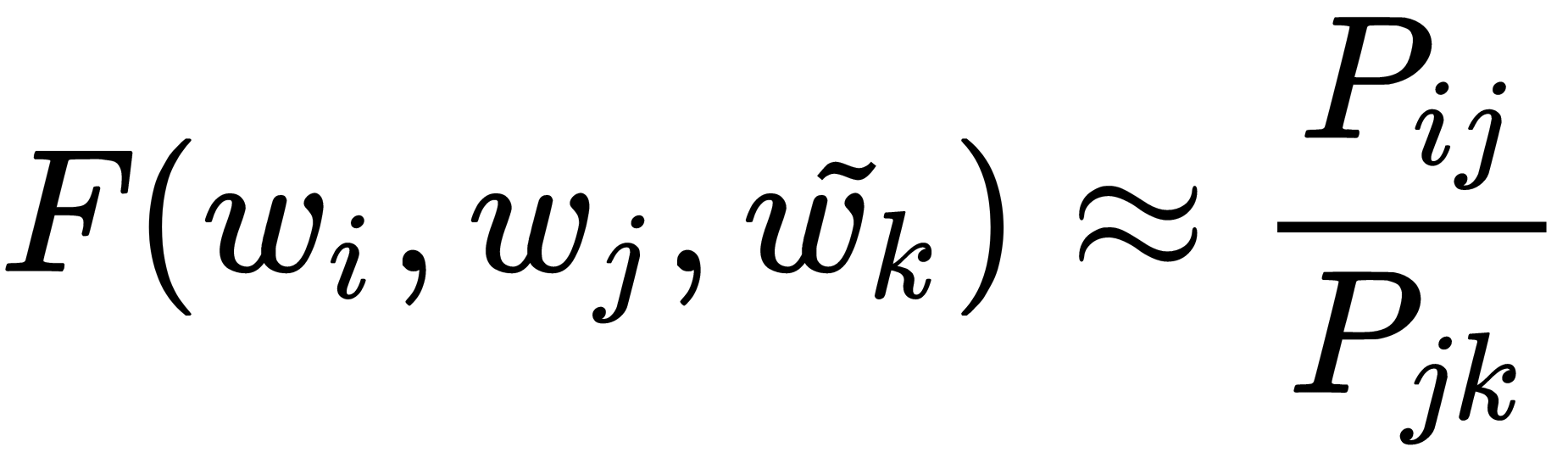
Here, 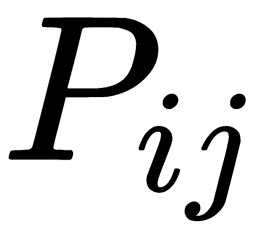 denotes the probability of the appearance of the word j in the context of the word i, which can be expressed as follows:
denotes the probability of the appearance of the word j in the context of the word i, which can be expressed as follows:
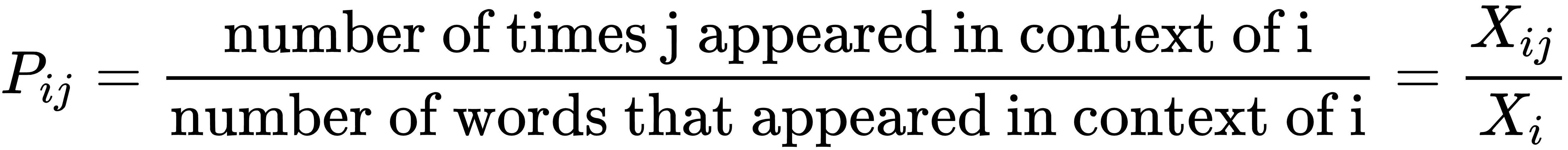
F is an unknown function, which takes embeddings for the words i, k, and j. Note that there are two kinds of embedding: input for context and output for the target word (expressed as  and
and  , respectively). These two kinds of embeddings are a minor detail, but nonetheless important to remember.
, respectively). These two kinds of embeddings are a minor detail, but nonetheless important to remember.
Now, the question is, how do we generate the function, F? As you may recall, one of the goals of GloVe was to create vectors with values that have a good generalizing ability, which can be expressed using simple arithmetic operations (such as addition and subtraction). We must choose F so that the vectors that we get when using this function match this property.
Since we want the use of arithmetic operations between vectors to be meaningful, we have to make the input for the function, F, the result of an arithmetic operation between vectors. The easiest way to do this is to apply F to the difference between the vectors we are comparing, as follows:
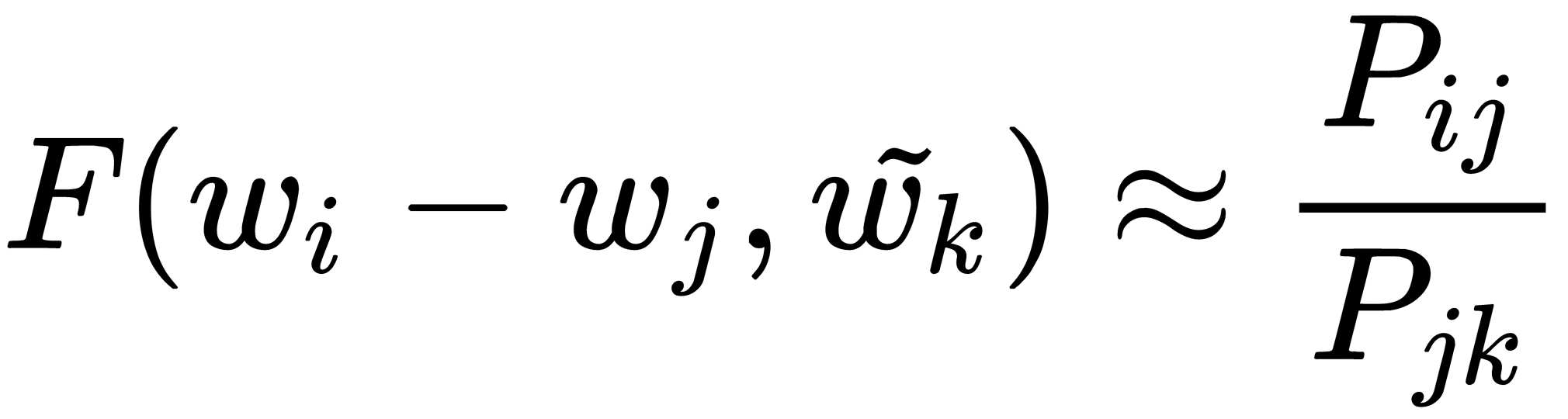
To specify a linear relationship between 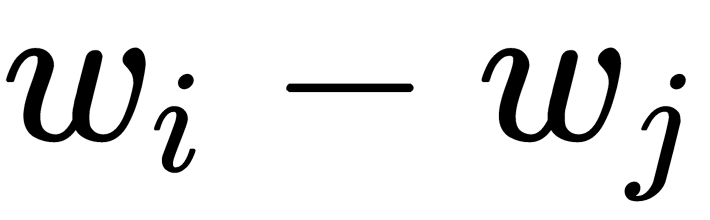 and
and 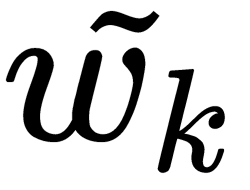 , we use the dot-product operation:
, we use the dot-product operation:
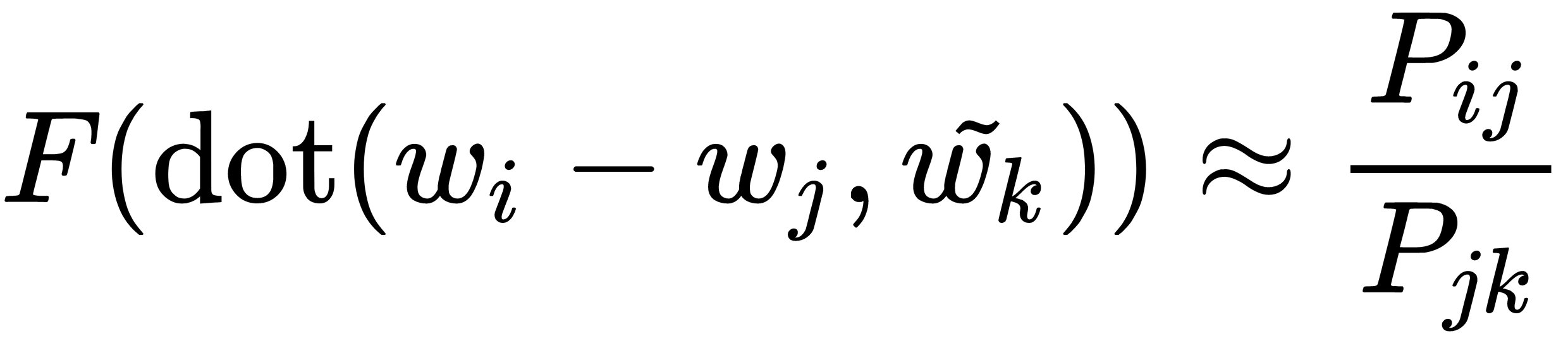
Now, to simplify the expression and evaluate the function, F, we use the following approach.
First, we can take the logarithm of the probabilities ratio to convert the ratio into the difference between the probabilities. Then, we can express the fact that some words are more common than others by adding an offset term for each word.
Given these considerations, we obtain the following equation:
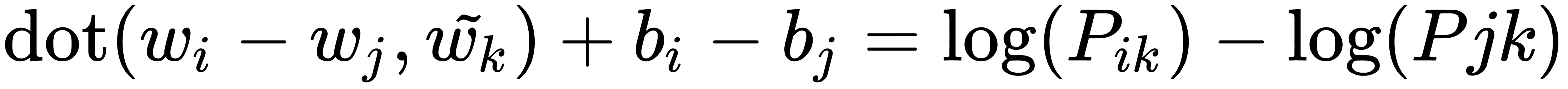
We can convert this equation into an equation for a single record from the co-occurrence matrix:
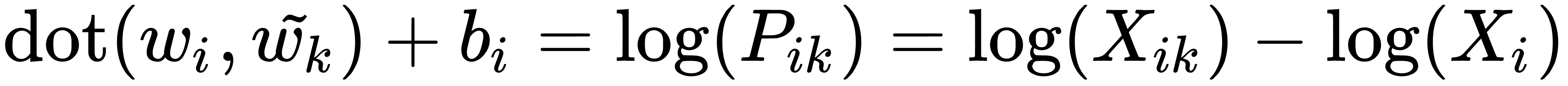
By doing this, we transform the last term of the equation on the right-hand side into the bias term. By adding the output bias for symmetry, we get the following formula:
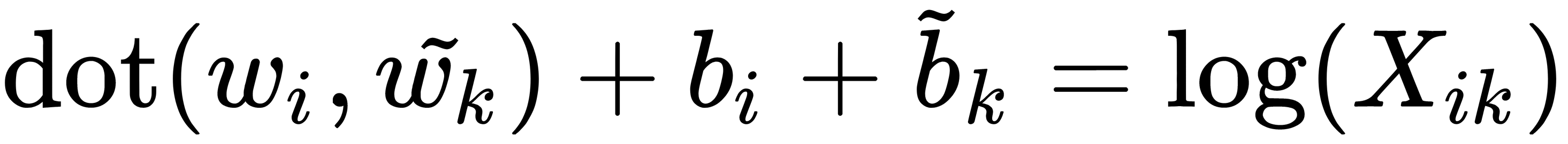
This formula is the central GloVe equation. But there is one problem with this equation: it equally evaluates all co-occurrences of words. However, in reality, not all co-occurrences have the same quality of information. Co-occurrences that are rare tend to be noisy and unreliable, so we want stronger weights to be attached to more frequent co-occurrences. On the other hand, we do not want frequent co-occurrences to dominate the loss function entirely, so we do not want the estimates to be solely dependent on frequency.
As a result of experimentation, Jeffrey Pennington, Richard Socher, and Christopher D. Manning, the authors of the original article, GloVe: Global Vectors for Word Representation, found that the following weight function works well:
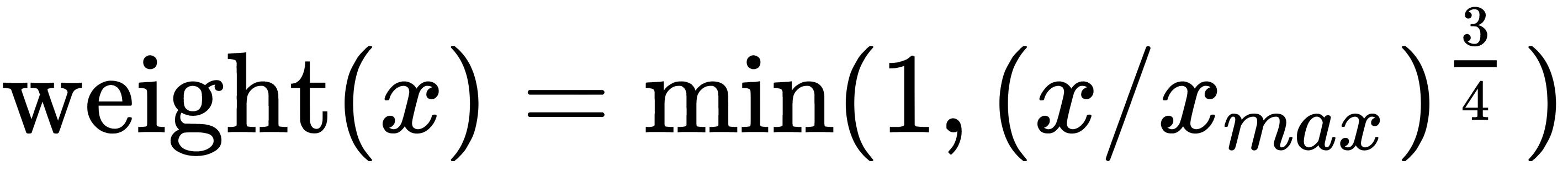
Using this function, we can transform the loss function into the following form:
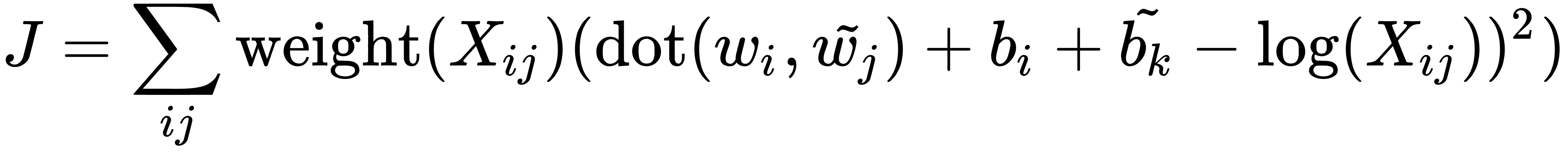
Now, the task of finding embedding vectors is reduced to minimizing this loss function. This operation can be accomplished, for example, using the stochastic gradient descent approach.
In the next section, we will develop a sentiment analysis model with the PyTorch library using the RNN principles we learned about in the previous sections.