
In this section, we are going to build a machine learning model that can detect review sentiment (detect whether a review is positive or negative) using PyTorch. As a training set, we are going to use the Large Movie Review Dataset, which contains a set of 25,000 movie reviews for training and 25,000 for testing, both of which are highly polarized.
First, we have to develop parser and data loader classes to move the dataset to memory in a format suitable for use with PyTorch.
Let's start with the parser. The dataset we have is organized as follows: there are two folders for the train and test sets, and each of these folders contains two child folders named pos and neg, which is where the positive review files and negative review files are placed. Each file in the dataset contains exactly one review, and its sentiment is determined by the folder it's placed in. In the following code sample, we will define the interface for the reader class:
class ImdbReader {
public:
ImdbReader(const std::string& root_path);
size_t GetPosSize() const;
size_t GetNegSize() const;
size_t GetMaxSize() const;
using Review = std::vector<std::string>;
const Review& GetPos(size_t index) const;
const Review& GetNeg(size_t index) const;
private:
using Reviews = std::vector<Review>;
void ReadDirectory(const std::string& path, Reviews& reviews);
private:
Reviews pos_samples_;
Reviews neg_samples_;
size_t max_size_{0};
};
We defined the Review type as a vector of strings. There are also two more vectors, pos_samples_ and neg_samples_, which contain the reviews that were read from the corresponding folders.
We will assume that the object of this class should be initialized with the path to the root folder where one of the datasets is placed (the training set or testing set). We can initialize this in the following way:
int main(int argc, char** argv) {
if (argc > 0) {
auto root_path = fs::path(argv[1]);
...
ImdbReader train_reader(root_path / "train");
ImdbReader test_reader(root_path / "test");
}
...
}
The most important parts of this class are the constructor and the ReadDirectory methods. The constructor is the main point wherein we fill the containers, pos_samples_ and neg_samples_, with actual reviews from the pos and neg folders:
namespace fs = std::filesystem;
...
ImdbReader::ImdbReader(const std::string& root_path) {
auto root = fs::path(root_path);
auto neg_path = root / "neg";
auto pos_path = root / "pos";
if (fs::exists(neg_path) && fs::exists(pos_path)) {
auto neg = std::async(std::launch::async,
[&]() { ReadDirectory(neg_path, neg_samples_); });
auto pos = std::async(std::launch::async,
[&]() { ReadDirectory(pos_path, pos_samples_); });
neg.get();
pos.get();
} else {
throw std::invalid_argument("ImdbReader incorrect path");
}
}
The ReadDirectory method implements the logic for iterating files in the given directory. It also reads them, tokenizes lines, and fills the dataset container, which is then passed as a function parameter. The following code shows the ReadDirectory method's implementation:
void ImdbReader::ReadDirectory(const std::string& path, Reviews& reviews) {
std::regex re("[^a-zA-Z0-9]");
std::sregex_token_iterator end;
for (auto& entry : fs::directory_iterator(path)) {
if (entry.is_regular_file()) {
std::ifstream file(entry.path());
if (file) {
std::string text;
{
std::stringstream buffer;
buffer << file.rdbuf();
text = buffer.str();
}
std::sregex_token_iterator token(text.begin(), text.end(),
re, -1);
Review words;
for (; token != end; ++token) {
if (token->length() > 1) { // don't use one letter
// words
words.push_back(*token);
}
}
max_size_ = std::max(max_size_, words.size());
reviews.push_back(std::move(words));
}
}
}
}
We used the standard library directory iterator class, fs::directory_iterator, to get every file in the folder. The object of this class returns the object of the fs::directory_entry class, and this object can be used to determine whether this is a regular file with the is_regular_file method. We got the file path of this entry with the path method.
We read the whole file to one string object using the rdbuf method of the std::ifstream type object. Then, we tokenized (split the distinct words) this string with the use of a regular expression. The std::sregex_token_iterator class in the C++ standard library can be used precisely for this purpose. The object of this class was initialized with the iterator range of the target text string we need to split, the regular expression object, and the index of the sub-match that the object will search. We defined the re object (which matched everything that was not the alpha-numeric character) with regular expressions. As a sub-match index, we used -1 because 0 represents the entire match and -1 represents the characters between matches. Iterating through the tokens, we selected words with a length greater than one in order to reduce computational complexity and eliminate meaningless characters. All the relevant tokens were placed in the Review container type, which represents a single review. This review was also placed in the top-level container, which is passed as a function argument. Notice that we used the std::move function to move containers in order to eliminate a heavy copy operation.
After we've read the train and test datasets, we need to build a word vocabulary where each string representing a word matches a unique index. We are going to use such a vocabulary to convert string-based reviews into integer-based representations that can be used with linear algebra abstractions. We can build such a vocabulary from the whole set of words that appeared in the reviews, but this would produce a huge corpus; in practice, many words are used very rarely, so they produce unnecessary noise. To avoid these issues, we can only use a certain number of the most frequently used words. To select such words, we need to calculate the frequencies of all the words in the reviews. We can do this by using the hash map object:
using WordsFrequencies = std::unordered_map<std::string, size_t>;
We can calculate frequencies by accumulating the number of times words appear in the second member of the pair from the map. This is done by iterating through all of the words in the reviews:
void GetWordsFrequencies(const ImdbReader& reader,
WordsFrequencies& frequencies) {
for (size_t i = 0; i < reader.GetPosSize(); ++i) {
const ImdbReader::Review& review = reader.GetPos(i);
for (auto& word : review) {
frequencies[word] += 1;
}
}
for (size_t i = 0; i < reader.GetNegSize(); ++i) {
const ImdbReader::Review& review = reader.GetNeg(i);
for (auto& word : review) {
frequencies[word] += 1;
}
}
}
This function is used in the following way:
WordsFrequencies words_frequencies;
GetWordsFrequencies(train_reader, words_frequencies);
GetWordsFrequencies(test_reader, words_frequencies);
After we have calculated the number of occurrences of each word in the datasets, we can select a specific number of the most frequently used ones. Let's set the size of the vocabulary to 25,000 words:
int64_t vocab_size = 25000;
To select the top 25,000 most frequent words, we have to sort all the words by their frequency. To perform this operation, we need to use a container other than a hash map (because it is an unordered container). Therefore, we will use the C++ vector class. It should be parameterized with a pair type containing the frequency value and the iterator to the original item. This iterator should point to the element in the hash map. Such an approach will allow us to reduce copying operations. Then, we can use the standard sorting algorithm with a custom comparison function. This concept is fully implemented in the SelectTopFrequencies function:
void SelectTopFrequencies(WordsFrequencies& vocab, int64_t new_size) {
using FreqItem = std::pair<size_t, WordsFrequencies::iterator>;
std::vector<FreqItem> freq_items;
freq_items.reserve(vocab.size());
auto i = vocab.begin();
auto e = vocab.end();
for (; i != e; ++i) {
freq_items.push_back({i->second, i});
}
std::sort(
freq_items.begin(), freq_items.end(),
[](const FreqItem& a, const FreqItem& b)
{ return a.first < b.first; });
std::reverse(freq_items.begin(), freq_items.end());
freq_items.resize(static_cast<size_t>(new_size));
WordsFrequencies new_vocab;
for (auto& item : freq_items) {
new_vocab.insert({item.second->first, item.first});
}
vocab = new_vocab;
}
The standard library's sort function assumes that a passed comparison function returns true if the first argument is less than the second. So, after sorting, we reversed the result in order to move the most frequent words to the beginning of the container. Then, we simply resized the freq_items container to the desired length. The last step in this function was creating the new WordsFrequencies type object from the items representing the most frequently used words. Also, we replaced the content of the original vocab object with the new_vocab object content. The following code shows how to use this function:
SelectTopFrequencies(words_frequencies, vocab_size);
Before we assign indices to the words, we have to decide how we are going to generate embeddings for them. This is an important issue because the indices we assign will be used to access the word embeddings. In this example, we used the pre-trained GloVe word embeddings. We can find different variants on the original article's site: https://nlp.stanford.edu/projects/glove/.
Word vectors learned from the Wikipedia 2014 materials and Gigaword 5 text corpora, which contain 6 billion tokens and 100-dimensional vectors, was chosen for this example. As in the previous case, we need to create a parser for the downloaded embeddings. The downloaded embeddings file contains one key-value pair per line, where the key is the word and the value is the 100-dimensional vector. All the items in the line are separated by spaces, so the format look likes this: word x0 x1 x2 ... x99.
The following code defines the class interface for the GloVe embedding's parser:
class GloveDict {
public:
GloveDict(const std::string& file_name, int64_t vec_size);
torch::Tensor Get(const std::string& key) const;
torch::Tensor GetUnknown() const;
private:
torch::Tensor unknown_;
std::unordered_map<std::string, torch::Tensor> dict_;
};
The GloveDict class constructor takes the filename and the size of the embedding vector. There are two methods being used here. The Get method returns the torch::Tensor type object for the embedding that corresponds to the input word. The second method, GetUnknown, returns the tensor representing the embedding for the words that don't exist in the embeddings list. In our case, this is the zero tensor.
The main work is done by the constructor of the class, where we read a file with GloVe vectors, parse it, and initialize the dict_ map object with words in the keys role and embed tensors as values:
GloveDict::GloveDict(const std::string& file_name, int64_t vec_size) {
std::ifstream file;
file.exceptions(std::ifstream::badbit);
file.open(file_name);
if (file) {
auto sizes = {static_cast<long>(vec_size)};
std::string line;
std::vector<float> vec(static_cast<size_t>(vec_size));
unknown_ = torch::zeros(sizes, torch::dtype(torch::kFloat));
std::string key;
std::string token;
while (std::getline(file, line)) {
if (!line.empty()) {
std::stringstream line_stream(line);
size_t num = 0;
while (std::getline(line_stream, token, ' ')) {
if (num == 0) {
key = token;
} else {
vec[num - 1] = std::stof(token);
}
++num;
}
assert(num == (static_cast<size_t>(vec_size) + 1));
torch::Tensor tvec = torch::from_blob(
vec.data(), sizes,
torch::TensorOptions().dtype(torch::kFloat));
dict_[key] = tvec.clone();
}
}
}
}
In this method, we read a file line by line with the std::getline function from the standard library. We defined one object of the std::vector<float> type to hold the embedding vector values, and we initialized the unknown_ tensor for unknown words with zeros using the torch::zeros function from the PyTorch library. To split the line in the tokens, we also used the std::getline function. This is because it has a second parameter that can be used to specify the delimiter. By default, the delimiter is a newline character, but we specified the space character as the delimiter. We used the first token as a keyword. Regarding the other tokens from each file line, we put them into the vector of floating-point numbers. When we parsed a whole line, we constructed the torch::Tensor object with the torch::from_blob method, which wraps existing data without copying it to the tensor object with specified options. Finally, we put the key-value pair on the map; the key is the word and the value is the tensor object. Notice that we used the clone method to copy exact data to a new object stored in the map. The vec object is used to reuse memory while parsing the vectors. The std::stof function from the standard library is used to convert a string into a floating-point number.
Now, we have everything we need to create a vocabulary class that can associate a word with a unique index, and the index with a vector embedding. The following snippet shows its definition:
class Vocabulary {
public:
Vocabulary(const WordsFrequencies& words_frequencies,
const GloveDict& glove_dict);
int64_t GetIndex(const std::string& word) const;
int64_t GetPaddingIndex() const;
torch::Tensor GetEmbeddings() const;
int64_t GetEmbeddingsCount() const;
private:
std::unordered_map<std::string, size_t> words_to_index_map_;
std::vector<torch::Tensor> embeddings_;
size_t unk_index_;
size_t pad_index_;
};
The object of the Vocabulary class should be initialized with the instances of the WordsFrequencies and GloveDict classes; it implements the next vital methods. GetIndex returns the index for the input word, while GetEmbeddings returns a tensor containing all embeddings (in rows) in the same order as the word indices. The GetPaddingIndex method returns the index of the embedding, which can be used for padding (it is a zero tensor in reality). The GetEmbeddingsCount method returns the total count of the embeddings.
The following code shows how the constructor is implemented:
Vocabulary::Vocabulary(const WordsFrequencies& words_frequencies,
const GloveDict& glove_dict) {
words_to_index_map_.reserve(words_frequencies.size());
embeddings_.reserve(words_frequencies.size());
unk_index_ = 0;
pad_index_ = unk_index_ + 1;
embeddings_.push_back(glove_dict.GetUnknown()); // unknown
embeddings_.push_back(glove_dict.GetUnknown()); // padding
size_t index = pad_index_ + 1;
for (auto& wf : words_frequencies) {
auto embedding = glove_dict.Get(wf.first);
if (embedding.size(0) != 0) {
embeddings_.push_back(embedding);
words_to_index_map_.insert({wf.first, index});
++index;
} else {
words_to_index_map_.insert({wf.first, unk_index_});
}
}
}
In this method, we populated the words_to_index_map_ and embeddings_ containers. First, we inserted two zero-valued tensors into the embeddings_ container: one for the GloVe unknown word and another for padding values:
embeddings_.push_back(glove_dict.GetUnknown()); // unknown
embeddings_.push_back(glove_dict.GetUnknown()); // padding
We use padding values to create a batch of reviews for training because almost all review texts have different lengths. Then, we iterated over the words_frequencies object, which was passed as a parameter, and used the glove_dict object to search the embedding vector for the word from the dictionary. If the word is found in the glove_dict object, then we populate the embeddings_ object with the tensor and the words_to_index_map_ object with the word as a key and the index as a value. If a word is not found in the glove_dict object, then we populate only the words_to_index_map_ object, with the word as a key and unk_index_ as a value. Notice how the index value is initialized and incremented; it starts with 2 because the 0 index is occupied for unknown embedding and the 1 index is occupied for padding value embedding:
unk_index_ = 0;
pad_index_ = unk_index_ + 1;
...
size_t index = pad_index_ + 1;
Notice that we only increased the index after we inserted a new embedding tensor into the embeddings_ object. In the opposite case, when an embedding for the word was not found, the word was associated with the unknown value index. The next important method in the Vocabulary class in the GetEmbeddings method, which makes a single tensor from a vector of embedding tensors. The following code shows its implementation:
at::Tensor Vocabulary::GetEmbeddings() const {
at::Tensor weights = torch::stack(embeddings_);
return weights;
}
Here, we used the torch::stack function, which concatenates tensors from the given container along a new dimension (by default, this function adds a dimension with index 0).
Other Vocabulary class methods return corresponding values:
- GetIndex: Returns the index of a given word in the vocabulary
- GetPaddingIndex: Returns the index of padding values in the vocabulary
- GetEmbeddings: Returns all embeddings as one tensor object
- GetEmbeddingsCount: Returns the number of embeddings in the vocabulary
Now, we have all the necessary classes for dataset class implementation. Such classes can be used for the PyTorch data loader's initialization. However, before we develop it, we should discuss how our model should process training batches. We already mentioned that review texts are of different lengths, so it is impossible to combine several of them into one rectangular tensor (remember that words are represented with numeric indices). To solve this problem, we need to make them all the same length. This operation can be done by determining the most extended text in the dataset with the GetMaxSize method of ImdbReader and allocating the tensor with this size as one of the dimensions. The shorter text is padded with zero values. We already defined the method to get the padding index in the Vocabulary class.
However, such an approach also leads to numerous unnecessary calculations and adds noise to our training data, which can make our model less precise. Fortunately, because this is a common problem, there is a solution. The PyTorch library has an LSTM module implementation, which can effectively work with padded batches by ignoring the padding values. To use such functionality, we need to add information regarding the length of each text (sequence) in the batch.
So, our dataset class should return a pair of training tensors: one representing the encoded text and another containing its length. Also, we need to develop a custom function to convert the vector of tensors in a batch into one single tensor. This function is required if we want to make PyTorch compatible with custom training data.
Let's define the ImdbSample type for a custom training data sample. We will use this with the torch::data::Dataset type:
using ImdbData = std::pair<torch::Tensor, torch::Tensor>;
using ImdbSample = torch::data::Example<ImdbData, torch::Tensor>;
ImdbData represents the training data and has two tensors for test sequence and length. ImdbSample represents the whole sample with a target value. A tensor contains a 1 or 0 for positive or negative sentiment, respectively.
The following code snippet shows the ImdbDataset class' declaration:
class ImdbDataset : public torch::data::Dataset<ImdbDataset, ImdbSample> {
public:
ImdbDataset(ImdbReader* reader,
Vocabulary* vocabulary,
torch::DeviceType device);
// torch::data::Dataset implementation
ImdbSample get(size_t index) override;
torch::optional<size_t> size() const override;
private:
torch::DeviceType device_{torch::DeviceType::CPU};
ImdbReader* reader_{nullptr};
Vocabulary* vocabulary_{nullptr};
};
We inherited our dataset class from the torch::data::Dataset class so that we can use it for data loader initialization. The PyTorch data loader object is responsible for sampling random training objects and making batches from them. The objects of our ImdbDataset class should be initialized with the ImdbReader and Vocabulary class instances. We also added the device parameter of torch::DeviceType into the constructor to tell the object where to place the training object in CPU or GPU memory. In the constructor, we store the pointers to input objects and the device type. We overrode two methods from the torch::data::Dataset class: the get and size methods.
The following code shows how we implemented the size method:
torch::optional<size_t> ImdbDataset::size() const {
return reader_->GetPosSize() + reader_->GetNegSize();
}
The size method returns the number of reviews in the ImdbReader object. The get method has a more complicated implementation than the previous one, as shown in the following code:
ImdbSample ImdbDataset::get(size_t index) {
torch::Tensor target;
const ImdbReader::Review* review{nullptr};
if (index < reader_->GetPosSize()) {
review = &reader_->GetPos(index);
target = torch::tensor(1.f,
torch::dtype(torch::kFloat).device(
device_).requires_grad(false));
} else {
review = &reader_->GetNeg(index - reader_->GetPosSize());
target = torch::tensor(0.f,
torch::dtype(torch::kFloat).device(
device_).requires_grad(false));
}
First, we got the review text and sentiment value from the given index (the function argument value). In the size method, we returned the total number of positive and negative reviews, so if the input index is greater than the number of positive reviews, then this index points to a negative one. Then, we subtracted the number of positive reviews from it.
After we got the correct index, we also got the corresponding text review and assigned its address to the review pointer and initialized the target tensor. The torch::tensor function was used to initialize the target tensor. This function takes an arbitrary numeric value and tensor options such as a type and a device. Notice that we set the requires_grad option to false because we don't need to calculate the gradient for this variable. The following code shows the continuation of the get method's implementation:
// encode text
std::vector<int64_t> indices(reader_->GetMaxSize());
size_t i = 0;
for (auto& w : (*review)) {
indices[i] = vocabulary_->GetIndex(w);
++i;
}
Here, we encoded the review text from string words to their indices. We defined the indices vector of integer values in order to store the encoding of the maximum possible length. Then, we filled it in the cycle by applying the GetIndex method of the vocabulary object to each of the words. Notice that we used the i variable to count the number of words we encode. The use of this variable was required because other positions in the sequence will be padded with a particular padding index.
The following code shows how we add the padding indices to the sequence:
// pad text to same size
for (; i < indices.size(); ++i) {
indices[i] = vocabulary_->GetPaddingIndex();
}
When we've initialized all the data we need for one training sample, we have to convert it into a torch::Tensor object. For this purpose, we can use already known functions, namely torch::from_blob and torch::tensor. The torch::from_blob function takes the pointer for raw numeric data, the dimensions container, and tensor options. The following code shows how we used these functions to create the final tensor object at the end of the get method's implementation:
auto data = torch::from_blob(indices.data(),
{static_cast<int64_t>(reader_->GetMaxSize())},
torch::dtype(torch::kLong).requires_grad(false));
auto data_len = torch::tensor(static_cast<int64_t>(review->size()),
torch::dtype(torch::kLong).requires_grad(false));
return {{data.clone().to(device_), data_len.clone()},
target.squeeze()};
}
Notice that the data object containing the text sequence was moved to the specific device with the to method, but data_len was left in the default (CPU) device because this is a requirement of the PyTorch LSTM implementation API. Also, look at the use of the squeeze method – this method removes all tensor dimensions equal to 1, so in our case, we used it to make a single value tensor (not a rectangular one).
The following code shows how to use the classes we defined previously to initialize data loaders for the training and test datasets:
torch::DeviceType device = torch::cuda::is_available()
? torch::DeviceType::CUDA
: torch::DeviceType::CPU;
...
// create datasets
ImdbDataset train_dataset(&train_reader, &vocab, device);
ImdbDataset test_dataset(&test_reader, &vocab, device);
// init data loaders
size_t batch_size = 32;
auto train_loader = torch::data::make_data_loader(train_dataset,
torch::data::DataLoaderOptions().batch_size(batch_size).workers(4));
auto test_loader = torch::data::make_data_loader(test_dataset,
torch::data::DataLoaderOptions().batch_size(batch_size).workers(4));
Before we move on, we need to define one more helper function, which converts the batch vector of tensors into one tensor. This conversion is needed to vectorize the calculation for better utilization of hardware resources, in order to improve performance. Notice that when we initialized the data loaders with the make_data_loader function, we didn't use the mapping and transform methods for datasets objects as in the previous example. This was done because, by default, PyTorch can't automatically transform arbitrary types (in our case, the ImdbData pair type) into tensors. The following code shows the beginning of the MakeBatchTensors function's implementation:
std::tuple<torch::Tensor, torch::Tensor, torch::Tensor>
MakeBatchTensors(const std::vector<ImdbSample>& batch) {
// prepare batch data
std::vector<torch::Tensor> text_data;
std::vector<torch::Tensor> text_lengths;
std::vector<torch::Tensor> label_data;
for (auto& item : batch) {
text_data.push_back(item.data.first);
text_lengths.push_back(item.data.second);
label_data.push_back(item.target);
}
First, we split a single vector of the ImdbSample objects into three: text_data, which contains all texts; text_lengths, which contains the corresponding lengths; and label_data, which contains the target value. Then, we need to sort them in decreasing order of text length. This order is a requirement of the pack_padded_sequence function, which we will use in our model to transform padded sequences into packed ones to improve performance. We can't simultaneously sort three containers in C++, so we have to use a custom approach based on a defined permutation. The following code shows how we applied this approach while continuing to implement the method:
std::vector<std::size_t> permutation(text_lengths.size());
std::iota(permutation.begin(), permutation.end(), 0);
std::sort(permutation.begin(), permutation.end(),
[&](std::size_t i, std::size_t j) {
return text_lengths[i].item().toLong() <
text_lengths[j].item().toLong();
});
std::reverse(permutation.begin(), permutation.end());
Here, we defined the permutation vector of indices with a number of items equal to the batch size. Then, we filled it consistently with numbers starting from 0, and sorted it with the standard std::sort algorithm function, but with a custom comparison functor, which compares the lengths of sequences with correspondent indices. Notice that to get the raw value from the torch::Tensor type object, the item() and toLong() methods were used. Also, because we needed the decreasing order of items, we used the std::reverse algorithm. The following code shows how we used the permutation object to sort three containers in the same way:
auto appy_permutation = [&permutation](
const std::vector<torch::Tensor>& vec) {
std::vector<torch::Tensor> sorted_vec(vec.size());
std::transform(permutation.begin(), permutation.end(),
sorted_vec.begin(),
[&](std::size_t i) { return vec[i]; });
return sorted_vec;
};
text_data = appy_permutation(text_data);
text_lengths = appy_permutation(text_lengths);
label_data = appy_permutation(label_data);
To perform the sorting operation, we defined a lambda function that changes the order of the container's items by the given vector of indices. This was the appy_permutation lambda. This function created a new intermediate vector of the same size as the one we want to reorder and filled it with the std::transform algorithm with a custom functor, which returns the item from the original container but with the index taken from the permutation object.
When all the batch vectors have been sorted in the required order, we can use the torch::stack function to concatenate each of them into the single tensor with an additional dimension. The following code snippet shows how we used this function to create the final tensor objects. This is the final part of the MakeBatchTensors method's implementation:
torch::Tensor texts = torch::stack(text_data);
torch::Tensor lengths = torch::stack(text_lengths);
torch::Tensor labels = torch::stack(label_data);
return {texts, lengths, labels};
}
At this point, we have written all the code required to parse and prepare the training data. Now, we can create classes for our RNN model. We are going to base our model on the LSTM architecture. There is a module called torch::nn::LSTM in the PyTorch C++ API for this purpose. The problem is that this module can't work with packed sequences. There is a standalone function called torch::lstm that can do this, so we need to create our custom module to combine the torch::nn::LSTM module and the torch::lstm function so that we can work with packed sequences. Such an approach causes our RNN to only process the non-padded elements of our sequence.
The following code shows the PackedLSTMImpl class' declaration and the PackedLSTM module's definition:
class PackedLSTMImpl : public torch::nn::Module {
public:
explicit PackedLSTMImpl(const torch::nn::LSTMOptions& options);
std::vector<torch::Tensor> flat_weights() const;
torch::nn::RNNOutput forward(const torch::Tensor& input,
const torch::Tensor& lengths,
torch::Tensor state = {});
const torch::nn::LSTMOptions& options() const;
private:
torch::nn::LSTM rnn_ = nullptr;
};
TORCH_MODULE(PackedLSTM);
The PackedLSTM module definition uses the PackedLSTMImpl class as the module function's implementation. Also, notice that the PackedLSTM module definition differs from the torch::nn::LSTM module in that the forward function takes the additional parameter, lengths. The implementation of this module is based on the code of the torch::nn::LSTM module from the PyTorch library. The flat_weights and forward functions were mostly copied from the PyTorch library's source code. We overrode the flat_weights function because it is hidden in the base class, and we can access it from the torch::nn::LSTM module.
The following code shows the PackedLSTMImpl class constructor's implementation:
PackedLSTMImpl::PackedLSTMImpl(const torch::nn::LSTMOptions& options) {
rnn_ = torch::nn::LSTM(options);
register_module("rnn", rnn_);
}
In the constructor, we created and registered the torch::nn::LSTM module object. Notice that we used an instance of the torch::nn::LSTM module to access the properly initialized weights for the LSTM's implementation.
The following code shows the flat_weights method's implementation:
std::vector<torch::Tensor> PackedLSTMImpl::flat_weights() const {
std::vector<torch::Tensor> flat;
const auto num_directions = rnn_->options.bidirectional_ ? 2 : 1;
for (int64_t layer = 0; layer < rnn_->options.layers_; layer++) {
for (auto direction = 0; direction < num_directions; direction++) {
const auto layer_idx =
static_cast<size_t>((layer * num_directions) + direction);
flat.push_back(rnn_->w_ih[layer_idx]);
flat.push_back(rnn_->w_hh[layer_idx]);
if (rnn_->options.with_bias_) {
flat.push_back(rnn_->b_ih[layer_idx]);
flat.push_back(rnn_->b_hh[layer_idx]);
}
}
}
return flat;
}
In the flat_weights method, we organized all the weights into a flat vector in the order 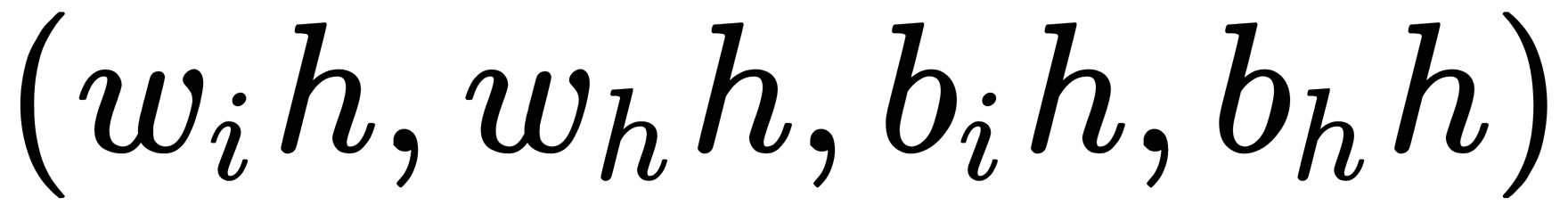 , repeated for each layer, and next to each other. This is a copy of the same method from the torch::nn::LSTM module.
, repeated for each layer, and next to each other. This is a copy of the same method from the torch::nn::LSTM module.
The following code shows the forward method's implementation:
torch::nn::RNNOutput PackedLSTMImpl::forward(const torch::Tensor& input,
const at::Tensor& lengths,
torch::Tensor state) {
if (!state.defined()) {
const auto max_batch_size = lengths[0].item().toLong();
const auto num_directions = rnn_->options.bidirectional_ ? 2 : 1;
state = torch::zeros({2, rnn_->options.layers_ * num_directions,
max_batch_size, rnn_->options.hidden_size_},
input.options());
}
torch::Tensor output, hidden_state, cell_state;
std::tie(output, hidden_state, cell_state) = torch::lstm(
input, lengths, {state[0], state[1]}, flat_weights(),
rnn_->options.with_bias_, rnn_->options.layers_,
rnn_->options.dropout_, rnn_->is_training(),
rnn_->options.bidirectional_);
return {output, torch::stack({hidden_state, cell_state})};
}
The forward method is also a copy of the same method from the torch::nn::LSTM module, but it used a different overload of the torch::lstm function. We can see that the main logic in the forward method is to initialize the cell state if it is not defined and call the torch::lstm function. Notice that all the methods in this class consider the options.bidirectional_ flag in order to configure the dimensions of the weights and state tensors. Also, notice that the module's state is a combined tensor from two tensors: the hidden state and the cell state.
The following code shows how we can define our RNN model with the SentimentRNN class:
class SentimentRNNImpl : public torch::nn::Module {
public:
SentimentRNNImpl(int64_t vocab_size,
int64_t embedding_dim,
int64_t hidden_dim,
int64_t output_dim,
int64_t n_layers,
bool bidirectional,
double dropout,
int64_t pad_idx);
void SetPretrainedEmbeddings(const torch::Tensor& weights);
torch::Tensor forward(const torch::Tensor& text,
const at::Tensor& length);
private:
int64_t pad_idx_{-1};
torch::autograd::Variable embeddings_weights_;
PackedLSTM rnn_ = nullptr;
torch::nn::Linear fc_ = nullptr;
torch::nn::Dropout dropout_ = nullptr;
};
TORCH_MODULE(SentimentRNN);
Our model can be configured so that it's multilayer and bidirectional. These properties can significantly improve model performance for the sentiment analysis task.
Notice that we defined the embeddings_weights_ class member, which is of the torch::autograd::Variable type. This was done because we used the torch::embedding function to convert the input batch sequence's items into embeddings automatically. We can use the torch::nn:Embeding module for this purpose, but the C++ API can't use pre-trained values. This is why we used the torch::embedding function directly. We also used the torch::autograd::Variable type instead of a simple tensor because we need to calculate the gradient for our module during the training process.
The following code shows the SentimentRNNImpl class constructor's implementation:
SentimentRNNImpl::SentimentRNNImpl(int64_t vocab_size,
int64_t embedding_dim,
int64_t hidden_dim,
int64_t output_dim,
int64_t n_layers,
bool bidirectional,
double dropout,
int64_t pad_idx)
: pad_idx_(pad_idx) {
embeddings_weights_ = register_parameter(
"embeddings_weights", torch::empty({vocab_size, embedding_dim}));
rnn_ = PackedLSTM(torch::nn::LSTMOptions(embedding_dim, hidden_dim)
.layers(n_layers)
.bidirectional(bidirectional)
.dropout(dropout));
register_module("rnn", rnn_);
fc_ = torch::nn::Linear(torch::nn::LinearOptions(hidden_dim * 2,
output_dim));
register_module("fc", fc_);
dropout_ = torch::nn::Dropout(torch::nn::DropoutOptions(dropout));
register_module("dropout", dropout_);
}
In the constructor of our module, we initialized the base blocks of our network. We used the register_parameter method of the torch::nn::Module class to create the embeddings_weights_ object, which is filled with the empty tensor. Registration makes automatically calculating the gradient possible. Notice that the one dimension of the embeddings_weights_ object is equal to the vocabulary length, while the other one is equal to the length of the embedding vector (100, in our case). The rnn_ object is initialized with the torch::nn::LSTMOptions type object. We defined the length of the embedding, the number of hidden dimensions (number of hidden neurons in the LSTM module layers), the number of RNN layers, the flag that tells us whether the RNN is bidirectional or not, and specified the regularization parameter (the dropout factor value).
The fc_ object is our output layer with just a fully connected layer and a linear activation function. It is configured to take the hidden_dim * 2 number of input items, which means that we are going to pass the hidden states from the last two modules of our RNN into it. The fc_ object returns only one value; we didn't use the sigmoid activation function for it because, as stated in the PyTorch documentation, it makes sense to use a special loss function called binary_cross_entropy_with_logits, which includes the sigmoid and is more stable than using a plain sigmoid followed by binary cross-entropy loss. We also initialized and registered the dropout_ object, which is used for additional regularization; the torch::nn::DropoutOptions object only takes a dropout factor value as its setting.
The following code snippet shows the forward method's implementation:
torch::Tensor SentimentRNNImpl::forward(const at::Tensor& text,
const at::Tensor& length) {
auto embedded =
dropout_(torch::embedding(embeddings_weights_, text, pad_idx_));
torch::Tensor packed_text, packed_length;
std::tie(packed_text, packed_length) = torch::_pack_padded_sequence(
embedded, length.squeeze(1), /*batch_first*/ false);
auto rnn_out = rnn_->forward(packed_text, packed_length);
auto hidden_state = rnn_out.state.narrow(0, 0, 1);
hidden_state.squeeze_(0); // remove 0 dimension equals to 1 after
// narrowing
// take last hidden layers state
auto last_index = rnn_->options().layers() - 2;
hidden_state =
at::cat({hidden_state.narrow(0, last_index, 1).squeeze(0),
hidden_state.narrow(0, last_index + 1, 1).squeeze(0)},
/*dim*/ 1);
auto hidden = dropout_(hidden_state);
return fc_(hidden);
}
The implementation of the forward method takes two tensors as input parameters. One is the text sequences, which are [sequence length x batch size] in size, while the other is text lengths, which are [batch size x 1] in size. First, we applied the torch::embedding function to our text sequences. This function converts indexed sequences into ones with embedding values (this is just a table lookup operation). It also takes embeddings_weights_ as a parameter. embeddings_weights_ is the tensor that contains our pre-trained embeddings. The pad_idx_ parameter tells us what index points to the padding value embedding. The result of calling this function is [sequence length x batch size x 100]. We also applied the dropout module to the embedded sequences to perform regularization.
Then, we converted the padded embedded sequences into packed ones with the torch::_pack_padded_sequence function. This function takes the padded sequences with their lengths (which should be one-dimensional tensors) and returns a pair of new tensors with different sizes, which also represent packed sequences and packed lengths, correspondingly. We used packed sequences to improve the performance of the model.
After, we passed the packed sequences and their lengths into the PackedLSTM module's forward function. This module processed the input sequences with the RNN and returned an object of the torch::nn::RNNOutput type with two members: output and state. The state member is in the following format: {hidden_state, cell_state}.
We used the values of the hidden state as input for the fully connected layer. To get the hidden state values, we extracted them from the combined state, which was done with the narrow method of a tensor object. This method returns the narrowed version of the original tensor. The first argument is the dimension index that narrowing should be performed along, while the next two arguments are the start position and the length. The returned tensor and input tensor share the same underlying storage.
The hidden state has the following shape: {num layers * num directions x batch size x hid dim}. The number of directions is 2 in the case of a bidirectional RNN. RNN layers are ordered as follows: [forward_layer_0, backward_layer_0, forward_layer_1, backward_layer 1, ..., forward_layer_n, backward_layer n].
The following code shows how to get the hidden states for the last (top) layers:
auto last_index = rnn_->options().layers() - 2;
hidden_state =
at::cat({hidden_state.narrow(0, last_index, 1).squeeze(0),
hidden_state.narrow(0, last_index + 1, 1).squeeze(0)},
/*dim*/ 1);
Here, we got the top two hidden layer states from the first dimension. Then, we concatenated them with the torch::cat function before passing them to the linear layer (after applying dropout). The torch::cat function combines tensors along an existing dimension. Note that the tensors should be the same shape, contrary to the torch::stack function (which adds a new dimension when it combines tensors). Performing these narrowing operations left the original dimensions. Due to this, we used the squeeze function to remove them.
The last step of the forward function was applying the dropout and passing the results to the fully connected layer. The following snippet shows how this was done:
auto hidden = dropout_(hidden_state);
return fc_(hidden);
The following code shows how we can initialize the model:
int64_t hidden_dim = 256;
int64_t output_dim = 1;
int64_t n_layers = 2;
bool bidirectional = true;
double dropout = 0.5;
int64_t pad_idx = vocab.GetPaddingIndex();
SentimentRNN model(vocab.GetEmbeddingsCount(),
embedding_dim,
hidden_dim,
output_dim,
n_layers,
bidirectional,
dropout,
pad_idx);
We configured it to be multilayer and bidirectional with 256 hidden neurons. The next important step in the model configuration process is initializing the pre-trained embeddings. The following snippet shows how to use the SetPretrainedEmbeddings method to do so:
model->SetPretrainedEmbeddings(vocab.GetEmbeddings());
The SetPretrainedEmbeddings method is implemented in the following way:
void SentimentRNNImpl::SetPretrainedEmbeddings(const at::Tensor& weights) {
torch::NoGradGuard guard;
embeddings_weights_.copy_(weights);
}
With the instance of the torch::NoGradGuard type, we put the PyTorch library into special mode, which allowed us to update the internal structure of the modules without influencing the gradient calculations. We used the tensor's copy_ method to copy the data one by one.
When the model has been initialized and configured, we can begin training. The necessary part of the training process is an optimizer object. In this example, we will use the Adam optimization algorithm. The name Adam is derived from the adaptive moment estimation. This algorithm usually results in a better and faster convergence in comparison with pure stochastic gradient descent. The following code shows how to define an instance of the torch::optim::Adam class:
double learning_rate = 0.01;
torch::optim::Adam optimizer(model->parameters(),
torch::optim::AdamOptions(learning_rate));
As with all optimizer objects in the PyTorch library, it should be initialized with the list of parameters for optimization. We passed all the parameters (weights) from our model, model->parameters().
Now, we can move the model to a computational device such as a GPU:
model->to(device);
Then, we can start training the model. Training will be performed for 100 epochs over all the samples in the training dataset. After each epoch, we will run the test model's evaluation to check that there is no overfitting. The following code shows how to define such a training process:
int epochs = 100;
for (int epoch = 0; epoch < epochs; ++epoch) {
TrainModel(epoch, model, optimizer, *train_loader);
TestModel(epoch, model, *test_loader);
}
The TrainModel function will be implemented in a standardized way for training neural networks with PyTorch. Its declaration is shown in the following code:
void TrainModel(int epoch,
SentimentRNN& model,
torch::optim::Optimizer& optimizer,
torch::data::StatelessDataLoader<ImdbDataset,
torch::data::samplers::RandomSampler>& train_loader);
Before we start training iterations, we have to switch the model into training mode. It is essential to do this because some modules behave differently in evaluation mode versus training mode. For example, the dropout is not applied in evaluation mode and only results in an average correction. The following code shows how to enable training mode for the model:
model->train(); // switch to the training mode
The following snippet shows the beginning of the TrainModel function's implementation:
double epoch_loss = 0;
double epoch_acc = 0;
int batch_index = 0;
for (auto& batch : train_loader) {
...
}
Here, we defined two variables to calculate the average loss value and accuracy per epoch. The iteration that we performed over all the batches from the train_loader object was used to train the model.
The following series of code snippets shows the implementation of a training cycle's iteration:
- First, we clear the previous gradients from the optimizer:
optimizer.zero_grad();
- Then, we convert the batch data into distinct tensors:
torch::Tensor texts, lengths, labels;
std::tie(texts, lengths, labels) = MakeBatchTensors(batch);
- Now that we have the sample texts and lengths, we can perform the forward pass of the model:
torch::Tensor prediction = model->forward(texts.t(), lengths);
prediction.squeeze_(1);
Notice that we used the transposed text sequence tensor because the LSTM module requires input data in the [seq_len, batch_size, features] format. Here, seq_len is the number of items (words) in a sequence, batch_size is the size of the current batch, and features is the number of elements in one item (it's not an embedding dimension).
- Now that we have the predictions from our model, we use the squeeze_ function to remove any unnecessary dimensions so that the model's compatible with the loss function. Notice that the squeeze_ function has an underscore, which means that the function is evaluated in place, without any additional memory being allocated.
- Then, we compute a loss value to estimate the error of our model:
torch::Tensor loss = torch::binary_cross_entropy_with_logits(
prediction, labels, {}, {}, Reduction::Mean);
Here, we used the torch::binary_cross_entropy_with_logits function, which measures the binary cross-entropy between the prediction logits and the target labels. This function already includes a sigmoid calculation. This is why our model returns the output from the linear full connection layer. We also specified the reduction type in order to apply to the loss output. Losses from each sample in the batch are summed and divided by the number of elements in the batch.
- Then, we compute the gradients for our model and update its parameters with these gradients:
loss.backward();
optimizer.step();
- One of the final steps of the training function is to accumulate the loss and the accuracy values for averaging:
auto loss_value = static_cast<double>(loss.item<float>());
auto acc_value = static_cast<double>(BinaryAccuracy(prediction, labels));
epoch_loss += loss_value;
epoch_acc += acc_value;
Here, we used the custom BinaryAccuracy function for the accuracy calculation. The following code shows its implementation:
float BinaryAccuracy(const torch::Tensor& preds,
const torch::Tensor& target) {
auto rounded_preds = torch::round(torch::sigmoid(preds));
auto correct = torch::eq(rounded_preds,
target).to(torch::dtype(torch::kFloat));
auto acc = correct.sum() / correct.size(0);
return acc.item<float>();
}
In this function, we applied torch::sigmoid to the predictions of our model. This operation converts the logits values into values we can interpret as a label (1 or 0), but because these values are floating points, we applied the torch::round function to them. The torch::round function rounds the input values to the closest integer. Then, we compared the predicted labels with the target values using the torch::eq function. This operation gave us an initialized tensor, with 1 where labels matched and with 0 otherwise. We calculated the ratio between the number of all labels in the batch and the number of correct predictions as an accuracy value.
The following snippet shows the end of the training function's implementation:
std::cout << "Epoch: " << epoch
<< " | Loss: " << (epoch_loss / (batch_index - 1))
<< " | Acc: " << (epoch_acc / (batch_index - 1))
<< std::endl;
Here, we printed the average values for the loss and accuracy. Notice that we divided the accumulated values by the number of batches.
The following code shows the TestModel function's implementation, which looks pretty similar to the TrainModel function:
void TestModel(int epoch, SentimentRNN& model,
torch::data::StatelessDataLoader<ImdbDataset,
torch::data::samplers::RandomSampler>& test_loader) {
torch::NoGradGuard guard;
double epoch_loss = 0;
double epoch_acc = 0;
model->eval(); // switch to the evaluation mode
// Iterate the data loader to get batches from the dataset
int batch_index = 0;
for (auto& batch : test_loader) {
// prepare batch data
torch::Tensor texts, lengths, labels;
std::tie(texts, lengths, labels) = MakeBatchTensors(batch);
// Forward pass the model on the input data
torch::Tensor prediction = model->forward(texts.t(), lengths);
prediction.squeeze_(1);
// Compute a loss value to estimate error of our model
torch::Tensor loss = torch::binary_cross_entropy_with_logits(
prediction, labels, {},
{}, Reduction::Mean);
auto loss_value = static_cast<double>(loss.item<float>());
auto acc_value = static_cast<double>(BinaryAccuracy(prediction,
labels));
epoch_loss += loss_value;
epoch_acc += acc_value;
++batch_index;
}
std::cout << "Epoch: " << epoch
<< " | Test Loss: " << (epoch_loss / (batch_index - 1))
<< " | Test Acc: " << (epoch_acc / (batch_index - 1)) << std::endl;
}
The main differences regarding this function are that we used the test_loader objects for data, switched the model to the evaluation state with the model->eval() call, and we didn't use any optimization operations.
This RNN architecture, with the settings we used, results in 85% accuracy in the sentiment analysis of movie reviews.