
8
Simplifying Deep Learning Model Deployment
The deep learning (DL) models that are deployed in production environments are often different from the models that are fresh out of the training process. They are usually augmented to handle incoming requests with the highest performance. However, the target environments are often too broad, so a lot of customization is necessary to cover vastly different deployment settings. To overcome this difficulty, you can make use of open neural network exchange (ONNX), a standard file format for ML models. In this chapter, we will introduce how you can utilize ONNX to convert DL models between DL frameworks and how it separates the model development process from deployment.
In this chapter, we’re going to cover the following main topics:
- Introduction to ONNX
- Conversion between TensorFlow and ONNX
- Conversion between PyTorch and ONNX
Technical requirements
You can download the supplemental material for this chapter from the following GitHub link: https://github.com/PacktPublishing/Production-Ready-Applied-Deep-Learning/tree/main/Chapter_8.
Introduction to ONNX
There are a variety of DL frameworks you can use to train a DL model. However, one of the major difficulties in DL model deployment arises from the lack of interoperability among these frameworks. For example, conversion between PyTorch and TensorFlow (TF) introduces many difficulties.
In many cases, DL models are augmented further for the deployment environment to increase accuracy and reduce inference latency, utilizing the acceleration provided by the underlying hardware. Unfortunately, this requires a broad knowledge of software as well as hardware because each type of hardware provides different accelerations for the running application. Hardware that is commonly used for DL includes the Central Processing Unit (CPU), Graphical Processing Unit (GPU), Associative Processing Unit (APU), Tensor Processing Unit (TPU), Field Programmable Gate Array (FPGA), Vision Processing Unit (VPU), Neural Processing Unit (NPU), and JetsonBoard.
This process is not a one-time operation; once the model has been updated in any way, this process may need to be repeated. To reduce the engineering effort in this domain, a group of engineers have worked together to come up with a mediator that standardizes the model components: ONNX. This innovative idea helps us train various DL models using any tool without worrying about the difficulties in deployment. Currently, ONNX is the standard file format for machine learning (ML) models that enables you to export a fully trained ML model from one framework for other development environments. ONNX generates an .onnx file that keeps track of how the model is designed and how each operation within a network is linked to other components. Netron is a popular tool that people use to visualize the DL network inside an .onnx file (https://github.com/lutzroeder/netron). The following is a sample visualization:
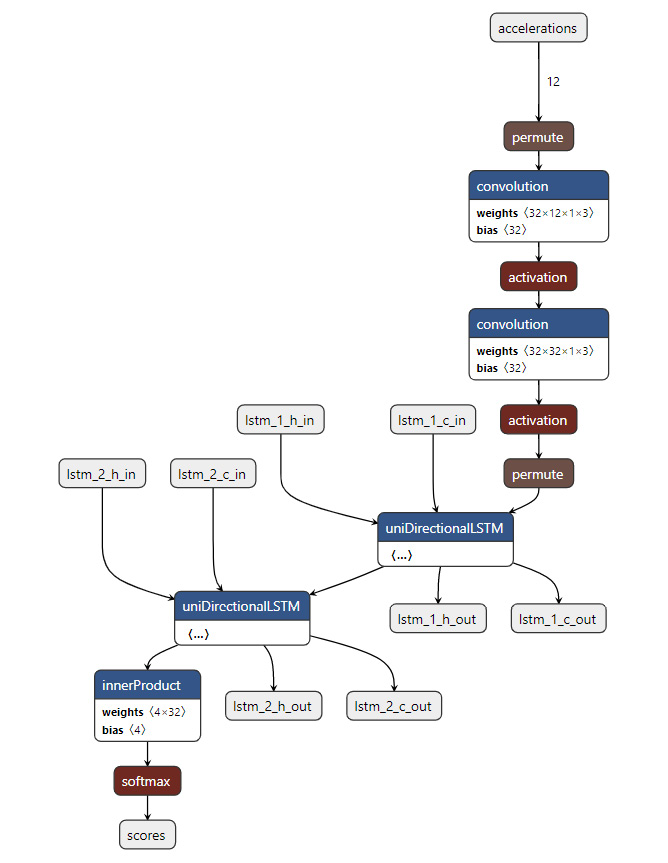
Figure 8.1 – Netron visualization for an ONNX file
As you can see, ONNX is a layer between training frameworks and deployment environments. While the ONNX file defines an exchange format, there also exists ONNX Runtime (ORT), which supports hardware-agnostic acceleration for ONNX models. In other words, the ONNX ecosystem allows you to choose any DL framework for training and makes hardware-specific optimization for deployment easily achievable:
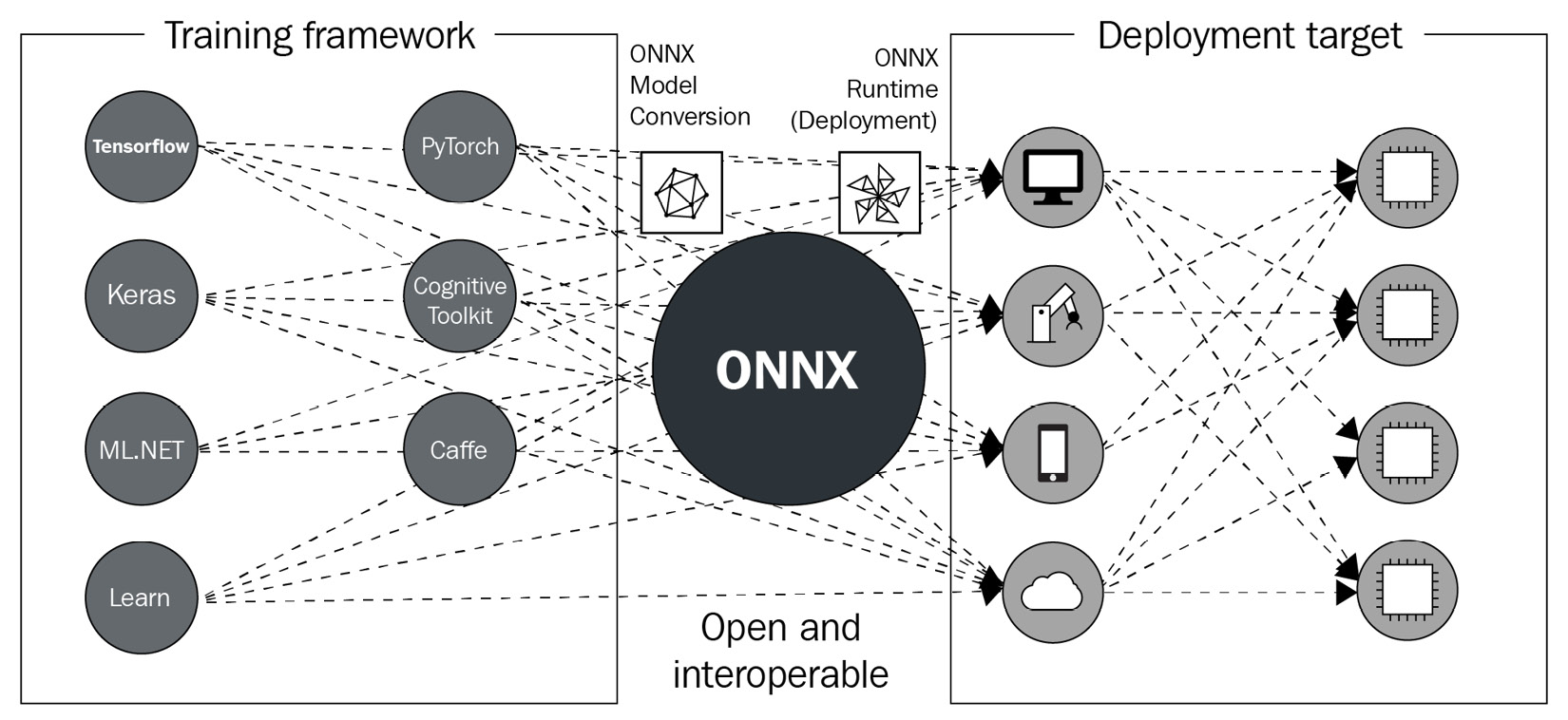
Figure 8.2 – The position of ONNX in a DL project
To summarize, ONNX helps with the following tasks:
- Simplifying the model conversion among various DL frameworks
- Providing hardware-agnostic optimizations for DL models
In the following section, we will take a closer look at ORT.
Running inference using ONNX Runtime
ORT is designed to support training and inferencing using ONNX models directly without converting them into a particular framework. However, training is not the main use case of ORT, so we will focus on the latter aspect, inferencing, in this section.
ORT leverages different hardware acceleration libraries, so-called Execution Providers (EPs), to improve the latency and accuracy of various hardware architectures. The ORT inference code will stay the same regardless of the DL framework used during model training and the underlying hardware.
The following code snippet is a sample ONNX inference code. The complete details can be found at https://onnxruntime.ai/docs/get-started/with-python.html:
import onnxruntime as rt
providers = ['CPUExecutionProvider'] # select desired provider or use rt.get_available_providers()
model = rt.InferenceSession("model.onnx", providers=providers)
onnx_pred = model.run(output_names, {"input": x}) # x is your model's inputThe InferenceSession class takes in a filename, a serialized ONNX model, or an ORT model in a byte string. In the preceding example, we specified the name of an ONNX file ("model.onnx"). The providers parameter and a list of execution providers ordered by precedence (such as CPUExecutionProvider, TvmExecutionProvider, CUDAExecutionProvider, and many more) are optional but important as they define the type of hardware acceleration that will be applied. In the last line, the run function triggers the model prediction. There are two main parameters for the run function: output_names (the names of the model’s output) and input_feed (the input dictionary with input names and values that you want to run model prediction with).
Things to remember
a. ONNX provides a standardized and cross-platform representation for ML models.
b. ONNX can be used to convert a DL model implemented in one DL framework into another with minimal effort.
c. ORT provides hardware-agnostic acceleration for deployed models.
In the next two sections, we will look at the process of creating ONNX models using TF and PyTorch.
Conversion between TensorFlow and ONNX
First, we will look at the conversion between TF and ONNX. We will break down the process into two: converting a TF model into an ONNX model and converting an ONNX model back into a TF model.
Converting a TensorFlow model into an ONNX model
tf2onnx is used to convert a TF model into an ONNX model (https://github.com/onnx/tensorflow-onnx). This library supports both versions of TF (version 1 as well as version 2). Furthermore, conversions to deployment-specific TF formats such as TensorFlow.js and TensorFlow Lite are also available.
To convert a TF model generated using the saved_model module into an ONNX model, you can use the tf2onnx.convert module, as follows:
python -m tf2onnx.convert --saved-model tensorflow_model_path --opset 9 --output model.onnx
In the preceding command, tensorflow-model-path points to a TF model saved on disk, --output defines where the generated ONNX model will be saved, and --opset sets ONNX to opset, which defines the ONNX version and operators (https://github.com/onnx/onnx/releases). If your TF model wasn’t saved using the tf.saved_model.save function, you need to specify the input and output format as follows:
# model in checkpoint format
python -m tf2onnx.convert --checkpoint tensorflow-model-meta-file-path --output model.onnx --inputs input0:0,input1:0 --outputs output0:0
# model in graphdef format
python -m tf2onnx.convert --graphdef tensorflow_model_graphdef-file --output model.onnx --inputs input0:0,input1:0 --outputs output0:0
The preceding commands describe the conversion for models in Checkpoint (https://www.tensorflow.org/api_docs/python/tf/train/Checkpoint) and GraphDef (https://www.tensorflow.org/api_docs/python/tf/compat/v1/GraphDef) formats. The key arguments are --checkpoint and --graphdef, which indicate the model format as well as the location of the source model.
tf2onnx also provides a Python API that you can find at https://github.com/onnx/tensorflow-onnx.
Next, we will look at how to convert an ONNX model into a TF model.
Converting an ONNX model into a TensorFlow model
While tf2onnx is used for conversion from TF into ONNX, onnx-tensorflow (https://github.com/onnx/onnx-tensorflow) is used for converting an ONNX model into a TF model. It is based on terminal commands as in the case of tf2onnx. The following line shows a simple onnx-tf command use case:
onnx-tf convert -i model.onnx -o tensorflow_model_file
In the preceding command, the -i parameter is used to specify the source .onnx file, and the -o parameter is used to specify the output location for the new TF model. Other use cases of the onnx-tf command are well-documented at https://github.com/onnx/onnx-tensorflow/blob/main/doc/CLI.md.
In addition, you can perform the same conversion using a Python API:
import onnx
from onnx_tf.backend import prepare
onnx_model = onnx.load("model.onnx")
tf_rep = prepare(onnx_model)
tensorflow-model-file-path = path/to/tensorflow-model
tf_rep.export_graph(tensorflow_model_file_path)In the preceding Python code, the ONNX model is loaded using the onnx.load function and then adjusted for conversion using prepare, which was imported from onnx_tf.backend. Finally, the TF model gets exported and saved to the specified location (tensorflow_model_file_path) using the export_graph function.
Things to remember
a. Conversions from TF into ONNX and from ONNX into TF are performed via onnx-tensorflow and tf2onnx, respectively.
b. Both onnx-tensorflow and tf2onnx support command-line interfaces as well as providing a Python API.
Next, we will describe how the conversions from and to ONNX are performed in PyTorch.
Conversion between PyTorch and ONNX
In this section, we will explain how to convert a PyTorch model into an ONNX model and back again. With the conversion between TF and ONNX covered in the previous section, you should be able to convert your model between TF and PyTorch as well by the end of this section.
Converting a PyTorch model into an ONNX model
Interestingly, PyTorch has built-in support for exporting its model as an ONNX model (https://pytorch.org/tutorials/advanced/super_resolution_with_onnxruntime.html). Given a model, all you need is the torch.onnx.export function as shown in the following code snippet:
import torch pytorch_model = ... # Input to the model dummy_input = torch.randn(..., requires_grad=True) onnx_model_path = "model.onnx" # Export the model torch.onnx.export( pytorch_model, # model being run dummy_input, # model input (or a tuple for multiple inputs) onnx_model_path # where to save the model (can be a file or file-like object) )
The first parameter of torch.onnx.export is a PyTorch model that you want to convert. As the second parameter, you must provide a tensor that represents a dummy input. In other words, this tensor must be the size that the model is expecting as an input. The last parameter is the local path for the ONNX model.
After triggering the torch.onnx.export function, you should see an .onnx file generated at the path you provide (onnx_model_path).
Now, let’s look at how to load an ONNX model as a PyTorch model.
Converting an ONNX model into a PyTorch model
Unfortunately, PyTorch does not have built-in support for loading an ONNX model. However, there is a popular library for this conversion called onnx2pytorch (https://github.com/ToriML/onnx2pytorch). Given that this library is installed with a pip command, the following code snippet demonstrates the conversion:
import onnx
from onnx2pytorch import ConvertModel
onnx_model = onnx.load("model.onnx")
pytorch_model = ConvertModel(onnx_model)The key class we need from the onnx2pytorch module is ConverModel. As shown in the preceding code snippet, we pass an ONNX model into this class to generate a PyTorch model.
Things to remember
a. PyTorch has built-in support for exporting a PyTorch model as an ONNX model. This process involves the torch.onnx.export function.
b. Importing an ONNX model into a PyTorch environment requires the onnx2pytorch library.
In this section, we described the conversion between ONNX and PyTorch. Since we already know how to convert a model between ONNX and TF, the conversion between TF and PyTorch comes naturally.
Summary
In this chapter, we introduced ONNX, a universal representation of ML models. The benefit of ONNX mostly comes from its model deployment, as it handles environment-specific optimization and conversions for us behind the scenes through ORT. Another advantage of ONNX comes from its interoperability; it can be used to convert a DL model generated with a framework for the other frameworks. In this chapter, we covered conversion for TensorFlow and PyTorch specifically, as they are the two most standard DL frameworks.
Taking another step toward efficient DL model deployment, in the next chapter, we will learn how to use Elastic Kubernetes Service (EKS) and SageMaker to set up a model inference endpoint.