
The most popular format for representing structured data is called CSV. This format is just a text file with a two-dimensional table in it whereby values in a row are separated with commas, and rows are placed on every new line. It looks like this:
1, 2, 3, 4
5, 6, 7, 8
9, 10, 11, 12
The advantages of this file format are that it has a straightforward structure, there are many software tools that can process it, it is human-readable, and it is supported on a variety of computer platforms. Disadvantages are a lack of support of multidimensional data and data with complex structuring, as well as slow parsing speed in comparison with binary formats.
Another widely used format is JSON. Although the format contains JavaScript in its abbreviation, we can use it with almost all programming languages. This is a file format with name-value pairs and arrays of such pairs. It has rules on how to group such pairs to distinct objects and array declarations, and there are rules on how to define values of different types. The following code sample shows a file in JSON format:
{
name:"Bill",
age: 25,
phones:[
{
type:"home"
number:43534590
},
{
type:"work"
number:56985468
}
]
}
The advantages of this format are human readability, software support on many computer platforms, and the possibility to store hierarchical and nested data structures. Disadvantages are its slow parsing speed in comparison with binary formats, and the fact it is not very useful for representing numerical matrices.
Often, we use a combination of file formats to represent a complex dataset. For example, we can describe object relations with JSON, and data/numerical data in the binary form can be stored in a folder structure on the filesystem with references to them in JSON files.
HDF5 is a specialized file format for storing scientific data. This file format was developed to store heterogeneous multidimensional data with a complex structure. It provides fast access to single elements because it has optimized data structures for using secondary storage. Furthermore, HDF5 supports data compression. In general, this file format consists of named groups that contain multidimensional arrays of multitype data. Each element of this file format can contain metadata, as illustrated in the following diagram:
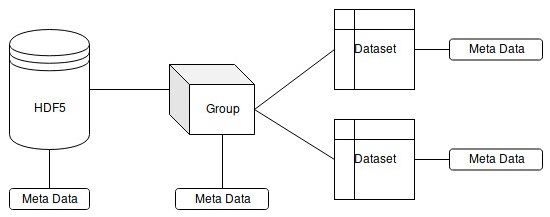
The advantages of this format are its high read-and-write speed, fast access to distinct elements, and its ability to support data with a complex structure and various types of data. Disadvantages are the requirement of specialized tools for editing and viewing by users, the limited support of type conversions among different platforms, and using a single file for the whole dataset. The last issue makes data restoration almost impossible in the event of file corruption.
There are a lot of other formats for representing datasets for machine learning, but we found the ones mentioned to be the most useful.