
Chapter 8: Human-Friendly Explanations with TCAV
In the previous few chapters, we have extensively discussed LIME and SHAP. You have also seen the practical aspect of applying the Python frameworks of LIME and SHAP to explain black-box models. One major limitation of both frameworks is that the method of explanation is not extremely consistent and intuitive with how non-technical end users would explain an observation. For example, if you have an image of a glass filled with Coke and use LIME and SHAP to explain a black-box model used to correctly classify the image as Coke, both LIME and SHAP would highlight regions of the image that lead to the correct prediction by the trained model. But if you ask a non-technical user to describe the image, the user would classify the image as Coke due to the presence of a dark-colored carbonated liquid in a glass that resembles a Cola drink. In other words, human beings tend to relate any observation with known concepts to explain it.
Testing with Concept Activation Vector (TCAV) from Google AI also follows a similar approach in terms of explaining model predictions with known human concepts. So, in this chapter, we will cover how TCAV can be used to provide concept-based human-friendly explanations. Unlike LIME and SHAP, TCAV works beyond feature attribution and refers to concepts such as color, gender, race, shape, any known object, or an abstract idea to explain model predictions. In this chapter, we will discuss the workings of the TCAV algorithm. I will cover some of the advantages and disadvantages of the framework. We will also discuss using this framework for practical problem-solving. In Chapter 2, Model Explainability Methods, under Representation-based explanation, you did get some exposure to TCAV, but in this chapter, we will cover the following topics:
- Understanding TCAV intuitively
- Exploring the practical applications of TCAV
- Advantages and limitations
- Potential applications of concept-based explanations
It's time to get started now!
Technical requirements
This code tutorial and the requisite resources can be downloaded or cloned from the GitHub repository for this chapter at https://github.com/PacktPublishing/Applied-Machine-Learning-Explainability-Techniques/tree/main/Chapter08. Similar to other chapters, Python and Jupyter notebooks are used to implement the practical application of the theoretical concepts covered in this chapter. However, I would recommend you run the notebooks only after you have gone through this chapter for a better understanding.
Understanding TCAV intuitively
The idea of TCAV was first introduced by Kim et al. in their work – Interpretability beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV) (https://arxiv.org/pdf/1711.11279.pdf). The framework was designed to provide interpretability beyond feature attribution, particularly for deep learning models that rely on low-level transformed features that are not human-interpretable. TCAV aims to explain the opaque internal state of the deep learning model using abstract, high-level, human-friendly concepts. In this section, I will present you with an intuitive understanding of TCAV and explain how it works to provide human-friendly explanations.
What is TCAV?
So far, we have covered many methods and frameworks to explain ML models through feature-based approaches. But it might occur to you that since most ML models operate on low-level features, the feature-based explanation approaches might highlight features that are not human-interpretable. For example, for explaining image classifiers, pixel intensity values or pixels coordinates in an image might not be useful for end users without any technical background in data science and ML. So, these features are not user-friendly. Moreover, feature-based explanations are always restricted by the selection of features and the number of features present in the dataset. Out of all the features selected by the feature-based explanation methods, end users might be interested in a particular feature that is not picked by the algorithm.
So, instead of this approach, concept-based approaches provide a much wider abstraction that is human-friendly and more relevant as interpretability is provided in terms of the importance of high-level concepts. So, TCAV is a model interpretability framework from Google AI that implements the idea of a concept-based explanation method in practice. The algorithm depends on Concept Activation Vectors (CAV), which provide an interpretation of the internal state of ML models using human-friendly concepts. In a more technical sense, TCAV uses directional derivatives to quantify the importance of human-friendly, high-level concepts for model predictions. For example, while describing hairstyles, concepts such as curly hair, straight hair, or hair color can be used by TCAV. These user-defined concepts are not the input features of the dataset that are used by the algorithm during the training process.
The following figure illustrates the key question addressed by TCAV:
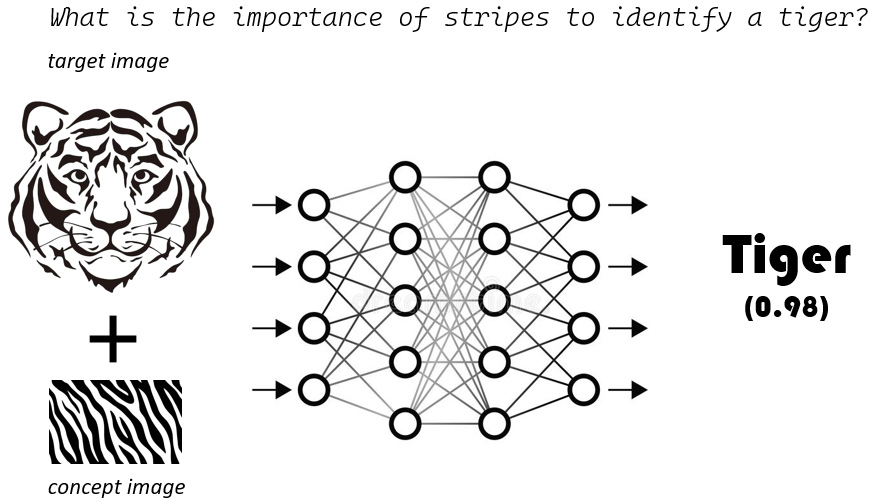
Figure 8.1 – TCAV helps us to address the key question of concept importance of a user-defined concept for image classification by a neural network
In the next section, let's try to understand the idea of model explanation using abstract concepts.
Explaining with abstract concepts
By now, you may have an intuitive understanding of the method of providing explanations with abstract concepts. But why do you think this is an effective approach? Let's take another example. Suppose you are working on building a deep learning-based image classifier for detecting doctors from images. After applying TCAV, let's say that you have found out that the concept importance of the concept white male is maximum, followed by stethoscope and white coat. The concept importance of stethoscope and white coat is expected, but the high concept importance of white male indicates a biased dataset. Hence, TCAV can help to evaluate fairness in trained models.
Essentially, the goal of CAVs is to estimate the importance of a concept (such as color, gender, and race) for the prediction of a trained model, even though the concepts were not used during the model training process. This is because TCAV learns concepts from a few example samples. For example, in order to learn a gender concept, TCAV needs a few data instances that have a male concept and a few non-male examples. Hence, TCAV can quantitatively estimate the trained model's sensitivity to a particular concept for that class. For generating explanations, TCAV perturbs data points toward a concept that is relatable to humans, and so it is a type of global perturbation method. Next, let's try to learn the main objectives of TCAV.
Goals of TCAV
I found the approach of TCAV to be very unique as compared to other explanation methods. One of the main reasons is because the developers of this framework established clear goals that resonate with my own understanding of human-friendly explanations. The following are the established goals of TCAV:
- Accessibility: The developers of TCAV wanted this approach to be accessible to any end user, irrespective of their knowledge of ML or data science.
- Customization: The framework can adapt to any user-defined concept. This is not limited to concepts considered during the training process.
- Plug-in readiness: The developers wanted this approach to work without the need to retrain or fine-tune trained ML models.
- Global interpretability: TCAV can interpret the entire class or multiple samples of the dataset with a single quantitative measure. It is not restricted to the local explainability of data instances.
Now that we have an idea of what can be achieved using TCAV, let's discuss the general approach to how TCAV works.
Approach of TCAV
In this section, we will cover the workings of TCAV in more depth. The overall workings of this algorithm can be summarized in the following methods:
- Applying directional derivatives to quantitatively estimate the sensitivity of predictions of trained ML models for various user-defined concepts.
- Computing the final quantitative explanation, which is termed TCAVq measure, without any model re-training or fine-tuning. This measure is the relative importance of each concept to each model prediction class.
Now, I will try to further simplify the approach of TCAV without using too many mathematical notions. Let's assume we have a model for identifying zebras from images. To apply TCAV, the following approach can be taken:
- Defining a concept of interest: The very first step is to consider the concepts of interest. For our zebra classifier, either we can have a given set of examples that represent the concept (such as black stripes are important in identifying a zebra) or we can have an independent dataset with the concepts labeled. The major benefit of this step is that it does not limit the algorithm from using features used by the model. Even non-technical users or domain experts can define the concepts based on their existing knowledge.
- Learning concept activation vectors: The algorithm tries to learn a vector in the space of activation of the layers by training a linear classifier to differentiate between activations generated by a concept's instances and instances present in any layer. So, a CAV is defined as the normal projection to a hyperplane that separates instances with a concept and instances without a concept in the model's activation. For our zebra classifier, CAVs help to distinguish representations that denote black stripes and representations that do not denote black stripes.
- Estimating directional derivatives: Directional derivatives are used to quantify the sensitivity of a model prediction toward a concept. So, for our zebra classifier, directional directives help us to measure the importance of the black stripes representation in predicting zebras. Unlike saliency maps, which use per-pixel saliency, directional derivatives are computed on the entire dataset or a set of inputs but for a specific concept. This helps to give a global perspective for the explanation.
- Estimating the TCAV score: To quantify the concept importance of a particular class, the TCAV score (TCAVq) is calculated. This metric helps to measure the positive or negative influence of a defined concept on a particular activation layer of a model.
- CAV validation: CAV can be produced from randomly selected data. But unfortunately, this might not produce meaningful concepts. So, in order to improve the generated concepts, TCAV runs multiple iterations for finding concepts from different batches of data, instead of training CAV once, on a single batch of data. Then, a statistical significance test is performed using two-side t-test for selecting the statistically significant concepts. Necessary corrections, such as the Bonferroni correction, are also performed to control the false discovery rate.
Thus, we have covered the intuitive workings of the TCAV algorithm. Next, let's cover how TCAV can actually be implemented in practice.
Exploring the practical applications of TCAV
In this section, we will explore the practical applications of TCAV for explaining pre-trained image explainers with concept importance. The entire notebook tutorial is available in the code repository of this chapter at https://github.com/PacktPublishing/Applied-Machine-Learning-Explainability-Techniques/blob/main/Chapter08/Intro_to_TCAV.ipynb. This tutorial is presented based on the notebook provided in the original GitHub project repository of TCAV https://github.com/tensorflow/tcav. I recommend that you all refer to the main project repository of TCAV since the credit for implementation should go to the developers and contributors of TCAV.
In this tutorial, we will cover how to apply TCAV to validate the concept importance of the concept of stripes as compared to the honeycomb pattern for identifying tigers. The following images illustrate the flow of the approach used by TCAV to ascertain concept importance using a simple visualization:
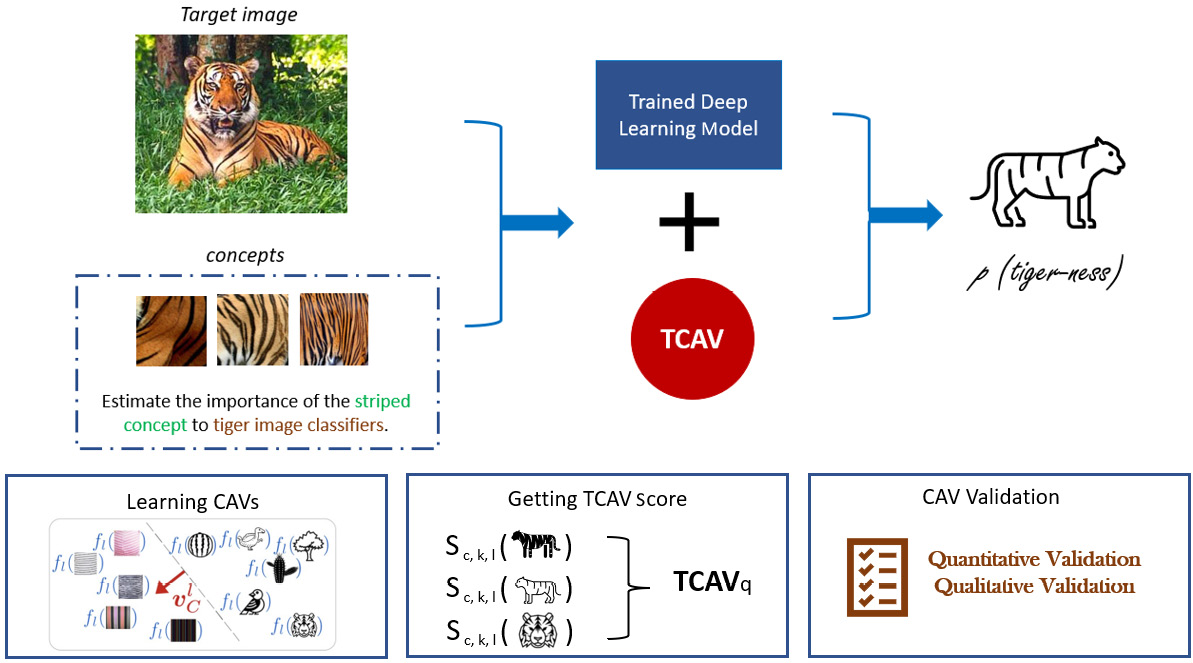
Figure 8.2 – Using TCAV to estimate the concept importance of stripes in a tiger image classifier
Let's begin by setting up our Jupyter notebook.
Getting started
Similar to the other tutorial examples covered in the previous chapters, to install the necessary Python modules required to run the notebook, you can use the pip install command in a Jupyter notebook:
!pip install --upgrade pandas numpy matplotlib tensorflow tcav
You can import all the modules to validate the successful installation of these frameworks:
import tensorflow as tf
import tcav
Next, let's take a look at the data that we'll be working with.
About the data
I felt that the data preparation process, which is provided in the original project repository of TCAV, is slightly time-consuming. So, I have already prepared the necessary datasets, which you can refer to from this project repository. Since we will be validating the importance of the concept of stripes for images of tigers, we will need an image dataset for tigers. The data is collected from the ImageNet collection and is provided in the project repository at https://github.com/PacktPublishing/Applied-Machine-Learning-Explainability-Techniques/tree/main/Chapter08/images/tiger. The images are randomly curated and collected using the data collection script provided in the TCAV repository: https://github.com/tensorflow/tcav/tree/master/tcav/tcav_examples/image_models/imagenet.
In order to run TCAV, you would need to have the necessary concept images, target class images, and random dataset images. For this tutorial, I have prepared the concept images from the Broden dataset (http://netdissect.csail.mit.edu/data/broden1_224.zip), as suggested in the main project example. Please go through the research work that led to the creation of this dataset: https://github.com/CSAILVision/NetDissect. You can also explore the Broden dataset texture images provided at https://github.com/PacktPublishing/Applied-Machine-Learning-Explainability-Techniques/tree/main/Chapter08/concepts/broden_concepts to learn more. I recommend you to experiment with other concepts or other images and play around with TCAV-based concept importance!
Broden dataset
David Bau*, Bolei Zhou*, Aditya Khosla, Aude Oliva, and Antonio Torralba. Network Dissection: Quantifying Interpretability of Deep Visual Representations. Computer Vision and Pattern Recognition (CVPR), 2017.
As TCAV also requires some random datasets to ascertain the statistical significance of the concepts learned from target image examples, I have provided some sample random images in the project repository, thereby simplifying the running of the tutorial notebook! But as always, you should experiment with other random image examples as well. These random images are also collected using the image fetcher script provided in the main project: https://github.com/tensorflow/tcav/blob/master/tcav/tcav_examples/image_models/imagenet/download_and_make_datasets.py.
To proceed further, you need to define the variables for the target class and the concepts:
target = 'tiger'
concepts = ['honeycombed', 'striped']
You can also create the necessary paths and directories to store the generated activations and CAVs as mentioned in the notebook tutorial. Next, let's discuss the model used in this example.
Discussions about the deep learning model used
In this example, we will use a pre-trained deep learning model to highlight the fact that even though TCAV is considered to be a model-specific approach, as it is only applicable to neural networks, it does not make an assumption of the network architecture as such and can work well with most deep neural network models.
For this example, we will use the pre-trained GoogleNet model, https://paperswithcode.com/method/googlenet, based on the ImageNet dataset (https://www.image-net.org/). The model files are provided in the code repository: https://github.com/PacktPublishing/Applied-Machine-Learning-Explainability-Techniques/tree/main/Chapter08/models/inception5h. You can load the trained model using the following lines of code:
model_to_run = 'GoogleNet'
sess = utils.create_session()
GRAPH_PATH = "models/inception5h/tensorflow_inception_graph.pb"
LABEL_PATH = "models/inception5h/imagenet_comp_graph_label_strings.txt"
trained_model = model.GoogleNetWrapper_public(sess,
GRAPH_PATH,
LABEL_PATH)
The model wrapper is actually used to get the internal state and tensors of the trained model. Concept importance is actually computed based on the internal neuron activations and hence, this model wrapper is important. For more details about the workings of the internal API, please refer to the following link: https://github.com/tensorflow/tcav/blob/master/Run_TCAV_on_colab.ipynb.
Next, we would need to generate the concept activations using the ImageActivationGenerator method:
act_generator = act_gen.ImageActivationGenerator(
trained_model, source_dir, activation_dir,
max_examples=100)
Next, we will explore model explainability using TCAV.
Model explainability using TCAV
As discussed before, TCAV is currently used to explain neural networks and the inner layers of a neural network. So, it is not model-agnostic, but rather a model-centric explainability method. This requires us to define the bottleneck layer of the network:
bottlenecks = [ 'mixed4c']
The next step will be to apply the TCAV algorithm to create the concept activation vectors. The process also includes performing statistical significance testing using two side t-test between the concept importance of the target class and the random samples:
num_random_exp= 15
mytcav = tcav.TCAV(sess,
target,
concepts,
bottlenecks,
act_generator,
[0.1],
cav_dir=cav_dir,
num_random_exp=num_random_exp)
The original experiment mentioned in the TCAV paper, https://arxiv.org/abs/1711.11279, mentioned using at least 500 random experiments to identify the statistically significant concepts. But for the sake of simplicity, and to achieve faster results, we are using 15 random experiments. You can experiment with more random experiments as well.
Finally, we can get the results and visualize the concept importance:
results = mytcav.run(run_parallel=False)
utils_plot.plot_results(results,
num_random_exp=num_random_exp)
This will generate the following plot that helps us to compare concept importance:
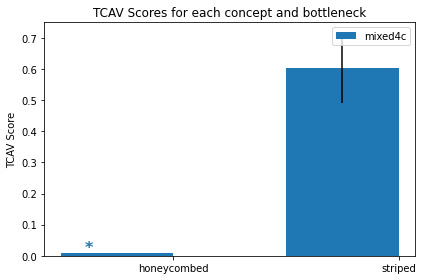
Figure 8.3 – TCAV concept importance of the concepts of striped and honeycombed for identifying tiger images
As you can observe from Figure 8.3, the striped concept has significantly higher concept importance than the honeycombed concept for identifying tigers.
Now that we have covered the practical application part, let me give you a similar challenge as an exercise. Can you now use the ImageNet dataset and ascertain the importance of the concept of water to ships and of clouds or sky to airplanes? This will help you understand this concept in more depth and give you more confidence to apply TCAV. Next, we will discuss some advantages and limitations of TCAV.
Advantages and limitations
In the previous section, we covered the practical aspects of TCAV. TCAV is indeed a very interesting and novel approach to explaining complex deep learning models. Although it has many advantages, unfortunately, I did find some limitations in terms of the current framework that can definitely be improved in the revised version.
Advantages
Let's discuss the following advantages first:
- As you have previously seen with the LIME framework in Chapter 4, LIME for Model Interpretability (which generates explanations using a global perturbation method), there can be contradicting explanations for two data instances for the same class. Even though TCAV is also a type of global perturbation method, unlike LIME, TCAV-generated explanations are not only true for a single data instance but also true for the entire class. This is a major advantage of TCAV over LIME, which increases the user's trust in the explanation method.
- Concept-based explanations are closer to how humans would explain an unknown observation, rather than feature-based explanations as adopted in LIME and SHAP. So, TCAV-generated explanations are indeed more human-friendly.
- Feature-based explanations are limited to the features used in the model. To introduce any new feature for model explainability, we would need to re-train the model, whereas a concept-based explanation is more flexible and is not limited to features used during model training. To introduce a new concept, we do not need to retrain the model. Also, for introducing the concepts, you don't have to know anything about ML. You would just have to make the necessary datasets to generate concepts.
- Model explainability is not the only benefit of TCAV. TCAV can help to detect issues during the training process, such as imbalanced datasets leading to bias in the dataset vis-à-vis the majority class. In fact, concept importance can be used as a metric to compare models. For example, suppose you are using a VGG19 model and a ResNet50 model. Let's say both these models have similar accuracy and model performance, yet concept importance for a user-defined concept is much higher for the VGG19 model as compared to the ResNet50 model. In such a case, it is better to use the VGG19 model as compared to ResNet50. Hence, TCAV can be used to improve the model training process.
These are some of the distinct advantages of TCAV, which makes it more human-friendly than LIME and SHAP. Next, let's discuss some known limitations of TCAV.
Limitations
The following are some of the known disadvantages of the TCAV approach:
- Currently, the approach of concept-based explanation using TCAV is limited to just neural networks. In order to increase its adoption, TCAV would need an implementation that can work with classical machine learning algorithms such as Decision Trees, Support Vector Machines, and Ensemble Learning algorithms. Both LIME and SHAP can be applied with classical ML algorithms to solve standard ML problems and that is probably why LIME and SHAP have more adoption. Similarly, with text data, too, TCAV has very limited applications.
TCAV is highly prone to data drift, adversarial effects, and other data quality issues discussed in Chapter 3, Data-Centric Approaches. If you are using TCAV, you would need to ensure that training data, inference data, and even concept data have similar statistical properties. Otherwise, the concepts generated can become affected due to noise or data impurity issues:
- Guillaume Alain and Yoshua Bengio, in their paper Understanding intermediate layers using linear classifier probes (https://arxiv.org/abs/1610.01644), have expressed some concern about applying TCAV to shallower neural networks. Many similar research papers have suggested that concepts in deeper layers are more separable as compared to concepts in shallower networks and, hence, the use of TCAV is limited to mostly deep neural networks.
- Preparing a concept dataset can be a challenging and expensive task. Although you don't need ML knowledge to prepare a concept dataset, still, in practice, you do not expect any common end user to spend time creating an annotated concept dataset for any customized user-defined concept.
- I felt that the TCAV Python framework would require further improvements before being used in any production-level system. In my opinion, at the time of writing this chapter, this framework would need to mature further so that it can be used easily with any production-level ML system.
I think all these limitations can indeed be solved to make TCAV a much more robust framework that is widely adopted. If you are interested, you can also reach out to authors and developers of the TCAV framework and contribute to the open source community! In the next section, let's discuss some potential applications of concept-based explanations.
Potential applications of concept-based explanations
I do see great potential for concept-based explanations such as TCAV! In this section, you will get exposure to some potential applications of concept-based explanations that can be important research topics for the entire AI community, which are as follows:
- Estimation of transparency and fairness in AI: Most regulatory concerns for black-box AI models are related to concepts such as gender, color, and race. Concept-based explanations can actually help to estimate whether an AI algorithm is fair in terms of these abstract concepts. The detection of bias for AI models can actually improve its transparency and help to address certain regulatory concerns. For example, in terms of doctors using deep learning models, TCAV can be used to detect whether the model is biased toward a specific gender, color, or race as ideally, these concepts are not important as regards the model's decision. High concept importance for these concepts indicates the presence of bias. Figure 8.4 illustrates an example where TCAV is used to detect model bias.
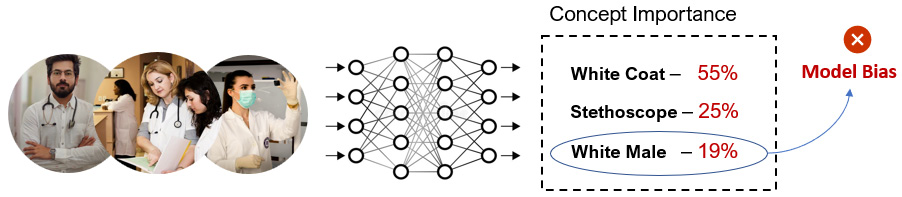
Figure 8.4 – TCAV can be used to detect model bias based on concept importance
- Detection of adversarial attacks with CAV: If you go through the appendix of the TCAV research paper (https://arxiv.org/pdf/1711.11279.pdf), the authors have mentioned that the concept importance of actual samples and adversarial samples are quite different. This means that if an image gets impacted by an adversarial attack, the concept importance would also change. So, CAVs can be a potential method in detecting adversarial attacks, as discussed in Chapter 3, Data-Centric Approaches.
- Concept-based image clustering: Using CAVs to cluster images based on similar concepts can be an interesting application. Deep learning-based image search engines are a common application in which clustering or similarity algorithms are applied to feature vectors to locate similar images. However, these are feature-based methods. Similarly, there is a potential to apply concept-based image clustering using CAVs.
- Automated concept-based explanations (ACE): Ghorbani, Amirata, James Wexler, James Zou, and Been Kim, in their research work – Towards automatic concept-based explanations, mentioned an automated version of TCAV that goes through the training images and automatically discovers prominent concepts. This is an interesting work, as I think it can have an important application in identifying incorrectly labeled training data. In industrial applications, getting a perfectly labeled curated dataset is extremely challenging. This problem can be solved to a great extent using ACE.
- Concept-based Counterfactual Explanation: In Chapter 2, Model Explainability Methods, we discussed counterfactual explanation (CFE) as a mechanism for generating actionable insights by suggesting changes to the input features that can change the overall outcome. However, CFE is a feature-based explanation method. It would be a really interesting topic of research to have a concept-based counterfactual explanation, which is one step closer to human-friendly explanations.
For example, if we say that it is going to rain today although there is a clear sky now, we usually add a further explanation that suggests that the clear sky can be covered with clouds, which increases the probability of rainfall. In other words, a clear sky is a concept related to a sunny day, while a cloudy sky is a concept related to rainfall. This example suggests that the forecast can be flipped if the concept describing the situation is also flipped. Hence, this is the idea of the concept-based counterfactual. The idea is not very far-fetched as concept bottleneck models (CBMs) presented in the research work by Koh et al., in https://arxiv.org/abs/2007.04612, can implement a similar idea of generated concept-based counterfactuals by manipulating the neuron action of the bottleneck layer.
Figure 8.5 illustrates an example of using a concept-based counterfactual example. There is no existing algorithm or framework that can help us achieve this, yet this can be a useful application of concept-based approaches in computer vision.
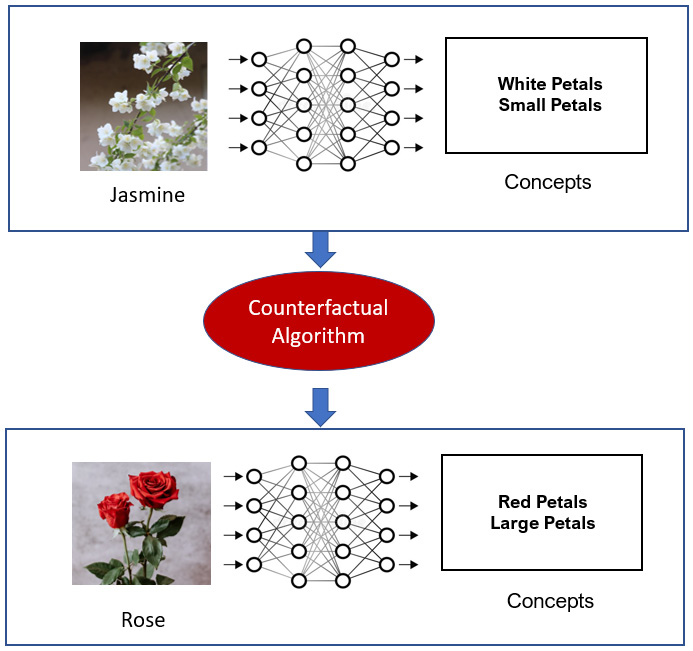
Figure 8.5 – An illustration of the idea of concept-based counterfactual examples
I feel this is a wide-open research field and the potential to come up with game-changing applications using concept-based explanations is immense. I do sincerely hope that more and more researchers and AI developers start working on this area to make significant progress in the coming years! Thus, we have arrived at the end of this chapter. Let me now summarize what has been covered in this chapter in the next section.
Summary
This chapter covers the concepts of TCAV, a novel approach, and a framework developed by Google AI. You have received a conceptual understanding of TCAV, practical exposure to applying the Python TCAV framework, learned about some key advantages and limitations of TCAV, and finally, I presented some interesting ideas regarding potential research problems that can be solved using concept-based explanations.
In the next chapter, we will explore other popular XAI frameworks and apply these frameworks to solving practical problems.
References
Please refer to the following resources to gain additional information:
- Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV): https://arxiv.org/pdf/1711.11279.pdf
- TCAV Python framework - https://github.com/tensorflow/tcav
- Koh et al. "Concept Bottleneck Models": https://arxiv.org/abs/2007.04612
- Guillaume Alain and Yoshua Bengio, "Understanding intermediate layers using linear classifier probes": https://arxiv.org/abs/1610.01644
- Ghorbani, Amirata, James Wexler, James Zou and Been Kim, "Towards automatic concept-based explanations": https://arxiv.org/abs/1902.03129
- Detecting Concepts, Chapter 10.3 Molnar, C. (2022). Interpretable Machine Learning: A Guide for Making Black Box Models Explainable (2nd ed.).: https://christophm.github.io/interpretable-ml-book/detecting-concepts.html