
Coherence was originally conceived as a reliable and scalable distributed cache for J2EE applications connected to relational databases. It has since evolved to become the market leader in data grid technologies. Today many users of Coherence forego the database and store the entire data set for their applications in memory.
However, in spite of the innovation that makes this architecture possible, these applications are still vastly outnumbered by applications that use a database as the system of record. Relational databases continue to be the workhorse of today's enterprise IT; the need for reliable persistence, along with the number of applications and reporting tools that use databases, indicate that they won't be going away anytime soon.
Coherence contains a rich set of features that make it an ideal caching layer for applications that rely on an external data source as the system of record. Relational databases are the most common data source used with Coherence; however, you have the ability to use any data source, including mainframes, web services, SAN file systems, and so on. We will use the term 'database' in the remainder of the chapter for simplicity, but keep in mind that you can put Coherence in front of pretty much any data source you can think of.
Note
Although any type of data source can be used, the one requirement is that it must be a shared resource that all storage members have access to.
This means that the persistence API described in this chapter should not be implemented with technologies requiring the use of local disk (writing to the local file system, embedded databases such as Berkeley DB, and so on).
In this chapter, we will explore persistence patterns offered by Coherence, including cache aside, read through, write through, and write behind. We will discuss the pros and cons of each approach, common issues that often come up, and features in Coherence that resolve these issues.
Perhaps the most common caching pattern in use today is cache aside. If you have ever used a standard map to implement primitive caching yourself, you are already familiar with this approach—you check if a piece of data is in the cache and if it isn't then you load it from the database and put it in the cache for future requests. When the data is subsequently updated, it is up to the application to either invalidate the cache or update it with the new value.
Applications that have a well-defined data access object (DAO) layer can easily treat caching as a cross-cutting concern. The DAO can be wrapped by a proxy that performs the cache-aside operations. This can be as simple as the use of java.util.Proxy or as advanced as the use of AspectJ or any other AOP framework.
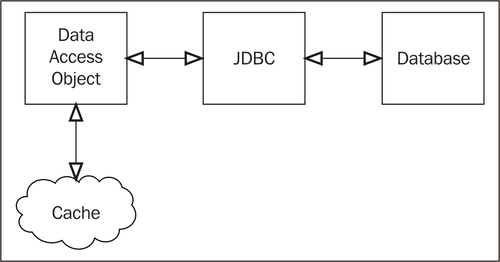
There are some consequences of cache aside that should be kept in mind:
If multiple threads require access to the same piece of data that is not in the cache, it may result in multiple redundant reads to the database.
When an application writes directly to the database, concurrency concerns are handled by the database, whether via optimistic or pessimistic locking. When writing to a cache in memory, data integrity must be maintained via some explicit concurrency control mechanism.
In the case of a single JVM, these problems are not too difficult to overcome although it will take some effort. However, when you start to add more JVMs (each with its own cache) things become complicated very quickly. The likelihood of these caches containing overlapping and inconsistent data is very high.
At this point we should mention that for some types of data this incoherency across JVMs might be acceptable, especially for small amounts of reference data that can easily fit within the allocated heap of the JVM. For data that must be consistent across JVMs and/or is updated often, cache aside in a local cache is clearly not the right solution.
To solve some of these cache-aside problems in a multi JVM environment, Coherence provides the following tools:
Although Coherence provides these tools to ease the implementation of a distributed cache-aside solution, it also provides tools that enable much more efficient and easier-to-implement persistence patterns.
When using cache aside, the application has to check both the cache and (potentially) the database when reading data. Although these operations can be abstracted away for most of the part, it would be easier if the developer could deal with just one source of data.
This is exactly what the read-through pattern provides. With the read-through pattern, the cache is the single interface the application deals with when reading data. If the requested piece of data exists in the cache it will be returned, thus avoiding a hit to the database. If the data is not in the cache, the cache itself will fetch the data from the database, store it, and return the value to the client. This approach has the following advantages:
The responsibility of connecting to the data source is pushed away from the client tier, thus simplifying client code.
Reads to the database are coalesced, meaning that multiple requests for a piece of data absent from the cache will result in one request to the database. This eliminates redundant reads to the database when multiple threads attempt to access the same piece of data simultaneously.
Moving the responsibility of database connectivity to the cache allows for optimizations, such as pre-fetching of the data to avoid having a client wait for data retrieval.
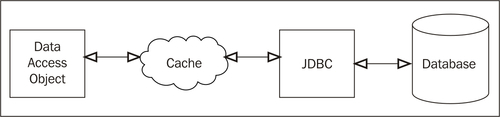
Enabling read through in Coherence requires the implementation of an interface called CacheLoader. The CacheLoader interface in its entirety is as follows:
public interface CacheLoader {
Object load(Object key);
Map loadAll(Collection keys);
}
The load method is responsible for retrieving the value from the database, based on the specified key. The loadAll method accepts a collection of keys that may be bulk loaded; it returns a map of the keys and their corresponding values loaded from the database. If one of the requested keys does not exist in the database, that key should be excluded from the result map. As can be observed via the key-based API, read through will only work with key-based access, that is, queries executed via the QueryMap API will not use CacheLoader.
Note
The loadAll method in CacheLoader will not be invoked by Coherence unless operation bundling is configured. This topic falls outside the scope of this book; however, this feature is documented in the Coherence user guide on OTN under the operation-bundling section.
Note that the interface does not dictate in any way what type of data store can be used. In the following example we will use the H2 database available at http://www.h2database.com/html/main.html.
Note
Accessing a NamedCache from a CacheLoader
In Chapter 5, Querying the Data Grid, we discussed the dangers of reentrant entry processors and the potential for deadlock. The same caveat also applies here; a CacheLoader or CacheStore (introduced later in this chapter) should not access its own cache or any other caches that belong to the same cache service.
Here is a simple implementation of CacheLoader for our Account class. Note that it extends AbstractCacheLoader, which provides a simple implementation of loadAll that delegates to load.
public class AccountCacheLoader
extends AbstractCacheLoader {
public AccountCacheLoader() throws Exception {
JdbcDataSource ds = new JdbcDataSource();
ds.setURL("jdbc:h2:tcp://localhost/db/coherent-bank-db");
ds.setUser("sa");
ds.setPassword("");
this.dataSource = ds;
}
@Override
public Object load(Object oKey) {
Connection con = null;
PreparedStatement ps = null;
ResultSet rs = null;
Account act = null;
try {
con = dataSource.getConnection();
ps = con.prepareStatement(
"SELECT id, description, balance, " +
"currency, last_tx, customer_id " +
"FROM accounts WHERE id = ?");
ps.setLong(1, (long) oKey);
rs = ps.executeQuery();
if (rs.next()) {
act = new Account(rs.getLong("id"),
rs.getString("description"),
new Money(rs.getLong("balance"),
rs.getString("currency")),
rs.getLong("last_tx"),
rs.getLong("customer_id"));
}
}
catch (SQLException e) {
throw new RuntimeException("Error loading key " + oKey, e);
}
finally {
// clean up connection, etc
}
return act;
}
private DataSource dataSource;
}
In order to use this CacheLoader, we must configure a read-write backing map.
The use of CacheLoader or CacheStore requires the backing map for the partitioned cache to be configured as a read-write backing map. A read-write backing map provides many configuration options for CacheLoader and CacheStore that will soon be covered in detail.
Note
A read-write backing map can only be used with partitioned caches; replicated caches are not supported.
The following is a sample configuration for the CacheLoader:
<distributed-scheme> <scheme-name>partitioned</scheme-name> <backing-map-scheme> <read-write-backing-map-scheme> <internal-cache-scheme> <local-scheme /> </internal-cache-scheme> <cachestore-scheme> <class-scheme> <class-name> com.seovic.coherence.book.ch8.AccountCacheLoader </class-name> </class-scheme> </cachestore-scheme> </read-write-backing-map-scheme> </backing-map-scheme> <autostart>true</autostart> </distributed-scheme>
The
<internal-cache-scheme>indicates the data structure that will be used for managing the data in memory; this will normally be<local-scheme>Under
<cachestore-scheme>, a<class-scheme>is used to configure the name of theCacheLoaderimplementation classWhen the backing map is instantiated for the cache, an instance of the
CacheLoaderwill be created by Coherence and held in memory
Although this CacheLoader will work perfectly well in development, it has several flaws that make it unsuitable for use in production, which are as follows:
The
DataSourceconfiguration is hard coded, thus requiring a recompile for any changesIt is not configured to use a connection pool, thus a new connection will be created each time
loadis invokedThe addition of another
CacheStorewill require theDataSourceconfiguration to be copied/pasted, or refactored so that it can be shared
Due to these issues, it may be desirable (but not required) to use a container to manage the configuration and shared infrastructure required for database connectivity. This can be accomplished with a standard JEE container such as Oracle WebLogic Server or Apache Tomcat.
It can also be accomplished with a non-JEE container such as the Spring Framework. For the remainder of this chapter, we will use Spring to manage cache stores and related artifacts.
Spring is a popular dependency injection framework that provides utility classes that make it easy to write JDBC code and manage a DataSource. A full tutorial on Spring is beyond the scope of this chapter; if you are unfamiliar with Spring please refer to the user guide at http://www.springsource.org/documentation.
The Coherence Tools project provides several useful classes that make both the implementation and configuration of CacheLoader and CacheStore classes much more convenient.
The first one is ConfigurableCacheStore, which allows you to configure cache stores within a Spring application context. The main benefit is that you can have a single backing map configuration for all persistent caches in your application. You configure Coherence to use ConfigurableCacheStore, which in turn delegates to the concrete CacheStore implementation defined within the Spring application context.
For example, we can add the following backing map definition to our cache configuration file and reuse it for all the caches that require persistence, as shown next:
<read-write-backing-map-scheme>
<scheme-name>persistent-backing-map</scheme-name>
<internal-cache-scheme>
<local-scheme>
<scheme-ref>unlimited-backing-map</scheme-ref>
</local-scheme>
</internal-cache-scheme>
<cachestore-scheme>
<class-scheme>
<class-name>
c.s.coherence.util.persistence.ConfigurableCacheStore
</class-name>
<init-params>
<init-param>
<param-type>string</param-type>
<param-value>{cache-name}</param-value>
</init-param>
</init-params>
</class-scheme>
</cachestore-scheme>
<write-delay>
{write-delay 0}
</write-delay>
<write-batch-factor>
{write-batch-factor 0}
</write-batch-factor>
<write-requeue-threshold>
{write-requeue-threshold 0}
</write-requeue-threshold>
<refresh-ahead-factor>
{refresh-ahead-factor 0}
</refresh-ahead-factor>
</read-write-backing-map-scheme>
The ConfigurableCacheStore constructor takes a single string argument, which is used to retrieve the concrete CacheStore to delegate to from the associated Spring context. In this example we are simply passing cache name, which implies that we will need to define a Spring bean with a matching name for each concrete cache store within the persistence context.
You should also notice that we use macro arguments to configure several read-write backing map settings at the bottom. This will allow us to change the persistence behavior of individual caches without having to create separate backing map configurations. These settings will be covered in the upcoming sections.
Now that we have a backing map definition, we can use it to configure the cache scheme for accounts, as is done in the following code:
<distributed-scheme> <scheme-name>accounts-scheme</scheme-name> <scheme-ref>default-partitioned</scheme-ref> <service-name>AccountsCacheService</service-name> <backing-map-scheme> <read-write-backing-map-scheme> <scheme-ref>persistent-backing-map</scheme-ref> </read-write-backing-map-scheme> </backing-map-scheme> <autostart>true</autostart> </distributed-scheme>
Another important benefit of ConfigurableCacheStore is that it allows us to use all the existing Spring constructs when configuring our cache stores, including transaction managers, data sources, connection pools, and so on. This makes cache store configuration significantly easier, as you'll see shortly.
The second useful class provided by the Coherence Tools project is AbstractJdbcCacheStore. This class uses Spring's JdbcTemplate to implement all necessary data access code, which makes implementation of concrete JDBC-based cache stores trivial; all you need to do is to define the SQL statements and RowMapper that will be used for object retrieval and persistence.
The following is a snippet of AbstractJdbcCacheStore relevant to the load operation:
@Transactional
public abstract class AbstractJdbcCacheStore<T>
extends AbstractBatchingCacheStore {
public AbstractJdbcCacheStore(DataSource dataSource) {
m_jdbcTemplate = new SimpleJdbcTemplate(dataSource);
}
protected abstract String getSelectSql();
protected abstract RowMapper<T> getRowMapper();
@Transactional(readOnly = true)
public Object load(Object key) {
List<T> results = getJdbcTemplate().query(
getSelectSql(), getRowMapper(),
getPrimaryKeyComponents(key));
return results.size() == 0 ? null : results.get(0);
}
protected Object[] getPrimaryKeyComponents(Object key) {
return new Object[] {key};
}
protected SimpleJdbcTemplate getJdbcTemplate() {
return m_jdbcTemplate;
}
private final SimpleJdbcTemplate m_jdbcTemplate;
AbstractJdbcCacheStore classAbstractJdbcCacheStore classabout}
The following is an implementation of the AccountJdbcCacheStore from our sample application, which leverages features provided by AbstractJdbcCacheStore. The parts relevant to load are included, as shown in the following code:
public class AccountJdbcCacheStore
extends AbstractJdbcCacheStore<Account> {
public AccountJdbcCacheStore(DataSource dataSource) {
super(dataSource);
}
@Override
protected String getSelectSql() {
return SELECT_SQL;
}
@Override
protected RowMapper<Account> getRowMapper() {
return ROW_MAPPER;
}
private static final RowMapper<Account> ROW_MAPPER =
new RowMapper<Account>() {
public Account mapRow(ResultSet rs, int i)
throws SQLException {
return new Account(rs.getLong("id"),
rs.getString("description"),
new Money(rs.getLong("balance"),
rs.getString("currency")),
rs.getLong("last_tx"),
rs.getLong("customer_id"));
}
};
private static final String SELECT_SQL = "SELECT id, description, balance, currency, " + "last_tx, customer_id " +
"FROM accounts WHERE id = ?";
}
Now that we have both the CacheStore and necessary cache configuration, the last thing we need to do is add the CacheStore bean definition to the Spring context defined in the persistence-context.xml file, which should be located in the root of the classpath:
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns=...> <tx:annotation-driven transaction-manager="txManager"/> <bean id="txManager" class="o.s.j.d.DataSourceTransactionManager"> <property name="dataSource" ref="dataSource"/> </bean> <!-- H2 DataSource connection pool --> <bean id="dataSource" class="org.h2.jdbcx.JdbcConnectionPool" factory-method="create"> <constructor-arg value="jdbc:h2:tcp://localhost/db/ coherent-bank-db"/> <constructor-arg value="sa"/> <constructor-arg value=""/> <property name="maxConnections" value="5" /> </bean> <!-- cache store definitions --> <bean name="accounts" class="c.s.s.bank.persistence.AccountJdbcCacheStore"> <constructor-arg ref="dataSource"/> </bean> </beans>
Note that the JDBC DataSource in this example is configured using the connection pool that ships with the H2 database we used for the sample application. If your JDBC driver does not provide its own connection pool you can use a third-party pool such as Apache DBCP (http://commons.apache.org/dbcp/) or C3P0 (http://sourceforge.net/projects/c3p0/). The Oracle Universal Connection Pool (UCP) is another free option for connection pooling, which is available at http://www.oracle.com/technology/tech/java/sqlj_jdbc/UCP_dev_guide.pdf.
The configuration above should be self-explanatory—the accounts bean is injected with a data source, which is the only dependency it requires.
Many Coherence applications do not have exclusive access to the database. In several cases the database and its contents outlive several generations of applications that create and access that data. For these types of applications, Coherence caches can be configured to expire after a configurable amount of time to limit data staleness.
The expiration of heavily accessed cached entries may cause inconsistent response times, as some requests will require a read through to the database. This is especially true for applications that have aggressive expiry configured in order to minimize the amount of time for which cache entries may remain stale. However, a read-write backing map can be configured to fetch these items from the database in a background thread before they expire from the cache.
This setting is controlled by<refresh-ahead-factor>, which is a fraction of the expiry time. If an entry is accessed from the cache during the configured refresh-ahead period, it will be refreshed from the data source in a background thread.
Our sample banking application uses an external REST web service to obtain exchange rates for currency conversion. In order to retrieve the rate on a cache miss, we have implemented a simple CacheLoader that uses Spring's RestTemplate to invoke the web service, as shown next:
public class ExchangeRateRestCacheLoader
extends AbstractCacheLoader {
public Object load(Object key) {
Map<String, String> params =
Collections.singletonMap("instrument", (String) key);
RestTemplate client = new RestTemplate();
String rate = client.getForObject(m_url, String.class, params);
return new BigDecimal(rate);
}
public void setUrl(String url) {
m_url = url;
}
private String m_url;
}
While this works well for the most part, the issue is that the external web service has non-deterministic latency. In most cases latency is minimal, but during peak periods it can be several seconds (which, for arguments sake, is not acceptable in our case).
Fortunately, we can use refresh ahead to solve the problem. The code snippet is as follows:
<cache-mapping> <cache-name>exchange-rates</cache-name> <scheme-name>exchange-rates-scheme</scheme-name> <init-params> <init-param> <param-name>refresh-ahead-factor</param-name> <param-value>.75</param-value> </init-param> </init-params> </cache-mapping> ... <distributed-scheme> <scheme-name>exchange-rates-scheme</scheme-name> <scheme-ref>default-partitioned</scheme-ref> <service-name>ExchangeRatesCacheService</service-name> <backing-map-scheme> <read-write-backing-map-scheme> <scheme-ref>persistent-backing-map</scheme-ref> <internal-cache-scheme> <local-scheme> <scheme-ref>unlimited-backing-map</scheme-ref> <expiry-delay>1m</expiry-delay> </local-scheme> </internal-cache-scheme> </read-write-backing-map-scheme> </backing-map-scheme> <autostart>true</autostart> </distributed-scheme>
By configuring the exchange rate cache to expire entries after one minute (which is the degree of staleness we are willing to tolerate), and setting refresh ahead factor to .75, we can ensure that any requests for entries that have been in the cache between 45 and 60 seconds will trigger an automatic refresh by invoking our cache loader (and consequently, the external web service).
However, keep in mind that refresh ahead only works for frequently accessed entries; if no requests are made for the entry after it has been in the cache for 45 seconds, it will be automatically evicted once it expires (after 60 seconds). In other words, refresh ahead is triggered by reads during the refresh-ahead interval, but not by evictions.
Another important thing to realize is that the read that initiates refresh ahead, as well as all the reads that come after it, will not block—refresh ahead is asynchronous, so all read requests will simply return the old value until it is updated by the loader.
There are a few additional items that should be configured in the read-write backing map to support read through. First, a<high-units> setting should be configured for the<local-scheme> in<internal-cache-scheme>. This will ensure that the storage-enabled cluster member does not run out of memory while storing cached data.
Additionally, a thread pool should be configured for the partitioned cache service. Normal partitioned caching does not require a thread pool. This is because a thread pool will cause the service thread to queue up a cache request and a context switch will be required for a worker thread to process the request. Since reading from memory is such a low-overhead operation, there will be less overhead if the service thread simply processes the request.
However, the inevitability of a cache request through the read-write backing map resulting in a blocking I/O call over the network makes it a requirement to configure a thread pool. The service thread is the lifeblood of the partitioned cache; it should be kept as free as possible so it can service requests coming from other cluster members.
To start with, configure the thread count to be equal to the number of connections in the connection pool. Your application may be able to handle more threads and/or less connections; be sure to load test your configuration before going to production.
In order to configure a thread pool for the AccountsCacheService we defined earlier, we need to add a thread-count configuration element to it, which is shown next:
<distributed-scheme> <scheme-name>accounts-scheme</scheme-name> <scheme-ref>default-partitioned</scheme-ref> <service-name>AccountsCacheService</service-name> <thread-count>5</thread-count> <backing-map-scheme> <read-write-backing-map-scheme> <scheme-ref>persistent-backing-map</scheme-ref> </read-write-backing-map-scheme> </backing-map-scheme> <autostart>true</autostart> </distributed-scheme>
Finally, when using read through, it may be desirable to maintain a set of cache misses. This information can be used to avoid reading through to the CacheLoader if the likelihood of the value existing in the database immediately after a cache miss is low.
This cache can be configured via the<miss-cache-scheme> in the read-write backing map. This setting requires the use of<local-scheme>, which would ideally be configured with an expiry that indicates how long the read-write backing map will wait before reissuing a load request for a given key to the CacheLoader.
The pattern of accessing the cache exclusively for reading data can be extended for writing data as well. Write through inherits all of the benefits associated with read through, but it adds a few of its own as well, which are as follows:
A single point of data update simplifies the handling of concurrent updates.
While write through is synchronous by default, it could easily be made asynchronous by changing a configuration option, which will be covered in the next section.
The biggest benefit of synchronous (as opposed to asynchronous) writes is that failed operations to the database will cause the cache update to roll back, and an exception will be thrown to the client indicating the failure of the store operation.
Note
Prior to Coherence 3.6, the default handling of write through failure was to log the exception on the storage cluster member and allow the cache write to succeed. In order to propagate the store exception to the client and roll back the cache update, the<rollback-cachestore-failures> element in the read-write backing map configuration should be set to true.
To enable writes to the database via the cache, the CacheStore interface must be implemented. The CacheStore interface in its entirety is as follows:
public interface CacheStore extends CacheLoader {
void store(Object oKey, Object oValue);
void storeAll(Map mapEntries);
void erase(Object oKey);
void eraseAll(Collection colKeys);
}
Note that CacheStore extends CacheLoader. As is the case with CacheLoader, Coherence provides an AbstractCacheStore class that implements the bulk operation methods by iterating each entry and invoking the respective corresponding single entry methods.
The store implementation of AbstractJdbcCacheStore is as follows:
protected abstract String getMergeSql();
public void store(Object key, Object value) {
getJdbcTemplate().update(getMergeSql(),
new BeanPropertySqlParameterSource(value));
}
The AccountJdbcCacheStore class including the code required for store is as follows:
public class AccountJdbcCacheStore
extends AbstractJdbcCacheStore<Account> {
public AccountJdbcCacheStore(DataSource dataSource) {
super(dataSource);
}
...
@Override
protected String getMergeSql() {
return MERGE_SQL;
}
...
private static final String MERGE_SQL =
"MERGE INTO accounts (id, description, "+
"balance, currency, last_tx, customer_id) " +
"VALUES (:id, :description, :balance.amount, "+
":balance.currency.currencyCode, " +
":lastTransactionId, :customerId)";
}
Write through is an excellent choice in many situations, but unfortunately it will only scale as far as the underlying database scales. If you need to scale data writes beyond that, you will need to use the asynchronous cousin of write through—write behind.
Most users of Coherence choose the write behind pattern for updating data through the cache. Write behind offers the following benefits over write through:
The response time and scalability of updates will be decoupled from the database
Multiple updates to the same entry are coalesced, thus resulting in a reduction in the number of updates sent to the database
Multiple updates to different entries can be batched
The application can continue to function upon database failure
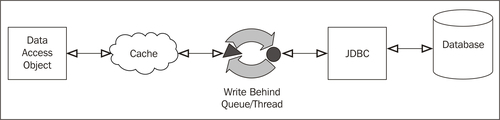
In order to configure write behind, modify the<write-delay> setting in the read-write backing map configuration to the amount of time the data should live in the cache before being flushed to the database.
Upon insertion into a read-write backing map configured with write behind, an entry will be queued until it is time to write it out to the CacheStore. An entry that has lived in the queue for the amount of time specified by the write delay setting is considered to be ripe. Once a cache entry becomes ripe, a dedicated write-behind thread will dequeue that entry and other ripe entries, and write them out to the CacheStore.
A read-write backing map can also be configured to write queued entries that have not reached ripe status via<write-batch-factor>. This value is a percentage of the<write-delay> time and is specified as a double (between 0.0 and 1.0). Entries in the write behind queue that reach this threshold are considered soft-ripe. A value of 1.0 will store all entries that are currently in the queue, whereas 0.0 (the default) will only store ripe entries.
Accounts and transactions are the most heavily used objects in our banking applications. To make things worse, they are also heavily write-biased, that is, whenever a new transaction is posted, it is inserted into the transaction cache and the corresponding account is updated.
While we would prefer the reliability of a synchronous write through, the transaction volume is so high that our database simply cannot cope with it. Thus, we will use write behind to increase throughput, which means we will simply write transactions and account updates into Coherence and allow the database to catch up in the background.
There are two reasons why write behind is a good fit. In the case of accounts, a single account object might be updated several times a second. Instead of writing each update into the database, write behind will allow us to coalesce them and perform a single database update for many cache updates. In the case of transactions, it will allow us to perform bulk inserts by batching many transactions into a single database call (this feature is introduced in a subsequent section). Both of these features will allow us to significantly reduce the database load, while at the same time reducing latency and improving throughput from the end-user perspective.
You have seen earlier that we defined macro parameters for write-delay and write-batch-factor within the persistent-backing-map definition, which makes it simple to enable write behind for accounts and transactions. We just need to define these two parameters within the corresponding cache mappings, as shown next:
<cache-mapping> <cache-name>accounts</cache-name> <scheme-name>accounts-scheme</scheme-name> <init-params> <init-param> <param-name>write-delay</param-name> <param-value>10s</param-value> </init-param> <init-param> <param-name>write-batch-factor</param-name> <param-value>.25</param-value> </init-param> </init-params> </cache-mapping> <cache-mapping> <cache-name>transactions</cache-name> <scheme-name>accounts-scheme</scheme-name> <init-params> <init-param> <param-name>write-delay</param-name> <param-value>10s</param-value> </init-param> <init-param> <param-name>write-batch-factor</param-name> <param-value>.25</param-value> </init-param> </init-params> </cache-mapping>
This configuration will enable write behind for these two caches and will persist all entries between 2.5 and 10 seconds old.
As previously mentioned, Coherence ships with AbstractCacheStore, which provides a default implementation of storeAll that iterates the map passed to it and invokes store on each entry. Although this implementation works, it may not be the optimal way of storing multiple entries to the database.
With a write through configuration, this method will never be invoked by Coherence (unless operation-bundling is enabled, see the previous note on loadAll). Each entry will be written to the database via the store method, even if using putAll from the client.
On the other hand, write behind does invoke storeAll when there are multiple entries in the queue that need to be stored. Therefore, a CacheStore configured to use write behind should take advantage of any batching functionality provided by the database. Many databases and other data stores have batching features that allow for a much more efficient (in terms of both latency and throughput) storeAll implementation.
The AbstractJdbcCacheStore base class being used for our CacheStore implementations extends AbstractBatchingCacheStore, and implements an abstract method storeBatch, as shown next:
public void storeBatch(Map mapBatch) {
SqlParameterSource[] batch =
SqlParameterSourceUtils.createBatch(
mapBatch.values().toArray());
getJdbcTemplate().batchUpdate(getMergeSql(), batch);
}
This implementation uses batching via Spring's SimpleJdbcTemplate.batchUpdate method, whose underlying implementation uses JDBC PreparedStatement batching, to execute the updates. Depending on the JDBC driver implementation and latency to the database, batching updates in this manner can yield an order of magnitude performance improvement over sending one update at a time, even within the same database transaction.
Note
If you implement a CacheStore using a JPA implementation such as TopLink or Hibernate, refer to their respective documents on batching.
In turn, storeBatch is invoked by AbstractBatchingCacheStore as follows:
public void storeAll(Map mapEntries) {
int batchSize = getBatchSize();
if (batchSize == 0 || mapEntries.size() < batchSize) {
storeBatch(mapEntries);
}
else {
Map batch = new HashMap(batchSize);
while (!mapEntries.isEmpty()) {
// since entries will be removed from mapEntries,
// the iterator needs to be recreated every time
Iterator iter = mapEntries.entrySet().iterator();
while (iter.hasNext() && batch.size() < batchSize) {
// retrieving the entry will force
// deserialization
Map.Entry entry = (Map.Entry) iter.next();
batch.put(entry.getKey(), entry.getValue());
}
storeBatch(batch);
// remove the entries we've successfully stored
mapEntries.keySet().removeAll(batch.keySet());
batch.clear();
}
}
}
AbstractBatchingCacheStore gives us more control over batching granularity, by allowing us to chunk the map passed by the write-behind thread to storeAll into batches of configurable size.
Let's say that we have determined during load testing that batches of 500 objects work best for our application. Although you can use the write batch factor to roughly determine the percentage of queued entries that will be persisted at a time, there is no way to tell Coherence exactly how many objects to send in each batch. You might get 50, or you might get 10,000.
Smaller batches are usually not a problem—they simply lighter load on the system. However, writing out a large number (thousands) of items to a database in a single batch may be suboptimal for various reasons (very large transactions requiring a large transaction/rollback log in the database, memory consumption by the JDBC driver, and so on). It will also cause Coherence to consume more memory in the storage member.
As mentioned in the previous chapters, data is stored in binary format in the backing map. This is also the case for data stored in the write-behind queue. The map passed to storeAll will deserialize its contents lazily. If a large amount of data is passed in the map and it is deserialized in its entirety to perform a batch store, the JVM may experience very long GC pauses or even run out of heap. Therefore, it is a good idea to cap the number of items written to the database in a single batch.
Fortunately, the solution is simple—implement chunking within the storeAll method and persist large batches in multiple database calls. This is exactly what AbstractBatchingCacheStore does for us; all we need to do is configure the batch size for accounts and transactions within our cache store bean definitions, as shown next:
<bean name="accounts" class="c.s.s.b.persistence.AccountJdbcCacheStore"> <constructor-arg ref="dataSource"/> <property name="batchSize" value="500"/> </bean> <bean name="transactions" class="c.s.s.b.persistence.TransactionJdbcCacheStore"> <constructor-arg ref="dataSource"/> <property name="batchSize" value="500"/> </bean>
Both Coherence cluster members and persistent data stores that Coherence writes data to could fail at any time. That means that we need to be prepared to deal with such failures.
In order to handle member failover correctly, store and storeAll implementations must be idempotent, which means that invoking these methods multiple times for the same entry will not yield undesired effects.
To demonstrate why this is necessary, consider the case where a primary storage member receives a put request, calls store to write it to the database, and fails before sending the entry to the backup member. The client will detect the failure of the storage member and repeat the operation, as it never received confirmation from the failed member that the operation did in fact succeed. If the store operation is idempotent, the backup member can invoke the operation again without any ill side effects.
Handling a store failure in write-through mode is fairly straightforward. If an exception is thrown by store, the exception will be propagated to the client inserting the cache entry (see the previous section on write through for caveats).
Dealing with store failures in a write behind scenario is more complex. The client performing the write to the cache will not have an exception thrown to it upon failure, so it is incapable of handling the exception. Therefore we will explore several strategies and configuration options intended to deal with write behind store failures.
The first thing to note is that there are no guarantees as far as ordering of writes to the database goes. Therefore, it is not advised to have store or storeAll implementations with external dependencies, including referential integrity, or data validation on the database tier that is not performed on the application tier.
If a store operation does fail, the entry will not be requeued by default. Requeuing can be enabled by setting<write-requeue-threshold> to the maximum number of entries that should exist in the queue upon failure. When another attempt is made to store the failed entries, the entire set of requeued entries will be passed to the storeAll method, thus the intention of<write-requeue-threshold> is to cap the
size of the map sent to storeAll after a storeAll failure. This limitation is in place to protect against storeAll implementations that attempt to write the contents of the entire map at once. For properly implemented storeAll implementations (such as the one provided by AbstractBatchingCacheStore) the<write-requeue-threshold> setting can be set very high to ensure that all failed entries are requeued.
Note
This behavior has changed in Coherence 3.6. The read-write backing map will now limit the number of entries sent to storeAll regardless of how many entries are in the write-behind queue. By default this limit is set to 128, but it can be modified via the<write-max-batch-size> setting. To enable requeuing in Coherence 3.6,<write-requeue-threshold> should be set to a value greater than 0.
If storeAll throws an exception, the read-write backing map will requeue all entries that are still present in mapEntries. Therefore, removing entries that are successfully stored will reduce the number of entries that need to be requeued in case of failure.
It is considered a good practice to configure backing maps with size limits to prevent an OutOfMemoryError in the cache server tier. This can present interesting challenges in a write-behind scenario.
Consider the case where a client thread performs a put into a cache that causes evictions to occur to avoid exceeding high units. What will happen if the eviction policy dictates that we evict an entry from the backing map that is still in the write-behind queue (and therefore has not been flushed to the database)?
In this situation, the read-write backing map will synchronously invoke the store operation on any entries about to be evicted. The implication here is that the client thread performing the put operation will be blocked while evicted entries are flushed to the database. It is an unfortunate side effect for the client thread, as its operation will experience a higher than expected latency, but it acts as a necessary throttle to avoid losing data.
This edge condition highlights the necessity to configure a worker thread pool even for caches that are strictly performing write behind in order to prevent this flush from occurring on the service thread. It is important to keep in mind that the store operation won't always necessarily be performed by the write-behind thread.
Note that this can also occur with caches that have expiry configured. The likelihood of this occurring will decrease if there is a large difference between expiry time and write-behind time.
The CacheStore interface defines erase and eraseAll for removing entries from a backing store. These operations are always performed synchronously, even if write behind is enabled.
That said, most enterprise databases never allow the execution of DELETE statements. Instead, records no longer in use are flagged as inactive. It is therefore expected that erase and eraseAll will be implemented sparingly.
The erase implementation of AbstractCacheStore throws UnsupportedOperationException to indicate that the method is not implemented. This is also optional for store and storeAll implementations. If the read-write backing map detects that any of these methods are not implemented, it will refrain from invoking them in the future.
By default Coherence distributed caches will maintain one backup copy of each cache entry. When using a read-write backing map, other backup options may be considered that will reduce overall memory consumption across the cluster and allow for greater storage capacity.
Applications that use read through are most likely using a database as the system of record. If a storage member is lost, the data can be retrieved from the database when needed. Therefore, this type of application may be a good candidate for a distributed cache with backups disabled.
Disabling backups will slightly improve read through performance (as a backup copy will not be made when the object is loaded from the database) and it will increase the storage capacity of the distributed cache. The downside is increased latency to retrieve lost items from the database if a storage member fails.
To disable backups, add the following to<distributed-scheme>:
<backup-count>0</backup-count>
Although disabling backups with read through is a good combination, disabling backups with write behind is not a good idea, as it can result in data loss if a storage member fails while cache entries are in the write behind queue.
However, once the queued entries are flushed, it may be desirable to remove the backup copy for the reasons mentioned previously. This can be enabled in<distributed-scheme> with the following setting:
<backup-count-after-writebehind> 0 </backup-count-after-writebehind>
Coherence ships with a number of CacheStore implementations that work with popular commercial and open-source object relational mapping (ORM) tools including JPA, TopLink, and Hibernate.
This section will highlight the steps required to configure the JPA CacheStore with EclipseLink (http://www.eclipse.org/eclipselink/). Please refer to the Coherence User Guide for configuration details regarding TopLink and Hibernate. If you are using TopLink, it is recommended to investigate TopLink Grid (http://www.oracle.com/technology/products/ias/toplink/tl_grid.html), as it ships with custom CacheLoader and CacheStore implementations that auto-configure a persistence unit for use in a CacheStore context.
The first step is to modify the Account object with the required JPA annotations, as shown next:
@Entity
@Table(name="accounts")
public class Account
implements Serializable {
public Account() {
}
...
@Id
private long id;
...
}
There are several ways of mapping a Java class to a relational database using JPA. The previous example uses field-level mapping and specifies the table and column names that deviate from the defaults. There is no @GeneratedValue annotation as JPA will not be responsible for key generation. In general, optimistic locking should not be enabled, especially when combined with write behind.
The next step is to create the META-INF/persistence.xml file that JPA requires for configuration:
<persistence xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_1_0.xsd" version="1.0"> <persistence-unit name="CoherentBankUnit" transaction-type="RESOURCE_LOCAL"> <provider> org.eclipse.persistence.jpa.PersistenceProvider </provider> <class>com.seovic.coherence.book.ch8.Account</class> <properties> <property name="javax.persistence.jdbc.driver" value="oracle.jdbc.OracleDriver"/> <property name="javax.persistence.jdbc.url" value="jdbc:oracle:thin:@10.211.55.4:1521:XE"/> <property name="javax.persistence.jdbc.user" value="scott"/> <property name="javax.persistence.jdbc.password" value="tiger"/> <property name="eclipselink.cache.shared.default" value="false"/> <property name="eclipselink.jdbc.read-connections.min" value="1"/> <property name="eclipselink.jdbc.read-connections.max" value="3"/> <property name="eclipselink.jdbc.write-connections.min" value="2"/> <property name="eclipselink.jdbc.write-connections.max" value="5"/> <property name="eclipselink.jdbc.batch-writing" value="JDBC"/> <property name="eclipselink.logging.level" value="FINEST"/> </properties> </persistence-unit> </persistence>
As EclipseLink is running outside of a JEE container, the only supported transaction type is RESOURCE_LOCAL. Note that JPA entities should be listed in<class> elements.
By default L2 caching is enabled; this should be disabled (via the eclipselink.cache.shared.default property) when using EclipseLink in a CacheStore, as L2 caching would be redundant.
EclipseLink ships with a connection pool suitable for JPA applications running outside of a container, the settings for which are configured via the eclipselink.jdbc.*-connections properties indicated in persistence.xml previously. To enable batching for storeAll operations, the eclipselink.jdbc.batch-writing property is set for JDBC PreparedStatement batching. For development/testing purposes, logging is set to the highest setting (to produce the most output); this should be adjusted accordingly when deploying to production.
Finally, the following modifications should be made to coherence-cache-config.xml:
<class-scheme> <class-name> com.tangosol.coherence.jpa.JpaCacheStore </class-name> <init-params> <!-- Entity name --> <init-param> <param-type>java.lang.String</param-type> <param-value>account</param-value> </init-param> <!-- Fully qualified entity class name --> <init-param> <param-type>java.lang.String</param-type> <param-value> com.seovic.samples.bank.domain.Account </param-value> </init-param> <!-- Persistence unit name --> <init-param> <param-type>java.lang.String</param-type> <param-value>CoherentBankUnit</param-value> </init-param> </init-params> </class-scheme>
Note the name of the CacheStore class, com.tangosol.coherence.jpa.JpaCacheStore. This class ships with Coherence, but in order to use it, you will need to add coherence-jpa.jar to the classpath.
The JpaCacheStore constructor requires the following parameters:
As we are using ConfigurableCacheStore, we can optionally leave the Coherence cache configuration alone, and simply change the definition of our accounts bean within persistence-context.xml, as shown next:
<bean name="accounts" class="com.tangosol.coherence.jpa.JpaCacheStore"> <constructor-arg value="Account"/> <constructor-arg value="com.seovic.samples.bank.domain.Account"/> <constructor-arg value="CoherentBankUnit"/> </bean>
This simplified configuration for JpaCacheStore is a further demonstration of the benefits of using ConfigurableCacheStore in Spring-based Coherence applications.
Relational databases, web services, and even mainframes are permanent fixtures in today's IT ecosystem. The need to persist data to disk will never go away; however the demand for reliable, scalable, and fast access to data increases with each passing day.
The advanced caching features provided by Coherence render it an excellent choice to bridge the gap between legacy systems and producers/consumers of data hosted by these systems.
This chapter gave you enough information to choose the most appropriate persistence approach for your caches. You can easily integrate Coherence into existing applications using the cache-aside pattern.
However, if you want to take it a step further and reap the benefits of coalesced reads and a single data source for application developers to deal with, you can switch to read through by implementing and configuring the necessary cache loaders. When working with a high-latency data source, you can use refresh-ahead functionality to ensure that frequently accessed data is automatically updated before it expires.
If you also need to write data into the database, you can chose between synchronous write through and asynchronous write behind. The later is especially attractive if you need to minimize latency and maximize throughput, and will allow you to keep the database load within comfortable boundaries as you scale into extreme transaction processing (XTP).
In the next chapter we will look at Coherence support for remote grid clients, a feature that allows you to extend Coherence to users' desktops and to connect Coherence clusters across the WAN.