
In this chapter, you will learn how to implement classes from your domain model in order to make them work well with Coherence. While for the most part you can design and implement your objects the way you normally do, the fact that they will be stored within a distributed cache does impose some additional requirements and restrictions.
For one, your objects have to be serializable in order to be moved across the process and machine boundaries. The easiest way to accomplish this is by implementing the java.io.Serializable interface, but there are several alternative serialization mechanisms you can use with Coherence that perform better and result in a significantly smaller binary representation of your data. The latter is extremely important when you are working with an in-memory data grid, such as Coherence, as the more compact serialization format can save you quite a bit of money in terms of the hardware and software licenses you need.
Second, you need to plan ahead to allow for easy schema evolution of your data objects. While you don't have to worry about this too much when you use Coherence simply as a caching layer, many applications can benefit from using Coherence as a system of record and a database simply as a persistent data store. In those cases, it is typically undesirable, and sometimes even impossible, to bring the whole cluster down for an upgrade. Instead, you need to be able to upgrade the cluster node by node, while keeping the system as a whole fully operational and allowing multiple versions of the same classes to co-exist within the cluster. Coherence allows you to achieve this in a very effective way, but it does require a certain degree of assistance from you in order to make it happen.
Finally, you need to ensure that your application does not depend on sharing state (references to the same shared object) across multiple data objects. While dependence on the shared state is generally a bad idea and should be avoided, it will become your worst nightmare if your objects rely on it and you try to use them with Coherence (or any other distributed caching product, for that matter).
The reason for that is that your objects can share state only when they coexist within the same process. Once they get serialized and sent to another machine (which happens all the time in an application backed by a distributed cache), each one will have its own copy of the shared data, and will retain its own copy when deserialized.
We will discuss all of these topics shortly and you will learn how to make your objects good citizens of a Coherence cluster. But first, let's set the stage by defining the domain model for the sample application that will be used throughout the book.
If you are anything like me, you will agree that a good sample application is priceless. In this chapter, we will create the core domain model for Coherent Bank, a sample banking application that you can download from the book's website. We will continue to build it throughout the book, and I hope that you will find the end result as interesting to read as it was to write.
Note
Oversimplification warning
I apologize in advance to the readers that write banking software for living—the requirements and the domain model that follow are severely constrained and oversimplified.
The goal is not to teach anyone how to write a banking application, but how to use Coherence. A banking application was chosen because most, if not all readers, are familiar with the problem domain, at least at the superficial level presented here.
Our sample application has three major components.
The first one is a customer-oriented online banking portal that allows customers to register, open accounts, pay bills, and view posted transactions. This is a typical Java web application that uses Spring MVC to implement REST services. We used Ext JS (www.extjs.com) to implement the UI, but you can easily replace it with the presentation technology of your choice.
The second component is a branch terminal application that is used by bank employees to check account balances and make cash deposits and withdrawals for the customers. This is a .NET desktop application written in C# that uses Windows Presentation Foundation (WPF) to implement the presentation layer.
Finally, no bank should be without ATMs, so we implemented a small command line application in C++ that emulates ATM deposits and withdrawals.
As you can see, the technical scope of the application is fairly broad, covering all three platforms that are supported by Coherence. While this does add some complexity to the sample application, please keep in mind that you don't have to read and understand the code for all three applications.
The bulk of the core logic for the application is implemented in Java, and that is what we'll focus on most. However, I do believe that it is important to show how that same logic can be invoked from .NET and C++ clients as well, and that the readers who need to build client applications using one of those two platforms will find the latter two examples very useful.
In order to keep things simple despite the fact that we are creating a multi-platform application, we have decided to implement only a very small set of business requirements:
A customer must be able to open one or more accounts.
A customer must be able to deposit money into and withdraw money from the accounts either in the branch or using an ATM.
A customer must be able to pay bills using an online banking portal.
A customer must be able to view account transactions (deposits and withdrawals) for a given period.
Withdrawal should only be allowed if there are sufficient funds in the account.
Each account has a designated currency. All deposits and withdrawals in other currencies must be automatically converted to the account currency.
These requirements should be enough to make the implementation interesting without making it overly complex.
Based on the previous requirements, we can define the following domain model to use as a starting point:
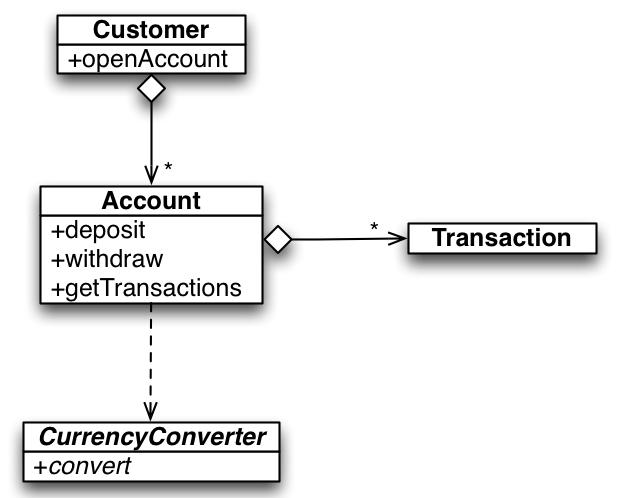
The preceding model is just a rough sketch containing the most important classes in the system. As we go along we will refine it and extend it, but for the time being this should be more than enough.
If you have read Domain Driven Design by Eric Evans [DDD], much of the information in this section will simply refresh your knowledge of the domain model building blocks described by Eric, with a Coherence twist. If you haven't, this section will give you enough background information to allow you to identify various domain objects within the application, but I strongly suggest that you read Eric's book for a much more complete coverage of the topics presented here (and many others).
Note
Rich versus Anemic domain models
The main argument Eric Evans makes in Domain Driven Design is that your domain objects should be used to implement business logic of your application, not just to hold data. While this logically makes perfect sense, it is not what most developers are used to, primarily because such architecture was discouraged by the J2EE spec, which pretty much required from you to turn your domain objects into property bags and implement all the logic in a higher-level service layer using session EJBs.
If you still develop the applications that way, you might be wondering if Coherence requires you to use rich domain objects. The short answer is: no, it does not. You can use any object with Coherence, as long as it is serializable, so you can easily use anemic domain objects as well.
The question, however, is why you would want to do that. If you are already creating custom classes for your objects, you might as well take the extra step and implement related behavior within them as well, instead of moving all the logic to a higher-level service layer. Otherwise, as Martin Fowler points out in his article Anemic Domain Model (http://martinfowler.com/bliki/AnemicDomainModel.html), you will be "robbing yourself blind and paying all the costs of a domain model without yielding any of the benefits".
After all, there isn't much you can achieve with an anemic domain object that you can't do using a more generic and readily available data structure, such as a map, so why even bother with custom objects if they are just dumb data holders?
In Domain Driven Design, Eric identifies a number of core building blocks of the domain model, such as entities, aggregates, value objects, services, factories, and repositories. The first three represent data objects in the model, and as such are the most important domain model artifacts from our perspective—they are what we will be storing in Coherence.
An entity is an object that has an identity. The identity can be either a natural attribute of an object, such as the country code we used to identify Country objects in Chapter 2, Getting Started, or it can be a surrogate attribute that is generated by the system when the entity is first created. Regardless of the type of identity, what is important is that once an identity is assigned to an entity, it remains the same throughout its lifetime.
An aggregate is a special, composite entity type, which represents a containment relationship between an aggregate root and dependent weak entities. For example, an order contains one or more line items, and while both the order and each individual line item are entities in their own right, a single line item is only meaningful within the larger context of an order.
Entities and aggregates are the most important types of domain objects from the Coherence perspective, as they usually have one-to-one mapping to Coherence caches.
One of the most common mistakes that beginners make is to treat Coherence as an in-memory database and create caches that are too finely grained. For example, they might configure one cache for orders and a separate cache for line items.
While this makes perfect sense when using a relational database, it isn't the best approach when using Coherence. Aggregates represent units of consistency from a business perspective, and the easiest way to achieve atomicity and consistency when using Coherence is to limit the scope of mutating operations to a single cache entry. Because of this, you should almost always store whole aggregates as individual cache entries. In the previous example that we used, an order and all of its line items would be stored as a single cache entry in the orders cache.
One exception to this rule might be the case when the aggregate root contains an unbound, continuously growing collection of dependent entities, such as Account and Transaction items in our domain model. In this case, it makes sense to separate dependent entities into their own cache, in order to avoid infinite growth of the aggregate object and to allow different caching policies to be used (for example, we might decide to keep all the accounts in the cache at all times, but only the last 60 days of transactions for each account, in order to keep the amount of memory used by transactions relatively constant over time).
The domain model for our banking application contains three entities so far: Customer, Account, and Transaction. The last two form an aggregate, with the Account as aggregate root.
Because an entity is such an important type of object within a Coherence application, we will define an interface that all our entities have to implement:
public interface Entity<T> {
T getId();
}
The Entity interface is very simple, but it makes the fact that entities have an identity explicit. This is not strictly required, but it will come in handy on many occasions, such as when we implement repositories for our entities, as you'll see in a bit.
Entity implementation is quite simple for the most part: you define the attributes as you normally would and implement the necessary operations. In the case of the Account class, this might lead you to create something along these lines:
public class Account
implements Entity<Long>, Serializable {
// data members
private final Long m_id;
private final Long m_customerId;
private String m_description;
private Money m_balance;
private int m_lastTransactionId;
// dependencies
private transient CurrencyConverter m_currencyConverter;
private transient TransactionRepository m_transactionRepository;
// constructor, getters and setters omitted for brevity
...
// core logic
public Money withdraw(Money amount, String description)
throws InsufficientFundsException {
Money balance = m_balance;
if (!balance.isSameCurrency(amount)) {
CurrencyConversion conversion =
getCurrencyConverter().convert(amount, getCurrency());
amount = conversion.getConvertedAmount();
description += " (" +
conversion.getOriginalAmount() + " @ " +
conversion.getExchangeRate() + ")";
}
if (amount.greaterThan(balance)) {
throw new InsufficientFundsException(balance, amount);
}
entity, domain model building blocksimplementingm_balance = balance = balance.subtract(amount);
postTransaction(TransactionType.WITHDRAWAL, description, amount, balance);
return balance;
}
public Money deposit(Money amount, String description) {
// omitted for brevity (similar to withdraw)
}
protected void postTransaction(TransactionType type,
String description,
Money amount, Money balance) {
Transaction transaction =
Transaction.create(m_id, ++m_lastTransactionId,
type, description,
amount, balance);
getTransactionRepository().save(transaction);
}
}
As you can see, except for the fact that we've implemented the Entity interface and made the class Serializable, there is nothing particularly interesting about this class. The logic within it is expressed using concepts from a domain and there is absolutely nothing that ties it to Coherence.
However, we are not done yet, as there are few more things to consider.
If an entity has a natural attribute that can be used to uniquely identify an instance of an entity, it is usually best to use that attribute as an identity. Unfortunately, many entities do not have such an attribute, in which case a surrogate identity must be generated by the system and assigned to entity instance.
Most databases provide a built-in mechanism for this purpose. For example, SQL Server allows you to define a numeric field that is automatically incremented when a new record is inserted into the table, while Oracle has a sequence mechanism, which allows you to get the next number for the named sequence object and use it within your INSERT statement. Another option is to generate and use a GUID (Globally Unique Identifier) object as an identity, which might be the best (or even required) option for scenarios where replication and synchronization across multiple independent data stores is required.
When you use the identity generation features of your database, you essentially let it handle all the grunt work for you and your biggest problem becomes how to obtain the generated identifier from the database and update your in-memory object to reflect it.
Coherence, on the other hand, forces you to define an object's identity up front. Because identity is typically used as a cache key, it is impossible to put an object into the cache unless you have a valid identifier for it. Unfortunately, while Coherence allows you to use UUIDs (Universally Unique Identifiers) as object identifiers and even provides an excellent, platform independent implementation of UUID, it does not have an out-of-the-box mechanism for sequential identifier generation. However, it is not too difficult to implement one, and the Coherence Tools open source project I mentioned earlier provides one such implementation in the form of SequenceGenerator class.
The SequenceGenerator is very simple to use. All you need to do is create an instance of it, passing sequence name and the number of identifiers the client should allocate on each call to the server (a variation of a Hi/Lo algorithm). The generator uses Coherence cache internally to keep track of all the sequences, which allows it to be used from any cluster member. It is also thread-safe and intended to be shared by instances of an entity that it creates identifiers for, so you will typically create it as a static final field:
public class Account
implements Entity<Long>, Serializable {
private static IdentityGenerator<Long> s_idGen =
SequenceGenerator.create("account.id", 20);
...
}
Now that we have identity generator, we should ensure that whenever a new object is created it is assigned a unique identity. While we could do this in a constructor, the idiom I like to use is to keep the constructor private and to provide a static factory method that is used to create new entity instances:
public class Account
implements Entity<Long>, Serializable {
...
private Account(Long id, Long customerId,
String description, Money balance) {
m_id = id;
m_customerId = customerId;
m_description = description;
m_balance = balance;
}
static Account create(Customer customer,
String description,
Currency currency) {
return new Account(s_idGen.generateIdentity(),
customer.getId(),
description,
new Money(0, currency));
}
...
}
This way a single constructor can be used to properly initialize an object instance not only during the initial creation, but also when the object is loaded from a persistent store or deserialized, as we'll see shortly.
One thing you might've noticed in the previous examples is that the Account does not have a direct reference to a Customer. Instead, we only store the Customer's identifier as part of the Account's state and use it to obtain the customer when necessary:
public class Account
entity, domain model building blocksrelationships, managingimplements Entity<Long>, Serializable {
private final Long m_customerId;
...
public Customer getCustomer() {
return getCustomerRepository()
.getCustomer(m_customerId);
}
}
This is a common pattern when using Coherence, as identity lookups from a cache are cheap operations, especially if we configure near caching for the customers cache in this example. By doing this, we ensure that a Customer, which can be shared by several Account classes, is always obtained from the authoritative source and avoid the issues that would be caused if the shared Customer instance was serialized as part of each Account object that references it.
On the other hand, this is only one side of the relationship. How would we model a one-to-many relationship, such as the relationship between a Customer and several Account classes, or an Account and several Transaction classes?
There are two possible approaches. The first one is to query the cache on the many side of the relationship. For example, we could query the accounts cache for all the accounts that have a specific customer id. This is essentially the same approach you use with a relational database when you query a child table based on the foreign key that identifies the parent.
However, with Coherence you also have another option that will yield significantly better performance—you can store the identifiers of the child objects within the parent, and simply perform a getAll operation against the underlying Coherence cache when you need to retrieve them:
public class Customer
implements Entity<Long>, Serializable {
private Collection<Long> m_accountIds;
...
public Collection<Account> getAccounts() {
return getAccountRepository()
.getAccounts(m_accountIds);
}
}
This approach makes sense when the number of child objects is finite and you don't need to constrain the results in some other way. Neither of these is true for the getTransactions methods of the Account class—the transaction collection will likely grow indefinitely and the results of the getTransactions call need to be constrained by a time period. In this case, query against the transactions cache is a better approach.
Note
Leaky abstractions
Notice that in the previous example, I passed a collection of account ids directly to the getAccounts repository method, which leaks the fact that we are doing a bulk identity lookup from the underlying store.
This might make it difficult to implement a repository for the store that doesn't support such operation or might force us to implement it in a suboptimal manner. For example, if we had to implement the same repository for a relational database, our only option would be to use an IN clause when selecting from a child table. While this is not the end of the world, a more natural and better performing approach would be to query the child table on the foreign key.
We can make that possible by modifying the repository interface to expose the getAccountsForCustomer method that accepts a Customer instance instead of a collection of account ids. That way the Coherence repository implementation would be able to perform identity lookup and the database repository implementation could execute the query on the foreign key.
The downside of such a change is that we would have to expose a getter for m_accountIds field to the outside world, which would break encapsulation. Considering that repositories tend to be leaky abstraction anyway and that they are rarely implemented for more than one specific persistence technology, the benefits of such change are questionable.
Both examples in the previous section had an external dependency on a repository, which begs the question on how these dependencies are provided to entities and by whom.
In a conventional application you could use Spring in combination with AspectJ or Dependency Injection features of your ORM to inject necessary dependencies into entities. However, implementing either of these approaches in a distributed system can be tricky, due to the fact that most repository implementations are not serializable.
The pattern I like to use is to lazily initialize dependencies by looking them up from a Registry:
private transient CustomerRepository m_customerRepository;
protected CustomerRepository getCustomerRepository() {
if (m_customerRepository == null) {
m_customerRepository =
RepositoryRegistry.getCustomerRepository();
}
return m_customerRepository;
}
public void setCustomerRepository(CustomerRepository customerRepository) {
m_customerRepository = customerRepository;
}
In this example, the m_customerRepository field is lazily initialized by retrieving a CustomerRepository instance from a RepositoryRegistry. The registry itself is a singleton that simply wraps Spring application context, which enables easy configuration of concrete repository implementations to use.
Finally, the setter allows injection of fakes or mocks within unit tests, which significantly simplifies testing by not requiring the registry to be configured.
In some cases you might want to tell Coherence to store related objects together. For example, if we had a way to ensure that all the transactions for any given account are stored within the same cache partition, we would be able to optimize the query that returns transactions for an account by telling Coherence to only search that one partition. That means that in a well-balanced cluster with a million transactions in a cache and thousand partitions, we would only need to search one thousandth of the data, or 1,000 transactions, to find the ones we need.
While it is not possible to tell Coherence explicitly where to put individual cache entries, there is a way to specify which objects should be collocated within the same partition.
Coherence uses the cache entry key (or entity identifier, depending how you look at it) to determine which node and cache partition an entry should be stored on. If you want to ensure that two entries are stored within the same partition, all you need to do is tell Coherence how to associate their keys.
You can achieve this in two different ways:
By having your key classes implement the
KeyAssociationinterfaceBy implementing and configuring an external
KeyAssociator
Both approaches require that you implement custom classes for your related objects' keys, typically as value objects containing the identifier of the parent object you want to associate with in addition to the object's own identifier. For example, in order to associate Transaction instances with the Account they belong to, we can implement a custom identity class as follows:
public class Transaction
implements Entity<Id>, Serializable {
...
public static class Id implements Serializable, KeyAssociation {
private Long m_accountId;
private Long m_txNumber;
public LineItemId(Long accountId, Long txNumber) {
m_accountId = accountId;
m_txNumber = txNumber;
}
public Object getAssociatedKey() {
return m_accountId;
}
public boolean equals(Object o) {
...
}
public int hashCode() {
...
}
}
}
The previous example uses the first of the two approaches, the KeyAssociation interface. The implementation of that interface is a single method, getAssociatedKey, which in this case returns the identifier of the parent Account instance.
The second approach requires you to implement key association logic in a separate class:
public class TransactionAssociator implements KeyAssociator {
public void init(PartitionedService partitionedService) {
}
}
If you choose this approach, you will also need to configure the line items cache to use the TransactionAssociator:
<distributed-scheme> <!-- ... --> </distributed-scheme>
Regardless of how you establish the association between your entities, Coherence will use the value returned by the getAssociatedKey method instead of the key itself to determine the storage partition for an object. This will ensure that all transactions for an account are stored within the same partition as the account itself.
Key association is not limited to aggregates and can be used to ensure that any related entities are collocated within the same partition. However, separately stored weak entities are usually very good candidates for key association, so you should keep that in mind when designing your domain model.
One potential issue with data affinity is that it might prevent Coherence from fully balancing the cluster. For example, if some accounts have many transactions and some only a few, you could run out of memory on one node even though there is plenty of room in the cluster as a whole. Because of this, you will only want to use data affinity if the associated objects are naturally well-balanced.
Unlike entities, value objects are not uniquely identifiable within a system. They simply represent values from the domain, and are typically immutable (and if they are not, they probably should be). An example of a value object might be a Money object, representing monetary amount, or an Address object, representing a mailing address of a person or a company, and defined by attributes such as street, street number, city, state, postal code, and country.
The value objects are typically used as attributes of entities. That means that they won't have their own cache, but will be stored as part of an entity's serialized state, within the cache for an entity they belong to. For example, our Account entity has a balance attribute represented by the Money value object, which will be serialized and stored with the rest of the account's state.
It is amazing that there is no built-in Money class in standard class libraries in either Java or .NET, especially considering the fact that most applications deal with monetary values one way or another.
However, that might work to our advantage in this case, as it gives us the opportunity to create a portable implementation of Money in Java, .NET, and C++. In this section, we will look at the Java implementation, but the other two are available within the sample application if you would like to see the details.
The Money class is an immutable class that simply encapsulates the amount and currency attributes:
public class Money implements Serializable {
private final BigDecimal m_amount;
private final Currency m_currency;
public Money(BigDecimal amount, Currency currency) {
m_amount = amount.setScale(
currency.getDefaultFractionDigits(),
RoundingMode.HALF_EVEN);
m_currency = currency;
}
public BigDecimal getAmount() {
return m_amount;
}
public Currency getCurrency() {
return m_currency;
}
}
In addition to the constructor shown earlier, the class also provides a number of convenience constructors that allow you to specify the amount as a string, integer, or floating-point value, and currency either as a currency code or an actual java.util.Currency instance.
However, the main reason for creating the Money class is not to capture its attributes, but to define the behavior applicable to monetary values:
public class Money implements Serializable {
...
public boolean isSameCurrency(Money money) {
return m_currency.equals(money.m_currency);
}
public Money add(Money money) {
checkCurrency(money);
return new Money(m_amount.add(money.m_amount), m_currency);
}
public Money subtract(Money money) {
checkCurrency(money);
return new Money(m_amount.subtract(money.m_amount), m_currency);
}
public boolean greaterThan(Money money) {
checkCurrency(money);
return m_amount.compareTo(money.m_amount) > 0;
}
public boolean lessThan(Money money) {
checkCurrency(money);
return m_amount.compareTo(money.m_amount) < 0;
}
}
This gives us everything we need to work with monetary values within our application, and ensures that currency is taken into account when performing arithmetic operations or comparisons on two monetary values.
Value objects can also be used as identifiers for an entity; while they don't have an identity themselves, they are often used to represent composite identifiers containing two or more entity attributes. An example of such a value object is the Transaction.Id class we created earlier.
While in most cases all that Coherence cares about is that value objects are serializable, when they are used as identifiers you also need to ensure that they implement the equals and hashCode methods properly, and that the serialized binary form of equivalent value objects is identical.
This is very important, because key-based lookups against the Coherence cache depend on either standard object equality, or the binary equality of serialized keys. The exact requirement varies based on how objects are stored internally within the cache, but as a best practice, you should ensure that your identity object's serialized form is always consistent with equals. That way you won't have to worry about the details regarding the internal behavior of the cache type you are using.
Note
Broken keys
I cannot stress the importance of this enough, as I have seen time and time again broken implementations of key classes, which have caused a lot of headache and wasted time.
By far the most common reason for broken keys is the omission of non-transient fields in the implementation of the equals method, so make sure that doesn't happen to you—if the field is serialized, it should be used for comparison within the equals implementation as well.
In a rich domain model, the best places to put business logic are the domain objects that the behavior naturally belongs to, such as entities and aggregates. However, in most applications there is some behavior that doesn't clearly belong to any of the data objects. In such cases, you can define services within the domain itself that implement the necessary logic.
These domain-layer services are not the same as the course-grained services most of us got accustomed to while building applications using session EJBs. They are much lighter and much more focused, usually encapsulating only a handful of business methods, and very often only one or two.
You will typically still have a set of coarse-grained services within the orchestration layer, that are used to coordinate multiple activities within the domain layer and transform output into the most appropriate format for the presentation layer. They can also come in handy as a boundary for some of the infrastructure-level services, such as transactions and security.
However, the big difference between these orchestration-layer services and the services most of us used to implement using session beans is that session beans tended to contain most, if not all of the business logic, making domain objects dumb data holders in the process. The orchestration-layer services, on the other hand, are there purely for coordination and boundary definition purposes, while the business logic is implemented within the domain model.
A good example of a domain service is the CurrencyConverter we defined within our domain model. The conversion logic clearly doesn't belong to the Account, so introducing a service whose only responsibility is to perform currency conversions makes perfect sense.
The best way to implement services in general is to hide the implementation behind an interface. That way the implementation can be easily replaced without any impact on the service clients.
We will follow that approach and define a CurrencyConverter interface:
public interface CurrencyConverter {
CurrencyConversion convert(Money amount,
Currency targetCurrency);
}
As you can see, the interface is quite simple—it defines a single method that accepts the amount to convert and target currency as arguments and returns a CurrencyConversion value object:
public class CurrencyConversion {
private final Money m_originalAmount;
private final Money m_convertedAmount;
public CurrencyConversion(Money originalAmount,
Money convertedAmount) {
m_originalAmount = originalAmount;
m_convertedAmount = convertedAmount;
}
public Money getOriginalAmount() {
return m_originalAmount;
}
public Money getConvertedAmount() {
return m_convertedAmount;
}
public BigDecimal getExchangeRate() {
BigDecimal exchangeRate =
m_convertedAmount.getAmount()
.divide(m_originalAmount.getAmount());
return exchangeRate.setScale(4, RoundingMode.HALF_EVEN);
}
}
Finally, we have a service implementation that looks up the exchange rate for the requested conversion and performs the conversion. The actual implementation is not that important for the further discussion and is available in the sample code download, so I will omit the code in order to save some trees.
When we discussed creation of entity instances I mentioned that I prefer a static factory method to a direct use of a constructor. In most cases, either of those two options will be all you need. However, in some cases the creational logic for an entity might be complex, in which case implementing a factory as a separate class might be the best approach.
In most cases, implementing a factory as a separate class is not very different from the static factory method approach. For example, the following factory class is functionally equivalent to the static factory method we created earlier:
public class AccountFactory {
private static IdentityGenerator<Long> s_idGen =
SequenceGenerator.create("account.id", 20);
public Account createAccount(Customer customer,
String description,
Currency currency) {
return new Account(s_idGen.generateIdentity(),
customer.getId(),
description,
new Money(0, currency));
}
}
However, the fact that the factory is now a separate class opens up some interesting possibilities. For example, we could get rid of the hardcoded SequenceGenerator dependency and use Spring to configure the factory instance:
public class AccountFactory {
private IdentityGenerator<Long> m_idGen;
public AccountFactory(IdentityGenerator<Long> idGen) {
m_idGen = idGen;
}
public Account createAccount(Customer customer,
String description,
Currency currency) {
return new Account(m_idGen.generateIdentity(),
customer.getId(),
description,
new Money(0, currency));
}
}
The following Spring configuration could then be used to wire the AccountFactory instance:
<bean id="accountFactory" class="domain.AccountFactory"> <constructor-arg> <bean class="c.s.c.identity.sequence.SequenceGenerator"> <constructor-arg value="account.id"/> <constructor-arg value="20"/> </bean> </constructor-arg> </bean>
That way you can let Spring manage dependencies and will be able to provide a fake or mock for the identity generator within unit tests, which alone might be a good enough reason to take this extra step.
The factories are useful when we need to create new instances of domain objects, but in many cases we simply need to retrieve the existing instances. In order to accomplish that, we can use a repository.
According to Domain Driven Design, a repository can be thought of as an unlimited, memory-backed object store containing all objects of a specific type. If that definition reminds you of a Coherence cache, you are not alone—a Coherence cache is a great object repository indeed.
Ideally, the repository interface should be completely independent of the underlying infrastructure and should be expressed in terms of domain objects and their attributes only. For example, we could define AccountRepository like this:
public interface AccountRepository {
Account getAccount(Long id);
Collection<Account> getAccounts(Collection<Long> accountIds);
void save(Account account);
}
As you can see, the interface is completely Coherence agnostic, and can be implemented for pretty much any data source. A Coherence implementation might look like this:
public class CoherenceAccountRepository
implements AccountRepository {
private static final NamedCache s_accounts = CacheFactory.getCache("accounts");
public Account getAccount(Long id) {
return (Account) s_accounts.get(id);
}
public Collection<Account> getAccounts( Collection<Long> accountIds) {
return (Collection<Account>)
s_accounts.getAll(accountIds).values();
}
public void save(Account account) {
s_accounts.put(account.getId(), account);
}
}
What you will quickly notice if you start implementing repositories this way is that basic CRUD operations tend to repeat within every repository implementation, so it makes sense to pull them up into an abstract base class in order to avoid implementing them over and over again:
public abstract class AbstractCoherenceRepository<K, V extends Entity<K>> {
public abstract NamedCache getCache();
public V get(K key) {
return (V) getCache().get(key);
repository, domain model building blocksabstract base class}
public Collection<V> getAll(Collection<K> keys) {
return getCache().getAll(keys).values();
}
public void save(V value) {
getCache().putAll(
Collections.singletonMap(value.getId(), value));
}
public void saveAll(Collection<V> values) {
Map batch = new HashMap(values.size());
for (V value : values) {
batch.put(value.getId(), value);
}
getCache().putAll(batch);
}
}
This abstract base class for our repository implementations uses generics to specify the key and value type for the cache that the repository is used to access, and constrains value type to the types that implement the Entity interface we defined earlier. This allows us to implement the save and saveAll methods as mentioned earlier, because we can obtain the cache key for any entity by calling its getId method.
Note
NamedCache.put versus NamedCache.putAll
One thing to note is the implementation of the save method. While I could've just made a simple call to a NamedCache.put method, I have chosen to use putAll instead, in order to improve performance by eliminating one network call.
The reason for this is that the NamedCache.put method strictly follows the contract defined by the Map interface and returns the old value from the cache. This is fine when you are accessing a map in-process or need the old value, but in this case neither is true and using put would simply increase the latency.
Our CoherenceAccountRepository implementation now simply becomes:
public class CoherenceOrderRepository
extends AbstractCoherenceRepository<Long, Account>
implements AccountRepository {
private static final NamedCache m_accounts = CacheFactory.getCache("accounts");
public NamedCache getCache() {
return m_accounts;
}
public Account getAccount(Long id) {
return super.get(id);
}
public Collection<Account> getAccounts( Collection<Long> accountIds) {
return super.getAll(accountIds);
}
}
This concludes our coverage of different types of data objects within a domain model and how to map them to Coherence caches. For the most part, you should now know enough to be able to implement your data objects and put them into the cache.
One thing you might've noticed is that, aside from the repository implementation, none of the domain classes we implemented thus far have any dependency on or knowledge of Coherence, despite the somewhat leaky repository abstraction. This is an example of what DDD calls persistence ignorance (PI) and is extremely important as it allows us to unit test our domain model objects in isolation.
For the most part, you can use the domain objects we implemented in this section without any modifications. However, there are several important considerations that we haven't discussed yet that you need to understand in order to implement your data objects (entities and aggregates) in an optimal way.
One of the most important choices you need to make for your domain objects (from the Coherence perspective) is how they will be serialized. Coherence works just fine with objects that simply implement java.io.Serializable interface, so that is typically the easiest way to try things out. However, that is also the slowest way to serialize your objects, as it heavily depends on reflection. It also introduces a lot of overhead into the object's serialized binary form, as it embeds into it things such as full class name, field names, and field types.
Serialization performance will impact most operations against a distributed cache, while the size of the serialized binary form will not only have an impact on network throughput, but more importantly, it will ultimately determine how much data you can store within a cluster of a certain size. Or, looking at it from a different angle, it will determine how many servers, how much RAM and how many Coherence licenses you will need in order to manage your data.
Coherence provides several serialization mechanisms that are significantly faster than the standard Java serialization and typically also result in a much smaller serialized binary form. The reason why there are several of them is that they were introduced one by one, in an effort to improve performance. The latest one, called Portable Object Format or POF, was introduced in Coherence 3.2 in order to allow .NET clients to access data within a Coherence cluster, but has since then become the recommended serialization format for pure Java applications as well.
POF is an extremely compact, platform-independent binary serialization format. It can be used to serialize almost any Java, .NET, or C++ object into a POF value.
A POF value is a binary structure containing type identifier and value. The type identifier is an integer number, where numbers less than zero are used for the intrinsic types, while the numbers greater than zero can be used for custom user types.
User types are what we are interested in most, as all the domain objects we will create within an application are considered user types. The value of a user type is encoded within the POF stream as a list of indexed attributes, where each data member of a user type is encoded by specifying its index within the type. The attribute value is then encoded as a POF value, defined previously.
The fact that attribute indexes are used instead of attribute names makes POF very compact and fast, but it puts burden on the serializer implementation to ensure that attributes are written to and read from the POF stream in the same order, using the same indexes.
This decision, as well as the decision to use an integer type identifier instead of class name to represent the type of the value was made consciously, in order to make POF platform independent—Java class name is meaningless to a .NET client and vice-versa, and attribute names might be as well. The consequence is that unlike many other serialization formats, POF is not a self-describing serialization format by design, and it requires an external means of correlating platform independent user type identifiers with platform-specific classes.
Note
A brief history of POF
Back in December of 2005, during the first The Spring Experience conference in Miami, I was working with Rob Harrop on the interoperability solution that would allow Spring.NET clients to communicate with Spring-managed Java services on the server. We had several working implementations, including SOAP web services and a custom IIOP implementation for .NET, but we weren't really happy with any of them, as they either had significant limitations, required too much configuration, were just plain slow, or all of the above, as was the case with SOAP web services.
What we wanted was something that was easy to configure, didn't impose inheritance requirements on our services and was as fast as it could be. The only option we saw was to implement a custom binary serialization mechanism that would be platform independent, but neither of us was brave enough to start working on it.
The very next week I was at JavaPolis in Antwerp, Belgium, listening to Cameron Purdy's talk on Coherence. One of the things he mentioned was how Java serialization is extremely slow and how Tangosol's proprietary ExternalizableLite serialization mechanism is some ten to twelve times faster. With Spring interop still fresh in mind, I approached Cameron after the talk and asked him if it would be possible to port ExternalizableLite to .NET. He just looked at me and said: "We need to talk.".
Well, we did talk, and what I learned was that Tangosol wanted to implement the .NET client for Coherence, as many customers were asking for it, and that in order to do that they needed a platform-independent serialization format and serializer implementations in both Java and .NET. A few months later, I received an e-mail with a serialization format specification, complete Java POF implementation and a question "Can you implement this in .NET for us?"
Over the next six months or so we implemented both POF and the full-blown .NET client for Coherence. All I can say is that the experience for me was very intense, and was definitely one of those humbling projects where you realize how little you really know. Working with Cameron and Jason Howes on POF and Coherence for .NET was a lot of fun and a great learning experience.
Although, I knew it would be that way as soon as I saw the following sentence in the POF specification:
In other words, PIF-POF is explicitly not intended to be able to answer all questions, nor to be all things to all people. If there is an 80/20 rule and a 90/10 rule, PIF-POF is designed for the equivalent of a 98/2 rule: it should suffice for all but the designs of an esoteric and/or convoluted mind.
A POF context provides a way to assign POF type identifiers to your custom types. There are two implementations that ship with Coherence, and you are free to implement your own if neither fits the bill, which is highly unlikely.
The first implementation is a SimplePofContext, which allows you to register user types programmatically, by calling the registerUserType method. This method takes three arguments: POF type identifier, a class of a user type, and a POF serializer to use.
The last argument, POF serializer, can be an instance of any class that implements the com.tangosol.io.pof.PofSerializer interface. You can implement the serializer yourself, or you can implement the com.tangosol.io.pof.PortableObject interface within your data objects and use the built-in PortableObjectSerializer, as in the following example:
SimplePofContext ctx = new SimplePofContext(); ctx.registerUserType(1000, Account.class, new PortableObjectSerializer(1000)); ctx.registerUserType(1001, Transaction.class, new PortableObjectSerializer(1001)); ctx.registerUserType(1002, Customer.class, new Customer.Serializer());
Regardless of the option chosen, you will also have to implement the actual serialization code that reads and writes object's attributes from/to a POF stream. We will get to that shortly, but now let's take a look at the other implementation of a PofContext interface, a ConfigurablePofContext class.
The ConfigurablePofContext allows you to define mappings of user types to POF type identifiers in an external configuration file and is most likely what you will be using within your applications.
The POF configuration file is an XML file that has the following format:
<!DOCTYPE pof-config SYSTEM "pof-config.dtd"> <pof-config> <user-type-list> <include>otherPofConfig</include> <user-type> <type-id>typeId</type-id> <class-name>userTypeClass</class-name> <serializer> <class-name>serializerClass</class-name> <init-params>...</init-params> </serializer> </user-type> ... </user-type-list> </pof-config>
The include element allows us to import user type definitions from another file. This enables us to separate POF configuration into multiple files in order to keep those files close to the actual types they are configuring, and to import all of them into the main POF configuration file that the application will use.
The serializer definition within the user-type element is optional, and if it is not specified PortableObjectSerializer will be used. For example, if we were to create a configuration file for the same user types we registered manually with the SimplePofContext in the previous example, it would look like this:
<!DOCTYPE pof-config SYSTEM "pof-config.dtd"> <pof-config> <user-type-list> <user-type> <type-id>1000</type-id> <class-name> sample.domain.Account </class-name> </user-type> <user-type> <type-id>1001</type-id> <class-name> sample.domain.Transaction </class-name> </user-type> <user-type> <type-id>1002</type-id> <class-name> sample.domain.Customer </class-name> <serializer> <class-name> sample.domain.Customer$Serializer </class-name> </serializer> </user-type> </user-type-list> </pof-config>
There is another thing worth pointing out regarding user type registration within a POF context.
You have probably noticed that I used type identifiers of 1000 and greater, even though any positive integer can be used. The reason for this is that the numbers below 1000 are reserved for various user types within Coherence itself, such as filter and entry processor implementations.
All internal user types are configured in the coherence-pof-config.xml file within coherence.jar, and you should import their definitions into your main POF configuration file using an include element:
<include>coherence-pof-config.xml</include>
Finally, it is worth noting that even though POF is the recommended serialization format from Coherence 3.4, it is not enabled within the cluster by default, for backwards compatibility reasons. In order to enable it you need to either configure it on a per service basis within the cache configuration file, or enable it globally by specifying the following system properties:
-Dtangosol.pof.enabled=true -Dtangosol.pof.config=my-pof-config.xml
The easiest way to implement POF serialization is to make your objects implement the PortableObject interface.
public interface PortableObject extends Serializable {
void readExternal(PofReader pofReader)
throws IOException;
void writeExternal(PofWriter pofWriter)
throws IOException;
}
The methods defined by the PortableObject interface return no value and accept a single argument that allows us to read the indexed attributes from the POF stream, in the case of readExternal, or to write attributes into the POF stream in writeExternal. To learn how to implement these methods, let's look at the implementation of a POF-enabled Customer class:
public class Customer
implements Entity<Long>, PortableObject {
// data members
private final Long m_id;
private String m_name;
private String m_email;
private Address m_address;
private Collection<Long> m_accountIds;
public Customer() {
}
public void readExternal(PofReader pofReader)
throws IOException {
m_id = pofReader.readLong(0);
m_name = pofReader.readString(1);
m_email = pofReader.readString(2);
m_address = (Address) pofReader.readObject(3);
m_accountIds = pofReader.readCollection( 4, new ArrayList<Long>());
}
public void writeExternal(PofWriter pofWriter)
throws IOException {
pofWriter.writeLong(0, m_d);
pofWriter.writeString(1, m_name);
pofWriter.writeString(2, m_email);
pofWriter.writeObject(3, m_address);
pofWriter.writeCollection(4, m_accountIds);
}
}
As you can see, while it probably isn't the most exciting code to write, serialization code is fairly straightforward and simply uses the appropriate PofReader and PofWriter methods to read and write attribute values.
Once you implement the PortableObject interface, all you need to do is register your user type within the POF context by adding a user-type element for it into the POF configuration file, as we've done in the previous section. You can omit the serializer element, and PortableObjectSerializer will be used by default.
The second way to implement serialization logic is to create a separate serializer class that implements the PofSerializer interface:
public interface PofSerializer {
void serialize(PofWriter pofWriter, Object o)
throws IOException;
Object deserialize(PofReader pofReader)
throws IOException;
}
As you can see, the methods that need to be implemented are very similar to the ones defined by the PortableObject interface, so the logic within them will also look familiar:
public class CustomerSerializer implements PofSerializer {
public void serialize(PofWriter writer, Object obj)
throws IOException {
Customer c = (Customer) obj;
writer.writeLong(0, c.getId());
writer.writeString(1, c.getName());
writer.writeString (2, c.getEmail());
writer.writeObject(3, c.getAddress());
writer.writeCollection(4, c.getAccountIds());
writer.writeRemainder(null);
}
public Object deserialize(PofReader reader)
throws IOException {
Long id = reader.readLong(0);
String name = reader.readString(1);
String email = reader.readString (2);
Address address = (Address) reader.readObject(3);
Collection<Long> accountIds =
reader.readCollection(4, new ArrayList<Long>());
pofReader.readRemainder();
return new Customer(id, name, email, address, accountIds);
}
}
Apart from the fact that we now have to use getters to retrieve attribute values, there are only two things that are different: calls to writeReminder and readReminder methods, and the Customer creation in the deserialization method.
The read/writeReminder methods are part of the schema evolution support, which we will discuss in more detail shortly. For now, all you need to know is that you have to call them in order to properly terminate reading or writing of a user type instance from or into a POF stream. The PortableObjectSerializer does that for us, so we didn't have to worry about it when we implemented serialization within PortableObject methods, but you do need to do it in your custom implementations of PofSerializer.
The way the Customer instance is created within the deserialize method points out one of the major differences between the two possible serialization implementations: if you write a custom serializer you have complete control over the object creation. You can use a parameterized constructor, as in the previous example, or a factory that encapsulates possibly complex creational logic.
On the other hand, in order for the PortableObjectSerializer to work, your class needs to provide a public default constructor. While in many cases this isn't a problem as there are other application components that require default constructors, such as ORM tools, in some situations this might be an issue and you might want to implement external serializers in order to have complete control over the instantiations of your objects. This brings us to our next topic: How to decide on which option to use.
One of the reasons you should choose custom PofSerializer implementation is what we discussed previously—when you have complex creational logic for your objects and need to have complete control over their instantiation.
A second, very obvious reason is that you may not be able to add the necessary POF serialization code to a class. While it is usually possible to add such code to your own classes, being able to have the code in a separate PofSerializer implementation means that you can serialize other peoples' non-POF-compliant classes using POF, including classes that come with the JDK, various frameworks, application servers, and even packaged applications.
For example, we have used the java.util.Currency class within the Money implementation. In order to make Money as a whole portable, we need to ensure that Currency is portable as well. The only way to do that is by creating an external serializer:
public class CurrencySerializer implements PofSerializer {
public void serialize(PofWriter writer, Object obj)
throws IOException {
Currency currency = (Currency) obj;
writer.writeString(0, currency.getCurrencyCode());
writer.writeRemainder(null);
}
public Object deserialize(PofReader reader)
throws IOException {
String currencyCode = reader.readString(0);
pofReader.readRemainder();
return Currency.getInstance(currencyCode);
}
}
Another good reason to choose an external serializer is when you can write a single serializer that is able to handle many different types. For example, let's take a look at serialization of enum values.
In order to serialize enums in a platform-independent way, the best option is to write the name of the enum value into a POF stream. On the surface, this seems easy enough to do directly within the serialization code:
public enum TransactionType {
DEPOSIT,
WITHDRAWAL
}
public class Transaction implements PortableObject {
// data members
private TransactionType m_type;
public Transaction() {
}
public void readExternal(PofReader pofReader)
throws IOException {
m_type = Enum.valueOf(TransactionType.class,
pofReader.readString(0));
}
public void writeExternal(PofWriter pofWriter)
throws IOException {
pofWriter.writeString(0, m_type.name());
}
}
Unfortunately, there are several issues with the approach.
For one, you will have to repeat a somewhat cumbersome piece of code that is used to deserialize enums for each serializable enum field within your application. Second, if you need to serialize an instance of a collection that contains one or more enum values, you will not have a sufficient degree of control that will allow you to inject the custom deserialization logic used previously.
Because of this, it is much better solution to implement a custom PofSerializer that can be used to serialize all enum types:
public class EnumPofSerializer implements PofSerializer {{
public void serialize(PofWriter writer, Object o)
throws IOException {
if (!o.getClass().isEnum()) {
throw new IOException(
"EnumPofSerializer can only be used to " +
"serialize enum types.");
}
writer.writeString(0, ((Enum) o).name());
writer.writeRemainder(null);
}
public Object deserialize(PofReader reader)
throws IOException {
PofContext pofContext = reader.getPofContext();
Class enumType = pofContext.getClass(reader.getUserTypeId());
if (!enumType.isEnum()) {
throw new IOException(
"EnumPofSerializer can only be used to " +
"deserialize enum types.");
}
Enum enumValue = Enum.valueOf(enumType, reader.readString(0));
reader.readRemainder();
return enumValue;
}
}
Now all we have to do is register our enum types within the POF configuration, specifying EnumPofSerializer as their serializer, and use read/writeObject methods to serialize them:
public void readExternal(PofReader pofReader)
throws IOException {
m_type = (TransactionType) pofReader.readObject(0);
}
public void writeExternal(PofWriter pofWriter)
throws IOException {
pofWriter.writeObject(0, m_type);
}
This greatly simplifies enum serialization and ensures that they are serialized consistently throughout the application. Better yet, it will allow for a completely transparent serialization of enum values within various collections.
The previous examples demonstrate some great uses for external serializers, but we still haven't answered the question we started this section with—which approach to use when serializing our domain objects.
Implementing the PortableObject interface is quick and easy, and it doesn't require you to configure a serializer for each class. However, it forces you to define a public default constructor, which can be used by anyone to create instances of your domain objects that are in an invalid state.
An external serializer gives you full control over object creation, but is more cumbersome to write and configure. It also might force you to break the encapsulation, as we did earlier, by providing a getAccountIds method on the Customer class in order to allow serialization of account identifiers.
The last problem can be easily solved by implementing the external serializer as a static inner class of the class it serializes. That way, it will be able to access its private members directly, which is really what you want to do within the serializer.
In addition to that, the Coherence Tools project provides AbstractPofSerializer, an abstract base class that makes the implementation of external serializers significantly simpler by removing the need to read and write the remainder. We will actually discuss the implementation of this class shortly, but for now let's see how the customer serializer would look like if implemented as a static inner class that extends AbstractPofSerializer:
public class Customer
implements Entity<Long> {
...
public static class Serializer
extends AbstractPofSerializer<Customer> {
protected void serializeAttributes(Customer c, PofWriter writer)
throws IOException {
writer.writeLong (0, c.m_id);
writer.writeString (1, c.m_name);
writer.writeString (2, c.m_email);
writer.writeObject (3, c.m_address);
writer.writeCollection(4, c.m_accountIds);
}
protected Customer createInstance(PofReader reader)
throws IOException {
return new Customer(
reader.readLong(0),
reader.readString(1),
reader.readString(2),
(Address) reader.readObject(3),
reader.readCollection(4, new ArrayList<Long>()));
}
}
}
I believe you will agree that implementing the external serializer this way is almost as simple as implementing the PortableObject interface directly (we still need to configure the serializer explicitly), but without its downsides.
Because of this, my recommendation is to implement external serializers in the manner presented for all domain classes, and to implement the PortableObject interface directly only within the classes that are closely related to Coherence infrastructure, such as entry processors, filters, and value extractors, which will be discussed in the following chapters.
While implementation of the POF serialization code is straightforward, one subject that deserves a more detailed discussion is collection serialization.
POF does not encode collection type into the POF stream. If it did, it wouldn't be portable, as collection types are platform dependent. For example, if it encoded the type of a java.util.LinkedList into the stream, there would be no way for a .NET client to deserialize the collection as there is no built-in linked list type in .NET.
Instead, POF leaves it to the serialization code to decide which collection type to return by providing a collection template to the PofReader.readCollection method:
List myList = pofReader.readCollection(0, new LinkedList());
The situation with maps is similar:
Map myMap = pofReader.readMap(1, new TreeMap());
You can specify null in both cases, but you should never do that if you care about the type of the returned object and not just about the fact that it implements the Collection or Map interface. If you do, Coherence will return an instance of a default type, which is probably not what you want.
For example, you might've noticed that I specified a new ArrayList as a collection template whenever I was reading account ids from the POF stream in the Customer serialization examples. The reason for that is that I need the collection of account ids to be mutable after deserialization (so the customer can open a new account). If I didn't provide a template, account ids would be returned as ImmutableArrayList, one of the internal List implementations within Coherence.
To make things even worse, there is no guarantee that the default implementation will even remain the same across Coherence versions, and you might get surprised if you move from one supported platform to another (for example, the .NET Coherence client returns an object array as a default implementation). The bottom line is that you should always specify a template when reading collections and maps.
The situation with object arrays is similar: if you want the serializer to return an array of a specific type, you should provide a template for it.
myProductArray = pofReader.readObjectArray(2, new Product[0]);
If you know the number of elements ahead of time you should size the array accordingly, but more likely than not you will not have that information. In that case, you can simply create an empty array as in the previous example, and let the POF serializer resize it for you.
The only exception to this rule is if you have written the array into the stream using the PofWriter.writeObjectArray overload that writes out a uniform array, in which case the serializer will have enough information to create an array of a correct type even if you don't specify a template for it.
This brings us to the discussion about uniform versus non-uniform collection and array write methods.
If you browse the API documentation for PofWriter, you will notice that there are multiple overloaded versions of the writeCollection, writeMap, and writeObjectArray methods.
The basic ones simply take the attribute index and value as arguments and they will write the value out using a non-uniform format, which means that the element type will be encoded for each element in a collection. Obviously, this is wasteful if all elements are of the same type, so PofWriter provides methods that allow you to specify element type as well, or in the case of the writeMap method, both the key type and the value type of map entries.
If your collection, array or a map is uniform, and most are, you should always use the uniform versions of write methods and specify the element type explicitly. This can significantly reduce the size of the serialized data by allowing the POF serializer to write type information only once instead of for each element.
Now that you know everything you need to know about serialization and POF, let's discuss the closely related subject of schema evolution support in Coherence.
The fact of life is that things change, and this applies to domain objects as well. New releases of an application usually bring new features, and new features typically require new attributes within domain objects.
In a typical non-Coherence application, you can introduce new columns into database tables, add attributes to your classes, modify ORM configuration files, or custom database access logic and be on your way. However, when your objects are stored within a Coherence cluster, things are not that simple.
The main reason for that is that Coherence stores objects, not raw data, and objects have a specific serialization format, be it POF or something else. You can modify the database schema, your classes, and O-R mapping code just as you used to, but you will also have to decide what to do with the objects stored within Coherence caches that were serialized in a format that is likely incompatible with the serialization format of your modified classes.
There are really only a two possible choices you can make:
Shut down the whole cluster, perform an upgrade, and reload the data into the cache using the latest classes
Make your classes evolvable
It is important to note that there is nothing wrong with the first option and if your application can be shut down temporarily for an upgrade, by all means, go for it. However, many Coherence-powered solutions are mission-critical applications that cannot be shut down for any period of time, and many of them depend on Coherence being the system of record.
In those cases, you need to be able to upgrade the Coherence cluster node by node, while keeping the system as a whole fully operational, so your only option is to add support for schema evolution to your objects.
The first step you need to take when adding support for schema evolution to your application is to make your data objects implement the com.tangosol.io.Evolvable interface:
public interface Evolvable extends java.io.Serializable {
int getImplVersion();
int getDataVersion();
void setDataVersion(int i);
com.tangosol.util.Binary getFutureData();
void setFutureData(com.tangosol.util.Binary binary);
}
The Evolvable interface defines the attributes each object instance needs to have in order to support the schema evolution. This includes the following:
Implementation Version is the version number of the class implementation. This is typically defined as a constant within the class, which is then returned by the
getImplVersionmethod. You need to increment the implementation version for a new release if you have added any attributes to the class.Data Version is the version number of the class data. You can also think of it as the version number of the serialized form of a class. The Data Version attribute is set by the serializer during deserialization, based on the version number found in the POF stream.
Future Data is used to store attributes that exist within the POF stream but are not read explicitly by the deserializer of an older version of a class. They are simply stored within an object as a binary blob so they can be written out into the POF stream during serialization, thus preventing data loss during round tripping.
To illustrate all of this, let's return to our earlier example and see how we could add evolution support to the Customer class:
public class Customer
implements Entity<Long>, Evolvable {
// evolvable support
public static final int IMPL_VERSION = 1;
private int dataVersion;
private Binary futureData;
// data members
private Long m_id;
private String m_name;
private String m_email;
// constructors, getters and setters omitted for brevity
...
public int getImplVersion() {
return IMPL_VERSION;
}
public int getDataVersion() {
return dataVersion;
}
public void setDataVersion(int dataVersion) {
this.dataVersion = dataVersion;
}
public Binary getFutureData() {
return futureData;
}
public void setFutureData(Binary futureData) {
this.futureData = futureData;
}
}
It is immediately obvious that the implementation of this interface will be the same for all evolvable classes, so it makes sense to pull the dataVersion and futureData attributes into a base class and define the getImplVersion method as abstract. As a matter of fact, such a class already exists within coherence.jar, and is called AbstractEvolvable.
Using AbstractEvolvable as a base class greatly simplifies implementation of evolvable objects, as you only need to implement the getImplVersion method:
public class Customer
extends AbstractEvolvable
implements Entity<Long> {
// evolvable support
public static final int IMPL_VERSION = 1;
// data members
private Long m_id;
private String m_name;
private String m_email;
// constructors, getters and setters omitted for brevity
...
public int getImplVersion() {
return IMPL_VERSION;
}
}
The Evolvable interface simply defines which information class instances need to be able to provide in order for the class to support schema evolution. The rest of the work is performed by a serializer that knows how to use that information to support serialization across multiple versions of a class.
The easiest way to add schema evolution support to your application is to use an out-of-the-box serializer that implements the necessary logic. One such serializer is the PortableObjectSerializer we discussed earlier, and it makes schema evolution a breeze. You simply implement both PortableObject and Evolvable interfaces within your class (or even simpler, a convenience EvolvablePortableObject interface), and the serializer takes care of the rest.
However, if you follow my earlier advice and implement external serializers for your domain objects, you need to handle object evolution yourself.
The algorithm to implement is fairly simple. When deserializing an object, we need to:
Read the data version from the POF stream and set the
dataVersionattributeRead object attributes as usual
Read the remaining attributes, if any, from the POF stream and set the
futureDataattribute
The last item is only meaningful when we are deserializing a newer object version. In all other cases futureData will be null.
When serializing an object, we need to do the exact opposite for steps 2 and 3, but the first step is slightly different:
Set the data version of the POF stream to the greater of implementation version or data version
Write object attributes as usual
Write future data into the POF stream
The reason why we need to write the greater of implementation or data version in the first step, is that we always want to have the latest possible version in the POF stream. If we deserialize a newer version of an object, we need to ensure that its version is written into the POF stream when we serialize the object again, as we'll be including its original data into the POF stream as well. On the other hand, if we deserialized an older version, we should write a new version, containing new attributes while serializing the object again.
This is actually the key element of the schema evolution strategy in Coherence that allows us to upgrade the cluster node by node, upgrading the data stored within the cluster in the process as well.
Imagine that you have a ten-node Coherence cluster that you need to upgrade. You can shut a single node down, upgrade it with new JAR files and restart it. Because the data is partitioned across the cluster and there are backup copies available, the loss of a single node is irrelevant—the cluster will repartition itself, backup copies of the data will be promoted to primary copies, and the application or applications using the cluster will be oblivious to the loss of a node.
When an upgraded node rejoins the cluster, it will become responsible for some of the data partitions. As the data it manages is deserialized, instances of new classes will be created and the new attributes will be either calculated or defaulted to their initial values. When those instances are subsequently serialized and stored in the cluster, their version is set to the latest implementation version and any node or client application using one of the older versions of the class will use the futureData attribute to preserve new attributes.
As you go through the same process with the remaining nodes, more and more data will be incrementally upgraded to the latest class version, until eventually all the data in the cluster uses the current version.
What is important to note is that client applications do not need to be simultaneously upgraded to use the new classes. They can continue to use the older versions of the classes and will simply store future data as a binary blob on reads, and include it into the POF stream on writes. As a matter of fact, you can have ten different applications, each using different versions of the data classes, and they will all continue to work just fine, as long as all classes are evolvable.
Now that we have the theory covered, let's see how we would actually implement a serializer for our Customer class to support evolution.
public class CustomerSerializer implements PofSerializer {
public void serialize(PofWriter writer, Object o)
throws IOException {
Customer c = (Customer) o;
int dataVersion = Math.max(c.getImplVersion(),
c.getDataVersion());
writer.setVersionId(dataVersion);
writer.writeLong(0, c.getId());
writer.writeString(1, c.getName());
writer.writeString (2, c.getEmail());
writer.writeObject(3, c.getAddress());
writer.writeCollection(4, c.getAccountIds());
writer.writeRemainder(c.getFutureData());
}
public Object deserialize(PofReader reader)
throws IOException {
Long id = reader.readLong(0);
String name = reader.readString(1);
String email = reader.readString (2);
Address address = (Address) reader.readObject(3);
Collection<Long> accountIds =
reader.readCollection(4, new ArrayList<Long>());
Customer c = new Customer(id, name, email, address,accountIds);
c.setDataVersion(pofReader.getVersionId());
c.setFutureData(pofReader.readRemainder());
return c;
}
}
The highlighted code is simple, but it is immediately obvious that it has nothing to do with the Customer class per se, as it only depends on the methods defined by the Evolvable interface. As such, it simply begs for refactoring into an abstract base class that we can reuse for all of our serializers:
public abstract class AbstractPofSerializer<T>
implements PofSerializer {
protected abstract void
serializeAttributes(T obj, PofWriter writer)
throws IOException;
protected abstract void
deserializeAttributes(T obj, PofReader reader)
throws IOException;
protected abstract T createInstance(PofReader reader)
throws IOException;
public void serialize(PofWriter writer, Object obj)
throws IOException {
T instance = (T) obj;
boolean isEvolvable = obj instanceof Evolvable;
Evolvable evolvable = null;
if (isEvolvable) {
evolvable = (Evolvable) obj;
int dataVersion = Math.max(
evolvable.getImplVersion(),
evolvable.getDataVersion());
writer.setVersionId(dataVersion);
}
serializeAttributes(instance, writer);
Binary futureData = isEvolvable
? evolvable.getFutureData()
: null;
writer.writeRemainder(futureData);
}
public Object deserialize(PofReader reader)
throws IOException {
T instance = createInstance(reader);
Evolvable evolvable = null;
boolean isEvolvable = instance instanceof Evolvable;
if (isEvolvable) {
evolvable = (Evolvable) instance;
evolvable.setDataVersion(
reader.getVersionId());
}
schema evolutionevolvable objects serialization, implementingdeserializeAttributes(instance, reader);
Binary futureData = reader.readRemainder();
if (isEvolvable) {
evolvable.setFutureData(futureData);
}
return instance;
}
}
The only thing worth pointing out is the fact that both the createInstance method and deserializeAttributes method read attributes from the POF stream. The difference between the two is that createInstance should only read the attributes that are necessary for instance creation, such as constructor or factory method arguments. All other object attributes should be read from the stream and set within the deserializeAttributes method.
In this chapter, we have covered some very important topics.
We discussed how various types of domain objects map to Coherence caches, how to model object relationships, and how you can use key association to ensure that related objects are stored within the same Coherence partition. We also talked about identity management and you learned how to use the identity generator provided by Coherence Tools project.
Then we moved on to discuss access to Coherence caches from your domain objects through repository interfaces and implemented a reusable base class for repository implementations that need to access data within Coherence caches.
Finally, we talked about serialization and schema evolution of domain objects and learned how to implement both in a way that optimizes serialization performance and size of the serialized objects, while allowing for rolling upgrades of an application that do not require us to shut the whole cluster down.
The material in this and the previous chapter provides you with enough information to place Coherence into the overall application architecture, create domain objects that work well with Coherence, and map them to Coherence caches.
In the next chapter, you will learn how to query and aggregate data in the Coherence cluster.