
The bias is a prediction characteristic that tells us about the distance between model predictions and ground truth values. Usually, we use the term high bias or underfitting to say that model prediction is too far from the ground truth values, which means that the model generalization ability is weak. Consider the following graph:
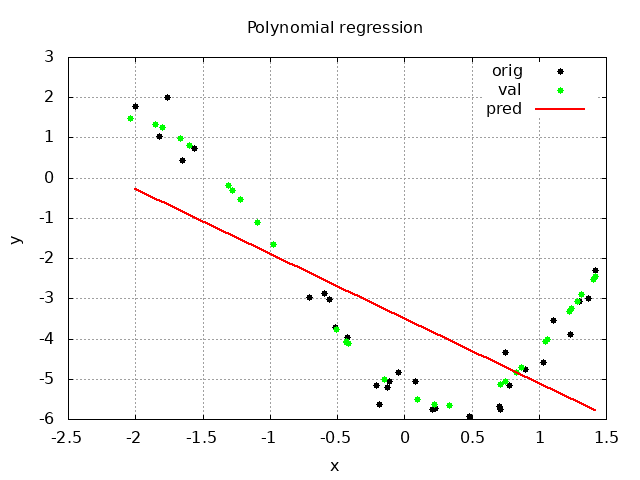
This graph shows the original values with black dots, the values used for validation with green dots, and a line that represents the polynomial regression model output. In this case, the polynomial degree is equal to one. We can see that the predicted values do not describe the original data at all, so we can say that this model has a high bias. Also, we can plot validation metrics for each training cycle to get more information about the training process and the model's behavior.
The following graph shows the MAE metric values for the training process of the polynomial regression model, where the polynomial degree is equal to one:
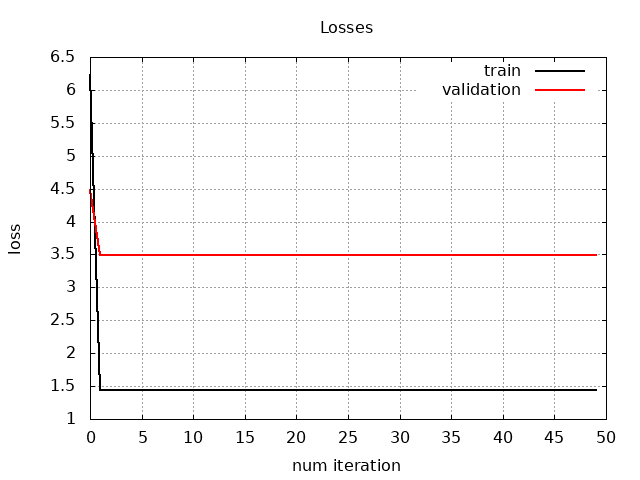
We can see that the lines for the metric values for the train and validation data are parallel and distant enough. Moreover, these lines do not change their direction after numerous training iterations. These facts also tell us that the model has a high bias because, for a regular training process, validation metric values should be close to the training values.
To deal with high bias, we can add more features to the training samples. For example, increasing the polynomial degree for the polynomial regression model adds more features; these all-new features describe the original training sample because each additional polynomial term is based on the original sample value.